
Two-Level Attention Module Based on Spurious-3D Residual Networks for Human Action Recognition

Abstract
:1. Introduction
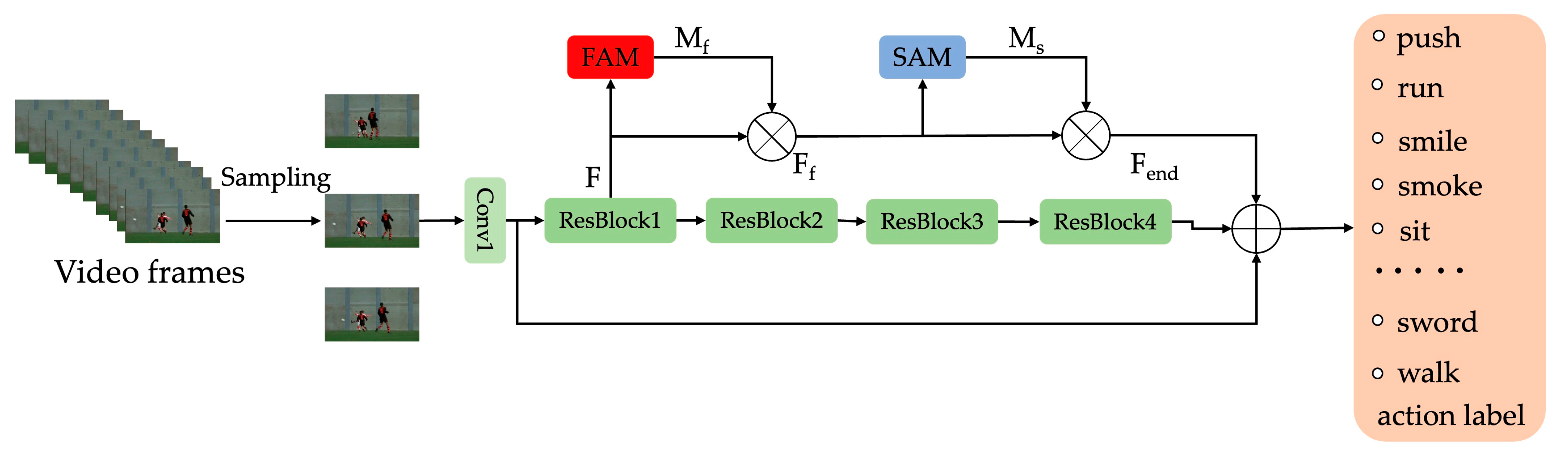
- We propose an FSAN model with the ability to model spatiotemporal features of video information. FSAN contains a spurious-3D convolutional network and a two-level attention module that can be easily implemented and embedded into a CNN-based action recognition model with end-to-end training.
- We design an effective two-level attention module to help exploit information features across channel, time and space dimensions, and a video frame attention module to highlight the more important frames in the entire video sequence to reduce interference due to similarities between heterogeneous action video sequences. The spatial attention module focuses on the more important spatial regions in some given frames.
- Implementing end-to-end training on two challenging action recognition datasets, UCF101 and HMDB51, FSAN outperforms state-of-the-art video action recognition networks compared to existing methods.
2. Related Works
2.1. Video-Based Action Recognition
2.2. Attention Mechanism
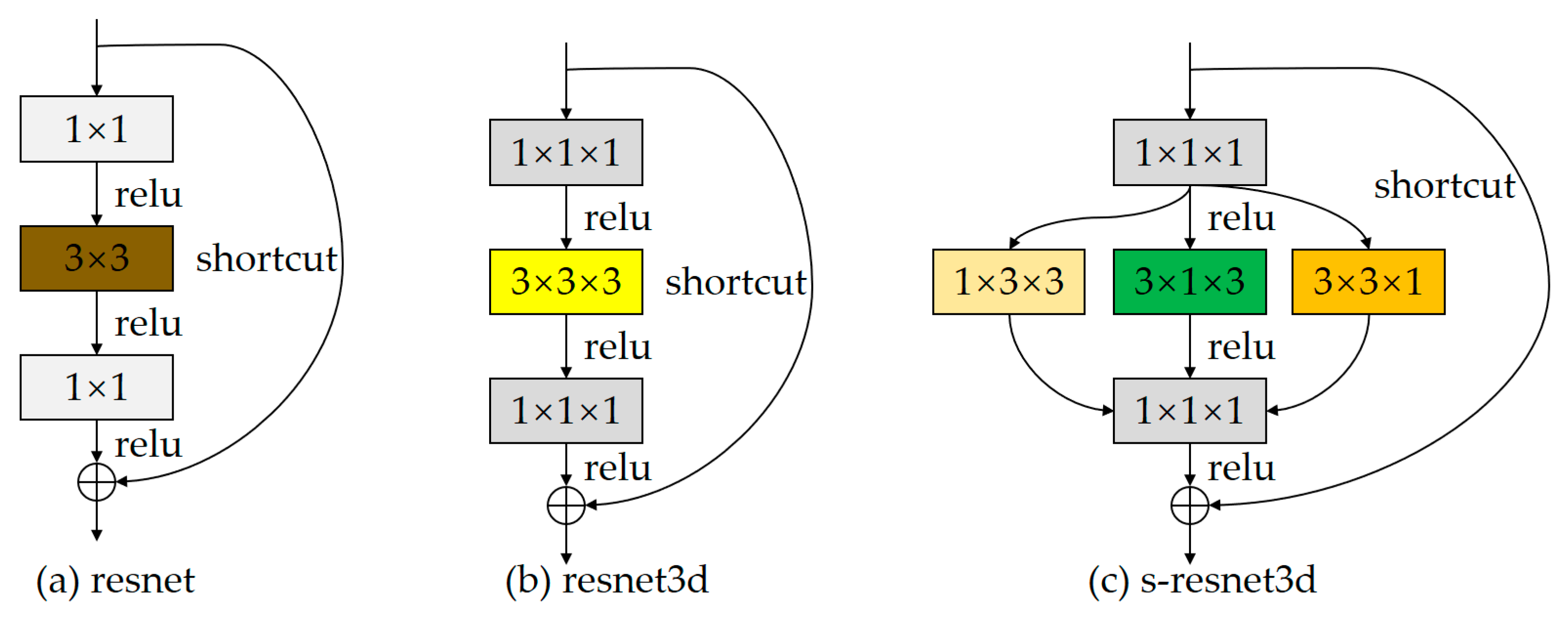
3. Module Design
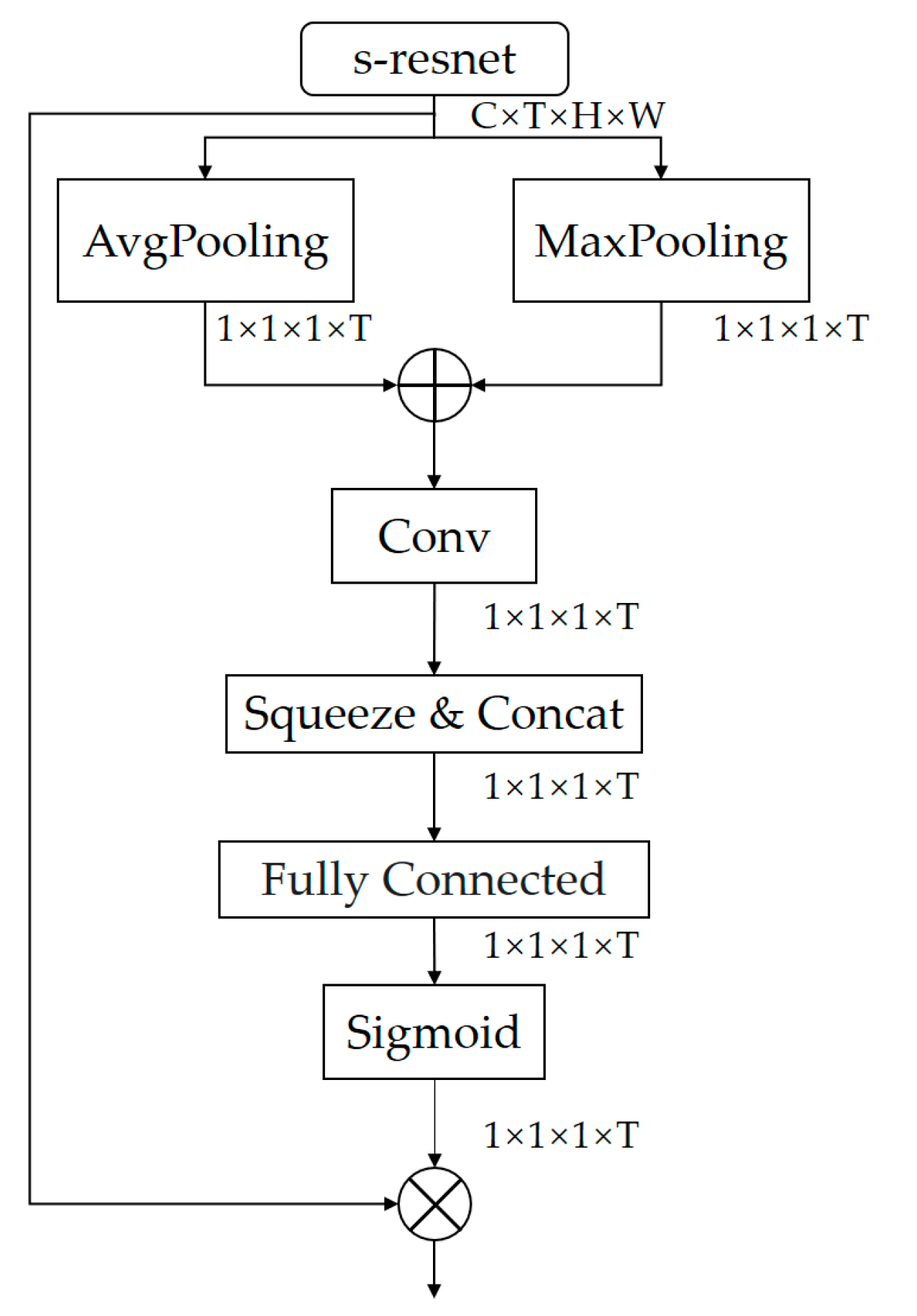
3.1. Frame Attention Module
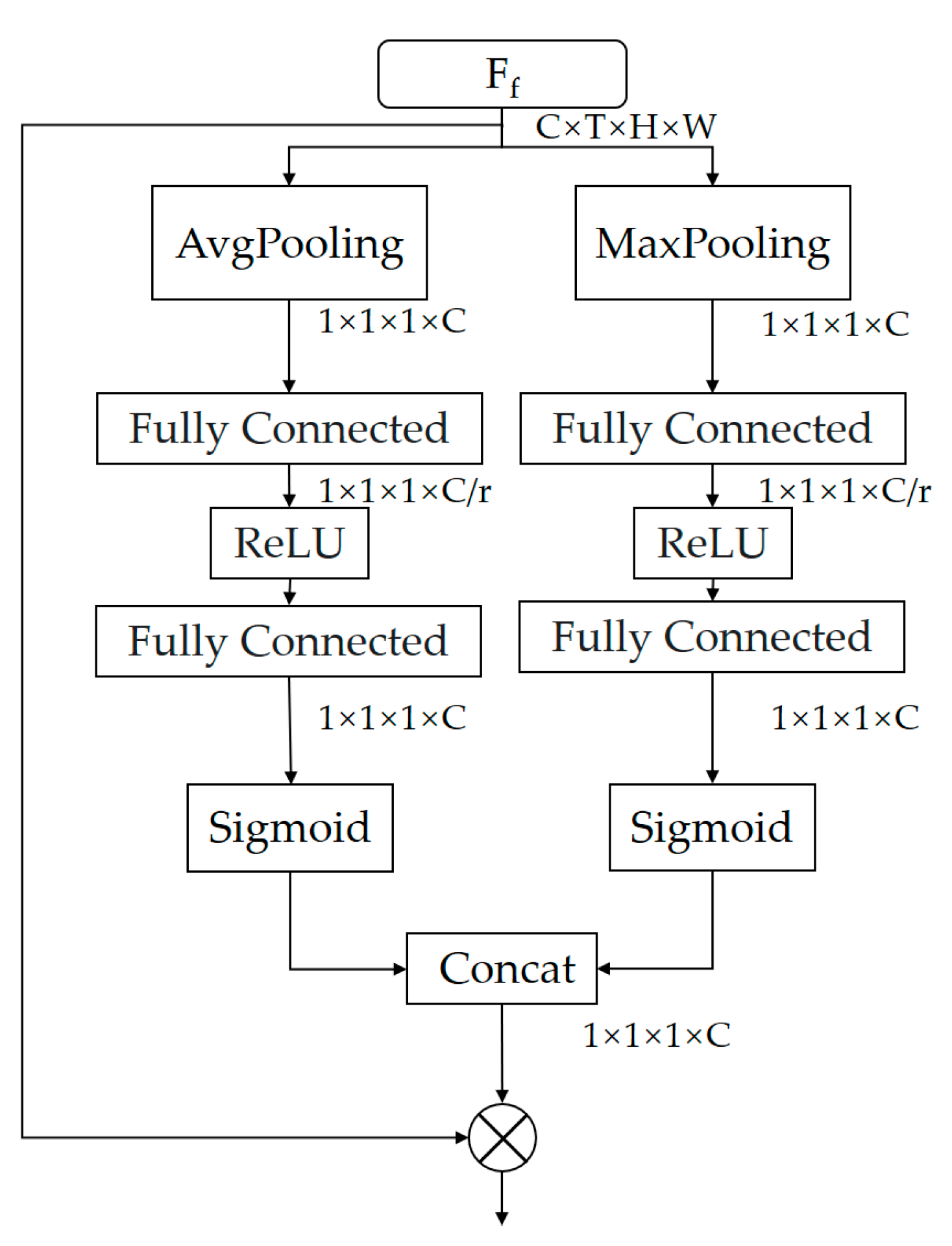
3.2. Spatial Attention Module
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.2.1. Data Processing
4.2.2. Training Settings
4.2.3. Inference
4.3. Ablation Studies
4.4. Comparisons with the State-of-the-Art
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yi, S.; Li, H.; Wang, X. Pedestrian Behavior Modeling from Stationary Crowds With Applications to Intelligent Surveillance. IEEE Trans. Image Process. 2016, 25, 4354–4368. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, C.; Zhou, H.; Sakane, S. Learning by showing: An end-to-end imitation leaning approach for robot action recognition and generation. In Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics (ROBIO), Qingdao, China, 3–7 December 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kaur, A.; Singh, Y.; Neeru, N.; Kaur, L.; Singh, A. A Survey on Deep Learning Approaches to Medical Images and a Systematic Look up into Real-Time Object Detection. Arch. Comput. Methods Eng. 2022, 29, 2071–2111. [Google Scholar] [CrossRef]
- Wang, T.; Li, J.K.; Wu, H.N.; Li, C.; Snoussi, H.; Wu, Y. ResLNet: Deep residual LSTM network with longer input for action recogntion. Front. Comput. Sci. 2022, 16, 166334. [Google Scholar] [CrossRef]
- Vrskova, R.; Hudec, R.; Kamencay, P.; Sykora, P. Human Activity Classification Using the 3DCNN Architecture. Appl. Sci. Basel 2022, 12, 931. [Google Scholar] [CrossRef]
- Moniruzzaman, M.; Yin, Z.Z.; He, Z.H.; Qin, R.W.; Leu, M.C. Human Action Recognition by Discriminative Feature Pooling and Video Segment Attention Model. IEEE Trans. Multimed. 2022, 24, 689–701. [Google Scholar] [CrossRef]
- Chen, B.; Tang, H.; Zhang, Z.; Tong, G.; Li, B. Video-based action recognition using spurious-3D residual attention networks. Iet Image Process. 2022, 16, 3097–3111. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- Du, T.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Lan, Z.Z.; Lin, M.; Li, X.C.; Hauptmann, A.G.; Raj, B. Beyond Gaussian Pyramid: Multi-skip Feature Stacking for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Peng, X.J.; Zou, C.Q.; Qiao, Y.; Peng, Q. Action Recognition with Stacked Fisher Vectors. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Wang, H.; Schmid, C. Action Recognition with Improved Trajectories. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems. Commun. ACM 2012, 25, 84–90. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, CA, USA, 8–13 December 2014. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sun, M.; Yuan, Y.C.; Zhou, F.; Ding, E.R. Multi-Attention Multi-Class Constraint for Fine-grained Image Recognition. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zheng, H.L.; Fu, J.L.; Mei, T.; Luo, J.B. Learning Multi-Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, F.; Jiang, M.Q.; Qian, C.; Yang, S.; Li, C.; Zhang, H.G.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, H.; Chen, J.; Hu, R.; Yu, M.; Chen, H.; Xu, Z. Action Recognition Using Visual Attention with Reinforcement Learning. In Proceedings of the 25th International Conference on MultiMedia Modeling (MMM), Thessaloniki, Greece, 8–11 January 2019. [Google Scholar]
- Ma, C.Y.; Kadav, A.; Melvin, I.; Kira, Z.; AlRegib, G.; Graf, H.P. Attend and Interact: Higher-Order Object Interactions for Video Understanding. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 January 2018. [Google Scholar]
- Girdhar, R.; Ramanan, D. Attentional Pooling for Action Recognition. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Chen, L.; Liu, Y.G.; Man, Y.C. Spatial-temporal channel-wise attention network for action recognition. Multimed. Tools Appl. 2021, 80, 21789–21808. [Google Scholar] [CrossRef]
- Shi, Z.S.; Cao, L.J.; Guan, C.; Zheng, H.Y.; Gu, Z.R.; Yu, Z.B.; Zheng, B. Learning Attention-Enhanced Spatiotemporal Representation for Action Recognition. IEEE Access 2020, 8, 16785–16794. [Google Scholar] [CrossRef]
- Long, X.; Gan, C.; de Melo, G.; Wu, J.J.; Liu, X.; Wen, S. Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, J.C.; Peng, Y.X. Hierarchical Vision-Language Alignment for Video Captioning. In Proceedings of the 25th International Conference on MultiMedia Modeling (MMM), Thessaloniki, Greece, 8–11 January 2019. [Google Scholar]
- Zhang, J.C.; Peng, Y.X.; Soc, I.C. Object-aware Aggregation with Bidirectional Temporal Graph for Video Captioning. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 January 2019. [Google Scholar]
- Peng, Y.X.; Zhao, Y.Z.; Zhang, J.C. Two-Stream Collaborative Learning With Spatial-Temporal Attention for Video Classification. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 773–786. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y. Towards Good Practices for Very Deep Two-Stream ConvNets. arXiv 2015, arXiv:1507.02159. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhou, Y.; Sun, X.; Zha, Z.-J.; Zeng, W. MiCT: Mixed 3D/2D Convolutional Tube for Human Action Recognition. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, H.; Yuan, C.; Zhang, L.; Sun, Y.; Hu, W.; Maybank, S.J. STA-CNN: Convolutional Spatial-Temporal Attention Learning for Action Recognition. IEEE Trans. Image Process. 2020, 29, 5783–5793. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Yang, Y.; Lu, Z.; Yang, J.; Liu, D.; Zhou, C.; Fan, Z. STA-TSN: Spatial-Temporal Attention Temporal Segment Network for action recognition in video. PLoS ONE 2022, 17, e0265115. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Xie, M.; Zhang, Y.; Ding, G.; Tong, W. Dual attention convolutional network for action recognition. Iet Image Process. 2020, 14, 1059–1065. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Shen, Z.W.; Wu, X.J.; Kittler, J. 2D progressive fusion module for action recognition. Image Vis. Comput. 2021, 109, 104122. [Google Scholar] [CrossRef]
- Zhang, Y. MEST: An Action Recognition Network with Motion Encoder and Spatio-Temporal Module. Sensors 2022, 22, 6595. [Google Scholar] [CrossRef]
- Yang, G.; Zou, W.X. Deep learning network model based on fusion of spatiotemporal features for action recognition. Multimed. Tools Appl. 2022, 81, 9875–9986. [Google Scholar] [CrossRef]
- Tu, Z.; Li, H.; Zhang, D.; Dauwels, J.; Li, B.; Yuan, J. Action-Stage Emphasized Spatiotemporal VLAD for Video Action Recognition. IEEE Trans. Image Process. 2019, 28, 2799–2812. [Google Scholar] [CrossRef]
- Wang, L.; Tong, Z.; Ji, B.; Wu, G.; Ieee Comp, S.O.C. TDN: Temporal Difference Networks for Efficient Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Omi, K.; Kimata, J.; Tamaki, T. Model-Agnostic Multi-Domain Learning with Domain-Specific Adapters for Action Recognition. IEICE Trans. Inf. Syst. 2022, 105, 2119–2126. [Google Scholar] [CrossRef]
- Dave, I.; Gupta, R.; Rizve, M.N.; Shah, M. TCLR: Temporal contrastive learning for video representation. Comput. Vis. Image Underst. 2022, 219, 103406. [Google Scholar] [CrossRef]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action Recognition in Video Sequences using Deep Bi-Directional LSTM With CNN Features. IEEE Access 2018, 6, 1155–1166. [Google Scholar] [CrossRef]
- Sahoo, S.P.; Ari, S.; Mahapatra, K.; Mohanty, S.P. HAR-Depth: A Novel Framework for Human Action Recognition Using Sequential Learning and Depth Estimated History Images. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 813–825. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
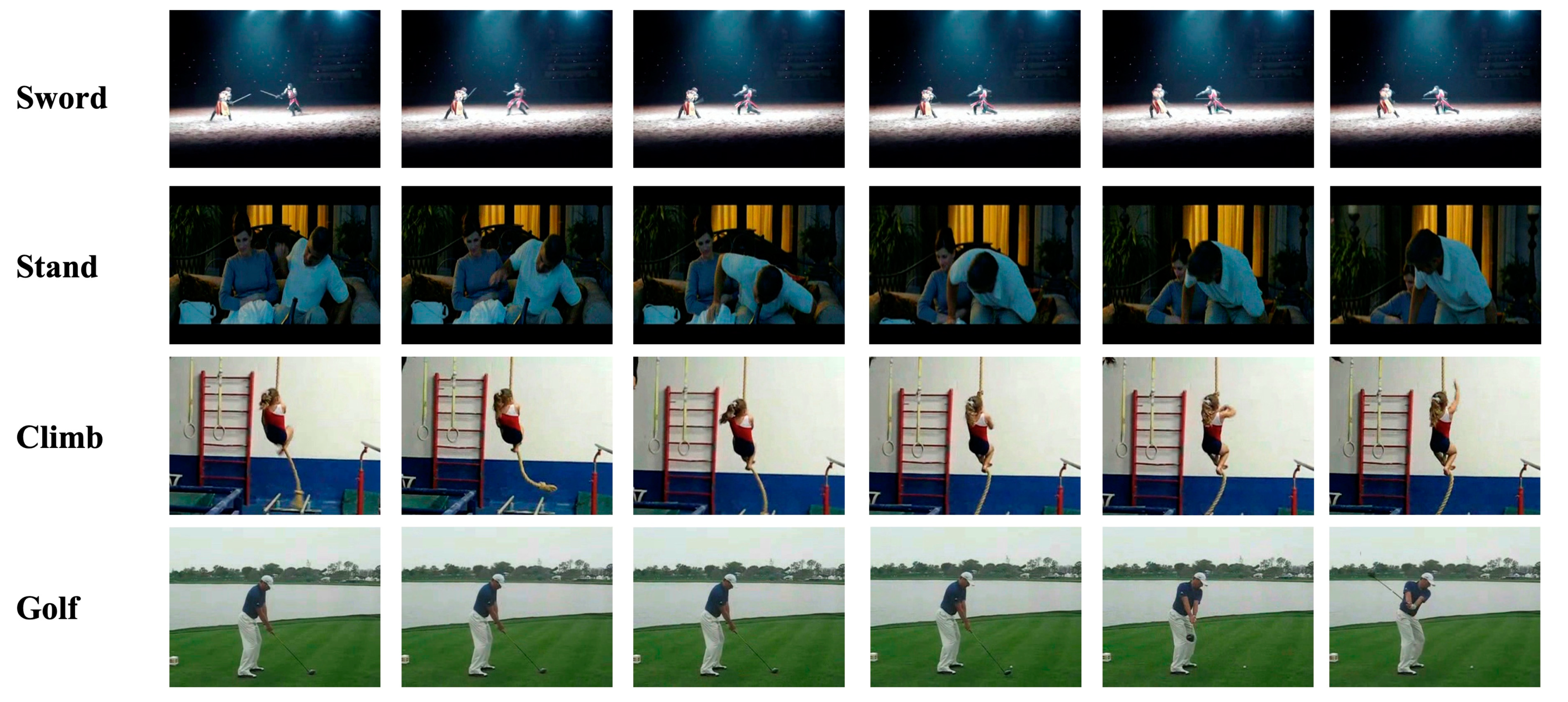{kind=link}
| Model | HMDB-51 | |
|---|---|---|
| Baseline | s-resnet50 | 66.2% |
| Spatial | SAM | 67.4% |
| Frame | FAM | 67.9% |
| Model | HMDB-51 | |
|---|---|---|
| Both | F//S | 68.4% |
| SF | 69.2% | |
| FS | 72.6% |
| Method | Pre-Trained | Params(M) | UCF-101 | HMDB-51 |
|---|---|---|---|---|
| IDT [13] | - | - | 86.4% | 61.7% |
| Two-stream [15] | ImageNet | 25 | 88.% | 59.4% |
| C3D [10] | Kinetics400 | 78 | 85.2% | - |
| TSN [16] | ImageNet | 24.3 | 94% | 68.5% |
| P3D [36] | Kinetics400 + ImageNet | 25.4 | 88.6% | - |
| MiCT-Net [37] | Kinetics400 | 50.2 | 88.9% | 63.8% |
| STA [38] | - | 35.3 | 89.5% | 70.2% |
| STA-TSN [39] | - | 29.8 | 82.1% | 51% |
| DANet [40] | - | 36.26 | 86.7% | 54.3% |
| R(2+1)D [41] | Kinetics400 | 63.6 | 96.8% | 74.5% |
| DPF [42] | - | 48.6 | 79.6% | - |
| MEST [43] | ImageNet | 89.32 | 96.8% | 73.4% |
| FSTFN [44] | - | 39 | 92.4% | 69.43% |
| ActionS-ST-VLAD [45] | - | - | 95.6% | 71.4% |
| TDN [46] | Kinetics400 + ImageNet | 52.3 | 97.4% | 76.3% |
| Multi-Domain [47] | Kinetics400 | 32.02 | 94.82% | 71.57% |
| TCLR [48] | ImageNet | 45 | 82.4% | 52.9% |
| DB-LSTM [49] | - | - | 91.21% | 87.64% |
| HAR-Depth [50] | - | - | 92.97% | 69.74% |
| Ours | Kinetics400 | 30.12 | 95.68% | 72.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, B.; Meng, F.; Tang, H.; Tong, G. Two-Level Attention Module Based on Spurious-3D Residual Networks for Human Action Recognition. Sensors 2023, 23, 1707. https://doi.org/10.3390/s23031707
Chen B, Meng F, Tang H, Tong G. Two-Level Attention Module Based on Spurious-3D Residual Networks for Human Action Recognition. Sensors. 2023; 23(3):1707. https://doi.org/10.3390/s23031707
Chicago/Turabian StyleChen, Bo, Fangzhou Meng, Hongying Tang, and Guanjun Tong. 2023. "Two-Level Attention Module Based on Spurious-3D Residual Networks for Human Action Recognition" Sensors 23, no. 3: 1707. https://doi.org/10.3390/s23031707