

SAR Target Recognition with Limited Training Samples in Open Set Conditions

Abstract
:1. Introduction
- We are the first to explore the problem of SAR OSR with limited training samples, which has practical implications.
- We introduce the GNN to SAR OSR; the proposed method can identify targets from seen and unseen categories well.
- For the target of the unseen category, the proposed method can not only identify but also interpret it by distance measurement. The method has stability for different recognition tasks.
2. Related Work
2.1. Generalized Open Set Recognition
2.2. OSR for SAR Target
2.3. GNN-Based Methods in FSL
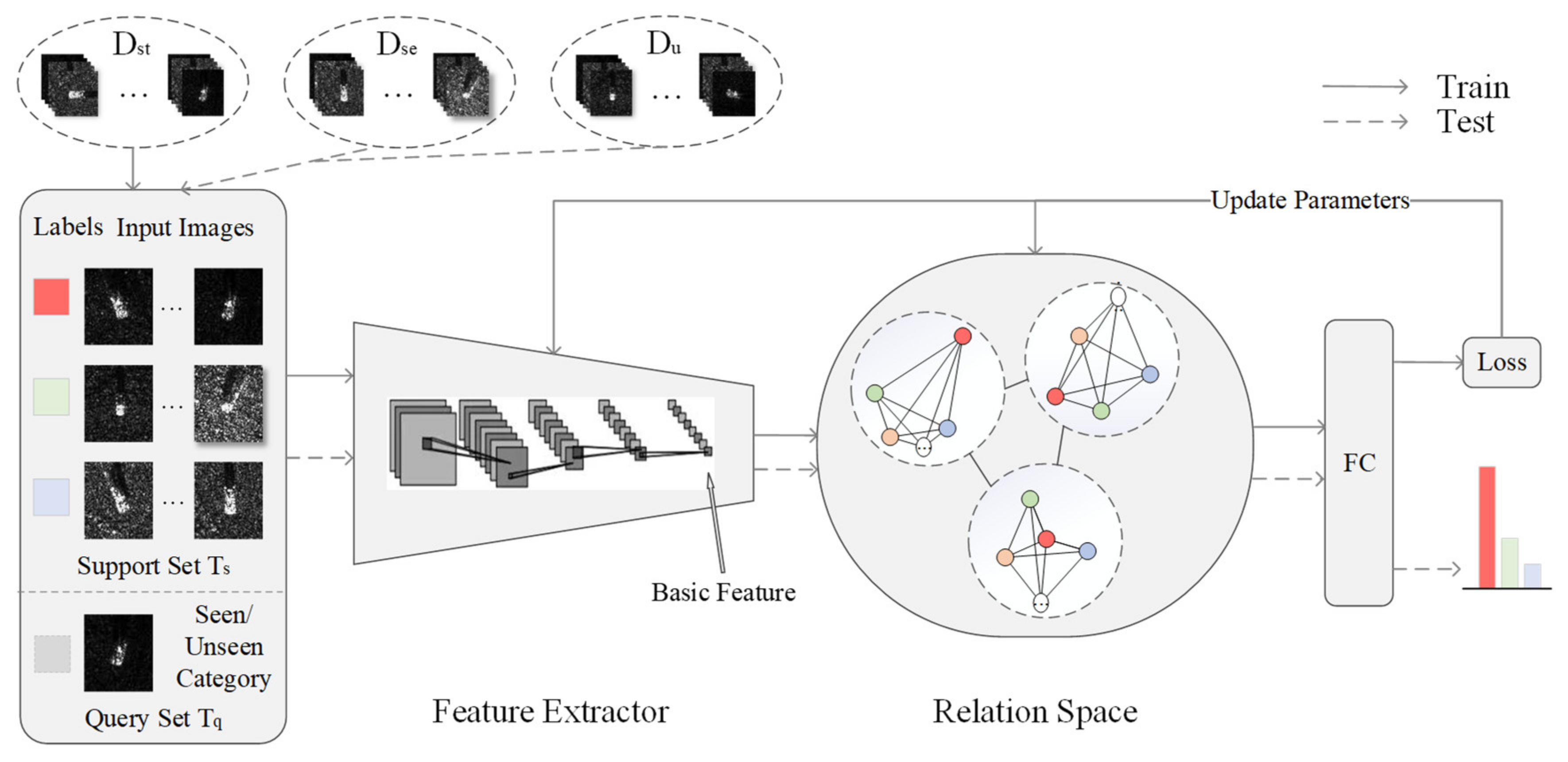
3. Materials and Methods
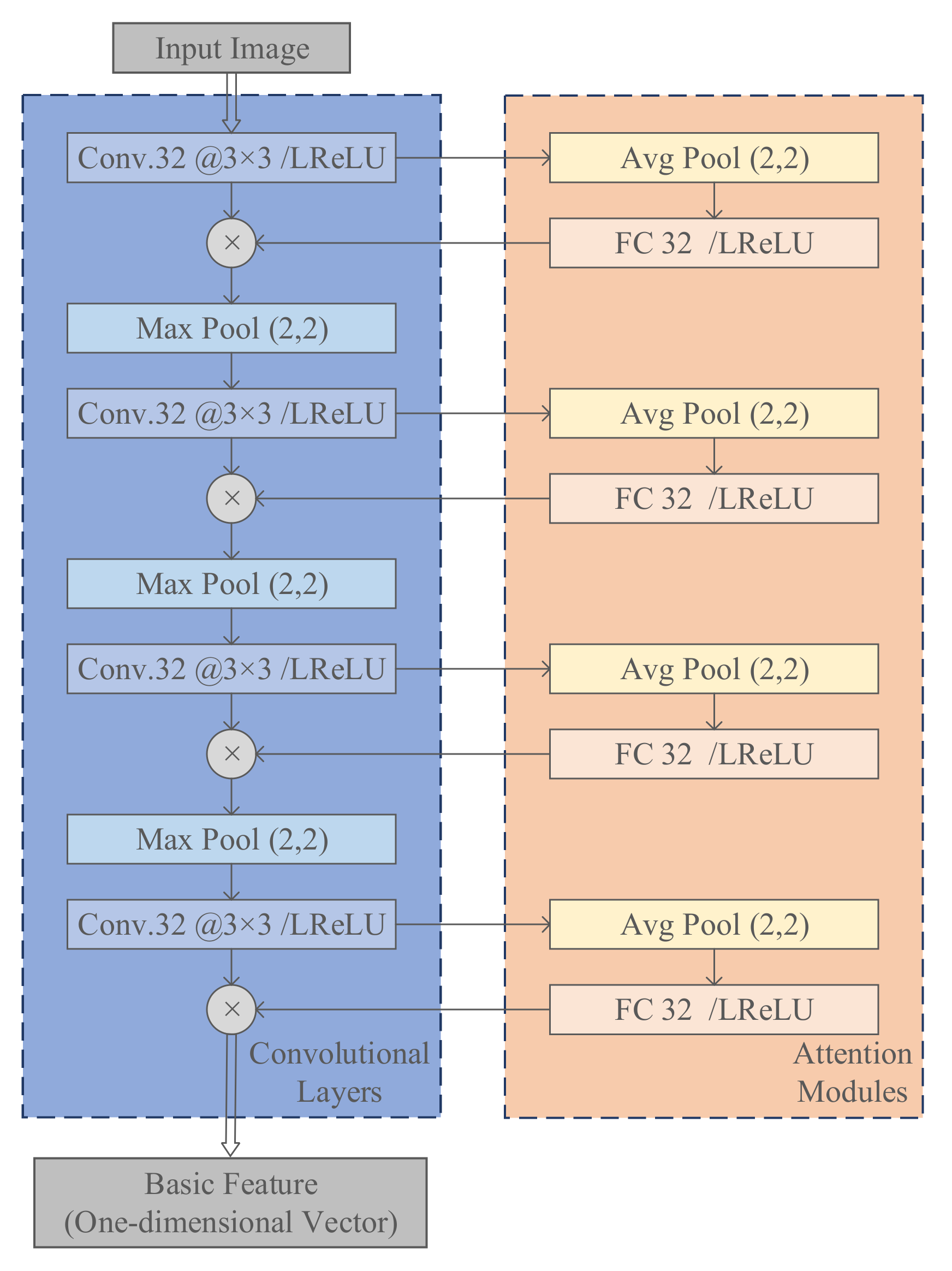
3.1. Feature Extraction
3.2. Relationship Measurement
- Construct the adjacency matrix (adjacency module): The relationship between every two nodes is expressed as:
- where MLP is a multi-layer neural network, for which the input is the Euclidean distance between and . After obtaining all , adjacency matrix can be constructed.
- Change the features (update module and concatenation): The new features are learned by the following equation:
- where represents the update module (contains FC and ReLU layers, the former for tensor deformation and the latter for the nonlinear activation function). is a learned weight parameter. is the matrix of features before the lth iteration, and . Concatenate previous features with learned features as:
3.3. Strategies in Training and Testing Phase
| Algorithm 1: Training phase. |
| Input: Learning rate , the whole model , task distribution , the number of batches , the batch size Output: good parameters |
| 1: Randomly initialize ; 2: for ; ; do 3: Sample tasks from ; 4: for ; do 5: Get initial features ; 6: Get the matrix of initial features ; 7: for ; do 8: ; 9: Get the adjacency matrix ; 10: ; 11: ; 12: end for 13: Get the final adjacency matrix ; 14: Get the categories possibility distribution ; 15: ; 16: end for 17: Backward as ; 18: ; 19: end for |
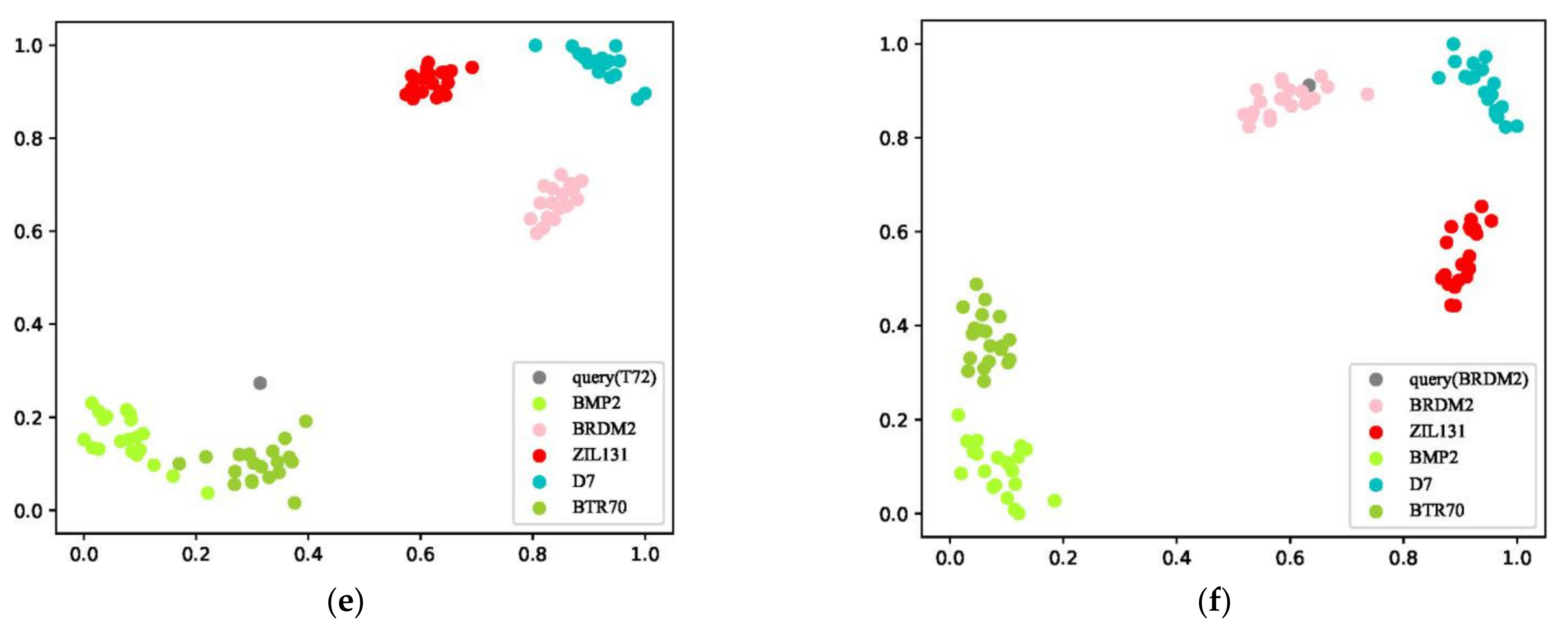
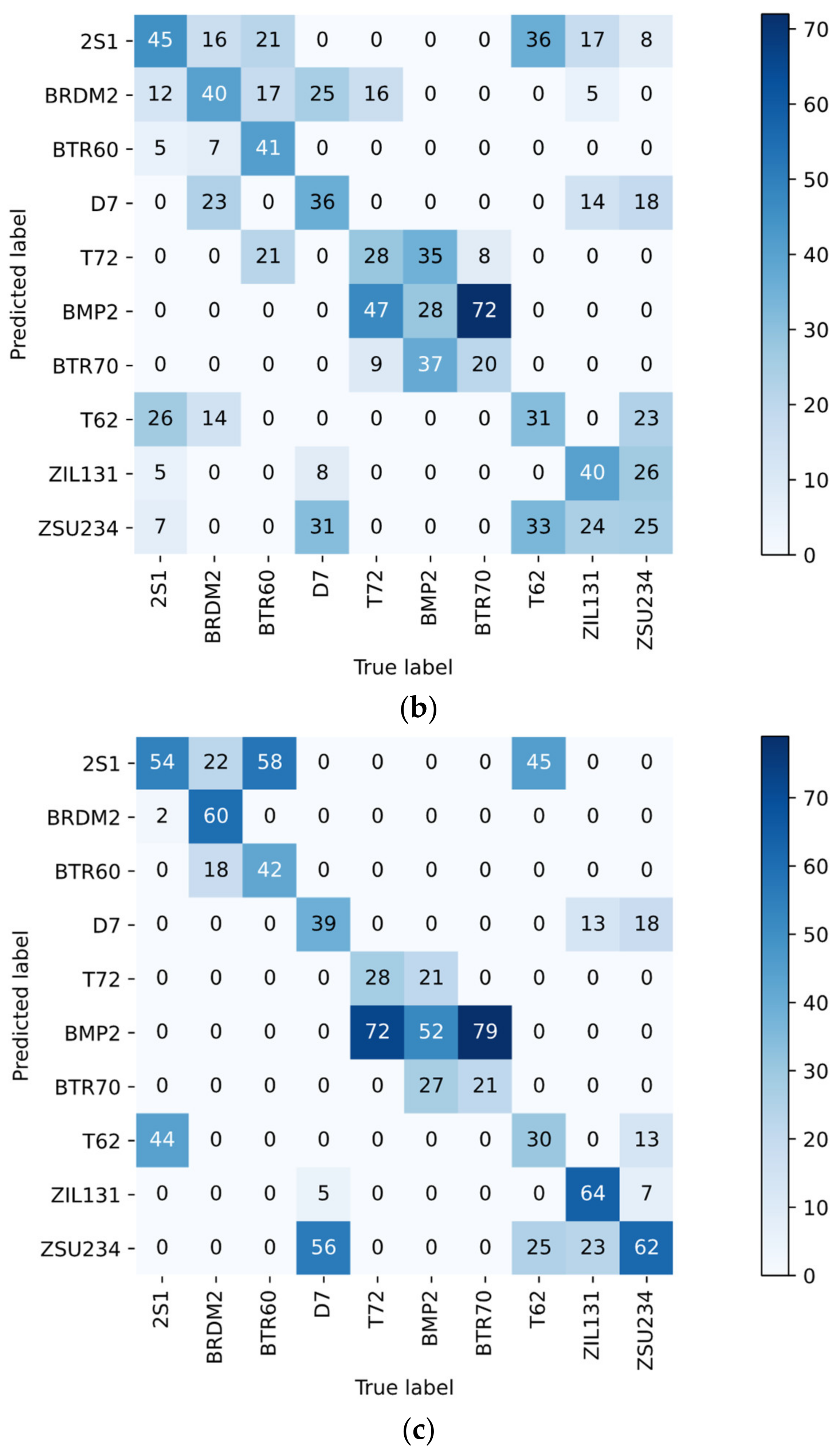
4. Experiment and Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Scheirer, W.J.; de Rezende Rocha, A.; Sapkota, A.; Boult, T.E. Toward Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1757–1772. [Google Scholar] [CrossRef]
- Scherreik, M.D.; Rigling, B.D. Open set recognition for automatic target classification with rejection. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 632–642. [Google Scholar] [CrossRef]
- Giusti, E.; Ghio, S.; Oveis, A.H.; Martorella, M. Proportional Similarity-Based Openmax Classifier for Open Set Recognition in SAR Images. Remote Sens. 2022, 14, 4665. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4080–4090. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef]
- Wen, Z.; Liu, Z.; Zhang, S.; Pan, Q. Rotation Awareness Based Self-Supervised Learning for SAR Target Recognition with Limited Training Samples. IEEE Trans. Image Process. 2021, 30, 7266–7279. [Google Scholar] [CrossRef]
- Che, J.; Wang, L.; Bai, X.; Liu, C.; Zhou, F. Spatial-Temporal Hybrid Feature Extraction Network for Few-Shot Automatic Modulation Classification. IEEE Trans. Veh. Technol. 2022, 71, 13387–13392. [Google Scholar] [CrossRef]
- Gao, F.; Xu, J.; Lang, R.; Wang, J.; Hussain, A.; Zhou, H. A Few-Shot Learning Method for SAR Images Based on Weighted Distance and Feature Fusion. Remote Sens. 2022, 14, 4583. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef]
- Garcia, V.; Bruna, J. Few-shot learning with graph neural networks. arXiv 2017, arXiv:1711.04043. [Google Scholar]
- Zhou, X.; Zhang, Y.; Wei, Q. Few-Shot Fine-Grained Image Classification via GNN. Sensors 2022, 22, 7640. [Google Scholar] [CrossRef] [PubMed]
- Bendale, A.; Boult, T.E. Towards open set deep networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1563–1572. [Google Scholar]
- Bapst, A.B.; Tran, J.; Koch, M.W.; Moya, M.M.; Swahn, R. Open set recognition of aircraft in aerial imagery using synthetic template models. Proc. SPIE 2017, 10202, 1020206. [Google Scholar] [CrossRef]
- Rudd, E.M.; Jain, L.P.; Scheirer, W.J.; Boult, T.E. The extreme value machine. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 762–768. [Google Scholar] [CrossRef]
- Dang, S.; Cao, Z.; Cui, Z.; Pi, Y.; Liu, N. Open Set Incremental Learning for Automatic Target Recognition. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4445–4456. [Google Scholar] [CrossRef]
- Scherreik, M.; Rigling, B. Multi-class open set recognition for SAR imagery. Proc. SPIE 2016, 9844, 150–158. [Google Scholar] [CrossRef]
- Toizumi, T.; Sagi, K.; Senda, Y. Automatic association between SAR and optical images based on zero-shot learning. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 17–20. [Google Scholar]
- Song, Q.; Xu, F. Zero-Shot Learning of SAR Target Feature Space with Deep Generative Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2245–2249. [Google Scholar] [CrossRef]
- Song, Q.; Chen, H.; Xu, F.; Cui, T.J. EM Simulation-Aided Zero-Shot Learning for SAR Automatic Target Recognition. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1092–1096. [Google Scholar] [CrossRef]
- Dang, S.; Cao, Z.; Cui, Z.; Pi, Y. Open Set SAR Target Recognition Using Class Boundary Extracting. In Proceedings of the 6th Asia–Pacific Conference on Synthetic Aperture Radar (APSAR), Xiamen, China, 26–29 November 2019; pp. 1–4. [Google Scholar]
- Wei, Q.-R.; He, H.; Zhao, Y.; Li, J.-A. Learn to Recognize Unknown SAR Targets from Reflection Similarity. IEEE Geosci. Remote Sens. Lett. 2020, 19, 4002205. [Google Scholar] [CrossRef]
- Ma, X.; Ji, K.; Zhang, L.; Feng, S.; Xiong, B.; Kuang, G. An Open Set Recognition Method for SAR Targets Based on Multitask Learning. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4014005. [Google Scholar] [CrossRef]
- Zeng, Z.; Sun, J.; Xu, C.; Wang, H. Unknown SAR Target Identification Method Based on Feature Extraction Network and KLD–RPA Joint Discrimination. Remote Sens. 2021, 13, 2901. [Google Scholar] [CrossRef]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, Y. Transductive propagation network for few-shot learning. arXiv 2018, arXiv:1805.10002. [Google Scholar]
- Kim, J.; Kim, T.; Kim, S.; Yoo, C.D. Edge-labeling graph neural network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11–20. [Google Scholar]
- Gidaris, S.; Komodakis, N. Generating Classification Weights with GNN Denoising Autoencoders for Few-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 21–30. [Google Scholar]
- Yang, L.; Li, L.; Zhang, Z.; Zhou, X.; Zhou, E.; Liu, Y. Dpgn: Distribution propagation graph network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13390–13399. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: New York City, NY, USA, 2017; pp. 1126–1135. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- The Air Force Moving and Stationary Target Recognition Database. Available online: https://www.sdms.afrl.af.mil (accessed on 30 January 2023).
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579C2605. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | √ | |||
| √ | ||||
| Testing | √ | |||
| √ | √ | |||
| Method | Unseen Categories | Seen Categories |
|---|---|---|
| Prototype Network [3] | 16.72% | 16.80% |
| Fea-DA [19] | 32.87% | 78.19% |
| GAN_OSR [18] | 45.43% | 90.31% |
| O_SAR [16] | 60.24% | 42.72% |
| Proposed Method | 52.76% | 95.00% |
| C = 3 | C = 5 | C = 7 | ||
|---|---|---|---|---|
| Unseen Categories | K = 10 | 62.89% | 46.24% | 31.78% |
| K = 20 | 67.00% | 52.76% | 34.12% | |
| Seen Categories | K = 10 | 96.92% | 96.48% | 93.37% |
| K = 20 | 99.06% | 96.00% | 94.27% | |
| Ratio 1 | 3:1 | 1:1 | 1:3 | |
|---|---|---|---|---|
| Unseen Categories | C = 3 | 62.64% | 68.50% | 70.00% |
| C = 5 | 37.30% | 52.76% | 57.22% | |
| All Categories | C = 3 | 91.16% | 92.06% | 91.50% |
| C = 5 | 88.96% | 90.80% | 89.05% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Zhang, Y.; Liu, D.; Wei, Q. SAR Target Recognition with Limited Training Samples in Open Set Conditions. Sensors 2023, 23, 1668. https://doi.org/10.3390/s23031668
Zhou X, Zhang Y, Liu D, Wei Q. SAR Target Recognition with Limited Training Samples in Open Set Conditions. Sensors. 2023; 23(3):1668. https://doi.org/10.3390/s23031668
Chicago/Turabian StyleZhou, Xiangyu, Yifan Zhang, Di Liu, and Qianru Wei. 2023. "SAR Target Recognition with Limited Training Samples in Open Set Conditions" Sensors 23, no. 3: 1668. https://doi.org/10.3390/s23031668