1. Introduction
Cloud computing has led to an ever-growing demand for computing infrastructure, storage, data services, and applications. Examples of famous Cloud Service Providers (CSPs) are AWS, Azure, Google Cloud, and IBM. The National Institute of Standards and Technology (NIST) defines cloud computing as a “model for granting users access to a shared pool of configurable computational resources including networks, servers, storage, applications, and services that can be rapidly provisioned (adapted for new services) with little management or service provider interaction” [
1]. Thus, this technology allows computational resources to be employed significantly more efficiently, resulting in faster services being provided.
Over time, there is a problem that arises with the use of a single cloud: a vendor lock-in. Vendor lock-in is a condition where the users become dependent on a single provider [
2]. For instance, if a company were to host its resources to a provider and that provider were to go bankrupt, the company might lose all of its data on that cloud. One of the solutions to this problem is utilizing a multi-cloud. The multi-cloud can consist of several private and/or public clouds. Correspondingly, it could enhance data availability.
However, this technology introduces new security challenges, such as unreliable Cloud Service Providers (CSPs) [
3,
4]. When users outsource their data to CSPs, they provide CSPs with the right to perform any operation on their data. Thus, the user cannot fully control what happens to their data. Moreover, users may already remove the original data from their local storage because it is already stored in CSPs. A major problem with loss of data possession is that CSPs can hide mistakes they made from users for their benefit [
5,
6]. Besides, CSPs may face internal or external security problems such as accidentally corrupting or eliminating rarely accessed users’ data to reduce storage burden and claims that all data are still stored within the cloud and internal software bugs [
3]. In another case, data integrity is at risk if a bad actor successfully compromises the CSPs’ systems [
3,
4,
5,
6,
7].
Some real cases of data corruption were reported to affect various companies, such as the Amazon S3 breakdown [
8], Gmail mass deletion [
9], and Amazon EC2 services outage [
10,
11]. Furthermore, the Privacy Rights Clearinghouse (PRC) reports more than 535 data breaches to several cloud-based email service providers. For instance, these have affected Sony Online Entertainment, Sony PlayStation Network, and Sony Pictures [
12]. Lastly, 3.3 million patients’ medical data from Sutter Physicians Services were stolen [
13]. These incidents highlight the importance of data integrity auditing protocol in cloud computing.
In light of the aforementioned context, this paper aims to enhance the data integrity verification process in a multi-cloud environment. Nevertheless, maintaining data integrity in a multi-cloud scenario presents several challenges. First, considering that stored data may have a large amount of size if the verifier has to download all the data in advance, it is both impractical and inefficient. Besides, the verifier may not have enough resources. The threat to users’ privacy is more significant and there is no assurance of unbiased data verification. Therefore, various kinds of research are conducted to develop auditing protocols in the cloud system. Particularly, research on verifying data integrity in cloud servers without requiring access to whole data is receiving much attention.
A pioneer in addressing this issue is Ateniese et al. [
14]. The authors proposed an auditing protocol called Provable Data Possession (PDP). They introduce the concept of probabilistically checking the data integrity stored by users in the cloud server. Through this technique, users may be able to efficiently check the data integrity without saving the original data locally. The authors [
15] proposed a scheme called Proof of Retrievability (PoR). They use spot-checking and error-correcting codes to guarantee data possession and retrievability on remote storage systems. Afterward, other data integrity verification protocols have been proposed in [
3], but those protocols only focus on a single cloud environment.
The second challenge is unreliable verifiers. Some work explained in [
4] includes a data integrity verification scheme in a multi-cloud environment. However, the scheme is inefficient because the verifier needs to check the data from each CSP separately [
4,
6]. Some authors proposed batch data integrity verification in a multi-cloud environment presented in [
16]. Unfortunately, these approaches use a third-party auditor (TPA) and assume they are reliable, while, in reality, TPA may not be honest and it is difficult to find TPA trusted by multiple CSPs [
3,
6]. The development of blockchain technology is a promising solution for the above challenges. The decentralized and transparent nature of blockchain has become the main interest of the academic community to propose data integrity verification schemes. For example, Refs. [
5,
6,
7] uses blockchain smart contracts to replace centralized TPA as a trusted verifier.
The third challenge is that most of the algorithms employed to audit data use a sampling method [
3,
4,
5,
6,
7,
14,
17]. This means they randomly challenge some data blocks to provide probabilistic data possession proof. The probabilistic scheme relies on the spot-checking approach in which only a random fraction of the file is checked [
4]. In a multi-cloud environment, users will store huge amounts of data. Thus, this paper wants to increase the sampling without increasing the cost by proposing a distributed data integrity verification scheme.
Motivated by the challenges mentioned above, to assure data integrity in a multi-cloud environment, this paper proposes a distributed data integrity verification in a multi-cloud environment by utilizing blockchain technology that also provides a batch verification process. This scheme will spread the verification task among several verifiers, thereby reducing computation and communication costs.
This paper’s main contributions are summarized as follows:
This paper designs and proposes a blockchain-based distributed data integrity verification in the multi-cloud environment that increases the verification sampling rate without increasing the computation and communication costs by enabling data verification with multi-verifiers rather than single verifiers. By doing so, the burden is distributed to several verifiers.
This scheme supports batch verification to increase the efficiency of proof validation and lower the cost for the cloud organizer (CO).
This paper presents security and performance analyses of distributed data integrity verification protocols under the multi-verifier case. The security analysis consists of a proof of correctness of the equations and unforgeability by malicious CSPs, verifiers, and COs. The performance analysis consists of evaluating computation and communication costs, experiment results, gas usage estimation, and a comparative analysis of existing works.
The rest of the paper is organized as follows. This paper presents preliminaries in
Section 3. Next, the property requirements for the data verification protocol are presented in
Section 4. Further, the related work is provided in
Section 2. This paper’s proposed scheme is presented in
Section 5. This paper also presents a security analysis and performance evaluation in
Section 6 and
Section 7, respectively. Finally, the conclusion of the paper is presented in
Section 8.
2. Related Works
The authors in [
7] proposed a blockchain-based cloud data integrity verification using a lattice signature, cuckoo filter, and Merkle Hash Tree (MHT). The data are divided into blocks and a lattice signature is used to compute the tag for each data block. At the same time, the cuckoo filter is used for a lookup table in the verification process. However, in this paper, the signature of each data block is stored in the CSP. When users challenge CSP, CSP may only send previously stored signatures rather than recompute the proof from the file itself. So, the signatures will not represent the data integrity itself. Furthermore, this scheme did not support batch verification and concentrated on a single cloud environment. The authors of [
5] proposed a blockchain-based cloud data integrity verification using the ZSS signature and T-Merkle tree. ZSS signature is used to compute the tag for each data block. They employ bilinear pairings in the verification process to support blockless verification and the T-Merkle tree is used as a data structure. However, this work did not support distributed verification by multi-verifiers and focused only on a single cloud environment.
The authors of [
6] proposed a blockchain-based data integrity verification for multi-cloud storage. They use a homomorphic verifiable tag (HVT) to generate a tag for each data block. The verification process is performed through a homomorphism equation to support blockless verification. However, this work did not support distributed verification using multi-verifiers. The authors of [
17] proposed a data integrity verification scheme for cloud storage using algebraic signatures. The verifier in this paper is a third-party auditor (TPA), which is assumed to be faithful and reliable. However, in reality, there is no guarantee for that claim. Therefore, this paper did not support a trusted verifier and only focused on a single cloud environment.
The authors of [
18] proposed a blockchain-based public auditing scheme in multi-replica and multi-cloud environments. This work is based on a certificateless cryptosystem that aims to avoid the certificate management problem in PKI and key escrow problems in an identity-based cryptosystem. Unfortunately, this paper did not support batch verification and distributed verification. The authors of [
19] proposed a blockchain-based public auditing scheme for cloud storage without trusted auditors. Their work replaced trusted third-party auditors (TPAs) with blockchain to resist malicious auditors. They also used certificateless public auditing to avoid key escrow problems. Unfortunately, this work did not support distributed verification and was only concentrated on a single cloud environment.
The authors of [
20] used a BLS signature in their data integrity auditing protocol. They claimed that their scheme could efficiently reduce metadata computation costs for clients during the system setup phase in auditing protocol. However, this work did not support batch and distributed verification. The authors of [
21] used an attribute-based signature in their data integrity auditing protocol. In this scheme, the users’ private keys are generated through arbitrary attributes chosen by users. By doing so, this signature enables data owners to specify the scope of auditors to avoid a single point of failure in traditional protocols, which have a single TPA. However, this work did not support batch verification and only focused on a single cloud environment.
The authors of [
22] proposed a blockchain-based data integrity verification for large-scale IoT data. Instead of relying on trusted TPAs, this work used blockchain in the verification process. They also use HVT to generate tags for each data block. Unfortunately, this scheme did not support batch and distributed verification by multi-verifiers. The authors of [
23] proposed a distributed machine learning-oriented data integrity verification scheme in a cloud computing environment. They adopted PDP as a sampling auditing algorithm in their scheme and generated a random number called a blinding factor and applied a discrete logarithm problem (DLP) to construct a proof and ensure privacy protection in the TPA verification process. However, this scheme did not support batch verification and distributed verification. This work also focused only on a single cloud environment. Furthermore, the verification uses a TPA that is assumed to be trusted. In reality, there is no guarantee for that claim.
From the above review of existing works, the challenge that is still ongoing is to accomplish batch verification and provide a distributed data verification process using multi-verifiers. Therefore, this paper proposes a blockchain-based distributed data integrity verification in a multi-cloud environment that provides a batch verification process. This paper aims to increase the sampling rate without increasing the costs by enabling the verification process to be performed by multi-verifiers rather than only a single verifier. Furthermore, batch verification will increase efficiency and decrease costs during the verification process for the cloud organizer in a multi-cloud environment.
5. Proposed Scheme
This section presents the distributed data integrity verification scheme in the multi-cloud environment that supports the aforementioned requirements in
Section 4. This proposed protocol has four types of actors: user, CO, CSP, and verifier. The user is the one that stores the data in multiple CSPs and wants to verify the integrity of the stored data. Since it is a multi-cloud environment, a CO controls the interaction between users and CSPs [
6]. The CO will send the user’s data to each CSP. They will also assign the verifiers when the user requests data integrity verification. Each verifier will send a challenge request to the corresponding CSP related to the data that need to be verified. Later, the CSP will reply by sending proof of so-called
to the corresponding verifier. The verifier will verify each proof with a bilinear pairing equation by generating a proof of the so-called
as the pair of proof
. In the final step of the verification process, the CO will aggregate proofs from the verifiers and perform batch verification.
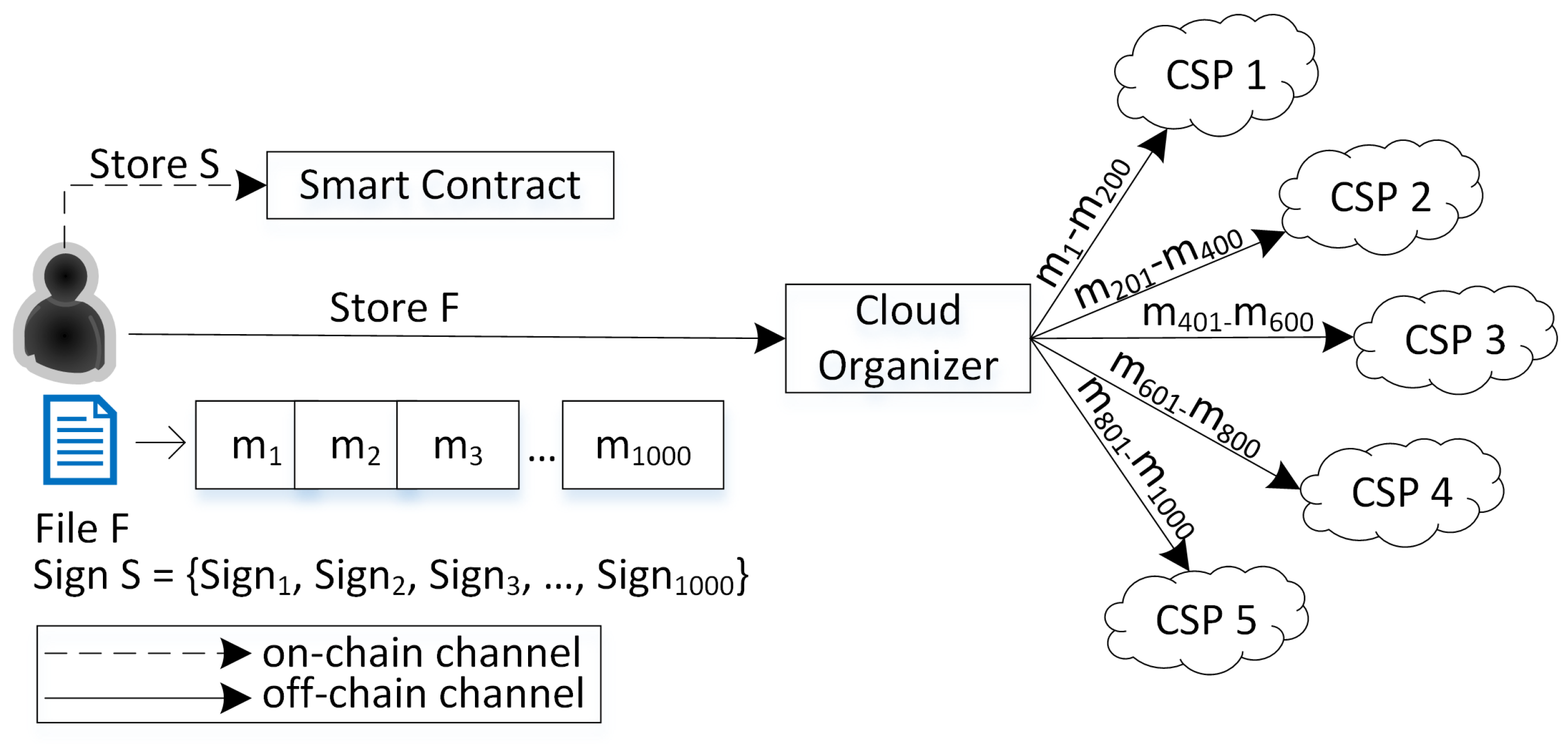
This paper presents a numerical example of the proposed scheme through
Figure 1.
The user splits the file
F into 1000 blocks in the example. So, the user will generate 1000 ZSS signatures (
S). This paper chose the ZSS signature because it required less pairing operation than other short signatures, such as the BLS signature [
24]. Furthermore, ZSS does not need a special hash function, i.e., MapToPoint, when used in BLS. So, we can use a general hash function such as SHA family or MD5 [
24]. After that, the user sends file
F to CO and signs
S to the smart contract. Then, CO distributes 1000 blocks into several CSPs. Assuming that the CO spreads to five CSPs, each CSP will store 200 data blocks. The CO also stores the list of block ranges stored in each CSP in its local database. Then, in the verification phase, if the CO assigns four verifiers, each verifier can verify 250 data blocks. When assigning the verifier, the CO will also send the information of the CSPs that stored the related data. In this case, because each CSP only stores 200 data blocks earlier, each verifier needs to send challenges to two CSPs to obtain the rest of the data blocks. For example, verifier-1 will send challenges to CSP 1 for blocks 1–200 and CSP 2 for blocks 201–250. Verifier-2 will send challenges to CSP 2 for blocks 251–400 and CSP 3 for blocks 401–500. This pattern continues until the fourth verifier. Therefore, each verifier will have two proofs
. Subsequently, each verifier will generate proof
as a pair for each proof
. So, in this example, there will be eight pairs of proofs
and
. In the end, CO will aggregate these eight pairs to perform a batch verification and send the result to the user.
This paper provides a list of notations used in the proposed scheme in Nomenclature and explain the details of the proposed protocol as follows.
Setup phase.
- -
ParamGen. Let be a Gap Diffie–Hellman (GDH) group and be multiplicative cyclic groups with prime order q; P is the generator of a group . The mapping is a bilinear map with some properties. H is a general hash function such as the SHA family or MD5. The system parameters are .
- -
KeyGen. Randomly selects as a secret key and computes as a public key.
- -
User generates ZSS signature for each data block
as shown in Equation (
2).
Registration Phase.
In the beginning, each user, CO, and verifier need to register to the smart contract once by sending their blockchain address as shown in
Figure 2. After that, they will receive an ID so-called
and
, respectively, that will be used in the storing and verification phases. These IDs are assigned by smart contract internal generation rules. Each ID starts with a different first digit to determine the category. The first digit for
is 1,
is 2, and
is 3, while the rest digit shows the serial number of the ID.
Figure 2.
Registration phase.
Figure 2.
Registration phase.
Storing Phase.
The details of the data storing phase are shown in
Figure 3 as follows.
In this phase, the user divides the file F into n blocks of m. For the general case, let each block size be 4 KB. So, the file .
Then, he will generate a signature for each data block. So, the set of signatures is .
Subsequently, the user stores the signatures in the smart contract by sending the and S values.
Then, the smart contract will assign an value, a unique identity number for each file F, to the user. is assigned by the smart contract internal generation rule that begins with 4 as the first digit. The rest of the digits show the serial number of the .
Next, the user sends file F and also the signature of F that is signed with the private key of the user () to the CO.
Upon receiving F from the user, CO verifies the signature first using the user’s public key. If valid, CO continues the process; otherwise, it rejects it. The signature verification process is important to prove that the sender is the real user and to prevent the adversary from impersonating the real sender.
The next process involves CO distributing it to several CSPs with ranges showing the beginning of the data blocks, while shows the last data blocks that will send to the CSP. The CO also sends along the digital signature of the message that is signed with the CO’s private key (). Subsequently, the CO stores the list of data blocks and the corresponding CSPs in the local database.
The CSP will verify the file from the CO using the CO’s public key. If valid, store the file; otherwise, reject it.
Figure 3.
Data storing phase.
Figure 3.
Data storing phase.
Verification Phase.
The details of the data verification phase are shown in
Figure 4 as follows.
The user sends a data integrity verification (DIV) request by transmitting , , and the signature of the corresponding message that is signed with the user’s private key () as parameters to the CO.
(a.) Then, CO verifies the signature of the message received from the user using the user’s public key. (b.) If valid, it will obtain the number of blocks of the corresponding ; otherwise, the CO rejects it. The signature verification process is important to prove that the sender is a real user and also prevents the adversary from impersonating the real sender.
After that, the CO publishes a DIV task in the smart contract by sending , and as parameters.
The smart contract processes the request and assigns a to be returned to the CO, which is a unique number for each task.
Since it is a broadcast message, all the nodes that join the blockchain network will receive this notification. Several verifiers will then apply to perform the verification task for the CO by sending the corresponding , and the signature of the message that is signed by the verifier’s private key ().
(a.) Subsequently, CO verifies the message from the verifier with the verifier’s public key. If valid, continue; otherwise, reject it. (b.) Afterward, CO sets the verifiers that will perform the DIV task by sending and Q as parameters to the smart contract, where a is the number of verifiers and Q is the set of assigned to perform a verification task.
The CO then sends and the signature of the that is signed with CO’s private key () to each selected verifier, where k is an index of the proof that will be generated by the corresponding CSP, I is the set of challenged data blocks so , and c is the total number of challenged data blocks for each CSP. contains the corresponding CSP information. So, in the given scenario, the CO will send two to verifier-1, first with , I with blocks, and of CSP 1. Second, , I with blocks and of CSP 2.
(a.) After receiving
from the CO, the verifier will verify the signature of the received message using the CO’s public key. If valid, continue; otherwise, reject it. (b.) Then, each verifier will send challenge
and the signature of the message that is signed with verifier’s private key (
) to the corresponding CSPs that have data blocks needed to be verified, where
is a random number in
and
i is an index of randomly selected data blocks to be verified in the set of
I.
Figure 4.
Data verification phase.
Figure 4.
Data verification phase.
(a.) Upon receiving
from the verifier, the CSP verifies the received message’s signature first using the verifier’s public key. If valid, continue; otherwise, reject it. (b.) Afterward, the CSP will compute the proof
as shown in Equation (
3). In the above scenario, for verifier-1, CSP 1 generates
blocks 1–200 and CSP 2 generates
blocks 201–250, respectively.
Later, the CSP sends proof to the corresponding verifier along with the signature of the message that is signed with the CSP’s private key () to the verifier. So, based on the given scenario, verifier-1 will receive from CSP 1 and from CSP 2.
(a.) The verifier then verifies the received message’s signature using the CSP’s public key. If valid, continue; otherwise, reject it. (b.) Next, the verifier requests the ZSS signature S value to the smart contract according to the ranges of data blocks to be verified. So, based on the scenario above, verifier-1 will request S for blocks 1–250.
In response to the verifier, the smart contract sends the corresponding S value.
Subsequently, the verifier computes proof
. The
is the pair of the proof
. So, in Equation (
4), the value of a set
I is the same as
I in Equation (
3) for the same
k. From the given scenario above, verifier-1 generates
blocks 1–200 and
blocks 201–250.
After that, the verifier checks the validity of each pair of proofs
and
as shown in Equation (
5). So, from the example above, verifier-1 will perform the bilinear pairing for proofs
,
and
,
, respectively. If the equation holds, the data blocks in the corresponding CSP are safe; otherwise, the verifier will know which CSP failed to prove the integrity of the user’s data.
Consequently, the verifier reports the results to the smart contract.
Then, each verifier sends proofs , and the signature of the message signed with the corresponding verifier’s private key to the CO.
(a.) In this step, the CO will verify the received message’s signature using the verifier’s public key. If valid, continue; otherwise, reject it. (b.) Next, in this step, the CO receives several proofs
and
from multiple verifiers and will start the batch verification. In the above example, there are four verifiers. The batch verification in this work supports aggregating proofs of file
F from multi-verifiers. In the process, the CO will check if Equation (
6) holds, where
K is a set of proofs =
and
t is the total number of proofs that the CO received from verifiers. To calculate
t, first, let
the number of blocks stored in the CSP and
number of verifiers. If
equals 0, then
. Otherwise, check if
, then
; otherwise,
. In the given scenario, the CO receives eight pairs of proofs
and
.
If it holds, update the verification task’s status in the smart contract to success; otherwise, it failed.
The CO reports the DIV result to the corresponding user and the message’s signature that is signed with CO’s private key ().
After receiving the result from the CO, the user will verify the signature using the CO’s public key. If valid, the user is assured that the message is indeed from the CO; otherwise, it rejects it.
7. Performance Evaluation
This section presents the proposed protocol’s implementation results and evaluates the performance by calculating the estimation of gas consumption, computation, and communication costs.
The prototype was implemented using Docker installed on Windows 10 with Intel Core i5-7200U @2.50 GHz CPU and 4 GB memory. There are four main actors, user, CO, CSP, and verifier, with the specifications shown in
Table 1. The blockchain network was based on Ganache. Ganache is a rapid Ethereum and Corda distributed application development [
25]. The smart contract is written in the Solidity programming language. The ZSS signature generation code was implemented based on the Pairing-Based Cryptography (PBC) Go Wrapper package, while for the digital signature, this paper uses the crypto-ecdsa package with the Go language version 1.19.3 [
26,
27]. The parameters of PBC that this paper used are type A param, with group order 160 bits and the base field order 512 bits.
7.1. Computation Cost
The computation cost for the proposed protocol is shown in
Table 2. The result for the user is
with the front bracket showing the cost for generating ZSS signatures for
n data blocks. The cost of the CSP is
with the bracket showing the cost for generating proof
, while the cost of the verifier is
with the bracket showing the cost for generating proof
and bilinear pairing of proofs
in the verification process. The last is the cost of CO,
with the bracket showing the cost for the batch verification process.
Furthermore, a variable
c shows the number of data blocks that need to be verified by each verifier. This variable depends on the total number of data blocks (
n) and the total number of verifiers (
a). So, based on the given scenario in
Section 5, if
n is 1000 blocks and
a is 1,
c is 1000. It means one verifier needs to verify all 1000 data blocks. As a result, the computation cost will be higher since its calculation will grow linearly as the number of
c increases. In the case of 1 user with multi-verifiers, if
a is 4, so each verifier must verify 250 data blocks. As a result, the computation cost will be lower because the burden is distributed to four verifiers. The proposed work also supports batch verification for the CO. At the end of the verification process, the CO will receive several proofs
and
from multi-verifiers. Instead of verifying one by one, the CO will aggregate those proofs and only perform bilinear pairing once.
This paper also presents the average computation time results for each operation used in the proposed scheme in
Table 3. The results show that multiplication and bilinear pairing operations consumed the highest average time, 1.464 ms and 1.125 ms, respectively. In comparison, addition and hash operations have the lowest computation time, 0.0001 and 0.0007 ms, respectively.
7.2. Communication Cost
This paper presents the communication cost for each actor as shown in
Table 4. Those costs are calculated from the size of the data transferred (bytes) between the actors in the proposed protocol. The communication cost for the user is calculated from the storing data in the CSP that costs
and sends a verification request to the CO, which costs 134 bytes. The size of the digital signature in the proposed scheme is 128 bytes generated by the crypto-ecdsa Go package. So, based on the given scenario in
Section 5 with
, the total communication cost of the user is 4,000,262 bytes or around 4 MB. The user seems to have a high communication cost in the storing phase depending on the data blocks the user will store, but it will only be performed once. For the CSP, the communication cost is for sending the generated proof
along with the digital signature to the verifier, which costs 218 bytes.
The verifier’s communication costs are calculated from sending challenges to the CSP and sending proofs to the CO, which are and 308 bytes, respectively. So, from the given scenario, if using one verifier, , the total cost becomes 47,436 bytes, while, in the case of multiple verifiers, if , the total cost reduces to 12,186 bytes. In the library that this paper used, the PBC Go wrapper support function called compressedBytes() was used to convert a value to the compact bytes size. Therefore, the size of the generated proof or is 90 bytes. Lastly, the communication costs for the CO are accumulated from sending task to each verifier and sending verification result to the user, which are and 133 bytes, respectively. So, from the presented scenario, the total communication costs for the CO if is 1461 bytes, and 2061 bytes if . The cost is slightly higher for the CO in the case of multi-verifiers. However, the trade-off is that it can reduce the costs for each verifier.
7.3. Experiment Results
In the experiments, each data block size is 4 KB. The minimum number of data blocks is defined as 50 and the maximum is 2000 data blocks. So, the minimum file size is 200 KB and the maximum is 8000 KB. In
Figure 5, this paper presents the result of the generation time comparison of the ZSS signature by the user and proof
by the CSP. It shows that the user and CSP generation time increases linearly with the CSPs with higher time consumption. The CSP reaches time 5.3 s for generating proof
of 2000 data blocks and the user 2.6 s for generating the ZSS signature of the same amount of data blocks. The CSP needs a longer time because, as shown in Equation (
3), it needs three multiplication operations. Different from the user that only needs one multiplication and one inverse operation in Equation (
2). Based on the average computation time for each operation in
Table 3, the multiplication operation consumed the highest computation time compared to the other operations, while the hash, inverse, and addition operations are negligible. So, the proposed scheme offers the users lower computation costs because they generally have limited resources compared to the CSP.
Next, this paper compares the file size of the total data blocks and generated ZSS signature. The result shows that even though the size of the data blocks increases linearly, the size of the ZSS signature is almost constant. For example, the 50 data block size is 200 KB and the ZSS signature size is 4.5 KB with the same number of blocks, while the 2000 data block size is 8000 KB and the ZSS signature size is only 182 KB. The generated ZSS signature size is smaller than the original data block because the ZSS signature processes the hash of the data rather than the original data. Therefore, the high reduction in size means it can reduce the overhead storage and communication costs on the user’s side, so they do not need to store other big-size files.
This paper also presented a simulation of multi-verifiers in the data verification process shown in
Figure 6. This paper tested the performance by comparing the required verification time between one verifier and multi-verifiers. It is worth noting that the verification time presented omits the transmission time needed between verifiers, CSPs, and CO because the time will vary and be influenced by many factors. The results show that, in the case of one verifier, the time increases linearly alongside the increasing number of data blocks. It needs 7.3 s to verify 2000 data blocks. However, the case of multi-verifiers (5, 10, 15, and 20 verifiers) significantly reduces the time consumption with results of 1.5 s, 0.7 s, 0.5 s, and 0.4 s, respectively, for the same amount of data blocks.
Based on the results of the experiments, we can argue that the proposed protocol has the advantage of requiring less storage space, computation, and communication costs from the user, which also eliminates the need for them to keep additional large files. Furthermore, this paper proves that the proposed scheme can complete verification tasks faster by spreading the workload among multiple verifiers. Hence, reduce the costs required for the verifiers.
7.4. Gas Usage Estimation Cost
Table 5 shows the proposed protocol’s estimation of gas usage and fee in USD. Every user, verifier, and CO needs to register themselves for the first time to the smart contract; it costs 50,733 gas for each function number 1–3. Then, every time the users add their data to be verified, it costs 107,399 gas. In order to perform a verification task, the CO needs to run the AddTask function, which costs 171,257 gas. When the CO wants to assign verifiers for a verification task, he calls AssignVerifier at once to assign
a number of verifiers, which costs 179,948 gas. The last function, SetTaskState, is able to be run by the CO or verifier to update the verification task status, which costs 32,141 gas.
According to the aforementioned analysis, we can conclude that, regardless of the number of verifiers, whether one verifier or multi-verifiers, the gas usage that the CO needed to perform the verification task is the same. However, the merit point of the proposed distributed data integrity verification protocol is highlighted in the computation and communication costs. In the case of one user − one verifier, the computation and communication costs will be higher because one verifier is required to verify all the data blocks. In contrast, the proposed protocol offers low computation and communication costs because, by utilizing more verifiers, the burden will be distributed evenly for each verifier. Furthermore, using batch verification, this paper also reduces costs for the CO.
7.5. Comparative Analysis
This section presents a comparative analysis between the proposed protocol and other related works, as shown in
Table 6 below. The comparison points are based on the property requirements explained in
Section 4. However, this paper omits the first three requirements, public verifiability, blockless verification, and privacy-preserving, because the proposed scheme and other related works already fulfilled those points. So, the main comparison points are batch verification, multi-cloud, reliable CO, reliable verifiers, blockchain-based, and distributed verification.
Batch verification. The proposed protocols support batch verification as shown in Equation (
6) where the CO will validate proofs from the verifiers. Compared to other work, two out of ten protocols also support batch verification, which is [
6,
19]. However, eight other protocols only verify the proof from CSPs one by one for each data block.
Multi-cloud environment and reliable CO. The proposed protocols [
6,
18] provide data verification in a multi-cloud environment. In addition, in a multi-cloud environment, a CO is assigned to distribute the files from the user to several CSPs. The proposed protocols and the other two supported reliable CO by utilizing blockchain technology. Unfortunately, eight other protocols did not. They mostly focused on verification in a single cloud environment and no CO was needed.
Reliable verifiers and blockchain-based. The proposed scheme and six out of ten other works support reliable verifiers by employing blockchain technology. This paper can design a decentralized verification process through blockchain to provide transparency between users and CSPs. It removes the intermediary and enables peer-to-peer interactions between nodes, therefore enhancing trust. The other four works [
17,
20,
21,
23] did not provide these two points because they rely on the credibility of the third-party auditor (TPA), which is not ideal in real case circumstances.
Distributed verification. The proposed protocol is the only one that can accomplish it. The other ten protocols were unable to. This paper fulfills it by enabling multi-verifiers to participate in a verification task, whereas the other protocols were interested in data verification by a single verifier. This paper also has performed the verification simulation using 5, 10, 15, and 20 verifiers and demonstrated that the proposed scheme could complete the verification tasks faster with less computation and communication costs than the single verifier.
Based on these comparative studies, this paper concludes that most related works have supported reliable verifiers by employing blockchain technology. However, only a few works provide batch verification and support data verification in a multi-cloud environment. Lastly, the proposed scheme fulfills all the comparison points with the distributed verification, which becomes the most prominent benefit of the proposed protocol and is not owned by any other related work. As presented early in this section, the advantage of the proposed distributed verification is that this paper can reduce the computation and communication costs because the workload is evenly distributed among multiple verifiers.
7.6. Case Study
In the previous sections, this paper already outlined the proposed scheme and performance evaluations. This part provides a case study of the applications of the proposed distributed data integrity protocol.
Distributed machine learning: In distributed machine learning, several nodes are used to perform the training in parallel. Thus, it can increase scalability and optimize time. The training data are stored in different storage locations with the nodes to reduce the burden [
23]. So, external or internal threats exist that can endanger the integrity of training data and lead to the wrong training results. Therefore, it is crucial to protect the training data’s integrity. The proposed scheme in this paper is suitable for overcoming this challenge. The proposed scheme can increase efficiency and reduce the costs needed to perform the data integrity verification scheme by enabling multi-verifiers and batch verification. Furthermore, this scheme can also resist malicious CSPs, verifiers, and COs that want to manipulate the verification results.
Big data: This proposed scheme is also a suitable solution in the case of a big data environment besides machine learning, such as medical, healthcare, and IoT data. In the medical or healthcare system, there will be vast quantities of patient information that needs to be stored over cloud computing systems [
2], while, in the IoT environment, there is already growing data collection from various devices such as smart devices, household electronics, or vehicle monitoring equipment [
22]. These kinds of data will also be stored in a multi-cloud environment, so the data integrity will need to be checked to ensure their trustworthiness. Therefore, with the property requirements and analyses presented in previous sections, this proposed scheme is relevant to solve these challenges.
8. Conclusions
This paper proposes a distributed data integrity verification in multi-cloud environments to increase the sampling rate in the probabilistic verification process without increasing the costs for the verifier. This paper presented a security analysis that proves the equation’s correctness and the proposed protocol’s unforgeability. Furthermore, this paper conducted several experiments to evaluate the performance of the proposed protocol. It shows that the distributed verification tasks with multi-verifiers can reduce time consumption compared to the single verifier. The numerical analysis also shows that the computation and communication costs are reduced in the case of multi-verifiers because the burden is distributed to multi-verifiers rather than only one verifier. Furthermore, by using batch verification, the costs for the CO are also lowered. The estimation of gas usage in smart contracts shows that the gas used between one verifier and multi-verifiers is the same. Lastly, the comparative studies also show that the proposed protocol can fulfill the important property requirements for data verification.
However, the limitation of the proposed scheme is that it does not support data dynamic property, which is also an important point when users store data in the cloud server. In cloud computing, users usually not only store data in the CSP. They may modify the data by updating, inserting, or deleting them. Therefore, this paper considers providing data dynamic property to the proposed data integrity verification scheme as part of future work.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}