1. Introduction
In the process industry, real-time estimations of key quality parameters are of great importance for process monitoring, control, and optimization. However, due to technical and economic limitations, these key parameters related to product quality and process status cannot be measured online. Instead, soft sensor technology, as an important indirect measurement tool, has been widely used in the process industry. The core of soft sensors is constructing mathematical models between easy-to-measure secondary variables and a primary variable. In recent years, rapid advances in machine learning, data science, computer, and communication technologies have stimulated development of data-driven soft sensor techniques [
1,
2]. Typical data-driven soft sensor modeling approaches include principal component regression (PCR), partial least squares (PLS), neuro-fuzzy systems (NFS), Gaussian process regression (GPR), artificial neural networks (ANN), support vector regression (SVR), recurrent neural network (RNN), and regression generative adversarial networks model with gradient penalty (RGAN-GP) [
3,
4,
5,
6,
7]. However, industrial processes often exhibit complex characteristics, such as nonlinearity, time-variability, and label scarcity, which pose great challenges for building high-performance data-driven soft sensor models.
Process data are often characterized by strong nonlinearity due to the inherent complexity of process production, variability in operating conditions, and demands for different grades of products. A popular solution to this issue is to use a local learning modeling framework. This approach is based on the idea of “divide and conquer” to describe a complex nonlinear space with locally linear spaces and build locally valid models for local regions of process. Common local soft sensor methods include clustering, ensemble learning, and JITL. Among them, clustering algorithms, such as k-means [
8] and Gaussian mixture models, aim to divide process data into multiple clusters by some similarity criterion for describing different local process regions. Ensemble learning methods, such as bagging [
9] and boosting [
10], construct diverse weak learners and combine them to obtain a strong ensemble. The JITL method [
11] is implemented through an online manner, where similar samples relevant to query samples are selected for online local models.
Another issue that needs to be addressed in soft sensor modeling is process time-variability. The data characteristics of production processes often change with time due to sensor drift, seasonal factors, and catalyst deactivation, which result in degradation of soft sensor models’ performance. In the field of machine learning, this problem is called concept drift. For such time-varying production environments, soft sensor models built offline are not well adapted to changes in process states. Therefore, it is necessary to introduce adaptive learning mechanisms to achieve self-maintenance of soft sensor models [
12]. Depending on the change’s speed, time-varying features can be classified into two types: gradual and abrupt changes. Gradual changes proceed slowly, while abrupt changes rapidly shift from one state to another, which makes it difficult for the model to accommodate the changing environments and thus leads to a decrease in model prediction performance. Popularly used adaptation mechanisms include moving window, recursive update, time difference modeling, offset compensation, JITL, and ensemble learning [
13,
14]. Among them, the first four methods can deal with gradual changes effectively, while the last two methods are good at dealing with abrupt changes.
Moreover, scarcity of labeled samples is also a great challenge to limiting accuracy of soft sensors. Generally, soft sensor models are built through supervised learning; thus, their prediction performance relies extremely on using several labeled data. However, in actual industrial processes, it is very common to encounter the dilemma of “labeled data poor and unlabeled data rich” due to the high cost of obtaining sufficient labeled data. To tackle such a challenge, semi-supervised learning methods have been proposed, aiming to improve model performance by making full use of information from unlabeled samples [
15]. The most representative semi-supervised methods are self-training, co-training, generative models, low-density region segmentation, and graph-based methods [
16,
17,
18].
Despite availability of many soft sensor methods proposed for dealing with the problems of process nonlinearity, time-varying behavior, multi-phase/multi-mode property, and labeled sample sparsity, these approaches usually assume that abundant modeling data are available for offline modeling. In practice, this assumption has many drawbacks for practical soft sensor modeling in the process industry: (1) samples obtained offline often ignore temporal correlation; (2) there may be several samples that are not helpful for the current prediction; (3) over-focusing on historical samples while ignoring the latest samples; (4) once the prediction model is implemented, it remains unchanged and thus cannot adapt well to new state changes, which leads to model performance deterioration. In the actual process industry, it is a natural aspect that process data are generated in the form of data streams. Unlike traditional static data, data streams have characteristics of infinite, sequential, high-speed arrival, concept drift, and label scarcity [
19]. Therefore, it is still a challenging issue to develop well-performing soft sensors for process data streams.
Over the years, the research on data streams has mainly focused on classification and clustering, while there are few studies on data stream regression. Among of them, the research on data stream regression mainly focuses on solving concept drift problems in nonstationary environments. The most commonly used algorithm is AMRules [
20], which is the first streaming rule-learning algorithm for regression problems that learns ordered and rule-free sets from data streams. Another classical algorithm is fast incremental model tree with drift detection (FIMI-DD) [
21], a method for learning a regression model tree that identifies changes in tree structure through explicit change detection and informed drift adaptation strategies. Until now, many existing data stream regression algorithms have been implemented based on the above two algorithms to improve performance while achieving better prediction results. The main work is summarized as follows.
- (1)
Rule-based data stream regression algorithms. Shaker et al. [
22] proposed a fuzzy rule-learning algorithm called TSKstream for data stream adaptive regression. The method introduces a new TSK fuzzy rule induction strategy by combining the merits of the rule induction concept implemented in AMRules with the expressive power of TSK fuzzy rules, which solves the problem of adaptive learning from evolving data streams. Yu et al. [
23] proposed an online multi-output regression algorithm called MORStreaming, which learns instances based on topological networks and correlations between outputs based on adaptive rules and can solve the problem of multiple output regression in the data stream environment.
- (2)
Tree-model-based data stream regression algorithms. Gomes et al. [
24] proposed an adaptive random forest algorithm capable of handling data stream regression tasks (ARF Reg). The algorithm uses the adaptive sliding window drift detection method and experiments with the original Page Hinkley test inside each FIMI-DD to detect and adapt to drift. Zhong et al. [
25] proposed an online weight-learning random forest regression (OWL-RFR). This method focuses on a sequential dataset problem that has been ignored in most studies on online RFs and improves the predictive accuracy of the regression model by exploiting data correlation. Subsequently, Zhong et al. [
26] proposed an adaptive long short-term memory online random forest regression, which designs an adaptive memory activation mechanism to handle static data streams or non-static data streams with different types of conceptual drift. Further, some researchers have attempted to introduce online clustering for dealing with data stream regression modeling. Ferdaus et al. [
27] proposed a new type of fuzzy rules based on the concept of hyperplane clustering for data stream regression problems called PALM; it can automatically generate, merge, and adjust hyperplane-based fuzzy rules in a single pass, which can effectively handle the concept drift of each path in the data stream, with advantages of low memory burden and low computational complexity. Song et al. [
28] proposed a data stream regression method based on fuzzy clustering called FUZZ-CARE. The algorithm can accomplish dynamic identification, training, and storage of three patterns, and the affiliation matrix obtained by fuzzy C-means clustering indicates affiliation of subsequent samples of the corresponding pattern. This method can address the concept drift problem in non-stationary environments and effectively avoid the problem of under-training due to lack of new data.
It is evident from the above studies that state identification of a process data stream is the key to obtaining high prediction accuracy from data stream regression models. For this reason, data stream clustering has been widely used to achieve local process state identification. Unlike traditional offline, single, fixed number clustering methods, data stream clustering has the advantage of online incremental learning and updating, which can provide concise representations of discovered clusters and enable processing of new samples in an incremental manner for clear and fast detection of outlier points. Generally, data stream clustering can be classified into hierarchical methods, partition-based methods, grid-based methods, density-based methods, and model-based methods [
29]. Hierarchical data stream clustering algorithms use tree structure, have high complexity, and are sensitive to outliers. The representative ones are ROCK [
30], evolution-based technique for stream clustering (E-stream) [
31], and its extension, HUE-stream [
32]. Partition-based clustering algorithms partition data into a predefined number of hyperspherical clusters, such as CluStream [
33], Streamkm++ [
34], and adaptive streaming k-means [
35]. Grid-based clustering algorithms require determining the number of grids in advance, and they can find arbitrarily shaped clusters and are more suitable for low-dimensional data, such as WaveCluster [
36], a grid-based clustering algorithm for high-dimensional data streams (GCHDS) [
37], and DGClust [
38]. Density-based algorithms form micro-clusters by radius and density, can find arbitrarily shaped clusters, and automatically determine number of clusters, which is suitable for high-dimensional data, and are capable of handling noise, such as DBSCAN [
39], DenStream [
40], online clustering algorithm for evolving data streams (CEDAS) [
41], MuDi-Stream [
42], and an improved data stream clustering algorithm [
43]. Performance of model-based clustering algorithms is mainly influenced by the chosen model, such as CluDistream [
44] and SWEM algorithm [
45].
Among the above-mentioned clustering methods, density-based clustering algorithms are frequently used due to their advantages, such as not requiring the number of clusters to be determined in advance, abilities of identifying outlier points, handling noise, and finding clusters of arbitrary shapes, and their applicability to high-dimensional data. Although traditional density-based clustering algorithms for data streams can discover clusters of arbitrary shapes, the generated clusters cannot evolve and overcome unstable data streams well. To address this issue, Hyde et al. proposed an improved algorithm of CODAS [
46], called CEDAS [
41], which is the first fully online clustering algorithm for evolving data streams. It consists of two main phases. The first phase establishes clusters, which enable updating, generation, and disappearance of clusters, while the second phase consists of forming macro-clusters from micro-clusters, which can handle changing data streams as well as noise characteristics and provide high-quality clustering results. However, this algorithm requires radius and threshold to be defined in advance, which has a large influence on the clustering results. Thus, a method of buffer-based online clustering (BOCEDS) was proposed to automatically determine clustering parameters [
47]. In addition, CEDGM has been proposed by using a grid-based approach as an outlier buffer to handle multi-density data and noise [
48]. Considering the effectiveness of online clustering to overcome data stream noise and achieve high-quality clustering results, this paper aims to build on it to achieve online dynamic clustering for industrial semi-supervised data streams and thus build a high-performance data stream soft sensor model.
Despite the availability of numerous methods proposed for data stream classification and clustering problems, so far, few attempts to study soft sensor applications from the perspective of process data streams have occurred. Since it is very common that numerous unlabeled data and a small number of labeled data are generated with the process data streams in the process industry, this paper focuses on soft sensor modeling for industrial semi-supervised data streams and aims to address the following issues: (1) as with traditional soft sensor methods, data stream soft sensor models also need to effectively deal with process nonlinearity; (2) it is desirable to empower soft sensor models with online learning capabilities for capturing the latest process states to prevent model performance deterioration; (3) it is appealing to mine both historical and new data information to avoid catastrophic forgetting of historical information by the newly acquired model; (4) performance of soft sensor models needs to be enhanced by semi-supervised learning using both labeled and unlabeled data.
To solve the above-mentioned problems, an online-dynamic-clustering-based soft sensor method (ODCSS) is proposed for semi-supervised data streams. ODCSS is capable of handling nonlinearity, time-variability, and label scarcity issues in industrial data streams. Two case studies have been reported to verify the effectiveness and superiority of the proposed ODCSS algorithm. The main contributions of this paper can be summarized as follows.
- (1)
An online dynamic clustering method is proposed to enable online identification of process states concealed in data streams. Unlike offline clustering, this method can automatically generate and update clusters in an online manner; a spatio-temporal double-weighting strategy is used to eliminate obsolete samples in clusters, which can effectively capture the time-varying characteristics of process data streams.
- (2)
An adaptive switching prediction strategy is proposed by combining selective ensemble learning and JITL. If the query sample is judged to be an outlier, JITL is used for prediction. Otherwise, selective ensemble learning is used. The method facilitates effective handling of both gradual and abrupt changes in process characteristics, which enables preventing high soft sensor performance from deteriorating in time-varying environments.
- (3)
Online semi-supervised learning is introduced to mine both labeled and unlabeled sample information, thus expanding the labeled training set. This strategy can effectively alleviate the problem of insufficient labeled modeling samples and can obtain better prediction performance than supervised learning.
The rest of the paper is organized as follows.
Section 2 provides details of the proposed ODCSS approach.
Section 3 demonstrates the effectiveness of the proposed method through two case studies. Finally,
Section 4 concludes the paper. A brief introduction of GPR, self-training, and JITL can be found in
Appendix A,
Appendix B,
Appendix C, respectively.
2. Proposed ODCSS Soft Sensor Method for Industrial Semi-Supervised Data Streams
Soft sensor modeling for data stream remains challenging for the following reasons. First, process data are often characterized by strong nonlinearity and time-variability, which makes the linear and nonadaptive models function badly. Second, many current data stream regression approaches rely on a single-model structure, thus limiting their prediction accuracy and reliability. Third, in industrial processes, it is often the case that labeled data are scarce but unlabeled data are abundant. In such situations, conventional supervised data stream regression models are ill-suited for semi-supervised data streams. Therefore, we propose a new soft sensor method, ODCSS, for industrial semi-supervised data streams. The main steps of ODCSS include: (1) online dynamic clustering; (2) adaptive switching prediction; and (3) sample augmentation and maintenance. The details are described in the following subsections.
2.1. Problem Definition
Semi-supervised data streams. Assuming that the data streams are the continuous sequence containing (∞) instances, i.e., D = {, , , …, , }, where is the sample arriving at time and = {,}, where denotes input features, is the label of the sample. In the context of soft sensor applications, corresponds to the hard-to-measure variables in industrial processes, such as product concentration, catalyst activity, etc. In the data streams, the ideal situation is that all data are labeled, which allows us to perform supervised learning. However, it is often expensive and laborious to obtain labels, thus creating a mixture of a small number of labeled samples and a large number of unlabeled samples, which are called semi-supervised data. Therefore, we assume that the data streams consist of successive arrivals of high-frequency unlabeled samples and low-frequency labeled samples, as denoted by = {, , …, , , , …, , }, where and represent unlabeled and labeled samples, respectively.
Regression task for soft sensor modeling. Suppose semi-supervised data streams
has been obtained up to time
. Given an online obtained
, unknown label
is required to be estimated. Thus, mathematical model
should be constructed based on coming semi-supervised data streams
; that is,
As can be seen from Equation (1), soft sensor modeling for a data stream has the following characteristics.
- (1)
Modeling data changes and accumulates over time. After a period of time, numerous historical data and a small set of recent process data will be obtained. Thus, it is crucial to coordinate the roles of historical data and the latest data for soft sensor modeling. If only the latest information is addressed while ignoring historical valuable information, the generalization performance of the model cannot be guaranteed. Contrarily, focusing only on historical information will make the soft sensor model unable to capture the latest process state.
- (2)
In most cases, the true value of is unknown, and only a few observed values are obtained through low-frequency and large-delay analysis. Traditional supervised learning can only effectively use labeled samples, ignoring the information from unlabeled samples. In practice, unlabeled samples also contain rich information about the process states. Thus, it is also an important way to improve soft sensor models by fully exploiting labeled and unlabeled samples through a semi-supervised learning framework.
- (3)
Stream data usually implies a complex nonlinear relationship between inputs and outputs. Therefore, the idea of local learning is often considered to obtain better prediction performance than a single global model. In addition, as the process runs and changes, is not constant and often exhibits significant time-varying characteristics. Therefore, to prevent degradation of the prediction performance of , it is necessary to introduce a suitable adaptive learning mechanism to achieve an online update of .
2.2. Online Dynamic Clustering
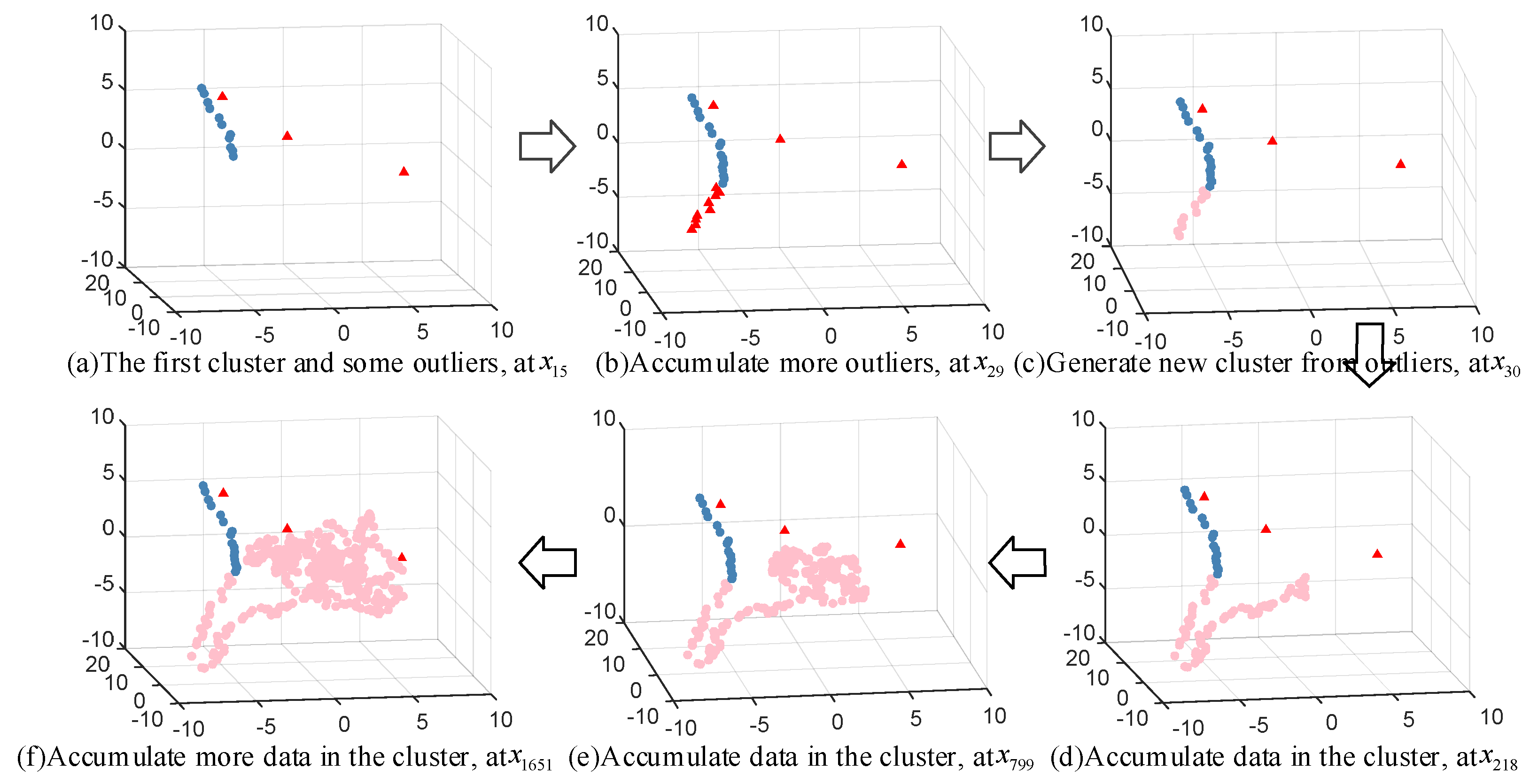
Industrial process stream data often contains rich process state information; however, traditional global modeling is difficult to obtain high prediction accuracy because local process states cannot be well characterized. For this reason, clustering algorithms are often used to implement process state identification. However, traditional clustering algorithms are usually implemented offline and the resulting clusters remain unchanged once the clustering is completed. Such approaches are not suitable for handling data streams that evolve in real time. Thus, in data stream environments, local process state identifications need to be performed dynamically in an online manner. To this end, an online dynamic clustering (ODC) method based on density estimation is proposed to achieve online state identification of process data streams.
Traditionally, offline clustering algorithms for batch data can usually obtain multiple clusters at the same time. In contrast to this, ODC processes the data online one by one and assigns them to the appropriate clusters. Without loss of generality, Euclidean distance is chosen to measure the similarity between samples in this paper. The calculation formula is as follows:
where
and
represent two arbitrary samples.
2.2.1. Initialization
The ODC process requires setting two important initial parameters: cluster radius
and minimum density threshold
. Given a dataset, the most appropriate cluster radius needs to be selected based on the data features, i.e., the maximum allowable distance from the cluster center to the cluster edge. When the distance between data points is less than the radius and the number of data reaches the minimum density threshold, cluster
can be formed. The average of all sample features in the cluster is calculated as cluster center
. Clustering is an unsupervised process and is completed using features only, where clustering center
is simply calculated as
where
is the sample size in the cluster and
is the
-th sample.
The first cluster is constructed to store information related to the clusters, including clustering center and the data samples stored in the cluster. Following this, online dynamic clustering is performed for sequentially arrived query sample .
2.2.2. Updating the Cluster
Assume that multiple clusters have been obtained, i.e.,
, and a new query sample
arrives; then, Euclidean distances
between
and the existing cluster centers are calculated as
If
,
is included to cluster
. Considering the boundary fuzzy property between different process states, a softening score strategy is used to group the sample points into all eligible clusters. In addition, if
, cluster center
will be updated to accommodate concept drift:
where
is the
-th cluster,
is the Euclidean distance between the new sample and the
-th cluster,
is the number of samples in the
-th cluster, and
and
denote the cluster centers before and after updating.
It should be noted that the shape of the cluster is not fixed but further evolves with migration of cluster center .
2.2.3. Generating the New Cluster
Since the process state is always changing, the clusters need to adapt to new state changes as samples accumulate. Thus, it is desirable to generate new clusters to accommodate concept drift as the process data grow. If Euclidean distance between and cluster center is larger than the radius, this sample is regarded as an outlier. In such a case, distances between the existing outliers are calculated, and a new cluster is generated if the number of outliers with distances less than the radius reaches minimum density threshold . The center of the new cluster is calculated using Equation (3). The remaining outliers that do not form clusters are retained and exist separately in space.
2.2.4. Removing Outdated Data in the Cluster
Ideally, data streams are an infinitely increasing process. However, the update burden of clusters as well as the computational efficiency of soft sensor models will grow as the process data accumulates. Hence, it is appealing to remove the outdated samples from the clusters.
Since Euclidean distance only considers spatial similarity and tends to ignore the temporal relevance of samples, a spatio-temporal double weighting strategy is proposed to consider both spatial and temporal similarity between historical and recent samples. For this purpose, the spatio-temporal weights are calculated to eliminate the least influential samples in the cluster on the query sample
:
where
is the distance from the
-th sample in the cluster to the cluster center and
is the time interval between the
-th sample in the cluster and query sample
, and
is a parameter controlling the influence of spatio-temporal information. The smaller the weights are, the smaller the corresponding history samples have an influence on query sample
. The spatio-temporal weights are sorted in ascending order, and a fixed proportion of historical samples are removed.
The pseudo code for the ODC method is given in Algorithm 1.
| Algorithm 1: Online dynamic clustering (ODC) |
| INPUT: : Data streams |
| : Cluster radius |
| : Minimum density threshold |
| : Controlling parameter |
| : The percentage of removed samples |
| PROCESS: |
| 1: Create a cluster structure containing: %% Initialization |
| 2: () = ; %% Cluster center |
| 3: () = ; %% Save data |
| 4: () = []; %% Save outlier, initially empty |
| 5: Calculate distances between and all cluster centers using Equation (3). |
| 6: if %% Updating the cluster |
| 7: is stored in all clusters where ; |
| 8: if 2/3 |
| 9: Update cluster center using Equation (5); |
| 10: end if |
| 11: else if %% Generating a new cluster |
| 12: is stored in the outliers; |
| 13: Calculate distances between samples stored in outliers; |
| 14: if & size(outliers) |
| 15: Generate a new cluster; |
| 16: is stored in the new cluster; |
| 17: Calculate new cluster center using Equation (3); |
| 18: end if |
| 19: end if |
| %% Removing the outdated data in the cluster |
| 20: Calculate the spatio-temporal weights for each sample in the cluster using Equation (6); |
| 21: Sort in ascending order; |
| 22: According to the sorting, delete the samples with the smallest weights in the cluster and fix the proportion of the deleted samples to ; |
| OUTPUT: Cluster results |
2.3. Adaptive Switching Prediction
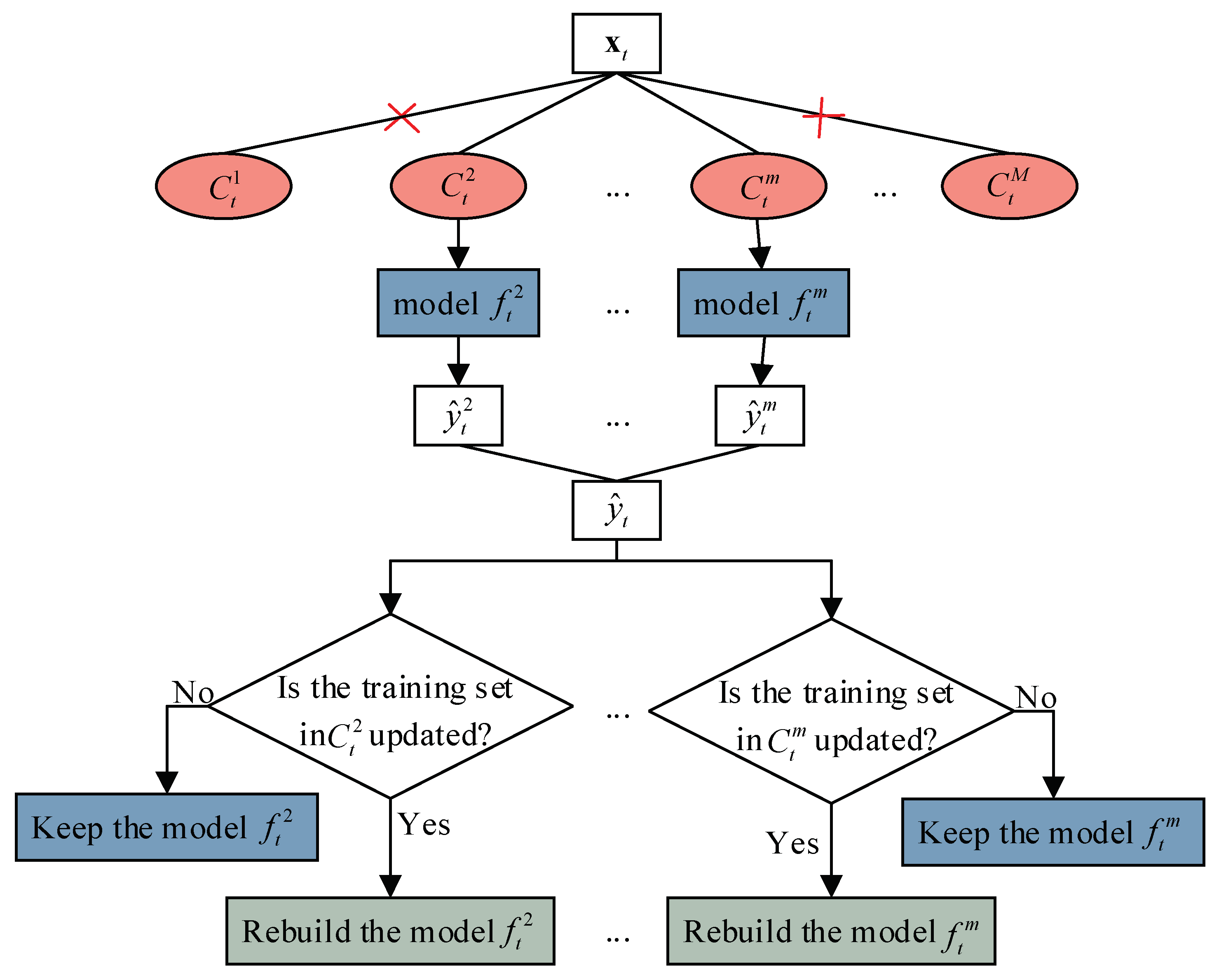
By applying online dynamic clustering, query sample can be assigned to either existing clusters or outliers. In comparison with samples within clusters, outliers reveal significantly different statistical characteristics of process variables. Thus, an adaptive switching prediction method is proposed by combining adaptive selective ensemble learning with JITL to achieve real-time predictions for within-cluster samples and outliers, respectively. In addition, GPR is used as the base modeling technique, which is a nonparametric regression model that can learn arbitrary forms of functions with advantages such as smoothness, parameter adaption, and strong capability of fitting nonlinear data.
2.3.1. Adaptive Selective Ensemble Learning for Online Prediction
Suppose that clusters have been obtained at moment , for which GPR base models are built. When query sample arrives, prediction is achieved using an adaptive selective ensemble learning strategy if is classified into clusters. Three main key steps are described as follows:
Step 1: evaluate distances between and its corresponding cluster center , and select () GPR models with small distances .
Step 2: provide
prediction values {
,
, …,
} based on the obtained models, and use simple averaging rule to obtain final prediction output
:
Step 3: if a new labeled sample or high-confidence pseudo-labeled sample is added to the clusters, the corresponding GPR models will be rebuilt.
It is worth noting that new labeled samples are often obtained by offline analysis, while pseudo-labeled samples are obtained by self-training, which is detailed in
Section 2.4.
Figure 1 shows the schematic diagram of the adaptive selective ensemble learning framework.
2.3.2. Just-In-Time Learning for Online Prediction
If query sample is judged to be an outlier, JITL is used for prediction. Since the outliers are samples deviating from the clusters, if the outliers are predicted by using the models built from clusters, the predictions may deviate greatly from the actual values. Therefore, by using all labeled samples as the database, a small-size dataset similar to query sample is constructed to build a JITGPR model for online prediction of .
Thus far, various similarity measures have been proposed for JITL methods [
49], including Euclidean distance similarity, cosine similarity, covariance weighted similarity, Manhattan distance similarity, Pearson coefficient similarity, etc.
Algorithm 2 presents the pseudo code of the adaptive switching prediction process.
| Algorithm 2: Adaptive switching prediction |
| INPUT: : Data streams |
| : Online clustering results |
| : The maximal size of the selective clusters |
| PROCESS: |
| 1: if is within clusters %% Adaptive selective ensemble learning for online prediction |
| 2: Select the GPR models corresponding to the closest clusters; |
| 3: Predict using the selected models to obtain {, , …, }; |
| 4: Calculate the average of using Equation (7) to obtain final prediction output ; |
| 5: for = 1, 2, …, do |
| 6: if there is an update to the samples in the -th cluster |
| 7: Rebuild a new GPR model using the updated samples; |
| 8: else if the samples in the -th cluster are not updated |
| 9: Keep the old GPR model; |
| 10: end if |
| 11: end for |
| 12: else if is judged to be an outlier %% Just-in-time learning for online prediction |
| 13: Select the most similar samples to the as training set from the historical labeled samples; |
| 14: Build a JITGPR model with ; |
| 15: Predict using the JITGPR model; |
| 16: Obtain finally predicted result ; |
| 17: end if |
| OUTPUT: Prediction result |
2.4. Sample Augmentation and Maintenance
Although the production process produces a large number of data records in the form of streams, the proportion of labeled samples is small. In practice, for arbitrary query sample , its label can be estimated by using the adaptive switching prediction method. Such predictions are called pseudo labels, which can be used to update the model if they are highly accurate. However, the actual labels for most unlabeled samples are unknown due to absence of offline analysis. For this reason, we borrow the idea of self-training, a widely used semi-supervised learning paradigm, to obtain high-confidence pseudo-labeled samples and then update the models.
One main difficulty of self-training is defining confidence evaluation criteria for selecting high-quality pseudo-labeled samples. Thus, we attempt to evaluate improvement of prediction performance before and after introducing pseudo-labeled samples. The specific steps are described as follows:
Step 1: select a certain proportion of the labeled samples similar to query sample as the online validation set and use the remaining labeled samples as the online training set.
Step 2: build two GPR models based on the training set before and after adding the pseudo-labeled data {, }, respectively.
Step 3: evaluate the prediction RMSE values of the two models on the validation set, and then the improvement rate (
) can be calculated as:
where RMSE and
are the root mean square errors of the GPR model on the validation set before and after the pseudo-labeled sample is added to the training set.
Step 4: if the value of the pseudo-label is greater than confidence threshold , {, } is added to the corresponding cluster to update the training set. Otherwise, this sample is removed from the clusters.
Although the latest pseudo-labeled samples added to the clusters can improve the prediction performance for the query sample, accumulating too many pseudo-labeled samples can cause error accumulation, so timely deletion of the outdated historical samples is very essential for reducing prediction deviations. To make full use of the information from the recent unlabeled samples, the sample deletion procedure is started only when the latest true label is detected, and the pseudo-labeled data that have the least impact on query sample are deleted. The above process is accomplished by online dynamic clustering, which can reduce the update burden of clustering on the one hand and improve the prediction efficiency of soft sensor models on the other hand.
2.5. Implementation Procedure of ODCSS
The overall framework of the ODCSS soft sensor method is illustrated in
Figure 2. With the process data arriving in the form of stream, ODCSS is implemented mainly through three steps: online dynamic clustering, adaptive switching prediction, and sample augmentation and maintenance.
Given the input: (1) data streams ={, , …, , , , …, , }; and (2) modeling parameters: clustering radius , minimum density threshold , controlling parameter , the proportion of deleted data , confidence threshold , and the maximal ensemble size . Assume that clusters and their corresponding models have been constructed at moment , along with a small number of outliers. The following steps are repeated for any newly arrived query sample:
Step 1: when query sample arrives at time , online dynamic clustering is performed to include to clusters or recognize as an outlier.
Step 2: if belongs to clusters, first select the GPR models corresponding to the nearest () clusters, and then obtain a set of predicted values {, , …, } based on the selected GPR models; finally, calculate the average value of predicted values to obtain final prediction output . If belongs to outliers, use a JITGPR model to obtain final prediction output .
Step 3: the confidence of {
,
} in the cluster is evaluated based on the proposed strategy in
Section 2.4. If
exceeds
, the obtained pseudo-labeled sample is added to the clusters to update the models. Otherwise, this sample is discarded.
Step 4: when actual label of is available, the sample {,} is used to update the training set and base models, while the corresponding pseudo-labeled sample is removed. Meanwhile, the outdated samples are removed by using the proposed ODC method.
4. Conclusions
This paper presents an online-dynamic-clustering-based soft sensor (ODCSS) for industrial semi-supervised data streams. By applying online dynamic clustering to process data streams, ODCSS enables automatic generation and update and deletion of obsolete samples, thus realizing dynamic identification of process state. In addition, an adaptive switching prediction method combining online selective ensemble with JITL is used to effectively handle gradual and abrupt time-varying features, thus preventing model degradation. Moreover, to tackle the label scarcity issue, semi-supervised learning is introduced to obtain high-confidence pseudo-labeled samples online. The proposed ODCSS is a fully online soft sensor method that can effectively deal with nonlinearity, time variability, and shortage of labeled samples in industrial data streaming environments.
To verify the effectiveness and superiority of the proposed ODCSS method, two application cases are considered. Meanwhile, seven representative soft sensor methods and ODCSSS (without pseudo-labeled samples) are compared with the proposed ODCSS. From the , , and , it is evident that the proposed method outperforms the other compared methods in terms of all evaluation metrics. Especially, in TE process, with as a baseline, ODCSS improves prediction accuracy by 48.7% compared to OSELM, and introduction of semi-supervised learning improves prediction performance by 3.6% compared to ODCSSS. For the CTC fermentation process, although ODCSS does not show significant differences from some methods in terms of overall testing performance, the superiority of the proposed method becomes more and more obvious with accumulation of streaming data and advancement in online learning. Both the TE and CTC application results confirm that the proposed ODCSS method can well address time-variability, nonlinearity, and label scarcity problems and thus achieve high-precision real-time prediction of subsequent online arrived samples by using only very few labeled samples and adding high-confidence pseudo-labeled data.
Currently, there is still a lack of research on soft sensor modeling for data streams, and this study is only a preliminary attempt. There are still several issues requiring further attention. First, although the proposed algorithm has good prediction accuracy, computational burden of online modeling will inevitably increase with accumulation of process data streams. Thus, how to improve the efficiency of online modeling is also a major concern. Second, with evolution of process data streams, optimal model parameters also change, so it is appealing to adjust the model parameters adaptively. Third, the proposed method only considers identifying local features based on the spatial relationship between samples. For data streams, temporal relationships between samples are also worth noting. Fourth, as streaming data accumulate, mining the hidden features of streaming data using incremental deep learning is also an interesting research direction. These issues remain to be studied in our later work.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}