1. Introduction
The distinguishing ability to learn higher-level feature representations at successive nonlinear layers makes deep neural networks (DNNs) widely applied in image classification. With the progression of hardware and learning techniques, DDNs become deeper. This dramatically increases the inference latency. However, the time needed to process an image usually depends on its complexity. For example, it is faster to recognize a person standing in front of a plain blue backdrop than amid a crowd. As the images in real-world datasets always have different classification difficulties, various researchers proposed the model early-exit mechanism and corresponding implementations for accelerating DNN inference by exiting the inferencing process earlier when reaching the required inference accuracy [
1,
2,
3,
4]. For example, BranchyNet [
1] is a programming framework that implements the model early-exit mechanism. A standard DNN can be resized to its BranchyNet version by adding exit branches with early exit points at certain layer locations. Then, simple images can be classified and exit the network through these early-exit points without going through all the layers of the original DNN, which leads to speedups of about two to five times in inference time, as shown in [
1].
Although the BranchyNet can effectively reduce inference time according to the classification complexity of different images by satisfying the required inference accuracy, it increases the model size by adding additional branches. For instance, the authors in [
1] add a branch consisting of one convolutional layer and one fully-connected layer into the basic LeNet-5 network. As a result, the total number of layers increases to seven, 1.4 times the original model’s. For AlexNet, the authors add two branches with a total of five additional layers. The number of layers gets to 1.625 times that of the original model. Larger models undoubtedly need more storage for storing and running. Moreover, running these additional branches can also cost more energy. In the above Branchy-LeNet (B-LeNet), a complex image will go through all seven layers before achieving its classification result, which runs one convolutional layer and one fully-connected layer additionally. Similarly, a complex image processed by the Branchy-AlexNet (B-AlexNet) needs to run three convolutional layers and two fully connected layers additionally. Evidently, this costs more energy than when processed by the original networks. Therefore, when applying BranchyNet in real applications, it is crucial to design and implement an efficient application strategy.
In order to effectively apply BranchyNet, the framework DDNNs [
5] adopt BranchyNet to distribute DNNs across the cloud, edge, and devices. It divides a BranchyNet into three parts at pre-defined early-exit points. Moreover, the authors propose three different aggregation methods to integrate results from various same-level exit points. Edgent [
6,
7] jointly applies model early-exit and model partition. It first trains a branchy model at the offline configuration stage. Then, it tries to obtain an optimal partition at the online tuning stage to maximize inference accuracy under the given latency requirement. This approach cuts the DNN according to the current bandwidth state and deploys the two sub-models to a model device and the edge server. The authors in [
4] propose an approach to utilize the communication channels efficiently when an edge device with a built-in auxiliary network shares workload with an edge server with a remote principal network. They introduce the dynamic network-sizing technology to vary the depth of the auxiliary network to adjust the amount of workloads to be transferred to the principal network while maintaining overall accuracy. These works only cut the BranchyNet into two or three fixed parts to support collaborated inferencing among cloud, edge, and devices. However, dividing a BranchyNet into multiple pieces for distributed collaboration by a group of robots, drones, vehicles, and other intelligent edge devices is still challenging.
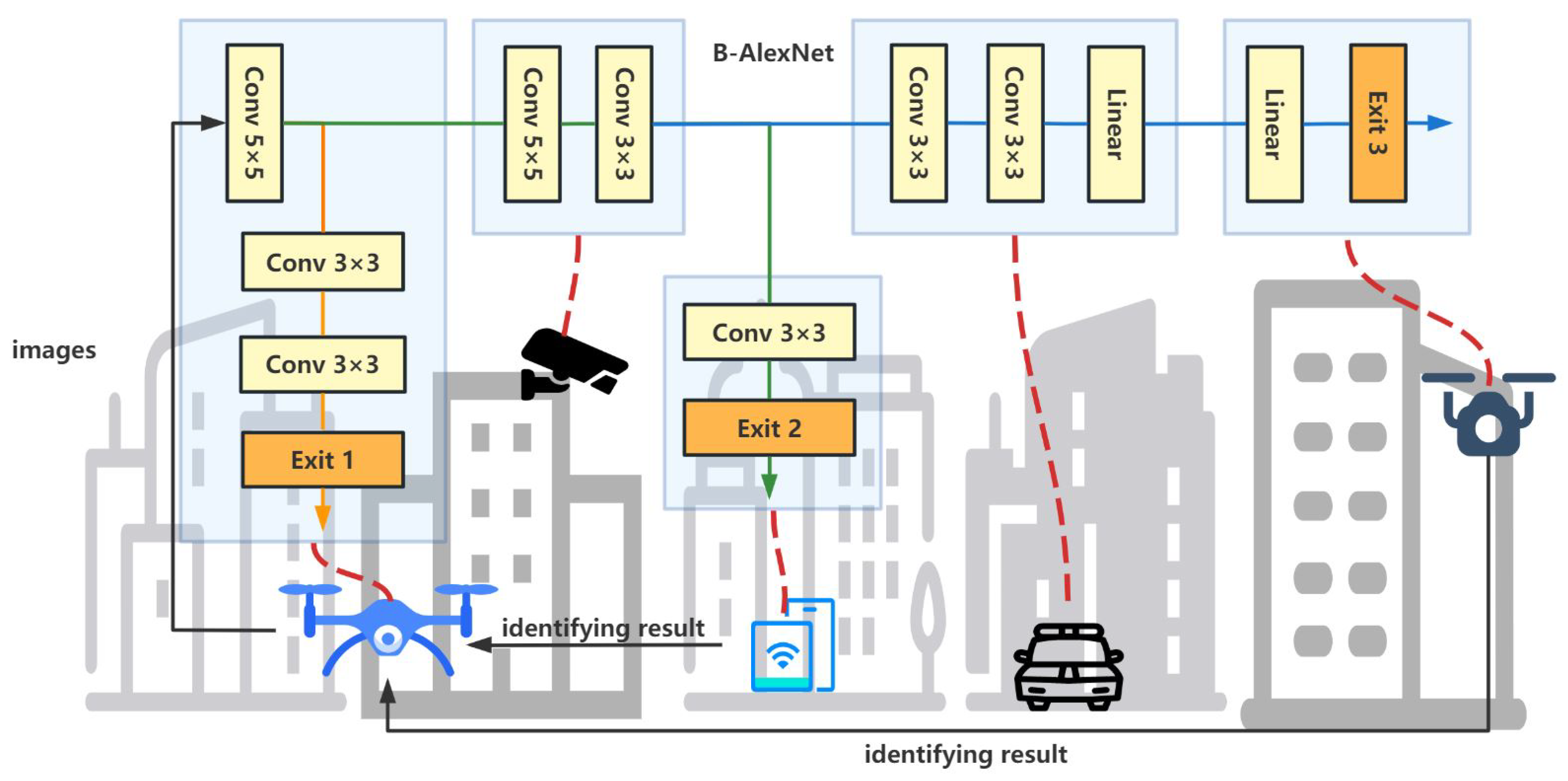
Unlike most existing cloud–edge or edge–device collaborations, this work focuses on collaborative inferencing among several intelligent edge devices. Let us take the example of object identification in public security systems or city surveillance systems illustrated in
Figure 1. A pre-trained B-AlexNet is divided into five pieces and deployed into two drones, a camera, a smartphone, and a smart car. To perform the object identification task, the leftmost drone capture images as input to the B-AlexNet and runs the first branch. If the first branch can result in a correct identification result, it will return the identification result to the business system. Otherwise, the process goes back to the first convolutional layer, whose result will be sent to the camera. In turn, the camera will run the inference task assigned to it and send the corresponding output to the smartphone, which performs the second exit branch and obtains corresponding identification results. There are more similar application scenarios, such as distributed fall detection [
8] and traffic prediction [
9].
The above illustration shows that the DNN partitioning problem is different from the general task offloading problem [
10,
11,
12], which is a topic of interest in edge computing and mobile edge computing. The task offloading problem emphasizes offloading all or part of computing tasks from an edge device to the associated edge server. On the contrary, DNN partitioning aims to split a large computation task into many sub-tasks and distribute them to a group of edge devices to use the free resources of such edge devices fully. As a result, an edge device needs to perform its task with the help of a selected edge server in task offloading, while the edge devices cooperate to perform a task without an edge server after DNN partitioning.
In order to accelerate edge inference, it has been emerging to partition a complete neural network into several parts and deploy them to a group of edge devices [
13,
14]. Due to the fact that intermediate results no longer need to be further sent to the remote cloud center, all inference tasks will be completed in the edge environment. This ensures data privacy and saves transmission costs. However, unlike only dividing a network into two or three parts, partitioning a network into multiple parts is an NP-hard problem. Although some strategies are trying to split a DNN into several parts effectively [
15,
16,
17], most of them try to select a particular branch to split and deploy rather than partitioning the whole BranchyNet with all branches which reduces the applicability and flexibility of the generated deployment plan.
This paper proposes a novel genetic algorithm (GA)-based BranchyNet partitioning approach for accelerating edge inference. In order to ensure the applicability of the resulting deployment plan, the partitioning problem is defined as a constrained optimization problem to generate an optimal deployment plan under a given amount of available resources. Then, a two-layer chromosome GA is designed to solve the established problem more efficiently. Experiments are taken on partitioning B-AlexNet and B-ResNet proposed in [
1]. By comparing with methods proposed in [
5,
18,
19], the proposed GA significantly decreases the inferencing latency. The main contributions of this paper are as follows:
Firstly, this paper presents the formulation for estimating the total execution time of a complete BranchyNet, including inferencing and transmitting the intermediate results, and converses the BranchyNet partitioning problem into a constrained optimization problem;
Secondly, this paper puts forward a two-layer chromosomes GA. It emphasizes the consistency between partitioning and deployment and divides chromosomes into partitioning and deployment chromosomes accordingly;
Finally, this paper presents a comprehensive experiment evaluation by comparing the proposed method with four other typical DNN partitioning approaches based on B-AlexNet and B-ResNet in inferencing performance and algorithm efficiency.
The rest of this paper is organized as follows.
Section 2 reviews and classifies existing DNN partitioning approaches.
Section 3 presents the problem formulation for achieving optimal BranchyNet partitioning. Then,
Section 4 describes the proposed algorithm’s details, including the network’s pre-processing and improving basic GA, and
Section 5 provides the corresponding experimental results. Finally,
Section 6 concludes this work and outlines possible directions for future research.
2. Literature Review
According to the different deployment targets of DNN, existing DNN partitioning methods can be divided into the following two categories.
One way is to divide a DNN into two or three parts for deploying to the edge device, edge server, and remote cloud. For example, the authors in [
20] propose to cut a CNN model at the end of the convolutional layer. Then, they allocate and perform the convolutional layers at the edge and the rest of the fully-connected layers in the cloud. Instead of selecting a fixed partitioning point according to the network structure, the authors in [
18] observe that ideal fine-grained DNN partition points depend on the layer compositions of the DNN, the particular mobile platform used, the wireless network configuration, and the server load. With this in mind, they propose a lightweight scheduler named Neurosurgeon to automatically partition DNN computation between mobile devices and data centers for either the best end-to-end latency or mobile energy consumption by testing every candidate point after each layer. Refs. [
6,
21,
22] also adopt similar strategies in order to identify the best partition points. However, unlike other works using exhaustive searching, ref. [
22] solves the problem by mixed integer linear programming.
The other way is to divide a DNN into more than two parts and deploy them onto multiple devices. There are usually three different perspectives to partition a DNN into multiple parts. Firstly, considering the requirements for storing large inputs or weights, inputs partitioning [
23,
24] and weights partitioning [
25] approaches are proposed. These two kinds of strategies attempt to slice a DNN horizontally, which enables a single-edge device to store part of the input data or weight when it does not have enough storage. Secondly, layer-based partitioning is proposed to solve the depth problem in DNN inference [
15,
16]. Thirdly, more works are emerging to provide a hybrid solution [
14,
17,
26,
27,
28,
29]. For example, ref. [
26] adopts both input partitioning and layer-based partitioning to obtain a group of small enough sub-models. Ref. [
17] proposes a grid fashion to fuse and partition layers vertically. Ref. [
28] models a DNN as a data-flow graph and transforms the DNN partitioning problem into a graph-partitioning problem.
In summary, there is a common assumption in nearly all of the above works: the DNN is a well-organized linear structure. Although [
6,
21] added early-exit branches to the original DNN before partitioning, they split the pre-trained BranchyNet into several independent linear DNNs before partitioning. They selected the best partition points by testing all positions after each layer in all these linear DNNs, which, in essence, only selects and deploys part of the original BranchyNet. It is hard to ensure the actual inference accuracy. As far as we know, there are currently few solutions specifically for BranchyNet partitioning. Moreover, more studies have begun to focus on the joint optimization of DNN partitioning and resource allocation [
30,
31,
32]. However, it is still an open and critical challenge.
3. Problem Formulation
3.1. System Model
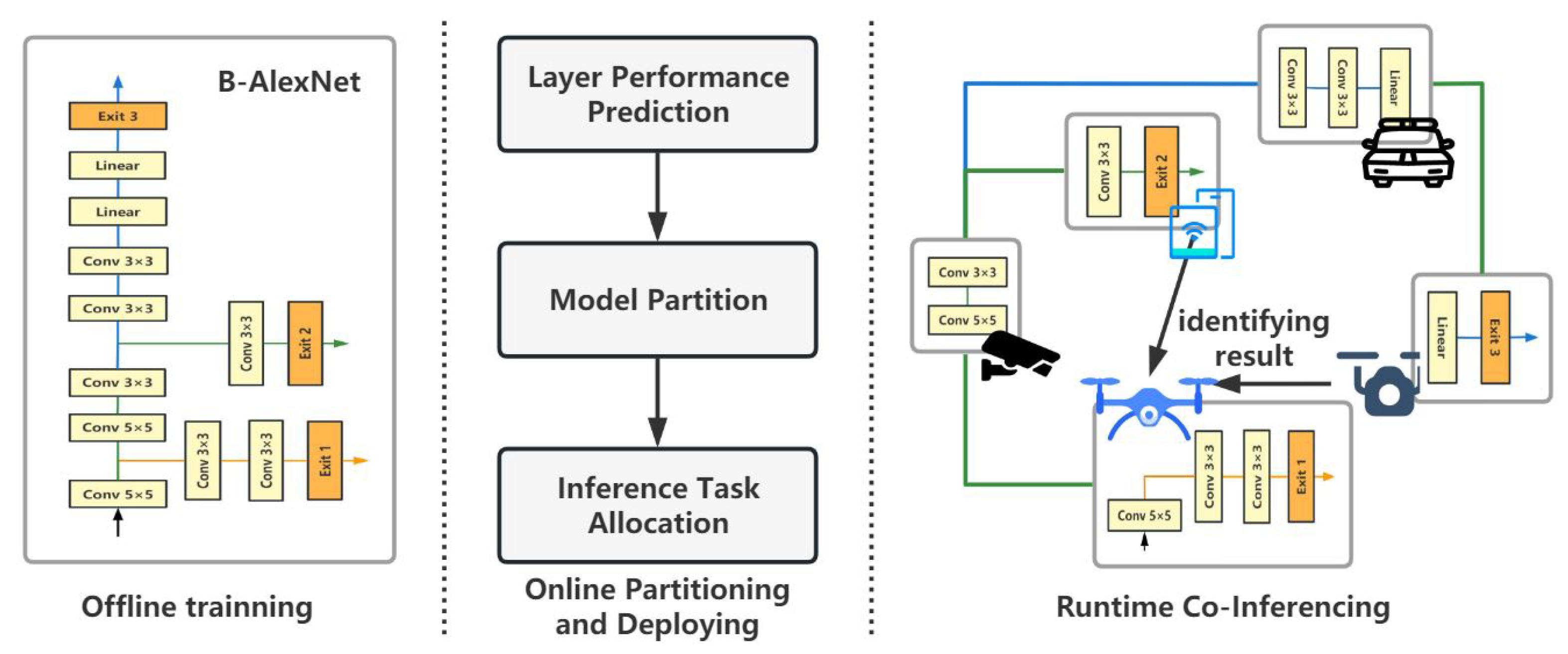
As illustrated in
Figure 1, suppose there are
N edge devices in an edge network. Regarding the available memory, computation capacity, and energy, various edge devices can perform different sub-tasks of a given inference. Then, when an intelligent edge application needs to be deployed, the corresponding edge server will act as a master to break down the DNN inference tasks according to the current states of all edge devices and the communication bandwidth of the edge network. Similar to [
6], this process can be divided into three main stages, as shown in
Figure 2.
At the offline training stage, a BranchyNet is trained for running. Then, the online partitioning and deploying stage will first predict the performance of each layer in the pre-trained model. This can be achieved by PALEO [
33], the layer performance regression function in [
6,
18], or other layer prediction models. Based on the result of layer performance prediction, the model partitioning algorithm generates an optimal deployment, according to which the sub-tasks are assigned to selected edge devices. Then, these edge devices perform the original inference task collaboratively at run-time. Unlike offline partitioning, which partitions a model immediately after training without considering existing available resources in the run-time environment, this work focuses on online partitioning that tries to achieve better execution performance in a given run-time environment.
In real-world applications, the online partitioning and deploying algorithm will be deployed on the edge server. Then, after a user deploys an intelligent application to the edge environment, the edge server will extract the inferencing task and the corresponding BranchyNet. It partitions and dispatches the BranchyNet according to the current status of each edge device which will then cooperate to complete a further distributed inferencing process without the edge server.
3.2. Duration for Performing a Sub-Task in the Cooperative Inferencing
Each device must receive input from its preceding device and deliver the output to its next device during cooperative inferencing. For example, in
Figure 2, the B-AlexNet is divided into five sub-models and deployed to five different devices. To perform the assigned inference task, the camera needs to receive input from the first drone and send its output to the smartphone, which will, in turn, execute the next sub-model.
Let us suppose a complete inference task is divided into
n sub-tasks deploying to
n selected devices. This paper uses
to represent a sub-model to be performed and
to represent one of those selected devices. If a sub-model
is deployed to device
, the corresponding execution time
is defined as
where
is the time of executing sub-model
on device
,
and
are the time for receiving the input of
and sending the output of
, respectively. If
is used to represent the total transmission time, then
and
.
3.3. Duration for Executing a Complete BranchyNet
Different from conventional linear structure DNNs, a BranchyNet usually has several early-exit branches. Based on the idea of an early-exit mechanism, not all the branches would be executed for processing a given input. Therefore, it is different from the total execution time calculation for linear structure DNNs, which can be easily achieved by summing up the execution duration of all the sub-tasks. The total execution time of a BranchyNet varies according to the complexity of the given input. This paper adopts the weighted average duration to represent the duration of performing a complete BranchyNet inference.
In detail, suppose there are
m branches in a given BranchyNet. Each branch
,
has a total execution duration
and a proportion representing the percentage of samples exit from this branch
. Then, the duration for performing the given BranchyNet is defined as
where
. The value of each
can be achieved after training or testing the BranchyNet model, which equals the ratio of the number of samples exiting from branch
and the total number of samples, while the execution time of a complete branch
is obtained by summing up the execution time of all layers that a sample traverses before exiting, i.e.,
where
is a coefficient to indicate whether a sub-model
is assigned to device
, whose value is either 0 or 1. When
, the sub-model
is assigned to device
. Otherwise, i.e.,
, the sub-model
is assigned to another device rather than
. If a branch is divided into
n parts, and each part is uniquely deployed to one specific device, then, for any device
, the equation
makes sense. Likewise, for any sub-model
,
.
3.4. Problem Formulation
Except for the above time cost for performing a BranchyNet, given the memory and power consumption requirements of performing each sub-model, it is also necessary to consider the available amount of memory and energy on each device to achieve a feasible partition. In summary, this work aims to minimize the execution time of a given BranchyNet under the constraints of memory and energy consumption, which is formulated the BranchyNet partition problem as the following constrained optimization problem.
Here, is the size of available memory on device , and is the required memory for running sub-model . If is assigned to device , i.e., , the available amount of memory should not be less than the required amount of memory . Similarly, the remaining energy should not be less than the required amount of energy, which is the product of the average running power and the sub-model execution time . If there are more constraints, such as computing capabilities, communication bandwidth, and other aspects, the problem can be modeled by adding corresponding constraints to the above formulation.
Based on Equations (
2) and (
3), the problem can be finally defined as follows:
where
is the number of pieces branch
is divided into.
All of these form an n-by-n matrix A, which represents an actual deployment plan. This paper aims to achieve a specific matrix A with the shortest execution time under memory and energy consumption constraints. Let us suppose a BranchyNet with L layers will be partitioned and deployed to N devices. There are different partition plans and different deployment plans. Therefore, the above problem is a typical NP problem.
4. The Proposed Two-Layer Chromosome GA
A genetic algorithm (GA) is a method to search for the optimal solution by simulating the natural evolution process. When solving complex combinatorial optimization problems, a GA can usually obtain better optimization results faster than some conventional optimization algorithms. The chromosome coding scheme is the fundamental element of a GA. This section analyzes problems of applying the basic GA to solve the formulated optimization problem and then introduces the corresponding solution in this paper.
4.1. Linearization of a BranchyNet
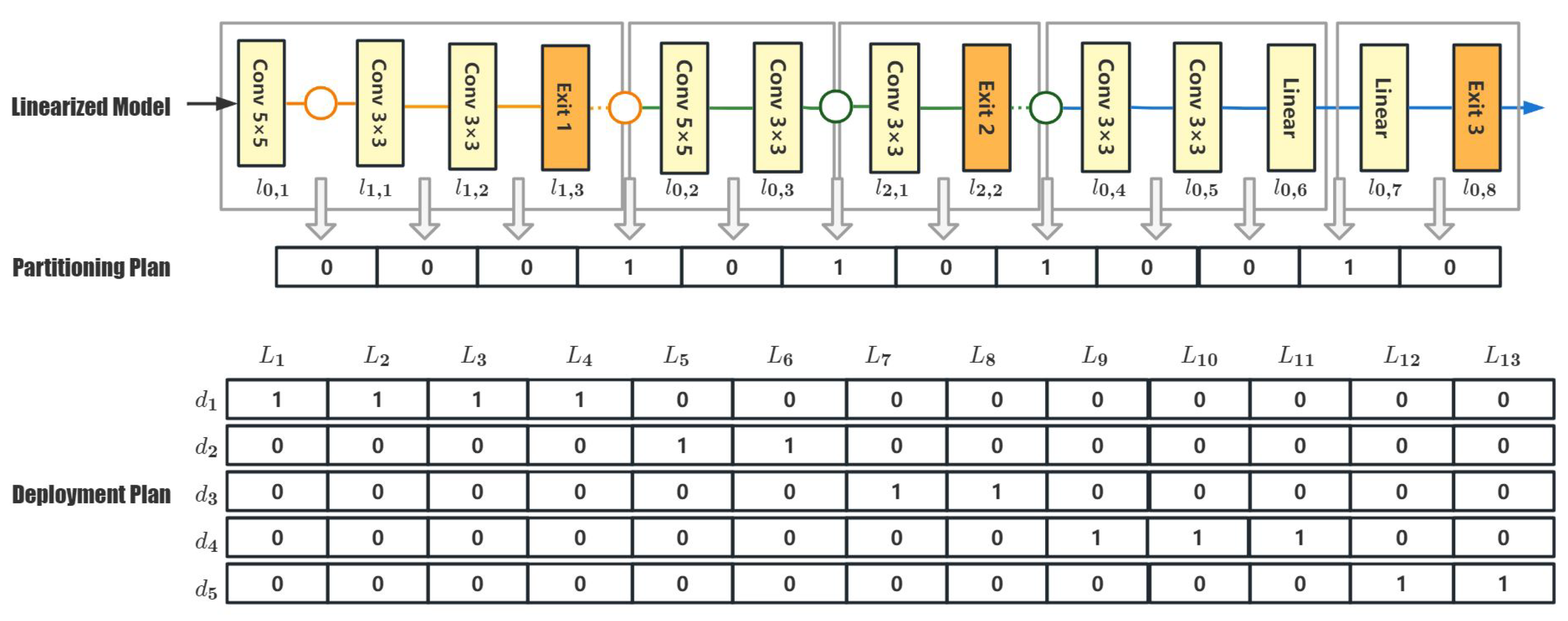
In order to calculate and represent the partitioning plan conveniently, a linearization strategy is proposed to convert a BranchyNet into a linear model. The linearization result of the B-AlexNet is shown in
Figure 3.
In
Figure 3, the first line illustrates the linearized results of the B-AlexNet, where circles are the fork nodes in the B-AlexNet. To distinguish different layers in a B-AlexNet, this work labels a layer as
, where
x refers to the branch the layer belongs to, and
y indicates the position that the layer is located in the branch. For example, in the B-AlexNet, as there are three branches, the value of
x is 0, 1, or 2.
is the second layer of the first exit branch. To simplify the representation and computation in the proposed algorithm, layers in the linearized model are further transformed to
, and a mapping is established between labels in the linearized model layer and their original position.
After the above linearization, a partition plan can be easily represented as a vector. As shown in the middle of
Figure 3, if there are
L layers in the linearized model, there should be
possible cut points. Hence, a partitioning plan can be modeled as a vector with
elements, each of which is either 0 or 1, and the value 1 represents a selected cut point. The B-AlexNet is divided into five parts in the illustrating example, so there are four cut points, as shown in
Figure 3.
Moreover, a deployment plan can be modeled as an
matrix,
A. The value of any
in
A is either 1 or 0. If
, it means that layer
is assigned to device
. As shown at the bottom of
Figure 3, there are five devices and thirteen layers. A deployment plan is modeled as a matrix with five rows and thirteen columns. The value 1 at the first line means layers
,
,
, and
are deployed to device
, where
,
,
, and
are the identifiers of layers in the linearized model.
4.2. Problems with Basic Crossover Operator
The basic process of a GA starts with generating an initial population, i.e., a set of chromosomes. Then, it runs through the loop, including individual evaluation, selection, crossover, and mutation, until satisfying the given termination condition. The crossover operator plays a core role in a GA, which acts on a group of chromosomes and generates new individuals by replacing part of the chromosomes of two father-generation individuals.
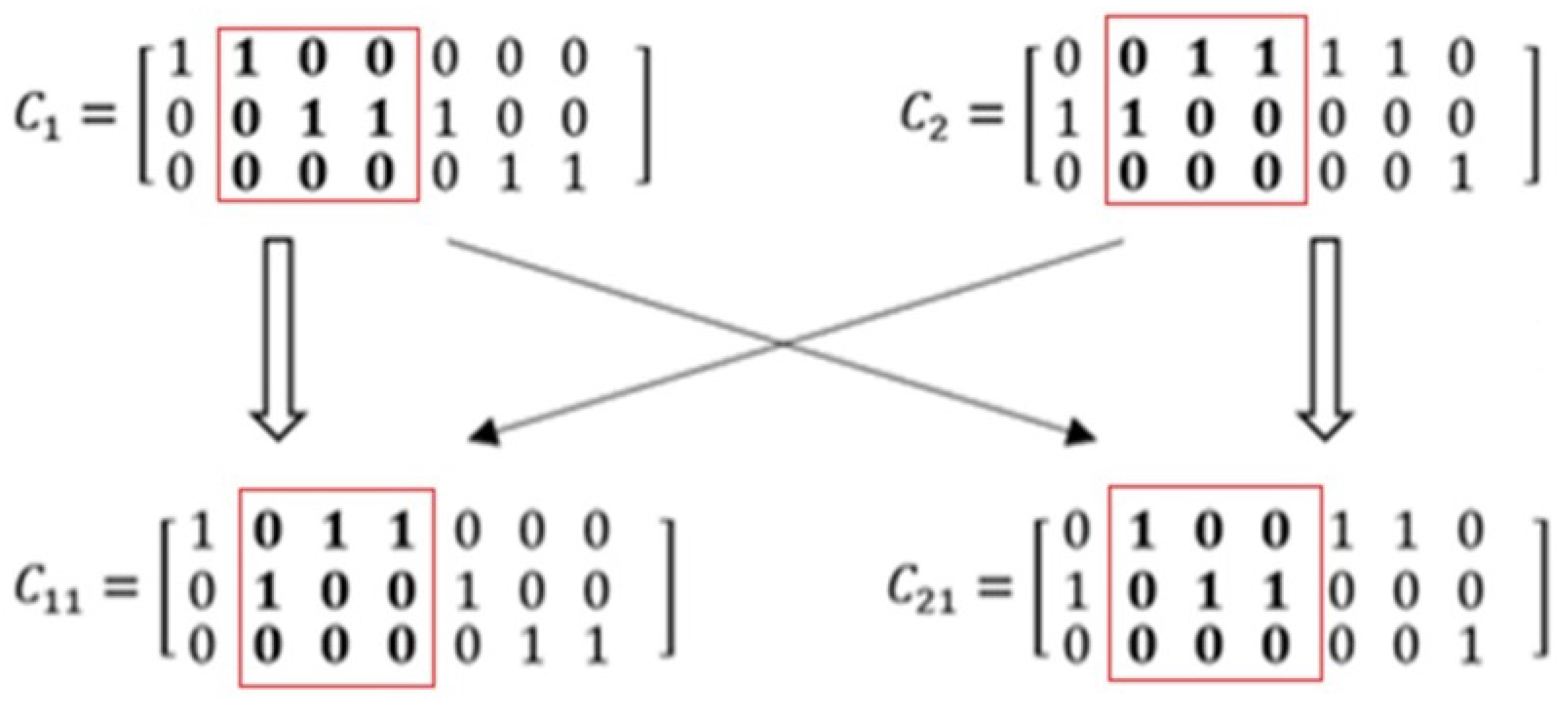
For example, in order to obtain an optimal deployment plan, the chromosome in the GA should be modeled as an
matrix according to the above representation of a deployment plan, such as
and
in
Figure 4.
represents a deployment plan where there are three devices and a seven-layer model. The model is divided into three pieces. Layers
and
are deployed to device
, layers
,
, and
are deployed to device
, and layers
and
are deployed to device
. Similarly,
also shows a deployment plan which divides the model into three pieces.
Figure 4 shows the computing process in a partially mapped crossover operator.
In
Figure 4,
and
are two new individuals generated by swapping the subsections in each father individual included in the rectangles. According to the chromosome coding rules, the model is divided into five parts in the newly generated individuals,
and
. In other words, a five-part partitioning plan is generated by the crossover operation based on two three-part partitioning plans.
Furthermore, such deployment plans will lead to extra network bandwidth and equipment energy consumption caused by repeated transmission between devices. For example, if deploying the inference task according to , the output of will be sent from to , and then the output of will be sent back from to . In turn, the output of will be sent from to again. As a result, the intermediate results need to be transferred four times among the given three devices, twice as many as deployed according to .
4.3. The Proposed Improvement
To ensure the new individuals generated by crossover are still consistent with the corresponding partitioning plans their parents belong to, this work proposes dividing the chromosomes into two classes, i.e., partitioning chromosomes and deployment chromosomes. Based on the representation introduced above, if an L-layers BranchyNet will be partitioned and deployed to N devices, this work adopts the representation of a partitioning plan which is a vector of length as a partitioning chromosome and the representation of a deployment plan which is an matrix as a deployment chromosome.
As illustrated in
Figure 3, there is a one-to-many relationship between the partitioning chromosome and the deployment chromosome. Let us suppose there are
N devices to participate in the collaborative inferencing, and each device will be only assigned one sub-model. Then, the total number of deployment chromosomes related to a given partitioning chromosome is
. Conversely, only one partitioning chromosome can be abstracted from a given deployment chromosome. Based on the relationship between the partitioning and deployment chromosomes, it is easy to build up corresponding conversion algorithms.
Then, this work modifies the process in the basic GA by performing crossover and mutation on partitioning chromosomes and selection on deployment chromosomes. A complete process of the improved GA is shown in Algorithm 1.
| Algorithm 1: The framework of the proposed genetic algorithm |
![Sensors 23 01500 i001]() |
Firstly, Algorithm 1 takes a linearized model to be partitioned and its layer-performance estimation on every candidate device D as input. Moreover, since the algorithm constructs two layers of populations, i.e., the partitioning population and the deployment population, the initial sizes of these two populations need to be set. As shown in the input description, this algorithm takes an input parameter to configure the number of initial individuals in the partitioning population. Then, if there are n devices to participate in the collaborated inferencing, there will be possible deployment individuals. To control the size of the deployment population, the algorithm adopts an additional parameter, , which is a proportion for generating deployment individuals. As a result, the size of the deployment population can reduce to .
Then, the algorithm can be divided into two parts. The first section consists of lines 2 through 9 and is responsible for initializing the algorithm. The second section lines 10 through 20, is the core process of the algorithm. In each iteration of the genetic algorithm, an optimal group of individuals is selected from the current deployment population (line 12), and the corresponding partitioning chromosome is extracted (line 13). The algorithm performs crossover and mutation operations on these partitioning chromosomes and generates a new generation of partitioning chromosomes (line 14). Then, based on the newly generated partitioning population, the existing excellent deployment chromosomes are filtered, and some new deployment chromosomes will be generated at the same time to complete the iteration of the deployment population (line 15). Finally, the current maximum fitness value is calculated on the newly generated deployment population, and the loop is terminated when the termination condition is met (lines 16 to 19).
The time complexity of GA is
, where
T is the maximum iteration times,
N is the population size, and
M is the number of genes in each individual. As we set the maximum iteration time to 200 in our experiments, the time complexity is
. The corresponding codebase is open-source and can be found at
https://github.com/handuoZhang/PGA (accessed on 31 December 2022).
According to the problem formulation described above, the fitness function is defined as follows:
Here,
is the
matrix in Equation (
5), representing a specific deployment plan.
5. Performance Evaluation
This section demonstrates the effects of the proposed algorithm. To provide a comprehensive comparison, this work evaluates the performance of the proposed BranchyNet partitioning approach on the B-AlexNet and B-ResNet proposed in [
1] compared with four other typical DNN partitioning methods. Model training and inferencing are performed on the Cifar-10 dataset [
34], which consists of
color images divided into ten classes. Furthermore, all of the experimental results are collected by running the same algorithm ten times as a group on a laptop with an AMD Ryzen7 5700U CPU and 16 GB memory in a Pycharm environment.
5.1. Experiments on Partitioning B-AlexNet
Firstly, a simulated distributed system with six devices with different configurations is set up, as shown in
Table 1.
As mentioned above, PALEO [
33] is a performance model that can estimate DNN performance under a given deployment assumption. Therefore, this experiment employs PALEO to evaluate the memory requirements and execution time of different DNN layers running on each candidate device in
Table 1 and construct corresponding performance description
D in Algorithm 1.
Based on the number of devices to join into an inference, the initial partitioning and deployment chromosome population size are set as follows in
Table 2:
The other parameter values in Algorithm 1 are set as follows. In both the basic GA and the improved GA, the crossover probability is , the mutation probability is , the maximum iteration number is 200, and the algorithm will be terminated when the optimal fitness value remains unchanged for 50 consecutive generations. In the basic GA, the chromosomes are modeled as deployment chromosomes.
To compare the resulting total execution time generated by different algorithms, this work considers two scenarios according to whether the partitioning and deploying are considered simultaneously.
5.1.1. Total Execution Time Comparison under Considering Partitioning and Deploying Separately
Considering partitioning and deploying separately means that the partitioning plan and deployment plan are generated one after another. In other words, the optimization is divided into two steps, i.e., first, to generate an optimal partitioning plan and then generate an accordingly optimal deployment plan. Specifically, the following experiment compares the proposed algorithm with generating the optimal deployment plan based on exhaustive searching after partitioning the B-AlexNet by the algorithms proposed in [
18,
19] and partitioning the B-AlexNet on one of the two fork points.
Here, the network structure and performance settings in implementing the Neurosurgeon DNN segmentation algorithm [
18] are the same as in the proposed GA introduced above. Moreover, the current data center load level is set to 0. Moreover, the local processing time, edge processing time, and output transmission time of each DNN layer in the shortest-path-based approach [
19] are also calculated by PALEO, and the corresponding SDAG in this approach is constructed according to the method in [
19]. The settings in other experiments are the same as those in this experiment, which will not be described below.
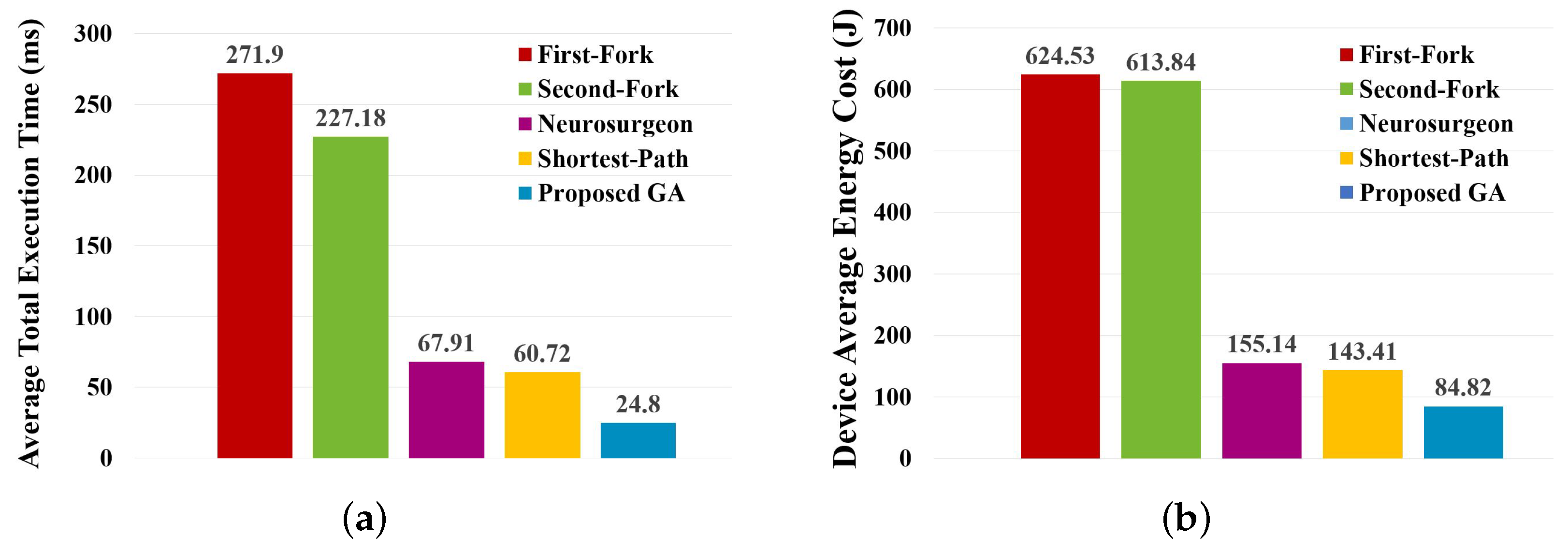
Figure 5 shows the average total execution time and device-average energy cost.
The above results show that the proposed GA results in a shorter average total execution time and lower device-average energy cost than other approaches. The reason is that the improved GA tries to find the best partitioning plan based on the corresponding performance when actually deploying to a given environment. A more detailed comparison of total execution time is shown in
Table 3.
As shown in
Table 3, the average total execution time resulting from the proposed algorithm is shorter than other approaches. Moreover, the standard deviation is almost 0, which indicates that the proposed algorithm is also more stable.
5.1.2. Total Execution Time Comparison When Considering Partitioning and Deploying Simultaneously
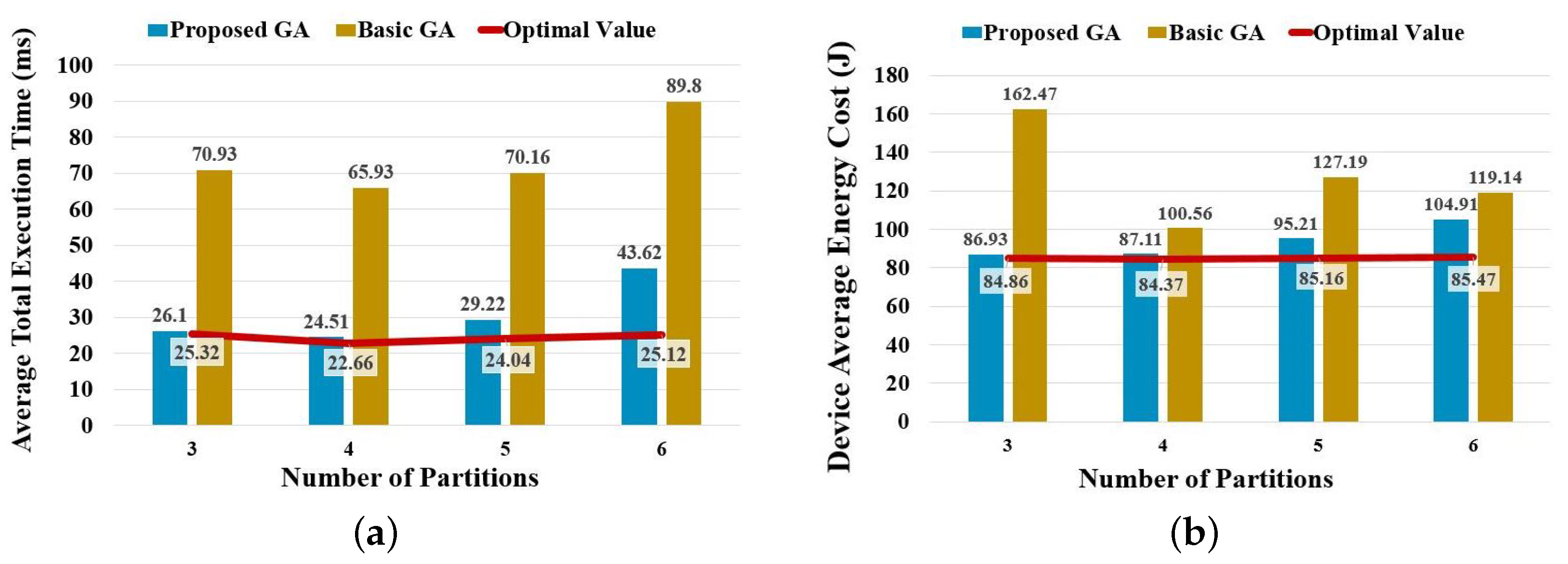
As a GA is an approximate algorithm, it cannot ensure obtaining the absolute optimal solution. This experiment adopts an exhaustive method that can provide the optimal total execution time and energy cost in any given setting as the baseline and then compares the corresponding results by running the basic and improved GA. The following figure shows the average total execution time and device-average energy cost by dividing the B-AlexNet into different pieces from three to six.
As shown in
Figure 6, both the average total execution time and the device-average energy cost of the proposed GA are close to the absolute optimal value, which is visibly superior to a basic GA. Compared with the absolute optimal value, the proposed algorithm has a difference of about
,
,
, and
in average total execution, and a difference of about
,
,
, and
in the device-average energy cost, respectively. A more detailed comparison of the total execution time is shown in
Table 4.
Here, the maximum and minimum values of total execution time obtained from the actual experiment show the variation range of all resulting total execution times. The average and median values reflect the most common values of all resulting total execution time, and the standard deviation indicates their volatility. From the above statistical results, it can be seen that the gap between the improved GA and the optimal value increases with the complexity of the problem. When deploying an L-layers BranchyNet to N devices, the total number of possible deployment plans is , i.e., . For example, in this experiment, when the number of partitions reaches 6, there are , i.e., 720, possible deployment plans for each partitioning plan. If each partition contains at least one convolutional layer, there are , i.e., 28, possible partitioning plans. As a result, the number of possible deployment plans reaches , i.e., 20,160. This is why there is a sudden decrease in algorithm stability. However, compared with the basic GA, the proposed GA achieves a shorter total execution time which is less than half of that of the basic GA.
Moreover, this work compares the average computation time for generating a deployment plan by exhaustive searching, basic GA, and the proposed GA.
Table 5 shows the results. As mentioned above, the primary and improved GA will stop when an optimal fitness value remains unchanged for 50 consecutive generations or they reach the maximum iteration number of 200 in the experiment setting. Moreover, all the algorithms are executed ten times, and the average value is calculated and compared in the following table.
In
Table 5, the rightmost column shows the execution time of the exhaustive searching compared to the proposed GA, which increases with the number of partitions rapidly. When the number of partitions is relatively small, the basic GA and proposed GA take more time to satisfy the terminal condition, which is longer than the time needed by exhaustive searching. However, as the number of partitions increases, the execution time required by the exhaustive method increases explosively, which is significantly higher than that of both GAs.
5.2. Experiments on Partitioning B-ResNet
Similar to the experiments above, the experiments setting and results on partitioning B-ResNet are as follows.
As the number of layers in a B-ResNet is much larger than in a B-AlexNet, this experiment constructs a simulated distributed system with only four different devices.
Table 6 shows the device configurations, and
Table 7 shows the initial population size. Other parameter settings are the same as those in the experiments on B-AlexNet.
In the scenario that considers partitioning and deploying separately, this experiment also compares the proposed GA with the approaches partitioning the given B-ResNet in two parts and then selecting an optimal deployment plan.
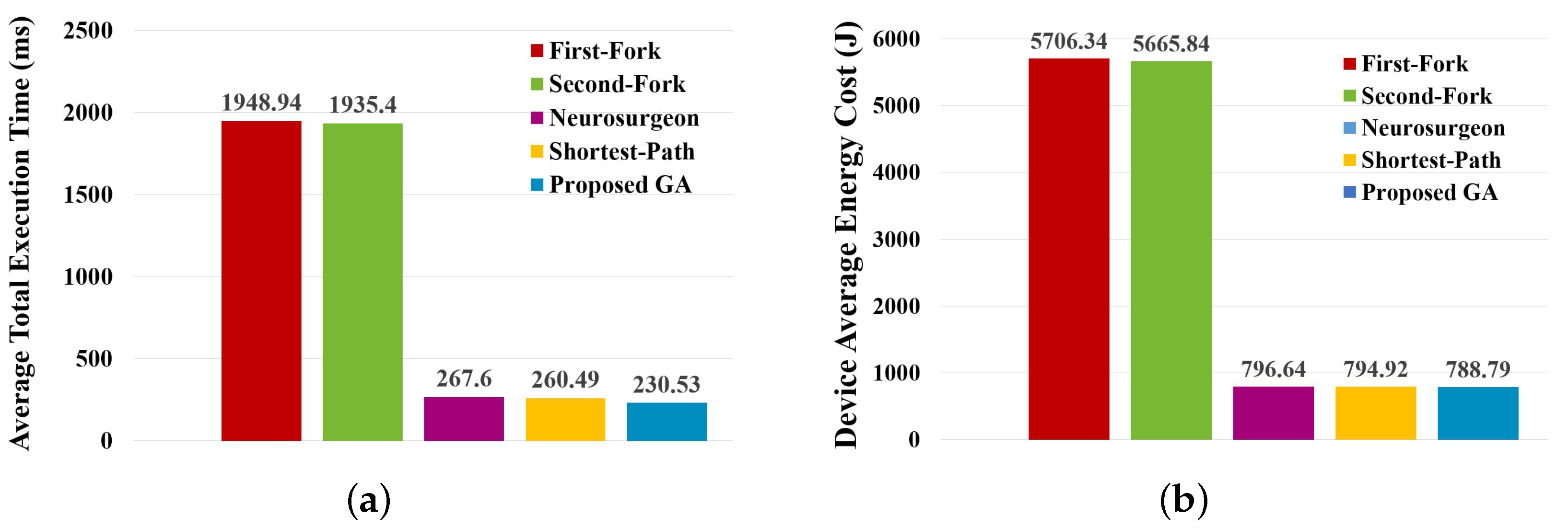
Figure 7 shows the comparisons of optimal average total execution time and device-average energy cost calculated by each method. Moreover,
Table 8 shows the comparison of statistical results of the resulting total execution time.
From the above results, it can be found that the proposed GA also has the best stability from the other methods and can result in a shorter total execution time. However, the base model of B-ResNet is ResNet-110 [
1], which has 109 convolutional layers and 1 fully-connected layer. Only adding two branches that totally have 5 convolutional layers and 2 fully-connected layers increases less than
computation, which has little impact on the overall execution time and energy cost. This is the reason why the proposed GA in this experiment is not as effective as the previous experiment.
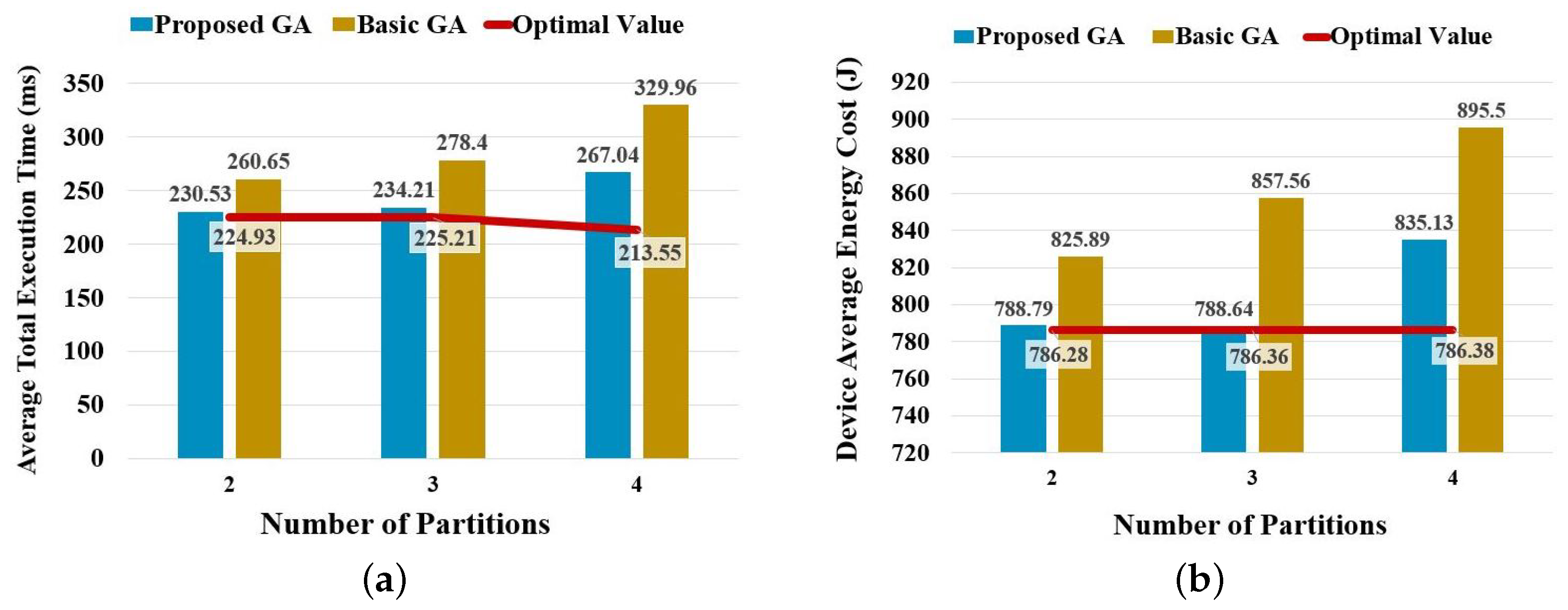
In the scenario that considers partitioning and deploying simultaneously, this experiment also compares the average total execution time and device-average energy cost of the proposed GA with the optimal value and that of the basic GA, which is shown in
Figure 8. Moreover, the statistical results of the resulting average total execution time are compared in
Table 9.
Similar to the corresponding results in experiments on B-AlexNet, the proposed GA also presents higher stability than the basic GA. However, as the number of possible deployment plans increases dramatically in partitioning a B-ResNet, the differences between the results of the proposed GA and the optimal value achieved by exhaustive searching turn out to be larger than that of partitioning B-AlexNet. However, the algorithm can be fine-tuned to achieve a better result by adjusting its maximum number of iterations and terminal condition.
At last,
Table 10 shows the comparison on execution time by running different algorithms.
The rightmost column in
Table 10 shows how many times the execution time of the exhaustive searching compared to the proposed GA, which increases with the number of partitions rapidly. Similar to the conclusion in partitioning B-AlexNet, as the number of partitions increases, the execution time required by the exhaustive method increases explosively, which is significantly higher than that of the two GAs, and the proposed GA shows its advantage in applying it for performing online partitioning.
6. Conclusions
This paper proposes a GA-based BranchyNet partitioning approach for accelerating edge inference. Considering the structural particularity of BranchyNet, this paper puts forward a weighted-average calculation approach for estimating the BranchyNet total execution time. Moreover, it proposes a two-layer chromosome GA by distinguishing partition and deployment during the evolution of a GA. In detail, there are two evolution levels in the proposed GA. On one side, crossover and mutation perform on partitioning chromosomes, ensuring the top-down consistency between the partitioning population and deployment population. On the other side, selection performs on the deployment chromosomes, which further drives the evolution of the partitioning population by ensuring down–top consistency.
In order to show the effects of the proposed approach, this work conducts a group of comprehensive experiments on both B-AlexNet and B-ResNet. The experiment results show that the proposed algorithm can not only result in shorter inferencing time and lower device average energy cost but also requires less time to obtain an optimal deployment plan. Such short running time of the proposed algorithm enables it to generate an optimal deployment plan online to satisfy the actual requirements in deploying an intelligent application dynamically. To further improve this work, the approach for finding the best settings of the algorithm parameters needs to be further studied to obtain better operation effects.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}