
A Machine Learning-Based Applied Prediction Model for Identification of Acute Coronary Syndrome (ACS) Outcomes and Mortality in Patients during the Hospital Stay
Abstract
:1. Introduction
1.1. Research Motivation
1.2. Research Objectives
- The machine learning-based prediction model is proposed for identification of acute coronary syndrome (ACS) outcomes and mortality in patients during the hospital stay.
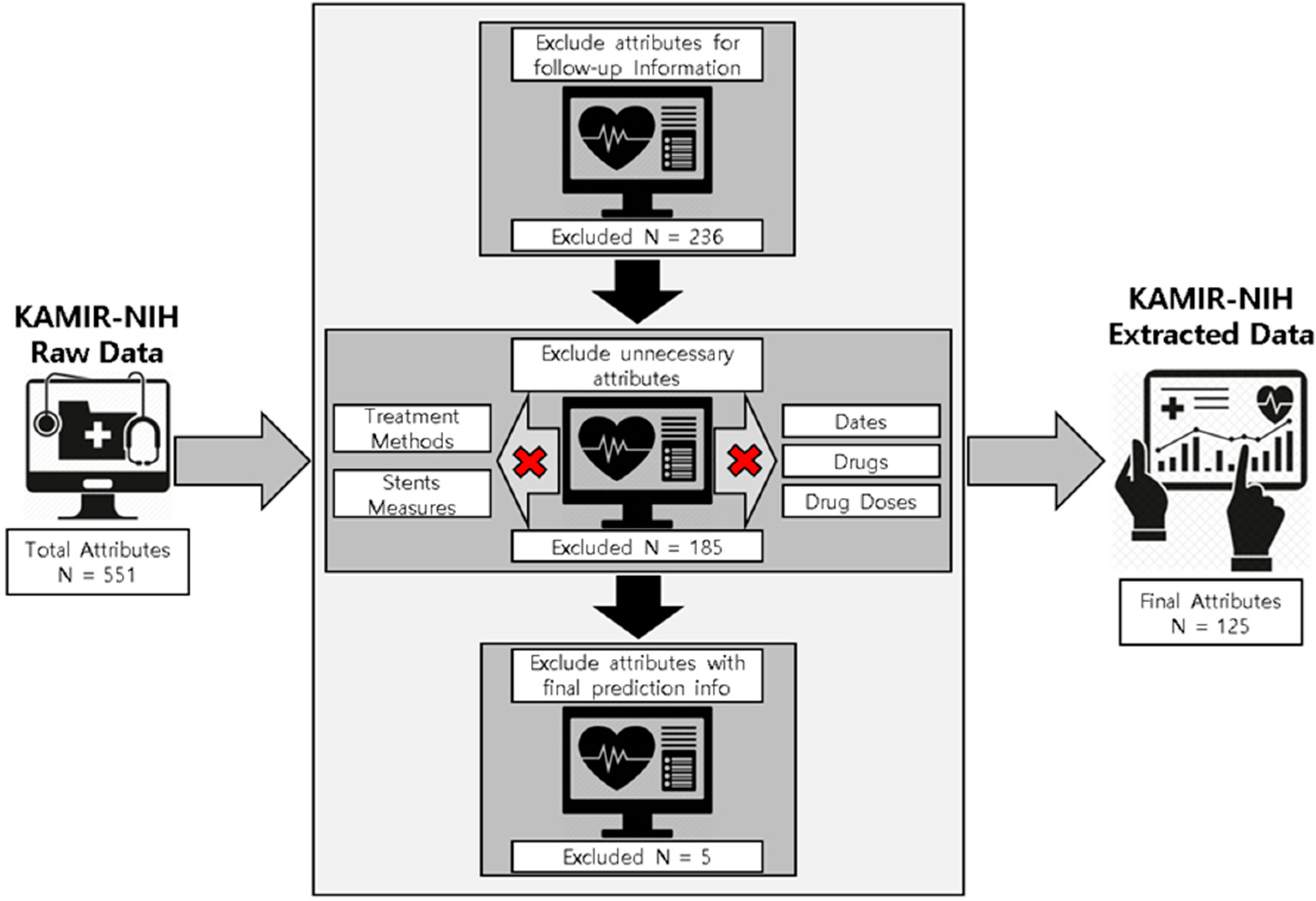
- For the proposed prediction model, the experimental dataset is preprocessed by applying multiple preprocessing, data cleaning, experimental data extraction, and data sampling methods, resulting in 13,104 patients’ records containing 125 important and useful attributes such as basic medical information, past medical history, family medical history, information about medical diagnosis tools, medical findings, PCI information, and initial diagnosis records, and so forth as the final experimental dataset.
- To deal with the data imbalance issue, we applied the SMOTETomek hybrid sampling technique to overcome the imbalanced class distribution in the experimental dataset.
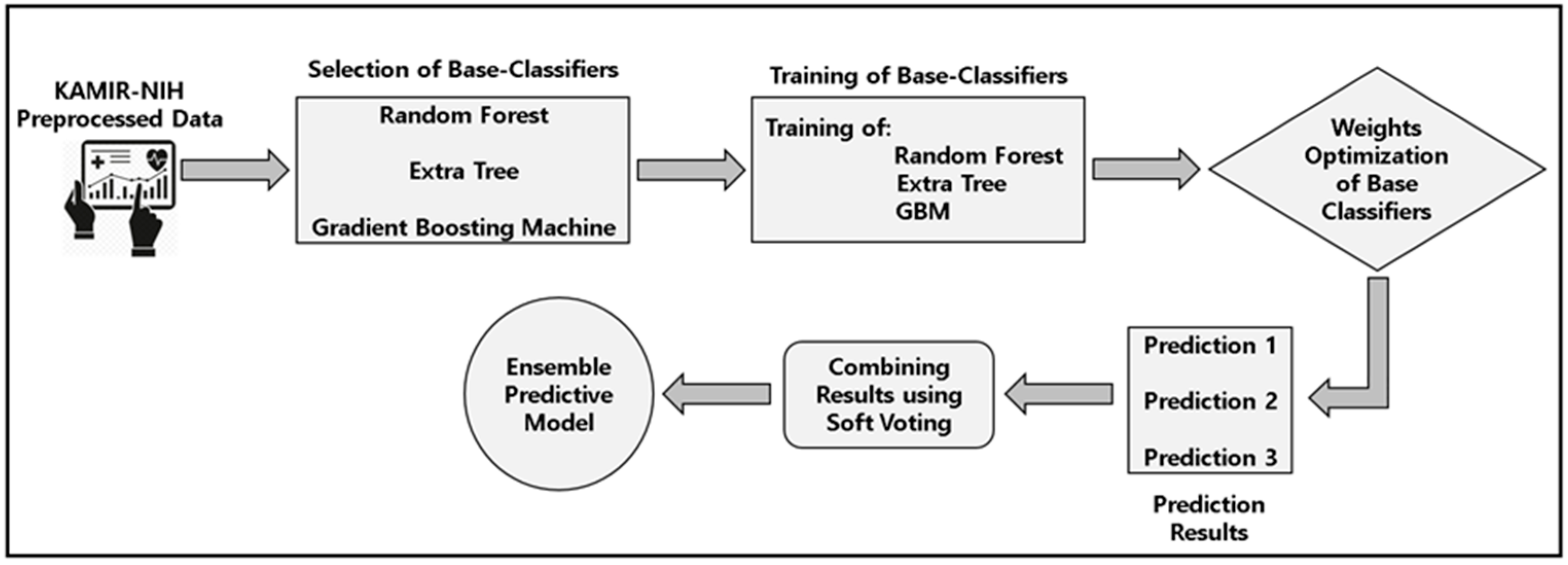
- For the experimental analysis, we applied the various machine learning algorithms and finalized the top three algorithms, such as the random forest, extra tree, and gradient boosting machine, and proposed the soft-voting ensemble classifier using these three algorithms as base classifiers for predictive modeling using the training dataset and then evaluated the performance of applied models using 5-fold cross-validation. After that, we applied the test data for the testing of the proposed predictive model and other machine learning models.
- For analyses of our experimental dataset, we applied various statistical methods such as the Chi-Square test and Analysis of Variance (ANOVA) test.
- For the evaluation of the proposed soft-voting ensemble classifier and other machine learning algorithms, we applied performance measures such as the AUC, precision, recall, F1-score, accuracy, and confusion matrices.
- From the experimental results and performance of the proposed predictive model, we conclude that the proposed model outperformed other models and is effective for timely identification of the ACS, as well as helpful for physicians and patients to identify future cardiac events and select the proper treatment for the patients so that the mortality ratio can be reduced in patients with ACS.
2. Materials and Methods
2.1. Data Source
2.2. Data Extraction and Data Preprocessing
2.3. Data Sampling
2.4. Architecture of Proposed Predictive Modeling System
2.5. Applied Machine Learning Algorithms
2.5.1. Random Forest
2.5.2. Extra Tree
2.5.3. Gradient Boosting Machine
2.6. Design of a Machine Learning-Based Soft-Voting Ensemble Classifier for Predictive Modeling
2.7. Statistical Analysis
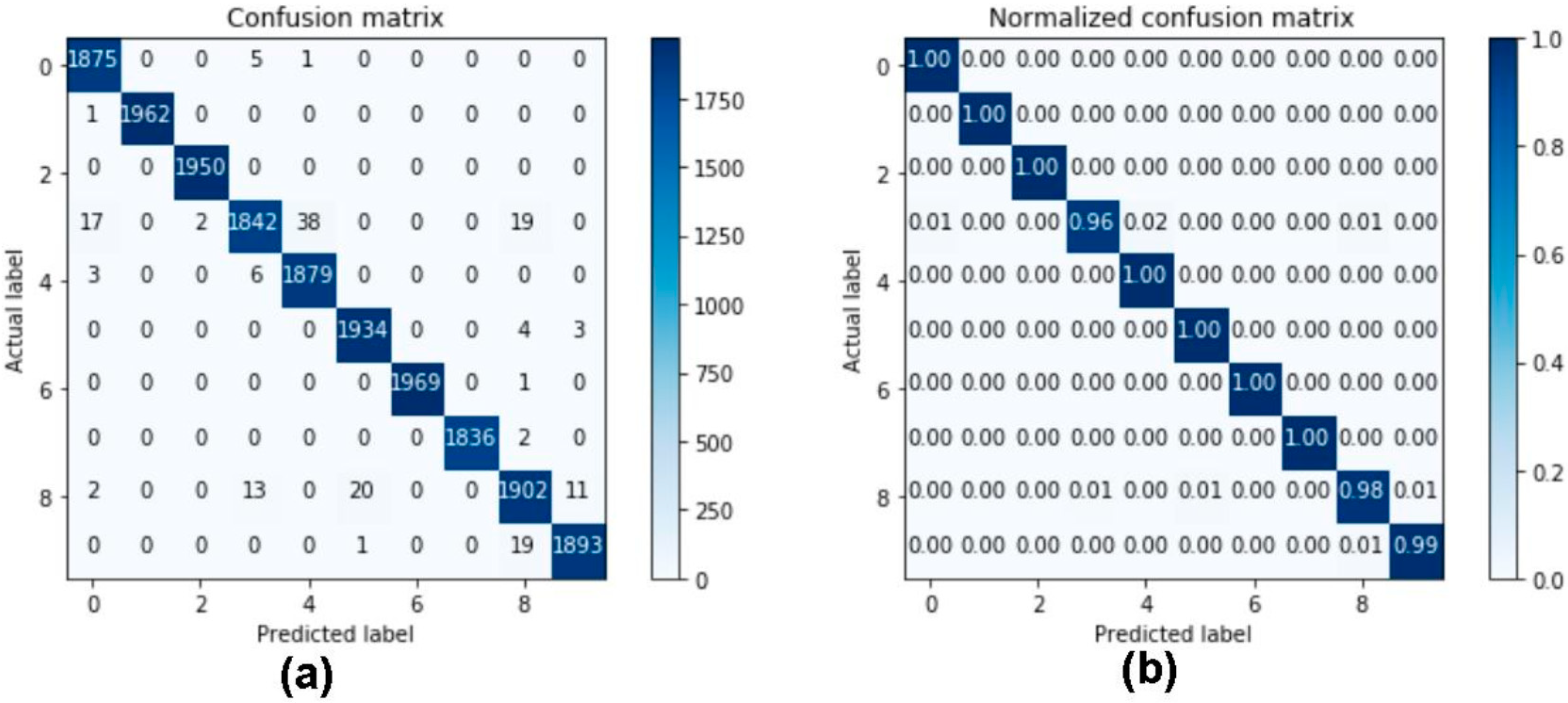
2.8. Evaluation Method and Performance Measures
2.9. Implementation Environments
3. Results
3.1. Baseline Characteristics
3.2. Results of Performance Measures for Applied Machine Learning-Based Predictive Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Descriptive Statistics | ||||
|---|---|---|---|---|---|
| Value | All (N = 13,104) | STEMI (N = 6325) | NSTEMI (N = 6779) | p Value | |
| Sex | Male | 73.92 (9686) | 77.71 (4915) | 70.38 (4771) | <0.001 ** |
| Female | 26.08 (3418) | 22.29 (1410) | 29.62 (2008) | ||
| Age | 63.96925 ± 12.64313 | 62.745 ± 12.8054 | 65.112 ± 12.3820 | <0.001 ** | |
| Chest Pain | Typical | 86.19 (11,294) | 90.85 (5746) | 81.84 (5548) | <0.001 ** |
| Dyspnea | Yes | 23.70 (3105) | 20.41 (1291) | 26.76 (1814) | <0.001 ** |
| Prev. Chest Pain | Yes | 25.57 (3351) | 21.53 (1362) | 29.34 (1989) | <0.001 ** |
| First Medical Center | This Hosp | 32.36 (4240) | 28.16 (1781) | 36.27 (2459) | <0.001 ** |
| SBP | 130.1542 ± 30.0512 | 125.45 ± 31.529 | 134.54 ± 27.903 | <0.001 ** | |
| DBP | 78.64339 ± 18.34411 | 76.62 ± 19.870 | 80.53 ± 16.580 | <0.001 ** | |
| Heart Rate | 78.6606 ± 19.59055 | 77.11 ± 20.545 | 80.11 ± 18.542 | <0.001 ** | |
| Killip Class | III–IV | 13.35 (1750) | 15.68 (992) | 11.18 (758) | <0.001 ** |
| Height | 164.2221 ± 11.22179 | 164.950 ± 12.1186 | 163.548 ± 10.2780 | <0.001 ** | |
| Weight | 65.28827 ± 12.1705 | 66.161 ± 12.0610 | 64.481 ± 12.2165 | <0.001 ** | |
| AC | 87.61039 ± 8.863507 | 87.786 ± 8.8728 | 87.475 ± 8.8557 | 0.244 | |
| ECG | Yes | 99.78 (13,075) | 99.86 (6316) | 99.70 (6759) | 0.145 |
| Past Medical History | Yes | 72.65 (9520) | 69.06 (4368) | 76.00 (5152) | <0.001 ** |
| HTN | Yes | 51.05 (6690) | 46.97 (2971) | 54.86 (3719) | <0.001 ** |
| DM | Yes | 28.63 (3752) | 25.03 (1583) | 32.00 (2169) | <0.001 ** |
| DL | Yes | 11.25 (1474) | 10.59 (670) | 11.86 (804) | <0.001 ** |
| Prev. MI | Yes | 7.85 (1029) | 5.98 (378) | 9.60 (651) | <0.001** |
| Prev. Angina | Yes | 9.76 (1279) | 6.48 (410) | 12.82 (869) | <0.001 ** |
| Prev. Heart Failure | Yes | 1.63 (213) | 0.89 (56) | 2.32 (157) | <0.001 ** |
| Prev. CVA | Infarction | 5.10 (668) | 4.05 (256) | 6.08 (412) | <0.001 ** |
| Smoking | Current | 39.02 (5113) | 44.08 (2788) | 34.30 (2325) | <0.001 ** |
| Family History | Yes | 6.33 (830) | 6.02 (381) | 6.62 (449) | 0.194 |
| F_H_o_E_A_I_H_D | Yes | 0.76 (100) | 0.74 (47) | 0.78 (53) | 0.361 |
| Menopause | Yes | 8.04 (1054) | 7.11 (450) | 8.91 (604) | <0.001 ** |
| Age of Menopause | 48.20648 ± 7.616432 | 47.93 ± 7.755 | 48.43 ± 7.523 | 0.605 | |
| Hysterectomy History | Yes | 0.67 (88) | 0.46 (29) | 0.87 (59) | <0.001 ** |
| HRT | Yes | 0.06 (8) | 0.16 (10) | 0.27 (18) | <0.05 * |
| MI Symptoms | Yes | 97.88 (12,826) | 98.50 (6230) | 97.30 (6596) | <0.001 ** |
| MI ECG | Yes | 68.16 (8932) | 94.25 (5961) | 43.83 (2971) | <0.001 ** |
| MI Imaging | Yes | 28.06 (3677) | 14.89 (942) | 40.35 (2735) | <0.001 ** |
| WBC | 10.50721 ± 4.552223 | 11.529 ± 4.1662 | 9.553 ± 4.6885 | <0.001 ** | |
| Neutrophil | 66.48509 ± 15.18227 | 66.324 ± 16.2682 | 66.635 ± 14.0928 | 0.242 | |
| Lymphocyte | 24.63949 ± 13.05661 | 25.337 ± 14.3136 | 23.989 ± 11.7264 | <0.001 ** | |
| Hemoglobin | 13.76865 ± 2.142532 | 14.127 ± 2.0190 | 13.435 ± 2.1999 | <0.001 ** | |
| Platelets | 232.3399 ± 67.78979 | 235.89 ± 67.208 | 229.02 ± 68.166 | <0.001 ** | |
| Glucose | 169.9549 ± 82.53465 | 179.21 ± 82.991 | 161.40 ± 81.184 | <0.001 ** | |
| Creatinine | 1.134202 ± 1.2009 | 1.047 ± 0.8031 | 1.215 ± 1.4741 | <0.001 ** | |
| Max. Creatine Kinase | 1019.191 ± 1955.354 | 1429.309 ± 2370.662 | 625.581 ± 1335.430 | <0.001 ** | |
| Creatine Kinase MB | 110.5776 ± 164.4305 | 166.2745 ± 189.54721 | 58.4153 ± 114.40263 | <0.001 ** | |
| Troponin I | 46.83087 ± 105.5838 | 75.4137 ± 138.28379 | 21.8091 ± 53.17410 | <0.001 ** | |
| Troponin T | 14.21992 ± 459.5798 | 4.8386 ± 12.85030 | 26.5103 ± 698.40787 | 0.306 | |
| Total Cholesterol | 177.8673 ± 46.35988 | 180.84 ± 46.078 | 175.08 ± 46.454 | <0.001 ** | |
| Triglyceride | 134.5005 ± 120.0775 | 140.29 ± 125.358 | 128.98 ± 114.547 | <0.001 ** | |
| HDL | 42.83839 ± 12.51687 | 42.61 ± 12.289 | 43.05 ± 12.727 | 0.053 | |
| LDL | 111.849 ± 40.58414 | 114.11 ± 40.616 | 109.72 ± 40.442 | <0.001 ** | |
| hsCRP | 1.554095 ± 6.201701 | 1.3933 ± 4.38070 | 1.7238 ± 7.66500 | <0.05 * | |
| NTproBNP | 2795.943 ± 9980.085 | 1872.666 ± 9574.2647 | 3695.017 ± 10281.7662 | <0.001 ** | |
| BNP | 319.4587 ± 741.2533 | 222.417 ± 533.8414 | 431.961 ± 912.7885 | <0.001 ** | |
| HbA1c | 6.486941 ± 1.482016 | 6.469 ± 1.5192 | 6.505 ± 1.4450 | 0.262 | |
| ARU | 460.0607 ± 73.9739 | 457.53 ± 75.363 | 462.30 ± 72.673 | 0.090 | |
| PRU | 199.4301 ± 109.9491 | 181.66 ± 108.618 | 217.63 ± 108.344 | <0.001 ** | |
| PCI | Performed | 89.55 (11,735) | 96.63 (6112) | 82.95 (5623) | <0.001 ** |
| Why not PCI | PCI not Indicated | 6.34 (831) | 1.91 (121) | 10.47 (710) | <0.001 ** |
| Puncture Route | Trnasfemoral | 55.21 (7235) | 71.38 (4515) | 40.12 (2720) | <0.001 ** |
| PCI Reason | pPCI in STEMI | 44.44 (5824) | 91.81 (5807) | 0.25 (17) | <0.001 ** |
| Distal Protection | No use | 66.82 (8756) | 61.01 (3859) | 72.24 (4897) | <0.001 ** |
| PCI Performed | Perform | 89.70 (11,754) | 96.76 (6120) | 83.11 (5634) | <0.001 ** |
| Target Vessel | LAD | 41.79 (5476) | 49.39 (3124) | 34.70 (2352) | <0.001 ** |
| Lesion Type | Type C | 44.36 (5813) | 52.17 (3300) | 37.07 (2513) | <0.001 ** |
| preTIMI | |||||
| TIMI 0 | 42.11 (5518) | 61.75 (3906) | 23.78 (1612) | <0.001 ** | |
| TIMI I | 9.81 (1286) | 10.29 (651) | 9.37 (635) | <0.001 ** | |
| TIMI II | 13.84 (1813) | 10.34 (654) | 17.10 (1159) | <0.001 ** | |
| TIMI III | 23.94 (3137) | 14.37 (909) | 13.41 (909) | <0.001 ** | |
| PCI Treatment | Stent | 83.00 (10,876) | 90.61 (5731) | 75.90 (5145) | <0.001 ** |
| PostTIMI | |||||
| TIMI 0 | 0.37 (49) | 0.43 (27) | 0.32 (22) | <0.001 ** | |
| TIMI I | 0.43 (57) | 0.62 (39) | 0.27 (18) | <0.001 ** | |
| TIMI II | 2.43 (319) | 3.49 (221) | 1.45 (98) | <0.001 ** | |
| TIMI III | 86.45 (11,329) | 92.22 (5833) | 81.07 (5496) | <0.001 ** | |
| PCI 2 | Perform | 89.61 (11,742) | 96.63 (6112) | 83.05 (5630) | <0.001 ** |
| PCI Left Main | Yes | 4.38 (574) | 3.49 (221) | 5.21(353) | <0.001 ** |
| PCI LM Treatment | Stent | 2.86 (375) | 2.15 (136) | 3.53 (239) | <0.001 ** |
| Stents in LM | 1–3 | 2.86 (375) | 2.15 (136) | 3.53 (239) | <0.001 ** |
| PCI LAD | Yes | 62.66 (8211) | 69.23 (4379) | 56.53 (3832) | <0.001 ** |
| PCI LAD Treatment | Stent | 47.86 (6272) | 54.04 (3418) | 42.10 (2854) | <0.001 ** |
| Stents in LAD | 1–4 | 48.56 (6363) | 54.48 (3446) | 43.03 (2917) | <0.001 ** |
| PCI LCX | Yes | 39.71 (5203) | 34.47 (2180) | 44.59 (3023) | <0.001 ** |
| PCI LCX Treatment | Stent | 20.86 (2733) | 14.09 (891) | 27.17 (1842) | <0.001 ** |
| Stents in LCX | 1–4 | 20.98 (2749) | 14.17 (896) | 27.33 (1853) | <0.001 ** |
| PCI RCA | Yes | 47.86 (6272) | 53.09 (3358) | 42.99 (2914) | <0.001 ** |
| PCI RCA Treatment | Stent | 33.33 (4368) | 38.53 (2437) | 28.49 (1931) | <0.001 ** |
| Stents in RCA | 1–4 | 33.34 (4369) | 38.55 (2438) | 28.49 (1931) | <0.001 ** |
| PCI Result | Successful | 88.37 (11,580) | 95.07 (6013) | 82.12 (5567) | <0.001 ** |
| Revascularization Status | Total | 61.53 (8063) | 66.21 (4188) | 57.16 (3875) | <0.001 ** |
| Index PCI | multivessel | 17.10 (2241) | 12.32 (779) | 21.57 (1462) | <0.001 ** |
| Staged PCI | Stepwise PCI | 8.44 (1106) | 11.18 (707) | 5.89 (399) | <0.001 ** |
| QCA | Performed | 80.17 (10,506) | 77.57 (4906) | 82.61 (5600) | <0.001 ** |
| Initial Diagnosis | |||||
| STEMI | 48.08 (6300) | 98.78 (6248) | 0.77 (52) | <0.001 ** | |
| NSTEMI | 51.91 (6802) | 1.20 (76) | 99.22 (6726) | <0.001 ** | |
| STEMI Treatment | pPCI | 46.55 (6100) | 95.72 (6054) | 0.68 (46) | <0.001 ** |
| NSTEMI Treatment | Early Invasive | 43.89 (5752) | 0.98 (62) | 83.94 (5690) | <0.001 ** |
| Thrombolysis | Yes | 1.00 (131) | 2.04 (129) | 0.03 (2) | <0.001 ** |
| CAG | Yes | 98.41 (12895) | 99.37 (6285) | 97.51 (6610) | <0.001 ** |
| 2DE | ECG Perform | 95.18 (12,472) | 94.31 (5965) | 95.99 (6507) | <0.001 ** |
| LVEF | 51.90744 ± 11.23909 | 50.12 ± 10.472 | 53.55 ± 11.660 | <0.001 ** | |
| RWMI | 1.4249 ± 0.388668 | 1.50 ± 0.373 | 1.36 ± 0.390 | <0.001 ** | |
| MR Grade | I–IV | 32.77 (4294) | 29.03 (1836) | 36.26 (2458) | <0.001 ** |
| LVESD | 35.02565 ± 8.382741 | 35.21 ± 8.140 | 34.86 ± 8.593 | <0.05 * | |
| LVEDD | 49.70543 ± 6.636215 | 49.56 ± 6.423 | 49.84 ± 6.821 | <0.05 * | |
| LVESV | 47.65738 ± 25.2402 | 48.35 ± 23.112 | 46.94 ± 27.238 | <0.05 * | |
| LVEDV | 95.02556 ± 42.32248 | 95.27 ± 47.419 | 94.77 ± 36.358 | 0.627 | |
| Hosp. Complications | Yes | 20.70 (2712) | 25.61 (1620) | 16.11 (1092) | <0.001 ** |
| Cardiogenic Shock | Yes | 9.00 (1180) | 13.01 (823) | 5.27 (357) | <0.001 ** |
| New Heart Failure | Yes | 4.49 (588) | 4.22 (267) | 4.74 (321) | <0.001 ** |
| Recurrent Ischemia | Yes | 0.89 (117) | 1.09 (69) | 0.71 (48) | <0.001 ** |
| Reinfarction | Yes | 0.37 (49) | 0.57 (36) | 0.19 (13) | <0.001 ** |
| ST | Yes | 0.33 (43) | 0.52 (33) | 0.15 (10) | <0.05 * |
| ST Type | Acute ST | 0.18 (23) | 0.27 (17) | 0.09 (6) | <0.05 * |
| Cerebral Infarction | Yes | 0.64 (84) | 0.55 (35) | 0.72 (49) | <0.001 ** |
| Cerebral hrr | Yes | 0.11 (15) | 0.16 (10) | 0.07 (5) | <0.001 ** |
| ICH | Yes | 0.11 (15) | 0.16 (10) | 0.07 (5) | <0.001 ** |
| Hb decrease 5 | Yes | 1.15 (151) | 1.23 (78) | 1.08 (73) | <0.001 ** |
| Hb decrease 15 | Yes | 1.24 (162) | 1.44 (91) | 1.05 (71) | <0.001 ** |
| Minor Bleeding | Yes | 3.08 (403) | 3.19 (202) | 2.97 (201) | <0.001 ** |
| Atrioventricular Block | Yes | 2.31 (303) | 3.79 (240) | 0.93 (63) | <0.001 ** |
| VT Drug | Yes | 1.30 (171) | 1.96 (124) | 0.69 (47) | <0.001 ** |
| VT DC | Yes | 2.68 (351) | 4.27 (270) | 1.19 (81) | <0.001 ** |
| VF | Yes | 1.95 (255) | 3.10 (196) | 0.87 (59) | <0.001 ** |
| AF | Yes | 3.41 (447) | 3.81 (241) | 3.04 (206) | <0.001 ** |
| AKI | Yes | 0.98 (129) | 1.00 (63) | 0.97 (66) | <0.001 ** |
| Sepsis | Yes | 0.60 (78) | 0.58 (37) | 0.60 (41) | <0.001 ** |
| MOF | Yes | 0.72 (94) | 0.89 (56) | 0.56 (38) | <0.001 ** |
| TPM | Yes | 4.04 (529) | 6.67 (422) | 1.58 (107) | <0.001 ** |
| CPR | Yes | 6.97 (914) | 8.93 (565) | 5.15 (349) | <0.001 ** |
| IABP | Yes | 3.24 (424) | 5.00 (316) | 1.59 (108) | <0.001 ** |
| ECMO | Yes | 1.13 (148) | 1.72 (109) | 0.58 (39) | <0.001 ** |
| Defibrillation | Yes | 4.17 (546) | 6.45 (408) | 2.04 (138) | <0.001** |
| PPM | Yes | 0.12 (16) | 0.13 (8) | 0.12 (8) | <0.001 ** |
| ICD | Yes | 0.12 (16) | 0.09 (6) | 0.15 (10) | <0.001 ** |
| CABG | Yes | 1.40 (184) | 0.57 (36) | 2.18 (148) | <0.001 ** |
References
- Bhardwaj, R.; Nambiar, A.R.; Dutta, D. A study of machine learning in healthcare. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Turin, Italy, 4–8 July 2017; Volume 2, pp. 236–241. [Google Scholar]
- Jafar, A.; Hameed, M.T.; Akram, N.; Waqas, U.; Kim, H.S.; Naqvi, R.A. CardioNet: Automatic Semantic Segmentation to Calculate the Cardiothoracic Ratio for Cardiomegaly and Other Chest Diseases. J. Pers. Med. 2022, 12, 988. [Google Scholar] [CrossRef] [PubMed]
- Vollmer, S.; Mateen, B.A.; Bohner, G.; Király, F.J.; Ghani, R.; Jonsson, P.; Cumbers, S.; Jonas, A.; McAllister, K.S.; Myles, P.; et al. Machine learning and artificial intelligence research for patient benefit: 20 critical questions on transparency, replicability, ethics, and effectiveness. BMJ 2020, 368, 16927. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naqvi, R.A.; Hussain, D.; Loh, W.K. Artificial intelligence-based semantic segmentation of ocular regions for biometrics and healthcare applications. CMC Comput. Mater. Contin. 2021, 66, 715–732. [Google Scholar] [CrossRef]
- Abraham, W.T.; Fonarow, G.C.; Albert, N.M.; Stough, W.G.; Gheorghiade, M.; Greenberg, B.H.; OPTIMIZE-HF Investigators and Coordinators. Predictors of in-hospital mortality in patients hospitalized for heart failure: Insights from the Organized Program to Initiate Lifesaving Treatment in Hospitalized Patients with Heart Failure (OPTIMIZE-HF). J. Am. Coll. Cardiol. 2008, 52, 347–356. [Google Scholar] [CrossRef] [Green Version]
- Sherazi, S.W.A.; Bae, J.W.; Lee, J.Y. A soft voting ensemble classifier for early prediction and diagnosis of occurrences of major adverse cardiovascular events for STEMI and NSTEMI during 2-year follow-up in patients with acute coronary syndrome. PLoS ONE 2021, 16, e0249338. [Google Scholar] [CrossRef]
- Kannel, W.B.; Gordon, T. The Framingham Study: An Epidemiological Investigation of Cardiovascular Disease; US Department of Health, Education, and Welfare, National Institutes of Health: Washington, DC, USA, 1970. [Google Scholar]
- Ferket, B.S.; van Kempen, B.J.; Hunink, M.M.; Agarwal, I.; Kavousi, M.; Franco, O.H.; Steyerberg, E.W.; Max, W.; Fleischmann, K.E. Predictive value of updating Framingham risk scores with novel risk markers in the US general population. PLoS ONE 2014, 9, e88312. [Google Scholar] [CrossRef] [Green Version]
- D’Agostino, R.B., Sr.; Vasan, R.S.; Pencina, M.J.; Wolf, P.A.; Cobain, M.; Massaro, J.M.; Kannel, W.B. General cardiovascular risk profile for use in primary care: The Framingham Heart Study. Circulation 2008, 117, 743–753. [Google Scholar] [CrossRef] [Green Version]
- Brindle, P.; Jonathan, E.; Lampe, F.; Walker, M.; Whincup, P.; Fahey, T.; Ebrahim, S. Predictive accuracy of the Framingham coronary risk score in British men: Prospective cohort study. BMJ 2003, 327, 1267. [Google Scholar] [CrossRef] [Green Version]
- Hippisley-Cox, J.; Coupland, C.; Vinogradova, Y.; Robson, J.; Minhas, R.; Sheikh, A.; Brindle, P. Predicting cardiovascular risk in England and Wales: Prospective derivation and validation of QRISK2. BMJ 2008, 336, 1475–1482. [Google Scholar] [CrossRef] [Green Version]
- Hippisley-Cox, J.; Coupland, C.; Brindle, P. Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: Prospective cohort study. BMJ 2017, 357, j2099. [Google Scholar] [CrossRef]
- Antman, E.M.; Cohen, M.; Bernink, P.J.L.M.; McCabe, C.H.; Horacek, T.; Papuchis, G.; Mautner, B.; Corbalan, R.; Radley, D.; Braunwald, E. The TIMI risk score for unstable angina/nonST elevation MI: A method for prognostication and therapeutic decision making. JAMA 2000, 284, 835–842. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amin, S.T.; Morrow, D.A.; Braunwald, E.; Sloan, S.; Contant, C.; Murphy, S.; Antman, E.M. Dynamic TIMI risk score for STEMI. J. Am. Heart Assoc. 2013, 2, e003269. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elbarouni, B.; Goodman, S.G.; Yan, R.T.; Welsh, R.C.; Kornder, J.M.; DeYoung, J.P.; Wong, G.C.; Rose, B.; Grondin, F.R.; Gallo, R.; et al. Validation of the Global Registry of Acute Coronary Event (GRACE) risk score for in-hospital mortality in patients with acute coronary syndrome in Canada. Am. Heart J. 2009, 158, 392–399. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; FitzGerald, G.; Goldberg, R.J.; Gore, J.; McManus, R.H.; Awad, H.; Waring, M.E.; Allison, J.; Saczynski, J.S.; Kiefe, C.I.; et al. Performance of the GRACE Risk Score 2.0 simplified algorithm for predicting 1-year death after hospitalization for an acute coronary syndrome in a contemporary multiracial cohort. Am. J. Cardiol. 2016, 118, 1105–1110. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Riley, R.F.; Miller, C.D.; Russell, G.B.; Harper, E.N.; Hiestand, B.C.; Hoekstra, J.W.; Lefebvre, C.W.; Nicks, B.A.; Cline, D.M.; Askew, K.L.; et al. Cost analysis of the History, ECG, Age, Risk factors, and initial Troponin (HEART) Pathway randomized control trial. Am. J. Emerg. Med. 2017, 35, 77–81. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhattacharya, P.T.; Golamari, R.R.; Vunnam, S.; Moparthi, S.; Venkatappa, N.; Dollard, D.J.; Missri, J.; Yang, W.; Kimmel, S.E. Predictive risk stratification using HEART (history, electrocardiogram, age, risk factors, and initial troponin) and TIMI (thrombolysis in myocardial infarction) scores in non-high risk chest pain patients: An African American urban community based hospital study. Medicine 2019, 98, e16370. [Google Scholar]
- Poldervaart, J.M.; Langedijk, M.; Backus, B.E.; Dekker, I.M.C.; Six, A.J.; Doevendans, P.A.; Hoes, A.W.; Reitsma, J.B. Comparison of the GRACE, HEART and TIMI score to predict major adverse cardiac events in chest pain patients at the emergency department. Int. J. Cardiol. 2017, 227, 656–661. [Google Scholar] [CrossRef] [Green Version]
- Lakshmanarao, A.; Swathi, Y.; Sundareswar, P.S.S. Machine learning techniques for heart disease prediction. Forest 2019, 95, 97. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Khalilia, M.; Chakraborty, S.; Popescu, M. Predicting disease risks from highly imbalanced data using random forest. BMC Med. Inform. Decis. Mak. 2011, 11, 51. [Google Scholar] [CrossRef] [Green Version]
- Singh, Y.K.; Sinha, N.; Singh, S.K. Heart disease prediction system using random forest. In International Conference on Advances in Computing and Data Sciences; Springer: Singapore, 2016; pp. 613–623. [Google Scholar]
- Shafique, R.; Mehmood, A.; Choi, G.S. Cardiovascular disease prediction system using extra trees classifier. Res. Sq. 2019, 11, 51. [Google Scholar]
- Subha, V.; Revathi, M.; Murugan, D. Comparative analysis of support vector machine ensembles for heart disease prediction. Int. J. Comp. Sci. Comm. Netw. 2015, 5, 386–390. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Statist. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef]
- Jiang, S.; Chin, K.S.; Tsui, K.L. A universal deep learning approach for modeling the flow of patients under different severities. Comput. Methods Programs Biomed. 2018, 154, 191–203. [Google Scholar] [CrossRef] [PubMed]
- Sherazi, S.W.A.; Jeong, Y.J.; Jae, M.H.; Bae, J.-W.; Lee, J.Y. A machine learning– based 1-year mortality prediction model after hospital discharge for clinical patients with acute coronary syndrome. Health Inform. J. 2020, 26, 1289–1304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mokashi, A.R.; Tambe, M.N.; Walke, P.T. Heart disease prediction using ANN and improved KMeans. Int. J. Innov. Res. Elect. Electr. Instrum. Contr. Eng. 2016, 4, 221–224. [Google Scholar]
- Latha, C.B.C.; Jeeva, S.C. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Inform. Med. Unlocked 2019, 16, 100203. [Google Scholar] [CrossRef]
- Goldstein, B.A.; Navar, A.M.; Carter, R.E. Moving beyond regression techniques in cardiovascular risk prediction: Applying machine learning to address analytic challenges. Eur. Heart J. 2017, 38, 1805–1814. [Google Scholar] [CrossRef] [Green Version]
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning-based prediction models in healthcare. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1379. [Google Scholar] [CrossRef]
- Aldahiri, A.; Alrashed, B.; Hussain, W. Trends in Using IoT with Machine Learning in Health Prediction System. Forecasting 2021, 3, 181–206. [Google Scholar] [CrossRef]
- Korea Acute Myocardial Infarction Registry. Available online: http://kamir5.kamir.or.kr/ (accessed on 1 March 2021).
- Peat, J.; Barton, B. Medical Statistics: A Guide to Data Analysis and Critical Appraisal; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Potdar, K.; Pardawala, T.S.; Pai, C.D. A comparative study of categorical variable encoding techniques for neural network classifiers. Int. J. Comput. Appl. 2017, 175, 7–9. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. Survey on categorical data for neural networks. J. Big Data 2020, 7, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Zheng, H.; Sherazi, S.W.A.; Lee, J.Y. A Stacking Ensemble Prediction Model for the Occurrences of Major Adverse Cardiovascular Events in Patients with Acute Coronary Syndrome on Imbalanced Data. IEEE Access 2021, 9, 113692–113704. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from classimbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Wang, Q. A hybrid sampling SVM approach to imbalanced data classification. Abstr. Appl. Anal. 2014, 2014, 972786. [Google Scholar] [CrossRef]
- Batista, G.E.; Bazzan, A.L.; Monard, M.C. Balancing Training Data for Automated Annotation of Keywords: A Case Study. WOB 2003, 10–18. [Google Scholar]
- PASW Statistics. Available online: http://www.spss.com.hk/statistics/ (accessed on 1 March 2021).
- Office 365 ProPlus. Available online: https://products.office.com/en-us/business/office-365-proplus-product (accessed on 1 March 2021).
- Jupyter.org. Project Jupyter. 2019. Available online: http://jupyter.org/ (accessed on 1 March 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Harris, C.R.; Millman, K.J.; Van Der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-Learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]




| Predicted Value (Predicted by the test) | |||
| Actual Value (Confirmed by Experience) | Positives | Negatives | |
| Positives | TP (True Positive) | FN (False Negative) | |
| Negatives | FP (False Positive) | TN (True Negative) | |
| Variable | Descriptive Statistics | ||||
|---|---|---|---|---|---|
| Value | All (N = 13,104) | STEMI (N = 6325) | NSTEMI (N = 6779) | p Value | |
| Sex | Male | 73.92 (9686) | 77.71 (4915) | 70.38 (4771) | <0.001 ** |
| Female | 26.08 (3418) | 22.29 (1410) | 29.62 (2008) | <0.001 ** | |
| Age | Number | 63.96925 ± 12.64313 | 62.745 ± 12.8054 | 65.112 ± 12.3820 | <0.001 ** |
| Chest Pain | Typical | 86.19 (11,294) | 90.85 (5746) | 81.84 (5548) | <0.001 ** |
| Systolic Blood Pressure | Number | 130.1542 ± 30.0512 | 125.45 ± 31.529 | 134.54 ± 27.903 | <0.001 ** |
| Diastolic Blood Pressure | Number | 78.64339 ± 18.34411 | 76.62 ± 19.870 | 80.53 ± 16.580 | <0.001 ** |
| Heart Rate | Number | 78.6606 ± 19.59055 | 77.11 ± 20.545 | 80.11 ± 18.542 | <0.001 ** |
| Killip Class | III–IV | 13.35 (1750) | 15.68 (992) | 11.18 (758) | <0.001 ** |
| Height | Number | 164.2221 ± 11.22179 | 164.950 ± 12.1186 | 163.548 ± 10.2780 | <0.001 ** |
| Weight | Number | 65.28827 ± 12.1705 | 66.161 ± 12.0610 | 64.481 ± 12.2165 | <0.001 ** |
| Prev. MI | Yes | 7.85 (1029) | 5.98 (378) | 9.60 (651) | <0.001 ** |
| Prev. Angina | Yes | 9.76 (1279) | 6.48 (410) | 12.82 (869) | <0.001 ** |
| Prev. Heart Failure | Yes | 1.63 (213) | 0.89 (56) | 2.32 (157) | <0.001 ** |
| Prev. CVA | Infarction | 5.10 (668) | 4.05 (256) | 6.08 (412) | <0.001 ** |
| Smoking | Current | 39.02 (5113) | 44.08 (2788) | 34.30 (2325) | <0.001 ** |
| White Blood Cells | Number | 10.50721 ± 4.552223 | 11.529 ± 4.1662 | 9.553 ± 4.6885 | <0.001 ** |
| Neutrophil | Number | 66.48509 ± 15.18227 | 66.324 ± 16.2682 | 66.635 ± 14.0928 | 0.242 |
| Lymphocyte | Number | 24.63949 ± 13.05661 | 25.337 ± 14.3136 | 23.989 ± 11.7264 | <0.001 ** |
| Hemoglobin | Number | 13.76865 ± 2.142532 | 14.127 ± 2.0190 | 13.435 ± 2.1999 | <0.001 ** |
| Platelets | Number | 232.3399 ± 67.78979 | 235.89 ± 67.208 | 229.02 ± 68.166 | <0.001 ** |
| Glucose | Number | 169.9549 ± 82.53465 | 179.21 ± 82.991 | 161.40 ± 81.184 | <0.001 ** |
| creatinine | Number | 1.134202 ± 1.2009 | 1.047 ± 0.8031 | 1.215 ± 1.4741 | <0.001 ** |
| Max. Creatine Kinase | Number | 1019.191 ± 1955.354 | 1429.309 ± 2370.662 | 625.581 ± 1335.430 | <0.001 ** |
| Creatine Kinase MB | Number | 110.5776 ± 164.4305 | 166.2745 ± 189.54721 | 58.4153 ± 114.40263 | <0.001 ** |
| Troponin I | Number | 46.83087 ± 105.5838 | 75.4137 ± 138.28379 | 21.8091 ± 53.17410 | <0.001 ** |
| Troponin T | Number | 14.21992 ± 459.5798 | 4.8386 ± 12.85030 | 26.5103 ± 698.40787 | 0.306 |
| Total Cholesterol | Number | 177.8673 ± 46.35988 | 180.84 ± 46.078 | 175.08 ± 46.454 | <0.001 ** |
| High Density Lipoprotein | Number | 42.83839 ± 12.51687 | 42.61 ± 12.289 | 43.05 ± 12.727 | 0.053 |
| Low Density Lipoprotein | Number | 111.849 ± 40.58414 | 114.11 ± 40.616 | 109.72 ± 40.442 | <0.001 ** |
| Triglyceride | Number | 134.5005 ± 120.0775 | 140.29 ± 125.358 | 128.98 ± 114.547 | <0.001 ** |
| hsCRP | Number | 1.554095 ± 6.201701 | 1.3933 ± 4.38070 | 1.7238 ± 7.66500 | <0.05 * |
| NTproBNP | Number | 2795.943 ± 9980.085 | 1872.666 ± 9574.2647 | 3695.017 ± 10,281.7662 | <0.001 ** |
| BNP | Number | 319.4587 ± 741.2533 | 222.417 ± 533.8414 | 431.961 ± 912.7885 | <0.001 ** |
| HbA1c | Number | 6.486941 ± 1.482016 | 6.469 ± 1.5192 | 6.505 ± 1.4450 | 0.262 |
| ARU | Number | 460.0607 ± 73.9739 | 457.53 ± 75.363 | 462.30 ± 72.673 | 0.090 |
| PRU | Number | 199.4301 ± 109.9491 | 181.66 ± 108.618 | 217.63 ± 108.344 | <0.001 ** |
| PreTIMI | TIMI 0 | 42.11 (5518) | 61.75 (3906) | 23.78 (1612) | <0.001 ** |
| TIMI I | 9.81 (1286) | 10.29 (651) | 9.37 (635) | <0.001 ** | |
| TIMI II | 13.84 (1813) | 10.34 (654) | 17.10 (1159) | <0.001 ** | |
| TIMI III | 23.94 (3137) | 14.37 (909) | 13.41 (909) | <0.001 ** | |
| PostTIMI | TIMI 0 | 0.37 (49) | 0.43 (27) | 0.32 (22) | <0.001 ** |
| TIMI I | 0.43 (57) | 0.62 (39) | 0.27 (18) | <0.001 ** | |
| TIMI II | 2.43 (319) | 3.49 (221) | 1.45 (98) | <0.001 ** | |
| TIMI III | 86.45 (11,329) | 92.22 (5833) | 81.07 (5496) | <0.001 ** | |
| Initial Diagnosis | STEMI | 48.08 (6300) | 98.78 (6248) | 0.77 (52) | <0.001 ** |
| NSTEMI | 51.91 (6802) | 1.20 (76) | 99.22 (6726) | <0.001 ** | |
| ST Type | Acute ST | 0.18 (23) | 0.27 (17) | 0.09 (6) | <0.05 * |
| Class Labels for Prediction | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|
| STEMI CD | 0.9862 | 0.9928 | 0.9895 | 0.9999 |
| STEMI NCD | 1.0000 | 0.9994 | 0.9997 | 1.0000 |
| STEMI Hopeless Discharge | 1.0000 | 0.9994 | 0.9997 | 1.0000 |
| STEMI Recovery to Home | 0.9778 | 0.9576 | 0.9676 | 0.9974 |
| STEMI Recovery to other Hospital | 0.9818 | 0.9890 | 0.9853 | 0.9999 |
| NSTEMI CD | 0.9852 | 0.9948 | 0.9900 | 0.9999 |
| NSTEMI NCD | 1.0000 | 0.9989 | 0.9994 | 1.0000 |
| NSTEMI Hopeless Discharge | 1.0000 | 0.9994 | 0.9997 | 1.0000 |
| NSTEMI Recovery to Home | 0.9670 | 0.9743 | 0.9706 | 0.9981 |
| NSTEMI Recovery to other Hospital | 0.9930 | 0.9851 | 0.9890 | 0.9999 |
| Class Labels for Prediction | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|
| STEMI CD | 0.9860 | 0.9956 | 0.9908 | 0.9999 |
| STEMI NCD | 1.0000 | 0.9963 | 0.9981 | 1.0000 |
| STEMI Hopeless Discharge | 0.9994 | 0.9979 | 0.9986 | 1.0000 |
| STEMI Recovery to Home | 0.9724 | 0.9567 | 0.9645 | 0.9983 |
| STEMI Recovery to other Hospital | 0.9789 | 0.9839 | 0.9814 | 0.9998 |
| NSTEMI CD | 0.9930 | 0.9962 | 0.9946 | 0.9999 |
| NSTEMI NCD | 0.9994 | 0.9994 | 0.9994 | 1.0000 |
| NSTEMI Hopeless Discharge | 1.0000 | 0.9989 | 0.9994 | 0.9999 |
| NSTEMI Recovery to Home | 0.9709 | 0.9874 | 0.9791 | 0.9992 |
| NSTEMI Recovery to other Hospital | 0.9994 | 0.9867 | 0.9930 | 0.9998 |
| Class Labels for Prediction | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|
| STEMI CD | 0.7166 | 0.7166 | 0.7166 | 0.9645 |
| STEMI NCD | 0.8263 | 0.8054 | 0.8157 | 0.9881 |
| STEMI Hopeless Discharge | 0.7815 | 0.7150 | 0.7467 | 0.9790 |
| STEMI Recovery to Home | 0.8504 | 0.8649 | 0.8576 | 0.9853 |
| STEMI Recovery to other Hospital | 0.7039 | 0.7544 | 0.7283 | 0.9645 |
| NSTEMI CD | 0.7709 | 0.7442 | 0.7573 | 0.9734 |
| NSTEMI NCD | 0.8033 | 0.8922 | 0.8454 | 0.9886 |
| NSTEMI Hopeless Discharge | 0.8394 | 0.8045 | 0.8215 | 0.9882 |
| NSTEMI Recovery to Home | 0.8731 | 0.8575 | 0.8653 | 0.9869 |
| NSTEMI Recovery to other Hospital | 0.6996 | 0.7025 | 0.7010 | 0.9525 |
| Class Labels for Prediction | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|
| STEMI CD | 0.9882 | 0.9948 | 0.9915 | 0.9999 |
| STEMI NCD | 1.0000 | 0.9984 | 0.9992 | 1.0000 |
| STEMI Hopeless Discharge | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| STEMI Recovery to Home | 0.9799 | 0.9596 | 0.9696 | 0.9977 |
| STEMI Recovery to other Hospital | 0.9792 | 0.9860 | 0.9826 | 0.9998 |
| NSTEMI CD | 0.9879 | 0.9989 | 0.9933 | 0.9999 |
| NSTEMI NCD | 0.9989 | 0.9994 | 0.9992 | 1.0000 |
| NSTEMI Hopeless Discharge | 1.0000 | 0.9979 | 0.9989 | 1.0000 |
| NSTEMI Recovery to Home | 0.9754 | 0.9826 | 0.9790 | 0.9989 |
| NSTEMI Recovery to other Hospital | 0.9974 | 0.9904 | 0.9939 | 0.9998 |
| Algorithms | Accuracy | AUC | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Random Forest | 98.9172 | 99.9650 | 98.9182 | 98.9172 | 98.9159 |
| Extra Tree | 98.9796 | 99.9828 | 98.9828 | 98.9797 | 98.9791 |
| Gradient Boosting Machine | 78.6517 | 97.7566 | 78.7202 | 78.6517 | 78.6302 |
| Proposed SVE Classifier | 99.0733 | 99.9702 | 99.0742 | 99.0734 | 99.9719 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sherazi, S.W.A.; Zheng, H.; Lee, J.Y. A Machine Learning-Based Applied Prediction Model for Identification of Acute Coronary Syndrome (ACS) Outcomes and Mortality in Patients during the Hospital Stay. Sensors 2023, 23, 1351. https://doi.org/10.3390/s23031351
Sherazi SWA, Zheng H, Lee JY. A Machine Learning-Based Applied Prediction Model for Identification of Acute Coronary Syndrome (ACS) Outcomes and Mortality in Patients during the Hospital Stay. Sensors. 2023; 23(3):1351. https://doi.org/10.3390/s23031351
Chicago/Turabian StyleSherazi, Syed Waseem Abbas, Huilin Zheng, and Jong Yun Lee. 2023. "A Machine Learning-Based Applied Prediction Model for Identification of Acute Coronary Syndrome (ACS) Outcomes and Mortality in Patients during the Hospital Stay" Sensors 23, no. 3: 1351. https://doi.org/10.3390/s23031351