

Performance Enhancement in Federated Learning by Reducing Class Imbalance of Non-IID Data


Abstract
:1. Introduction
- To mitigate intra-client class imbalance, a novel data sampling to local datasets is introduced, which results in accuracy improvement in non-IID environments.
- An FL server intelligently selects clients and allocates the amount of data to be actually used in local learning by balancing the class distributions of the selected clients.
- The batch size and the learning rate of clients are dynamically controlled according to the amount of local dataset for each client.
- Performance evaluation in various non-IID scenarios confirms that the proposed algorithm achieves high accuracy and low usage of computing and communication resources compared to existing algorithms.
2. Related Works
3. System Model and Data Distributions
3.1. System Model
3.2. Data Distributions
4. Proposed Algorithm
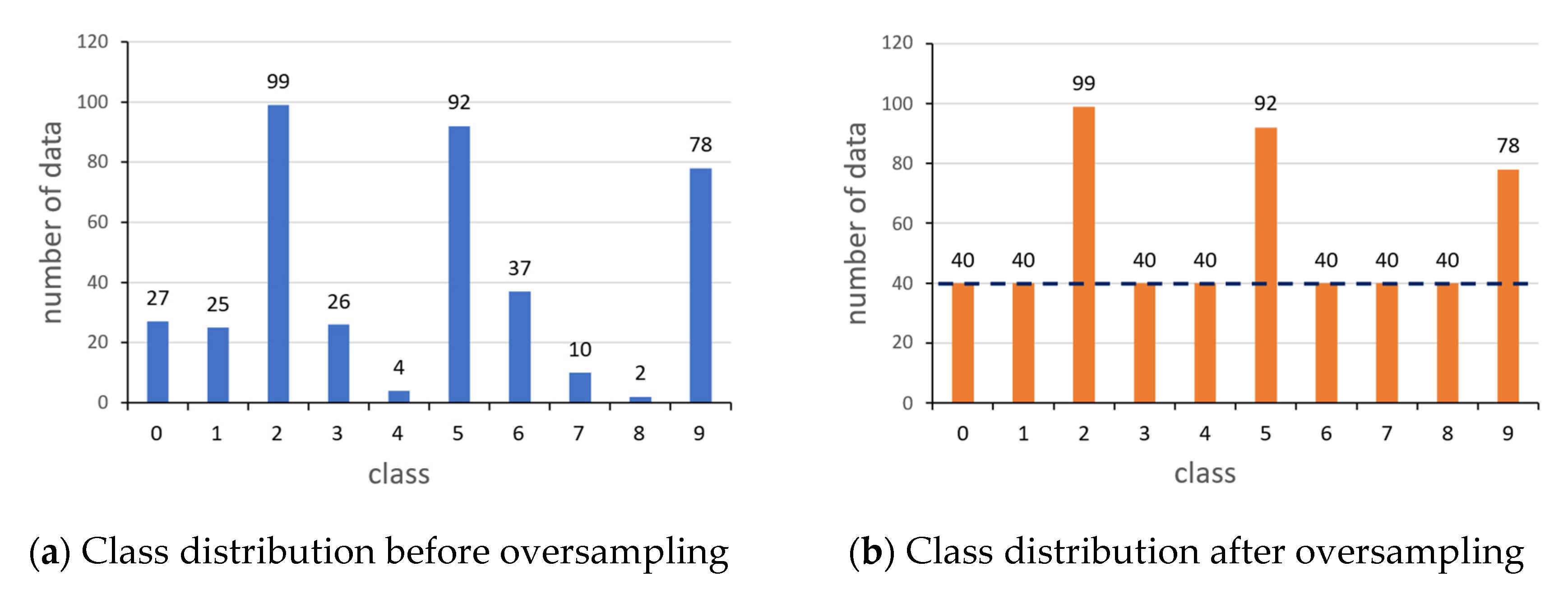
4.1. Alleviating Intra-Client Class Imbalance
| Algorithm 1. Sampling. number of data per class is greater than or equal to the average |
| • client executes: • Input , , • Output 1: 2: repeat 3: oversampling for 4: until 5: return • server executes: • Input selected client set • Output 1: if //calculate oversample data rate 2: 3: return |
4.2. Alleviating Inter-Client Class Imbalance
| Algorithm 2. Client Selection. The server selects clients and adjusts client’s training data |
| • Input • Output = 1: initialize 2: Sort in descending order by the amount of data 3: repeat 4: for each do 5: if then 6: for each , = 1, 2, …, do 7: 8: 9: end for 10: max() //Maximum value among 11: add in 12: else 13: 14: if then 15: for each , = 1, 2, …, do 16: + min(—, ) 17: min(—, ) 18: end for 19: add in 20: end if 21: end if 22: end for 23: until 24: return |
4.3. Dynamic Batch Size and Learning Rate Control
| Algorithm 3. DynamicBL. dynamically allocate batch size and learning rate |
| • Input , • Output 1: 2: 3: return |
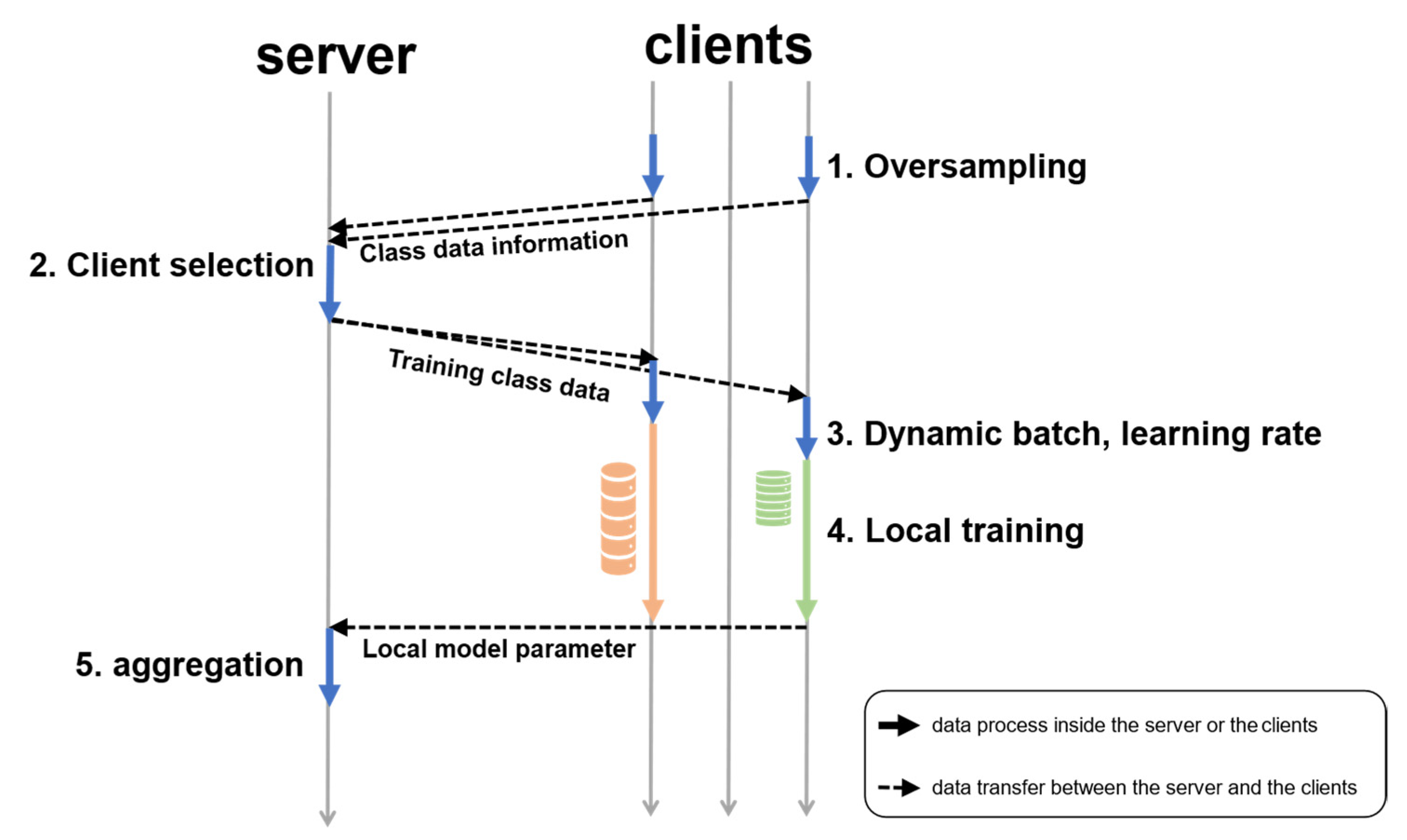
4.4. Workflow
- Local data sampling: a client who wants to participate in learning checks the class distribution of the local dataset and proceeds with oversampling, and then sends the data distribution information to the server.
- Client selection and allocation of training data: the server selects the clients to make the class distribution of learning data balanced for each round and delivers the information about the amount of training data to the selected clients.
- Dynamic batch and learning rate control: each client calculates the batch size and learning rate of local learning based on the amount of data it learns.
- Local training: Each client learns a local model using the amount of training data received from the server and the previously calculated batch size and learning rate. After learning, the client sends the local model parameters to the server.
- Aggregation: When the server receives all the selected clients’ local model parameters, it updates the global model parameters using Equation (2). Then repeat until the final round.
5. Experiment Results
5.1. Experiment Setup
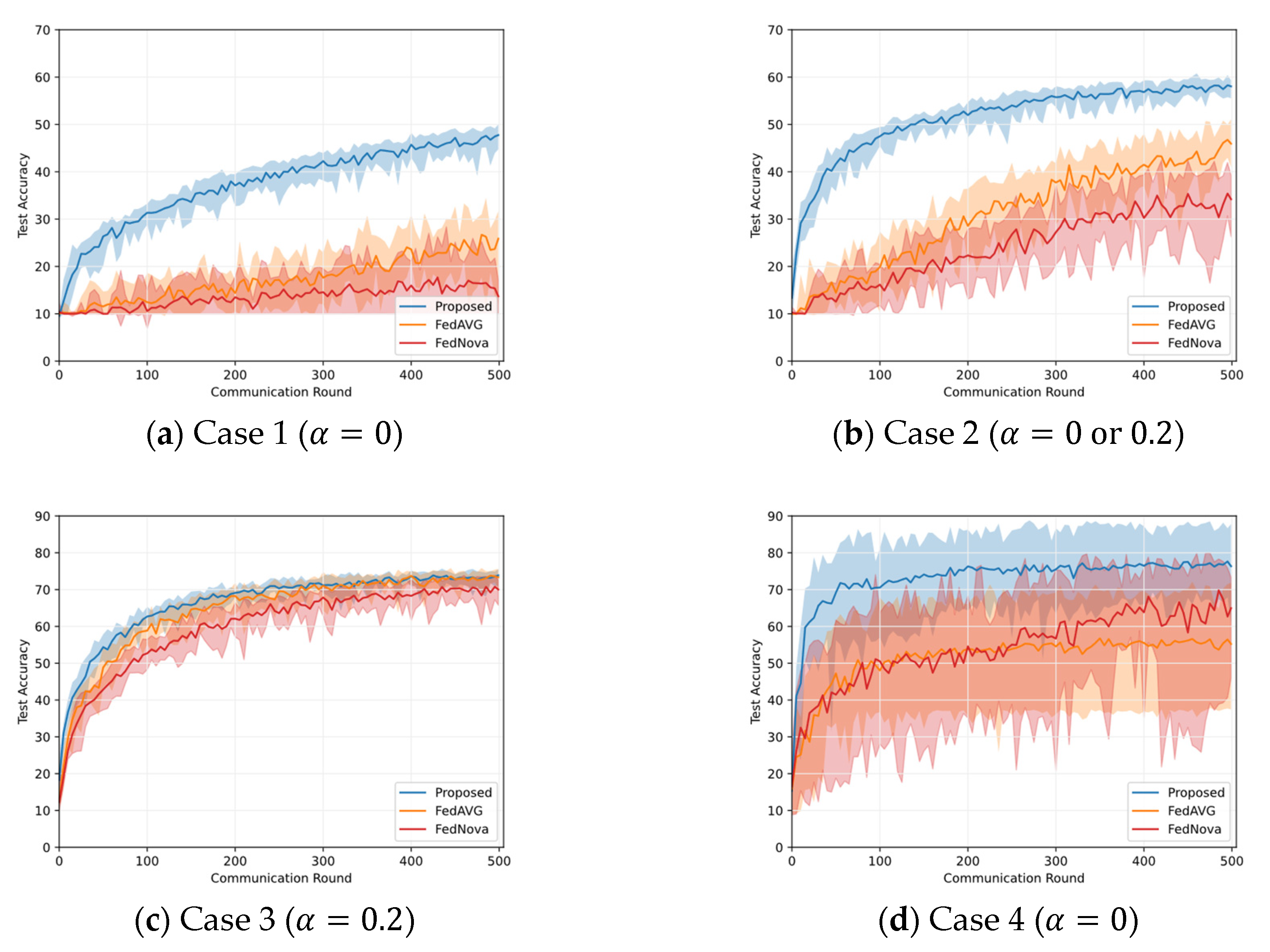
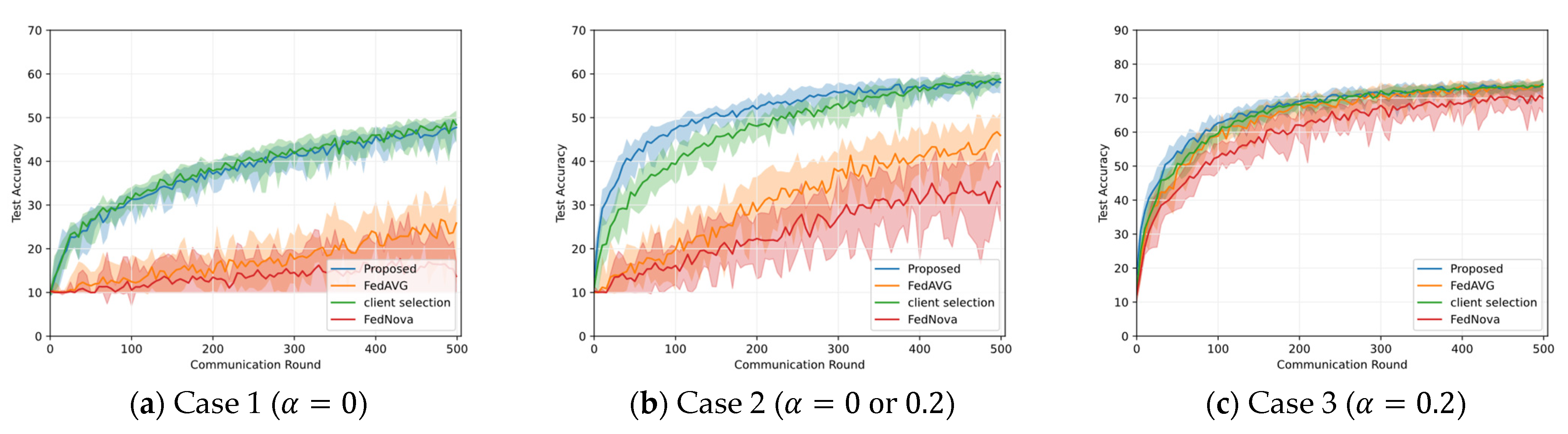
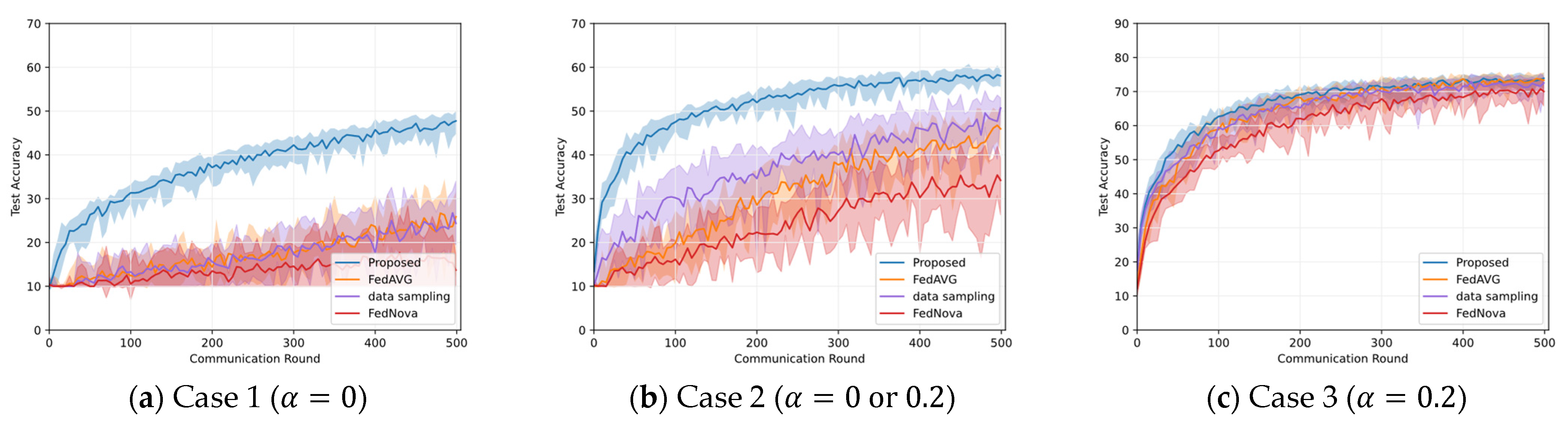
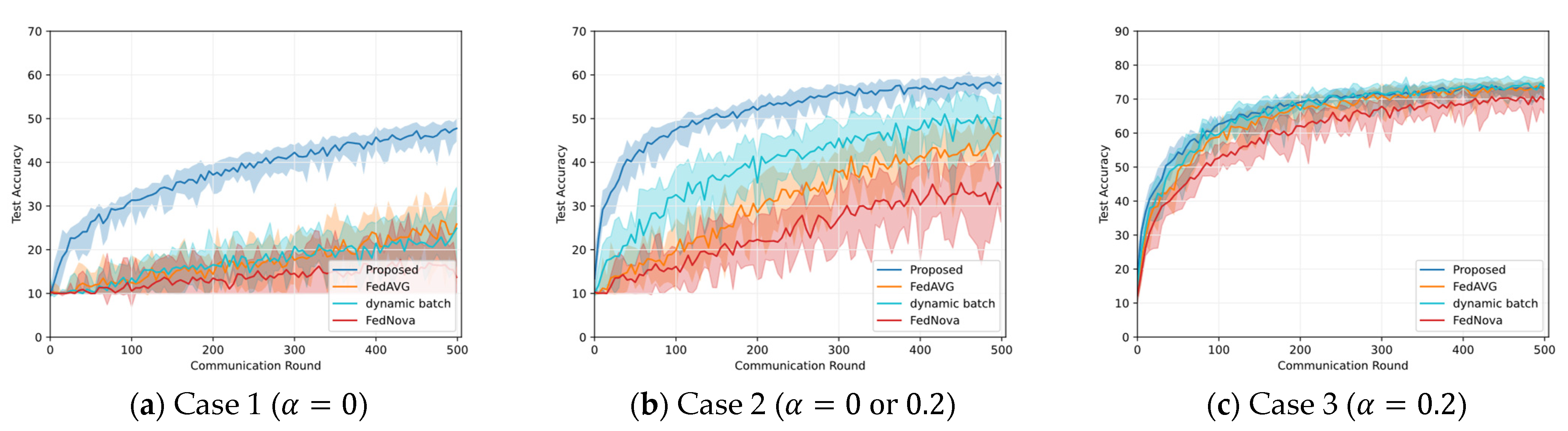
5.2. Results on Different Non-IID Data Distribution
5.3. Results on Class Imbalance Mitigation
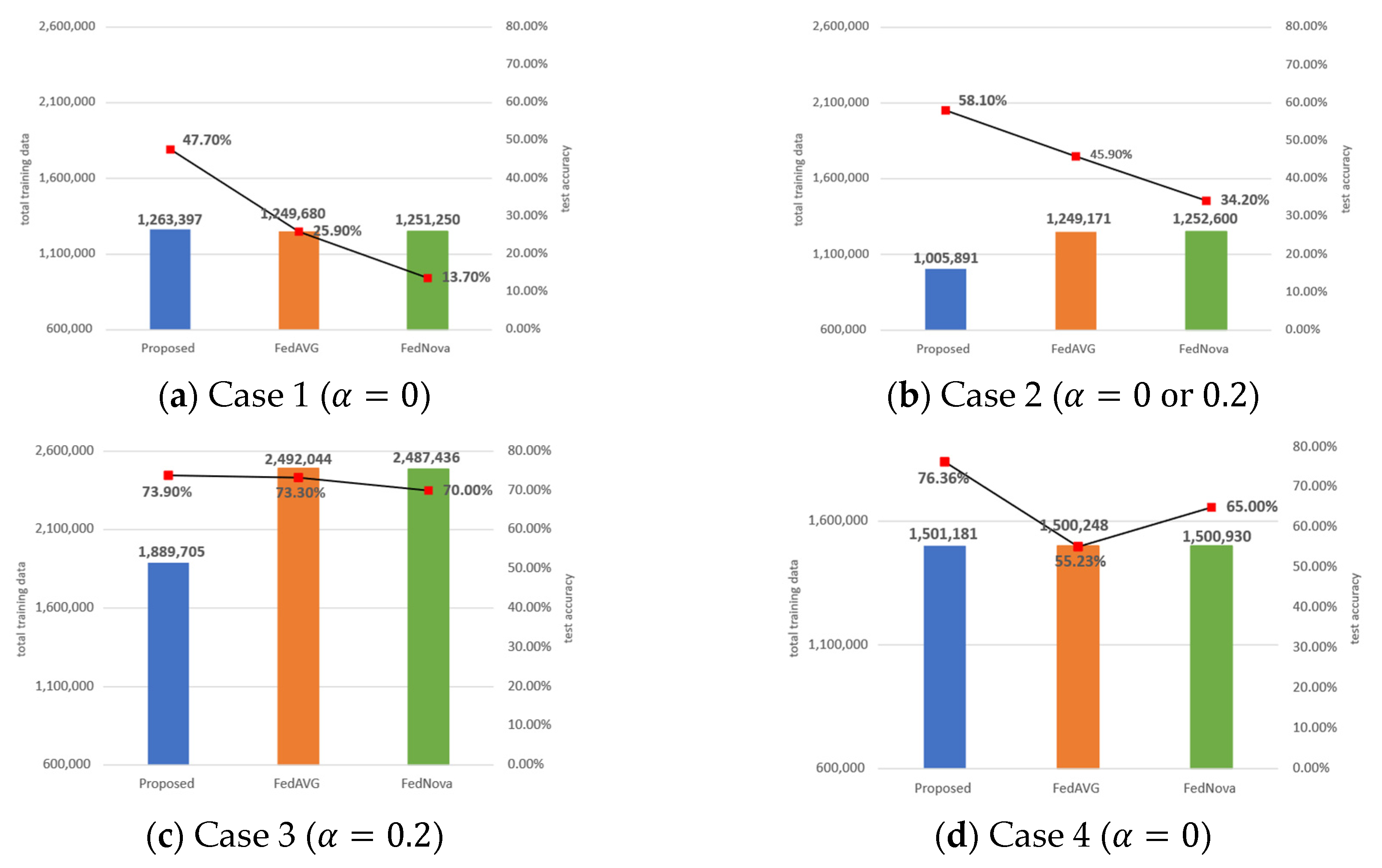
5.4. Amount of Training Data
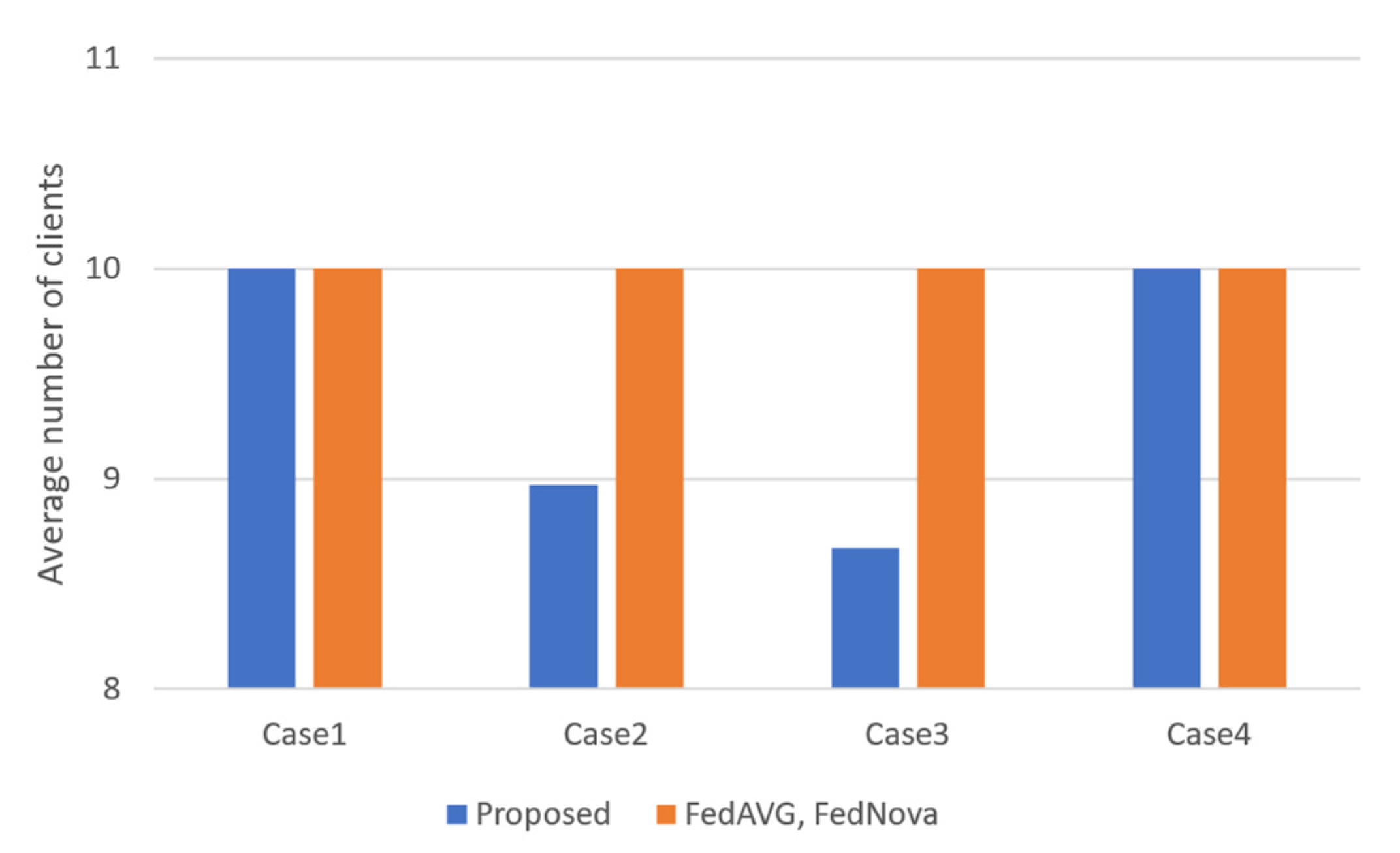
5.5. Average Number of Clients
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cisco. Cisco Annual Internet Report (2018–2023); White Paper; Cisco: San Jose, CA, USA, 2020. [Google Scholar]
- McMahan, B.; Ramage, D. Research Scientists. Federated Learning: Collaborative Machine Learning without Centralized Training Data. 2018. Available online: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html (accessed on 12 June 2021).
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics (AISTATS 2017), Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the 2019 IEEE International Conference on Communications (ICC 2019), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive Federated Learning in Resource Constrained Edge Computing Systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Xu, H.; Liu, J.; Huang, H.; Qiao, C.; Zhao, Y. Resource-Efficient Federated Learning with Hierarchical Aggregation in Edge Computing. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Muller, K.-R.; Samek, W. Robust and Communication-Efficient Federated Learning from Non-i.i.d. Data. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3400–3413. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Y.; Gong, X. Quality-Aware Distributed Computation and User Selection for Cost-Effective Federated Learning. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Vancouver, BC, Canada, 10–13 May 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Ma, Z.; Xu, Y.; Xu, H.; Meng, Z.; Huang, L.; Xue, Y. Adaptive Batch Size for Federated Learning in Resource-Constrained Edge Computing. IEEE Trans. Mob. Comput. 2021, 22, 37–53. [Google Scholar] [CrossRef]
- Shi, D.; Li, L.; Wu, M.; Shu, M.; Yu, R.; Pan, M.; Han, Z. To Talk or to Work: Dynamic Batch Sizes Assisted Time Efficient Federated Learning over Future Mobile Edge Devices. IEEE Trans. Wirel. Commun. 2022, 21, 11038–11050. [Google Scholar] [CrossRef]
- Li, Q.; Diao, Y.; Chen, Q.; He, B. Federated Learning on Non-Iid Data Silos: An Experimental Study. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 965–978. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated Learning with Non-IID Data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Li, D. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated Optimization in Heterogeneous Networks. arXiv 2018, arXiv:1812.06127. [Google Scholar]
- Shoham, N.; Avidor, T.; Keren, A.; Israel, N.; Benditkis, D.; Mor-Yosef, L.; Zeitak, I. Overcoming forgetting in federated learning on non-iid data. arXiv 2019, arXiv:1910.07796. [Google Scholar]
- Rizk, E.; Vlaski, S.; Sayed, A.H. Optimal Importance Sampling for Federated Learning. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3095–3099. [Google Scholar] [CrossRef]
- Kopparapu, K.; Lin, E. Fedfmc: Sequential efficient federated learning on non-iid data. arXiv 2020, arXiv:2006.10937. [Google Scholar]
- Briggs, C.; Fan, Z.; Andras, P. Federated Learning with Hierarchical Clustering of Local Updates to Improve Training on Non-IID Data. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Duan, M.; Liu, D.; Chen, X.; Tan, Y.; Ren, J.; Qiao, L.; Liang, L. Astraea: Self-Balancing Federated Learning for Improving Classification Accuracy of Mobile Deep Learning Applications. In Proceedings of the 2019 IEEE 37th International Conference on Computer Design (ICCD), Abu Dhabi, United Arab Emirates, 17–20 November 2019; pp. 246–254. [Google Scholar] [CrossRef] [Green Version]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time analysis of the multiarmed bandit problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, X.; Zhou, P.; Wu, W.; Zhang, X. Client Selection for Federated Learning With Non-IID Data in Mobile Edge Computing. IEEE Access 2021, 9, 24462–24474. [Google Scholar] [CrossRef]
- Yang, M.; Wang, X.; Zhu, H.; Wang, H.; Qian, H. Federated Learning with Class Imbalance Reduction. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 2174–2178. [Google Scholar] [CrossRef]
- Malandrino, F.; Chiasserini, C.F. Federated Learning at the Network Edge: When Not All Nodes Are Created Equal. IEEE Commun. Mag. 2021, 59, 68–73. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization. Adv. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 7611–7623. [Google Scholar]
- Zhang, J.; Guo, S.; Qu, Z.; Zeng, D.; Zhan, Y.; Liu, Q.; Akerkar, R. Adaptive Federated Learning on Non-IID Data with Resource Constraint. IEEE Trans. Comput. 2022, 71, 1655–1667. [Google Scholar] [CrossRef]
- Hsu, T.M.H.; Qi, H.; Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Goyal, P.; Dollár, P.; Girshick, R.B.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 h, CoRRabs/1706.02677. 2017. Available online: https://dblp.org/db/journals/corr/corr1706.html#GoyalDGNWKTJH17 (accessed on 30 April 2018).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Client index set | |
| r | Round index |
| Kullback–Leibler divergence threshold | |
| Maximum number of selected clients | |
| Number of classes | |
| Oversampling exponent | |
| Batch size of client at round | |
| Learning rate of client at round | |
| Global model parameter at round | |
| Local model parameter of client at round | |
| Local dataset of client | |
| Number of clients | |
| Mini batch set for client k | |
| Local loss function of client | |
| Dirichlet distribution control parameter | |
| Class data volume for client | |
| tk | Average amount of class data for client |
| Class training data volume for client at round | |
| vr | Class training data volume at round r |
| Number of SGD updates | |
| ηmax | Maximum learning rate |
| Distribution Setup | Experiment Parameter | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Datasets | Case | Sampling | Client Selection | Dynamic Batch | Local Training | ||||
| 𝛽 | epoch | ||||||||
| CIFAR-10 | 1 | 200 | 0 | 0.1 | 0.1 | 0.1 | 3 | 10 | 5 |
| 2 | 200 | 0 or 0.2 | 0.1 | 0.1 | 0.1 | 25 | 10 | 5 | |
| 3 | 100 | 0.2 | 0.1 | 0.1 | 0.1 | 25 | 10 | 5 | |
| MNIST | 4 | 200 | 0 | 0.1 | 0.1 | 0.1 | 25 | 10 | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seol, M.; Kim, T. Performance Enhancement in Federated Learning by Reducing Class Imbalance of Non-IID Data. Sensors 2023, 23, 1152. https://doi.org/10.3390/s23031152
Seol M, Kim T. Performance Enhancement in Federated Learning by Reducing Class Imbalance of Non-IID Data. Sensors. 2023; 23(3):1152. https://doi.org/10.3390/s23031152
Chicago/Turabian StyleSeol, Mihye, and Taejoon Kim. 2023. "Performance Enhancement in Federated Learning by Reducing Class Imbalance of Non-IID Data" Sensors 23, no. 3: 1152. https://doi.org/10.3390/s23031152