1. Introduction
In the contemporary mobile internet era, individuals increasingly depend on mobile devices and applications for activities such as information access, social networking, and online shopping, all facilitated by the collection and utilization of location data. Furthermore, the advancements in big data, artificial intelligence, and related technologies enable the utilization of users’ location data for purposes like optimization of traffic flows [
1] and advertising [
2], as well as intelligent medical systems [
3]. However, collecting location data also raises many security and privacy concerns. Unauthorized use and sharing of location data can result in privacy breaches [
4,
5,
6]. For instance, individuals may exploit location data for tracking and monitoring purposes [
7], including socializing [
8], navigation, and travel [
9]. Additionally, location data can help rescuers determine affected people’s location and movement trajectories in disaster rescue [
10], making location data security crucial for public safety. Therefore, protecting personal location privacy has become an essential part of personal privacy protection.
Despite the emergence of numerous location privacy protection techniques, the effectiveness of current approaches faces challenges regarding the relentless technical advancements of attackers [
11]. Consequently, researchers have been continuously exploring how to protect users’ location privacy more effectively.
Trajectory privacy protection techniques have gained significant attention in research due to their capacity to safeguard the privacy of users’ location and behavioral trajectories, becoming an integral component of location privacy protection strategies. There are three fundamental approaches to achieving trajectory privacy: (1) Fake Trajectory [
4,
12]. This method involves the addition of fabricated trajectory points [
12] or the exchange of two location pairs that are close in time and space [
4] to obfuscate the authentic trajectory data to preserve privacy. However, this method is susceptible to exploitation by attackers who can discern real from fake trajectory points by scrutinizing time and speed parameters. (2) Sensitive Location Suppression [
13]. This approach safeguards user privacy by eliminating or concealing sensitive locations, such as home addresses and workplaces. Nevertheless, if an attacker can access additional information, such as the user’s frequently visited locations, the user’s actual location can still be deduced. (3) Trajectory
k-Anonymity [
7,
14]. This approach is an extension of
k-anonymity, in which the user’s trajectory is divided into multiple sub-trajectories, and
other users’ trajectories are chosen for each sub-trajectory to obscure the current user’s trajectory.
During the process of
k-anonymizing trajectories, researchers leverage the similarity of certain trajectory data to anonymize them effectively, preventing attackers from discerning the user’s real trajectory. The method described in [
15] for publishing an anonymous trajectory is based on the generation of secure starting and ending points, the generation of candidate sets containing secure starting and ending points based on user habits, the generation of
anonymous trajectories in both directions, and the correction of the accessibility of location points on each anonymous trajectory using access probabilities. Zhou and Wang [
16] combined a fog computing and
k-anonymity approach to protect trajectories, using fog computing to provide users with local storage and mobility and
k-anonymity techniques to construct hidden regions for each trajectory snapshot based on time-dependent query probabilities and transfer probabilities to solve the problems of real-time trajectory privacy protection and offline trajectory data protection for continuous queries. Nevertheless, the trajectory
k-anonymity technique possesses certain limitations. For instance, attackers can deduce the actual trajectories of users by discerning information disparities (e.g., time, space) among different users [
17,
18]. As shown in
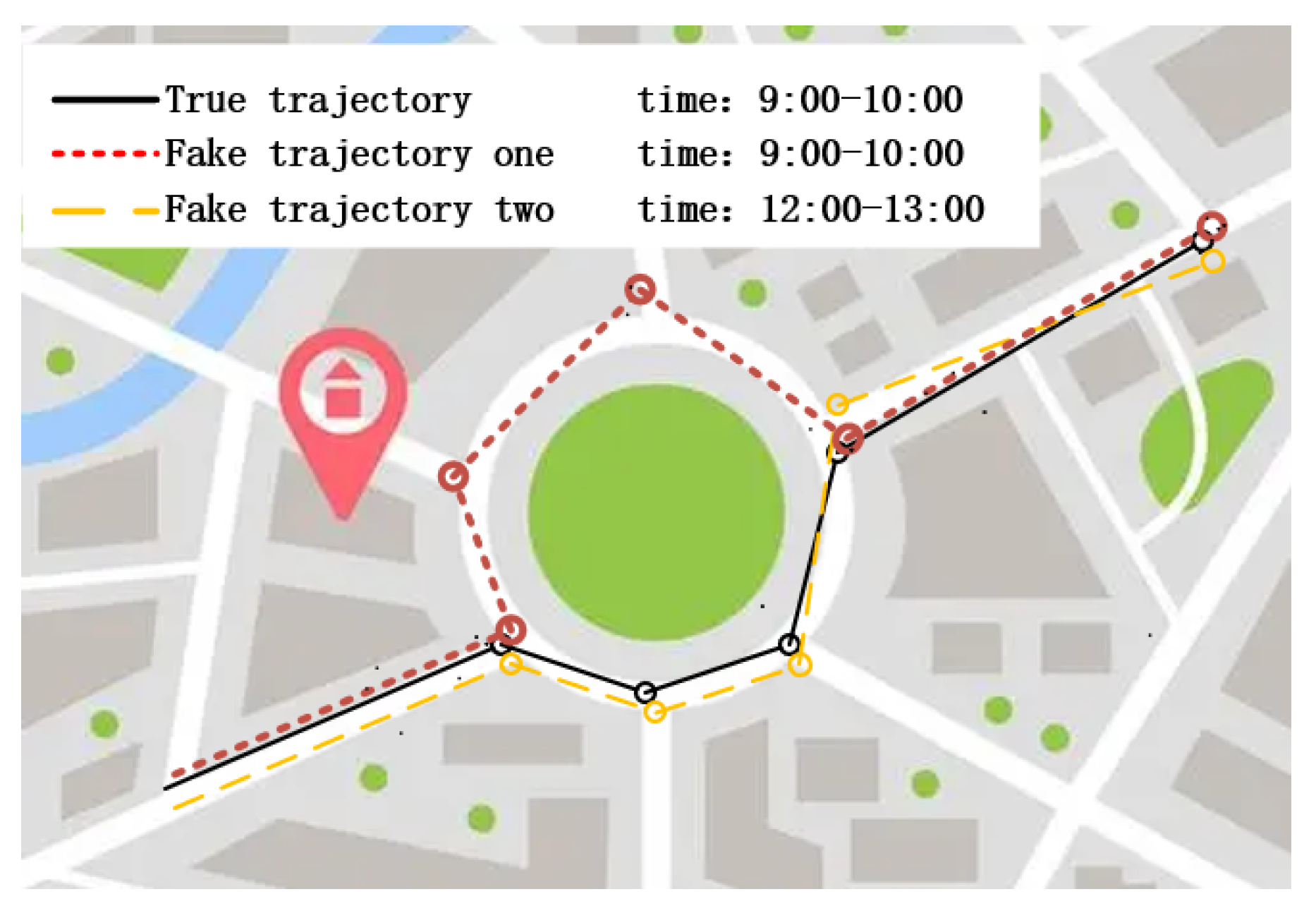
Figure 1, the attacker must distinguish between the user’s real trajectory (represented by a solid line) and the first fake trajectory (represented by a dotted line), which the attacker can easily distinguish because the two trajectories take different paths in the middle segment, which is the area through which the attacker distinguishes the user’s real trajectory. The attacker cannot distinguish between the real trajectory and the second fake trajectory (represented by a dashed line) because their routes are identical. However, because the real trajectory is generated between 9:00 and 10:00 and the second fake trajectory is generated between 12:00 and 13:00, the attacker can infer the real trajectory of the user using the time information of the trajectories. Thus, it can be seen that the method of selecting trajectories that meet the requirements of trajectory anonymity is the key to trajectory
k-anonymity.
To address the shortcomings of trajectory
k-anonymity, this study [
19] aims to address the privacy leakage problem caused by the increasing amount of personal information sources with the popularization of mobile devices. To prevent the disclosure of user privacy in the published spatio-temporal trajectory dataset, proposing a trajectory
k-anonymization model called KPDP, which is based on point density and partitioning. The model optimizes current anonymization methods in regards to trajectory collection, partitioning, preprocessing and trajectory clustering algorithms. It effectively prevents re-identification attacks and minimizes data utility loss in
k-anonymized datasets. Zhang [
20] proposed the
algorithm, which constructs a dummy location set by randomly selecting probabilistic similarity offset locations under guaranteed semantic distinction, improved security of location privacy, avoiding background knowledge attacks, edge information attacks, and homogeneity attacks to some extent. Yang [
21] generated similar trajectories in real-time by the angle and distance between real trajectory points during continuous query service, which can also prevent edge information attacks when protecting user trajectories. Guo [
22] introduced a new query privacy algorithm for continuous querying of location-based services that consider users with similar directions, speeds, and the same transmission patterns for anonymization, thus protecting users’ privacy throughout the query cycle. The literature [
23] introduces a method measuring semantic trajectory similarity across dimensions like weighted time and space. In contrast to conventional methods, it offers a comprehensive view of semantic relationships. Existing trajectory similarity approaches focus on two-dimensional raw trajectories, while literature proposed MSM considers and weights similarity across all dimensions. In summary, we can resist the aforementioned attack by taking into account the similarity of multiple perspectives (such as distance similarity, direction similarity, speed similarity, time similarity, and transmission similarity) between the produced
trajectories and the real trajectory while producing the
trajectories. However, we discover that the majority of the methods discussed above determine how similar two trajectories are by calculating the similarity between position points extracted from the two trajectories. The process of producing
dummy trajectories for a given trajectory usually includes four steps: The first one is to extract the start point, end point, and some other points from the given trajectory. The second one is to generate a point set of size
k for each extracted point in which every point is similar to the corresponding extracted point in multiple respects. The third is to produce a dummy trajectory by randomly choosing a point from the point set corresponding to the start point of the given trajectory, the point sets corresponding to the other extracted points, and the point set corresponding to the end point of the given trajectory in turn. The fourth is to determine
dummy trajectories that are most similar to the given trajectory from the produced dummy trajectories. Suppose we extract
n points from the given trajectory. We will have
n point sets of size
k. So, we will generate
dummy trajectories. Then, we need to choose
trajectories that are most similar to the given trajectory from the
dummy trajectories, which typically results in significant computational overhead.
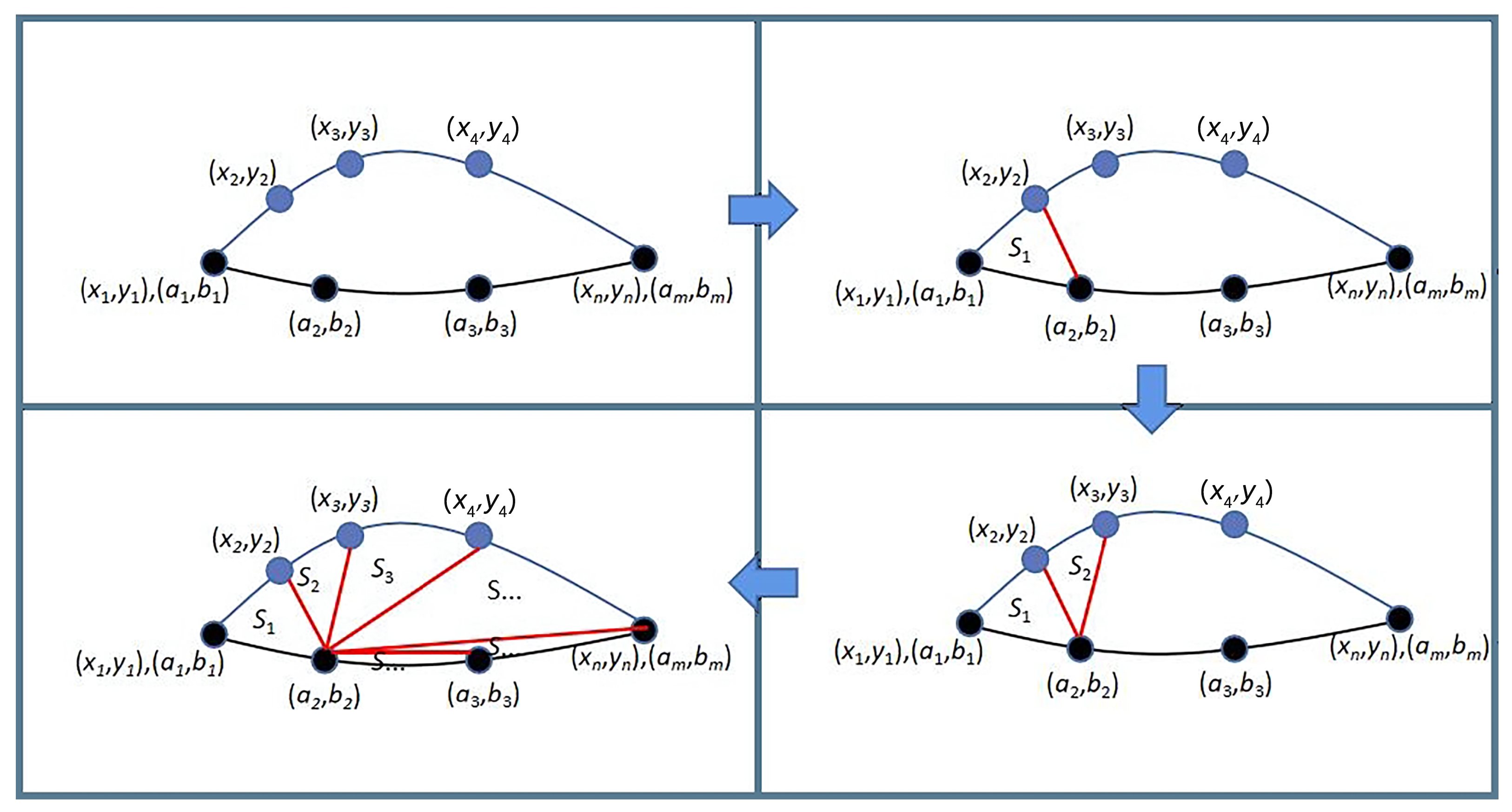
To address the limitations of trajectory k-anonymity with minimal computational overhead, this paper introduces a privacy-preserving trajectory publishing method (PP-TPS) that relies on multi-dimensional similarities among sub-trajectories. PP-TPS is a method for achieving trajectory k-anonymity. To minimize the computational burden associated with creating similar trajectories from a given trajectory, leveraging historic trajectory data, PP-TPS initially divides both the target trajectory and the historic data into sub-trajectories. Then, PP-TPS filters historic sub-trajectories for each sub-trajectory of the trajectory according to the computed multi-dimensional similarities between them. The main contributions of this paper are as follows:
We design a k-anonymous privacy-preserving method (PP-TPS) based on sub-trajectories’ similarity. PP-TPS divides a given real trajectory in chronological order to obtain multiple segments (that is, sub-trajectories). Then, PP-TPS finds all sub-trajectories that are similar to these segments from historic trajectory sets. Finally, PP-TPS generates dummy trajectories for the given real trajectory by splicing similar sub-trajectories in chronological order. In other words, PP-TPS generates dummy trajectories by using real historic sub-trajectories to improve the authenticity of the generated dummy trajectories, enhancing privacy protection for real trajectories.
PP-TPS considers the similarity of points between the historic trajectory and the real trajectory but also considers the similarity of the sub-trajectories between the historic and real trajectories. Moreover, PP-TPS proposes to measure the similarity of sub-trajectories by the area distance between them. This processing skill makes the processing process simpler and more efficient by drastically reducing the dummy trajectory space formed by simply taking the point similarity into account and skillfully avoiding solving the entire trajectory similarity.
PP-TPS present a novel multidimensional similarity calculation approach that surpasses conventional similarity measures. It not only considers trajectory similarities in space but also factors in multiple dimensions. This cutting-edge method allows for a more comprehensive and precise depiction of trajectory relationships, offering a detailed and profound perspective for trajectory research.
PP-TPS conducts comprehensive experiments on real datasets, and the results show that our method is more effective in terms of data availability and privacy protection compared to other methods.
The structure of the paper is outlined as follows:
Section 2 provides an overview of related work.
Section 3 introduces the relevant concepts and notations employed throughout the paper.
Section 4 offers a comprehensive description of the proposed method, PP-TPS.
Section 5 presents a comparative analysis of PP-TPS’s performance against other methods. Lastly,
Section 6 summarizes the paper.
2. Related Work
The concept and basic principles of
k-anonymity were first proposed by Latanya Sweeney [
24].
k-anonymity technology aims to protect personal privacy by preventing an attacker from uniquely identifying a specific user. Gruteser and Grunwald [
25] first applied
k-anonymity methods to location services. They proposed a method to ensure users’ real locations cannot be accurately determined by temporal masking of the location information in time and space. Subsequently,
k-anonymity techniques have gained significant traction in the domain of location-based services, with applications ranging from privacy-preserving traffic monitoring and management in traffic systems using
k-anonymity technologies [
26] to preventing the leakage of node location information in sensor networks through the adoption of
k-anonymity technologies [
27]. These techniques have also been instrumental in protecting user search history within search engines [
28], securing the trajectories of devices [
29], and preserving location privacy in mobile social networks [
30]. This paper focuses on trajectory privacy by utilizing
k-anonymization technologies. In summary,
k-anonymization methods for trajectory privacy can be divided into two types: discrete point-based
k-anonymization methods and trajectory-based
k-anonymization methods.
2.1. Discrete Point-Based k-Anonymization
The discrete point-based approach [
31,
32,
33] typically involves discretizing a trajectory into a sequence of points and then perturbing each point to attain
k-anonymity, thereby enabling the creation of
k-anonymized trajectories. The discrete point-based approaches are simple and intuitive. According to the dimension of similarity, this approach can be divided into two categories: discrete point-based
k-anonymization with one-dimensional similarity and discrete point-based
k-anonymization with multi-dimensional similarity.
The one-dimensional similarity
k-anonymization method considers the similarity of locations from one perspective, such as spatial, semantic, or probabilistic, simplifying implementation. For example, the paper [
34] proposed a new method called ARB to protect location privacy. The ARB method divides the space into grids and calculates the probability of queries within different grids based on historical data. Then, the query probabilities are used to generate anonymous regions for users to protect their location privacy. In [
35], a location
k-anonymity privacy protection scheme for vehicular networks was introduced. It involves dividing locations into multiple cells and assigning each cell a query probability based on the historical query distribution. By utilizing the Fréchet distance to measure trajectory similarity, it identifies the top
locations with the highest probabilistic similarity as candidates and delivers the optimal set of
k-anonymous locations for straightforward and effective location privacy protection. In [
29], the authors derived a gravity model describing user movement patterns from stored trajectory data. They established the flow relationships between locations, computed transfer probabilities among different grids based on the derived gravity model, and identified the virtual location with the highest location entropy to generate
virtual locations, thereby preserving user trajectory data. Ref. [
31] utilized a random walk to generate virtual location points within a specific geographic distance to ensure that all users in the steganography region have the same probability of being identified as real users. The scheme provided by [
32] considered the user’s sensitivity to different location semantics and optimized collaborative segmentation to protect location privacy.
Although location points
k-anonymity with similarity of one-dimensional location metric is easy to implement, an attacker can still threaten the user’s privacy with some side information. For example, an attacker may find that a user posts a post about a restaurant located in a certain area at one point in time, followed by a post about a movie theater located in a certain area at another point in time. By analyzing the temporal and geographical connections between these posts, the attacker can deduce the user’s unique trajectory based on the temporal references and location semantics (restaurant, movie theater), even when the user’s location has been anonymized. Researchers filtered them for multi-dimensional similarity to get virtual locations that are more similar to real locations. Literature [
36] presents Enhanced-DLP, a novel, lightweight false location privacy protection scheme, aimed at tackling computational cost and additional information attacks challenges found in traditional schemes. Enhanced-DLP efficiently selects false locations to create
k-anonymous sets using an improved greedy algorithm. The method incurs lower computational costs in selecting false locations and is capable of defending against attacks using supplementary information, in contrast with current approaches. The paper [
37] considered the side information that the adversary may exploit. It first selected these virtual locations based on the entropy metric and subsequently introduced an improved DLS algorithm to maximize the dispersion of these selected virtual locations. Based on this, Yang et al. [
38] took query probability and semantic location information as critical parameters, presented a virtual location selection model to evaluate the quality of virtual locations, and used a genetic algorithm-based optimization method to find the optimal solution, which ends up with a set of virtual locations with query probability as close as possible and also makes the locations in them as semantically and physically dispersed as possible. Unlike the above, the paper [
39] built a semantic location tree (LST) and converted the semantic distance into the number of hops between nodes in the LST, designing a method that takes into account the semantic diversity and physical dispersion of locations, and combined the two objectives of geographic location and location semantics into a single objective optimization problem to improve efficiency, and ultimately produced an anonymous region. Concerning multi-dimensional location point similarity, Ref. [
40] proposed a semantic-based method to protect trajectory anonymity. The method constructed a semantic region of sensitive location points by modeling each location point in the trajectory, where each sensitive point is associated with
similar POI points. The method compared spatiotemporal and semantic similarities for anonymization to generate a usable anonymized trajectory dataset.
To select the dummy trajectories closest to the supplied trajectory, this approach must consider various virtual trajectories created by orderly combining location points of candidate point sets (anonymous point sets) corresponding to the selected locations on the given trajectory. This process often leads to considerable computational overhead.
2.2. Trajectory-Based k-Anonymization
The discrete-point
k-anonymity-based approach significantly impacts trajectory accuracy and entails higher computational complexity, necessitating the processing of all individual points on the trajectory. In contrast, the trajectory
k-anonymity-based approach treats a sequence of discrete points within the trajectory holistically to achieve
k-anonymity, focusing on the trajectory’s overall characteristics for enhanced user privacy protection. This approach efficiently reduces computational overhead and enhances user privacy protection. Paper [
41] presents a novel distributed
k-anonymity algorithm to address the problem of location privacy leaks. The algorithm evaluates the similarity of users by analyzing their points of interest and social conduct, and picks users with a high similarity to form a group of anonymous collaborators. Ultimately, a homogenization algorithm guarantees the relative uniform distribution of the anonymized location points. Unlike the above scheme, ref. [
42] primarily constrained the geographic location of trajectories and introduced a privacy-preserving method for measuring distance-based trajectory similarity. This method entailed constructing a trajectory network with spatial similarity serving as weights and selecting the node with the highest weight as the clustering center to create clusters meeting specific conditions. In the process of trajectory point perturbation, the trajectory points are shifted to the positions of neighboring nodes according to their degrees and specific conditions to achieve anonymization. This research [
43] introduces sequential triple decision making and dynamic
k-values to traditional
k-anonymity to achieve personalized privacy protection. The proposed multi-level personalized
k-anonymization model constructs a hierarchical decision table with attribute generalization trees and sensitive decision values supplied by the user. It utilizes dynamic
k-value sequences to anonymize data. This study presents an extensive model for safeguarding privacy across multiple levels, thereby augmenting the use of sequential triple decision making in the privacy protection domain. Ref. [
44] fused the similarity of multiple dimensions into trajectory similarity and proposed a personalized anonymization model that considers trajectory privacy and data utility. The model considers the effects of trajectory similarity, direction, and the trajectory distance on privacy and data utility and achieves a near-optimal set of
k-anonymized trajectories by transforming the
k-optimal trajectory selection problem into a constrained minimum spanning tree problem and using a trajectory graph model with a greedy strategy. In addition, the model pays full attention to users’ characteristics and requirements, exhibits strong scalability, and proves to be well suited to practical application scenarios. To further enhance the privacy protection effect of trajectories, this research [
45] proposes the Privacy-Enhanced Distributed
k-Anonymous Reward Mechanism (PEAK) to incentivize users to participate in distributed
k-anonymity privacy protection in location services. PEAK does not need to trust third parties, establishes anonymous zones through currency transactions and location transmission, introduces role recognition and accountability mechanisms to limit malicious users, improves security and feasibility, and successfully establishes anonymous zones with a success rate of over 0.9, significantly reducing the utility of malicious users. Traditional
k-anonymous trajectory privacy-preserving methods based on trajectory similarity usually use only one or two similarities between trajectories, resulting in ignoring the relationship between other attributes in the trajectories, and thus they cannot achieve the expected privacy-preserving effect.
For the above issues, the proposed PP-TPS method generates dummy trajectories by combining candidate sub-trajectories instead of candidate location points to reduce the computation cost and filters historic sub-trajectories according to multi-dimensional similarities (including time, space, semantics, direction, and probability) when creating candidate sub-trajectory sets to improve the intensity of privacy protection of user trajectories.
6. Conclusions
This paper proposes an efficient method, PP-TPS, to realize the k-anonymity of a trajectory. PP-TPS involves filtering historic location points by calculating spatial, temporal, and semantic similarities. Based on the discovered similar points, PP-TPS can extract a large amount of corresponding sub-trajectories from many historic trajectories. Then, PP-TPS sifts through these historic sub-trajectories further according to the area distance between them and uses the sub-trajectories of the real trajectory to obtain candidate sub-trajectory sets. Finally, PP-TPS generates dummy trajectories for the real trajectory based on the candidate sub-trajectory sets.
PP-TPS guarantees that the generated dummy trajectory is similar to the real trajectory at the point level by carefully considering the multidimensional similarity of the location points. Furthermore, it measures the similarity between sub-trajectories using the area distance. This novel approach provides a more straightforward and efficient way to handle data when compared to computing the similarity of the entire trajectory, making the solution more practical and effective. Overall, PP-TPS surpasses traditional privacy methods, reduces computing costs, and achieves a satisfactory balance. Additionally, the method introduces a novel metric for trajectory similarity based on area. Moreover, PP-TPS utilizes real historic sub-trajectories to generate dummy trajectories, making them more authentic and providing better privacy protection for real trajectories, Although our approach has achieved some success in protecting user privacy, there are still some areas for improvement. Specifically, the challenges we faced included the sparsity of user historic trajectories, which made it relatively difficult to generate a sufficient number of virtual trajectories in some scenarios; at the same time, we also need to address the challenge of meeting the individual needs of different users, which requires us to further optimize the model to be more flexible in meeting user expectations in different scenarios.
In future work, we plan to extend the functionality of the system to provide enhanced privacy protection. This includes work in the following areas: (1) We will think about the possibility of filtering trajectories by sub-trajectory similarity in more dimensions and explore different distance computation methods in multiple dimensions to investigate more practical privacy-preserving solutions for trajectories. (2) Our emphasis will be on exploring the privacy-preserving impact of the algorithm when dealing with sparsely populated historic trajectories. Our objective is to tackle the challenges presented by sparse data to guarantee robust privacy preservation. (3) Our upcoming endeavors involve the creation of a personalized trajectory privacy protection model. This model will empower users to autonomously define the anonymization region for location points and determine the level of trajectory anonymization based on their unique privacy requirements. This approach aims to cater to the varied needs of distinct users and diverse scenarios.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}