
BézierCE: Low-Light Image Enhancement via Zero-Reference Bézier Curve Estimation

Abstract
:1. Introduction
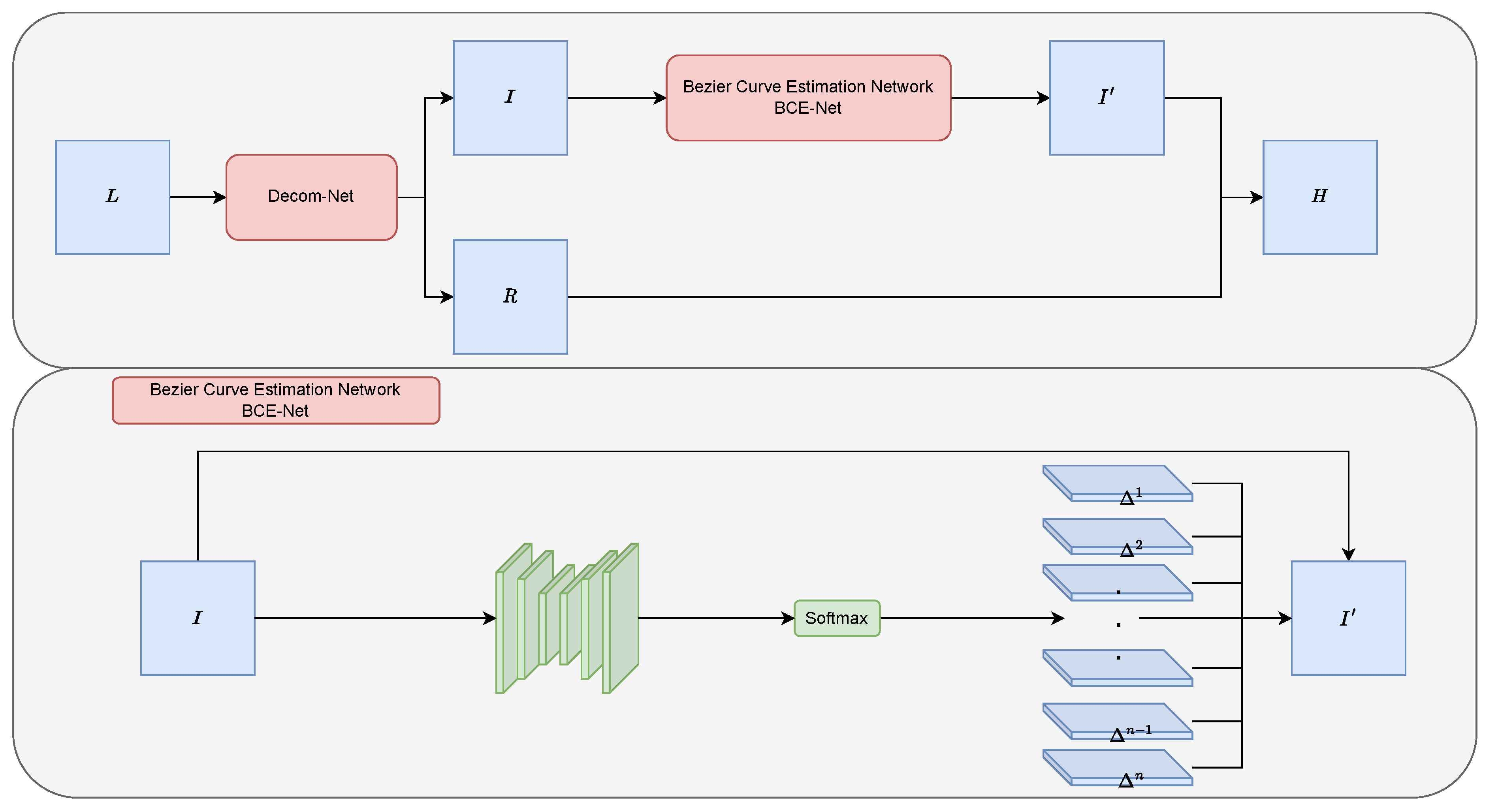
- Based on the good properties of the Bézier curve, we use it as the output for the dynamic adjustment of pixels. Compared with Zero-DCE, we overcome the overexposure problem.
- This paper proposes a zero-shot learning model with a short training time, which effectively avoids the risk of overfitting and improves the generalization ability.
- Experiments on a number of low-light image datasets reveal that our method outperforms some of the current state-of-the-art methods.
2. Related Works
2.1. Conventional Methods
2.1.1. Histogram Equalization Algorithms
2.1.2. Retinex Model-Based Methods
2.2. Deep Learning Methods
2.2.1. Supervised Learning
2.2.2. Unsupervised Learning
2.2.3. Semi-Supervised Learning
2.2.4. Reinforcement Learning
2.2.5. Zero-Shot Learning
3. Methodology
3.1. Decomposition
3.2. Bézier Curve Estimation
3.3. Non-Reference Loss Functions
3.3.1. Spatial Consistency Loss
3.3.2. Exposure Control Loss
3.3.3. Color Constancy Loss
3.3.4. Illumination Smoothness Loss
3.3.5. Total Loss
4. Experiment
4.1. Training Setting
4.2. Performance Criteria
4.3. Results
4.3.1. Qualitative Evaluation
4.3.2. Quantitative Comparison
4.4. Ablation Study
4.5. Time Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shyni, H.M.; Chitra, E. A comparative study of X-ray and ct images in COVID-19 detection using image processing and deep learning techniques. Comput. Methods Programs Biomed. Update 2022, 2, 100054. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3464–3473. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Buch, N.; Velastin, S.A.; Orwell, J. A review of computer vision techniques for the analysis of urban traffic. IEEE Trans. Intell. Transp. Syst. 2011, 12, 920–939. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Qi, G.J.; Gu, L.; You, S.; Zhang, Z.; Harada, T. Multitask aet with orthogonal tangent regularity for dark object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2553–2562. [Google Scholar]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Su, Y.; Wang, J.; Wang, X.; Hu, L.; Yao, Y.; Shou, W.; Li, D. Zero-reference deep learning for low-light image enhancement of underground utilities 3d reconstruction. Autom. Constr. 2023, 152, 104930. [Google Scholar] [CrossRef]
- Li, G.; Yang, Y.; Qu, X.; Cao, D.; Li, K. A deep learning based image enhancement approach for autonomous driving at night. Knowl. Based Syst. 2021, 213, 106617. [Google Scholar] [CrossRef]
- Ai, S.; Kwon, J. Extreme low-light image enhancement for surveillance cameras using attention u-net. Sensors 2020, 20, 495. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Ibrahim, H.; Kong, N.S.P. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Abdullah-Al-Wadud, M.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Arici, T.; Dikbas, S.; Altunbasak, Y. A histogram modification framework and its application for image contrast enhancement. IEEE Trans. Image Process. 2009, 18, 1921–1935. [Google Scholar] [CrossRef] [PubMed]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; Romeny, B.T.H.; Zimmerman, J.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vision Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Pisano, E.D.; Zong, S.; Hemminger, B.M.; DeLuca, M.; Johnston, R.E.; Muller, K.; Braeuning, M.P.; Pizer, S.M. Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms. J. Digit. Imaging 1998, 11, 193–200. [Google Scholar] [CrossRef] [PubMed]
- Celik, T.; Tjahjadi, T. Contextual and variational contrast enhancement. IEEE Trans. Image Process. 2011, 20, 3431–3441. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Lee, C.; Kim, C.S. Contrast enhancement based on layered difference representation of 2d histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef]
- Chen, S.D.; Ramli, A.R. Minimum mean brightness error bi-histogram equalization in contrast enhancement. IEEE Trans. Consum. Electron. 2003, 49, 1310–1319. [Google Scholar] [CrossRef]
- Kim, Y.T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 43, 1–8. [Google Scholar]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Kimmel, R.; Elad, M.; Shaked, D.; Keshet, R.; Sobel, I. A variational framework for retinex. Int. J. Comput. Vis. 2003, 52, 7–23. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Ding, X.; Zhang, X.P. A variational framework for single low light image enhancement using bright channel prior. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 1085–1088. [Google Scholar]
- Park, S.; Yu, S.; Moon, B.; Ko, S.; Paik, J. Low-light image enhancement using variational optimization-based retinex model. IEEE Trans. Consum. Electron. 2017, 63, 178–184. [Google Scholar] [CrossRef]
- Fu, G.; Duan, L.; Xiao, C. A hybrid L2-Lp variational model for single low-light image enhancement with bright channel prior. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, China, 22–25 September 2019; pp. 1925–1929. [Google Scholar]
- Zhang, Y.; Di, X.; Zhang, B.; Wang, C. Self-supervised image enhancement network: Training with low light images only. arXiv 2020, arXiv:2002.11300. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLnet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recogn. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Tao, L.; Zhu, C.; Xiang, G.; Li, Y.; Jia, H.; Xie, X. LLcnn: A convolutional neural network for low-light image enhancement. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Ignatov, A.; Kobyshev, N.; Timofte, R.; Vanhoey, K.; Van Gool, L. Dslr-quality photos on mobile devices with deep convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3277–3285. [Google Scholar]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. Msr-net: Low-light image enhancement using deep convolutional network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. Lightennet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recogn. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, Q.; Fu, C.W.; Shen, X.; Zheng, W.S.; Jia, J. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 6849–6857. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Eemefn: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13106–13113. [Google Scholar]
- Li, J.; Li, J.; Fang, F.; Li, F.; Zhang, G. Luminance-aware pyramid network for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 3153–3165. [Google Scholar] [CrossRef]
- Wang, L.W.; Liu, Z.S.; Siu, W.C.; Lun, D.P. Lightening network for low-light image enhancement. IEEE Trans. Image Process. 2020, 29, 7984–7996. [Google Scholar] [CrossRef]
- Li, J.; Feng, X.; Hua, Z. Low-light image enhancement via progressive-recursive network. IEEE Trans. Circ. Syst. Video Technol. 2021, 31, 4227–4240. [Google Scholar] [CrossRef]
- Fu, Y.; Hong, Y.; Chen, L.; You, S. LE-GAN: Unsupervised low-light image enhancement network using attention module and identity invariant loss. Knowl. Based Syst. 2022, 240, 108010. [Google Scholar] [CrossRef]
- Xiong, W.; Liu, D.; Shen, X.; Fang, C.; Luo, J. Unsupervised low-light image enhancement with decoupled networks. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 457–463. [Google Scholar]
- Han, G.; Zhou, Y.; Zeng, F. Unsupervised learning based dual-branch fusion low-light image enhancement. Multimed. Tools Appl. 2023, 82, 37593–37614. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3063–3072. [Google Scholar]
- Chen, J.; Wang, Y.; Han, Y. A semi-supervised network framework for low-light image enhancement. Eng. Appl. Artif. Intell. 2023, 126, 107003. [Google Scholar] [CrossRef]
- Malik, S.; Soundararajan, R. Semi-supervised learning for low-light image restoration through quality assisted pseudo-labeling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 4105–4114. [Google Scholar]
- Yu, R.; Liu, W.; Zhang, Y.; Qu, Z.; Zhao, D.; Zhang, B. Deepexposure: Learning to expose photos with asynchronously reinforced adversarial learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 2153–2163. [Google Scholar]
- Zhang, R.; Guo, L.; Huang, S.; Wen, B. Rellie: Deep reinforcement learning for customized low-light image enhancement. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 2429–2437. [Google Scholar]
- Cotogni, M.; Cusano, C. Treenhance: A tree search method for low-light image enhancement. Pattern Recogn. 2023, 136, 109249. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Liu, X.; Shen, Y.; Zhang, S.; Zhao, S. Zero-shot restoration of back-lit images using deep internal learning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1623–1631. [Google Scholar]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Zhao, Z.; Xiong, B.; Wang, L.; Ou, Q.; Yu, L.; Kuang, F. Retinexdip: A unified deep framework for low-light image enhancement. IEEE Trans. Circ. Syst. Video Technol. 2021, 32, 1076–1088. [Google Scholar] [CrossRef]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Zheng, S.; Gupta, G. Semantic-guided zero-shot learning for low-light image/video enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 581–590. [Google Scholar]
- Gao, X.; Zhang, M.; Luo, J. Low-light image enhancement via retinex-style decomposition of denoised deep image prior. Sensors 2022, 22, 5593. [Google Scholar] [CrossRef]
- Xie, C.; Tang, H.; Fei, L.; Zhu, H.; Hu, Y. IRNet: An improved zero-shot retinex network for low-light image enhancement. Electronics 2023, 12, 3162. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Loy, C.C. Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4225–4238. [Google Scholar] [CrossRef]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Gu, K.; Tao, D.; Qiao, J.F.; Lin, W. Learning a no-reference quality assessment model of enhanced images with big data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1301–1313. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2782–2790. [Google Scholar]
- Lee, C.; Lee, C.; Lee, Y.Y.; Kim, C.S. Power-constrained contrast enhancement for emissive displays based on histogram equalization. IEEE Trans. Image Process. 2011, 21, 80–93. [Google Scholar] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Params | Input Dim | Output Dim | Activate Function | Input Layer |
|---|---|---|---|---|---|
| Max | - | (3,H,W) | (1,H,W) | - | Input |
| Conv0 | (4,64,9,9) | (4,H,W) | (64,H,W) | ReLU | Cat (Input,Max) |
| Conv1 | (64,64,3,3) | (64,H,W) | (64,H,W) | ReLU | Conv0 |
| Conv2 | (64,64,3,3) | (64,H,W) | (64,H,W) | ReLU | Conv1 |
| Conv3 | (64,64,3,3) | (64,H,W) | (64,H,W) | ReLU | Conv2 |
| Conv4 | (64,64,3,3) | (64,H,W) | (64,H,W) | ReLU | Conv3 |
| Conv5 | (64,64,3,3) | (64,H,W) | (64,H,W) | ReLU | Conv4 |
| Conv6 | (64,4,3,3) | (64,H,W) | (4,H,W) | Sigmoid | Conv5 |
| Split | - | (4,H,W) | R:(3,H,W); I:(1,H,W) | - | Conv6 |
| Layer | Params | Input Dim | Output Dim | Activate Function | Input Layer |
|---|---|---|---|---|---|
| Conv0 | (1,32,3,3) | (1,H,W) | (32,H,W) | ReLU | Input |
| Conv1 | (32,32,3,3) | (32,H,W) | (32,H,W) | ReLU | Conv0 |
| Conv2 | (32,32,3,3) | (32,H,W) | (32,H,W) | ReLU | Conv1 |
| Conv3 | (32,32,3,3) | (32,H,W) | (32,H,W) | ReLU | Conv2 |
| Conv4 | (64,32,3,3) | (64,H,W) | (32,H,W) | ReLU | Cat(Conv2,Conv3) |
| Conv5 | (64,32,3,3) | (64,H,W) | (32,H,W) | ReLU | Cat(Conv1,Conv4) |
| Conv6 | (64,t,3,3) | (64,H,W) | (t,H,W) | - | Cat(Conv0,Conv5) |
| Softmax | - | - | - | - | Conv6 |
| Learning | Method | DICM | LIME | MEF | NPE | VV |
|---|---|---|---|---|---|---|
| CM | LIME | 3.5360 | 4.1423 | 3.7022 | 4.2625 | 2.7475 |
| NPE | 3.4530 | 3.9031 | 3.5155 | 3.9501 | 3.0290 | |
| SRIE | 3.5768 | 3.7868 | 3.4742 | 3.9883 | 3.1357 | |
| SL | KinD | 4.2691 | 4.3525 | 4.1318 | 3.9589 | 3.4255 |
| ZSL | Zero-DCE | 3.6091 | 3.9354 | 3.4044 | 4.0944 | 3.2245 |
| Ours | 3.6334 | 3.8553 | 3.3939 | 3.9021 | 3.1680 |
| Learning | Method | DICM | LIME | MEF | NPE | VV |
|---|---|---|---|---|---|---|
| CM | LIME | 0.8986 | 1.0882 | 1.0385 | 0.9844 | 0.9555 |
| NPE | 0.9139 | 1.0812 | 1.0372 | 1.0228 | 0.9557 | |
| SRIE | 0.9056 | 1.1121 | 1.0967 | 1.0258 | 0.9629 | |
| SL | KinD | 0.7459 | 0.8336 | 0.7877 | 0.8007 | 0.7418 |
| ZSL | Zero-DCE | 0.7818 | 0.9803 | 0.9461 | 0.8578 | 0.8396 |
| Ours | 0.8591 | 1.1016 | 1.0544 | 1.0135 | 0.9402 |
| Learning | Method | DICM | LIME | MEF | NPE | VV |
|---|---|---|---|---|---|---|
| CM | LIME | 1.6156 | 5.7242 | 0.8649 | 1.5840 | 0.4898 |
| NPE | 1.8238 | 3.8316 | 1.2291 | 1.5272 | 0.5843 | |
| SRIE | 1.7111 | 2.6850 | 0.8935 | 1.0207 | 0.7014 | |
| SL | KinD | 1.2968 | 2.9960 | 0.5795 | 1.9315 | 0.5780 |
| ZSL | Zero-DCE | 2.1590 | 5.1292 | 1.0877 | 0.9627 | 0.5733 |
| Ours | 2.2209 | 2.5713 | 1.0417 | 1.1559 | 0.7503 |
| Learning | Method | DICM | LIME | MEF | NPE | VV |
|---|---|---|---|---|---|---|
| CM | LIME | 0.0117 | 0.0138 | 0.0097 | 0.0040 | 0.0043 |
| NPE | 0.0064 | 0.0210 | 0.0154 | 0.0062 | 0.0045 | |
| SRIE | 0.0034 | 0.0123 | 0.0082 | 0.0112 | 0.0052 | |
| SL | KinD | 0.0061 | 0.0153 | 0.0043 | 0.0093 | 0.0032 |
| ZSL | Zero-DCE | 0.0150 | 0.0209 | 0.0135 | 0.0108 | 0.0102 |
| Ours | 0.0022 | 0.0091 | 0.0035 | 0.0043 | 0.0032 |
| Method | () | () | () | () | () |
|---|---|---|---|---|---|
| LIME | 0.1133 | 0.4196 | 1.0148 | 1.5713 | 2.3901 |
| NPE | 5.8861 | 26.6340 | 58.5019 | 104.8345 | 163.9938 |
| SRIE | 4.7643 | 33.6684 | 121.5802 | 343.9839 | 726.5981 |
| KinD | 0.1554 | 0.0464 | - | - | - |
| Zero-DCE | 0.12559 | 0.1390 | 0.2539 | 0.4051 | 0.83371 |
| Ours | 0.0301 | 0.0325 | 0.0724 | 0.1192 | 0.1882 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Zhao, K.; Han, L.; Luo, J. BézierCE: Low-Light Image Enhancement via Zero-Reference Bézier Curve Estimation. Sensors 2023, 23, 9593. https://doi.org/10.3390/s23239593
Gao X, Zhao K, Han L, Luo J. BézierCE: Low-Light Image Enhancement via Zero-Reference Bézier Curve Estimation. Sensors. 2023; 23(23):9593. https://doi.org/10.3390/s23239593
Chicago/Turabian StyleGao, Xianjie, Kai Zhao, Lei Han, and Jinming Luo. 2023. "BézierCE: Low-Light Image Enhancement via Zero-Reference Bézier Curve Estimation" Sensors 23, no. 23: 9593. https://doi.org/10.3390/s23239593