

A Light Vehicle License-Plate-Recognition System Based on Hybrid Edge–Cloud Computing

 ,
, 
Abstract
:1. Introduction
2. Related Work
2.1. License Plate Detection Algorithm
2.2. License Plate Recognition
2.3. Lightweight Object Detection Model
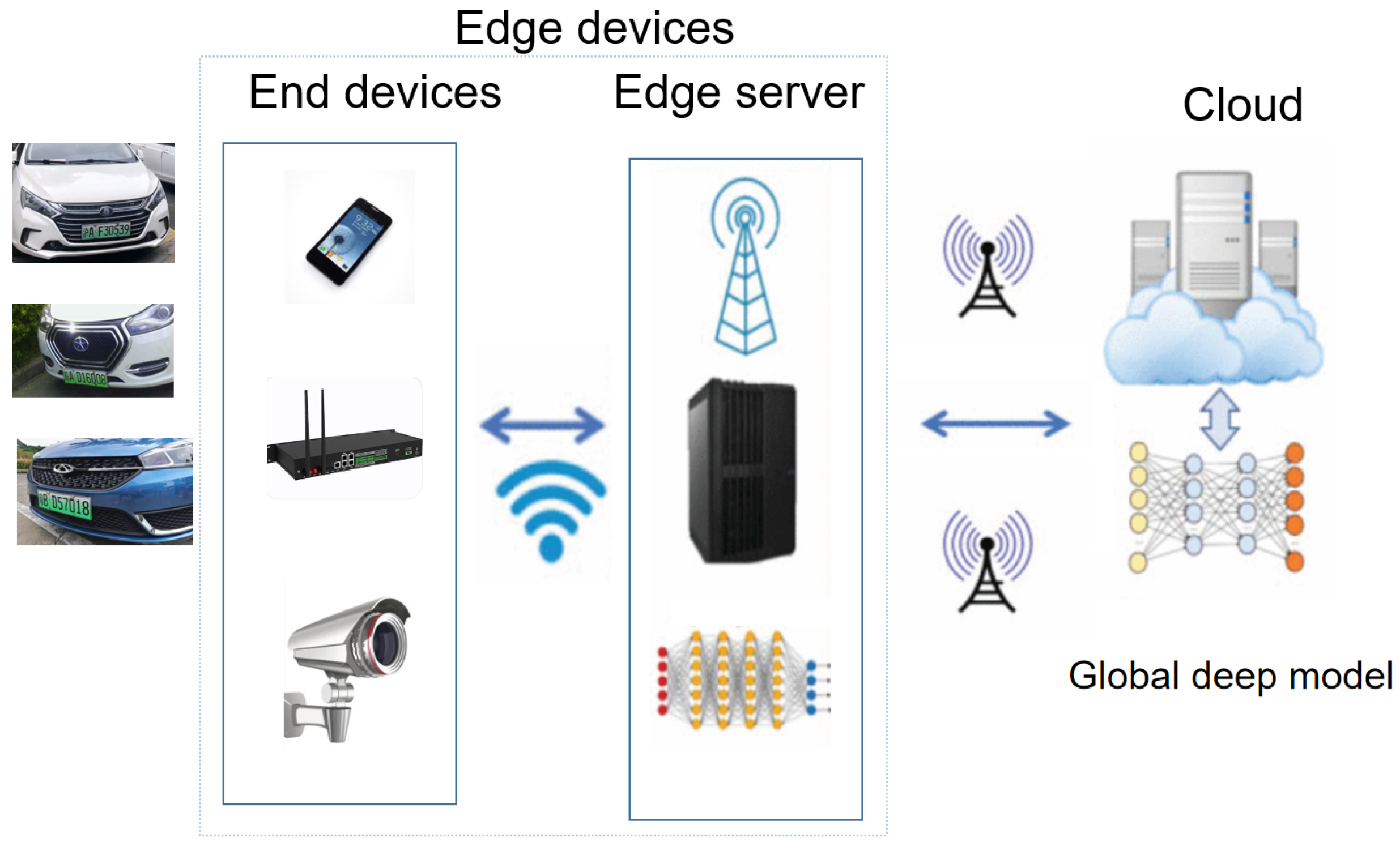
2.4. Object Detection Application at the Edge Platform
3. Method
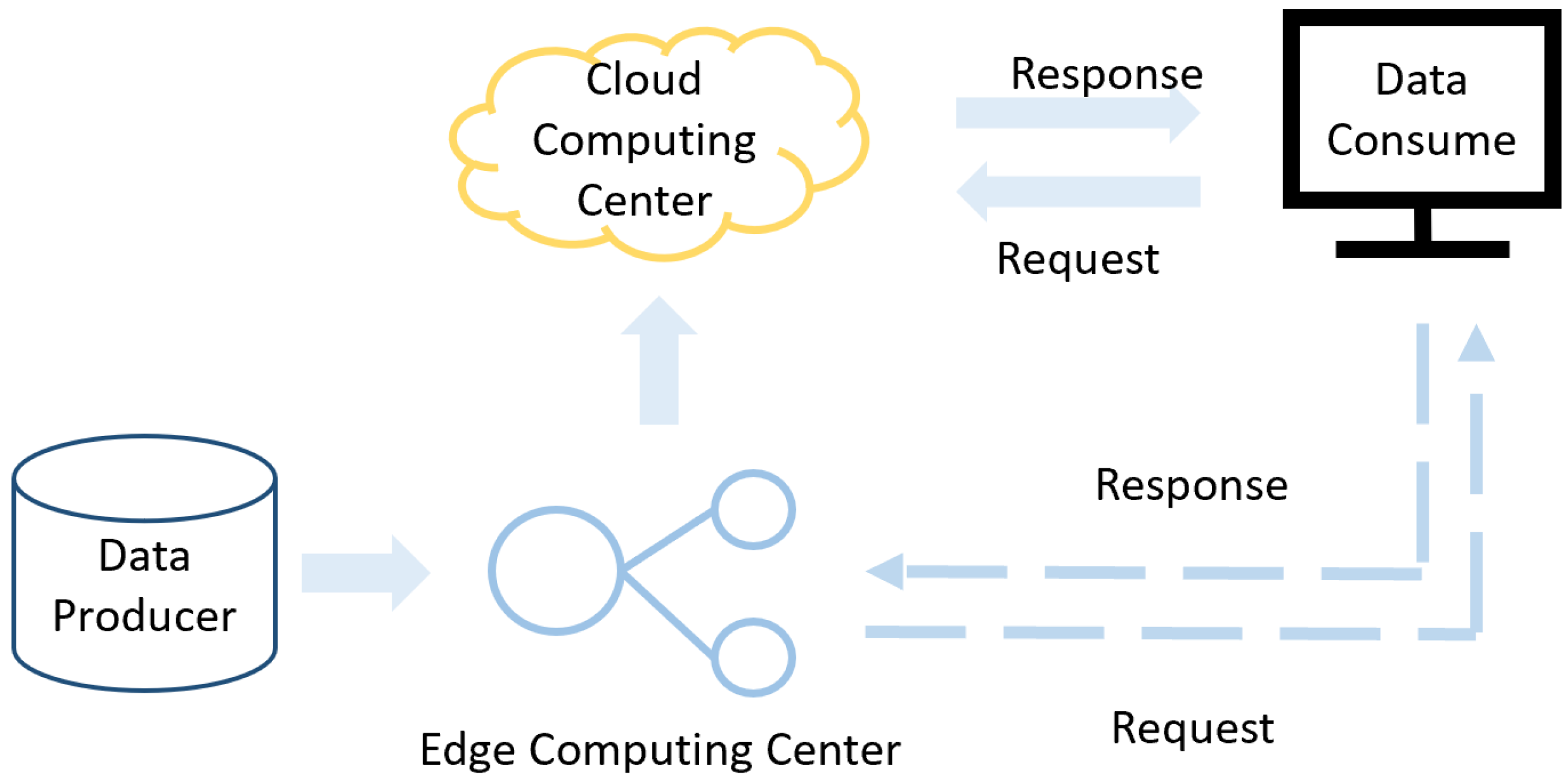
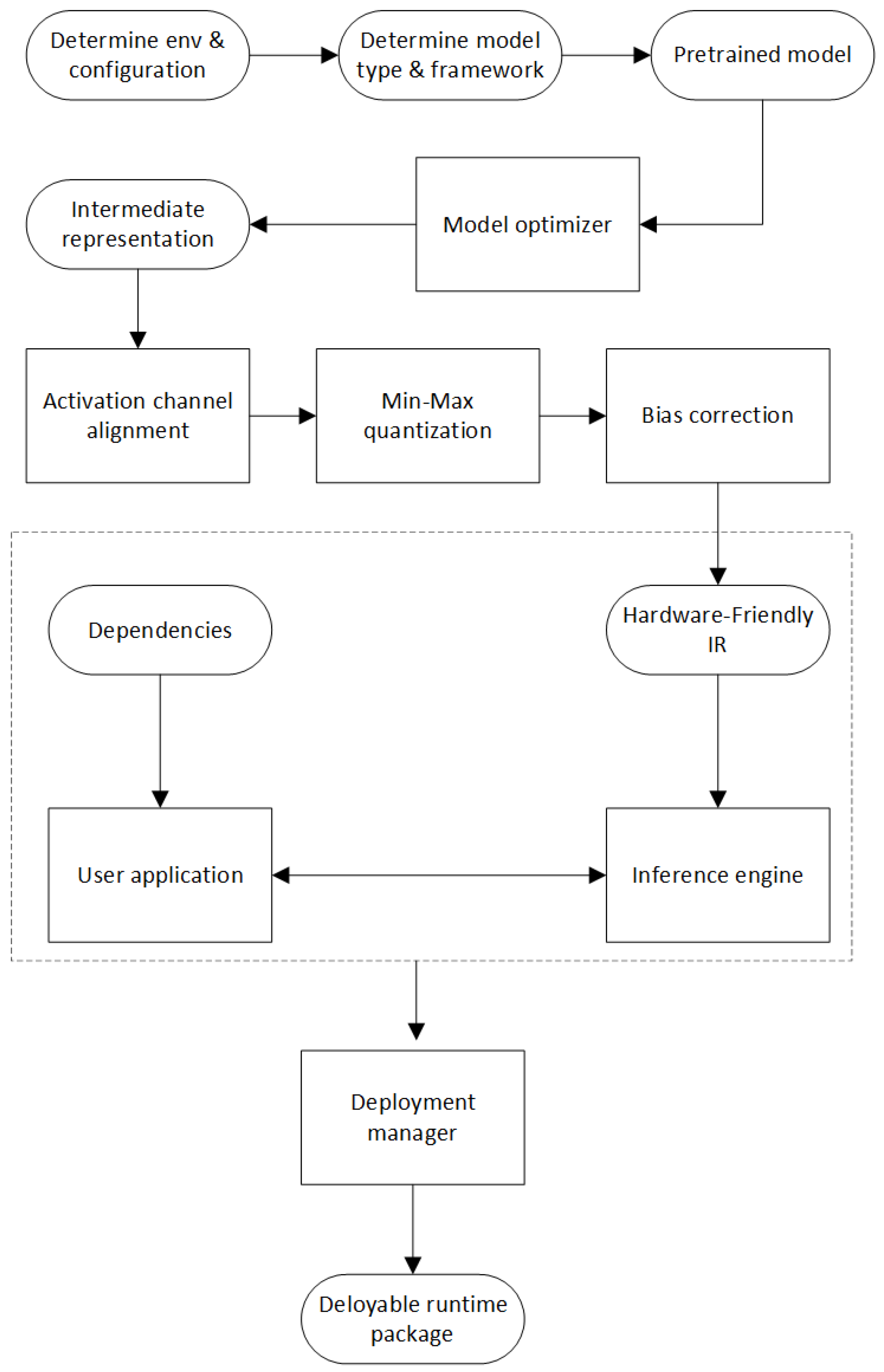
3.1. Comparative Design of System Platforms
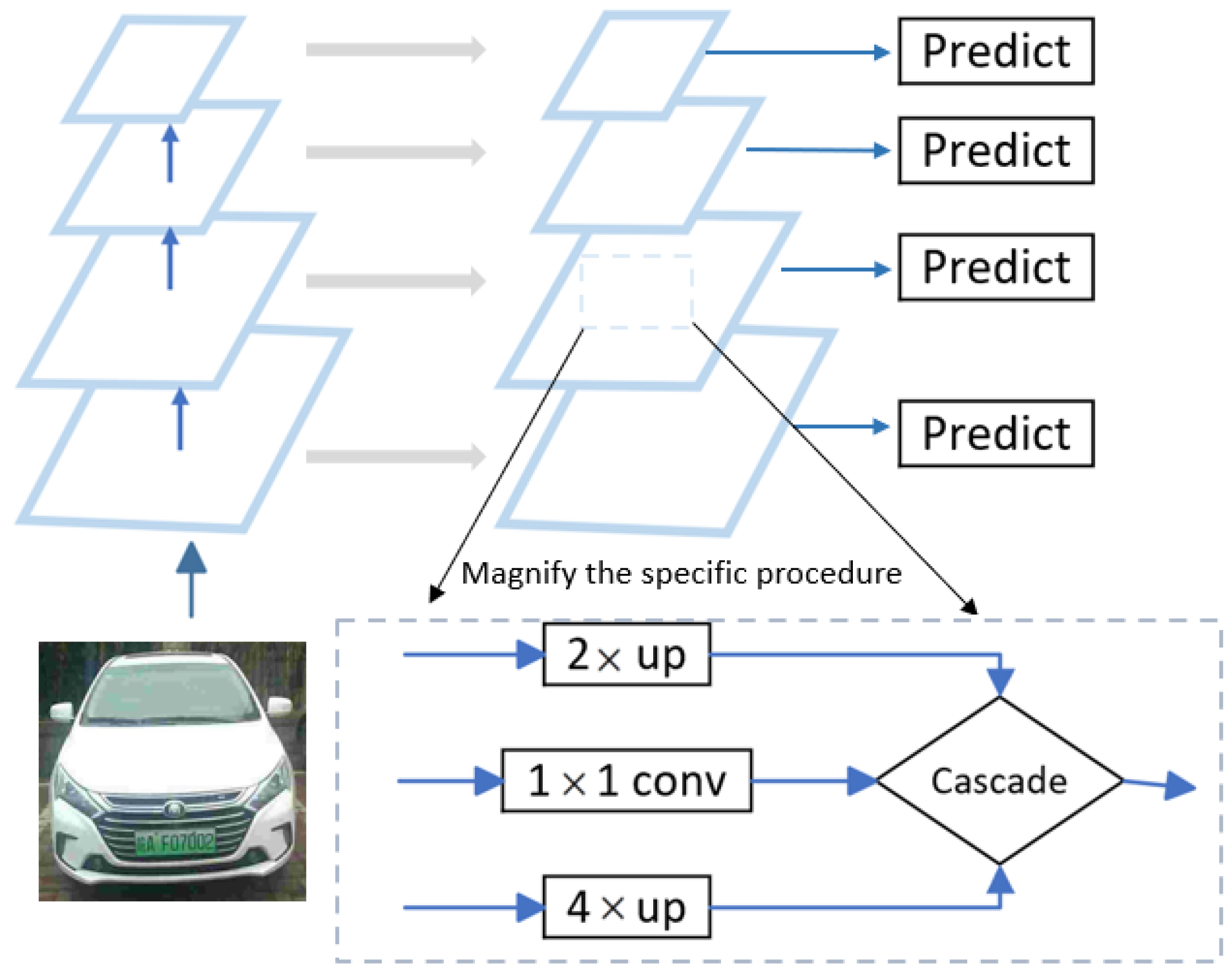
3.2. License Plate Detection
| Algorithm 1 Soft-NMS method. |
|
Input: B is a list of the initial detection boxes C contains a list of corresponding detection scores relates to is the NMS threshold Output: Final detection Bounding box list S
|
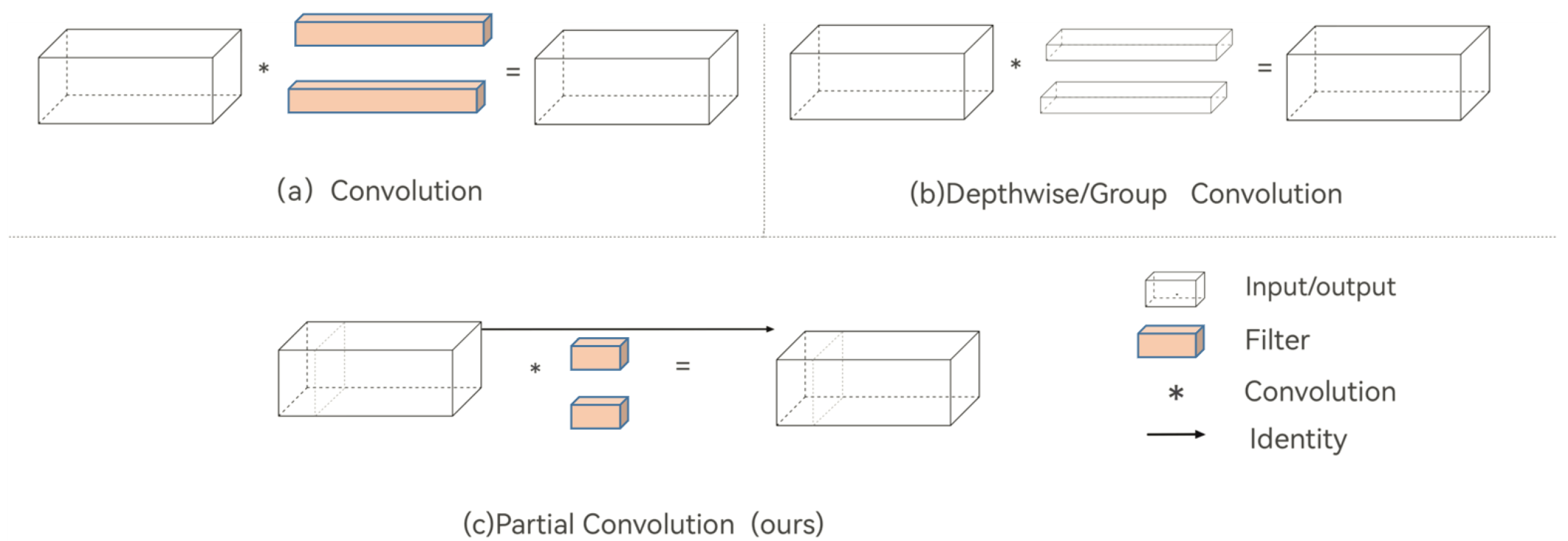
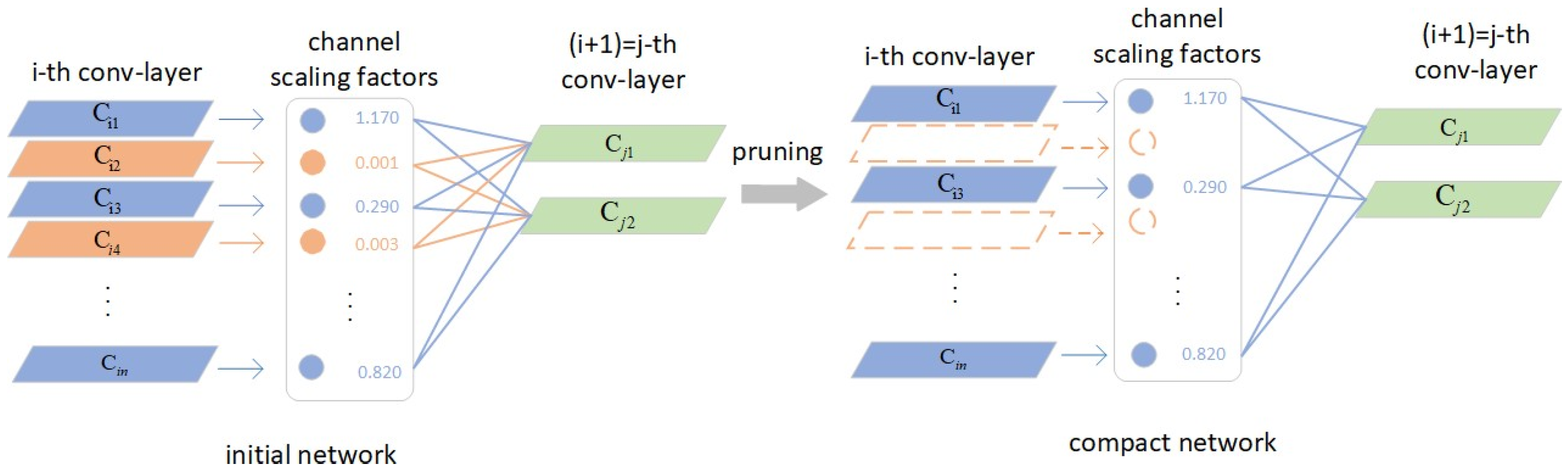
3.3. Model Compression
| Algorithm 2 Compression of Edge–LPR algorithm. |
|
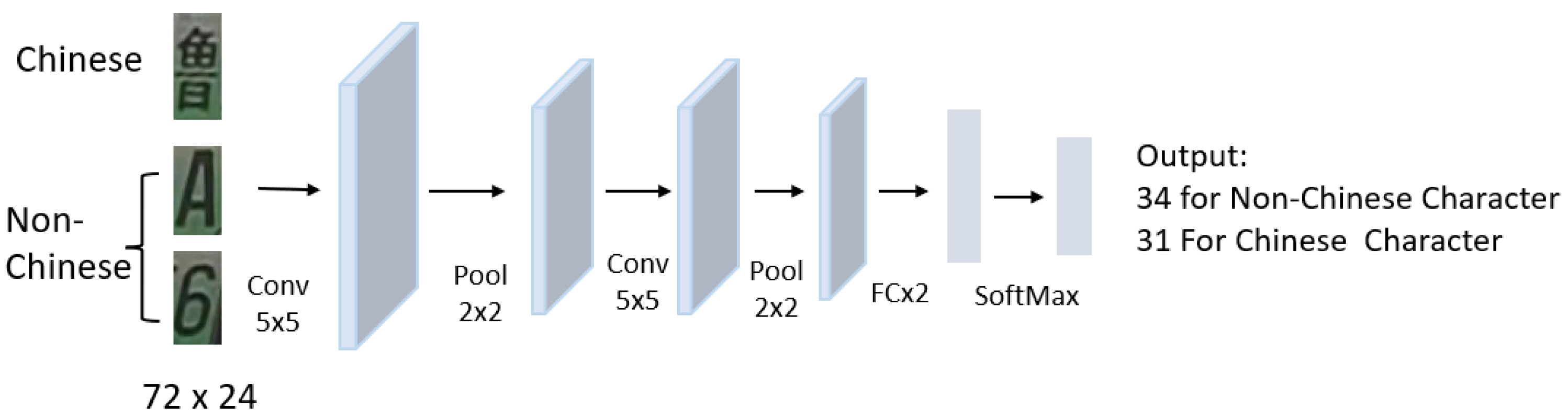
3.4. License Plate Recognition
3.5. Edge Computing
4. Result and Discussion
4.1. Dataset Description
4.2. Model Training
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gao, L.; Zhang, W. Research on License Plate Detection and Recognition Based on Deep Learning. In Proceedings of the 2021 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), Shanghai, China, 27–29 August 2021; pp. 410–415. [Google Scholar] [CrossRef]
- Zhu, G.; Liu, D.; Du, Y.; You, C.; Zhang, J.; Huang, K. Toward an Intelligent Edge: Wireless Communication Meets Machine Learning. IEEE Commun. Mag. 2020, 58, 19–25. [Google Scholar] [CrossRef]
- Mukherjee, M.; Matam, R.; Mavromoustakis, C.X.; Jiang, H.; Mastorakis, G.; Guo, M. Intelligent Edge Computing: Security and Privacy Challenges. IEEE Commun. Mag. 2020, 58, 26–31. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef]
- Ning, Z.; Zhang, K.; Wang, X.; Guo, L.; Hu, X.; Huang, J.; Hu, B.; Kwok, R.Y.K. Intelligent Edge Computing in Internet of Vehicles: A Joint Computation Offloading and Caching Solution. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2212–2225. [Google Scholar] [CrossRef]
- Hung, J.M.; Li, X.; Wu, J.; Chang, M.F. Challenges and Trends inDeveloping Nonvolatile Memory-Enabled Computing Chips for Intelligent Edge Devices. IEEE Trans. Electron Devices 2020, 67, 1444–1453. [Google Scholar] [CrossRef]
- Dong, C.; Shen, Y.; Qu, Y.; Wang, K.; Zheng, J.; Wu, Q.; Wu, F. UAVs as an Intelligent Service: Boosting Edge Intelligence for Air-Ground Integrated Networks. IEEE Netw. 2021, 35, 167–175. [Google Scholar] [CrossRef]
- Tian, H.; Wang, T.; Liu, Y.; Qiao, X.; Li, Y. Computer vision technology in agricultural automation—A review. Inf. Process. Agric. 2020, 7, 1–19. [Google Scholar] [CrossRef]
- Hua, X.; Cui, X.; Xu, X.; Qiu, S.; Liang, Y.; Bao, X.; Li, Z. Underwater object detection algorithm based on feature enhancement and progressive dynamic aggregation strategy. Pattern Recognit. 2023, 139, 109511. [Google Scholar] [CrossRef]
- Bai, T.; Yang, J.; Xu, G.; Yao, D. An optimized railway fastener detection method based on modified Faster R-CNN. Measurement 2021, 182, 109742. [Google Scholar] [CrossRef]
- Chu, P.; Li, Z.; Lammers, K.; Lu, R.; Liu, X. Deep learning-based apple detection using a suppression mask R-CNN. Pattern Recognit. Lett. 2021, 147, 206–211. [Google Scholar] [CrossRef]
- Li, G.; Huang, Y.; Chen, Z.; Chesser, G.D.; Purswell, J.L.; Linhoss, J.; Zhao, Y. Practices and Applications of Convolutional Neural Network-Based Computer Vision Systems in Animal Farming: A Review. Sensors 2021, 21, 1492. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Yao, J.; Xu, Z.; Meng, D. Hyperspectral Image Classification With Convolutional Neural Network and Active Learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4604–4616. [Google Scholar] [CrossRef]
- Fan, X.; Zhao, W. Improving robustness of license plates automatic recognition in natural scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18845–18854. [Google Scholar] [CrossRef]
- Wang, Q.; Lu, X.; Zhang, C.; Yuan, Y.; Li, X. LSV-LP: Large-Scale Video-Based License Plate Detection and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 752–767. [Google Scholar] [CrossRef]
- Su, H.; Wei, S.; Yan, M.; Wang, C.; Shi, J.; Zhang, X. Object Detection and Instance Segmentation in Remote Sensing Imagery Based on Precise Mask R-CNN. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2019), Yokohama, Japan, 28 July–2 August 2019; pp. 1454–1457. [Google Scholar] [CrossRef]
- Ghaderizadeh, S.; Abbasi-Moghadam, D.; Sharifi, A.; Zhao, N.; Tariq, A. Hyperspectral Image Classification Using a Hybrid 3D-2D Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7570–7588. [Google Scholar] [CrossRef]
- Rao, B.S. Dynamic Histogram Equalization for contrast enhancement for digital images. Appl. Soft Comput. 2020, 89, 106114. [Google Scholar] [CrossRef]
- Zheng, Z.; Ren, W.; Cao, X.; Hu, X.; Wang, T.; Song, F.; Jia, X. Ultra-High-Definition Image Dehazing via Multi-Guided Bilateral Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16180–16189. [Google Scholar] [CrossRef]
- Mazur, K.; Sucar, E.; Davison, A.J. Feature-Realistic Neural Fusion for Real-Time, Open Set Scene Understanding. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 8201–8207. [Google Scholar] [CrossRef]
- Yue, X.; Li, H.; Meng, L. An Ultralightweight Object Detection Network for Empty-Dish Recycling Robots. IEEE Trans. Instrum. Meas. 2023, 72, 2505612. [Google Scholar] [CrossRef]
- Zhang, Z.Y.; Zhao, P.; Jiang, Y.; Zhou, Z.H. Learning From Incomplete and Inaccurate Supervision. IEEE Trans. Knowl. Data Eng. 2022, 34, 5854–5868. [Google Scholar] [CrossRef]
- Bi, R.; Xiong, J.; Tian, Y.; Li, Q.; Choo, K.K.R. Achieving Lightweight and Privacy-Preserving Object Detection for Connected Autonomous Vehicles. IEEE Internet Things J. 2023, 10, 2314–2329. [Google Scholar] [CrossRef]
- Cao, J.; Feng, Y.; Zheng, R.; Cui, X.; Zhao, W.; Jiang, T.; Gao, F. Two-Stream Attention 3-D Deep Network-Based Childhood Epilepsy Syndrome Classification. IEEE Trans. Instrum. Meas. 2023, 72, 2503412. [Google Scholar] [CrossRef]
- Wang, D.; Tian, Y.; Geng, W.; Zhao, L.; Gong, C. LPR-Net: Recognizing Chinese license plate in complex environments. Pattern Recognit. Lett. 2020, 130, 148–156. [Google Scholar] [CrossRef]
- Li, Q.; Bi, Y.; Cai, R.; Li, J. Occluded pedestrian detection through bi-center prediction in anchor-free network. Neurocomputing 2022, 507, 199–207. [Google Scholar] [CrossRef]
- Hsieh, C.Y.; Ren, Y.; Chen, J.C. Edge-Cloud Offloading: Knapsack Potential Game in 5G Multi-Access Edge Computing. IEEE Trans. Wirel. Commun. 2023, 1. [Google Scholar] [CrossRef]
- Smyrnis, G.; Maragos, P.; Retsinas, G. Maxpolynomial Division with Application To Neural Network Simplification. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2020), Barcelona, Spain, 4–8 May 2020; pp. 4192–4196. [Google Scholar] [CrossRef]
- He, Y.; Dong, X.; Kang, G.; Fu, Y.; Yan, C.; Yang, Y. Asymptotic Soft Filter Pruning for Deep Convolutional Neural Networks. IEEE Trans. Cybern. 2020, 50, 3594–3604. [Google Scholar] [CrossRef]
- Li, H.; Wang, P.; Shen, C. Toward End-to-End Car License Plate Detection and Recognition with Deep Neural Networks. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1126–1136. [Google Scholar] [CrossRef]
- Feng, S.; Feng, R.; Liu, J.; Zhao, C.; Xiong, F.; Zhang, L. An Attention-Based Multiscale Spectral—Spatial Network for Hyperspectral Target Detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5503705. [Google Scholar] [CrossRef]
- Yang, L.; Shan, X.; Lv, C.; Brighton, J.; Zhao, Y. Learning Spatio-Temporal Representations With a Dual-Stream 3-D Residual Network for Nondriving Activity Recognition. IEEE Trans. Ind. Electron. 2022, 69, 7405–7414. [Google Scholar] [CrossRef]
- Huang, X.; Li, S.; Li, J.; Jia, X.; Li, J.; Zhu, X.X.; Benediktsson, J.A. A Multispectral and Multiangle 3-D Convolutional Neural Network for the Classification of ZY-3 Satellite Images Over Urban Areas. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10266–10285. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, L.; Ma, T.; Shen, F.; Cai, Y.; Zhou, C. A self-training semi-supervised machine learning method for predictive mapping of soil classes with limited sample data. Geoderma 2021, 384, 114809. [Google Scholar] [CrossRef]
- Musikawan, P.; Kongsorot, Y.; You, I.; So-In, C. An Enhanced Deep Learning Neural Network for the Detection and Identification of Android Malware. IEEE Internet Things J. 2023, 10, 8560–8577. [Google Scholar] [CrossRef]
- Jiang, Y.; Jiang, F.; Luo, H.; Lin, H.; Yao, J.; Liu, J.; Ren, J. An Efficient and Unified Recognition Method for Multiple License Plates in Unconstrained Scenarios. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5376–5389. [Google Scholar] [CrossRef]
- Gao, J.; Wang, H.; Shen, H. Machine Learning Based Workload Prediction in Cloud Computing. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Liu, X.; Liu, W.; Ma, H.; Fu, H. Large-scale vehicle re-identification in urban surveillance videos. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, B.; Sun, Y.; Li, S.; Cao, Q. Hierarchical Matching With Peer Effect for Low-Latency and High-Reliable Caching in Social IoT. IEEE Internet Things J. 2019, 6, 1193–1209. [Google Scholar] [CrossRef]
- Chen, C.; Liu, X.; Qiu, T.; Sangaiah, A.K. A short-term traffic prediction model in the vehicular cyber—Physical systems. Future Gener. Comput. Syst. 2020, 105, 894–903. [Google Scholar] [CrossRef]
- Gao, H.; Xu, Y.; Yin, Y.; Zhang, W.; Li, R.; Wang, X. Context-Aware QoS Prediction With Neural Collaborative Filtering for Internet-of-Things Services. IEEE Internet Things J. 2020, 7, 4532–4542. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M.; Elhoseny, M.; Song, H. ST-DeepHAR: Deep Learning Model for Human Activity Recognition in IoHT Applications. IEEE Internet Things J. 2021, 8, 4969–4979. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CCPD 2020 | Ours |
|---|---|---|
| Classes | 2 | 2 |
| Train dataset | 5769 | 2652 |
| Test dataset | 1001 | 650 |
| Validation dataset | 5006 | 1847 |
| Parameter | Values |
|---|---|
| Weight decay | 0.0005 |
| Batch size | 16 |
| Learning rate | 0.01 |
| Epoch | 200 |
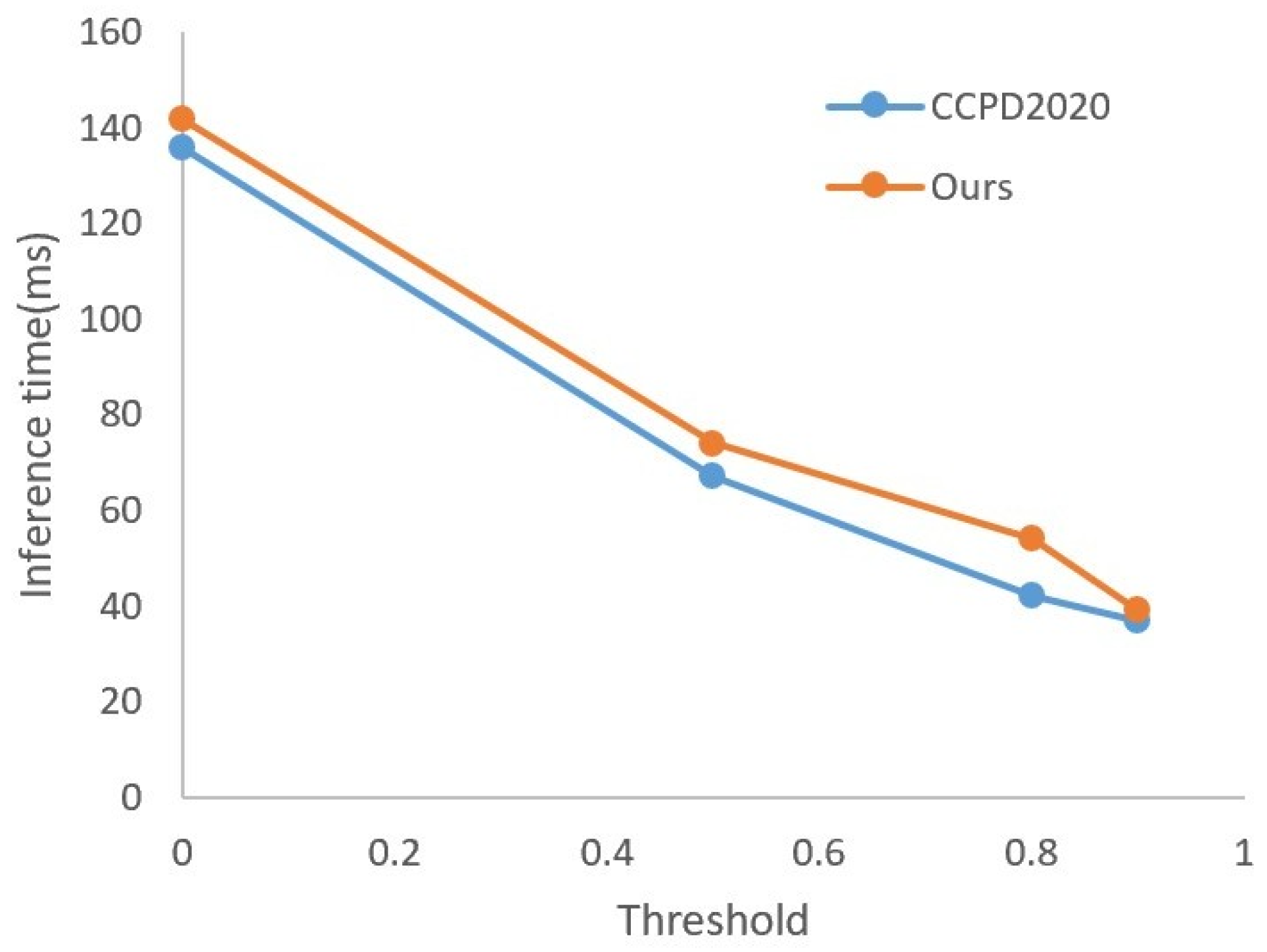
| Threshold | 0 | 0.5 | 0.8 | 0.9 |
|---|---|---|---|---|
| Params (MB) | 36.6 | 19.5 | 12.2 | 8.1 |
| Model storage size (MB) | 74.8 | 37.2 | 14.7 | 8.2 |
| Speed/GPU (ms) | 17 | 12 | 11 | 9 |
| Speed/CPU (ms) | 154 | 86 | 58 | 41 |
| mAP (%) | 97.1 | 96.5 | 96.2 | 95.6 |
| Threshold | 0 | 0.5 | 0.8 | 0.9 |
|---|---|---|---|---|
| Params (MB) | 36.6 | 23.5 | 12.3 | 8.3 |
| Model storage size (MB) | 74.8 | 37.3 | 14.0 | 8.1 |
| Speed/GPU (ms) | 26 | 18 | 15 | 11 |
| Speed/CPU (ms) | 168 | 98 | 64 | 52 |
| mAP (%) | 96.1 | 95.5 | 95.2 | 94.6 |
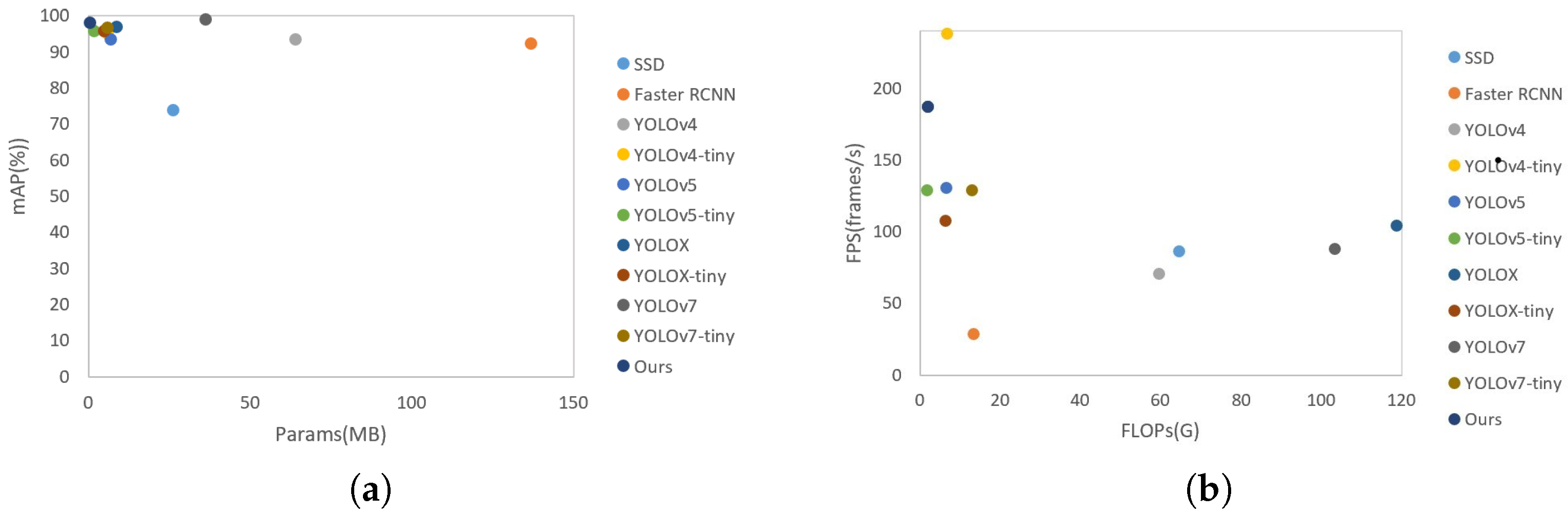
| Detection Algorithm | mAP (%) | F1 | Params (MB) | FLOPs (G) | Speed (FPS) |
|---|---|---|---|---|---|
| SSD | 73.82 | 0.725 | 26.285 | 64.818 | 86.174 |
| Faster RCNN | 92.25 | 0.891 | 137.057 | 13.52 | 28.405 |
| YOLOv4 | 93.48 | 0.872 | 64.106 | 59.851 | 70.622 |
| YOLOv4-tiny | 95.07 | 0.916 | 5.924 | 6.862 | 238.151 |
| YOLOv5 | 93.48 | 0.928 | 7.093 | 6.76 | 130.069 |
| YOLOv5-tiny | 95.77 | 0.919 | 1.821 | 1.796 | 128.555 |
| YOLOX | 96.92 | 0.928 | 8.968 | 118.965 | 104.149 |
| YOLOX-tiny | 95.65 | 0.931 | 5.056 | 6.41 | 107.208 |
| YOLOv7 | 98.83 | 0.945 | 36.49 | 103.5 | 87.624 |
| EfficientDet | 95.62 | 0.938 | 3.9 | 2.5 | 16.25 |
| DFF | 87.68 | 0.897 | 144 | 160 | 35.48 |
| Edge–LPR (ours) | 95.6 | 0.914 | 1.1 | 5.3 | 187.6 |
| Detection Algorithm | mAP (%) | Speed (FPS) |
|---|---|---|
| CA-CenterNet [17] | 96.8 | 52.7 |
| LSV-LP [18] | 89.3 | 112.56 |
| P2OD [25] | 97.52 | 108 |
| Li et al. [27] | 95.59 | 132.76 |
| MFLPR-Net [30] | 92.02 | 54 |
| Edge–LPR (Ours) | 95.6 | 187.6 |
| Computer Platform | Memory | GLOPS (FP16) | Thermal Design Power | Manufacturing Process |
|---|---|---|---|---|
| AMD Ryzen 7 5800H | 8 GB 64 bit DDR4 | 4600 | 45 W | 7 nm |
| Intel Core i711700K | 8 GB 64 bit LPDDR4x | 450 | 125 W | 10 nm |
| NVIDIA RTX2070 | 11 GB 35GDDR5X | 7500 | 175 W | 12 nm |
| NCS2 | 128 G | 4 | 1.5 W | 28 nm |
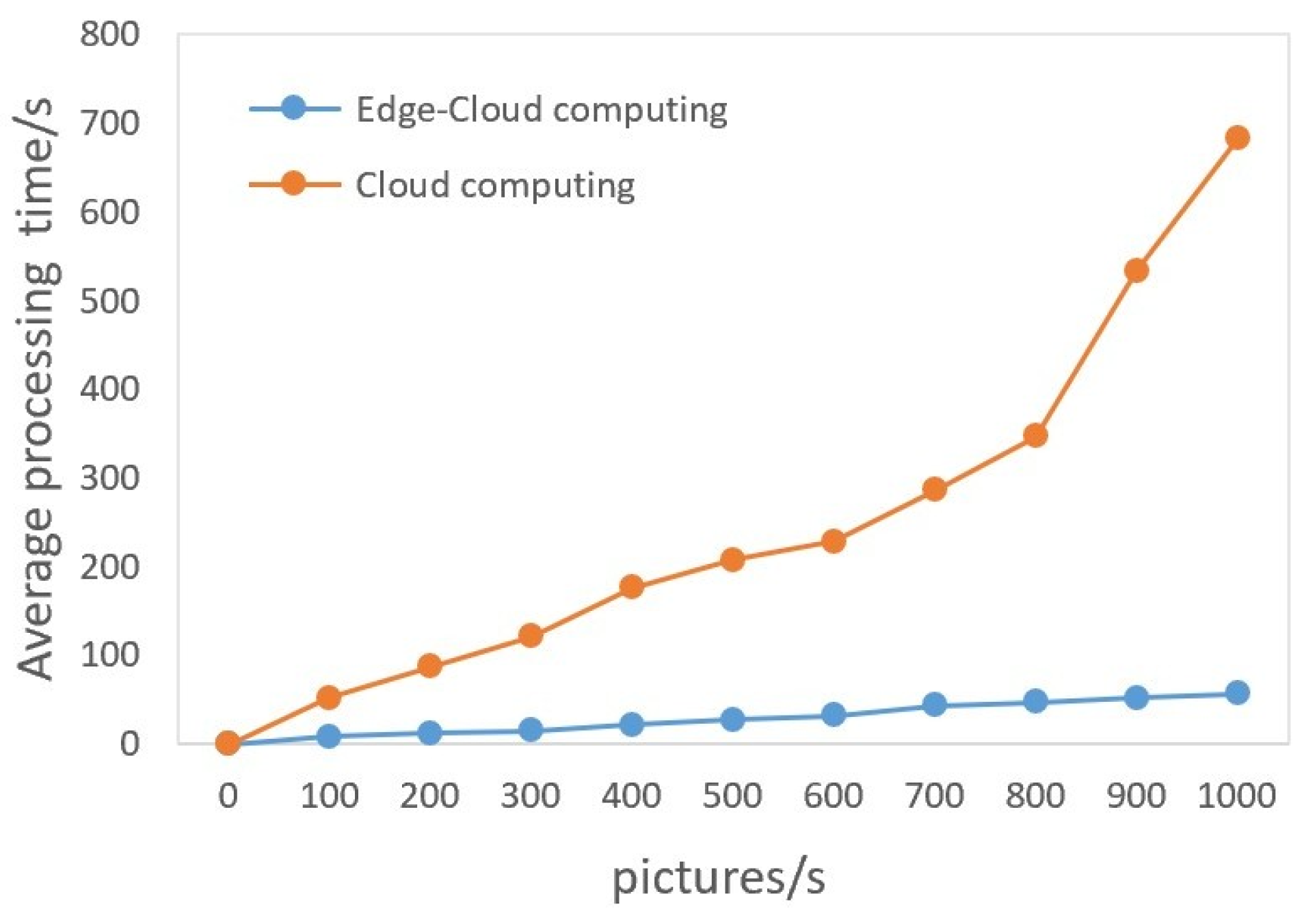
| Step | Edge Computing | Cloud Computing |
|---|---|---|
| Step 1 | Capturing images 21 ms | Capturing images 23 ms |
| Step 2 | Edge computing 96 ms | Uploading original images 104 ms |
| Step 3 | Output results 32 ms | Cloud computing 28 ms |
| Step 4 | – | Result returned 89 ms |
| Step 5 | – | Output results 34 ms |
| Response cycle | 148 ms | 278 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leng, J.; Chen, X.; Zhao, J.; Wang, C.; Zhu, J.; Yan, Y.; Zhao, J.; Shi, W.; Zhu, Z.; Jiang, X.; et al. A Light Vehicle License-Plate-Recognition System Based on Hybrid Edge–Cloud Computing. Sensors 2023, 23, 8913. https://doi.org/10.3390/s23218913
Leng J, Chen X, Zhao J, Wang C, Zhu J, Yan Y, Zhao J, Shi W, Zhu Z, Jiang X, et al. A Light Vehicle License-Plate-Recognition System Based on Hybrid Edge–Cloud Computing. Sensors. 2023; 23(21):8913. https://doi.org/10.3390/s23218913
Chicago/Turabian StyleLeng, Jiancai, Xinyi Chen, Jinzhao Zhao, Chongfeng Wang, Jianqun Zhu, Yihao Yan, Jiaqi Zhao, Weiyou Shi, Zhaoxin Zhu, Xiuquan Jiang, and et al. 2023. "A Light Vehicle License-Plate-Recognition System Based on Hybrid Edge–Cloud Computing" Sensors 23, no. 21: 8913. https://doi.org/10.3390/s23218913