
Deep Network-Assisted Quality Inspection of Laser Welding on Power Battery
Abstract
:1. Introduction
2. Overview of Welding Image Dataset
3. Proposed Framework
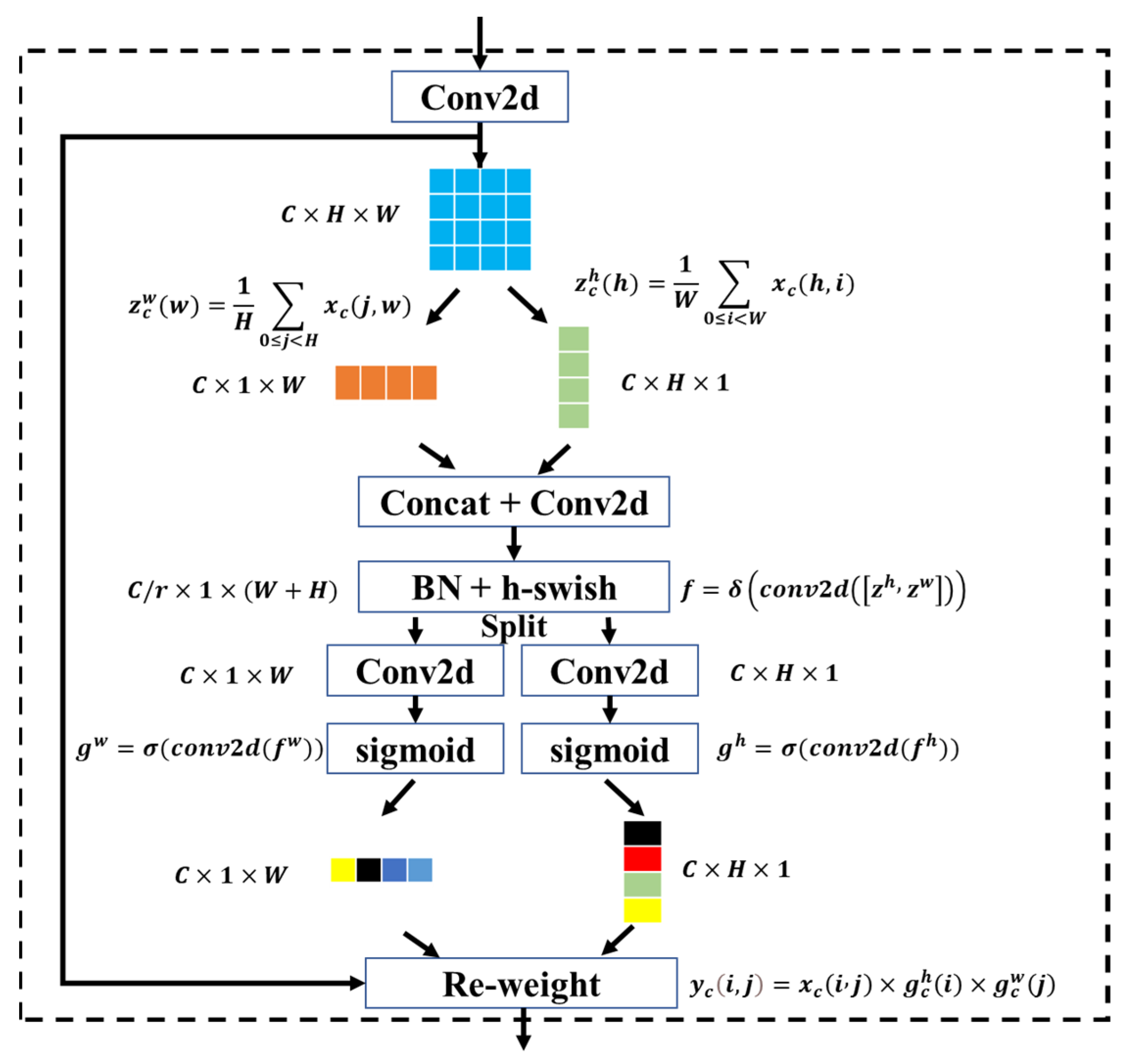
3.1. Coordinate Attention Module
3.2. Two-Branch Network Architecture
3.3. Post-Processing
| Algorithm 1: Circle detection using Hough transform | |
| Input: the segmented images, image coordinates . | |
| Output: circle center coordinates , circle radius . | |
| 1. | Initialize: . |
| 2. | Detect all edge points in the segmented image using the Canny operator. |
| 3. | for to the diagonal length of the image |
| 4. | for each edge pixel in the image |
| 5. | for = 0 to 360 |
| 6. | |
| 7. | |
| 8. | |
| 9. | Find the largest and second largest values of , whose parameters correspond to the inner and outer circles of the weld. |
4. Experiments and Discussion
4.1. Implementation Details
4.2. Evaluation Metrics
4.3. Experiment Results
4.3.1. Ablation Experiment
4.3.2. Sensitivity to the Number of Training Samples
4.4. Post-Processing Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tsoukantas, G.; Salonitis, K.; Stournaras, A.; Stavropoulos, P.; Chryssolouris, G. On optical design limitations of generalized two-mirror remote beam delivery laser systems: The case of remote welding. Int. J. Adv. Manuf. Technol. 2007, 32, 932–941. [Google Scholar] [CrossRef]
- Sadeghian, A.; Iqbal, N. A review on dissimilar laser welding of steel-copper, steel-aluminum, aluminum-copper, and steel-nickel for electric vehicle battery manufacturing. Opt. Laser Technol. 2021, 146, 107595. [Google Scholar] [CrossRef]
- Cao, X.; Wallace, W.; Poon, C.; Immarigeon, J.-P. Research and progress in laser welding of wrought aluminum alloys. i. laser welding processes. Mater. Manuf. Process. 2003, 18, 1–22. [Google Scholar] [CrossRef]
- Stavridis, J.; Papacharalampopoulos, A.; Stavropoulos, P. Quality assessment in laser welding: A critical review. Int. J. Adv. Manuf. Technol. 2017, 94, 1825–1847. [Google Scholar] [CrossRef]
- Xu, F.; Xu, Y.; Zhang, H.; Chen, S. Application of sensing technology in intelligent robotic arc welding: A review. J. Manuf. Process. 2022, 79, 854–880. [Google Scholar]
- Cai, W.; Wang, J.; Jiang, P.; Cao, L.; Mi, G.; Zhou, Q. Application of sensing techniques and artificial intelligence-based methods to laser welding real-time monitoring: A critical review of recent literature. J. Manuf. Syst. 2020, 57, 1–18. [Google Scholar]
- Fan, X.; Gao, X.; Liu, G.; Ma, N.; Zhang, Y. Research and prospect of welding monitoring technology based on machine vision. Int. J. Adv. Manuf. Technol. 2021, 115, 3365–3391. [Google Scholar]
- Gao, Y.; Zhong, P.; Tang, X.; Hu, H.; Xu, P. Feature Extraction of Laser Welding Pool Image and Application in Welding Quality Identification. IEEE Access 2021, 9, 120193–120202. [Google Scholar] [CrossRef]
- Cai, W.; Wang, J.; Cao, L.; Mi, G.; Shu, L.; Zhou, Q.; Jiang, P. Predicting the weld width from high-speed successive images of the weld zone using different machine learning algorithms during laser welding. Math. Biosci. Eng. 2019, 16, 5595–5612. [Google Scholar] [CrossRef]
- Zhang, Z.; Wen, G.; Chen, S. Weld image deep learning-based on-line defects detection using convolutional neural networks for Al alloy in robotic arc welding. J. Manuf. Process. 2019, 45, 208–216. [Google Scholar] [CrossRef]
- Xia, C.; Pan, Z.; Fei, Z.; Zhang, S.; Li, H. Vision based defects detection for Keyhole TIG welding using deep learning with visual explanation. J. Manuf. Process. 2020, 56, 845–855. [Google Scholar] [CrossRef]
- Wang, Q.; Jiao, W.; Wang, P.; Zhang, Y. A tutorial on deep learning-based data analytics in manufacturing through a welding case study. J. Manuf. Process. 2020, 63, 2–13. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Yang, Y.; Pan, L.; Ma, J.; Yang, R.; Zhu, Y.; Yang, Y.; Zhang, L. A High-Performance Deep Learning Algorithm for the Automated Optical Inspection of Laser Welding. Appl. Sci. 2020, 10, 933. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, R.; Pan, L.; Ma, J.; Zhu, Y.; Diao, T.; Zhang, L. A lightweight deep learning algorithm for inspection of laser welding defects on safety vent of power battery. Comput. Ind. 2020, 123, 103306. [Google Scholar] [CrossRef]
- Dai, W.; Li, D.; Tang, D.; Wang, H.; Peng, Y. Deep learning approach for defective spot welds classification using small and class-imbalanced datasets. Neurocomputing 2022, 477, 46–60. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ji, C.; Wang, H.; Li, H. Defects detection in weld joints based on visual attention and deep learning. NDT E Int. 2023, 133, 102764. [Google Scholar]
- Dai, W.; Li, D.; Tang, D.; Jiang, Q.; Wang, D.; Wang, H.; Peng, Y. Deep learning assisted vision inspection of resistance spot welds. J. Manuf. Process. 2020, 62, 262–274. [Google Scholar]
- Zhu, Y.; Yang, R.; He, Y.; Ma, J.; Guo, H.; Yang, Y.; Zhang, L. A Lightweight Multiscale Attention Semantic Segmentation Algorithm for Detecting Laser Welding Defects on Safety Vent of Power Battery. IEEE Access 2021, 9, 39245–39254. [Google Scholar] [CrossRef]
- Zhang, H.; Di, X.; Zhang, Y. Real-Time CU-Net-Based Welding Quality Inspection Algorithm in Battery Production. IEEE Trans. Ind. Electron. 2020, 67, 10942–10950. [Google Scholar] [CrossRef]
- Xu, H.; Yan, Z.H.; Ji, B.W.; Huang, P.F.; Cheng, J.P.; Wu, X.D. Defect detection in welding radiographic images based on semantic segmentation methods. Measurement 2021, 188, 110569. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2011–2023. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. IEEE Trans. Knowl. Data Eng. 2022, 34, 5586–5609. [Google Scholar]
- Vafaeikia, P.; Namdar, K.; Khalvati, F. A Brief Review of Deep Multi-task Learning and Auxiliary Task Learning. arXiv 2020, arXiv:2007.01126. [Google Scholar]
- Xie, Z.; Chen, J.; Feng, Y.; Zhang, K.; Zhou, Z. End to end multi-task learning with attention for multi-objective fault diagnosis under small sample. J. Manuf. Syst. 2021, 62, 301–316. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Use of the hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Ballard, D. Generalizing the hough transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network, ICLR 2014. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Sobel, I.; Feldman, G. A 3 × 3 isotropic gradient operator for image processing. Presented at a talk at the Stanford Artificial Project. In Pattern Classification and Scene Analysis; Duda, R., Hart, P., Eds.; John Wiley & Sons: Hoboken, NJ, USA, 1968; pp. 271–272. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Confusion Matrix | Prediction | ||
|---|---|---|---|
| Normal | Defect | ||
| True | Normal | True Negative (TN) | False Positive (FP) |
| defect | False Negative (FN) | True Positive (TP) | |
| CAM | TB | Acc | MAR | FAR | mIoU |
|---|---|---|---|---|---|
| — | — | 0.964 | 0.069 | 0.154 | — |
| √ | — | 0.966 | 0.063 | 0.144 | — |
| — | √ | 0.975 | 0.027 | 0.125 | 0.926 |
| √ | √ | 0.979 | 0.011 | 0.115 | 0.957 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Zheng, Y.; Dai, W.; Tang, D.; Peng, Y. Deep Network-Assisted Quality Inspection of Laser Welding on Power Battery. Sensors 2023, 23, 8894. https://doi.org/10.3390/s23218894
Wang D, Zheng Y, Dai W, Tang D, Peng Y. Deep Network-Assisted Quality Inspection of Laser Welding on Power Battery. Sensors. 2023; 23(21):8894. https://doi.org/10.3390/s23218894
Chicago/Turabian StyleWang, Dong, Yongjia Zheng, Wei Dai, Ding Tang, and Yinghong Peng. 2023. "Deep Network-Assisted Quality Inspection of Laser Welding on Power Battery" Sensors 23, no. 21: 8894. https://doi.org/10.3390/s23218894