1. Introduction
In recent years, the emergence of attention-based transformer models [
1,
2,
3] has stimulated interest in new architectures that have achieved state-of-the-art results on a wide variety of computer vision tasks [
4,
5,
6]. Along with these exciting developments and the growing interest in deploying models in practice, there is a need to investigate the robustness of attention-based models when deployed to new settings. This is especially useful when supervised transfer learning is not possible due to a lack of labels in the new domain. In this paper, we benchmark the generalization and adaptation performance of transformer models for vision and compare them with convolutional neural networks (CNNs) under distribution shifts between the training and testing data. Our in-depth analysis compares three members of the transformer family, vision transformer (ViT) [
1], shifted window transformer (SWIN) [
2] and dual attention vision transformer (DAViT) [
3], against convolution-based architectures ResNet50 [
7], HRNet [
8], and the more recently introduced attention-based ConvNeXt [
9]. While convolutions excel at capturing local patterns in the input domain (e.g., edges and contours) [
10], self-attention mechanisms have been shown to effectively learn global patterns, such as the relations between distant parts of an image [
1]. We explore the performance of these models through the lens of the source hypothesis transfer (SHOT) framework.
In the domain generalization and adaptation setting, the goal is (a) to learn robust feature representations for the source distribution that generalize well to the target distributions and (b) to adapt to the unlabeled target domain. In this paper, we consider domain adaptation benchmarks on two distinct visual perspectives or views: (i) images of objects at ground level found in standard datasets and (ii) aerial imagery from drones or satellites. Although previous works have looked at the performance of different domain transfer techniques on generic and aerial datasets [
11,
12], our work explores the merits of transformer vs. convolutional backbone architectures.
Our results on standard datasets, such as Office-Home [
13] and DomainNet [
14], serve as a benchmark for future work, while adaptation on aerial imagery deals with its own unique set of challenges. With changes in rotation, scale, illumination, and noise due to different sensor and viewpoint characteristics, dedicated models need to be trained on aerial data. The situation is further exacerbated by challenging conditions, including lower inter-class variance, weather-related disturbances, and greater variations in the orientation of objects with respect to the background. Our work examines how different convolutional and self-attention based models perform when presented with such challenging tasks.
In this paper, we present a broad comparison of the performance of different types of architectures for domain generalization and unsupervised domain adaptation tasks. Our systematic experiments on domain adaptation with the SHOT framework led to the following observations and contributions:
Self-attention based transformer models ViT, DAViT and SWIN generally outperform standard convolutional models ResNet and HRNet on both generalization and adaptation tasks.
The newer attention-based convolutional network ConvNext is on par or better than transformer models (ViT, SWIN, and DAViT) and does better than standard convolutional models (ResNet and HRNet).
Using the SWIN architecture as a backbone results in better performance compared to ViT and DAViT, especially for the adaptation task.
Image augmentations, such as RandAugment and RandomErasing, used for adaptation may result in lower performance for standard datasets but improve the performance of models on aerial datasets.
The remainder of this paper is organized as follows.
Section 2 focuses on a brief literature review of prior works done in this area.
Section 3 describes the different architectures as well as the SHOT framework that we employ to carry out the adaptation process.
Section 4 discusses our experimental setup, which includes the different types of datasets that we used and our
modern training recipe of data augmentations.
Section 5 provides comprehensive results from the study, while additional results are presented in the appendix. Finally,
Section 6 presents final remarks and conclusions based on our evaluation.
4. Experimental Setup
4.1. Benchmarking Datasets
In order to benchmark the performance of models over multiple scenarios, we conduct our experiments using two different categories of datasets. The first category includes Office-Home [
13] and DomainNet [
14], which are datasets with standard, ground-level views of commonly found objects across multiple domains. The second category of datasets comprises aerial imagery collected from satellites. Aerial datasets present unique challenges for cross-domain adaptation due to the different image characteristics based on ground sampling distances (GSDs), unique sensors used for data collection, and lower inter-class variation. The aerial datasets were introduced in [
12] and utilize the shared classes of publicly available aerial datasets for classification. We provide more information on the individual datasets in
Section 4.3.
4.2. Standard DA Datasets
For our experiments, we considered two standard DA datasets that portray objects at the ground level: Office-Home [
13] and DomainNet [
14]. We describe the characteristics of each of the datasets in more detail in the following subsections.
4.2.1. Office-Home
Office-Home [
13] is a medium-sized dataset with 15,500 images consisting of 65 different image classes across four domains: art (Ar), clipart (Cl), product (Pr), and real world (Rw). Sixteen of the classes across four domains are shown in
Figure 2.
4.2.2. DomainNet
The DomainNet dataset [
14] contains images of common objects in six different domains. All domains include 345 classes of everyday objects, such as bracelets, birds, and cellos. The domains include clipart (C), real world (R), sketch (S), painting (P), infograph (I), which are infographic images of a specific object, and quickdraw (Q), which are drawings from worldwide players of the game “Quick Draw!”. For the purposes of this study, we use DomainNet-126, which is a subset of the original DomainNet dataset with 126 classes across four domains: clipart, real world, sketch, and painting. We can see a sample of the dataset in
Figure 3.
4.3. Aerial Datasets
We consider two aerial datasets for our domain adaptation problem. Since there is a lack of datasets that are specifically suited for our task, we follow a process similar to [
12] in order to create our own datasets. To do so, we take four publicly available datasets and divide them into two pairs. We then utilize the shared classes between the datasets in each pair in order to represent the same object in a different domain.
4.3.1. DOTA-xView
Our first aerial dataset for the domain adaptation task was formed by taking the classes common between the dataset for object detection in aerial images (DOTA) [
47] and xView [
48] datasets. A sample of our combined dataset can be seen in
Figure 4. We take five shared classes and a varying number of samples from each class for our DOTA-xView DA dataset. More information can be found in
Table 2.
The DOTA dataset [
47] is a benchmark dataset created for performing object detection in aerial images. The images are mainly collated using data from Google Earth and the China Center for Resources—Satellite Data and Application. There are a total of 2086 high-resolution images ranging from 800 ×800 to 6000 × 6000 pixels. The dataset includes objects from 15 classes, and multiple objects of different classes may be present in the same image. This makes it difficult to perform classification accurately.
To overcome this limitation, each image is cropped around the bounding boxes to ensure it only has a single object corresponding to a specific class. The size of the cropped images ranges from 10 × 10 to 904 × 904. To further achieve optimal results, images smaller than 30 × 30 are discarded, and the number of images per class is restricted to 5000. We perform data augmentation for classes that do not meet this number by flipping the final images both horizontally and vertically.
For our experiments, we select the following five classes: large vehicle, plane, ship, small vehicle, and storage tank. We combine the large and small vehicle classes to form the vehicle class. We randomly delete half the images to keep the total number of images per class constant, which prevents overfitting.
The xView dataset was created as part of the 2018 xView Detection Challenge [
48]. It contains approximately 1 million object samples divided across 60 classes. The images in this dataset were captured using the WorldView-3 satellite and have a resolution of 0.3 m/pixel. The objects within each image in this dataset vary in size from 3 m to greater than 3000 m.
Similar to DOTA, xView has multiple instances of objects belonging to different classes in each high-resolution image. Therefore, we apply similar pre-processing steps by cropping each image around the bounding boxes and discard any cropped images less than 30 × 30 in size. We also restrict the number of images per class to 5000 and perform data augmentation by horizontally and vertically flipping images for classes that do not meet this number.
The final xView partition consists of the same classes as the DOTA dataset described above: large vehicle, plane, ship, small vehicle, and storage tank. As with DOTA, we combine and randomly delete half the images of large and small vehicles to form a singular vehicle class.
4.3.2. AID-UCM
Our second aerial dataset for the domain adaptation is formed by taking the classes common between the AID [
49] and UCM [
50] datasets, each of which we define in more detail below. We take nine shared classes and a varying number of samples from each class for our AID-UCM dataset. More information can be found in
Table 3, and a sample of our final dataset can be seen in
Figure 5.
The Aerial Image Dataset (AID) [
49] was developed for the task of aerial scene classification by taking images from Google Earth. It contains a total of 10,000 aerial images divided across 30 classes. Each image measures 600 × 600 pixels and is annotated by experts in remote sensing image interpretation. The data consist of images taken in diverse geographic locations with variances in both time and season. The images in the dataset are obtained at multiple GSDs ranging from 8 m to 0.5 m. We select nine classes from AID for the purposes of our experiments: airport, parking, storage tank, beach, forest, river, baseball field, medium residential, and sparse residential.
The UC Merced Land Dataset (UCM) [
50] is a publicly available image dataset of overhead land images meant for research purposes. It consists of 21 classes and has 100 images per class, measuring 256 × 256 pixels and having a resolution of 0.3 m/pixel in the RGB space. The images are downloaded from the United States Geological Survey (USGS) National Map from different urban US regions. The images selected contain a wide variety of spatial patterns, textures, and colors, making them ideal for scene classification.
Our partition of the UCM dataset consists of the same classes as the AID dataset described above: airport, parking lot, storage tank, beach, forest, river, baseball diamond, medium residential, and sparse residential.
4.4. Modernizing the Training Recipe with Data Augmentations
Self-attention models, in general, require a large amount of data for effective training [
1]. The lack of sufficient data was addressed by employing a training recipe via a new image augmentation protocol. We take this protocol and formulate our new training recipe involving augmentations to the source domain data during training to improve generalization. We implement two data augmentation procedures:
RandAugment: An automated data augmentation technique that uniformly samples operations from a set of augmentations, such as rotation, equalization, color jittering, solarization, translation, shearing, and altering physical characteristics, such as contrast, brightness, and sharpness.
Random erasing: A rectangular region in the image is replaced with random values. Multiple levels of occlusions are created to help the models generate more robust features.
These two data augmentation techniques allow the models to extract a richer set of features from the input images and provide larger variations in the appearance of aerial images by artificially varying physical characteristics, such as object positioning and frame contrast. Inspired by the augmentations in ConvNeXt [
9], our initial experiments considered two more augmentation techniques, Cutmix and Mixup, in addition to RandAugment and random erasing. Cutmix is based on interchanging patches between different images in the training set and Mixup is based on generating weighted combinations of random image pairs. However, our experiments in
Table 4 show that combining RandAugment and random erasing with any additional augmentations does not improve performance but rather results in a significant degradation in accuracy for both convolutional and self-attention based models. Thus, going forward, we only use RandAugment and random erasing as our image augmentation techniques for our study.
In keeping with the new augmentation process, we modify the parameters of our framework slightly and run adaptation for 100 epochs during source training. We also tune the learning rate to in order to prevent overfitting. To further validate the effectiveness of our modern training recipe, we compare our results with and without the use of these augmentations to determine if they help transformer models to generalize better.
Moreover, we find that our models benefit from a higher learning rate in the initial epochs and a lower learning rate during later epochs. Based on this observation, we use a linear learning rate decay during our training process. This allows us to achieve better convergence while training our models.
4.5. Setup of Architectures
In order to maintain consistency across the different architectures, we use an image size of pixels across all of the backbones. We also use the base models of the SWIN, ViT, ConvNeXt, and DAViT architectures. All models used are pre-trained on ImageNet-1k. For the generalization task without the modernized training recipe, all models are trained for 20 epochs with a learning rate of . During adaptation, we maintain the same learning rate of for standard datasets and use for the aerial datasets. This is done in order to compensate for the increased ambiguity present in images in the aerial domain, which make the task of image classification considerably harder.
To analyze the effect of image augmentation on domain generalization, we compare two training recipes. Image augmentations are only applied on the source domain data when training models for generalization, and after training, the models adapt to the target data without augmentations. This is done because of the lack of labels in the target domain in order to prevent the models from extracting incorrect labels for the images.
5. Results and Discussion
In this section, we present the results of our experiments and compare the performance of different backbone architectures for unsupervised domain adaptation. We evaluate our model with and without the modern training recipe in
Section 4.4 on both generic and aerial datasets.
The primary metric that we use to compare the models and architectures considered is classification accuracy, i.e., the ratio of the number of samples correctly classified by the model and the total number of predictions performed by the model. In our results, we report the ’mean percent accuracy’, which is the classification accuracy for each target domain averaged over all source–target pairs present in a particular dataset. We provide a more detailed presentation of our results over individual domains in
Appendix A.
5.1. Results for Standard Datasets
The standard DA datasets in our experiments are Office-Home [
13] and DomainNet [
14]. The results in
Table 5 show that the ConvNeXt backbone generalizes better than all the other models, closely followed by SWIN. For adaptation, ConvNeXt outperforms other models for Office-Home while coming just behind SWIN on DomainNet. More broadly put, self-attention based models, like ViT and SWIN, generalize and adapt better to other domains compared to convolutional backbones, like ResNet and HRNet. However, ConvNeXt breaks this trend by outperforming all other models under comparison, both convolutional and transformer-based. ConvNext [
9] utilizes a combination of cardinality and depthwise convolutions, along with a separate
layer for spatial downsampling. The ConvNext architecture allows it to capture richer spatial information and learn more powerful representations that help it achieve better performance.
Table 6 shows us the performance of our models on generic datasets with the modern training recipe defined in
Section 4.4 applied during training to obtain the source-trained model. We observe a similar pattern, as seen without these augmentations, repeated here. Self-attention transformer-based models outperform traditional convolutional architectures ResNet and HRNet, but ConvNeXt achieves the best or close to the best performance for both tasks on both datasets.
However, the image augmentations defined in our modern training recipe provide little to no improvement in terms of classification accuracy. In fact, at times, they even hurt the overall accuracy of the adaptation task. This can be attributed to the distortion introduced in the source images due to the strong augmentations. For standard datasets, such distortion leads to ambiguity in the otherwise unambiguous source data in terms of the centered positioning of the object, singular object in the frame, and non-interfering background, among others.
5.2. Aerial Datasets
The aerial datasets we evaluate consist of the DOTA-xView and the AID-UCM datasets, the formation of which is defined in
Section 4.3.
Table 7 shows the performance of our model backbones without the modern training recipe. Based on the results for the aerial datasets, we see a trend similar to standard datasets. Self-attention-based models tend to outperform convolutional models for the adaptation task. However, while ConvNeXt displays the best or close to the best performance for the generalization task, the SWIN backbone consistently outperforms all other models for the adaptation task.
Table 8 displays the results of our backbones on the aerial datasets with augmentations. In contrast to standard datasets, the modern training recipe image augmentations result in slightly increased performance for both generalization and adaptation tasks on aerial datasets. This can be attributed to larger variations in the appearance of the aerial images due to object positioning in the images, diverse angular rotations for each class, multiple objects in a frame, varying image contrast, etc. This is reflected in the increasing accuracy in
Table 8.
5.3. Qualitative Analysis
In this section, we provide a qualitative discussion of our results.
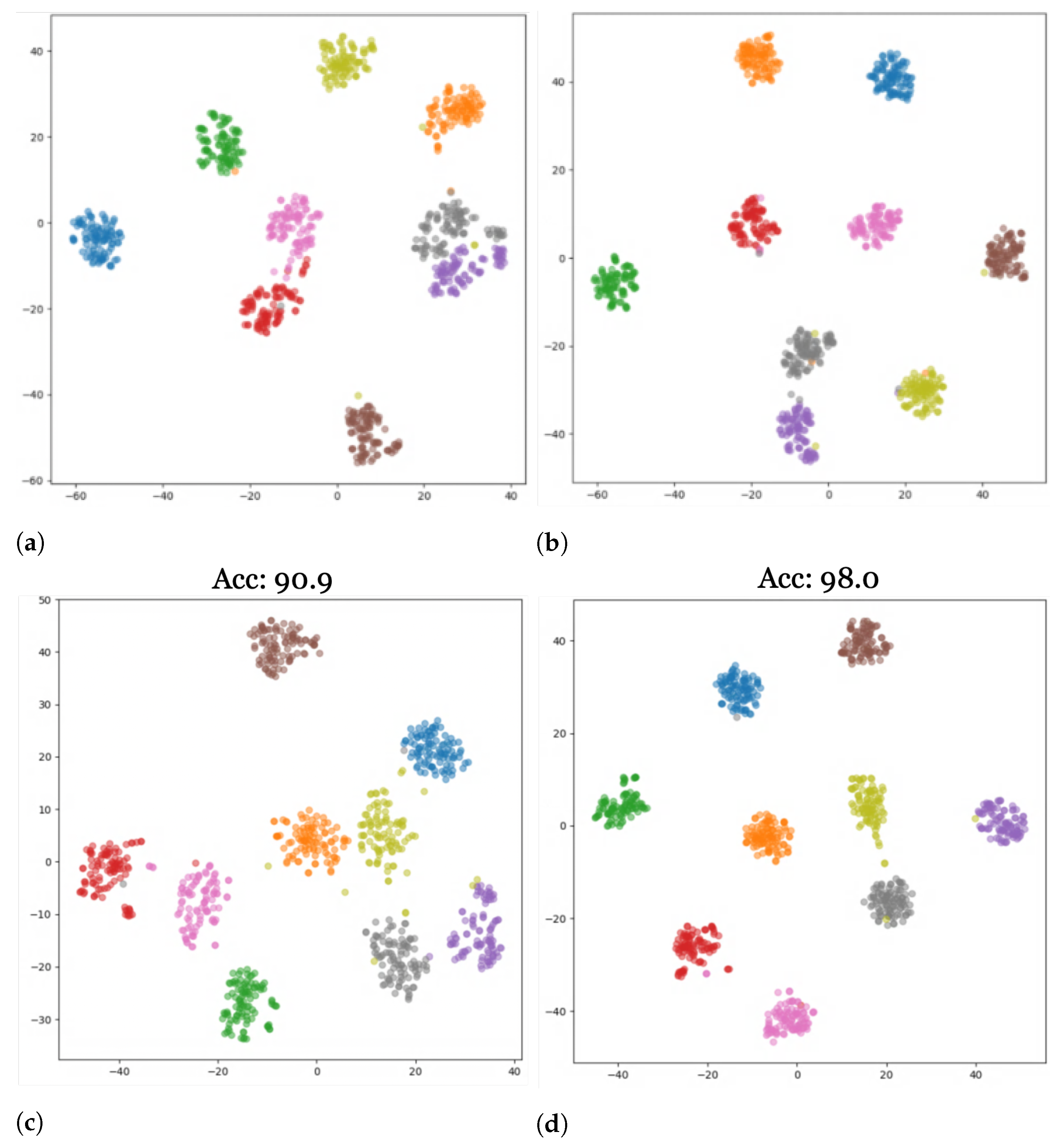
Figure 6 shows a graphical representation of our results for both standard and aerial datasets after applying our modernized training recipe. We additionally provide visualizations of the results of our study using t-distributed stochastic neighbor embeddings (t-SNE) [
51]. t-SNE visualizes high-dimensional data in a 2-dimensional plot in three steps: first, it calculates the similarity between points in the higher-dimensional space, followed by a calculation of the distribution that measures the pairwise distances between the points in the lower-dimensional embedding space. Finally, KL-divergence is used to minimize the difference between the probability distributions of the higher- and lower-dimensional embedding spaces.
Figure 7 and
Figure 8 show plots for the source AID and target UCM datasets with the nine clusters corresponding to the nine classes defined in
Table 3. The corresponding domain-wise results can be found in
Appendix A.
Figure 7a,c visualize the features produced by the ResNet and HRNet, respectively, for the generalization task on the target data with the models trained on the source data only.
Figure 7b,d provide the corresponding visualized features after adaptation. A significant tightening of clusters can be seen in the visualizations after adaptation, which is also reflected in the increased accuracies (~17% for ResNet and ~16% for HRNet).
Similarly,
Figure 8 shows the results for self-attention-based models ConvNeXt (
Figure 8a,b) and SWIN (
Figure 8c,d) before and after adaptation from AID to UCM. Due to the higher generalization scores before adaptation, the increase in the cluster compactness and the inter-cluster distance in the feature space after adaptation are less prominent, but they are noticeably visible nonetheless.
It is understood that for a model to generalize to previously unseen domains, its predictions should not depend on features that are specific to the distribution of the training data since domain-specific features lead to a loss in accuracy when the model is provided with out-of-distribution data. Spurious features are often described in the literature [
52] as any feature that correlates strongly with the labels in the training set, such as specific textures or colors in the background. Instead, the model should be able to utilize robust features that are invariant to covariate shift [
53] and generalize well across other domains. Vision transformer architectures work on the conjecture that attention-based architectures are more likely to learn robust features from data compared to CNNs, given the ability of their self-attention blocks to communicate globally within a given input [
1]. However, our results show that while a ConvNeXt backbone fares better in a sparse data setting (like Office-Home), the SWIN architecture shows a comparable or even better performance when provided with enough data. Moreover, our experiments with the modern training recipe verify that the augmentations help generalize better. This is especially apparent with aerial datasets. While self-attention based models require ample data to develop robust feature representations, with large enough datasets, they are able to generalize sufficiently well and adapt to other domains without a significant performance drop.
6. Conclusions
In this work, we provide an in-depth performance analysis of the effect of backbone architectures on domain generalization and unsupervised domain adaptation tasks for both standard and aerial datasets. Our experiments make use of the SHOT framework in order to perform unsupervised domain adaptation from the source domain to the target domain. We evaluate and compare the performance of convolutional and self-attention-based models, and observe that the architecture of the backbone plays a major role in generalization and adaptation to unseen domains. As shown in
Section 5, self-attention based models like ViT, SWIN, and DAViT consistently outperform convolutional models ResNet and HRNet. However, the newer ConvNext model, which combines elements of convolutional and self-attention architectures, performs as well or better than transformer architectures and significantly better than standard CNNs on domain generalization and adaptation.
Given that model architectures like ViT are bottlenecked by the lack of large-scale datasets, we applied a set of well-crafted data augmentation techniques, which we termed a modern training recipe, to the source datasets to determine if such augmentations could optimize the performance of vision transformer models on cross-domain generalization. While these augmentations can adversely impact the performance of generic standard datasets, they can be helpful for aerial datasets.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







