

Self-Attention-Based Deep Convolution LSTM Framework for Sensor-Based Badminton Activity Recognition

Abstract
:1. Introduction
- To overcome the shortcomings of the current methods for badminton activity recognition, we propose a new framework SADeepConvLSTM which combines the convolutional, recurrent, and self-attention layers together for synthetically improving the recognition performance. Such a design strategy has never been explored by previous work on badminton activity recognition.
- The adopted LSTM and self-attention layers in SADeepConvLSTM are able to effectively extract temporal features from the sensor signals and suppress the noise interference, which leads to the acceleration of the recognition process and an increase in the accuracy and macro F1-score at the same time.
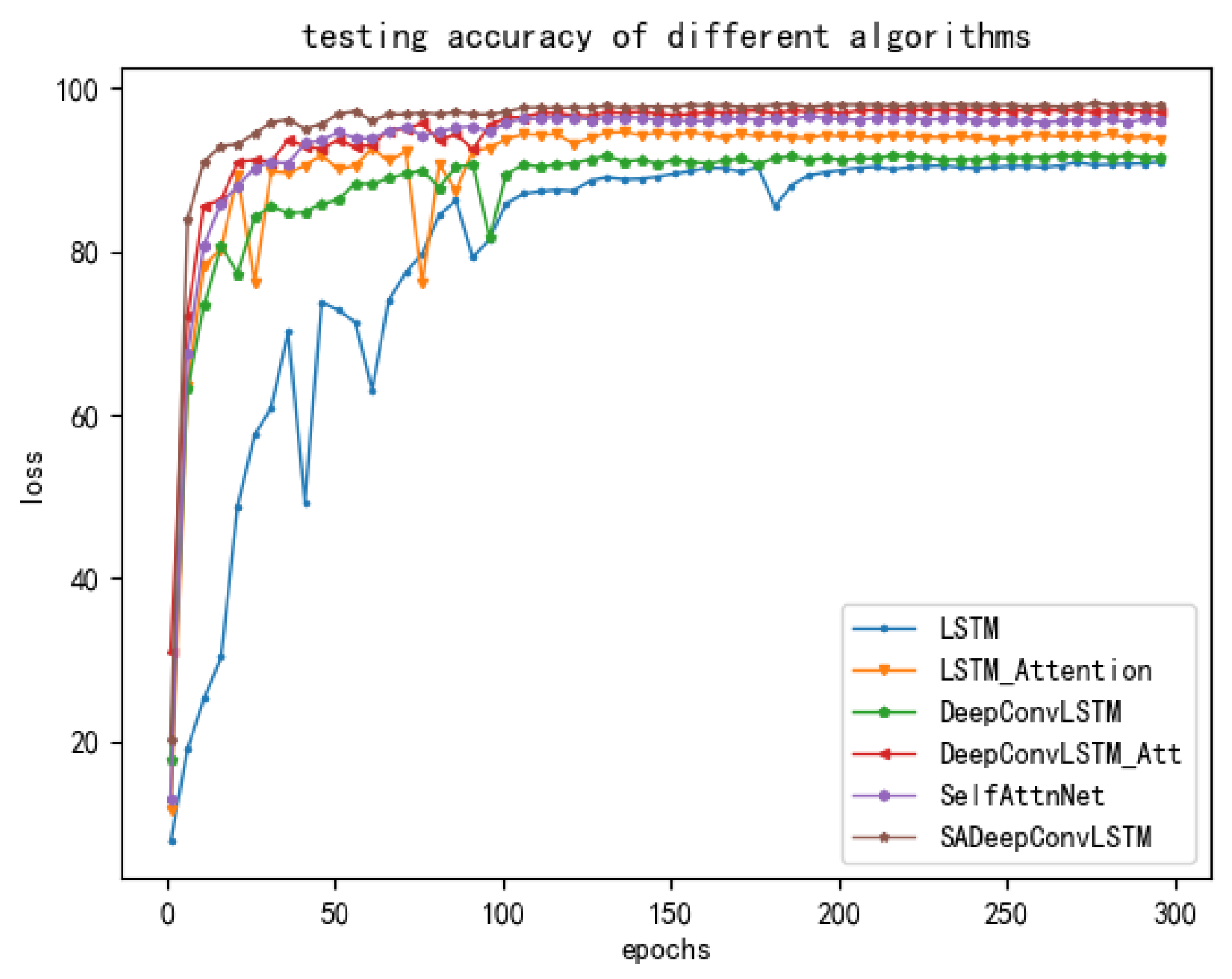
- Compared with the existing popular deep learning models for badminton activity recognition on the specialized BSS dataset, SADeepConvLSTM obtains the best recognition accuracy. Moreover, it also has the advantages of lower training time and faster convergence.
2. Related Work
2.1. Conventional Machine Learning
2.2. Deep Learning
3. Materials and Methods
3.1. Badminton Single-Sensor (BSS) Dataset
3.2. Proposed Framework and Learning Algorithms
3.2.1. DeepConvLSTM
- (a)
- Convolutional Layer. The first to fourth layers of the DeepConvLSTM model are all 1D convolutional layers. Different channels are convolved separately with the same kernel. Letting the data of the k-th sensor at time t in the i-th layer, j-th channel be , we denote the bias of the j-th kernel in the i-th layer as , and denote the value of its -th parameter on the channel c be . So, the operation of one-dimensional convolution can be mathematically expressed bywhere denotes the number of convolution kernels in the i-th layer, and denotes the size of the kernel in the i-th layer. In fact, is a nonlinear activation function, and is usually taken as the ReLU function; that is, .
- (b)
- Recurrent Layer. The fifth and sixth layers of the DeepConvLSTM model are recurrent layers, and their structures are adopted as the classical LSTM network that contains input, output, and forgetting gates:where denotes the input data, and and denote the hidden state and the output of the t-th cell, respectively. is a nonlinear activation function, and , , , , , , , and are learnable parameters.
- (c)
- Fully Connected Layer and Softmax Layer. The output of the last time-step of the sixth layer is then input into the fully connected layer, and the obtained N dimension vector is then input to the last Softmax layer to get the corresponding probability distribution . Letting , the output of the Softmax layer can be defined bywhereis the normalized coefficient.
3.2.2. Self-Attention-Based Deep Convolutional LSTM (SADeepConvLSTM)
- (a)
- Positional Encoding. Positional Encoding aims to add temporal positional information to the hidden features before feeding them into the self-attention module. In fact, the self-attention module given and discussed in the following Section 3.2.2 does not consider positional information; that is, the same embedding vector at different time-steps generates the same attention values.We adopt the position encoding method suggested by Vaswani et al. [19] into our SADeepConvLSTM framework. By denoting the number of time-steps of the previous recurrent layer as L, and the dimension of each hidden feature as , the k-th components of the position encoding at the pos-th time-step can be calculated bywhere , and . For clarity, we denote the feature matrices before and after the positional embedding by and , respectively.
- (b)
- Self-Attention Module. There are two main components in the self-attention module: multi-head attention layer and feed-forward network. The attention mechanism computes the relative weights of the query vector by considering the dot product similarity between and the key vector and then appending the weights to the value vector and summing up to obtain the attention value of . Mathematically, letting , , and be row vectors, , , we then havewhereis the dimension of and and is a constant zoom factor. The matrix form of the above equation can be written asLetting , since Equation (8) holds for any i, we thus havewhere Softmax can be considered as being computed by row.In the self-attention mechanism, the aforementioned Q, K, and V are all generated by applying nonlinear transformations to the input :where are learnable parameters. , , , where is the dimension of and , while is the dimension of . By introducing the self-attention mechanism, we can capture the crucial context information during the whole process of an action.In our SADeepConvLSTM framework, we adopt the multi-head attention [19] to extract the features in multiple aspects. In other words, we use n different sets of learnable parameters to generate different , , and to compute the attention values and concatenate them together. If , we use the learnable parameters to convert the input into the original dimension:Otherwise, we directly letSubsequently, the resulting is inputted into a feed-forward network consisting of 2 fully connected layers to implement the nonlinear transformations. In this module, we use the residual connections and layer normalization for both the multi-head attention and the feed-forward network.
- (c)
- Global Temporal Attention. We use the learnable parameters to evaluate the relative importance of the feature representation obtained by the last self-attention module at each time-step:where denotes the feature representation at time t. , , and are learnable parameters. Finally, we get the feature vector h by computing the weighted average of :
3.2.3. Training Process
4. Experimental Results
4.1. Evaluation Metrics
4.2. Experimental Settings
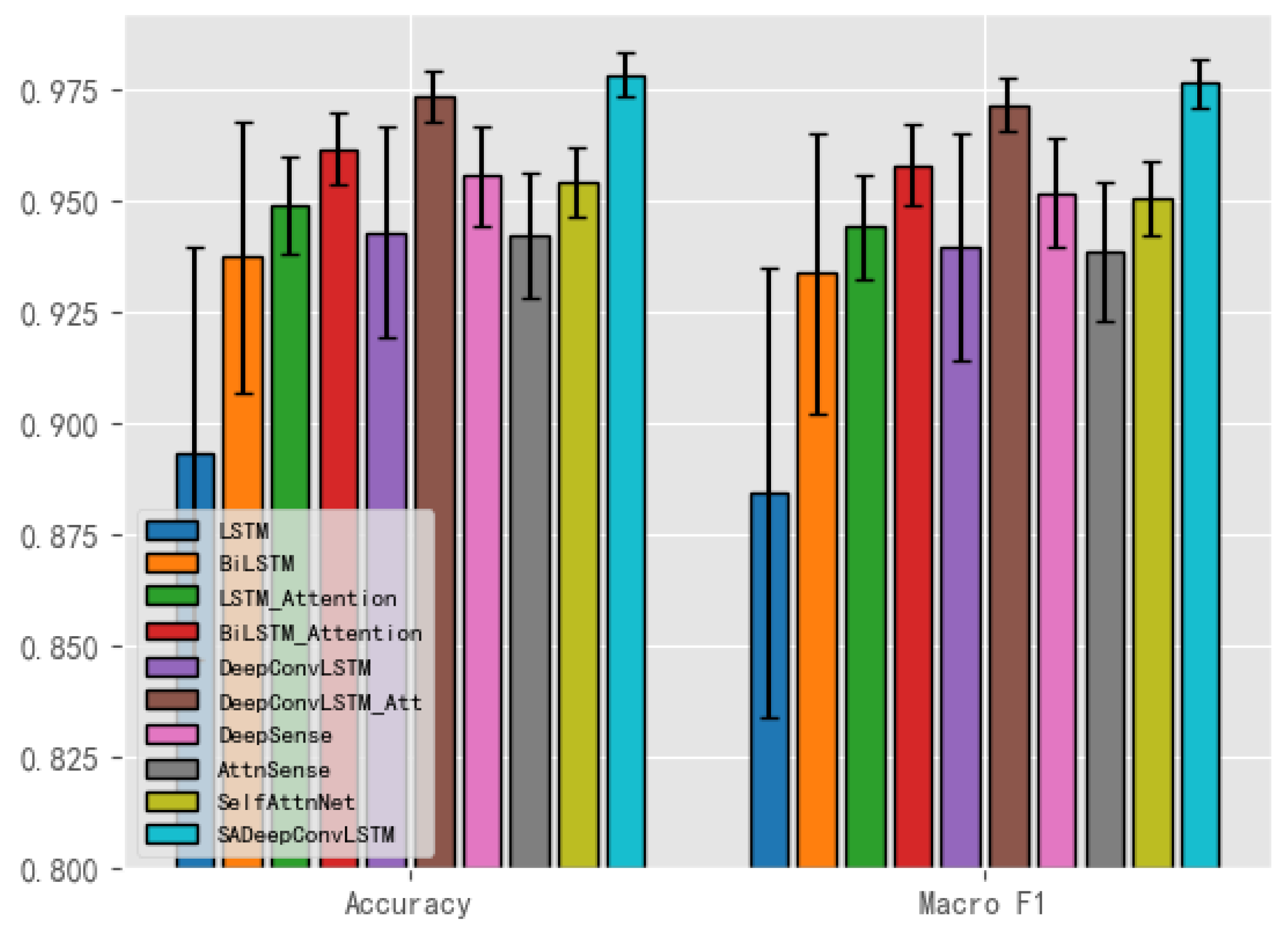
4.3. Results and Comparisons
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vepakomma, P.; De, D.; Das, S.K.; Bhansali, S. A-Wristocracy: Deep Learning on Wrist-worn Sensing for Recognition of User Complex Activities. In Proceedings of the 2015 IEEE 12th International Conference on Wearable and Implantable Body Sensor Networks, Cambridge, MA, USA, 9–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Hammerla, N.; Fisher, J.; Andras, P.; Rochester, L.; Walker, R.; Plötz, T. PD Disease State Assessment in Naturalistic Environments Using Deep Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29, pp. 1742–1748. [Google Scholar]
- Kim, Y.; Toomajian, B. Hand Gesture Recognition Using Micro-Doppler Signatures with Convolutional Neural Network. IEEE Access 2016, 4, 7125–7130. [Google Scholar] [CrossRef]
- Hsu, Y.L.; Yang, S.C.; Chang, H.C.; Lai, H.C. Human Daily and Sport Activity Recognition Using a Wearable Inertial Sensor Network. IEEE Access 2018, 6, 31715–31728. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and Vision-based Human Activity Recognition: A Comprehensive Survey. Pattern Recognit. 2020, 108, 107561–107584. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, W.; Ma, J.; Li, X.; Zhong, A. Automatic Badminton Action Recognition Using CNN with Adaptive Feature Extraction on Sensor Data. In Proceedings of the International Conference on Intelligent Computing, Nanchang, China, 3–6 August 2019; Springer: Cham, Switzerland, 2019; pp. 131–143. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep Learning for Sensor-based Activity Recognition: A Survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Hussain, S.; Rashid, H.U. User Independent Hand Gesture Recognition by Accelerated DTW. In Proceedings of the 2012 International Conference on Informatics, Electronics & Vision, Dhaka, Bangladesh, 18–19 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1033–1037. [Google Scholar]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. Deepsense: A Unified Deep Learning Framework for Time-series Mobile Sensing Data Processing. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar]
- Ma, H.; Li, W.; Zhang, X.; Gao, S.; Lu, S. AttnSense: Multi-level Attention Mechanism for Multimodal Human Activity Recognition. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3109–3115. [Google Scholar]
- Betancourt, C.; Chen, W.H.; Kuan, C.W. Self-Attention Networks for Human Activity Recognition Using Wearable Devices. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics, Toronto, ON, Canada, 11–14 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1194–1199. [Google Scholar]
- Wang, Y.; Ma, J.; Li, X.; Zhong, A. Hierarchical Multi-classification for Sensor-based Badminton Activity Recognition. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; IEEE: Piscataway, NJ, USA, 2020; Volume 1, pp. 371–375. [Google Scholar]
- Wang, Y.; Pan, G.; Ma, J.; Li, X.; Zhong, A. Label Similarity Based Graph Network for Badminton Activity Recognition. In Proceedings of the Intelligent Computing Theories and Application: 17th International Conference, ICIC 2021, Shenzhen, China, 12–15 August 2021; Proceedings, Part I 17. Springer: Cham, Switzerland, 2021; pp. 557–567. [Google Scholar]
- Yang, J.; Wang, S.; Chen, N.; Chen, X.; Shi, P. Wearable Accelerometer Based Extendable Activity Recognition System. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 3641–3647. [Google Scholar]
- Anik, M.A.I.; Hassan, M.; Mahmud, H.; Hasan, M.K. Activity Recognition of a Badminton Game through Accelerometer and Gyroscope. In Proceedings of the 2016 19th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 213–217. [Google Scholar]
- Hu, C.; Chen, Y.; Hu, L.; Peng, X. A Novel Random Forests Based Class Incremental Learning Method for Activity Recognition. Pattern Recognit. 2018, 78, 277–290. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed]
- Murahari, V.S.; Plötz, T. On Attention Models for Human Activity Recognition. In Proceedings of the 2018 ACM International Symposium on Wearable Computers, Singapore, 8–12 October 2018; pp. 100–103. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M. Preprocessing Techniques for Context Recognition from Accelerometer Data. Pers. Ubiquitous Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Wang, Z.; Guo, M.; Zhao, C. Badminton Stroke Recognition Based on Body Sensor Networks. IEEE Trans. Hum.-Mach. Syst. 2016, 46, 769–775. [Google Scholar] [CrossRef]
- Ma, C.; Yu, D.; Feng, H. Recognition of Badminton Shot Action Based on the Improved Hidden Markov Model. J. Healthc. Eng. 2021, 2021, 7892902. [Google Scholar] [CrossRef] [PubMed]
- Steels, T.; Van Herbruggen, B.; Fontaine, J.; De Pessemier, T.; Plets, D.; De Poorter, E. Badminton Activity Recognition Using Accelerometer Data. Sensors 2020, 20, 4685. [Google Scholar] [CrossRef] [PubMed]
- Anand, A.; Sharma, M.; Srivastava, R.; Kaligounder, L.; Prakash, D. Wearable Motion Sensor Based Analysis of Swing Sports. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 261–267. [Google Scholar]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Guan, Y.; Plötz, T. Ensembles of Deep LSTM Learners for Activity Recognition Using Wearables. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–28. [Google Scholar] [CrossRef]
- Mahmud, S.; Tonmoy, M.T.H.; Bhaumik, K.K.; Rahman, A.K.M.M.; Amin, M.A.; Shoyaib, M.; Khan, M.A.H.; Ali, A.A. Human Activity Recognition from Wearable Sensor Data Using Self-Attention. arXiv 2020, arXiv:2003.09018. [Google Scholar]
- Yao, S.; Zhao, Y.; Shao, H.; Liu, D.; Liu, S.; Hao, Y.; Piao, A.; Hu, S.; Lu, S.; Abdelzaher, T.F. Sadeepsense: Self-attention Deep Learning Framework for Heterogeneous On-device Sensors in Internet of Things Applications. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1243–1251. [Google Scholar]
- Saha, S.S.; Rahman, S.; Rasna, M.J.; Zahid, T.B.; Islam, A.M.; Ahad, M.A.R. Feature Extraction, Performance Analysis and System Design Using the Du Mobility Dataset. IEEE Access 2018, 6, 44776–44786. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Macro F1 | |
|---|---|---|
| SVM | 96.39% | 96.15% |
| RF | 96.53% | 96.27% |
| LSTM | 89.33% | 88.45% |
| BiLSTM | 93.73% | 93.38% |
| LSTM_Attention | 94.89% | 94.43% |
| BiLSTM_Attention | 96.17% | 95.81% |
| DeepConvLSTM [17] | 94.30% | 93.98% |
| DeepConvLSTM_Att [18] | 97.34% | 97.15% |
| DeepSense [9] | 95.55% | 95.18% |
| AttnSense [10] | 94.23% | 93.86% |
| SelfAttnNet [27] | 95.43% | 95.06% |
| SADeepConvLSTM_NP | 97.04% | 96.82% |
| SADeepConvLSTM_NC | 97.24% | 97.00% |
| SADeepConvLSTM | 97.83% | 97.64% |
| SADeepConvLSTM | 98.27% | 98.17% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, J.; Zhang, S.; Ma, J. Self-Attention-Based Deep Convolution LSTM Framework for Sensor-Based Badminton Activity Recognition. Sensors 2023, 23, 8373. https://doi.org/10.3390/s23208373
Deng J, Zhang S, Ma J. Self-Attention-Based Deep Convolution LSTM Framework for Sensor-Based Badminton Activity Recognition. Sensors. 2023; 23(20):8373. https://doi.org/10.3390/s23208373
Chicago/Turabian StyleDeng, Jingyang, Shuyi Zhang, and Jinwen Ma. 2023. "Self-Attention-Based Deep Convolution LSTM Framework for Sensor-Based Badminton Activity Recognition" Sensors 23, no. 20: 8373. https://doi.org/10.3390/s23208373