Our experiments evaluate one-way consistency with clean teacher and a composition of photometric and geometric perturbations (
). We compare our approach with other kinds of consistency and the state of the art in semi-supervised semantic segmentation. We denote simple one-way consistency as “simple”, Mean Teacher [
3] as “MT”, and our perturbations as “PhTPS”. In experiments that compare consistency variants, “1w” denotes one-way, “2w” denotes two way, “ct” denotes clean teacher, “cs” denotes clean student, and “2p” denotes both inputs perturbed. We present semi-supervised experiments in several semantic segmentation setups as well as in image-classification setups on CIFAR-10. Our implementations are based on the PyTorch framework [
68].
4.1. Experimental Setup
Datasets.We perform semantic segmentation on Cityscapes [
9], and image classification on CIFAR-10. Cityscapes contains 2975 training, 500 validation and 1525 testing images with resolution
. Images are acquired from a moving vehicle during daytime and fine weather conditions. We present half-resolution and full-resolution experiments. We use bilinear interpolation for images and nearest neighbour subsampling for labels. Some experiments on Cityscapes also use the coarsely labeled Cityscapes subset (“train-extra”) that contains 19,998 images. CIFAR-10 consists of 50,000 training and 10,000 test images of resolution
.
Common setup. We include both unlabeled and labeled images in
, which we use for the consistency loss. We train on batches of
labeled and
unlabeled images. We perform
training steps per epoch. We use the same perturbation model across all datasets and tasks (TPS displacements are proportional to image size), which is likely suboptimal [
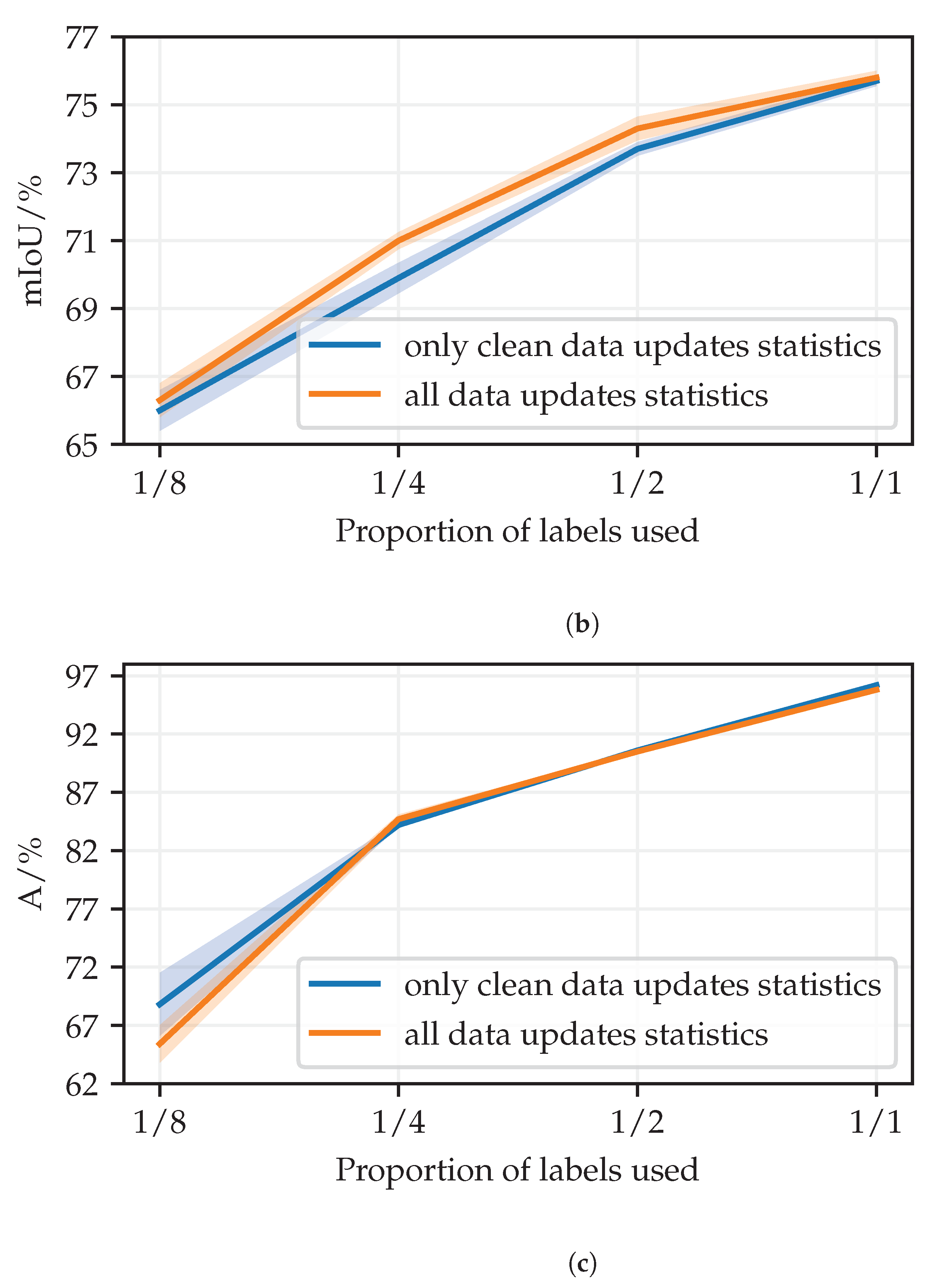
69]. Batch normalization statistics are updated only in non-teacher model instances with clean inputs except for full-resolution Cityscapes, for which updating the statistics in the perturbed student performed better in our validation experiments (cf.
Appendix B). The teacher always uses the estimated population statistics, and does not update them. In Mean Teacher, the teacher uses an exponential moving average of the student’s estimated population statistics.
Semantic segmentation setup. Cityscapes experiments involve the following models: SwiftNet with ResNet-18 (SwiftNet-RN18) or ResNet-34 (SwiftNet-RN34), and DeepLab v2 with a ResNet-101 backbone. We initialize the backbones with ImageNet pre-trained parameters. We apply random scaling, cropping, and horizontal flipping to all inputs and segmentation labels. We refer to such examples as clean. We schedule the learning rate according to
, where
is the fraction of epochs completed. This alleviates the generalization drop at the end of training with standard cosine annealing [
70]. We use learning rates
for randomly initialized parameters and
for pre-trained parameters. We use Adam with
. The L
regularization weight in supervised experiments is
for randomly initialized and
for pre-trained parameters [
27]. We have found that such L
regularization is too strong for our full-resolution semi-supervised experiments. Thus, we use a 4× smaller weight there. Based on early validation experiments, we use
unless stated otherwise. Batch sizes are
for SwiftNet-RN18 [
27] and
for DeepLab v2 (ResNet-101 backbone) [
26]. The batch size in corresponding supervised experiments is
.
In half-resolution Cityscapes experiments the size of crops is
and the logarithm of the scaling factor is sampled from
. We train SwiftNet for
epochs (200 epochs or 74,200 iterations when all labels are used), and DeepLab v2 for
epochs (100 epochs or 74,300 iterations when all labels are used). In comparison with SwiftNet-RN18, DeepLab v2 incurs a 12-fold per-image slowdown during supervised training. However, it also requires less epochs since it has very few parameters with random initialization. Hence, semi-supervised DeepLab v2 trains more than 4× slower than SwiftNet-RN18 on RTX 2080Ti.
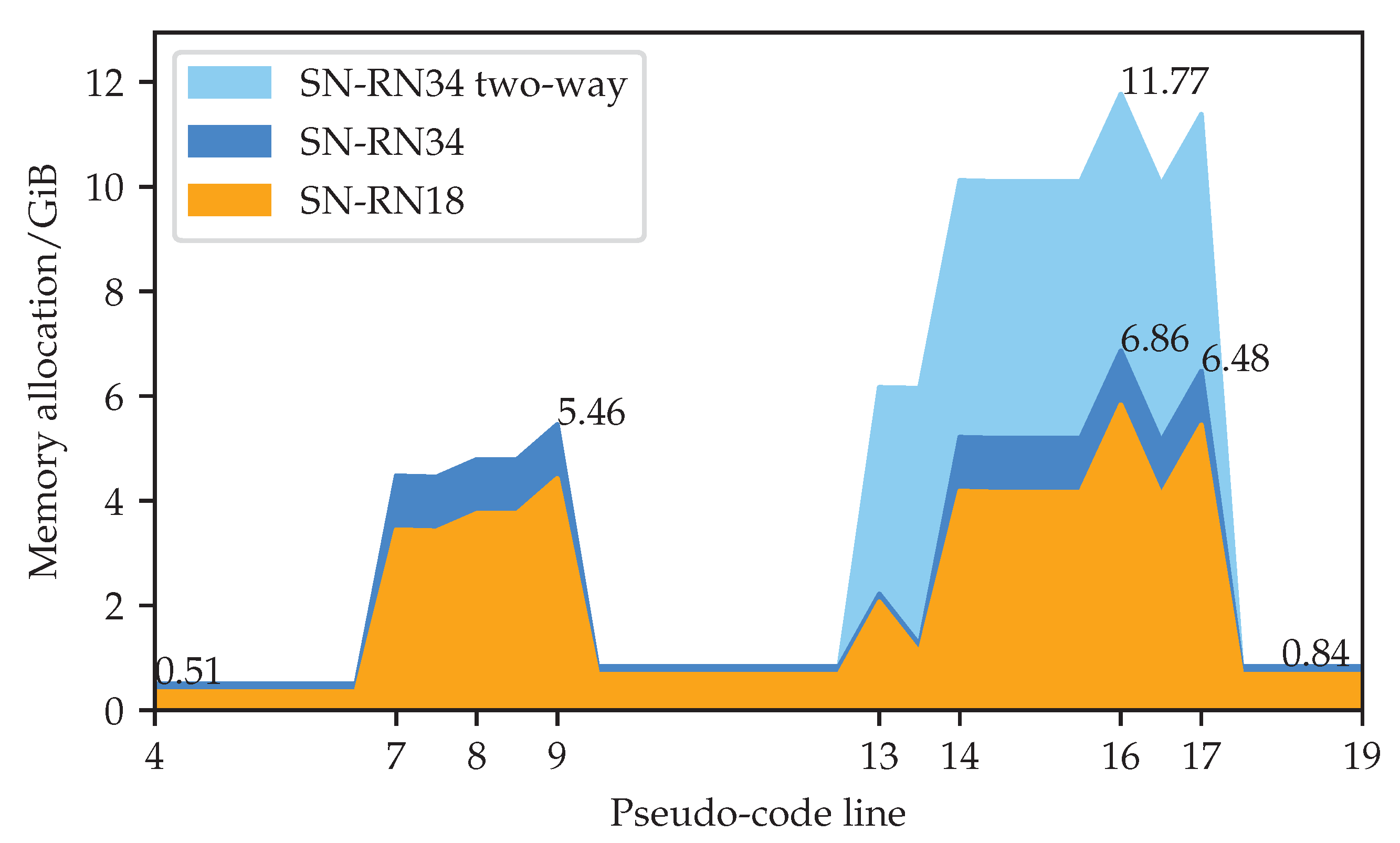
Appendix A.2 presents more detailed comparisons of memory and time requirements of different semi-supervised algorithms.
Our full-resolution experiments only use SwiftNet models. The crop size is and the spatial scaling is sampled from . The number of epochs is 250 when all labels are used. The batch size is 8 in supervised experiments, and in semi-supervised experiments.
Appendix A.1 presents an overview and comparison of hyper-parameters with other consistency-based methods that are compared in the experiments.
Classification setup. Classification experiments target CIFAR-10 and involve the Wide ResNet model WRN-28-2 with standard hyper-parameters [
71]. We augment all training images with random flips, padding and random cropping. We use all training images (including labeled images) in
for the consistency loss. Batch sizes are
. Thus, the number of iterations per epoch is
. For example, only one iteration is performed if
. We run
epochs in semi-supervised, and 100 epochs in supervised training. We use default VAT hyper-parameters
,
,
[
4]. We perform photometric perturbations as described, and sample TPS displacements from
.
Evaluation. We report generalization performance at the end of training. We report sample means and sample standard deviations (with Bessel’s correction) of the corresponding evaluation metric ( or classification accuracy) of 5 training runs, evaluated on the corresponding validation dataset.
4.2. Semantic Segmentation on Half-Resolution Cityscapes
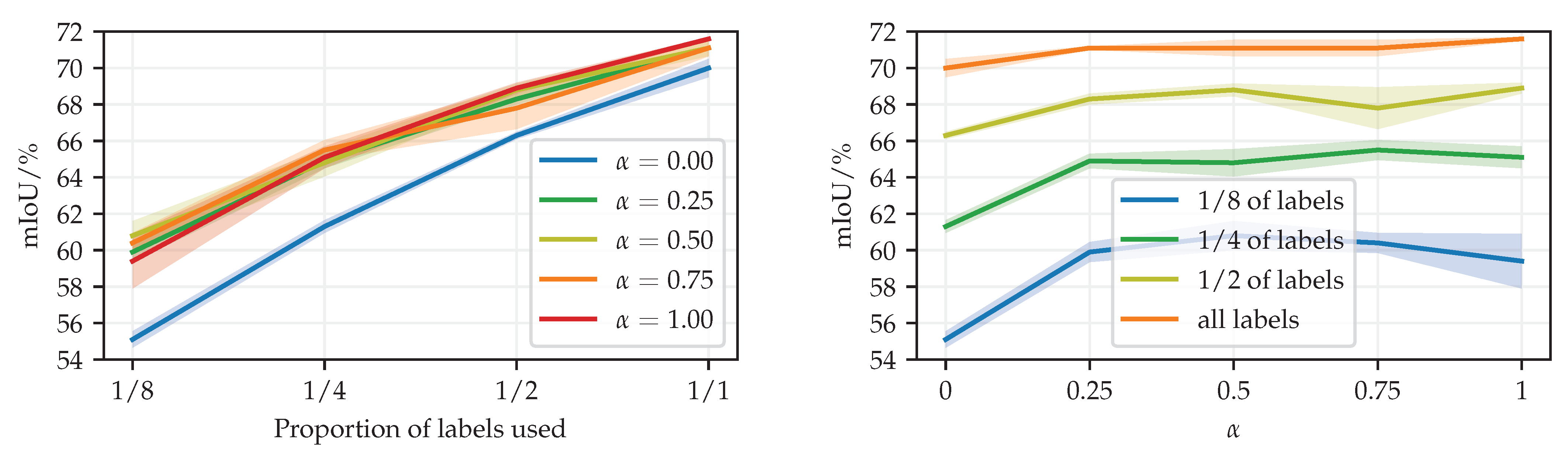
Table 1 compares our approach with the previous state of the art. We train using different proportions of training labels and evaluate mIoU on half-resolution Cityscapes val. The top section presents the previous work [
7,
8,
25,
57]. The middle section presents our experiments based on DeepLab v2 [
26]. Note that here we outperform some previous work due to more involved training (as described in
Section 4.1). since that would be a method of choice in all practical applications. Hence, we get consistently greater performance. We perform a proper comparison with [
25] by using our training setup in combination with their method. Our MT-PhTPS outperforms MT-CutMix with L2 loss and confidence thresholding when 1/4 or more labels are available, while underperforming with 1/8 labels.
The bottom section involves the efficient model SwiftNet-RN18. Our perturbation model outperforms CutMix both with simple consistency, as well as with Mean Teacher. Overall, Mean Teacher outperforms simple consistency. We observe that DeepLab v2 and SwiftNet-RN18 get very similar benefits from the consistency loss. SwiftNet-RN18 comes out as a method of choice due to about 12× faster inference than DeepLab v2 with ResNet-101 on RTX 2080Ti (see
Appendix A.2 for more details). Experiments from the middle and the bottom section use the same splits to ensure a fair comparison.
Now, we present ablation and hyper-parameter validation studies for simple-PhTPS consistency with SwiftNet-RN18.
Table 2 presents ablations of the perturbation model, and also includes supervised training with PhTPS augmentations in one half of each mini-batch in addition to standard jittering. Perturbing the whole mini-batch with PhTPS in supervised training did not improve upon the baseline. We observe that perturbing half of each mini-batch with PhTPS in addition to standard jittering improves the supervised performance, but quite less than semi-supervised training. Semi-supervised experiments suggest that photometric perturbations (Ph) contribute most, and that geometric perturbations (TPS) are not useful when there is
or more of the labels.
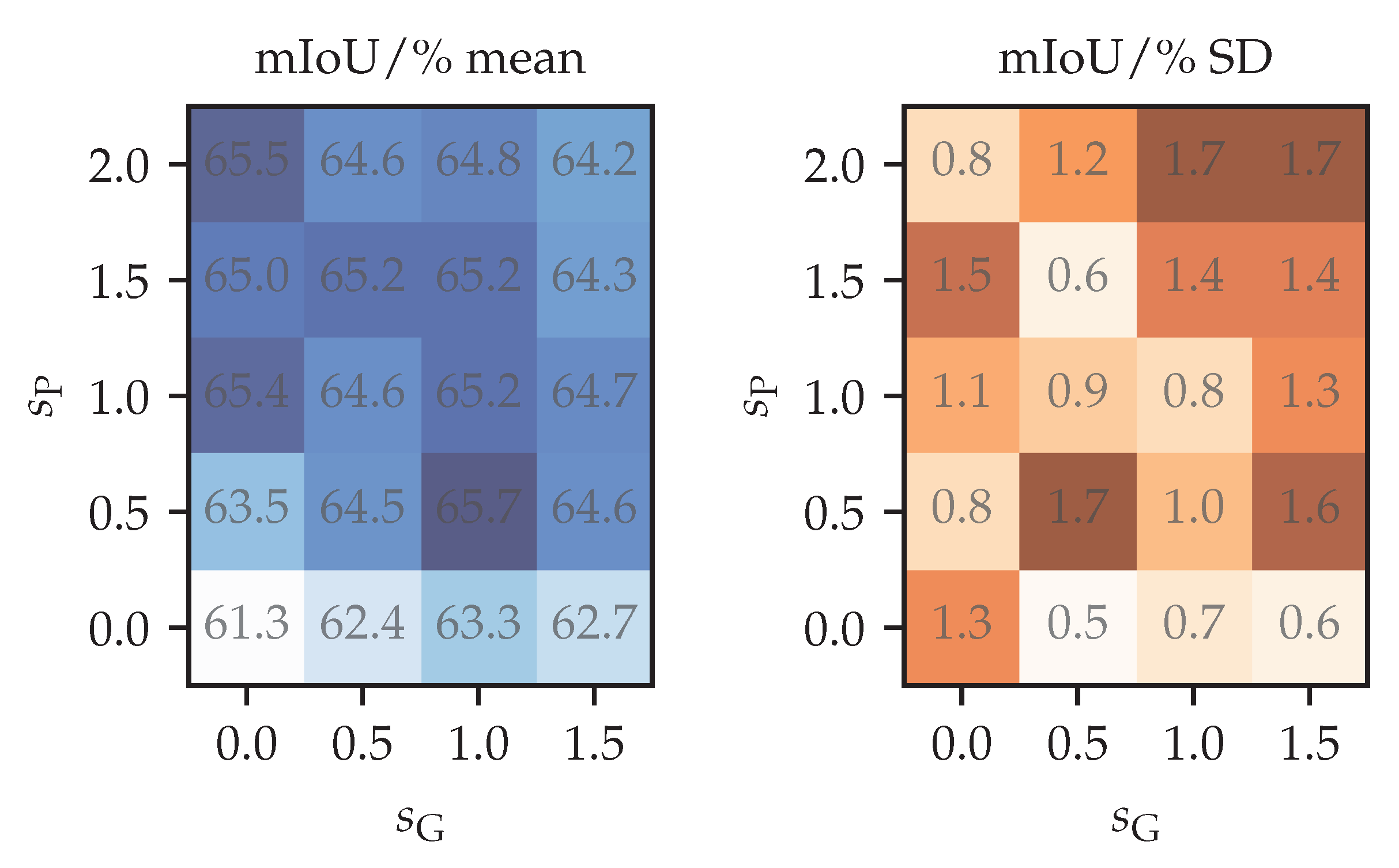
Figure 5 shows perturbation strength validation using
of the labels. Rows correspond to the factor that multiplies the standard deviation of control point displacements
defined at the end of
Section 3.4. Columns correspond to the strength of the photometric perturbation
. The photometric strength
modulates the random photometric parameters according to the following expression:
We set the probability of choosing a random channel permutation as
. Hence,
corresponds to the identity function. Note that the “
” column in
Table 2 uses the same semi-supervised configurations with strengths
. Moreover, note that the case
is slightly different from supervised training in that batch normalization statistics are still updated in the student. The differences in results are due to variance—the estimated standard error of the mean of 5 runs is between
and
. We can observe that the photometric component is more important, and that a stronger photometric component can compensate for a weaker geometric component. Our perturbation strength choice
is close to the optimum, which the experiments suggests to be at
.
Figure 6 shows our validation of the consistency loss weight
with SN-RN18 simple-PhTPS. We observe the best generalization performance for
. We do not scale the learning rate with
because we use a scale-invariant optimization algorithm.
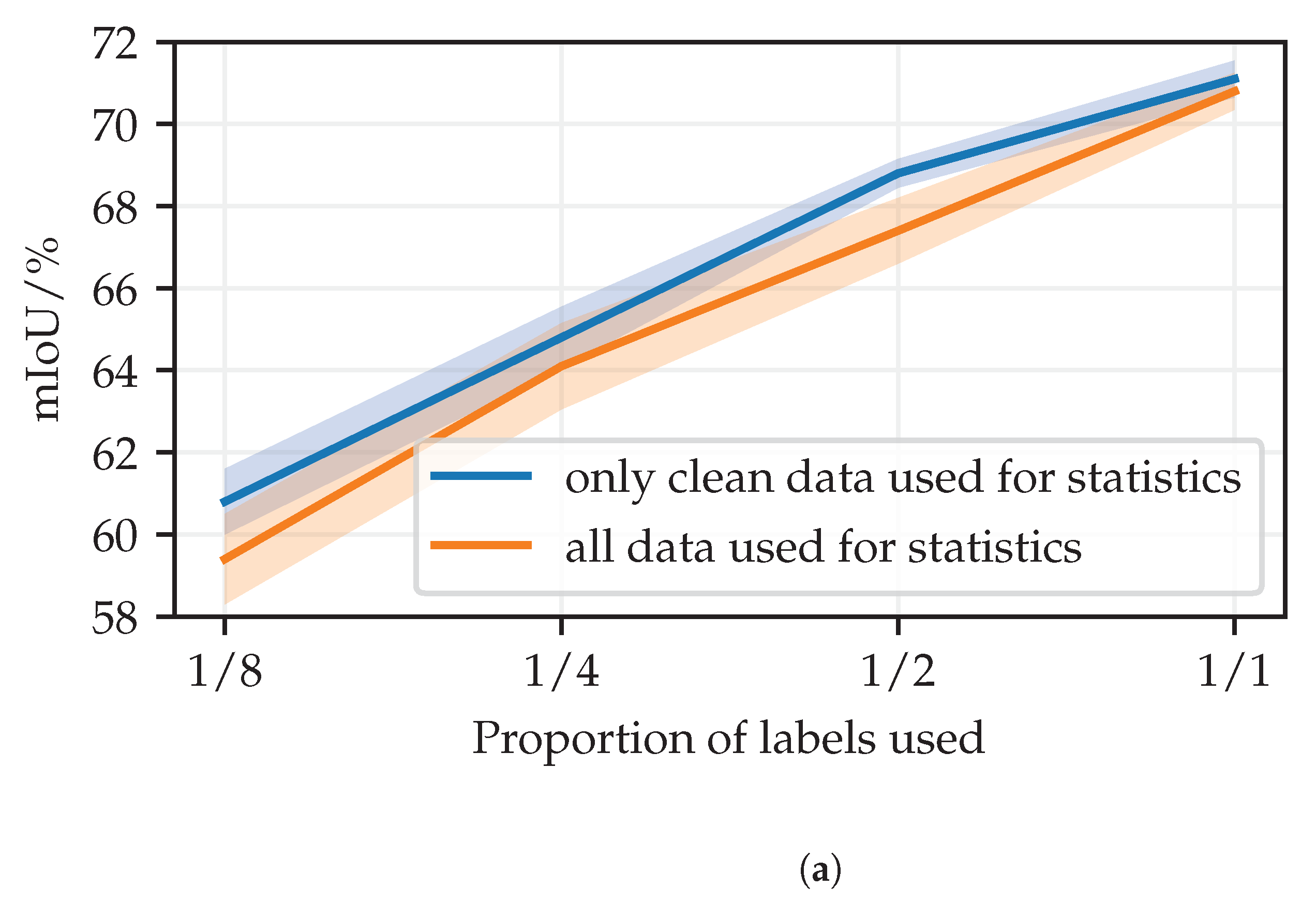
Appendix B presents experiments that quantify the effect of updating batch normalization statistics when the inputs are perturbed.
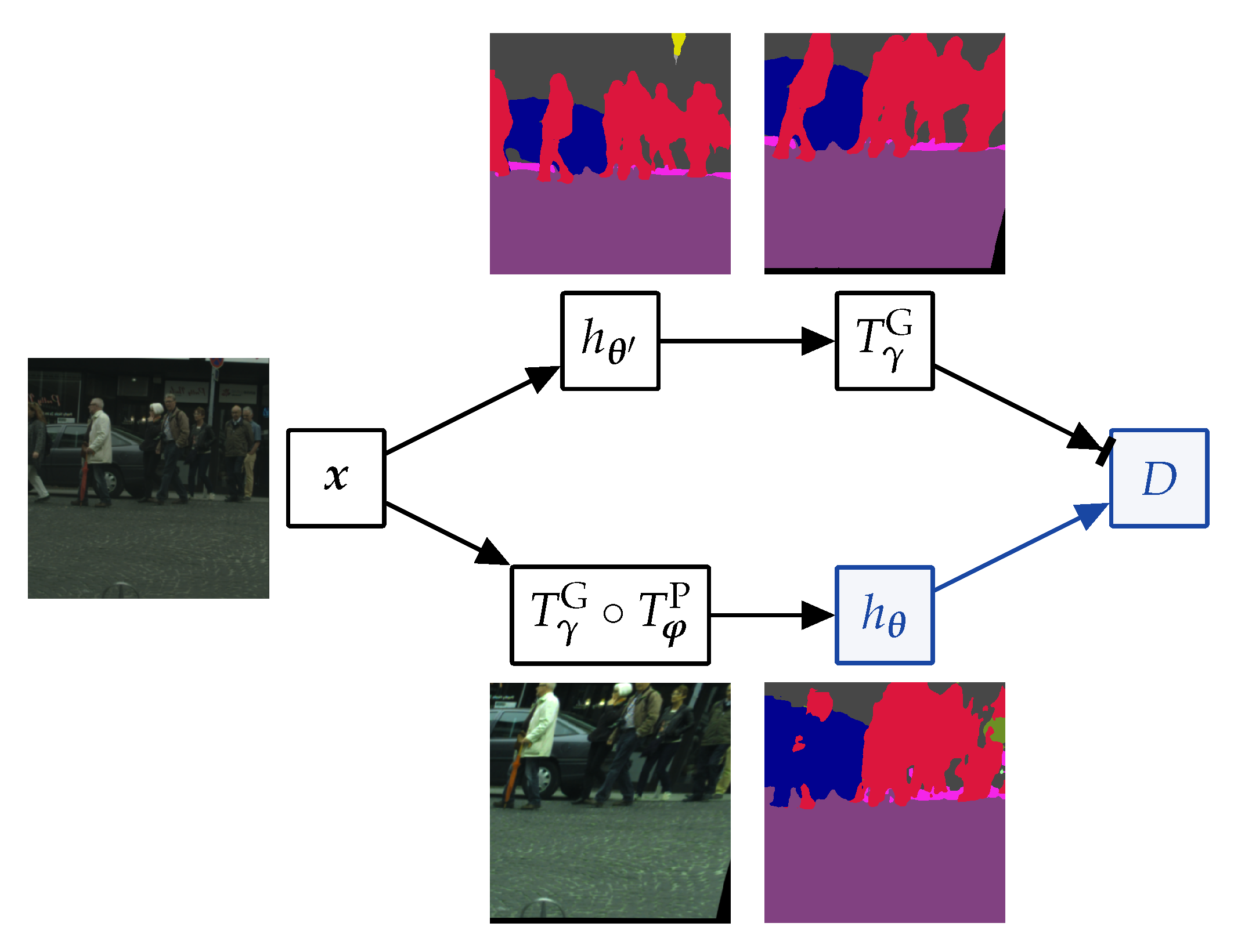
Figure 7 shows qualitative results on the first few validation images with SwiftNet-RN18 trained with
of labels. We observe that our method displays a substantial resilience to heavy perturbations, such as those used during training.
4.3. Semantic Segmentation on Full-Resolution Cityscapes
Table 3 presents our full resolution experiments in setups such as in
Table 1, and comparison with previous work, but with full-resolution images and labels. In comparison with KE-GAN [
53] and ECS [
57], we underperform with
labeled images, but outperform with
labeled images. Note that KE-GAN [
53] also trains on a large text corpus (MIT ConceptNet) as well as that ECS DLv3
-RN50 requires 22 GiB of GPU memory with batch size 6 [
57], while our SN-RN18 simple-PhTPS requires less than 8 GiB of GPU memory with batch size 8 and can be trained on affordable GPU hardware.
Appendix A.2 presents more detailed memory and execution time comparisons with other algorithms.
We note that the concurrent approach DLv3
-RN50 CAC [
58] outperforms our method with 1/8 and 1/1 labels. However, ResNet-18 has significantly less capacity than ResNet-50. Therefore, the bottom section applies our method to the SwiftNet model with a ResNet-34 backbone, which still has less capacity than ResNet-50. The resulting model outperforms DLv3
-RN50 CAC across most configurations. This shows that our method consistently improves when more capacity is available.
We note that training DLv3
-RN50 CAC requires three RTX 2080Ti GPUs [
58], while our SN-RN34 simple-PhTPS setup requires less than 9 GiB of GPU memory and fits on a single such GPU. Moreover, SN-RN34 has about 4× faster inference than DLv3
-RN50 on RTX 2080Ti.
Finally, we present experiments in the large-data regime, where we place the whole fine subset into
. In some of these experiments, we also train on the large coarsely labeled subset. We denote the extent of supervision with subscripts “l” (labeled) and “u” (unlabeled). Hence,
in the table denotes the coarse subset without labels.
Table 4 investigates the impact of the coarse subset on the SwiftNet performance on the full-resolution Cityscapes val. We observe that semi-supervised learning brings considerable improvement with respect to fully supervised learning on fine labels only (columns
vs.
). It is also interesting to compare the proposed semi-supervised setup (
) with classic fully supervised learning on both subsets (
). We observe that semi-supervised learning with SwiftNet-RN18 comes close to supervised learning with coarse labels. Moreover, semi-supervised learning prevails when we plug in the SwiftNet-RN34. These experiments suggest that semi-supervised training represents an attractive alternative to coarse labels and large annotation efforts.
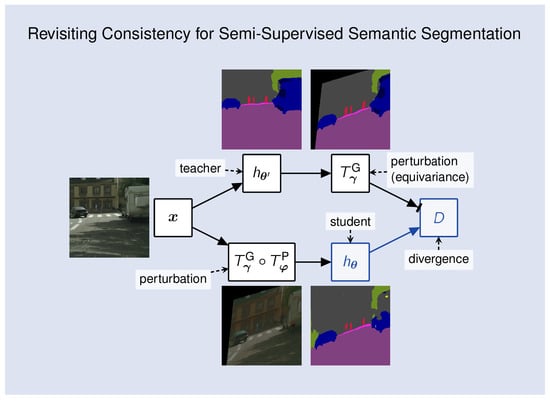
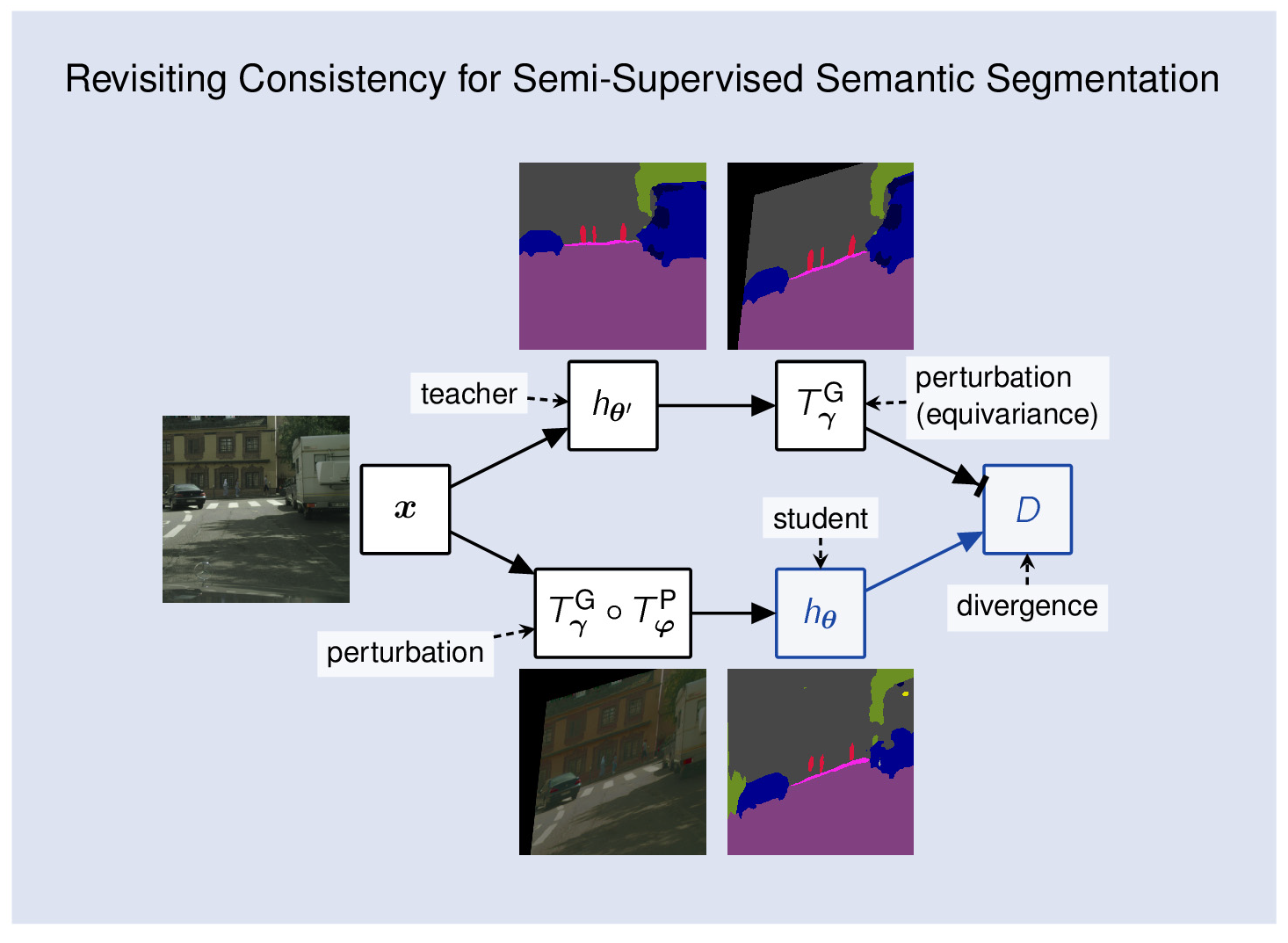
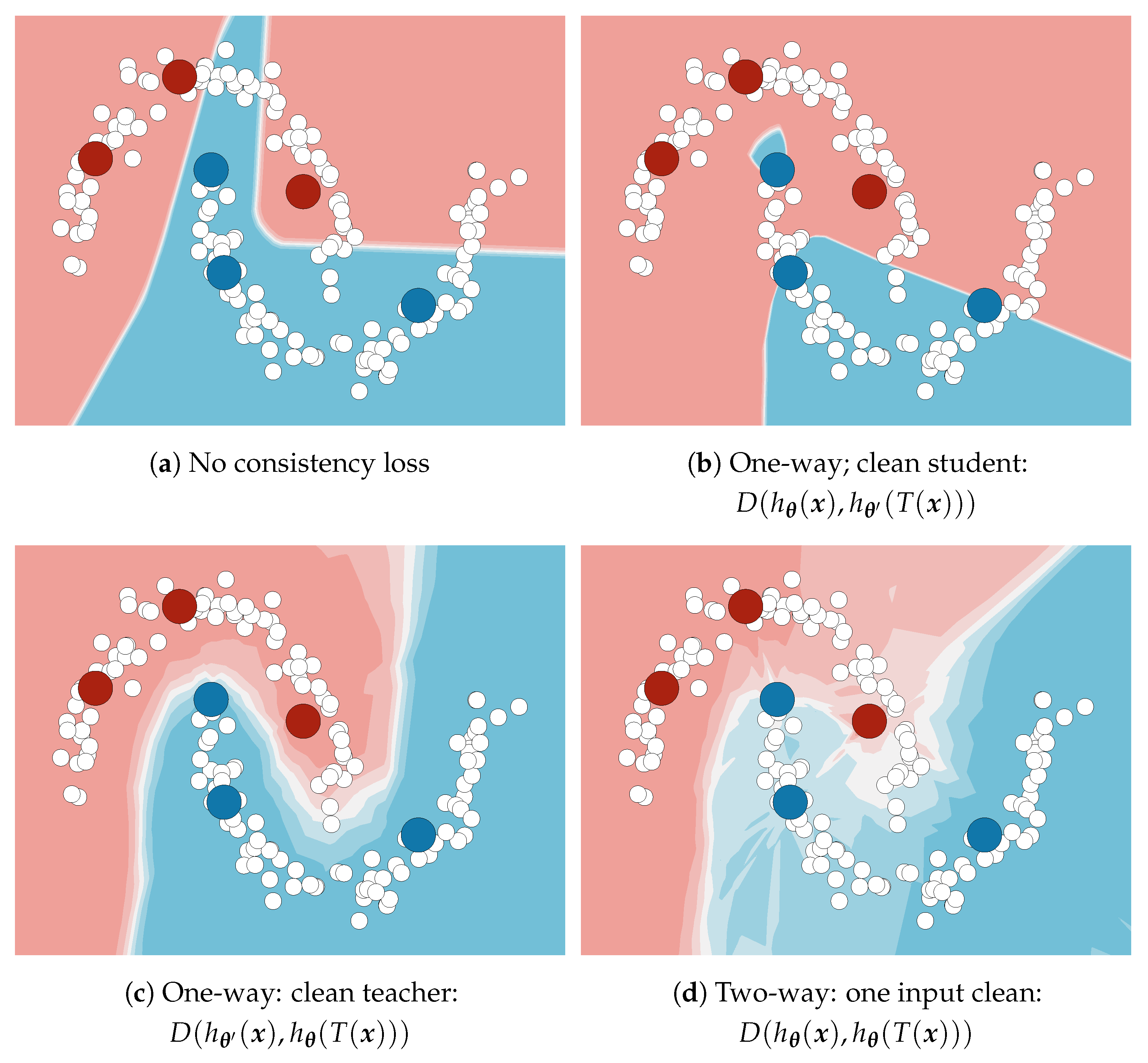
4.4. Validation of Consistency Variants
Table 5 presents experiments with supervised baselines and four variants of semi-supervised consistency training. All semi-supervised experiments use the same PhTPS perturbations on CIFAR-10 (4000 labels and 50,000 images) and half-resolution Cityscapes (the SwiftNet-RN18 setups with
labels from
Table 1). We investigate the following kinds of consistency: one-way with clean teacher (1w-ct, cf.
Figure 1c), one-way with clean student (1w-cs, cf.
Figure 1b), two-way with one clean input (2w-c1, cf.
Figure 1d), and one-way with both inputs perturbed (1w-p2). Note that two-way consistency is not possible with Mean Teacher. Moreover, when both inputs are perturbed (1w-p2), we have to use the inverse geometric transformation on dense predictions [
20]. We achieve that by forward warping [
72] with the same displacement field. Two-way consistency with both inputs perturbed (2w-p2) is possible as well. We expect it to behave similarly to 1w-2p because it could be observed as a superposition of two opposite one-way consistencies, and our preliminary experiments suggest as much.
We observe that 1w-ct outperforms all other variants, while 2w-c1 performs in-between 1w-ct and 1w-cs. This confirms our hypothesis that predictions in clean inputs make better consistency targets. We note that 1w-p2 often outperforms 1w-cs, while always underperforming with respect to 1w-ct. A closer inspection suggests that 1w-p2 sometimes learns to cheat the consistency loss by outputting similar predictions for all perturbed images. This occurs more often when batch normalization uses the batch statistics estimated during training. A closer inspection of 1w-cs experiments on Cityscapes indicates the consistency cheating combined with severe overfitting to the training dataset.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








