
UAV’s Status Is Worth Considering: A Fusion Representations Matching Method for Geo-Localization

Abstract
:1. Introduction
1.1. Related Work of Geo-Localization Methods
1.2. Related Work of Multimodal
1.3. Related Work of Pooling
1.4. Contributions
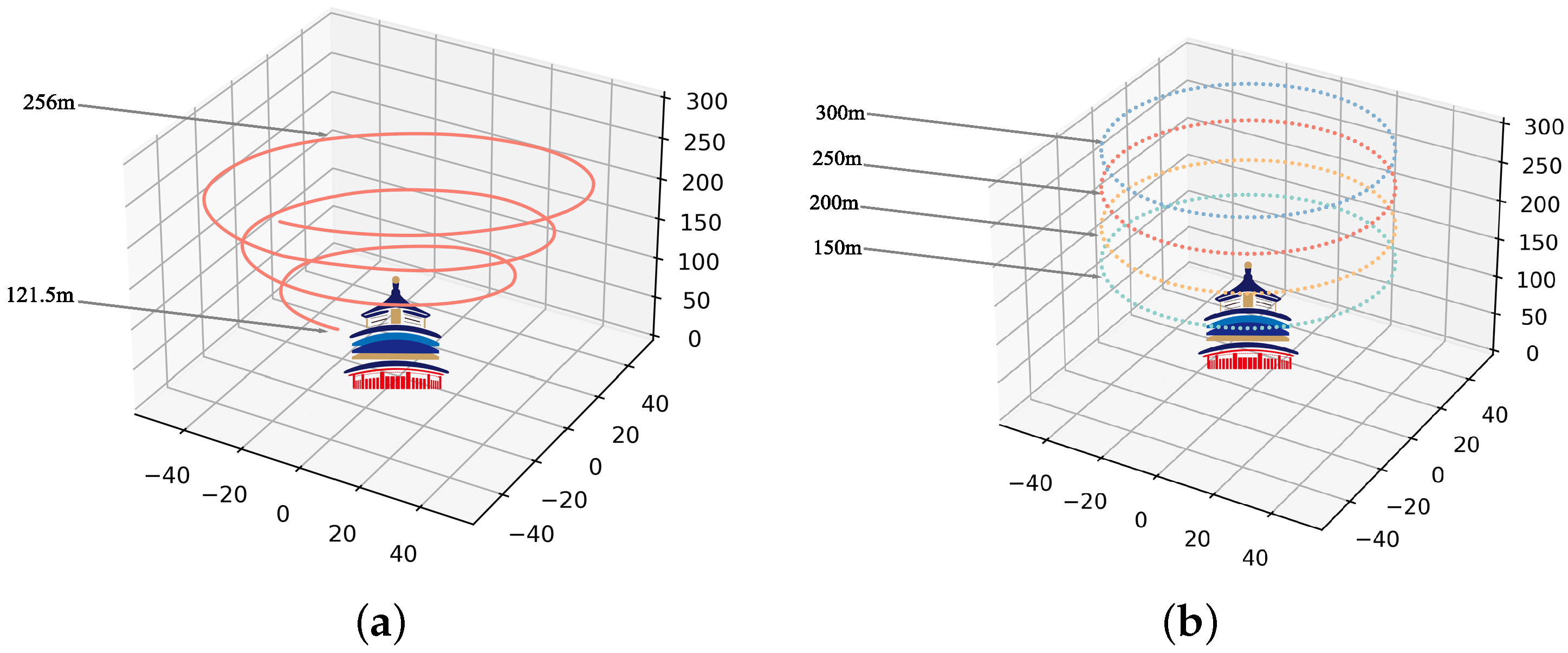
2. Datasets
2.1. University-1652
2.2. SUES-200
2.3. Evaluation Indicators
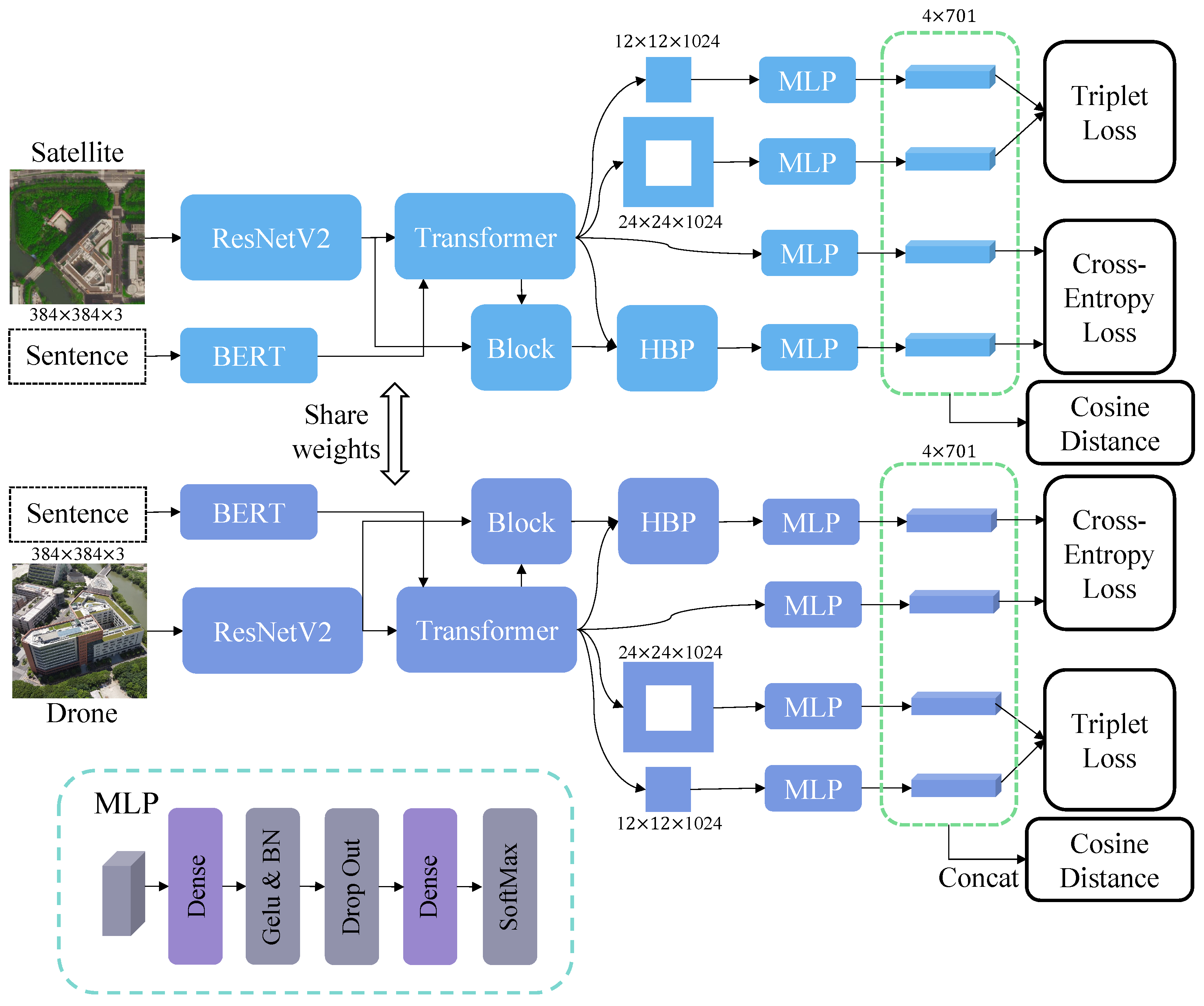
3. Method
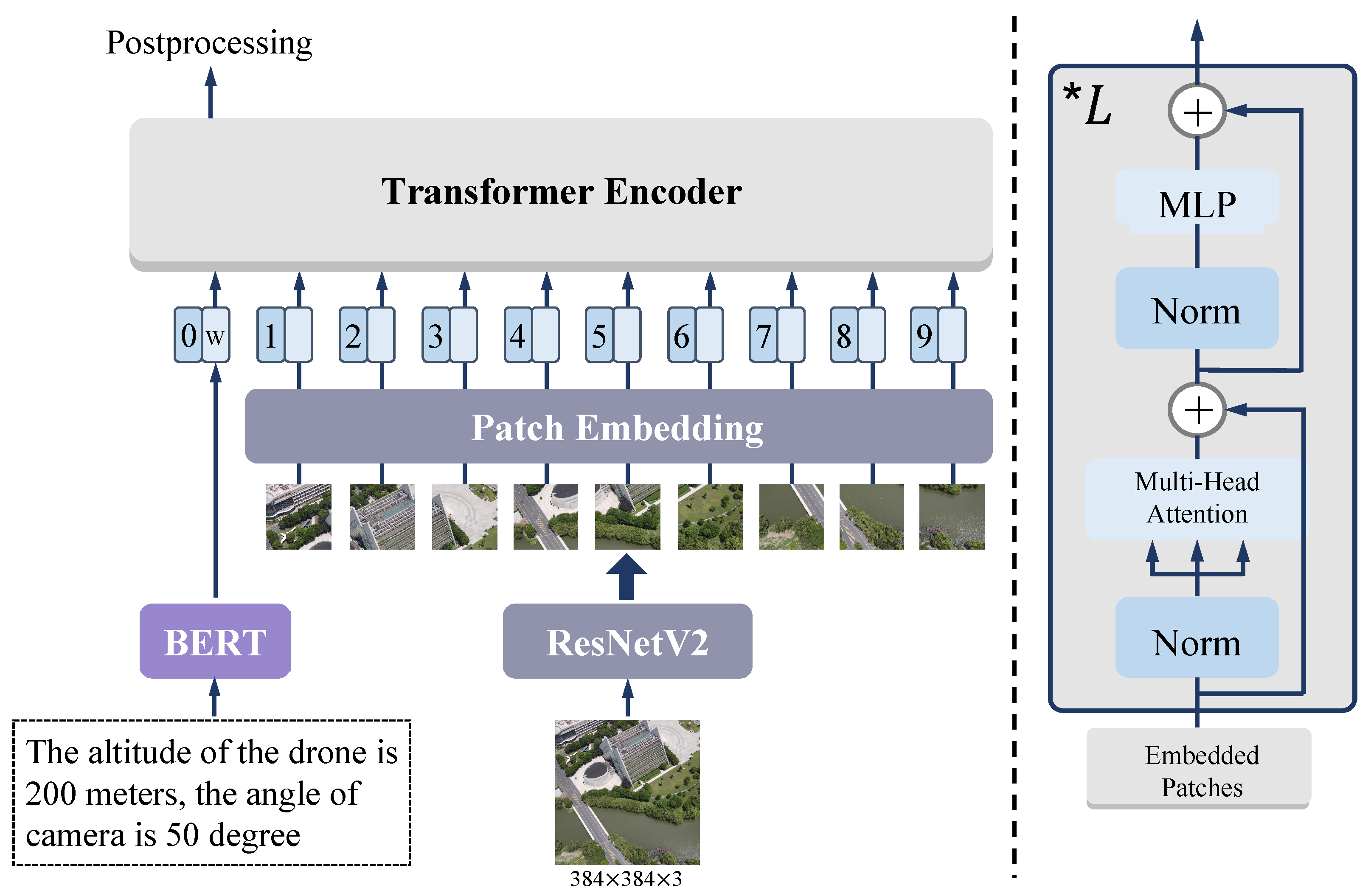
3.1. Backbone
3.2. Multimodal
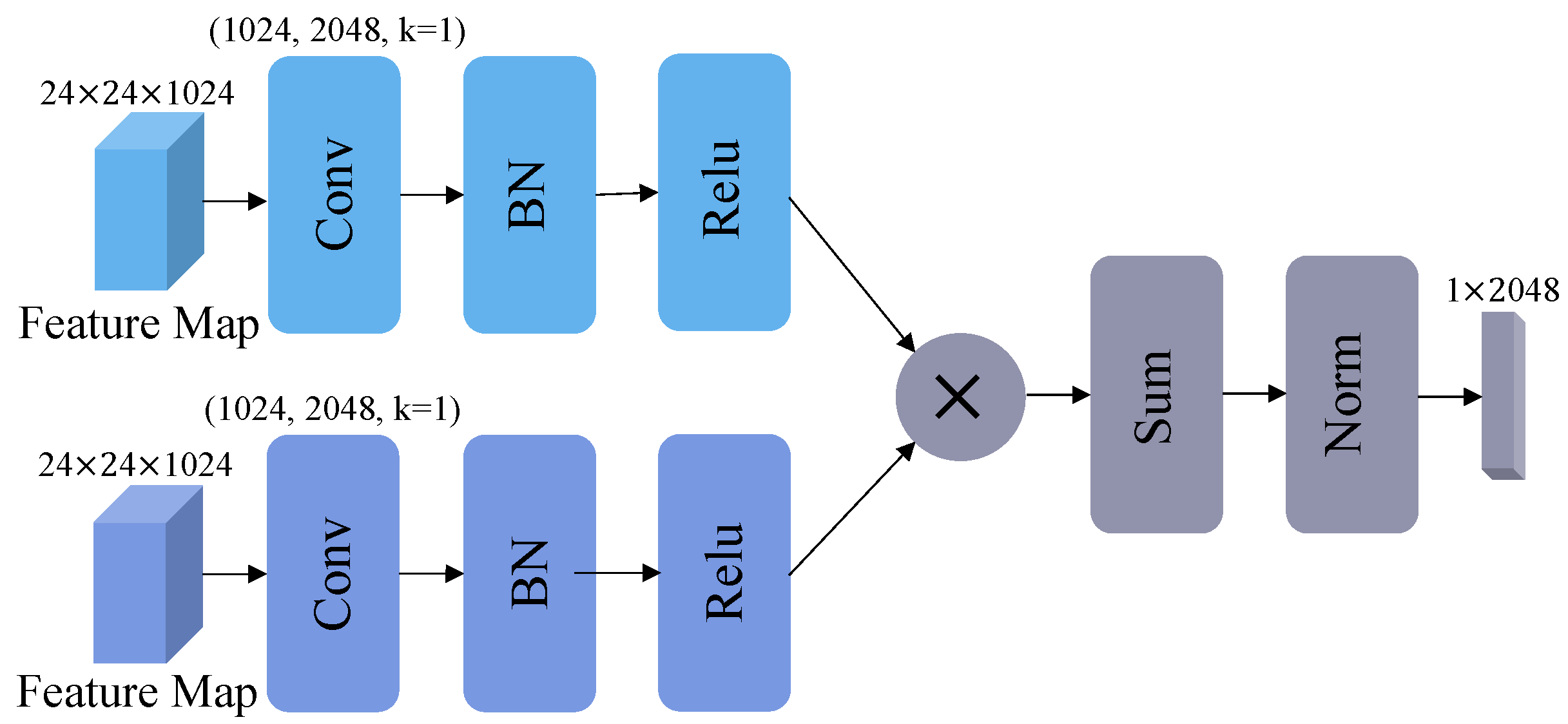
3.3. Bilinear Pooling
3.4. Improvement and Loss Function
4. Experiments
4.1. Implement Details
4.2. Comparison with the State-of-the-Art
4.3. Ablation Study of Methods
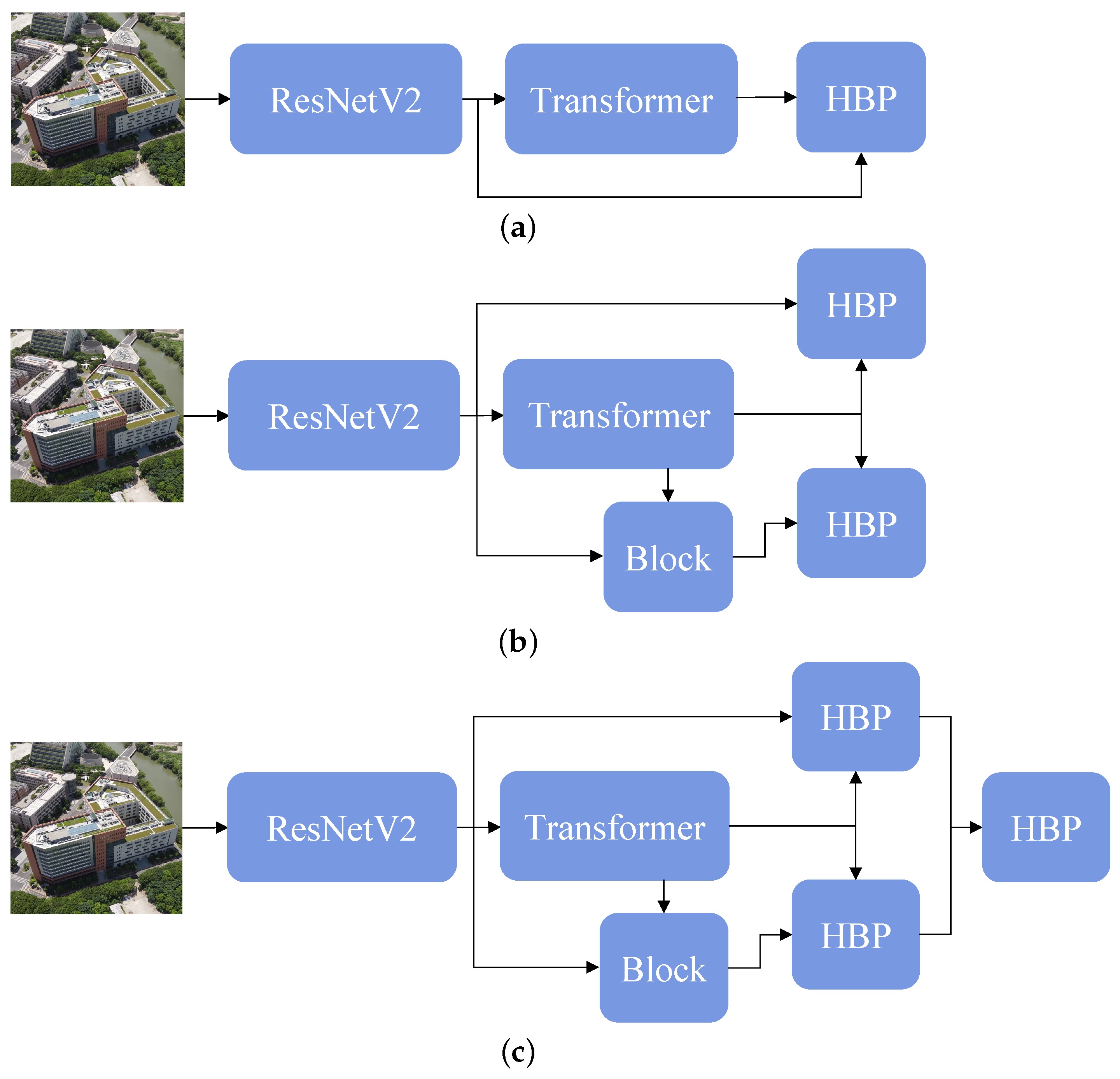
4.3.1. Effect of the Fusion Timing
4.3.2. Effect of the HBP Design
4.3.3. Effect of the Part Feature Numbers
4.3.4. Effect of the Proposed Methods
4.4. Shifted Query
4.5. Multi Query
4.6. Inference Time
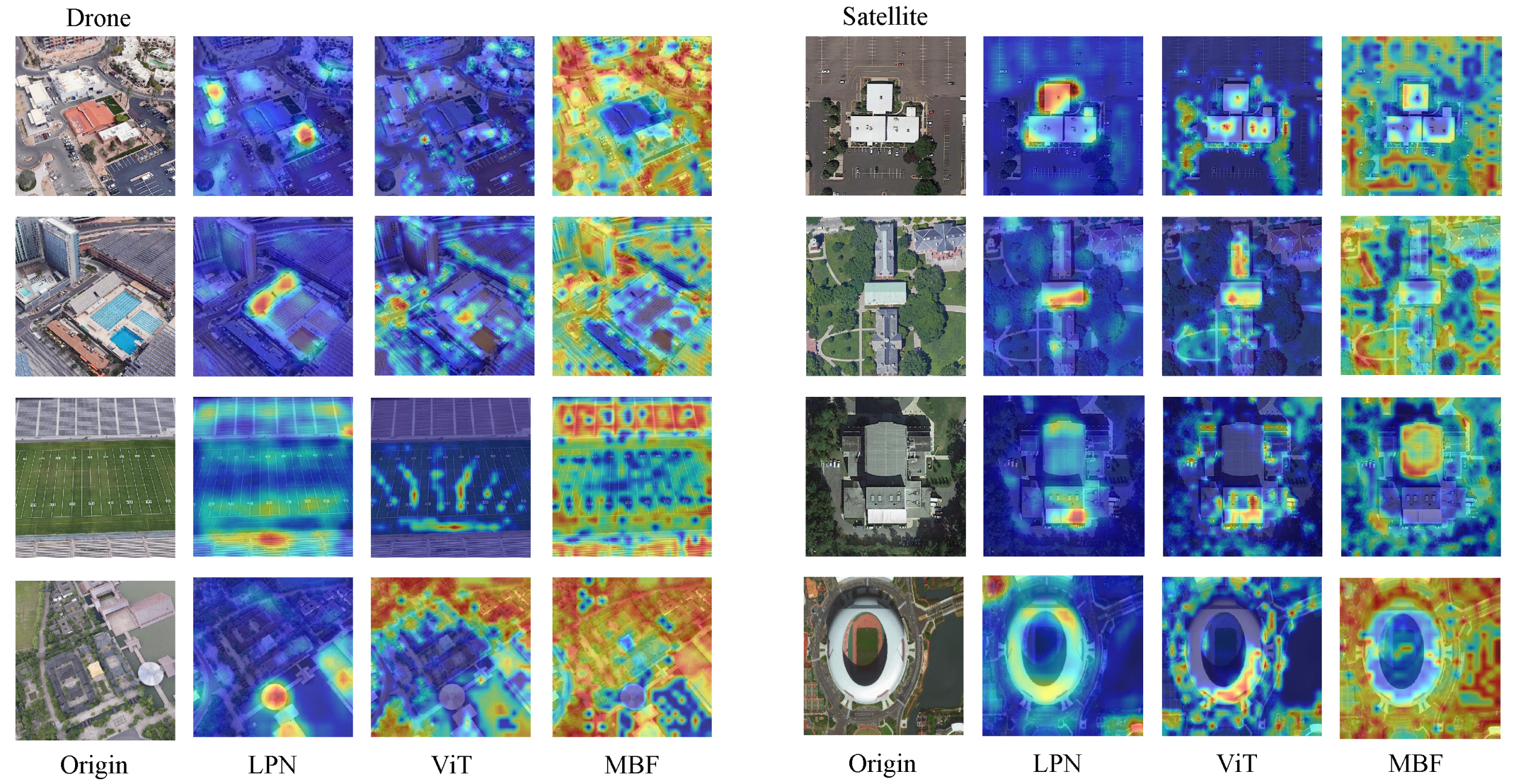
4.7. Visualization
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MBF | Multimodal Bilinear Feature Fusion Method |
| HBP | Hierarchical Bilinear Pooling |
| UAV | Unmanned Aerial Vehicles |
| GNSS | Global Navigation Satellite System |
| FPS | Feature Partition Strategy |
| BERT | Bidirectional Encoder Representations from Transformers |
| ReID | Re-identification |
| VQA | Visual Question Answering |
| R@K | Recall@K |
| AP | Average Precision |
References
- Wang, Y.; Li, S.; Lin, Y.; Wang, M. Lightweight Deep Neural Network Method for Water Body Extraction from High-Resolution Remote Sensing Images with Multisensors. Sensors 2021, 21, 7397. [Google Scholar] [CrossRef] [PubMed]
- Suo, C.; Zhao, J.; Zhang, W.; Li, P.; Huang, R.; Zhu, J.; Tan, X. Research on UAV Three-Phase Transmission Line Tracking and Localization Method Based on Electric Field Sensor Array. Sensors 2021, 21, 8400. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Zhu, J.; Bu, T.; Gao, X. Monitoring and Identification of Road Construction Safety Factors via UAV. Sensors 2022, 22, 8797. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.L.; He, R.; Peng, C.C. Development of an Online Adaptive Parameter Tuning vSLAM Algorithm for UAVs in GPS-Denied Environments. Sensors 2022, 22, 8067. [Google Scholar] [CrossRef]
- Hassan, S.I.; Alam, M.M.; Zia, M.Y.I.; Rashid, M.; Illahi, U.; Su’ud, M.M. Rice Crop Counting Using Aerial Imagery and GIS for the Assessment of Soil Health to Increase Crop Yield. Sensors 2022, 22, 8567. [Google Scholar] [CrossRef]
- Oh, D.; Han, J. Smart Search System of Autonomous Flight UAVs for Disaster Rescue. Sensors 2021, 21, 6810. [Google Scholar] [CrossRef]
- Bansal, M.; Sawhney, H.S.; Cheng, H.; Daniilidis, K. Geo-localization of street views with aerial image databases. In Proceedings of the 19th ACM international conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1125–1128. [Google Scholar]
- Senlet, T.; Elgammal, A. A framework for global vehicle localization using stereo images and satellite and road maps. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2034–2041. [Google Scholar]
- Lin, T.Y.; Belongie, S.; Hays, J. Cross-view image geolocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 891–898. [Google Scholar]
- Castaldo, F.; Zamir, A.; Angst, R.; Palmieri, F.; Savarese, S. Semantic cross-view matching. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 9–17. [Google Scholar]
- Gao, J.; Sun, Z. An Improved ASIFT Image Feature Matching Algorithm Based on POS Information. Sensors 2022, 22, 7749. [Google Scholar] [CrossRef]
- Lin, T.Y.; Cui, Y.; Belongie, S.; Hays, J. Learning deep representations for ground-to-aerial geolocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5007–5015. [Google Scholar]
- Tian, Y.; Chen, C.; Shah, M. Cross-view image matching for geo-localization in urban environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3608–3616. [Google Scholar]
- Workman, S.; Souvenir, R.; Jacobs, N. Wide-area image geolocalization with aerial reference imagery. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3961–3969. [Google Scholar]
- Liu, L.; Li, H. Lending orientation to neural networks for cross-view geo-localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5624–5633. [Google Scholar]
- Zheng, Z.; Wei, Y.; Yang, Y. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. In Proceedings of the 28th ACM international conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1395–1403. [Google Scholar]
- Ding, L.; Zhou, J.; Meng, L.; Long, Z. A practical cross-view image matching method between UAV and satellite for UAV-based geo-localization. Remote Sens. 2020, 13, 47. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, T.; Zheng, Z.; Yan, C.; Zhang, J.; Sun, Y.; Zhenga, B.; Yang, Y. Each part matters: Local patterns facilitate cross-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 867–879. [Google Scholar] [CrossRef]
- Zhuang, J.; Dai, M.; Chen, X.; Zheng, E. A Faster and More Effective Cross-View Matching Method of UAV and Satellite Images for UAV Geolocalization. Remote Sens. 2021, 13, 3979. [Google Scholar] [CrossRef]
- Tian, X.; Shao, J.; Ouyang, D.; Shen, H.T. UAV-Satellite View Synthesis for Cross-view Geo-Localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4804–4815. [Google Scholar] [CrossRef]
- Dai, M.; Hu, J.; Zhuang, J.; Zheng, E. A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4376–4389. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yang, H.; Lu, X.; Zhu, Y. Cross-view geo-localization with layer-to-layer transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 29009–29020. [Google Scholar]
- Zhu, S.; Yang, T.; Chen, C. Vigor: Cross-view image geo-localization beyond one-to-one retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3640–3649. [Google Scholar]
- Chen, Y.C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Universal image-text representation learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 104–120. [Google Scholar]
- Huang, Z.; Zeng, Z.; Huang, Y.; Liu, B.; Fu, D.; Fu, J. Seeing out of the box: End-to-end pre-training for vision-language representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12976–12985. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wang, X.; Li, S.; Chen, C.; Fang, Y.; Hao, A.; Qin, H. Data-level recombination and lightweight fusion scheme for RGB-D salient object detection. IEEE Trans. Image Process. 2020, 30, 458–471. [Google Scholar] [CrossRef]
- George, A.; Marcel, S. Cross modal focal loss for rgbd face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7882–7891. [Google Scholar]
- Zheng, A.; Wang, Z.; Chen, Z.; Li, C.; Tang, J. Robust Multi-Modality Person Re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3529–3537. [Google Scholar]
- Razavian, A.S.; Sullivan, J.; Carlsson, S.; Maki, A. Visual instance retrieval with deep convolutional networks. ITE Trans. Media Technol. Appl. 2016, 4, 251–258. [Google Scholar] [CrossRef] [Green Version]
- Babenko, A.; Lempitsky, V. Aggregating deep convolutional features for image retrieval. arXiv 2015, arXiv:1510.07493. [Google Scholar]
- Mousavian, A.; Kosecka, J. Deep convolutional features for image based retrieval and scene categorization. arXiv 2015, arXiv:1509.06033. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. Fine-tuning CNN image retrieval with no human annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1655–1668. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar]
- Gao, Y.; Beijbom, O.; Zhang, N.; Darrell, T. Compact bilinear pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 317–326. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the EMNLP, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Yu, C.; Zhao, X.; Zheng, Q.; Zhang, P.; You, X. Hierarchical bilinear pooling for fine-grained visual recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 574–589. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Zhu, R. SUES-200: A Multi-height Multi-scene Cross-view Image Benchmark Across Drone and Satellite. arXiv 2022, arXiv:2204.10704. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-aligned bilinear representations for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 402–419. [Google Scholar]
- Hu, Q.; Li, W.; Xu, X.; Liu, N.; Wang, L. Learning discriminative representations via variational self-distillation for cross-view geo-localization. Comput. Electr. Eng. 2022, 103, 108335. [Google Scholar] [CrossRef]
- Zhuang, J.; Chen, X.; Dai, M.; Lan, W.; Cai, Y.; Zheng, E. A Semantic Guidance and Transformer-Based Matching Method for UAVs and Satellite Images for UAV Geo-Localization. IEEE Access 2022, 10, 34277–34287. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Xiao, G.; Shao, Z.; Guo, X. A review of multimodal image matching: Methods and applications. Inf. Fusion 2021, 73, 22–71. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Author |
|---|---|
| - | |
| CVUSA | Workman et al. [14] |
| CVACT | Liu et al. [15] |
| L2LTR | Yang et al. [24] |
| VIGOR | Zhu et al. [25] |
| - | |
| University-1652 | Zheng et al. [16]. |
| LCM | Ding et al. [17] |
| LPN | Wang et al. [19] |
| PCL | Tian et al. [21] |
| FSRA | Dai et al. [22] |
| MSBA | Zhuang et al. [20] |
| Training Dataset | ||
|---|---|---|
| Views | Classes | Images |
| Drone | 701 | 37,854 |
| Satellite | 701 | 701 |
| Testing Dataset | ||
| Views | Classes | Images |
| Drone Query | 701 | 37,854 |
| Satellite Query | 701 | 701 |
| Drone Gallery | 951 | 51,355 |
| Satellite Gallery | 951 | 951 |
| Training Dataset | |||
|---|---|---|---|
| Views | Classes | Images at Each Height | Images |
| Drone | 120 | 6000 | 24,000 |
| Satellite | 120 | _ | 120 |
| Testing Dataset | |||
| Views | Classes | Images at Each Height | Images |
| Drone query | 80 | 4000 | 16,000 |
| Satellite query | 80 | _ | 80 |
| Drone gallery | 200 | 10,000 | 40,000 |
| Satellite gallery | 200 | _ | 200 |
| Method | Image Size | ||||
|---|---|---|---|---|---|
| Recall@1 | AP | Recall@1 | AP | ||
| Baseline [16] | 384 × 384 | 62.99 | 67.69 | 75.75 | 62.09 |
| LCM [17] | 384 × 384 | 66.65 | 70.82 | 79.89 | 65.38 |
| LPN [19] | 384 × 384 | 78.02 | 80.99 | 86.16 | 76.56 |
| LDRVSD [48] | 384 × 384 | 81.02 | 83.51 | 89.87 | 79.80 |
| SGM [49] | 256 × 256 | 82.14 | 84.72 | 88.16 | 81.81 |
| PCL [21] | 512 × 512 | 83.27 | 87.32 | 91.78 | 82.18 |
| FSRA [22] | 384 × 384 | 85.50 | 87.53 | 89.73 | 84.94 |
| MSBA [20] | 384 × 384 | 86.61 | 88.55 | 92.15 | 84.45 |
| MBF | 384 × 384 | 89.05 | 90.61 | 93.15 | 88.17 |
| Method | 150 m | 200 m | 250 m | 300 m | ||||
| Recall@1 | AP | Recall@1 | AP | Recall@1 | AP | Recall@1 | AP | |
| Baseline [43] | 55.65 | 61.92 | 66.78 | 71.55 | 72.00 | 76.43 | 74.05 | 78.26 |
| ViT [43] | 59.32 | 64.94 | 62.30 | 67.22 | 71.35 | 75.48 | 77.17 | 80.67 |
| LCM [17] | 43.42 | 49.65 | 49.42 | 55.91 | 54.47 | 60.31 | 60.43 | 65.78 |
| LPN [19] | 61.58 | 67.23 | 70.85 | 75.96 | 80.38 | 83.80 | 81.47 | 84.53 |
| MBF | 85.62 | 88.21 | 87.43 | 90.02 | 90.65 | 92.53 | 92.12 | 93.63 |
| Method | 150 m | 200 m | 250 m | 300 m | ||||
| Recall@1 | AP | Recall@1 | AP | Recall@1 | AP | Recall@1 | AP | |
| Baseline [43] | 75.00 | 55.46 | 85.00 | 66.05 | 86.25 | 69.94 | 88.75 | 74.46 |
| ViT [43] | 82.50 | 58.88 | 87.50 | 62.48 | 90.00 | 69.91 | 96.25 | 84.10 |
| LCM [17] | 57.50 | 38.11 | 68.75 | 49.19 | 72.50 | 47.94 | 75.00 | 59.36 |
| LPN [19] | 83.75 | 66.78 | 88.75 | 75.01 | 92.50 | 81.34 | 92.50 | 85.72 |
| MBF | 88.75 | 84.74 | 91.25 | 89.95 | 93.75 | 90.65 | 96.25 | 91.60 |
| Timing | ||||
|---|---|---|---|---|
| Recall@1 | AP | Recall@1 | AP | |
| Progressive | 86.27 | 88.25 | 91.73 | 85.92 |
| Late | 85.65 | 87.71 | 90.58 | 85.28 |
| HBP Design | ||||
|---|---|---|---|---|
| Recall@1 | AP | Recall@1 | AP | |
| Basic HBP | 84.55 | 86.70 | 90.30 | 83.97 |
| Double HBP | 86.39 | 88.38 | 91.58 | 85.34 |
| Triplet HBP | 86.95 | 88.93 | 91.87 | 86.24 |
| Numbers | ||||
|---|---|---|---|---|
| Recall@1 | AP | Recall@1 | AP | |
| 1 | 85.96 | 88.02 | 91.30 | 85.93 |
| 2 | 87.49 | 89.30 | 91.87 | 87.53 |
| 3 | 87.27 | 89.13 | 91.44 | 87.32 |
| 4 | 87.28 | 89.16 | 91.44 | 87.39 |
| Method | ||||
|---|---|---|---|---|
| Recall@1 | AP | Recall@1 | AP | |
| Baseline | 83.52 | 85.94 | 90.30 | 84.38 |
| + Triplet Loss | 84.63 | 86.79 | 90.30 | 84.39 |
| + Multimodal | 86.27 | 88.25 | 91.73 | 85.92 |
| + HBP | 87.34 | 89.15 | 92.87 | 87.50 |
| + Part Feature | 89.05 | 90.61 | 93.15 | 88.17 |
| Shifted Pixel | ||||
|---|---|---|---|---|
| Recall@1 | AP | Recall@1 | AP | |
| 0 | 89.05 | 90.61 | 93.15 | 88.17 |
| 10 | 88.83 | 90.44 | 92.58 | 88.01 |
| 20 | 87.91 | 89.69 | 92.30 | 87.25 |
| 30 | 86.45 | 88.50 | 92.01 | 86.05 |
| 40 | 84.81 | 87.11 | 91.58 | 84.41 |
| Query | ||||
|---|---|---|---|---|
| Recall@1 | Recall@5 | Recall@10 | AP | |
| 54 | 93.15 | 96.58 | 97.86 | 94.02 |
| 27 | 93.08 | 96.65 | 97.79 | 93.96 |
| 18 | 92.72 | 96.81 | 97.86 | 93.70 |
| 9 | 92.70 | 96.81 | 97.79 | 93.68 |
| 3 | 91.85 | 96.67 | 97.65 | 92.99 |
| 2 | 91.21 | 96.42 | 97.47 | 92.42 |
| 1 | 89.05 | 95.76 | 97.04 | 90.61 |
| Method | ||||
|---|---|---|---|---|
| Recall@1 | Recall@5 | Recall@10 | AP | |
| Baseline | 69.33 | 86.73 | 91.16 | 73.14 |
| LCM [17] | 77.89 | 91.30 | 94.58 | 81.05 |
| PCL [21] | 91.63 | 95.46 | 97.33 | 90.84 |
| MBF | 93.15 | 96.58 | 97.86 | 94.02 |
| Method | Step 1 | Step 2 |
|---|---|---|
| MBF | 2.56s | s |
| ViT-Base | 1.68s | s |
| LPN [19] | 1.01s | s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, R.; Yang, M.; Yin, L.; Wu, F.; Yang, Y. UAV’s Status Is Worth Considering: A Fusion Representations Matching Method for Geo-Localization. Sensors 2023, 23, 720. https://doi.org/10.3390/s23020720
Zhu R, Yang M, Yin L, Wu F, Yang Y. UAV’s Status Is Worth Considering: A Fusion Representations Matching Method for Geo-Localization. Sensors. 2023; 23(2):720. https://doi.org/10.3390/s23020720
Chicago/Turabian StyleZhu, Runzhe, Mingze Yang, Ling Yin, Fei Wu, and Yuncheng Yang. 2023. "UAV’s Status Is Worth Considering: A Fusion Representations Matching Method for Geo-Localization" Sensors 23, no. 2: 720. https://doi.org/10.3390/s23020720