1. Introduction
The integration of Internet of Things (IoT) systems with heterogeneous vehicular ad hoc networks (VANETs) has revitalized new capabilities in intelligent transportation systems (ITSs) [
1]. Through machine-to-machine (M2M) communication protocols and standards, facilities such as RFID, WSN, GPS, etc., the IoT complements the evolution of ITS applications [
2]. In fact, the future ITS is revolutionizing the transport system and autonomous mobility by the introduction of connected and autonomous vehicles (CAVs) with each vehicle having enormous capabilities in terms of storing, computing and networking (SCN). According to the worldwide CAV forecast from the International Data Corporation (IDC), the global market size of CAVs that are at upper levels of autonomy (
) will rise from 31.4 million units during the period 2019–2020 to 54.2 million units during the period 2024–2025, reflecting a five-year Compound Annual Growth Rate (CAGR) of 11.5%
https://www.idc.com/research/viewtoc.jsp?containerId=CA49221622, accessed on 20 October 2022). Feature by feature, the IoT adds novel capabilities for the smart, safe and secure operation of an incoming CAV fleet, a dramatic shift towards an increasingly autonomous future [
3].
However, as a curse of volume, vast amounts of data are generated, prompting a delay- and energy-critical analysis and processing. Each CAV is to be equipped with at least 200 on-board sensor units (OBUs) for gathering the ambient information; hence, a galactic volume of sensed data is generated when it is running on the road [
1]. According to preliminary estimates, a CAV generates approximately 30 terabytes of data every day. Furthermore, there will be a growing need for new services and frameworks that keep them connected while on the move for the rapid growth of connected mobility [
4]. In such a scenario, efficiently processing the quality of service (QoS)-intensive CAV workload, extracting valuable information and making the correct decisions become critical issues.
Although cloud computing employs high-end servers called cloud data centers (CDCs) for processing vehicular data streams, they cause an intolerable delay and have a huge energy footprint [
5]. Moreover, the presence of unstable connections in multi-user CAV environments degrades the overall quality of experience. For instance, many ITS applications need interactivity requiring a low response time and service delay for providing instant feedback [
6]. In such scenarios, the control nodes must provide accurate signals for the steering system in milliseconds. In the case of a queuing delay or networking failure in cloud server, a vehicle may loose its intelligence, which may even lead to a crash. As a result, a fog computing (FC) model is proposed. Contrary to the cloud computing, fog deploys SCN capabilities into the intermediary in-network devices as well as in the CDCs, making a cloud-to-edge continuum. As a result, FC reduces the overall service delay for the VANET applications [
7]. Moreover, since the data are processed and stored in the edge devices, the volume of data traffic transmitted through the network is also reduced [
8].
VFC is proposed as a special case of fog computing in VANETs [
9]. It is an emerging paradigm that can potentially provide real-time and location-aware SCN services for a wide range of ITS applications [
10]. The main idea of VFC is to employ the underutilized vehicular resources as active components of fog infrastructures and at the same time, enable the practical and effective use of conventional cloud resources [
9,
11]. VFC offers a context-aware, low latency, and energy-efficient SCN framework that leverages VANET users with a wide range of ITS applications [
8]. It also enables on-road vehicles to make intelligent offloading decisions, instantly reacting and attuning to rapid changes in the ITS supply chain [
12]. An overall architecture of VFC is given in
Figure 1.
Because of its peculiar properties, the VFC has been attracting significant dedicated attention from the transportation industry and research communities in recent years [
9]. The VFC infrastructure comprises fog nodes, both static (RSUs, BSs, etc.) and dynamic (heavy vehicles, taxis and buses) deployed at appropriate locations to provide computing services to the ITS users [
12]. Although VFC architecture can provide ultra-low latency communications and a very low response time, deploying the architecture in the real world is a complex task [
13]. The naive strategy to blindly place more and more resources is not practical because the corresponding cost will be very high. Thus, we need a mathematical framework to define the assignment of available resources across various architectural layers. In operation research, this is called an FLP. To be specific, a facility location model for VFC will deal with selecting optimal locations for installing a set of fog nodes, and the available channels for transferring vehicular data, by minimizing or maximizing some objectives. The solutions should satisfy the workload requirements with respect to a set of constraints defined over a given space [
14]. The formal definition of a VFC FLP is given as [
15]:
Definition 1. Facility Location Problem (FLP): Consider a bipartite graph with a bi-partition , where F and V represent the set of fog nodes and set of client vehicles, respectively. Suppose that the set denotes the potential facility locations, denotes the deployment cost of a facility at location for with capacity , denotes the communication cost for each link between and , and denotes a demand function for each client . Then, the goal of FLP is to find a subset and an assignment vector that maps requests from each client’s to appropriate facilities , such that the total communicating and processing cost is minimized. Note that this is the simplified definition sometimes known as simple FLP. However, we can generalize the depth of partition and make it a multi-level FLP [16]. EMO algorithms are a class of algorithms inspired by a mechanism of natural evolution. They apply intelligent and approximate heuristics in order to search the optimal Pareto trade-off fronts. Compared to classical methods, preference-based algorithms include weighted sum methods [
17],
-constraint methods [
18], and hierarchical methods [
19], etc. The EMO algorithms offer a good balance between the Pareto optimality and search time efficiency. Hence, the EMO algorithms are becoming increasingly popular in the modeling and optimization of complex systems. A study reveals that a significant number of studies have used EMO algorithms to find the solution to resource management problems. These are commonly used to study the structural complexity of decentralized computing models such as cloud or fog computing [
20], vehicular fog computing [
12], etc. In fact, the survey performed by the authors of [
21] found that, in approximately 18% of related studies, EMO algorithms were used to solve optimization problems such as VM allocation, VM migration, service placement, task offloading, and capacity planning, among others.
In this work, we present a multi-objective optimization model to formulate the FLP in VFC networks. The key objective of this model was to generate an optimal VFC topology that satisfies the service requirements of low-power and low-latency ITS applications. The objective function minimizes the average response delay and system energy consumption. The solutions to this model generate optimal decisions on where to install the fog nodes, how vehicle-generated requests are routed to these nodes, and the amount of storage–computation resources to be installed in each fog node. Essentially, we examine the suitability of different EMO algorithms to solve the FLP in VFC. The model is solved through one exact algorithm-weighted sum method in CPLEX solver, and two EMO algorithms; non-dominated sorting genetic algorithm-II (NSGA-II); and speed-constrained particle swarm optimization (SMPSO) algorithm. Motivated by the nature of solutions generated by these algorithms, we proposed a hybrid EMO algorithm called Swarm Optimized Non-dominated sorting Genetic Algorithm (SONG). Basically, SONG combines the convergence efficiency of NSGA-II [
22] and search efficiency of SMPSO [
23], and it gives better results in terms of solution quality. We measure the performance of the SONG algorithm by comparing with the baseline EMO algorithms against three baseline indicators, namely; hyper-volume (HV), inverted generational distance (IGD) and delay gap. The empirical results on real-world vehicular traces show that SONG exhibits better solution quality than the counterpart algorithms, and hence can be adapted as an efficient planning tool for planning and design of VFC networks.
The key highlights of this paper are given as follows:We formulate the FLP in VFC as a multi-objective optimization model combining two sub-problems: fog node placement (FNP) and fog node dimensioning (FND). The objective of this model is to minimize the average response delay and overall energy consumption, with an effort to attain Pareto-optimality.
We solve the model using an exact weighted-sum scalarization algorithm in the IBM ILOG CPLEX solver. The results obtained in this step are used as the baseline for EMO analysis. We also solved the model using two popular EMO algorithms: the NSGA-II and SMPSO algorithms. The nature of Pareto-fronts obtained in this step is the key driver for the development of a hybrid EMO algorithm.
We proposed a hybrid EMO algorithm called the Swarm Optimized Non-dominated Sorting Genetic algorithm (SONG) that combines the convergence efficiency of NSGA-II and the solution diversity of SMPSO. We compared and evaluated the efficiency of the SONG algorithm with that of weighted sum (CPLEX), NSGA-II, and SMPSO algorithms against three quality indicators; Hyper-Volume (HV), Inverted Generational Distance (IGD), and delay gap.
Through evaluation with real-world datasets, we showed that SONG exhibits a better solution quality than the three baseline algorithms, and can hence be utilized as an efficient planning tool for the planning and design of VFC networks.
The remainder of this paper is organized as follows.
Section 2 gives a brief overview of the FLP and the motivation for conducting this research. Related works are given in
Section 3. The system description and model formulations are provided in
Section 4.
Section 5 summarizes the exact and EMO algorithms for facility location in VFC. The proposed SONG algorithm is explained in
Section 6. The evolutionary parameters of SONG algorithms are discussed in
Section 7. Experimental and simulation setups are explained in
Section 8. The results and discussions are given in
Section 9. Finally,
Section 10 concludes the paper.
2. Motivation
In distributed network environments, FLP refers to the identification of facilities for the deployment of storage and computing services [
14]. The outputs of a facility location problem are: placement decisions regarding facilities that are placed at the potential locations; the links to be selected from an available set, and the amount of client workload that is to be transmitted across different architectural layers. It is a rational process that encompasses the topology design, network synthesis, and network realization [
24]. The facility location model in VFC deals with selecting the optimal locations for installing a set of fog nodes, and the available channels for transferring vehicular data by minimizing or maximizing some objectives. The solutions should satisfy the workload requirements with respect to a set of constraints defined over a given space [
25]. The constraints can be defined on available hardware, the fog node type and orientation, the channel bandwidth, etc. To be specific, it deals with the dimensioning and layout planning of VFC architectural components and generates a topology that optimizes parameters such as the response time, energy consumption, and cost of infrastructure, etc. [
13]. Often, these parameters are conflicting, so the resulting topology must give an optimal balance (trade-off) between the network and equipment power consumption, interference and performance (e.g., in terms of throughput or latency).
However, due to the highly decentralized and mobile nature of fog nodes and context-aware computational demands of vehicular applications, the facility location in VFC is a complex task [
6]. Here, the FLP can be partitioned into three sub-problems. The first sub-problem is an FNP that deals with selecting a subset of candidate nodes to act as fog nodes. FND is another sub-problem where the capacity levels of resources such as fog nodes, links and channels are estimated. The optimizing attributes for both these sub-problems are: the cost of the fog node, the weight (bandwidth) of communication links, the vehicular workload (# req/s) and other QoS parameters. The third sub-problem is computation offloading, i.e., the process of forwarding client requests to the appropriate nodes for execution. It is noteworthy that all these sub-problems are inter-dependent and are equally significant towards facility location in VFC networks. It has been theoretically proven that finding optimal solution for each of these individual sub-problems is NP-hard [
26]. Obviously, a model that integrates all these sub-problems will also be NP-hard [
16]. For an in-depth analysis of how facility location works in VFC, please refer to [
25].
As mentioned above, generating an optimal solution to facility location in VFC is a complex task due to many factors, e.g., the decentralized nature of VANETs, vehicle mobility, network size, the number and heterogeneous nature of the VFC hardware equipment(s), cloud–fog cooperation, etc. Therefore, it is critical for VFC network designers to adopt a structured methodology while formulating, designing, and planning VFC infrastructures [
27].
Figure 2 shows a comprehensive framework for facility location in VFC networks. In the definition phase, the input data from the VANET environment are collected to conduct a requirement analysis. The information, for instance, the vehicular traffic patterns and traffic density, can be used to estimate the hardware type and cost, network capacity and QoS requirements. Obtaining real-world vehicular data is often complex and time-consuming. In that case, the inputs can be synthetically generated and then validated against a real-world ITS scenario [
28].
In the network design phase, efficient dimensioning and layout planning algorithms are employed [
29]. These involve activities such as the selection of various processing nodes, potential locations, the sizing and costing, etc. Depending on the design constraints, the output of this phase can be a routing topology guaranteeing optimal QoS requirements. Furthermore, these outputs are selectively fed as input to the optimization model. This generates optimal solutions that correspond to minimized service delay, network traffic, deployment cost and energy consumption. The final step is a performance evaluation that involves the sensitivity and statistical analysis of model outputs. From a designer’s perspective, the overall facility location framework must deliver the maximum network performance to ITS users, which can be targeted to meet the following key objectives:
Minimizing service delay: Minimizing the service delay is persuaded to be the key performance objective in almost all networked architectures because a slight increase in the user-perceived delay might lead to a substantial revenue loss for the service providers. Since VFC services mainly target decentralized IoT devices and vehicles, an effective facility location framework should rigorously consider the latency requirements of ITS applications.
Minimizing energy consumption: With a huge volume of service requests, the power consumption of powering up (and cooling down) CDC is soaring. It is thus necessary to study the energy management aspects of VFC design.
Minimizing capital expenditure (CAPEX): Budgetary and monetary factors have always been a major concern for network designers. Therefore, it is crucial to minimize the total CAPEX involved in hardware purchasing, facility rental, link installation, etc.
It is observed that each of these objectives define sub-problems that are both inter-dependent as well as mutually conflicting [
30]. For example, to minimize the service delay, a large number of fog nodes might be deployed, but this will increase the CAPEX. The energy consumption also gears-up proportionally. On the contrary, the CAPEX can be kept within budget by selecting fewer locations for fog placement. However, in that case, the client requests might not be served in the fog layer, but rather offloaded to distant cloud servers leading to a degradation in network performance and QoS. Considering all these factors, we formulate the FLP as a multi-objective optimization model where the objective function minimizes the average response time as well as system energy consumption. The optimal solutions called Pareto Fronts seek for the best compromise between the response time and energy consumption [
31]. This leverages the VFC service providers as well as the network designers to assess the abilities of possible trade-off solutions, leading to intelligent network planning and design decisions.
3. Related Work
VFC extends fog computing to mobile VANETs, where the vehicles and RSU can both act as mobile fog nodes, thereby leveraging the full utilization of storage and computation resources. Considering the mobility of VANET infrastructures, the facility location and capacity planning in VFC recently received considerable attention. For example, in some papers, the VFC is studied from the viewpoint of delay optimization [
9], energy optimization [
32], utility maximization [
33], cost minimization [
6], etc.
The authors in [
34] investigated the scenario wherein multiple vehicles formed a community and jointly shared computing resources to maximize their utility. The RSU acts as an orchestrator and takes charge of decision making for community formation and workload scheduling. According to [
10], the RSU acts as both as a gateway to the remote CDC as well as a task scheduler.
Moreover, the use of EMO algorithms is becoming an emerging trend and has been widely adopted for resource management in decentralized architectures such as cloud, edge–fog computing, VFC, etc. EMO provides intelligent heuristics to solve a wide range of optimization problems such as VM allocation [
20], data replica placement [
35], federated clouds [
36], among others. Studies that address the facility location in fog environments can be broadly categorized from numerous perspectives. We exhaustively reviewed the existing literature in fog server placement, identified the key highlights and presented the motivation for carrying out similar research, which is equally adaptive to the vehicular fog computing environments.
The first set of works minimizes network delays which are approximated through geospatial distant metrics between generation nodes and fog servers. For instance, the authors in [
37], proposed an integer linear programming (ILP)-based service placement model that minimizes the hop-count between communicating nodes, thus reducing the communication latency and eventually the service latency. The bandwidth consumption between communicating services is implemented through a flow matrix. The goal of the architecture is to place the services in convenient for servers and allow these services to dynamically migrate according to the changing conditions of the network and status of the users. In [
38], the authors proposed an semi-Markov decision process (SMDP)-based task offloading model for VFC considering the transmission delay, processing delay, available RSUs, and the variability feature of tasks and vehicle mobility into account. The model is solved using an iterative Bellman method where the objective is to maximize the long-term reward.
Souza et al. [
39] proposed a QoS-aware service placement technique for cloud–fog scenarios in smart city environment. The model that minimizes the latency experienced by the services while guaranteeing the fulfillment of the capacity constraints. In [
40], the authors employed priced timed Petri nets (PTPNs) models that allow the user to choose the available resources from a pre-allocated resource pool. The algorithm dynamically allocates the fog resources based on the predicted value of price-time weighted cost and credibility evaluation scheme. The authors in [
8] have proposed a dynamic task allocation scheme that finds an optimal trade-off between service delay and quality loss constraints in VFC. The event-triggered task allocation problem is solved using a binary PSO algorithm and simulated in real-world vehicular mobility traces for video streaming and real-time object recognition tasks [
41]. Considering the distributed capacity, the range and types of user applications and the mobility of IoT devices, Bittencourt et al. [
42] analyzed the significance of concurrent, first-come first-served (FCFS), and delay-priority scheduling policies to improve the execution time in fog environments.
The authors in [
43] employed modified NSGA-II to propose a multi-level resource scheduling model in the fog environment. To address the uneven distribution of the solution in the Pareto fronts in the standard NSGA, a modified crowding distance expression is defined that minimizes the service latency and improve the task execution stability. In [
44], the authors employed the Tabu search for the joint optimization of data blocks placement and task scheduling in edge computing, with reduced computation delay and response time. Various parameters such as data block popularity, data storage capacity and replacement costs for data blocks, as well as replacement ratios of edge servers, are considered to calculate the value of each data block. Considering the containers as the lightweight resource unit for user services, an optimal placement scheme is presented that can avoid the repeated replacement of data blocks, thereby reducing the overall bandwidth overhead. Wang et al. [
45] employed M/M/1 waiting queues to develop a latency-minimum offloading decision- and resource-allocation scheme for fog-enabled IoT networks. The optimization problem is solved using genetic simulated annealing-based algorithm to generate offloading decisions with improved convergence speed and quality.
The next thread of the literature focuses on minimizing the deployment costs of the servers while limiting maximal latency. For instance, the authors in [
46] considered the client association, resource provisioning, task distribution, and VM placement as decision variables to develop a cost-effective optimization model for fog computing. The same set of variables were investigated in [
47] to propose a cost optimal placement model fog-computing-supported medical cyber-physical system (MCPS). Urgaonkar et al. [
48] modeled the dynamic service migration and workload scheduling in fog placement as a sequential Markov decision problem. The objective was to optimize operational costs while providing rigorous QoS guarantees. The same research group in [
49] simulated the fog nodes as mobile micro-clouds and proposed a placement scheme based on an online approximation algorithm. The algorithm minimizes the average cost over time, and converges in polynomial time, leveraging the ability of predicting the future cost parameters with known accuracy. González et al. [
50] employed the considered fog locations and their capacities, the user-to-fog association, and the number of deployed fog nodes as decision variables to model the fog placement as a mixed-integer linear programming (MILP) problem. The model is further solved using a hybrid simulated annealing algorithm, evaluated on a 5G desktop application leveraged with network function virtualization (NFV). A cost efficient data-driven VFC framework was proposed in a very recent work [
6] where authors used both heuristic and integer linear programming (ILP) to solve the data-driven capacity planning problem. The objective is to minimize installation and operational expenses considering spatio-temporal variations in vehicular traffic and QoS constraints. A similar work was proposed in [
31] that finds the optimal location of fog nodes in a green field scenario.
The third category of papers studies the impact of task and service placement strategies on the energy consumption of fog infrastructures. For example, the authors in [
51] presented a placement scheme that minimizes the total energy consumption of the network, keeping the access delay within an acceptable threshold. The multi-objective optimization problem was solved using the particle swarm optimization (PSO) algorithm and the performance was evaluated on the real-world dataset of Shanghai Telecom’s base stations. In [
52], the energy-sentient scheme for deploying flow-based IoT applications is proposed and formulated as a quadratic programming problem. The complexity of this model was handled by transforming it into to an MWIS problem via a co-location graph. Here, the mapping strategy seeks to minimize the total communication energy cost by merging the services and the co-locating neighboring services on the same node. In a recent work [
53], the authors used reinforcement leaning to implement an energy-efficient vehicle scheduling scheme that ensures task offloading to stationary as well as mobile fog nodes.
Another perspective for fog placement is to optimize the trade-off between latency and energy consumption. Deng et al. [
20] investigated the trade-off between power consumption and transmission delay in the fog–cloud computing system. A framework that obtains the optimal workload allocation is solved through sub-problem approximation approach. It demonstrates that, by sacrificing modest computation resources, fog computing can give a substantially improved performance over cloud computing. Mebrek et al. [
54] studied the optimization problem of an energy-delay trade-off in fog-based IoT architectures using the Genetic Algorithm (GA) and Broadcast Incremental Power (BIP) algorithm. In [
55], a computation offloading scheme was proposed that aimed to minimize the energy consumption and the task processing delay in the fog layer while increasing the network lifetime. The notion serves to distribute high computational tasks among several fog nodes and access points, such that the network lifetime increased, especially in mission-critical scenarios that consume much more network resources. Sarker et al. [
56] employed multiple parallel deep neural networks to propose an delay-energy-optimized binary offloading scheme in fog computing. The decision outputs are then placed in a relay memory system to train and test all neural networks. A similar algorithm was proposed in [
12], wherein task offloading in VFC was modeled as a Multi-Hop Computation Offloading (MHCO) framework. The model was solved using a modified differential evolution algorithm that optimizes both service delay and average energy consumption, and facilitates the allocation of tasks for both static (RSU) and vehicular fog nodes.
Table 1 presents a summary of the literature in facility location or service placement in VFC and related architectures.
Synthesis
From an extensive study of the recent literature, we concluded that the algorithms to solve FLPs can be categorized as: exact methods and approximate or EMO methods. Most exact algorithms combine multiple objectives into one single objective. A common advantage of such methods is that, for every weight assigned to the objectives, the translated problem is as difficult as a single-objective optimization problem. This makes the exact methods simple to implement. However, due to the presence of discrete structures in the instances of FLP, it is not sufficient to aggregate multiple objectives using a weight vector. Because of NP-hardness, there will be solution called non-supported efficient (NE) solutions which are not optimal for any weighted sum of objectives.
EMO algorithms come under approximate resolution methods, commonly termed meta-heuristic algorithms. These algorithms yield a good trade-off between the solution set quality, CPU time, and memory [
22]. They can be classified based on the principle of search directions and principle of dominance, where they take advantage of the information carried by a population of solutions using the notion of dominance. On the contrary to exact algorithms where only one individual is attracted to the non-dominated frontier, in EMO, all the population contributes to the evolution process. Thus, by maintaining a solution pool, then these methods can search for multiple efficient solution points in parallel via self-adaptation and cooperation. Such characteristics make EMO algorithms suitable for solving FLP in VFC [
26]. Driven by this motivation, in what follows, we discuss the popular EMO algorithms that solve the multi-objective versions of an FLP. We also propose a new EMO algorithm named SONG, which is characteristically a hybrid version of NSGA-II and SMPSO. We performed extensive experimentation on a wide set of inputs to demonstrate the efficiency of SONG. In particular, we compared the performance of SONG with that of NSGA-II and SMPSO, and showed that SONG offers a better balance between the Pareto optimality and computation time efficiency.
4. System Description and Problem Formulation
The system model is explained in detail in this section. We first introduced the scenario and then described the procedure of offloading a task in VFC according to the 802.11p standard [
38]. The VANET scenario considered in this paper is modeled as a connected undirected graph
. The vertices in set
include a set of vehicles
, a set of fog nodes
and a cloud server
. The vehicles moving on highway lanes form a VFC system equipped with seamless connectivity to an upper fog–cloud layer via BS or RSU. The function
denotes the set of edges having weights
. Here, each weight
represents the network usage descriptor (NUD) between each pair of vertices in
V(.). In our analysis, we model
by a triple
where
denotes the transmission rate between two nodes,
denotes the link bandwidth between two nodes and
denotes the end-to-end delay. The number of passengers residing inside each vehicle
v varies randomly between 0 and
, with one PD per person. Hence, the total number of PDs in a VFC system (cluster) can be given as
.
A vehicle joining or leaving the VFC system according to a Poisson process with an arrival and departure rate
and
, respectively. The vehicles adopted the 802.11p communication standard to transfer data/request through one-hop communication [
8]. Each vehicle knows the availability fog nodes by communicating with each other through handshaking [
12]. When the PD has a task to offload, the task offloading module makes a decision to offload it onto appropriate fog nodes. On the basis of the estimation of available resources, e.g., memory, vCPU, VM, bandwidth, etc., the host vehicle will either accept the task with a probability
or offload to a nearby fog node or to remote CDC. For the sake of simplicity, it is assumed that fog nodes, i.e., taxis as well as RSU are connected through a strong backhaul network [
27].
On the basis of the assumptions discussed above, we formulated the model for average response delay
and average energy consumption
per vehicular application, for the different scenarios of facility location in VFC. The overall framework is given in
Figure 3. The key symbols and notations used for the model are summarized in
Table 2.
Decision Variables:
Definition 2. Task: A task generated from a vehicle v can be defined by a triplet , where is the size of task in bytes, denotes the number of CPU cycles needed to process the task [27] and denotes the delay constraint for the vehicular application that generates the task . Definition 3. Response delay: The response delay for a task is the time required to serve it, i.e., the time interval between the moment when a client vehicle makes a service request and when it receives the response (result) for that request.
4.1. Delay and Energy Formulation
Case I: When vehicle v accepts the PD request: Generally, a vehicle pools requests from its resident PDs, and each task is assumed to be computationally intensive and mutually independent. In case a vehicle
v accepts the request coming from PD
with an arrival rate
, the overall workload
for vehicle
v can be given as:
Modeling the vehicular edge computation as an
queue, the service time when
v processes a task from a PD
p can be expressed as:
where
denotes the processing capability of the vehicle
v, and
denotes the normalized workload on vehicle
v, i.e., the fraction of processing a resource that is currently involved in serving other tasks. If
, then the CPU is fully occupied and hence the requests are offloaded either onto fog nodes or the cloud. Every time a vehicle is on the highway, it is processing some kernel tasks, therefore,
In our VFC framework, the client requests are forwarded via dedicated short-range communication (DSRC) or cellular V2X (C-V2X [
8], hence the energy required by PD
p to transmit a task of size
over a channel bandwidth
is given by [
57]:
where
is the transmission power of PD
p. The corresponding energy required by vehicle
v to execute this task is given by [
27]:
where
denotes the energy consumption (in energy units) per unit CPU cycle of task
.
Case II: When the vehicle v offloads the PD request to the fog node: Because of a limited processing capability, the host vehicle frequently fails to execute concurrent PD requests; hence, it is forwarded to a proximate fog node. Considering a reliable communication link of bandwidth
, the time required to offload the input request of size
into fog node
f is given by:
Similarly, the processing delay due to processing at fog node
f with computing capacity
is given by:
The energy consumed while forwarding a task of size
is given by:
where
depends on the communication channel over which the task is offloaded. For 5G-enabled V2X communication, we consider
mJ/s [
58]. The energy consumed by fog node
f to process task
can be expressed as:
where
and
represents the energy consumption per CPU cycle of fog node
f, and the number of CPU cycles required to process one bit of task
, respectively.
Case III: When vehicle v offloads the PD request to CDC: The time for the cloud layer consists of two parts. First, the transmission time for dispatching and processing time at the cloud server. Assuming the vehicle-cloud channel has infinite bandwidth, the transmission time can be considered constant [
30]. Realizing the cloud servers as an
queue with a service rate
, the processing time is given by:
Assuming that each server
c hosts a homogeneous VM with an identical CPU frequency, then the energy consumption can be approximated by a nonlinear function of CPU frequency [
20], i.e.,
where
u lies between 2.5 and 3 [
20]. In order to cope with the workload surge, the CDCs are enabled with power-saving modes wherein more servers are either powered ON or switched OFF dynamically. In that case, the energy consumption is given as:
where the binary decision variable
reflects the ON/OFF state of the server
c (0-OFF, 1-ON), and
denotes the number of machines that are currently turned ON. For the sake of keeping the model simple, we assume that the cloud servers are always ON (i.e.,
).
Integrating Equations (4), (8), (9) and (12), we obtain the average response delay
as:
Similarly, from Equations (6), (7), (10), (11) and (14),
4.2. Optimization Model
The overall goal of the proposed facility location model is to minimize the average response delay
and energy consumption
of the VFC components. Hence, the optimization problem can be formulated as:
Constraint (18) says that the workload at vehicle
v must not exceed its maximum processing capacity. Constraint (19) is an integrity constraint that keeps the service rate of CDCs much higher than that of fog nodes. Constraint (20) is a QoS constraint which the response delay for any task must not exceed the delay threshold specified for that vehicular application. Equation (
21) is a vehicular assignment constraint that assumes the workload generated from each vehicle
to be atomic. At every time-slot, a task is either offloaded for fog level processing or to the cloud, but not to both. Likewise, constraint (22) says that the vehicle
v should send its workload to one and only fog node. Constraint (23) ensures that the total workload of a fog node should not exceed its processing capacity. For simplicity, we use the constraint (24) as a node uniqueness constraint that limits each location
to accommodate at most one fog node
. This is realistic because an RSU can act as a single fog node only. However, it is also possible to install additional servers at the RSU site, when it will be hosting multiple fog nodes. Moreover, it also means that a VFN will not be selected in the range exclusive for RSU. Finally, constraint (25) guarantees that each vehicle
v can only offload to a location
k iff a fog node
f is installed there.
Remark 1. As mentioned in the system description, we abstract the weight vector through an NUD. It represents the resource usage between each facility in the VFC facility location. Since NUD is transparent to the mathematical solver and algorithms, it can be modified beforehand to meet specific design and dimensioning requirements. For example, if a specific passenger does not want to upload their data to a specific node due to security concerns or policy issues, then we may label the corresponding PD-fog node link as infinite. In that case, their data will never be forwarded to this adverse fog node and hence, a security requirement will be safeguarded.
4.3. Complexity Analysis
It can be observed that the multi-optimization model P1 has two conflicting objectives. A trivial strategy is to handle each objective sequentially by translating them into independent single objective sub-problems. However, this approach does not explore the interconnections and overlaps between sub-problems, and hence the solutions may suffer from a local optimum. Thus, it is preferable to employ a global approach, i.e., solve all sub-problems simultaneously.
For complexity analysis, let us relax and make three versions of P1: SP1, SP2 and SP3, from three perspectives. SP1 aims to minimize the response time and SP2 aims to minimize the energy consumption, while SP3 is a weighted combination of both SP1 and SP2, i.e.,
Definition 4. k-median clustering problem: Consider a bipartite graph with a bi-partition where F represents a set of fog nodes and V is a set of clients. Let k be a positive integer that specifies the number of nodes that are allowed to be deployed (e.g., may be limited by budgetary constraints). Suppose that the set denotes the cost (weight) of connection(s) between vehicle to fog node . Then, the goal of the k-median clustering problem is to select k representatives of F to minimize the total connecting cost. Mathematically,
k-MEDIAN CLUSTERING
Input: Finite set F and integer k
Output: with
Objective: minimum cost
Theorem 1. SP1 is NP-hard.
Proof. To approximate the hardness of SP1, we relax certain constraints. For instance, assume that we have prior information about the number of fog nodes
f that can be deployed and are available. We also relax the capacity constraint for nodes at each location
. In that case, the decision problem SP1 of finding an assignment vector from vehicle
to fog node
that minimizes the total response delay can be reduced to a
k-median clustering problem. It is well known that the k-median clustering problem is NP-complete [
16]. Since an instance of SP1 can be reduced to a k-median clustering problem (by definition 5.1), it is therefore also NP-hard. □
Theorem 2. SP2 is NP-hard.
Proof. Upon adopting a relaxation strategy similar to that for SP1, SP2 becomes an instance of the traveling salesman problem (TSP) with pre-determined initial and final locations. Since, TSP is known to be NP-hard, SP2 is also NP-hard. □
Theorem 3. SP3 is NP-hard.
Proof. If we carefully observe the SP3 and the definition of FLP in Section I, we will find that FLP is an instance of SP3 (provided with some relaxation). Since finding an optimal solution to FLP on general graphs is NP-hard, then SP3 is also NP-hard. □
6. Swarm Optimized Non-Dominated Sorting Genetic (SONG) Algorithm
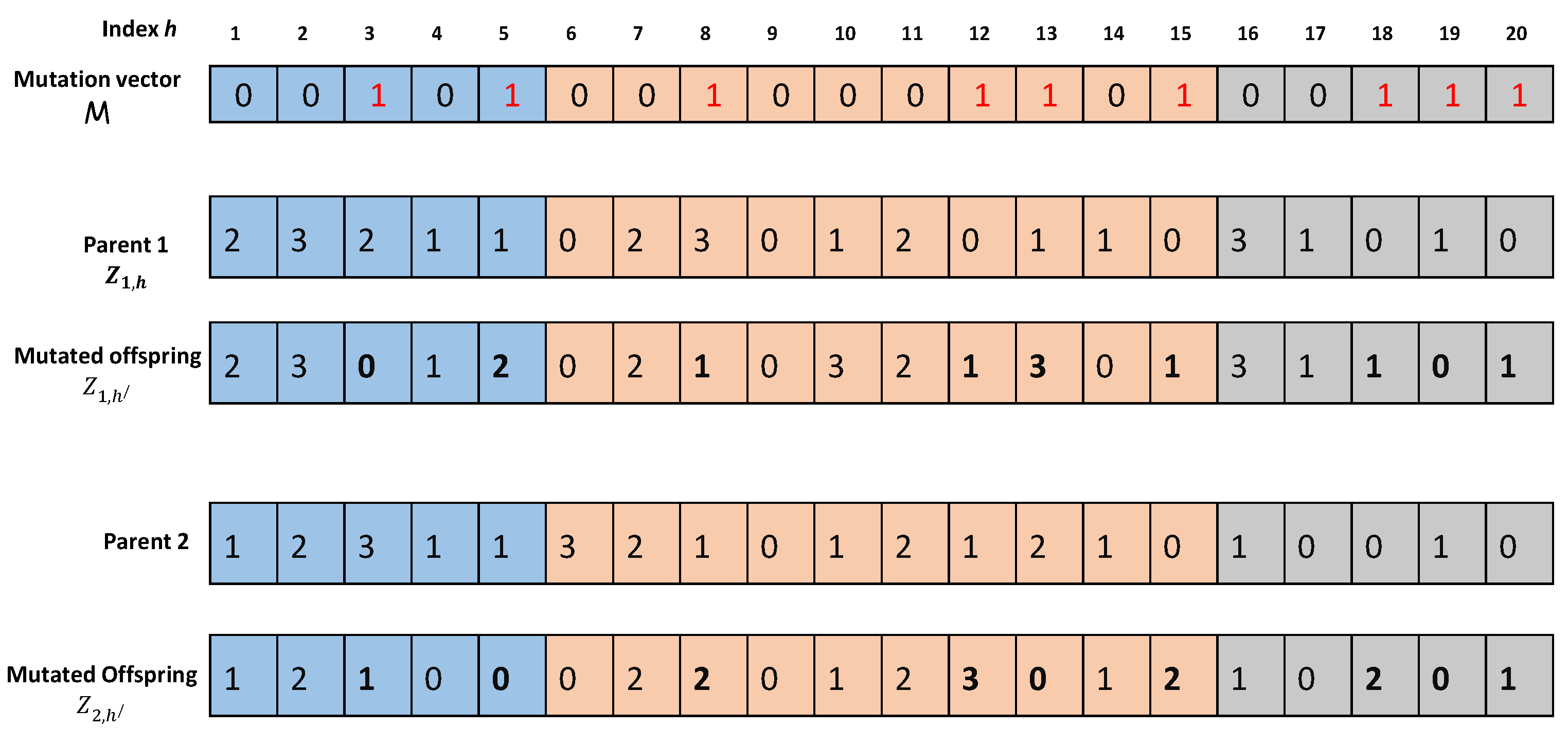
The motivation of developing the SONG algorithm is to address the drawback of NSGA-II and SMPSO algorithms, which is also to combine the advantages of both these EMO algorithms. SONG is actually a hybrid version of these two algorithms wherein SMPSO precedes the NSGA phase in order to pre-process the Pareto optimal solution set. By embedding the NSGA operators in SMPSO, the balance between exploration and exploitation is significantly improved. To summarize, the SONG algorithm combines the ability of social thinking in the swarm algorithm with the local search capability of the NSGA-II algorithm. Because SMPSO and NSGA-II both are population-based algorithms, the SONG algorithm is also a population-based algorithm and is hence guaranteed to find the global solution.
The proposed SONG algorithm is given in Algorithm 3. In the initialization phase, the particles of the swarm and corresponding velocities are randomly generated over the search space. Thereafter, the position of each particle is updated according to Equation (
27). After creating a new generation in the SMPSO phase, some particles of a new population are selected and NSGA-II is applied to each of them separately (line 18). Because the swarm size is often very large, it is not time efficient to employ NSGA over an entire population. Hence, out of the total swarm population, the number of swarm (
) that should evolve into a SMPSO renewal process is defined by:
where
and
denote the maximum number of generations in SMPSO, respectively. After selecting the individual with the highest fitness (greedy selection), SONG creates a new population by replacing the individuals with improved fitness via selection, crossover, and mutation operators. Once a new population is evaluated, the population size
and maximum number of iterations
for the NSGA-II phase are updated with respect to each SMPSO iteration according to the following equations:
| Algorithm 3 SONG Algorithm for facility location in VFC |
![Sensors 23 00667 i003]() |
Complexity Analysis
Denoting = initial population size, x = mutation probability, = number of objective functions, = Max. Iterations. For each iteration, the SMPSO algorithm includes three key operations:
Particle speed computation:
Uniform mutation operation:
Polling for elite set:
Thus, for iterations, the complexity of the SMPSO procedure is . Similarly, for each iteration, the NSGA-II algorithm includes three operations:
Non-dominated sorting:
Crowding distance assignment:
Sorting and polling:
Thus, for iterations, the complexity of the NSGA-II procedure is . Combining both phases, the overall complexity of the SONG algorithm becomes .
10. Conclusions
In this paper, we studied the FLP in VFC networks. Specifically, we provided a multi-objective formulation of the FLP to minimize the service delay and system energy consumption. To solve this problem, we developed a hybrid EMO algorithm called SONG, which combines the convergence speed of NSGA-II, and the diversity efficiency of SMPSO algorithm. We show that, although the SONG algorithm theoretically has the same complexity as NSGA-II and SMPSO, for a facility location in VFC, it gives improved results. Furthermore, to evaluate its empirical performance, we computed the values of three quality indicators, namely: HV, IGD, and delay gap, for each of these algorithms. We execute the SONG algorithm on an example problem as well as on real-world mobility datasets and observed that SONG exhibits a better solution quality than the NSGA-II and SMPSO algorithm. In particular, the SONG-based facility location framework will enable the VFC service providers as well as transportation planners to evaluate the pros and cons of each of the trade-off solutions, leading to informed network planning and design decisions. Moreover, because we consider the mobility of fog nodes through topology generation from real-world vehicular traces, the proposed framework will provide more flexibility, especially when there is uncertainty in the traffic demand.
The peculiar property of VFC to integrate the Internet of Vehicles (IoT), sensor fusion, and V2X communication is attributed to its wide application in the transportation industry. We believed that the analytical studies conducted in this work will pave better ways for researchers and ITS planners to develop VFC services for future connected and autonomous vehicle (CAV) driving beyond 5G networks. However, the current formulation is an offline model, i.e., it assumes all the workloads are known in advance. Although such a model can be extremely useful for benchmarking, it cannot be used in a real-time environment because some of the information, e.g., the start time, end time, task duration, etc., are not available at the time to make the decision. One possible approach to address such an issue is to develop online heuristics that dynamically assign tasks to fog nodes whenever they arrive, and simultaneously manage the status of all fog nodes. We keep this as a scope of our future study.

 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}