1. Introduction
Color selectivity refers to the ability of a system to respond selectively to specific colors or wavelengths of light inside its receptive field, that is, to locate patterns based on chromatic characteristics alone or color mixed with other visual features such as texture or shape. Taylor et al. [
1] showed that CNNs presented near-orthogonal color and form processing in early layers, but increasingly intermixed feature coding in higher layers. Previously, several authors [
2,
3,
4] have shown that CNN color selectivity is low in models trained with large datasets of natural scenes such as Imagenet, which are biased towards grayish, orangish, and bluish colors. It seems clear that increasing color selectivity is necessary to take full advantage of the information in the color channels, especially in scenarios where color is a primary characteristic.
The reason for this low color selectivity may be in the architecture itself. CNNs were inspired by early findings from the study of biological vision [
5]. Since Fukushima with the Neocognitron [
6], who built a basic block based on V1, or Lecun et al. with the Lenet architecture [
7], who continued the idea of aggregating simpler features into more complex ones with a sequential architecture of repetitive building blocks, CNNs have basically maintained the same architecture. This representational hierarchy appears to gradually transform a space-based visual into a shape-based and semantic representation [
8].
However, in the last thirty years, neuroscience has evolved in the understanding of the visual area and its active role in perception, as we can see in Hubel’s later work [
9] or that of Davila Teller [
10], where they advanced the study of the relationship between vision and the vision system using physiological and perceptual techniques. Although the process is mainly sequential and follows the scheme “
”, there are connections between these areas that do not follow this sequentiality. Some models have been proposed that partially skip this sequential structure [
11,
12,
13,
14] but none have been proposed to improve color selectivity.
In 1994, Ferrera et al. [
15] verified that the information structure of the LGN was maintained in the macaque visual area V4, which indicates that this area, specialized in the detection of shapes and colors [
16,
17], processes information coming from areas V1, V2, and V3, where color is intermixed for the detection of edges, shapes, and textures, and, in addition, from the LGN, where color and other features are present but at a lower level of processing. The author hypothesized that this structure of unprocessed information from the LGN is maintained in areas V1, V2, and V3 in mammals. Recently, these direct connections between the precortical area and neocortex visual areas have been analyzed in humans, indicating that there is a direct and bidirectional connection between the LGN and V4 [
18].
In this study, inspired by the direct connection , we propose the following hypothesis: it is possible to increase the color selectivity of a feed-forward architecture and improve its performance in classification tasks by modifying the structure of the network to reflect this direct connection. We do this by creating a long skip connection (LSC) between the output of the initial block, equivalent to the LGN, and the input of the last block of the feature extraction stage of the network so that this last block, similar to area V4, processes both branches together.
To evaluate this proposal, we selected several classic CNN architectures, VGG16, Densenet121, and Resnet50, which have sufficient blocks for the proposed connection to be functional and present different types of skip connections. Specifically, VGG16 does not have skip connections, Densenet121 uses skip connections via concatenation and Resnet50 uses skip connections via addition, which allows us to analyze the LSC extensively.
Our goal is to enhance the accuracy of current CNN models by using a long skip connection that boosts their ability to recognize colors. Our study improves existing methods for measuring color distinction in a more precise way and examines how it affects accuracy through filter removal. We also introduce a novel technique to assess color-related filters, simplifying the analysis process by organizing them based on color and selectivity. This reduces the number of filters needing examination.
Accordingly, the remainder of the paper is organized as follows.
Section 2 presents preliminary background information related to studying color selectivity in CNNs and different skip connection typologies.
Section 3 describes the implementation of LSC on several classic CNN architectures, and a simplified procedure to analyze quantitatively and qualitatively color selectivity.
Section 4 describes the experiments conducted to demonstrate color selectivity improvements of models with LSC.
Section 5 shows experimental results and discusses the results along with observations. Finally,
Section 6 concludes the paper.
3. Methods
In this section, we describe the implementation of LSC on the VGG16, Densenet121 and Resnet50 architectures and introduce two new procedures for analyzing color selectivity to show the improvements it introduces. To simplify the notation, we will refer to a generic architecture with M (Model) accompanied by the subscripts O when referring to the original architecture () and with when referring to the architecture with LSC (). In addition, we will use to refer to VGG16, for Densenet121 and for Resnet50. Therefore, for example, to refer specifically to the VGG16 architecture modified with LSC, we will use the notation .
3.1. The Proposed LSC Architecture
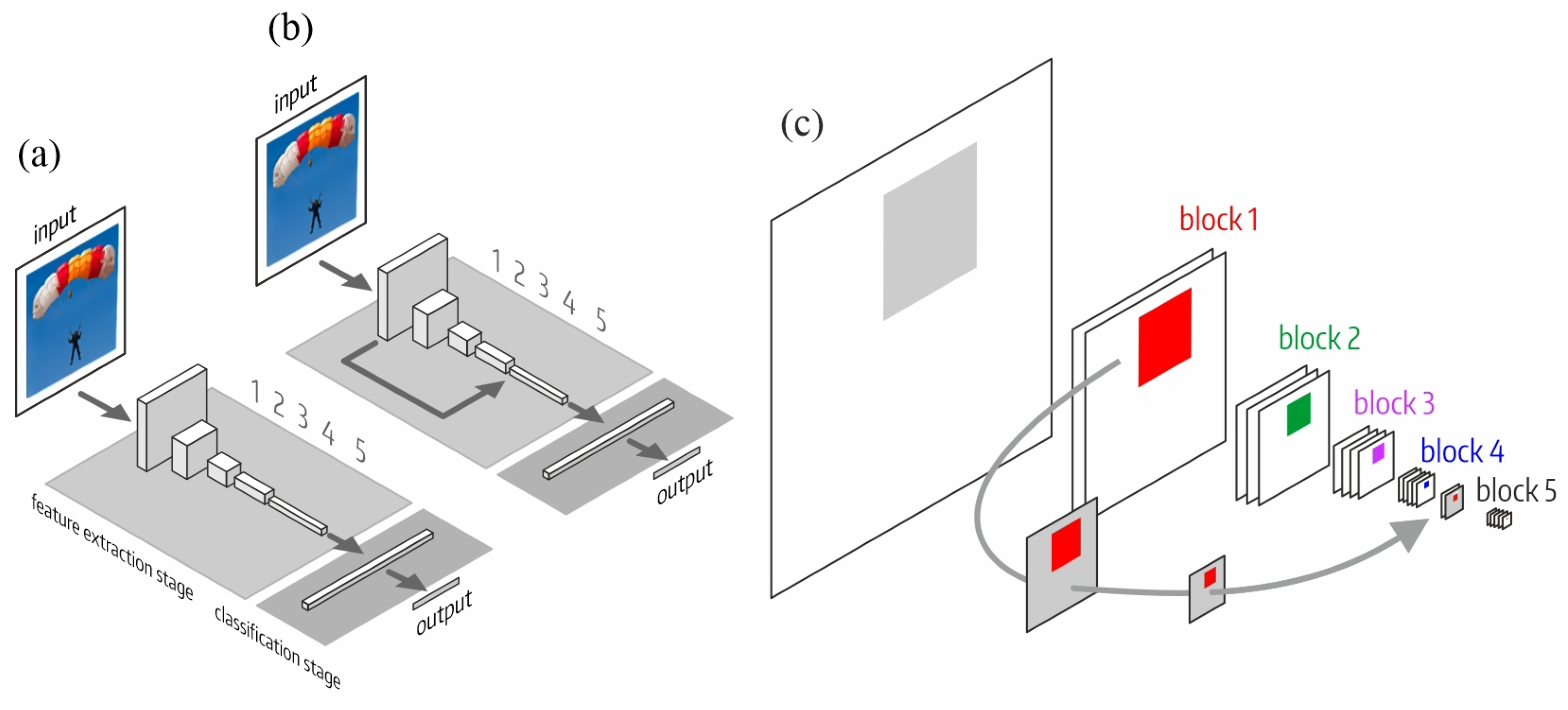
As mentioned in the introduction, we propose establishing an LSC between the output of the first block and the input of the last block of the feature extraction stage of the network. Our proposal was tested on three classic CNN architectures with and without skip connections: , and . All of these architectures use a similar down-sampling strategy along the network. However, there were differences between‘them.
We numbered the blocks of the feature extraction stage according to the pooling operations: 112 × 112 (first block), 56 × 56 (second block), 28 × 28 (third block), 14 × 14 (fourth block) and 7 × 7 (fifth block). The classification stage consists of one or more dense layers.
Figure 2 shows the structure of both architectures: the original,
, and the one with LSC,
.
Figure 2c shows the receptive field of a neuron in the fifth block of
. In the fifth block, the receptive field is composed (by adding or concatenation depending on the specific model where the LSC is implemented) of the fourth block output (forward path) and the LSC that originates from the first block. The LSC reduces the dimensions of the first block output by max-pooling, allowing the composition.
Table 1,
Table 2 and
Table 3 list the details of the implementation of the three architectures. The images are in RGB, and the input layer of all models consists of three channels. In
, the architecture is based on similar blocks (convolution layers plus an output max-pooling layer). In
and
, there is a convolution layer at the input and then five and four functional blocks respectively. While
and
maintain the same dimensionality reduction pattern in the last block (the last block input is 14 × 14 and its output is 7 × 7), in
, the last block input is 7 × 7 and its output is also 7 × 7. We now examine each model in detail.
The
architecture consists of five blocks in the feature extraction stage, and two fully connected layers and one softmax layer in the classification stage (
Table 1). Each block has several convolution layers and a max-pooling layer that halves the size of the feature maps. The number of filters increases from 64 in the first block to 512 in the last block. The LSC in
is established between the output of the first block (112 × 112) and the fourth (14 × 14) using three 2 × 2 max-pooling operations. Therefore, the fifth block receives the concatenated output of the fourth block and the down-sampled output of the first block. The classification stage has two dense layers of 4016 units and a soft-max layer that depends on the number of classes in each dataset.
The
architecture is composed of “dense blocks” followed by a “transition layer”, which halves the size of the feature maps (see
Table 2). Each dense block has three convolution layers: 1 × 1, 3 × 3, and 1 × 1. The number of filters in each layer varies as the network advances in depth from 64 to 2048, as well as the number of repetitions, which are concatenated. The transition layer is composed of a 1 × 1 convolution layer and a 2 × 2 and stride = 2 average pooling layer. The first block comprises the first convolution layer and the max-pooling layer, which reduces the dimension to 56 × 56. In the fifth block, unlike in
, where the dimension is reduced from 14 × 14 to 7 × 7, the fifth block has an input of 7 × 7 and no reduction. Therefore, the LSC from the first block reduces the dimension to 7 × 7. The classification stage has a soft-max layer that depends on the number of classes in each dataset.
The architecture is composed of “resnet blocks” containing three convolution layers: 1 × 1, 3 × 3, and 1 × 1, with a max-pooling of 2 × 2 and stride = 2 at the end to reduce the dimension. The output block has a 7 × 7 average-pooling and a soft-max layer that depends on the number of classes in each dataset. The LSC is established between the output of the first block and the output of the fourth block, performing an adding operation to maintain the type of skip connections used in this architecture. Owing to this addition operation, we increase the number of filters of the output of the first block from 64 to 1024 using a 1 × 1 convolution layer.
3.2. Evaluation of Color Selectivity
To demonstrate that the improvements introduced by the LSC are related to color processing, we performed two types of analysis: a quantitative analysis of the filter distribution according to color selectivity and a qualitative analysis of the filter’s response to color hue.
As mentioned above, we focused our analysis on the fifth block, as this is where the information coming from the different layers and from the LSC connection is combined to create the final features to be used in the classification stage.
3.2.1. Color Selectivity Properties of Filters
To analyze color selectivity, we will use the method of Rafegas and Vanrell described in
Section 2.1.1 to obtain the color selectivity index (CSI) and the neuronal feature image (NF) of each neuron. However, these values are oriented towards a neuron-level analysis. As it is impractical to analyze the response of all neurons individually, we simplified the analysis by selecting a representative neuron of each layer, reducing the number of elements to manage.
We evaluated the CSI values in the neurons of each feature map of the fifth block output and found that their variance followed a decreasing exponential distribution (; a = 109.76; b = −73.60), which is very narrow and indicates that any neuron in the feature map can be representative of the filter behavior. Therefore, for each feature map, we selected an active and centered neuron to obtain the CSI and NF values of the filters. The CSI difference of this representative neuron with respect to the average of the feature map is , which we consider insignificant for this study.
3.2.2. Qualitative Color Selectivity Analysis
A feature map shows the filter response to an input image. In order to analyze differences between and responses, we can compare all the feature maps of each block output. However, it is very complicated and cumbersome when the block has many feature maps because it is necessary to visualize all these monochrome images together (512, 768, and 2048 feature maps in VGG, Densenet, and Resnet, respectively).
To facilitate the analysis of color selectivity for a particular image, we propose the following color representation of the feature maps in the HSV space: H (hue) is the average hue of the of the filter that generates the feature map, S (saturation) is the value of the filter, and V (value) is the normalized activation value for image j. With this representation, we can reorganize the feature maps according to the CSI intervals and select the most active filters for each one. This reduces the number of images displayed, which remarkably simplifies the analysis and, as will be seen later, does not influence the results.
In
Figure 3, we show an example of how the new representation facilitates the analysis of the feature maps at the fifth block output in
(we just show a sample of 100 out of 512 feature maps for the sake of clarity). Given the input image shown in
Figure 3a,
Figure 3b shows the feature maps ordered according to their positions in the architecture, which is difficult to follow.
Figure 3c is an intermediate representation in the HSV space that groups feature maps in 12 hue ranges. The light gray boxes represent hue ranges without feature maps. In this representation, the maps are sorted by their hue range and intensity (average activation), facilitating the visualization of the visuospatial features of the original image they capture, such as contours, shapes, textures, and specific areas. Finally, to further simplify the analysis, the highest intensity feature maps for each hue range and CSI interval are selected (
Figure 3d).
5. Experimental Results
5.1. Global Performance Analysis
Table 6 lists the accuracy of each model for the validation datasets. Analyzing accuracy, we draw attention to the following results:
All variants improved accuracy compared to .
The accuracy achieved in each dataset varied significantly: [64–75]% in Imagenette, [20–29]% in Tiny Imagenet, [47–77]% in Birds and [25–57]% in Flowers.
Among the architectures, achieved the highest accuracy in almost all datasets, with few differences with respect to . performed worse, especially in Birds and Flowers.
achieved accuracy values similar to the original and .
Regarding the differences in accuracy between and , we highlight that:
The highest differences were produced in Birds and Flowers, independently of the architecture.
had the highest relative difference in all datasets (42% trained on Flowers stands out).
had the lowest relative difference (3%) on Tiny Imagenet.
In brief, LSC improved the accuracy of the architecture regardless of whether the original architecture already had skip connections.
The computation time during the training of LSC variants was higher, although it varies depending on the model and the number of classes in the dataset (see
Table 7). For VGG16, the LSC increment is 2.49% for Imagenette, 1.29% for Tiny Imagenet, 2.70% for Birds, and 3.44% for Flowers. Regarding Densenet, the increments are 1.21% in Imagenette, 3.18% in Tiny Imagenet, 2.92% in Birds, and 4.55% in Flowers. In the case of Resnet50, the increments are 3.11% in Imagenette, 1.23% in Tiny Imagenet, 4.07% in Birds, and 4.86% in Flowers. It is worth noting that these time variations are contingent on the model and dataset; however, in no scenario does the time increase surpass 5%.
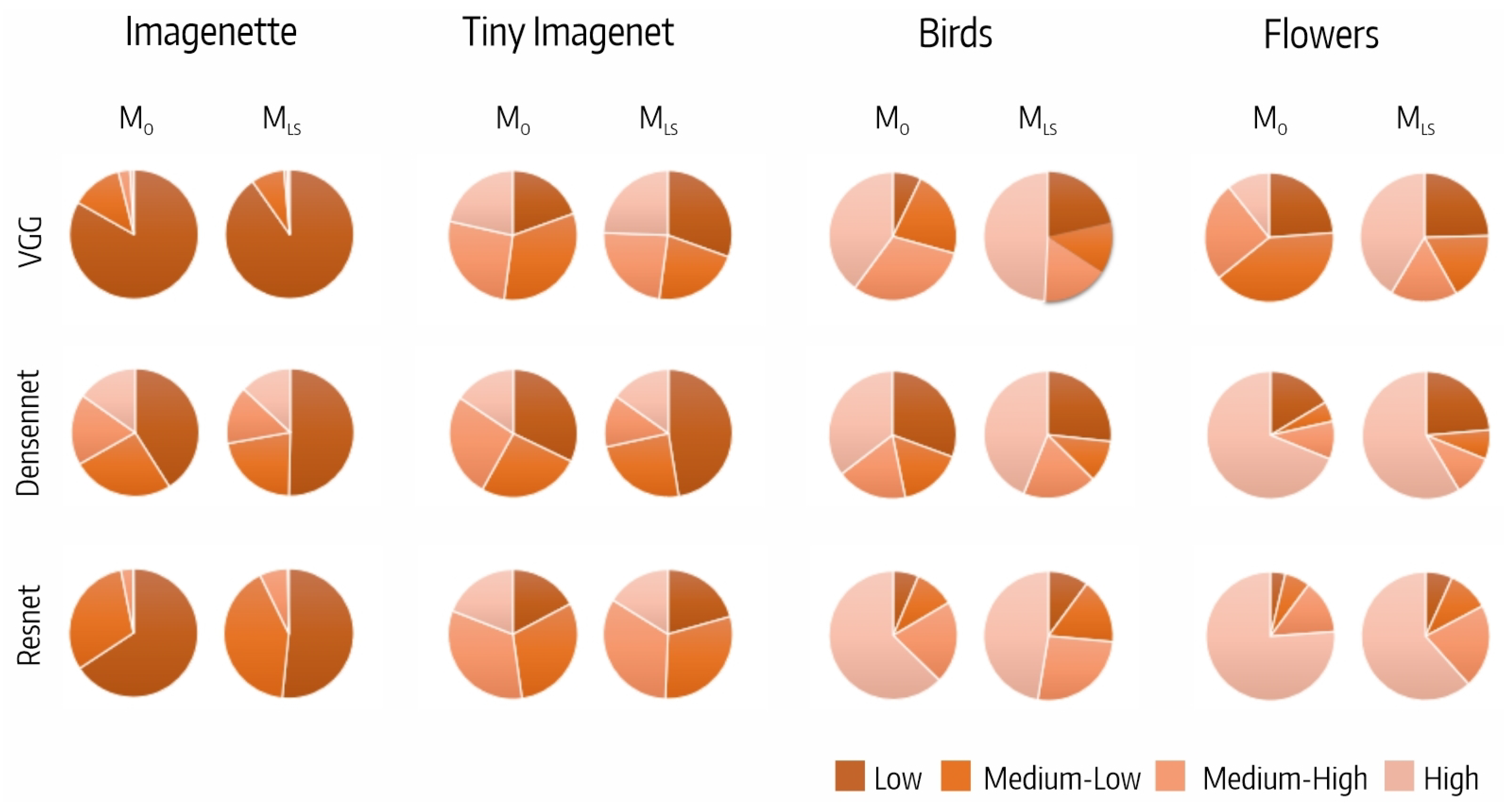
5.2. Filter CSI Analysis
Figure 5 shows the distribution of the fifth block output filters per CSI interval. We highlight that the distribution of filters per CSI interval varied with the dataset and was quite similar for all the architectures.
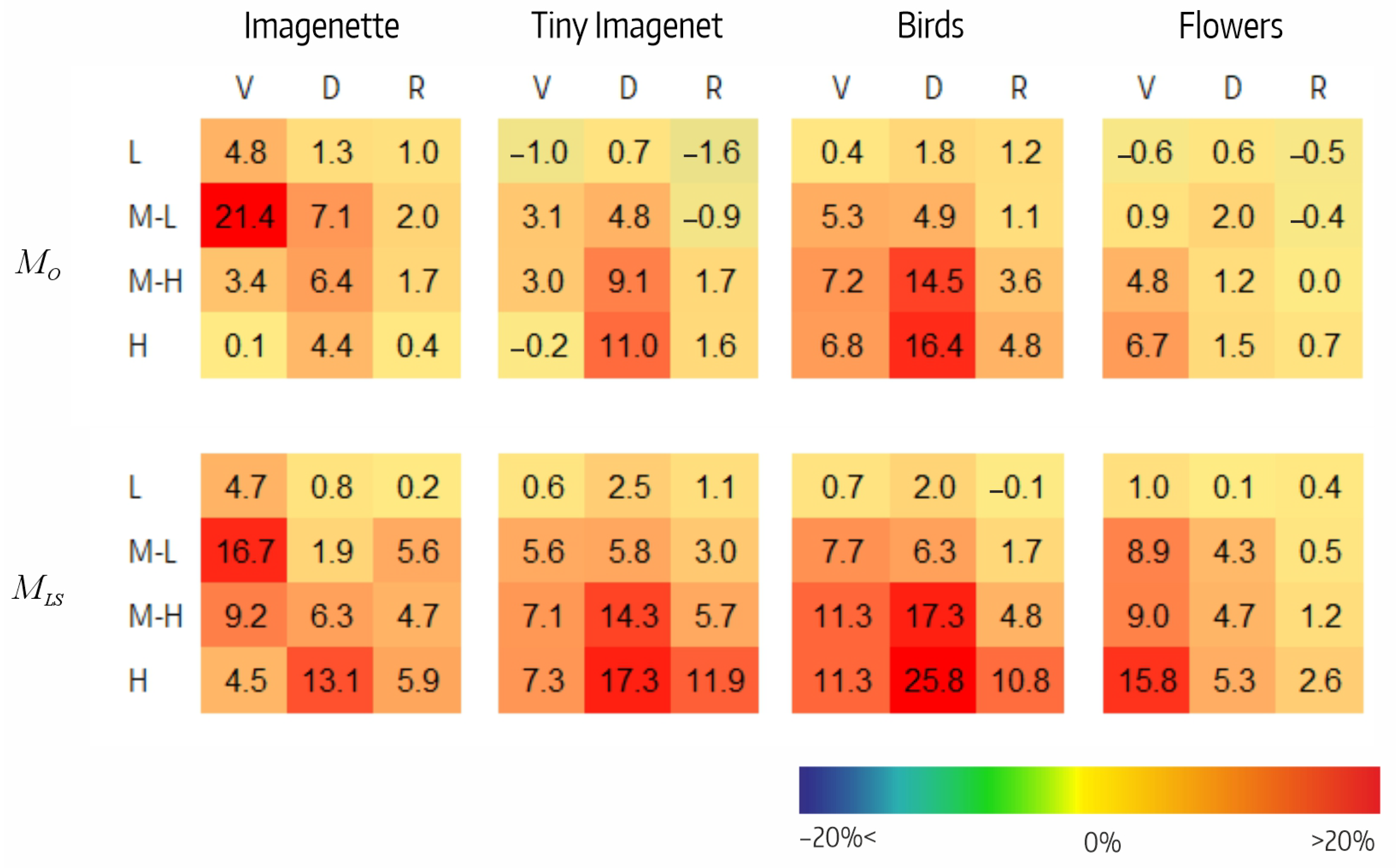
Figure 6 shows the reduction in accuracy resulting from filter ablation in each of the four CSI intervals. Analyzing, we highlight the following:
In , the decrease in performance tended to be greater at high CSI intervals. In and , it varied between −1% and 21%, whereas in , it did not exceeded 2%. Of note were the M-L interval in for Imagenette (21%) and the M-H and H intervals in for Tiny Imagenet (14% and 16%, respectively). There were three small negative values.
In , the performance decrease also tended to be greater at higher CSI intervals. The decrease varied between 1% and 17% in , between 0% and 26% in , and between 0% and 12% in . Negative values were not observed.
The difference between the effects on the accuracy of filter ablation per CSI interval,
, is shown in
Figure 7. The H intervals in
for Flowers (9%), in
for Imagenette and Birds (9%), and in
for Tiny Imagenet (10%) stand out. Also noteworthy are the negative values in the M-L intervals of
and
for Imagenette (−5%). The positive trend of
as CSI increases is clearly shown in
Figure 8, but the correlation analysis between the accuracy variation and the number of filters per CSI shows that the correlation is low in all cases (
Table 8).
In summary, the models increased the filters in the L (or even M-L) interval; however, the highest contribution to accuracy occurred in the H interval, supporting our hypothesis that LSC increases color selectivity.
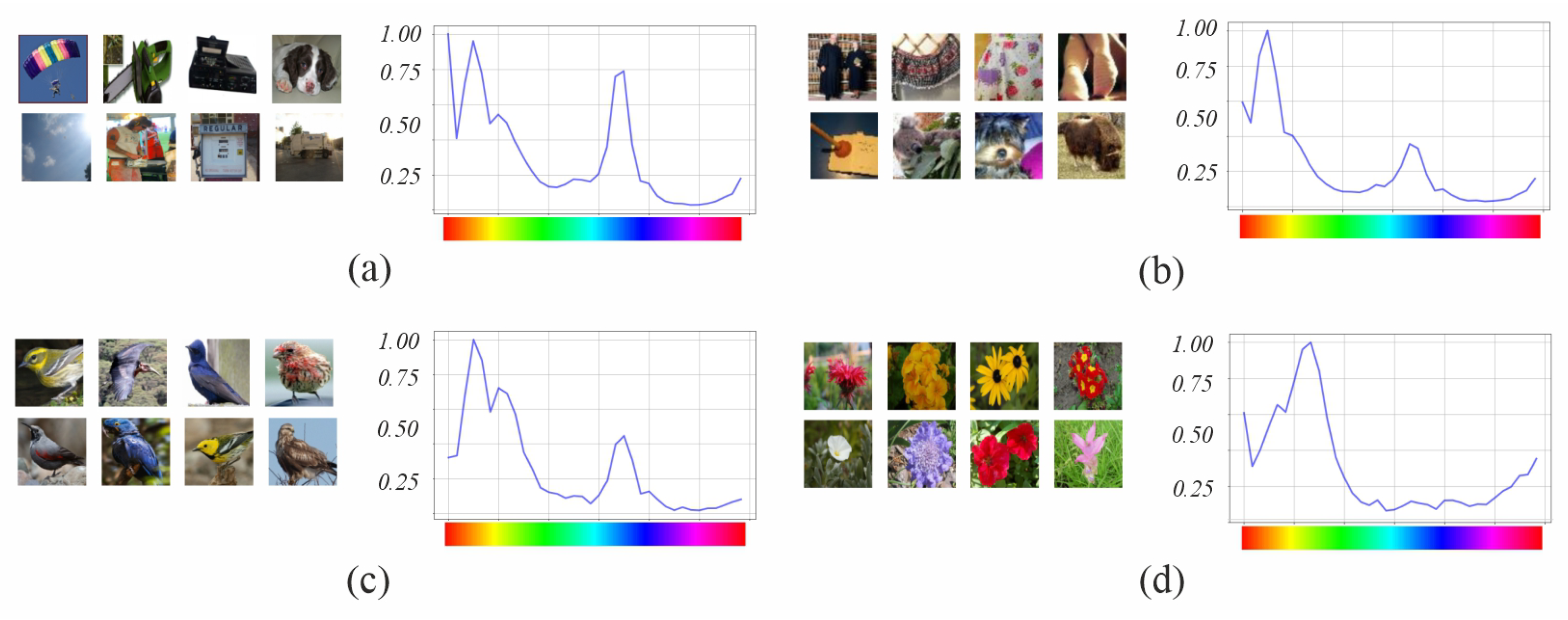
5.3. Color Hue Analysis
Table 9 shows the Pearson correlation, for each dataset, between the hue distribution of pixels in the dataset and the number of filters in the model trained with the same dataset. It is above 0.60 in three out of four datasets (Imagenette, Tiny Imagenette and Birds); however, it is low in Flowers (between 0.17 and 0.32). In this case, the yellow-green range is the most prevalent in the distribution of pixels in the dataset, whereas the orange-yellow range contains more filters. This difference can be explained by the fact that the former is more prevalent in the background and the latter in the figure.
Figure 9,
Figure 10 and
Figure 11 show the most activated feature maps for each CSI interval for the silhouette and texture datasets. We highlight the following results:
There were no significant differences between the maps of the silhouette and texture datasets.
The models had maps with more defined silhouettes in the H interval.
The difference between models was minimal in the L, M-L, and M-H intervals, except for and , which had maps with active areas in all hue ranges.
In the H interval, all variants had feature maps in more hue ranges than their counterparts, especially in the red-magenta-blue range; in particular, achieved higher activation.
In addition, in the H interval, had maps in all hue ranges of the dataset, whereas only had less active maps in the red and orange ranges. and had maps in the most frequent ranges of the Birds dataset but with incomplete silhouettes except on the orange hue, where obtained a complete figure. has maps in all dataset hue ranges, like , and , except for the magenta to red range.
In summary, the models with LSC improved the response of the filters to the hue ranges present in the dataset for both silhouettes and textures. The difference was higher in the architecture without skip connections. On the other hand, the ability of models to detect less present hue ranges varies. is the model with the strongest ability to detect both strongly and weakly present nuances. and also detected them, but at a lower activation level.
5.4. Qualitative Analysis of Filter Response
Figure 12 shows the color representation of the feature maps of the fifth block output for four randomly selected images, one from each dataset. In the visual analysis, we highlight the following points:
The image from Imagenette (
Figure 12a) has a strong contrast yellow-cyan between the figure and the background. The hue histogram shows that the cyan range is the most present in the image. Both variants of
get maps detecting the figure in yellow and the background in cyan; however,
has maps of the orange areas in addition to the yellow parachute areas.
only has maps with very specific edges of the parachute or the silhouette in the low CSI intervals, whereas
detects the silhouette of the figure in the M-H interval of the red range, although the activation area is larger than the corresponding figure in the image.
detects the background but not the figure, and
detects both the figure and the background.
The image from Tiny Imagenet (
Figure 12b) shows less contrast between the background and the figure. The hue histogram shows that the yellow-green range is the most present.
detects textures of the background in orange and yellow hues, while
detects textures of both the figure and background areas in green ranges as well.
and
only have maps with very small areas of the figure in the predominant hues in the image: red, orange, yellow, or green; less in
than in
.
does not detect areas of the figure and
does, even the silhouette in the orange or yellow ranges.
The image from Birds (
Figure 12c) shows a hue histogram where the yellow and cyan ranges are the highest, and green has a lower presence, representing areas in the background.
and
detect the silhouettes of the figure in their yellow hues. In addition,
detects the texture.
only detects reduced areas of the figure, whereas
gets larger zones, particularly in the figure.
has maps detecting background textures and
also detects the silhouette and background areas but with less definition than
.
Finally, the image from Flowers (
Figure 12d) shows a hue histogram with the yellow-green range as the most relevant, followed by orange.
detects the full silhouettes in the orange-yellow ranges and
either the edges or only one of the flowers.
,
, and
detect reduced areas of the figure in the orange-yellow ranges.
, like
, detects the full silhouettes but with less detail.
In cases with a higher contrast between the figure and background, such as in the Imagenette parachute (cyan range in the background and orange range in the figure), the improvements from LSC are smaller. However, in cases with less contrast (such as the Tiny Imagenet case or the Flowers case), LSC detects more features in the figure. This effect is higher for VGG and ResNet than for Densenet. This shows that LSC improves color selectivity in complex patterns, where contrast is more difficult to achieve, and facilitates feature extraction.
6. Conclusions and Future Work
In this paper, we focused on enhancing the color selectivity of CNN architectures. Bio-inspired by the direct connection between the LGN and area V4, we presented an LSC architecture that connects the first and last blocks of the feature extraction stage, which allows the incorporation of low-level features, detected near the RGB input, to the definition of the more abstract features used in the classification stage.
It has been demonstrated that our proposal improves the performance of the original CNN architectures by enhancing color selectivity, regardless of whether they have skip connections. On the one hand, this improvement correlates with CSI (the higher the CSI interval, the higher the improvement). On the other, the size of the improvement is more prominent in datasets where color is a more significant feature but the particular CSI redistribution of filters depends exclusively on the characteristics of the training dataset.
However, not all improvements were due to color processing. Ablation studies show that, although high CSI filters produce the most significant improvements, there are often improvements due to low CSI filters. Therefore, although we focused on the analysis of color selectivity in this study, the LSC connection probably also improves the treatment of low saturated colors and achromatic textures. This point should be studied experimentally using more controlled datasets.
Hue analysis was facilitated by the proposed qualitative methodology, which allows us to group and sort the feature maps. Although the hue distribution of filters correlates with that of pixels in the dataset, the LSC connection enables the setting of selective filters for color hues that are poorly represented in the dataset.
To conclude, in this study, we analyzed how the filters of the last block of the feature extraction stage improved their color selectivity when using LSC. In future studies, it would be interesting to establish the relationship between color selectivity in the feature extraction and classification stages, especially by analyzing the role of color selectivity in per-class accuracy. On the other hand, the study of the ablation of filters by CSI and hue could be used to improve performance and reduce computational costs.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}