1. Introduction
RSSOR is popularly adapted to specific tasks such as geological exploration, precision agriculture, and urban planning [
1,
2,
3]. As the name implies, RSSOR infers the right category of scene objectives by evaluating the content features that are included in the remote sensing data. With the continuous advancement of urban construction and the rapid progress of high-resolution observation satellites, the characteristics of diverse feature objectives and the scale of data are increasing, and how to perform RSSOR more accurately is already a popular and difficult problem for ongoing research in the field of remote sensing technology development [
4,
5,
6].
With the accumulation of data volume and the improvement of computer performance, artificial neural networks and deep learning networks are developing rapidly, and the use of CNN for RSSOR has come into being [
7]. CNN, as one of the emerging artificial neural network technologies, merges intelligent deep learning techniques, and has the advantages of “sparse connection”, “parameter sharing”, and “equivariant representation” [
8]. It can shorten the time required for model learning, lower the volumes of data requiring training parameters, and reduce the memory requirement for model operation. In addition, the feature maps obtained by using CNN generally have three layers: the bottom layer reflects the details of the color, texture, and shape of the objective; the middle layer reflects the state of an object in the image at a certain moment; and the top layer reflects the overall concept of the image with rich semantic information. In particular, it should be said that the top-layer feature maps are also the most applied in RSSORs. However, when CNN is employed for RSSOR, ignoring the other layers and just adopting the last layer not only fails to improve the recognition performance but also cannot fully exploit the advantages of CNN [
9].
Another popular method based on CNN is to integrate the hessian eigenmaps learned from different CNN layers to generate new discriminative feature maps for RSSOR, which can achieve complementary feature advantages and even improve the recognition effect of the network. Two structures are common for multilayer feature fusion networks: the first is a parallel multi-branch network (PMBN), and the other is a serial hop-layer connection network (SHLCN). PMBNs are usually used to fuse features using different convolutional kernels, convolution with holes, and pooling operations of different sizes. In [
10], the features are first extracted and then fused using four parallel structures, each containing convolutional kernels of different sizes. In [
11], highly accurate features were obtained using convolutional networks with holes. In [
12], the recognition accuracy of small samples is improved by assembling feature maps of different scales under different weights. The above methods achieve their purpose, but they ignore the relationship between adjacent layers. SHLCN is a combination of features implemented through hop-level connections. In [
13], the fusion of features obtained by using layer-hopping connections for recognition is superior to traditional methods. In [
14], the covariance matrix is obtained by superimposed multilayer features, and then the covariance matrix and support vector machine are used to further obtain better classification results. In [
15], sparse representation is used to fuse the middle layer and top layer features, and then the fused features are used for scene classification, which is effective for classification in limited data. The above method utilizes multilayer feature fusion, but there are problems of feature redundancy and offset in the integration process, which also ignores the relationship between adjacent layers. In summary, it is easy to understand that the parallel structure is able to acquire different perceptual field features at the same level, while serial structures are able to integrate features from various levels. All these methods are able to enhance the features, but they also bring the problems of redundancy and mutual exclusion of feature maps.
In addition, because of the complex and diverse characteristics of the features themselves, the satellite will be affected by the background, lighting, scale, and other imaging conditions in the process of photography. Therefore, two types of feature confusion problems arose in RSSOR: scene objectives with similar semantic categories probably share different visual variability, and scene images of different semantic categories may also have certain similarities [
16]. To reduce the impact of these two problems, many researchers have tried to use an attentional mechanism (AM) [
17]. In [
18], a dual-attention residual network is designed to extract features, embedding spatial attention into the bottom features and channeling attention into the top features. In [
19], adding AM to top-level features, selectively focusing on key content, and discarding non-key information improves classification performance. The above methods only add attention features after convolutional processing, so that attention features can only be learned from the current feature layer, ignoring the attention relationship with other convolutional layers.
To fully exploit the powerful learning capability provided by CNNs while reducing the impact of feature confusion for remote sensing scene objective recognition, inspired by the literature [
20] and AM, we plan to explore the complementary relationships and enhanced relationship messages existing between feature maps of adjacent convolutional layers, focusing on key messages and discarding non-key messages in the process of feature maps computation.
In general, this study has three main contributions.
- (1)
A complementary relational feature computation module is designed;
- (2)
An enhanced relational feature calculation module is designed;
- (3)
A contextual, relational attention-based recognition network is proposed to effectively enhance the performance of RSSOR using CNN.
Other important contents are organized as follows:
Section 2 describes related work;
Section 3 introduces CRABR-Net;
Section 4 reports the experimental results;
Section 5 carries out the discussion;
Section 6, the paper is summarized.
3. Methodology
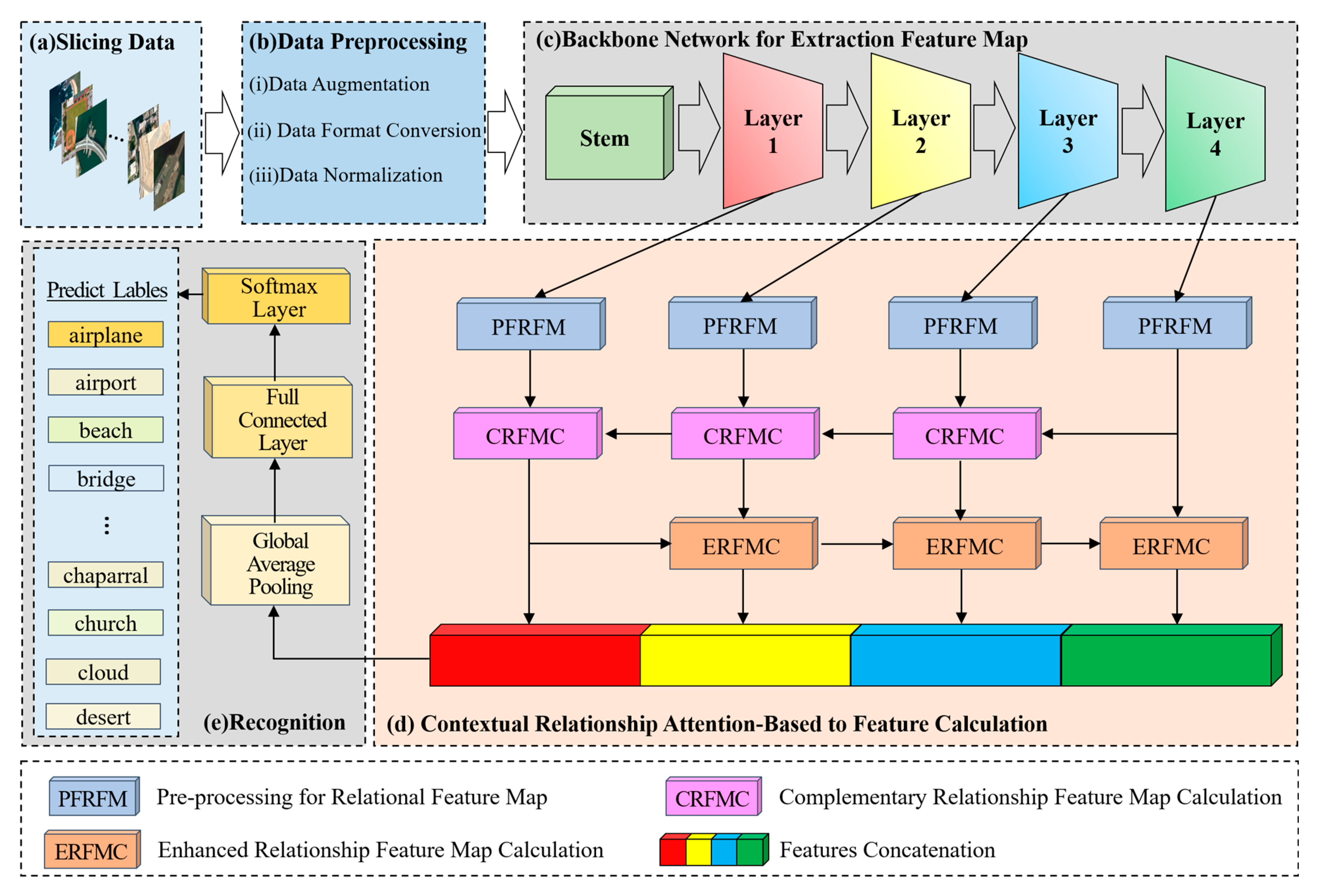
The architecture of the CRABR-Net proposed is shown in
Figure 1. It contains 5 main steps.
- (a)
The first step is to divide the data. Divide the remote sensing image dataset into the training dataset and verify the dataset according to a certain ratio (e.g., 4:1);
- (b)
The second step is data preprocessing. Firstly, augment the remote sensing image data to be input, including randomly cropping to 256 × 256, randomly rotating between −45 degrees and 45 degrees, flipping horizontally with 0.5 probability, and then cropping to 224 × 224; then converting the format, converting the data format to (Batch, Channel, Height, Width); and finally normalizing the data, setting the mean value of Height and Width of every Channel’s Height and Width mean value is set to 0 and standard deviation is set to 1, respectively;
- (c)
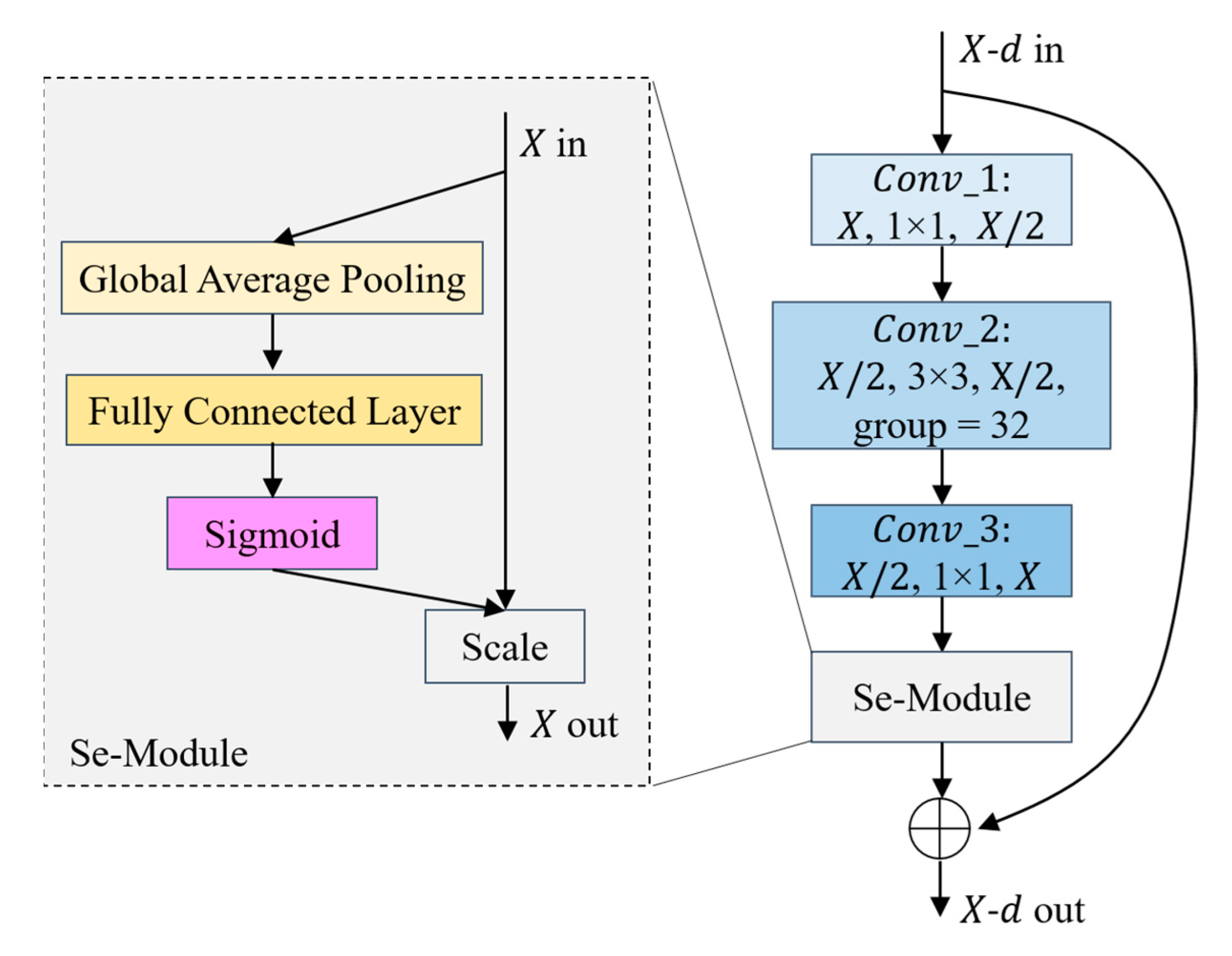
The third step is to extract features with the backbone network, a Bottleneck is shown in
Figure 2. The parameters that have been trained on the Image-Net dataset [
47] are imported into the Se-ResNext-50 network, the fully connected layers of the original network are replaced with the network structure designed in steps d and e, and then go on to extract
,
,
,
of the four different convolutional layers;
- (d)
The fourth step is to compute the relationship enhancement features.
(1) PFRFM. Obtain the refined features
,
,
,
by using SimAM.
(2) CRFMC. Sum the elements at the corresponding positions of
and
to obtain
. Before summing, up-sample
by a factor of 2 to obtain
. Similarly, we obtain
and
. For
,
,
, the processing flow shown in
Figure 3 can be utilized by using
,
,
respectively.
(3) ERFMC. For
,
is transformed into
= [B, 256, 1, 1] and
= [B, 256, 1, 1] using GAP and GMP, respectively, and then linearly transformed using MLP to obtain
= [B, 256, 1, 1] and
= [B, 256, 1, 1], respectively.
are obtained through Equation (9). Up-sampling
by a factor of 2 yields
, and multiplying
by
yields
. Similarly,
and
can be obtained. Specifically,
equals
. The process is illustrated in
Figure 4.
(4) Feature Fusion. Using Equation (11), splice
,
,
, and
to obtain
= [B, 1024, 56, 56];
- (e)
The fifth step is to recognize. F is fed into a recognizer consisting of GAP, Fully Connected Layer, and Softmax Layer for scene recognition.
3.1. Backbone Network for Extraction Feature Map
We use Se-ResNext-50 as the feature extraction backbone network for this remote sensing image recognition task. Se-ResNext-50 retains the advantages of the residual structure of ResNet, adopts ideas from the inception network model in widening network processing, and combines the advantages of the Se-Net network to exploit the relationship between channels between features, which performs better in feature learning compared to ResNet and other variants of the network [
48].
As shown in © CNN Backbone Network in
Figure 1, the Stem module, layer1 module, layer2 module, layer3 module, and layer4 module in the Se-ResNext-50 network are used to compute the preprocessed dataset in turn for obtaining the output feature maps from the four-level modules. Within the Stem module, 64 convolution kernels of size 7 × 7 are used for the convolution calculation at one step of 2. Then, the feature maps obtained in step 1 are pooled with a window of 3 × 3 and a maximum value of 2 for obtaining a feature mapping with a size variation of 56 × 56.
As shown in
Figure 2, the Layer1 module contains three groups of Bottleneck. Each group of Bottleneck consists of Conv_1, Conv_2, Conv_3, and Se-Module, where the convolutional kernel sizes of the three convolutional modules are 1 × 1, 3 × 3, and 1 × 1, and the numbers of convolutional kernels are 128, 128 and 256, in that order. Specifically, in the second convolution stage, 32 identical structures are utilized to widen this network module. In this se-module, the compression is performed using global average pooling, followed by modeling associations between channels through a full connectivity layer, a sigmoid function to export weights with an equal amount of input features, and finally, the normalized weights are added onto the features per channel. Similar to the Layer1 module, the number of Bottleneck compositions of Layer2, Layer3, and Layer4 modules are 4, 6, and 3, respectively, and each Bottleneck consists of Conv_1, Conv_2, Conv_3, and Se-Module, and the number of convolutional cores are, respectively [256, 256, 512], [512, 512, 1024], [1024, 1024, 2048]. After the calculation of each module above, we obtained the feature maps of four different convolutional layers, which are
= [B, 256, 56, 56],
= [B, 512, 28, 28],
= [B, 1024, 14, 14], and
= [B, 2048, 7, 7].
3.2. Preprocessing for Relational Feature Map
To prevent the model from becoming more complex and to control the number of parameters as much as possible, we use SimAM [
49] to focus the feature expressions of the four different layers deeper into the more important information without increasing the network parameters.
In order to facilitate the primary relational feature calculation and advanced relational feature calculation later, we use 1 × 1 convolution to perform channel reduction operation on the features maps. We design the convolutional dimensionality reduction module separately; the input size of the convolution kernel is set to the channel number scale of the input features, and the output number of the convolution kernel is kept the same as the channel number .
In the above processing, to avoid the instability of the network learning process due to the oversized feature data after the convolutional dimensionality reduction calculation, we batch normalize the dimensionality reduction results so that the feature data satisfy the distribution law of mean 0 and variance 1. In addition, to avoid over-fitting, we add a modified linear function [
50] to keep only the outputs larger than 0, and other inputs will be set to 0, so that the network can be better fitted.
So far, we obtained the results after relational feature maps preprocessing as = [B, 256, 56, 56], = [B, 256, 28, 28], = [ B, 256, 14, 14], = [B, 256, 7, 7].
3.3. Complementary Relationship Feature Map Calculation
Information about the relationship between
,
,
and
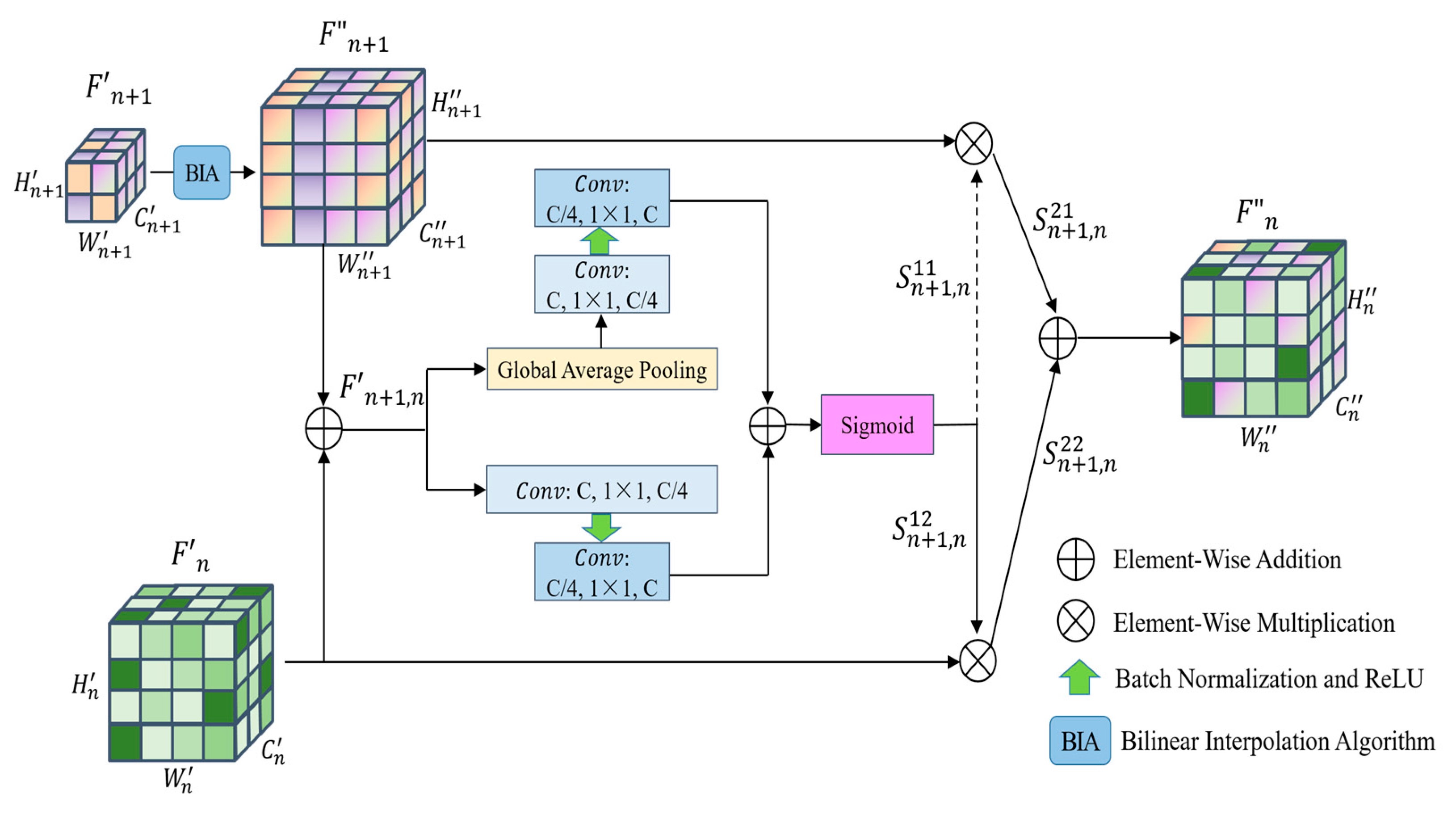
should be fully utilized. We design a primary relationship enhancement process from the high feature layer to the low feature layer to further extract the relationship between adjacent layer features and embed this relationship into the adjacent low layer features to complement the performance of low layer features, and the structure is described in
Figure 3.
In aiming to utilize the adjacent high convolutional layers to complement the missing global message of low-level features, we enhance the size of high-level feature maps with a bilinear difference algorithm to match the size of the feature maps acquired from low-level convolutional layers. In particular, unlike the literature [
20], considering various fusion methods of convolutional features from adjacent layers will have variable effects on integrated features; instead of simply using the direct summation of the corresponding elements, we obtain the primary relational features by assigning different weight parameters to the adjacent feature layers and then multiplying the corresponding elements with the weights before summation.
As seen in
Figure 3, firstly achieve size augmentation of dimensions between relational features by a bilinear interpolation algorithm, and then the dimensionally augmented feature map and the underlying feature map in its adjacent layers are sequentially summed by the corresponding positions of the pixels to acquire the fused feature map.
where
denotes the element-by-element summation operation.
Then, utilizing the features acquired in the previous step, the global and self-attentive relationship weights are calculated by the sigmoid function, respectively. As shown in
Figure 3, the process shown in the upper part of the branch is the computation process of global attention features. We perform a two-dimensional global average adaptive pooling of the input features, and then use a convolutional kernel of size 1 × 1, and the channel dimension of output features is one-fourth of the channel dimension of input features to realize the dimensionality reduction of convolutional feature channels. In order to avoid the computed data being too large and the network over-fitting problem, we perform batch normalization and add modified linear units. Finally, the original count of channels for features is to be restored with a convolutional kernel of size 1 × 1, and batch normalization is performed to obtain global attention features.
The process shown in the lower branch is the computation process of local attention features. By adopting a 1 × 1 size convolution kernel, the channel dimension of the input features is minimized to one-fourth of the original size. Then, batch normalization is performed, and corrected linear units are added. Finally, the amount of original channels to which the channel dimension of the feature map is restored with a convolution kernel of size 1 × 1 is applied, and then all feature values are normalized to acquire self-attention features.
After summing the global attentional features and self-attentive features per element according to the corresponding positions, the sigmoid function is employed for computing the focused relationship parameters of the bottom layer in the adjacent feature layer, which is . Similarly, the supplemental relationship parameter of the higher level is obtained, where .
This leads to the focused relation feature map
and the supplemental relation feature map
:
where
indicates that the elements in the corresponding positions are calculated sequentially according to the multiplication rule. Finally, the complementary relationship feature map is obtained.
By the same principle, we obtained the complementary relationship feature map for , , and .
3.4. Enhanced Relationship Feature Map Calculation
Considering the main relationship feature maps of two neighboring layers, where one lower layer contains the contextual information of the upper layer and the main relationship feature map of the upper layer is a more abstract representation of the lower layer, there is a rich contextual dependency between these feature maps.
The purpose of this proposed section is to capture such contextual relationships for embedding into the higher-level feature maps of neighboring layers so as to enhance the representation of higher-level features.
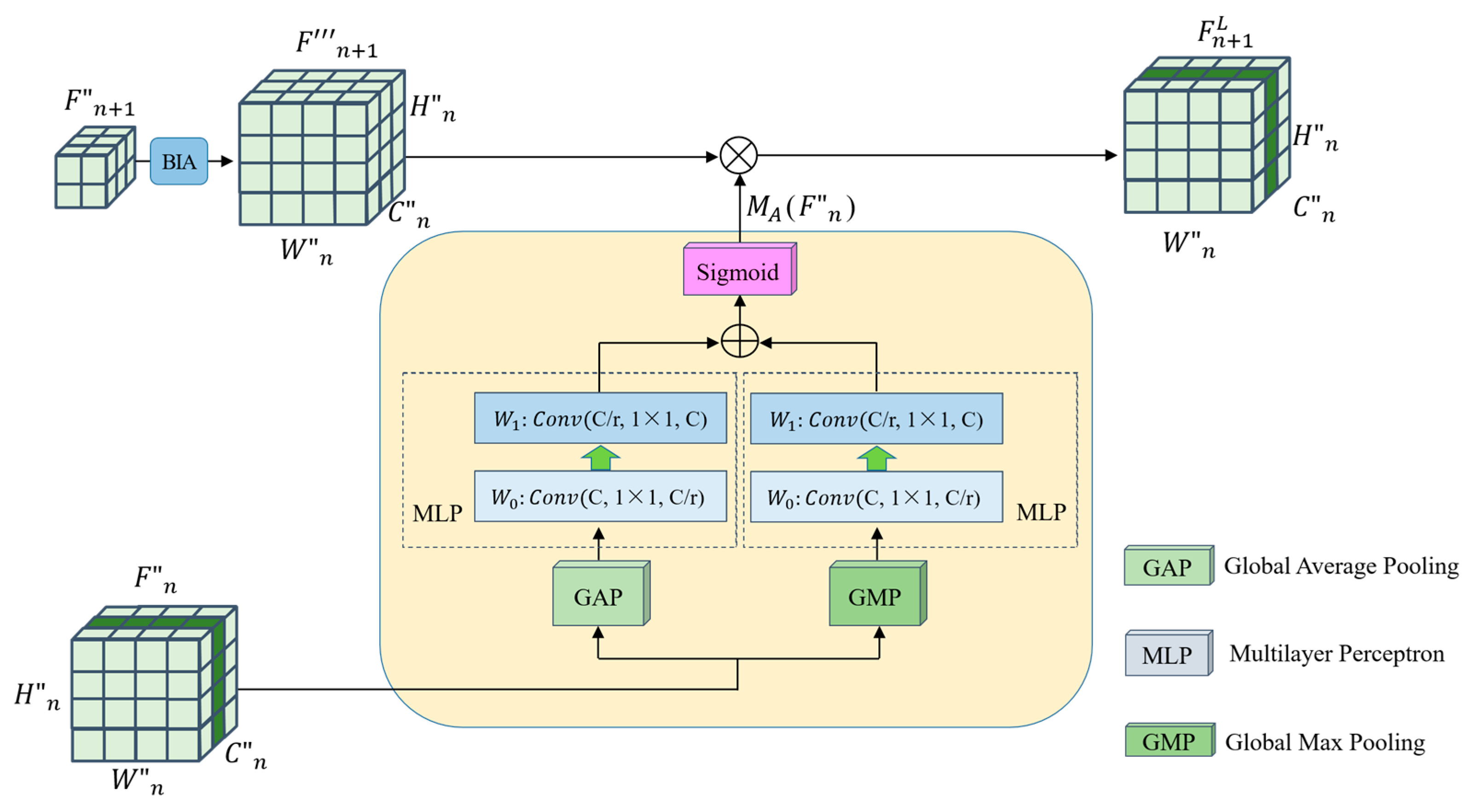
The calculation process for the module is illustrated in
Figure 4; let
denote the obtained primary relationship feature map, where
,
,
and
denote the number of learned features, the channel dimension of features, the horizontal dimension of features, and the vertical dimension of features in one training session, respectively.
To establish the high-level enhancement relationship between two adjacent layers of features
and
, the GAP is calculated to acquire global feature map
and the GMP algorithm is utilized for local feature map
.
where
indicates that after GAP calculation and
indicates that after GMP calculation.
Then, the two results are imported into the MLP separately.
where
and
represents the scaling ratio of the channel dimension.
and
are convolutional operations. In particular, the activation function
comes right after
to avoid over-fitting and speed up network convergence.
Then, the output from the multilayer perceptron
is subjected to an element-wise summation operation, followed by a Sigmoid activation operation to generate the enhanced weights of the adjacent two layers of feature maps:
where
denotes the Sigmoid function.
After calculating the augmented weights of the adjacent two layers of feature maps, we perform an elemental multiplication to calculate the mapping with feature augmentation:
where
denotes the element multiplication operation. The enhanced relationship feature maps
,
,
, and
can be calculated from Equation (10).
3.5. Feature Fusion and Objective Recognition
The advanced enhancement features are fused using the concatenation function to generate the final multilevel enhanced relationship feature map.
Then, after GAP calculation, the flattened feature is obtained by pulling the global average pooled features into a one-dimensional vector using the flatten function. Then, the flattened features are input to the fully connected layer. Finally, We use one-hot coding to represent categories of remote sensing scene categories, where the true probability of a category is denoted as . The predicted probability of each of the categories is obtained by inputting into the Softmax Layer.
The loss distance between the true probability and the predicted probability is determined by using the loss function; the smaller the loss value, the more accurate the prediction:
where
represents the total number of scene objective categories to be recognized.
5. Discussion
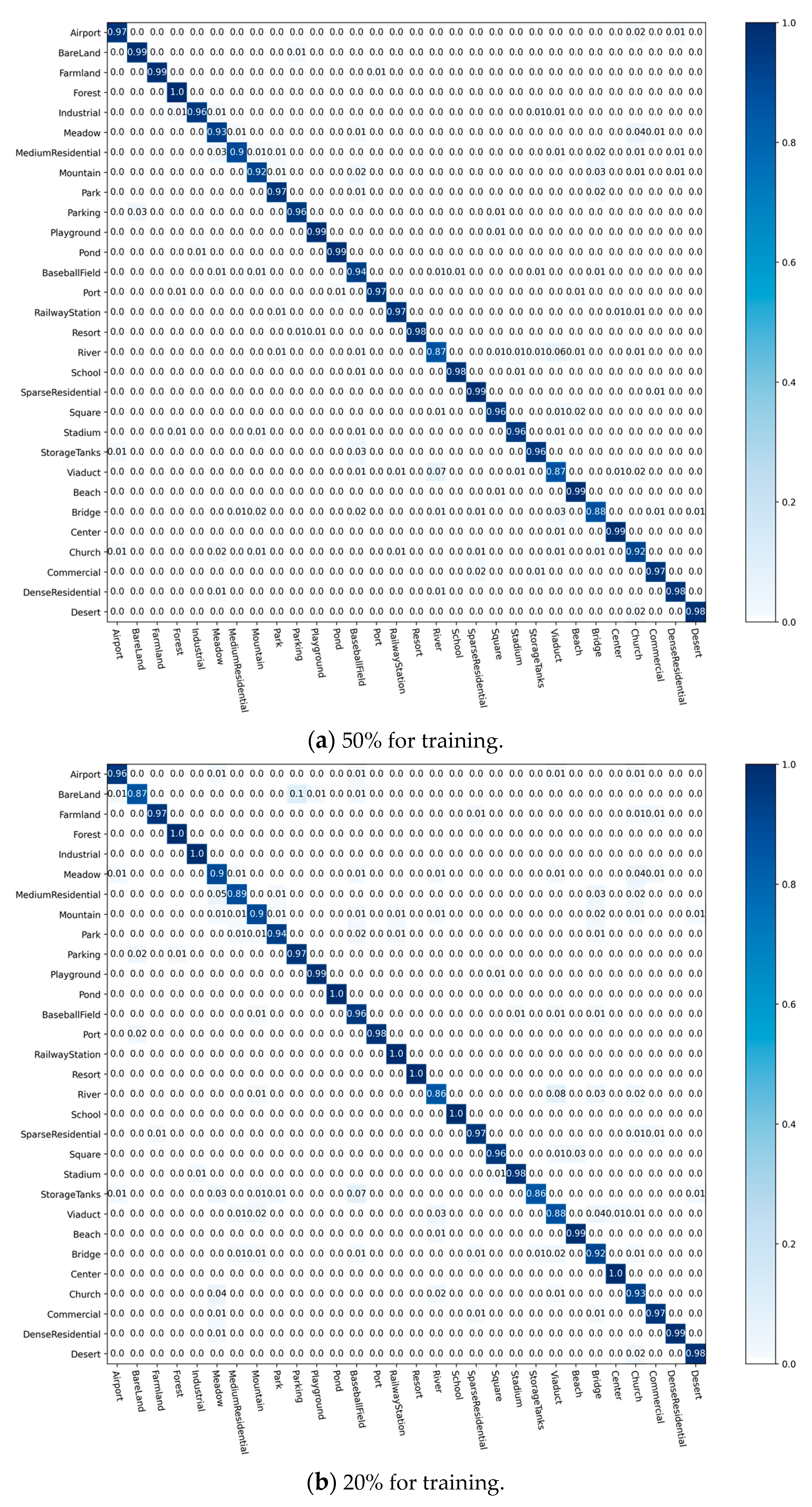
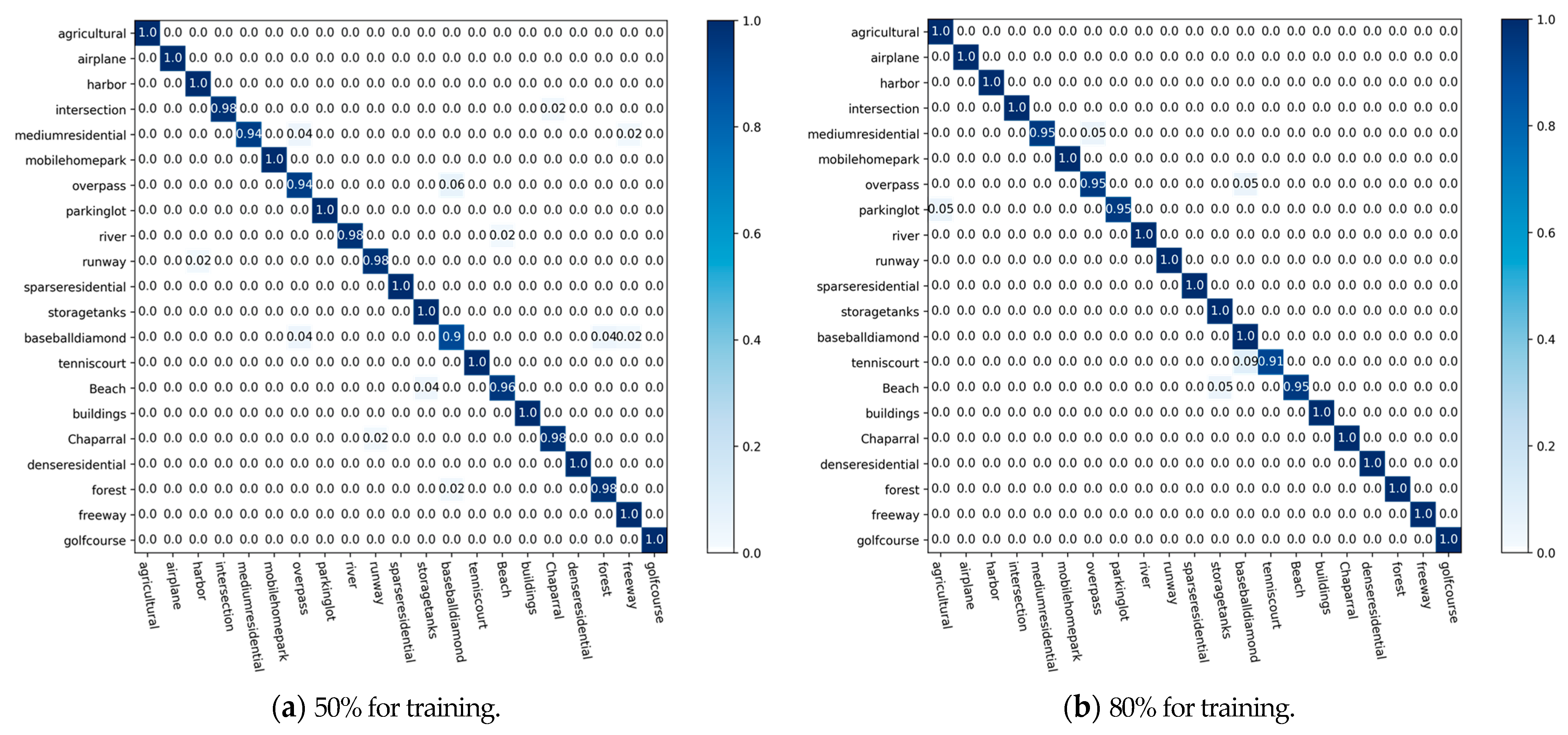
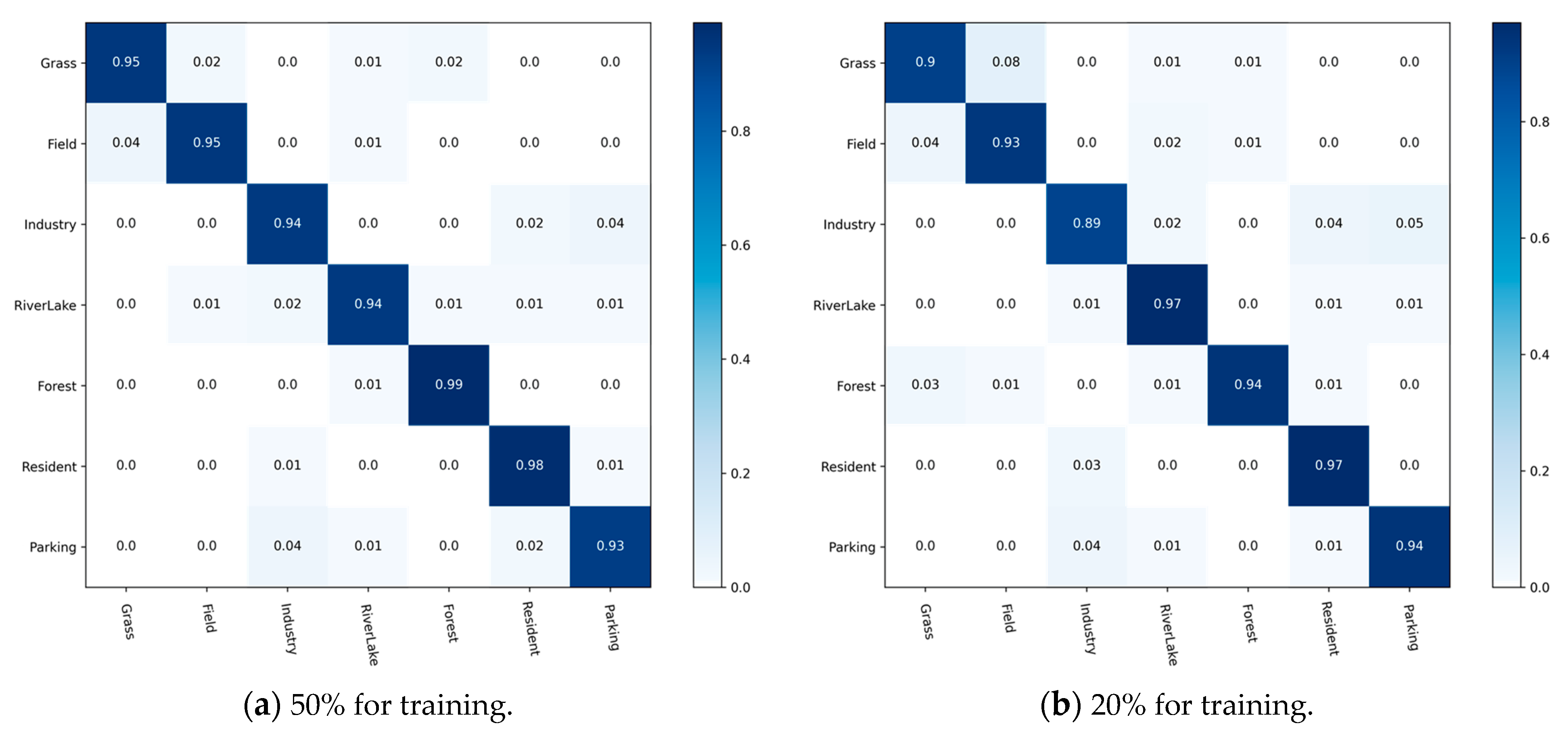
To evaluate our proposed method scientifically, we have conducted sufficient ablation studies in three aspects: the typical model used in extracting features, the attention mechanism used in preprocessing, and the two modules used in the calculation of relational feature maps to verify the scientific validity of the present method.
5.1. Effects of Backbone Network
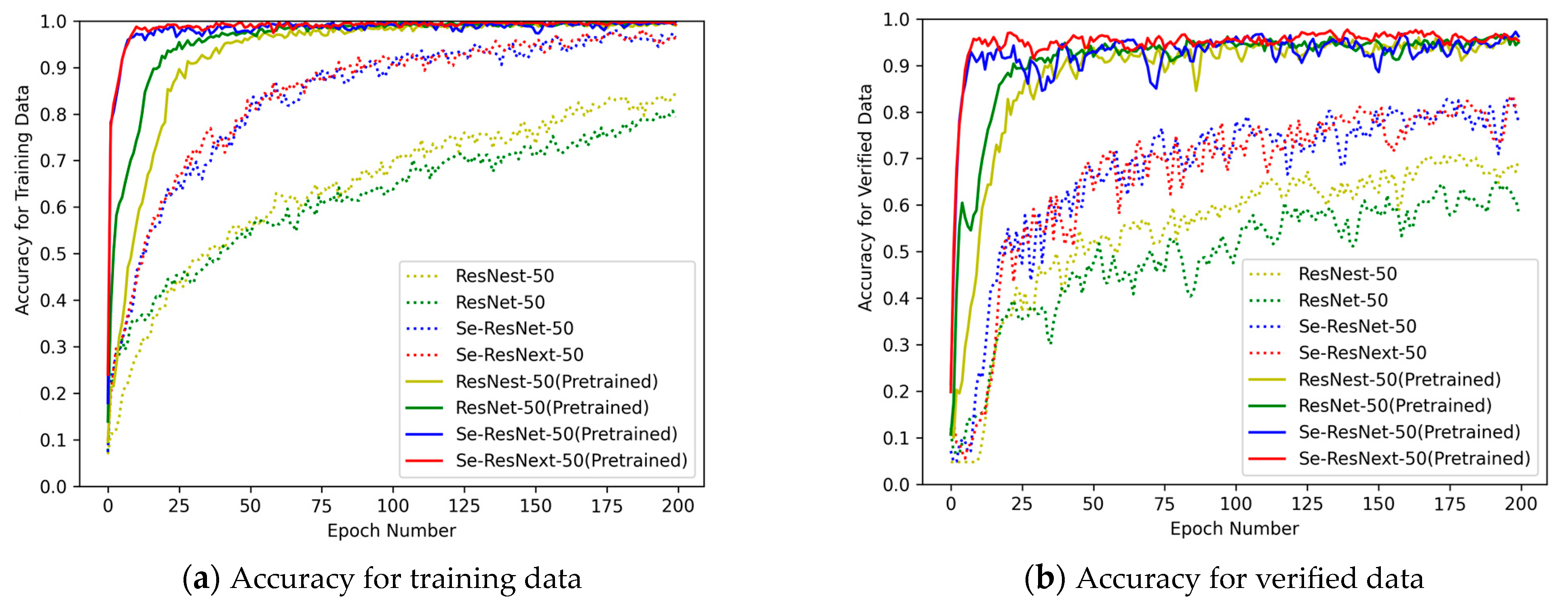
For a better demonstration of how superior the Se-ResNext-50 model is in our proposed approach, we selected ResNet-50 and its improved model to compare the experimental effects. Specifically, the UC-Merced dataset is split into training data and validation data in a 1:1 ratio, at the same time keeping the feature preprocessing module and two relational feature calculation modules unchanged. In addition, the optimizer and learning rate, etc., were also kept unchanged, and only the backbone network for extracting features was replaced, and 200 epochs were trained to obtain the accuracy results of RSSOR, as shown in
Figure 11.
The left panel in
Figure 11 shows the recognition accuracy of different backbone networks in the training data, while the right panel shows the recognition accuracy of different backbone networks in the verified data. The solid line indicates that we used pretraining parameters in the training, and the dashed line indicates that we did not use pretraining parameters. Obviously, the Se-ResNext-50 model with pretraining parameters in the same case not only converges quickly and smoothly during the learning process in both datasets, but also has the highest target recognition accuracy. Therefore, it is clear that the convolutional network backbone model used has some superiority.
5.2. Effects of Attentional Mechanism
With the aim of analyzing the influence of various attention mechanisms in the feature preprocessing stage on the final recognition effect of our method, we selected three typical attention mechanisms containing Efficient Channel Attention (ECA) [
65], Convolutional Block Attention Module (CBAM) [
66], and SimAM, and conducted validation experiments with other conditions remaining the same and not being changed, respectively. The specific results are presented in
Table 4.
Scientific and rational use of AM can improve the overall performance of the model to a certain stage on the basis of the original method performance level. To facilitate the comparison of experimental effects, we set up a new function, named
, to evaluate the enhancement of method performance by the attention mechanism by calculating the proportion of the amount of category scene features of the maximum evaluation metric. The bolded numbers in
Table 4 indicate the maximum rate of the results in this category, and it is easy to discover from the Maximum rate that the best results were achieved when we used SimAM, both in precision, recall, and specificity of the samples. Conversely, when ECA and CBAM were used, the Maximum rate of the sample data was lower than when no attention mechanism was used. Therefore, we chose SimAM with facilitation in the preprocessing stage.
5.3. Effects of MLP, GAP, and GMP
In enhanced relationship feature map calculation, the number of feature channels input to the MLP is 256, so we set seven different scaling values, and using the UCM dataset trained under the same conditions, we obtained the accuracy of the model under different channel scaling ratios. As can be seen from
Table 5, the model has the highest accuracy when the scaling ratio is equal to 16.
To verify the effect of GAP and GMP on the accuracy of the model, we designed three combinations and trained them under the same conditions, as shown in
Table 6; when both GAP and GMP are involved in the training, the local enhancement coefficients and global enhancement coefficients of the input features are involved in the relationship enhancement computation, which leads to the highest accuracy of the model.
5.4. Effects of Feature Fusion Strategy
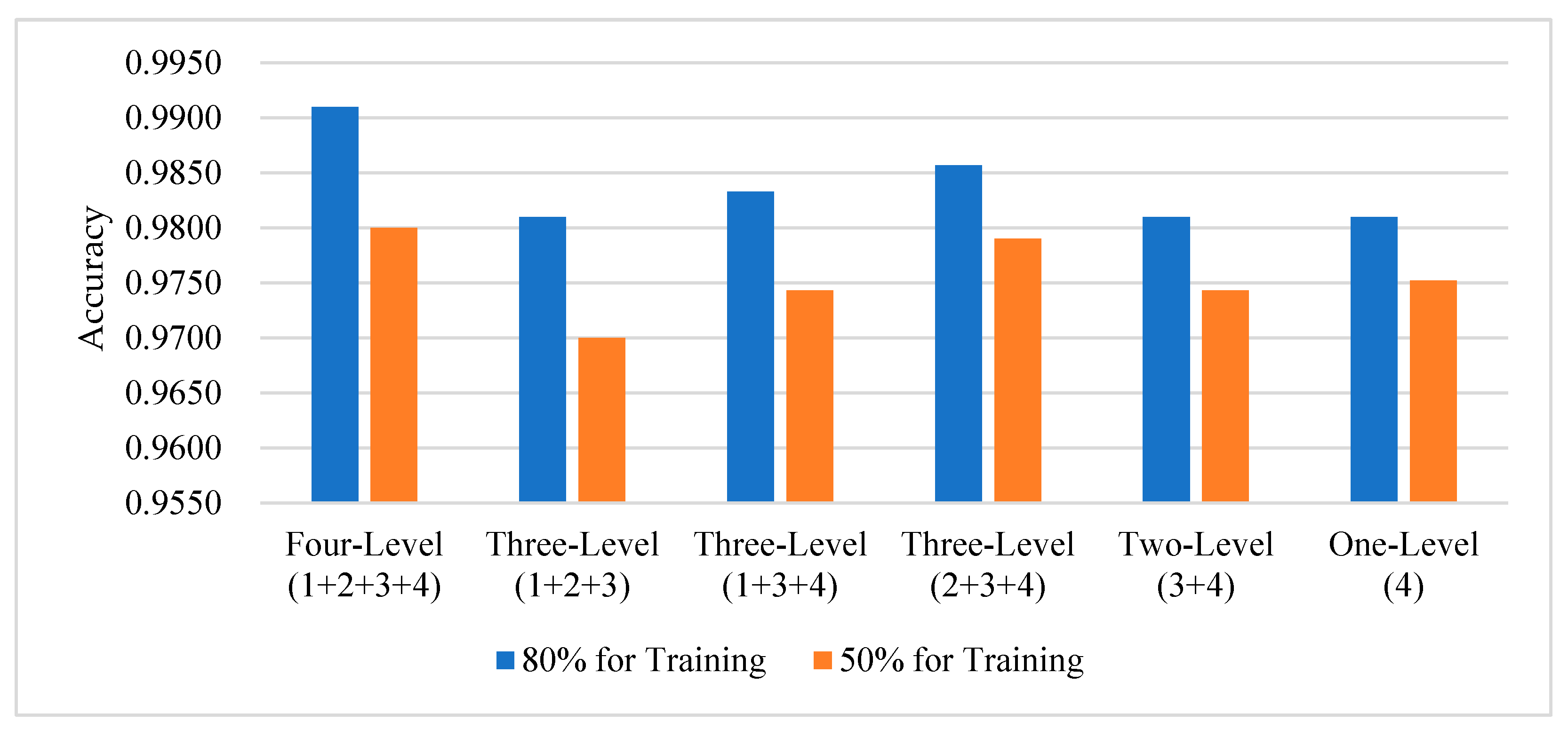
Towards analyzing the influence of multilevel enhancement relationship features on scene recognition effect under different fusion strategies, on the basis of fusing four-level features by using the concatenation function, we carried out comparison experiments on four high-level enhancement features according to the ways of fusing three-level features, fusing two level features and no fusing.
We design the model architecture in each of the four different fusion methods according to the mathematical approach to combination. When no features are fused, the channel dimension is minimized, which is 256; when two features are fused, the channel dimension is 512; and when three features are fused, the channel dimension is 768. Using 80% and 50% of the UCM data, we train under the same conditions.
Figure 12 lists some of the results of the experiments, from which it can be seen that the enhanced features are able to obtain high accuracy; in addition to the different strategies for combining the features, the recognition accuracy of the model under the same conditions is also different. When all four levels of features are concatenated by the concatenation function, the channel dimension reaches 1024, and the features at this time fully integrate the relationship information between the features at all levels, and after training, the model has the highest accuracy rate.
5.5. Effects of Calculation Module
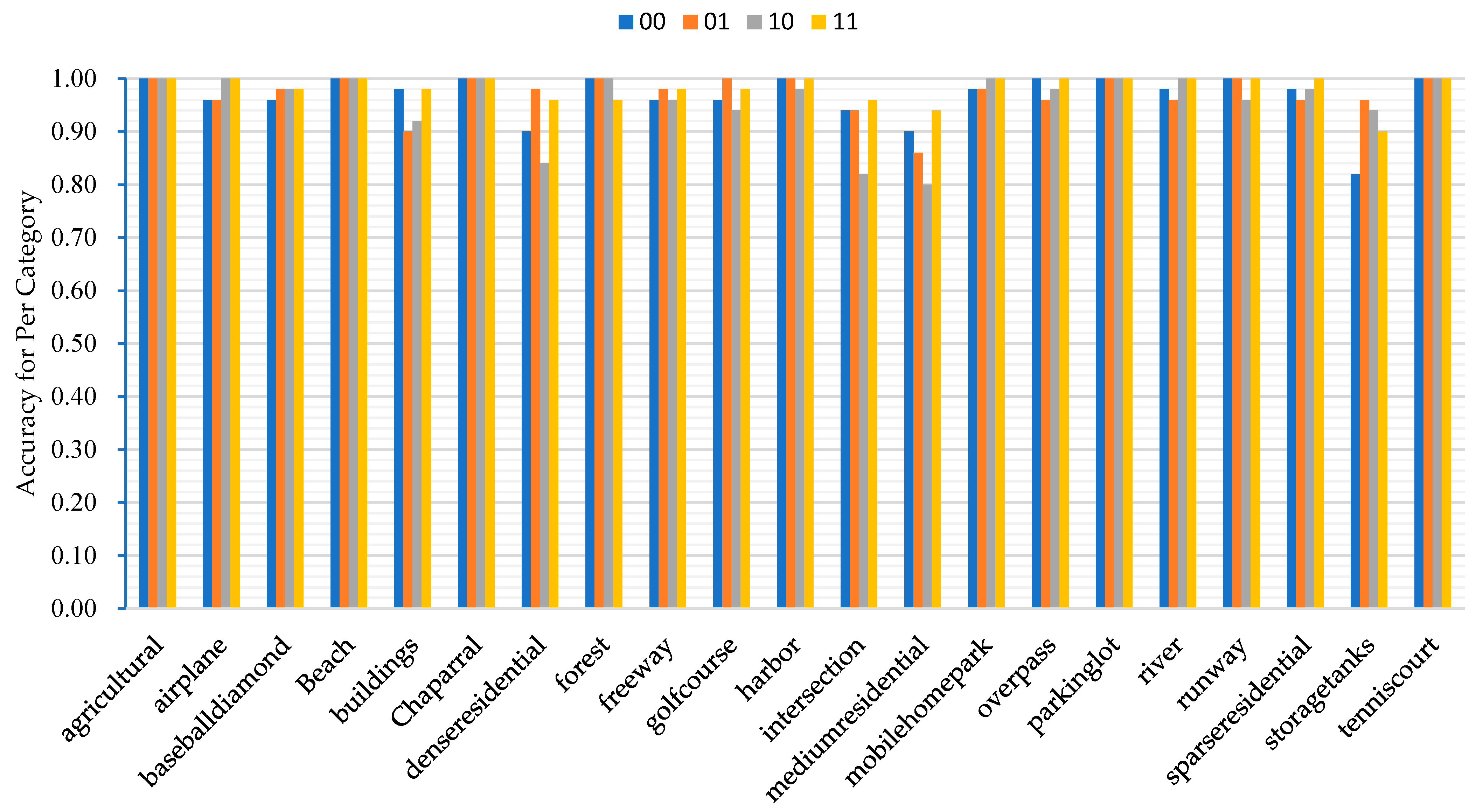
For analyzing the effect of our proposed complementary relationship and enhanced relationship module on the recognition effect of the model, we set four different combinations of the relationship module under the same other conditions, so as to verify the recognition accuracy of the method in terms of different combinations of modules.
As shown in
Figure 13, the “00” mode indicates that the complementary and augmented relationship modules are not used; the “01” mode indicates that the complementary relationship module is not utilized, but the augmented relationship module is utilized; the “10 “ mode indicates that the complementary relationship module is utilized and the augmented relationship module is not utilized; “11” mode indicates that the complementary relationship module and the augmented relationship module are utilized. We conducted comparison experiments on the UC-Merced dataset to obtain the recognition of each category of scene targets. From the figure, we can see that the “11” mode has relatively high accuracy and is more stable than the other modes.
6. Conclusions
Not only because of the complexity of remote sensing scene image data, but also because of the simple application of features to each layer of CNN, all of which affect the improvement of scene objective recognition accuracy to a certain extent. To solve the issue, we use the convolutional feature message of the upper layer to complement the lower layer, and complementary weights between adjacent layers are calculated using the self-attention relation and the global attention relation, and then the weights are assigned to the adjacent layers to complementary relationship feature maps, and the global and local features of the underlying layers are extracted to form the guide coefficients, and then fused with the features of the upper layers to obtain the enhanced relationship feature maps, and finally the features are fused to achieve scene objective recognition using softmax recognizer. The network is able to capture the key contents of scene objectives and enhance the representation of deep features by using the complementary relationships between contextual features and enhanced relational information, further improving the performance of scene recognition based on CNNs effectively. Experimental results on three common benchmark data collections (including AID, UC-Merced, and RSSCN7) indicate that CRABR-Net can fully utilize the powerful learning ability of CNN and realize higher recognition accuracy. In the next work, we will investigate various network architectures to enhance the efficiency of remote sensing scene objective recognition further by fusing and optimizing different networks.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}