1. Introduction
As a component that plays a role in fixing and reducing the load friction in mechanical transmission processes, bearings are widely used to guide the rotational motion of shaft parts and withstand the loads transmitted by the shaft to the frame. The quality of the bearings in mechanical equipment has a significant impact on the stability of the entire equipment operation. However, during the production and assembly process of bearings, surface defects are inevitable due to factors such as materials, processing, assembly, and transportation. Common surface defect types include cracks, black spots, scratches, dents, forging waste, helical marks, undersized inner and outer ring chamfers, and incorrect character engraving, among others. These defects affect not only the appearance and quality of the bearings but also their service life and performance. Therefore, quality inspection of bearings must be carried out before they leave the factory.
In recent years, with the development of machine vision and deep learning technologies, many defect detection methods based on machine vision and deep learning have been widely applied in various industrial scenarios, mainly including solar energy [
1,
2], transportation [
3,
4], textile [
5,
6], medical [
7,
8,
9], metal materials [
10,
11,
12], and other fields. However, machine vision inspection methods for surface defects on bearings are not commonly utilized.
Currently, bearing surface defect detection methods can be roughly divided into two categories. One is traditional machine vision-based detection methods, Liu et al. [
13] proposed an automatic synthetic tiny defect detection system for bearing surfaces with self-developed software and hardware, thresholding segmentation, contour extraction, contour filtering, center location, region zoning, and text recognition are successively implemented, but this method cannot detect small or too large defects. Jiang et al. [
14] proposed a cloud model-improved EEMD with superior performance in reducing multiple background noise and then proposed a rolling bearing defect detection scheme based on this method, but this method will adversely affect the fault feature extraction. Li et al. [
15] proposed a technique using the generalized synchrosqueezing transform (GST) guided by enhanced TF ridge extraction to detect the existence of the bearing defects. Wang et al. [
16] proposed a synthetic detection technique that uses a combination of empirical mode decomposition (EMD), ensemble empirical mode decomposition (EEMD), and a deep belief network (DBN) to improve the accuracy of the acoustic defective bearing detector. The alternative is deep learning-based detection methods. Tabernik et al. [
17] proposed a segmentation-based deep learning method for defect detection. The method first converts vibration signals into two-dimensional grayscale images in a time-frequency representation. Multiple binary segmentation models are then used to segment the images and obtain masks of the defect regions. Finally, a classification model is used to classify each defect region, which enables the detection and segmentation of surface cracks with a few defective samples. Xu et al. [
18] proposed an unsupervised neural network approach based on autoencoder networks for bearing fault detection. The method preprocesses bearing images using a normalization algorithm that preserves the symmetry of the samples and uses gradients as labels to automatically detect surface defects on bearings. However, this method does not consider information such as the types, locations, or sizes of bearing defects but simply distinguishes defects from normal regions. Lei et al. [
19] proposed a segmented embedded rapid surface defect detection (SERDD) method that achieves a bidirectional fusion of image processing and defect detection. The method uses the spatial pyramid character proportion matching (SPCPM) method for character recognition and the image self-stitching and cropping (ISSC) method to solve the problem of truncated characters during coordinate transformation and the recognition of imprinted characters on the dust covers of bearings. Li et al. [
20] proposed a real-time steel strip surface defect detection method based on an improved YOLO detection network. The method improves the structure and loss function of the YOLO network and adds an attention mechanism and a multiscale feature fusion module. The mAP for six types of defects reached 97.55%, and the FPS reached 83. Fu et al. [
21] proposed a two-stage attention-aware method based on convolutional neural networks for detecting oil leakage in bearings. They used a novel attention-aware network called APP-UNet16, which stacks attention to allow for adaptive changes in attention-aware features. However, this method requires precise positioning of the bearings. Kumar et al. [
22] proposed a bearing defect size estimation method based on a wavelet transform and a deep convolutional neural network (DCNN). The method uses a continuous wavelet transform to process vibration signals and form two-dimensional grayscale images in a time-frequency representation. Then, the DCNN is used to learn the bearing defects and extract high-level features from the images, and the trained grayscale images are applied to the DCNN. However, this method relies on the selection of wavelet transform parameters, which may cause distortion and time-frequency information loss if the parameters are not properly chosen. Song et al. [
23] proposed an object detection algorithm based on YOLOv4. The method modifies the loss function to a focal loss function to eliminate the problem of bearing background interference and uses a smooth activation function to improve the gradient descent optimization process.
The application prospects of object detection technology based on deep learning theory in the detection of surface defects in bearings are very promising, but there are still some difficulties. This is because the background texture of the bearing rings is complex, the sizes of the defects are different, the types are diverse, and the brightness is uneven. In addition, the production environment of bearings has a large amount of oil and dust, which can interfere with the bearing images. Based on this, in combination with the optical characteristics, imaging characteristics, and detection requirements of the bearing rings, an improved YOLOv5 defect detection network is proposed, and an automatic detection system for surface defects of bearings is developed, which is applied industrially. The primary contributions of this study are as follows:
The C3 module in the main network is replaced with a C2f module, which not only reduces the number of parameters and computational complexity but also yields features with higher levels of semantics and globality.
A new CNN module is constructed, and the SPD module is introduced into both the main and neck networks, thereby improving the ability to detect low-resolution and small-object images.
A lightweight and universal upsampling operator, CARAFE, is utilized to enrich contextual information, reduce information loss during transmission, and enhance both the defect detection capability and the diversity and robustness of the network.
The remainder of this paper is organized as follows.
Section 2 introduces the bearing defect detection system.
Section 3 presents the detection method in detail, including details network structure of the improved YOLOv5 and loss function.
Section 4 provides experimental validation of our method. Finally,
Section 5 is the conclusion of our work.
3. Bearing Rings Defect Detection Model Based on the Improved YOLOv5
3.1. Network Structure of the Improved YOLOv5
YOLOv5 employs CSPDarknet53 as the backbone network and combines a feature pyramid network (FPN) and path aggregation network (PAN) as the neck network to fuse the features extracted from the backbone [
24]. The main part of the output head consists of three Detect detectors, which perform object detection using grid-based anchors on feature maps of different scales.
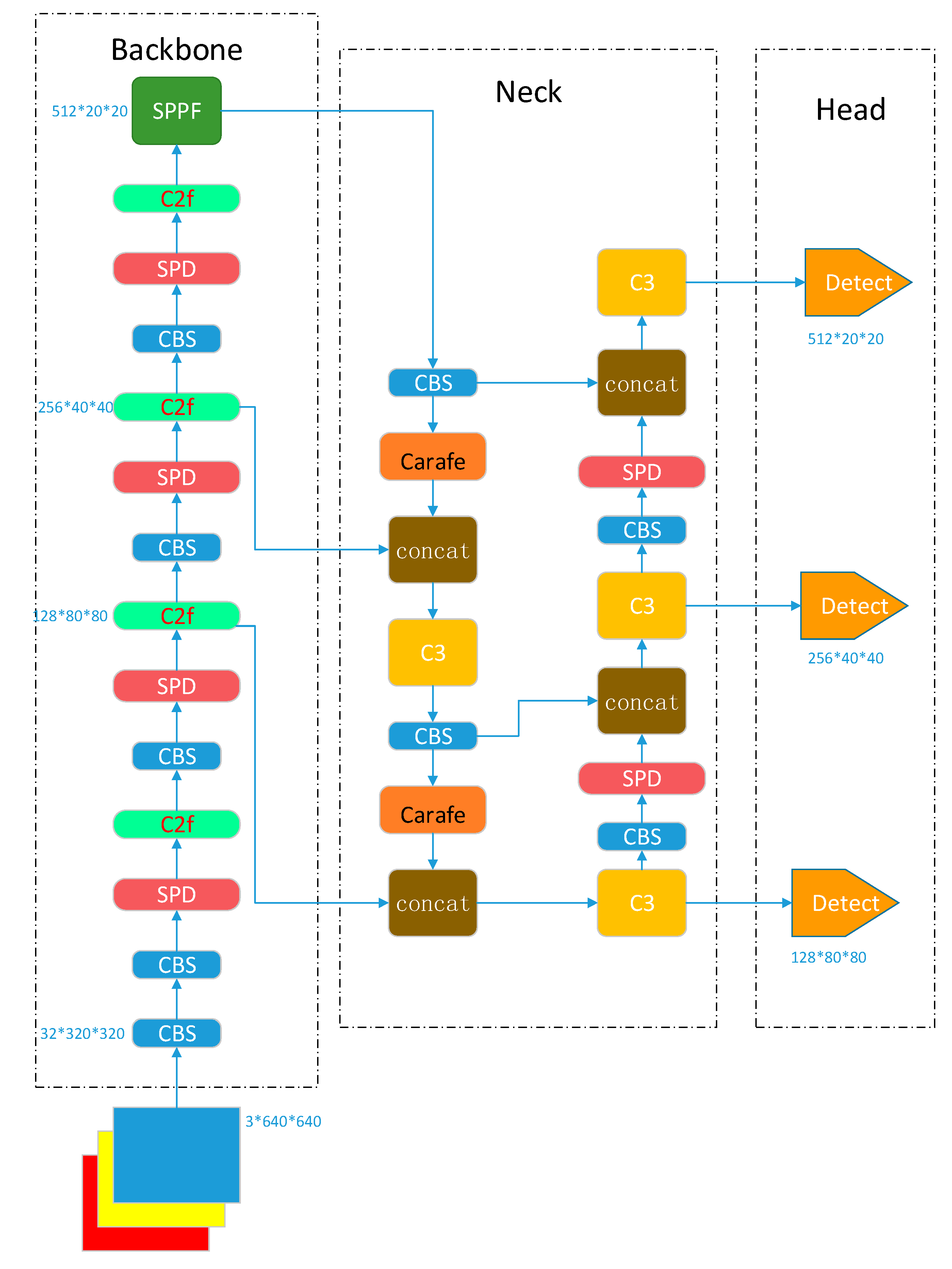
In the YOLOv5 network, strided convolutions and pooling layers can lead to the loss of fine-grained information and a decrease in feature extraction ability. The parameter and computational complexities of the C3 module, which affect the detection speed, are relatively high. Moreover, in the neck network, the use of the nearest-neighbor interpolation algorithm for feature map sampling can result in obvious jaggedness, leading to missing feature details and structural information in the feature map. Bearing defects such as helical marks, forging waste, black spots, dents, and scratches have different sizes and shapes, requiring the effective fusion of shallow and high-level semantic information across different scales of features. Based on this, to achieve the high-precision and high-efficiency detection of bearing defects on the surfaces of bearing races in complex scenes, this paper proposes an improved YOLOv5 network, as shown in
Figure 3. The network consists of three parts: the backbone, neck, and head. The backbone is used for feature extraction, the neck is used for the multiscale fusion of features extracted from different levels of the backbone using both top-down and bottom-up approaches, and the output is used for object detection and classification.
The backbone network performs five downsampling operations on the input through convolution, batch normalization, and SiLU activation function-based CBS downsampling modules.
In this paper, we use the SPD module to replace the previous Conv layer for downsampling, which increases the number of channels in the feature maps. The ability to detect low-resolution images and small objects is improved while maintaining the resolution of the feature map, which improves the model expression and generalization ability. Additionally, a C2f module is utilized to extract features. In contrast to the C3 module, C2f uses separable convolution and concatenation operations to enable the fusion of feature maps with different numbers of channels. In the neck, we employ CARAFE for upsampling, which preserves more detailed feature information and structural information, thereby improving the quality and accuracy of the upsampling operation.
The backbone network is a convolutional neural network that extracts features of different sizes from the input image through multiple convolutions and SPD modules. The input image size is 640 × 640 pixels, and the backbone network generates five layers of feature maps after 2, 4, 8, 16, and 32 downsampling operations. The sizes of these feature maps are 320 × 320, 160 × 160, 80 × 80, 40 × 40, and 20 × 20, respectively.
To obtain more contextual information and reduce information loss during transmission, the neck network fuses the feature maps of the third, fourth, and fifth layers of the backbone network to enhance the feature fusion capability of the neck network. During the fusion process, the FPN structure transmits shallow semantic information from the top down, while the PAN structure transmits deep semantic information from the bottom up. These two structures jointly enhance the feature fusion capability of the neck network, and after feature fusion, three new feature maps are generated through three output layers. These three output layers are the shallow, middle, and deep layers, and the output sizes are 80 × 80 × 128, 40 × 40 × 256, and 20 × 20 × 512, respectively, where 128, 256, and 512 represent the numbers of channels. The smaller a feature map is, the larger the image area represented by each grid cell in the feature map. The shallow feature map is suitable for detecting small targets, the middle feature map is suitable for detecting medium targets, and the deep feature map is suitable for detecting large targets. Based on these new feature maps, the output network performs object detection and classification.
3.2. Space-to-Depth
In the task of detecting surface defects on bearings with low image resolution or small objects, the performance of convolutional neural networks for computer vision tasks such as image classification and object detection will rapidly degrade. The reason for this is that existing CNN architectures use strided convolutions and pooling layers, which lead to the loss of fine-grained information and the learning of less-efficient feature representations.
The space-to-depth (SPD) [
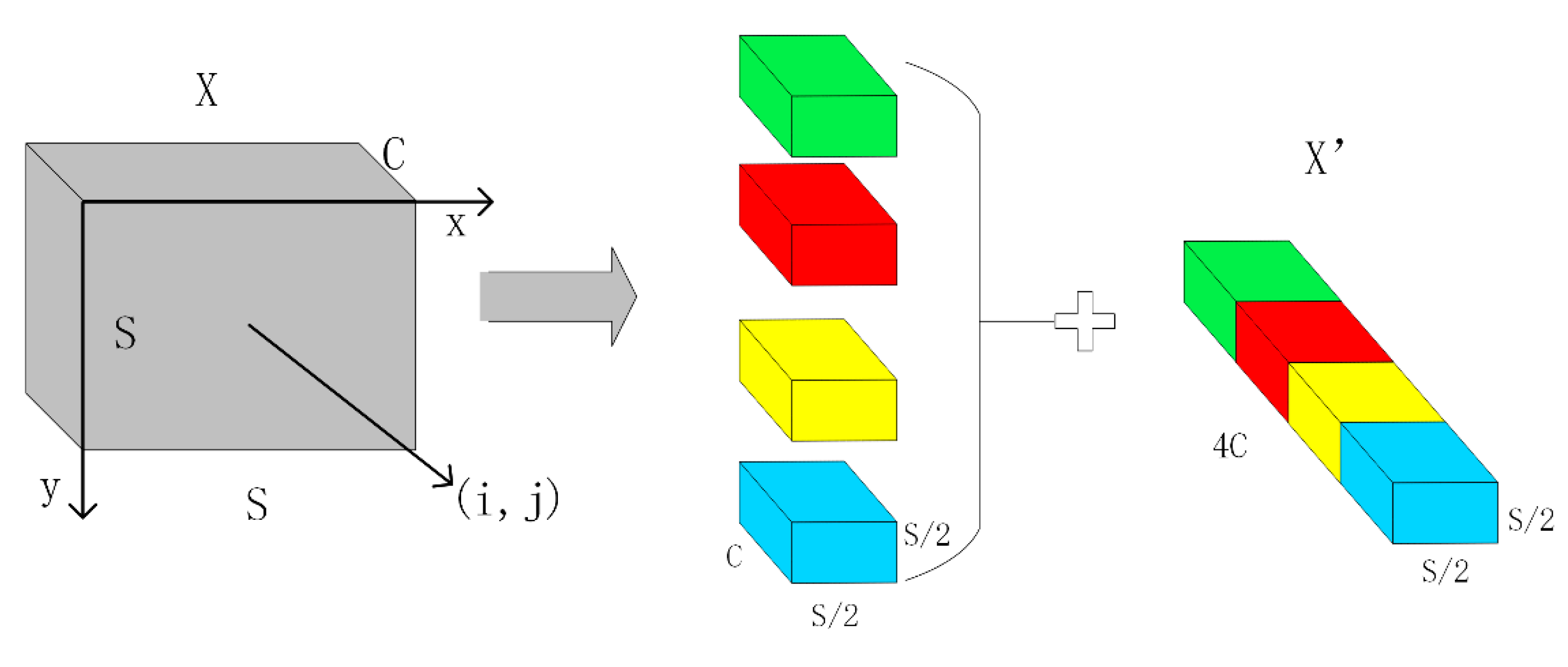
25] module can solve the problems of information loss and performance degradation caused by traditional strided convolutions or pooling layers when processing low-resolution images and small objects. The SPD module downsamples the feature map (X) within the entire network while retaining all the information in the channel dimension without information loss. A non-strided convolution layer is added after each SPD layer, which uses learnable parameters in the increased convolutional layer to reduce the number of channels and reduce the non-discriminatory loss of information. In this study, we use the SPD module for downsampling and change the stride of the Conv layer in the layer above the SPD module from 2 to 1.
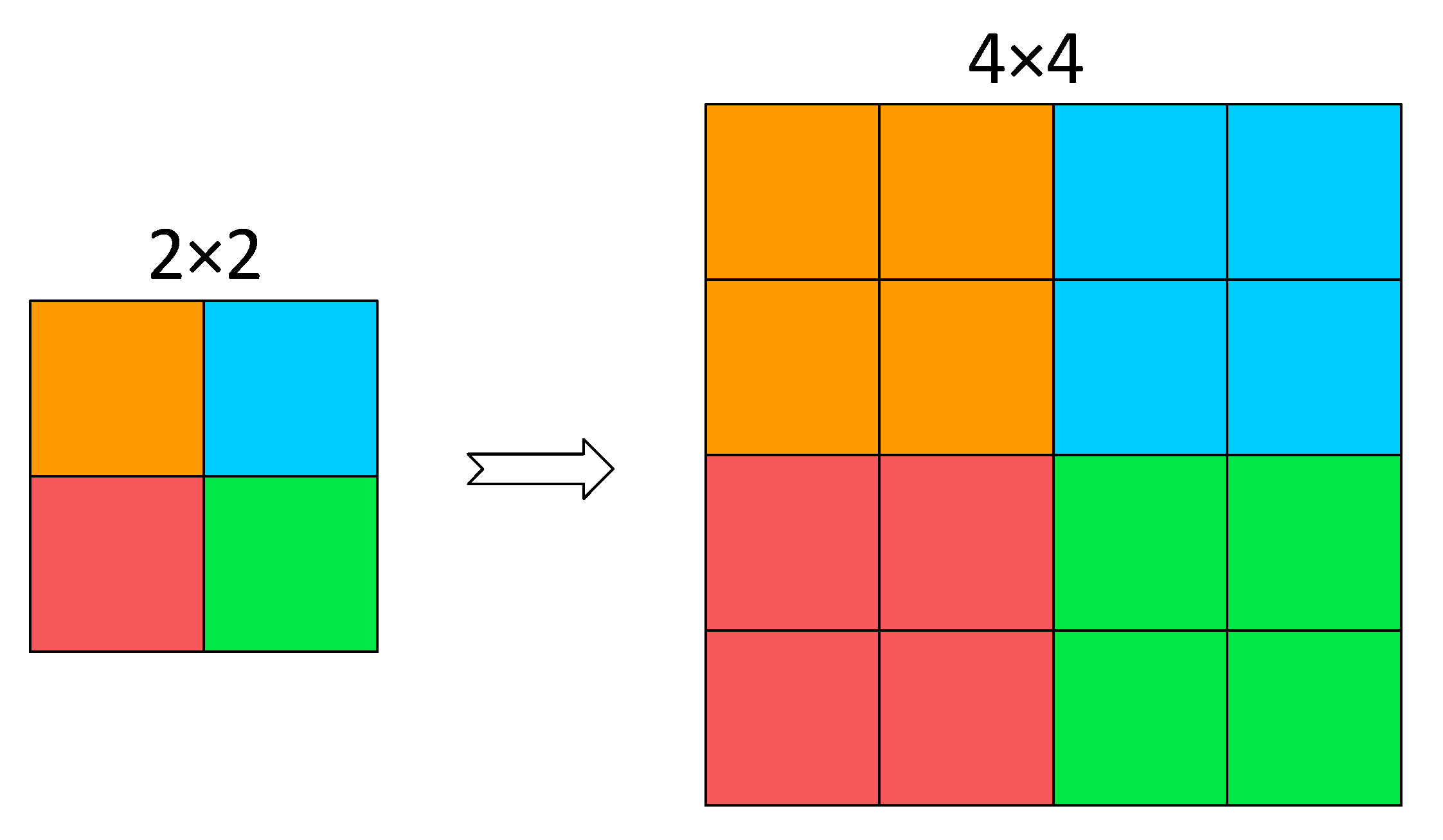
The original image or intermediate feature map is split into a series of sub-feature maps by the SPD layer, which are then stacked together, thereby increasing the number of channels and enlarging the receptive field while reducing the spatial dimensions. For any intermediate feature map
X of size
S ×
S ×
C, the series of sub-feature maps that are cut out are
In general, given any original feature map
X, a sub-map
is formed by all the entries
that
and
are divisible by scale. Therefore, each sub-map downsamples
X by a factor of scale. When scale = 2, as shown in
Figure 4, four sub-feature maps are obtained, each with a size of
. Meanwhile,
X is downsampled by a factor of 2, and the resulting sub-feature maps are concatenated along the channel dimension, resulting in a new feature map
. The spatial dimensions of
are one-fourth of
X, while its channel dimension is four times that of
X.
The SPD module can reduce the computational complexity by using an SPD layer instead of strided convolutional or pooling layers. The SPD layer reduces the height and width of the input feature map by half while increasing the number of channels by four times, thereby increasing the depth of the feature map and maintaining the total number of elements, which improves the representation ability and multiscale fusion performance of the feature map. As a result, subsequent C2f layers can perform computations on a smaller spatial scale without losing information.
The SPD module can improve the receptive field and localization accuracy by preserving all information of the input feature map without losing details, such as strided convolutional or pooling layers. The SPD module can enhance the model performance, particularly in handling more challenging tasks such as low-resolution images and small objects.
3.3. C3 Module and C2f Module
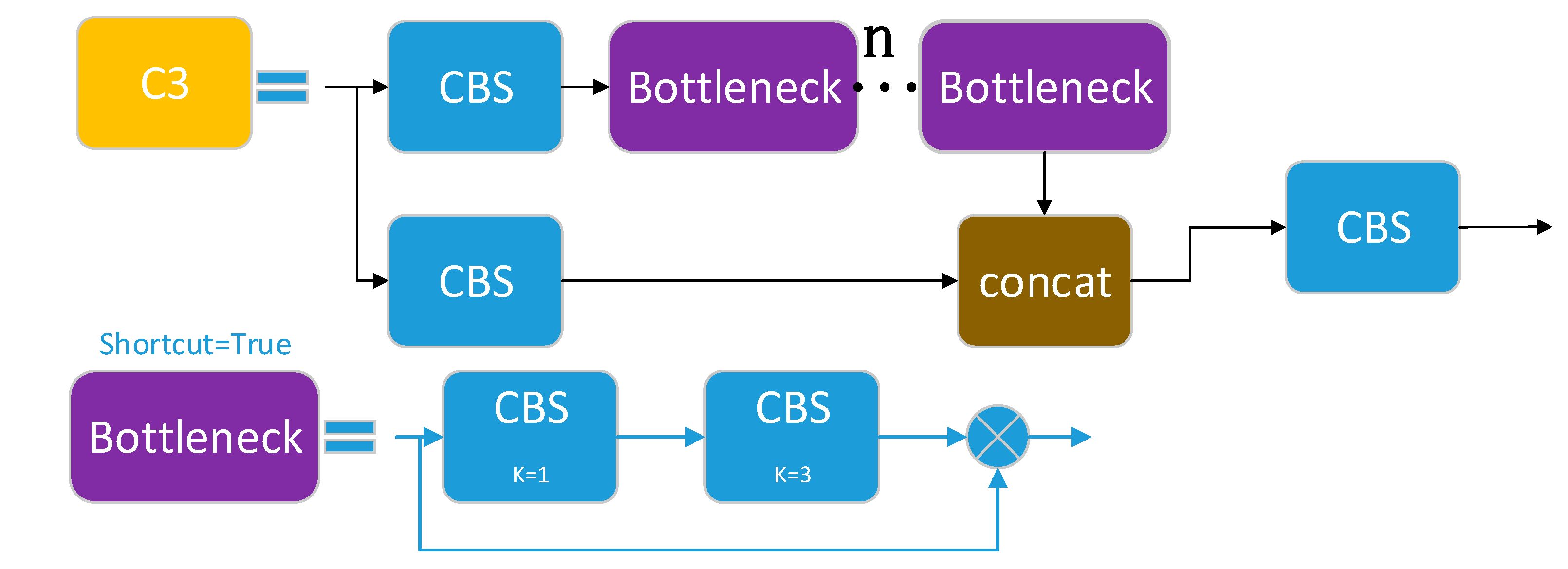
3.3.1. C3 Module
The C3 module consists of three standard convolutional layers and n bottleneck modules, where the value of n depends on the model’s scale. It is the primary module for learning residual features, and its function is to increase the number of channels of the feature map while maintaining its size, thereby improving the feature representation performance. The bottleneck modules in the backbone use shortcuts, while those in the neck do not. As shown in
Figure 5, the input feature map enters two branches, one of which generates a map, namely, sub-feature map 1, by stacking multiple bottleneck modules and one standard convolutional layer, while the other generates another map, namely, sub-feature map 2, with only one basic convolutional module. Finally, the two sub-feature maps are concatenated and output.
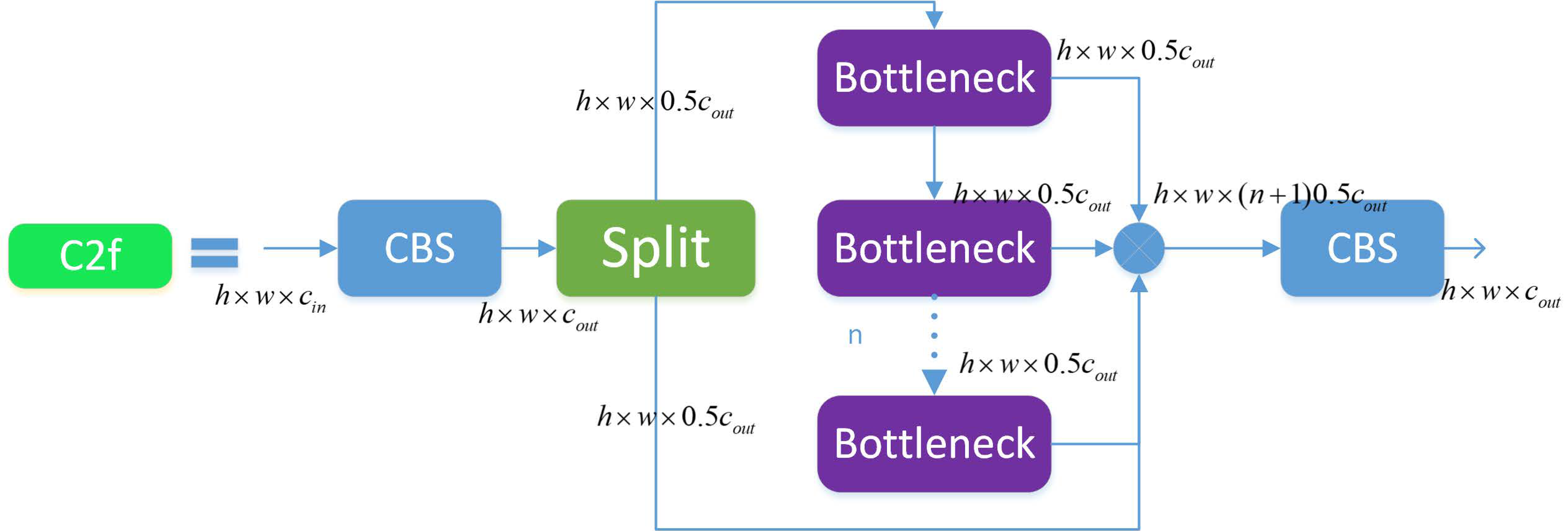
3.3.2. C2f Module
The C2f module [
26] was designed based on ideas from both the C3 module and ELAN. It utilizes one fewer CBS convolution than the C3 module and concatenates all the sub-feature maps output by each bottleneck module, which not only ensures a lightweight but also produces richer gradient flow information. Feature segmentation and fusion are achieved using the Split and Concat operations, respectively. Similar to the C3 module, the bottleneck modules in the backbone network use shortcut connections, while those in the neck network do not.
According to
Figure 6, the size of the input feature map is
. After passing through the CBS, the output size is
. The output feature map is split into two sub-feature maps through the Split operation, and one sub-feature map is processed through n bottleneck modules. Meanwhile, each sub-feature map output by the bottleneck module is concatenated with a sub-feature map previously split by the Split operation. Finally, a CBS module is used to output a feature map with the same size as the input.
In the network architecture, the C2f module does not use shortcut connections by default, while the C3 module uses shortcut connections by default. Compared with the C3 module, the C2f module is of lighter weight and uses fewer parameters and computational resources while maintaining high accuracy and speed. Its function is to extract feature maps in the backbone and achieve feature fusion and channel separation through the CSP structure, improving the quality and efficiency of the feature maps, enhancing the receptive field and multiscale ability of the feature maps, and obtaining more global and higher-level semantic features.
3.4. Lightweight Universal Upsampling Operator
3.4.1. Nearest-Neighbor Interpolation
The purpose of an upsampling module is to expand a low-resolution image or feature map into a high-resolution image or feature map, which can be displayed on higher-resolution display devices or improve the performance of subsequent tasks. An upsampling module can be used as an intermediate layer in a convolutional network to expand the size of the feature map and facilitate tensor concatenation. There are various methods for implementing upsampling, such as nearest-neighbor interpolation, bilinear interpolation, bicubic interpolation, trilinear interpolation, deconvolution, and transpose convolution [
27]. Upsampling modules are commonly used in tasks such as image segmentation, super-resolution, and style transfer. Almost all upsampling methods use interpolation, i.e., inserting new elements between pixel points using appropriate interpolation algorithms based on existing image pixels.
In YOLOv5, nearest-neighbor interpolation is used as the default upsampling algorithm. Nearest-neighbor interpolation is the simplest interpolation algorithm, which sets the grayscale value of the transformed pixel to the grayscale value of the input pixel that is closest to it. Nearest-neighbor interpolation is implemented through coordinate transformation, mapping each pixel point in the target image to the original image and then taking the grayscale value of the original image pixel nearest to the target image pixel as the grayscale value of the target image pixel, as shown in
Figure 7. When an image is enlarged, each missing pixel is generated directly using the nearest existing color, which means copying the neighboring pixels. However, this method produces obvious jaggedness. Jaggedness, commonly referred to as “jagged artifacts”, is a common phenomenon in image processing and computer graphics. They typically occur when resizing images or performing pixel-level resampling. The primary cause of this distortion is insufficient image resolution or inadequate smoothing of image details during image upscaling or resizing. When an image contains sharp transitions or edges between regions, low-quality interpolation methods, such as nearest-neighbor interpolation, can lead to abrupt changes in pixel values. This can result in pronounced jagged edges between edges and regions.
3.4.2. CARAFE
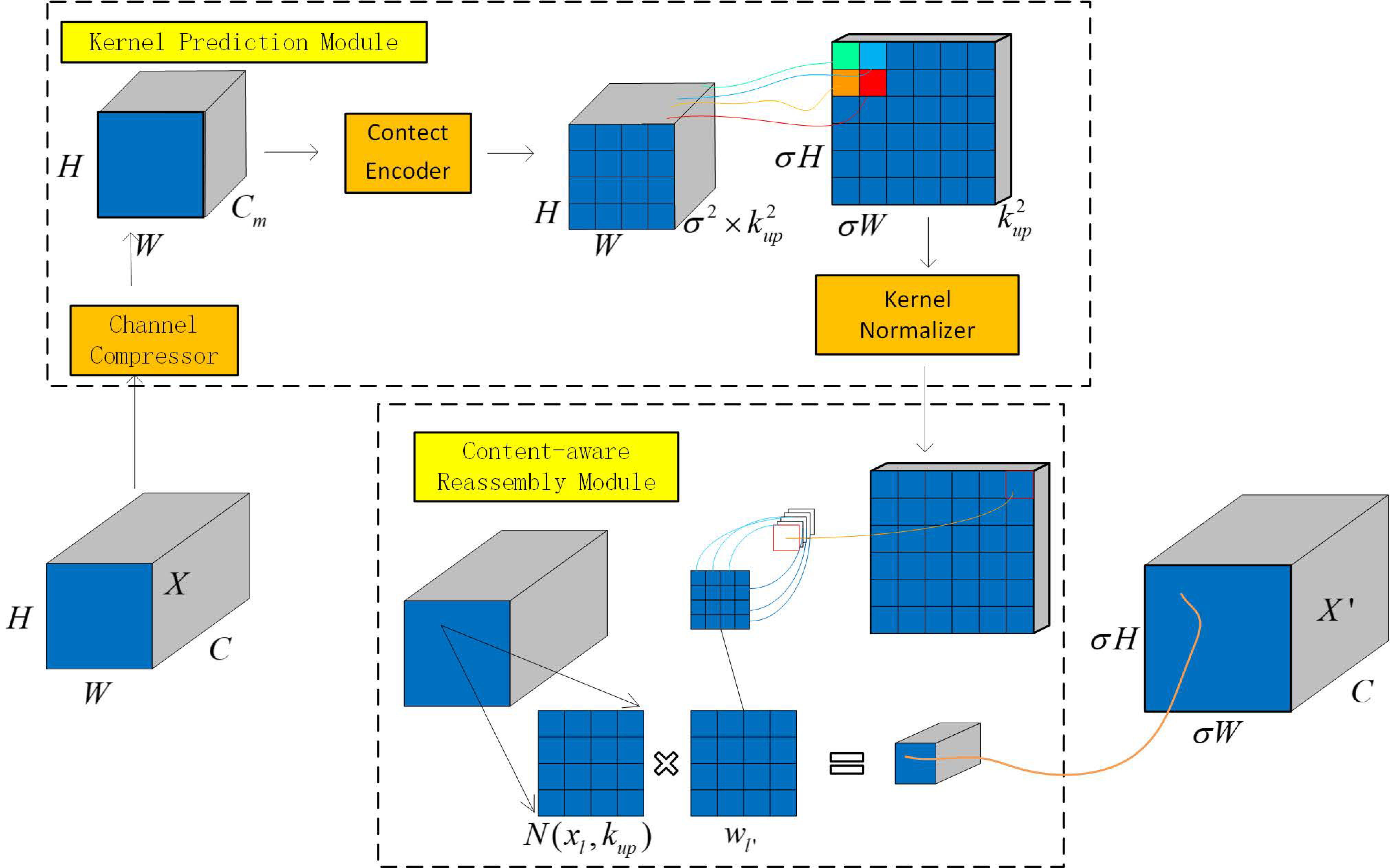
CARAFE stands for content-aware reassembly of features [
28], which is a lightweight and universal upsampling operator that can guide the upsampling process based on the semantic information of the input feature map. Its main strategy is to use a small convolutional network to generate an adaptive upsampling kernel and then to calculate the dot product of the kernel with the corresponding neighboring pixels in the input feature map to obtain the upsampled feature map. Compared with traditional upsampling operators such as nearest-neighbor or bilinear interpolation, CARAFE has a larger receptive field and better semantic adaptability while introducing very few parameters and not substantially increasing the computational cost.
The network structure of CARAFE consists of two parts, as shown in
Figure 8. One part is the kernel prediction module, which is used to generate weights for the kernel used in the reassembly calculation. The other part is the content-aware reassembly module, which is used to reassemble the features with the calculated weights.
In
Figure 8, a feature map X of size
is upsampled σ times using CARAFE. For each position
, a kernel is predicted for recombination. First, the channel compression module compresses the channel to
to reduce subsequent computation and enable the use of larger kernels during upsampling. Then, based on the size of the compressed feature map, a convolutional layer of size
is used to generate the kernel for feature recombination, where using a larger
expands the receptive field, while the channel dimensions become
. The new feature map is then recombined into the feature map of size
, and the softmax function is applied to normalize all channels at each position.
For any position in the output X’, there is a corresponding source position in the input X, where . We let be a subregion of X centered at position . The predicted kernel module predicts the position kernel for each position based on a subregion of , as shown in Equation (5). In Equation (6), the perception recombination module recombines the subregion of with the position kernel to obtain .
In the YOLOv5 network architecture, the introduction of CARAFE enables the dynamic generation of different upsampling kernels at different positions of the input feature map, adapting to targets of different scales and shapes in various instances and scenarios. The resulting upscaled feature map, obtained by calculating the inner product with the local neighborhood of the input feature map, possesses higher resolution and richer detail information, thereby enhancing the ability to recognize and locate different targets in object detection tasks. At the same time, with the introduction of only a small number of parameters and a low computational cost, compared to other upsampling methods, such as nearest-neighbor interpolation and deconvolution, the model has a smaller size and faster running speed, thereby meeting the real-time and efficiency requirements of object detection tasks.
3.5. Loss Function
A loss function is a function used to calculate the difference between predicted values and true values. The smaller the value of the loss function is, the closer the predicted output is to the expected output [
29]. In this study, the applied loss function is divided into three parts: classification loss, localization loss, and confidence loss. The classification loss is used to determine whether the anchor box and corresponding annotated classification are correct and represents the probability of belonging to a certain category. The localization loss is used to predict the error between the predicted box and the annotated box. The confidence loss is used to calculate the network’s confidence. It represents the probability of there being an object and typically has a value between 0 and 1, with larger values indicating a higher probability of there being an object. The overall loss function is a weighted sum of these three loss functions, as expressed in Equation (7):
where
,
, and
are weighting coefficients.
The localization loss
is defined using
as [
30]
where
is the intersection over union between the predicted box and the ground-truth box, with a larger value indicating a closer match;
represents the Euclidean distance between the center-point coordinates of the ground-truth box
and the predicted box
;
represents the diagonal distance of the minimum bounding box enclosing both the predicted box and ground-truth box;
is a weighting coefficient; and
is used to measure the consistency between the aspect ratios of
and
.
is defined as
where
is the ground-truth bounding box,
is the predicted bounding box,
represents the intersection of
and
, and
represents the union of
and
.
and
are defined as follows:
The binary cross-entropy with the logit loss is used for both the classification and confidence losses in this study, which is defined as follows:
where
represents the number of input samples,
represents the target values, and
represents the predicted output values.
5. Conclusions
In response to the complex and varied characteristics of the bearing surface image texture background, uneven brightness, and defects of different sizes and types, this paper proposes a bearing surface defect detection method based on the improved YOLOv5. To improve the speed and accuracy of the YOLOv5 backbone network, the C3 module in the backbone network was replaced with a C2f module, reducing the number of parameters and computational complexity. To enhance the ability to process low-resolution and small-bearing images, the SPD module was added to the backbone network and neck network, and a new CNN module was constructed. To improve the diversity and robustness of the model and adapt it to different instances and scenarios, the nearest-neighbor upsampling method was replaced with the lightweight universal upsampling operator (CARAFE).
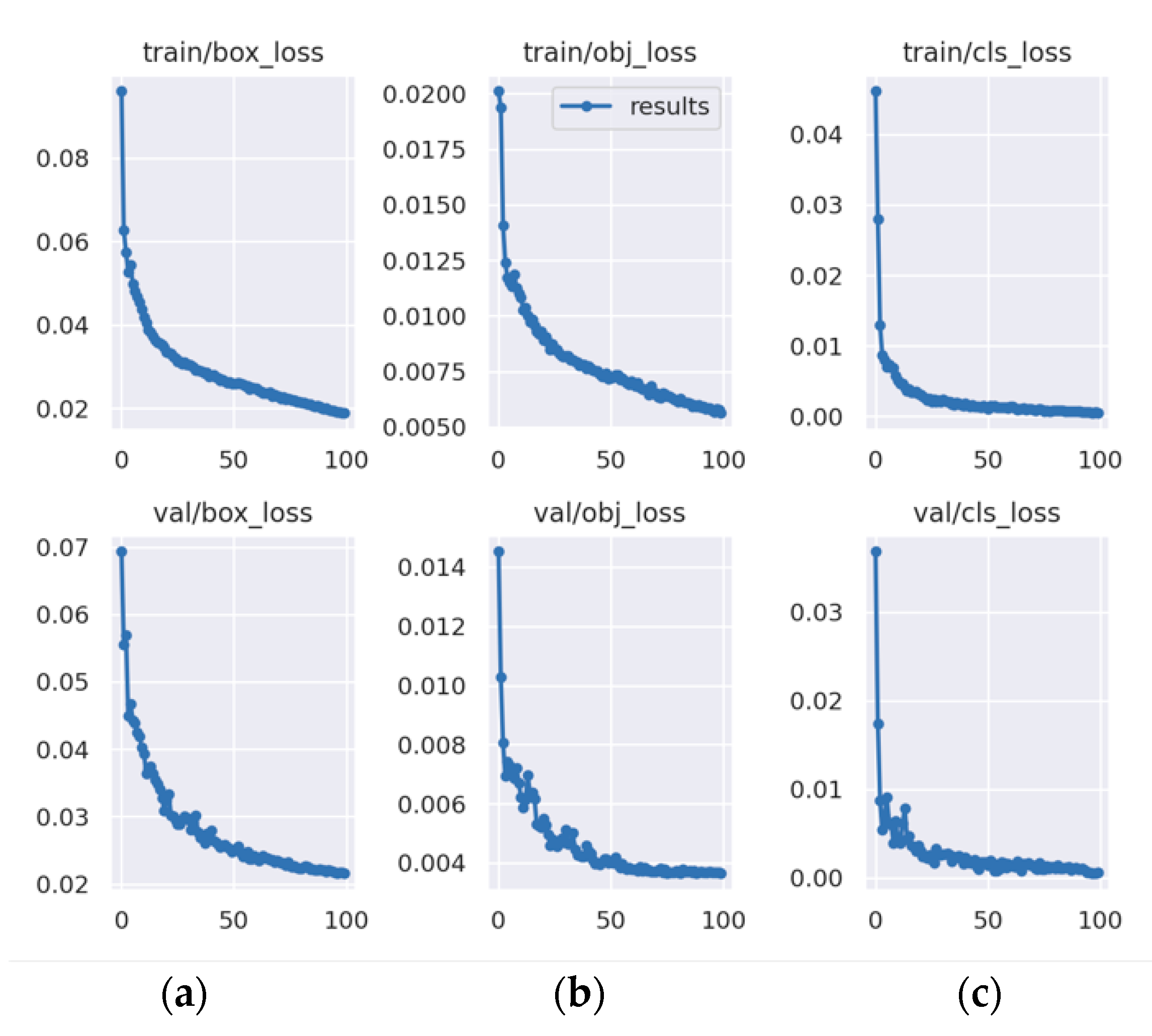
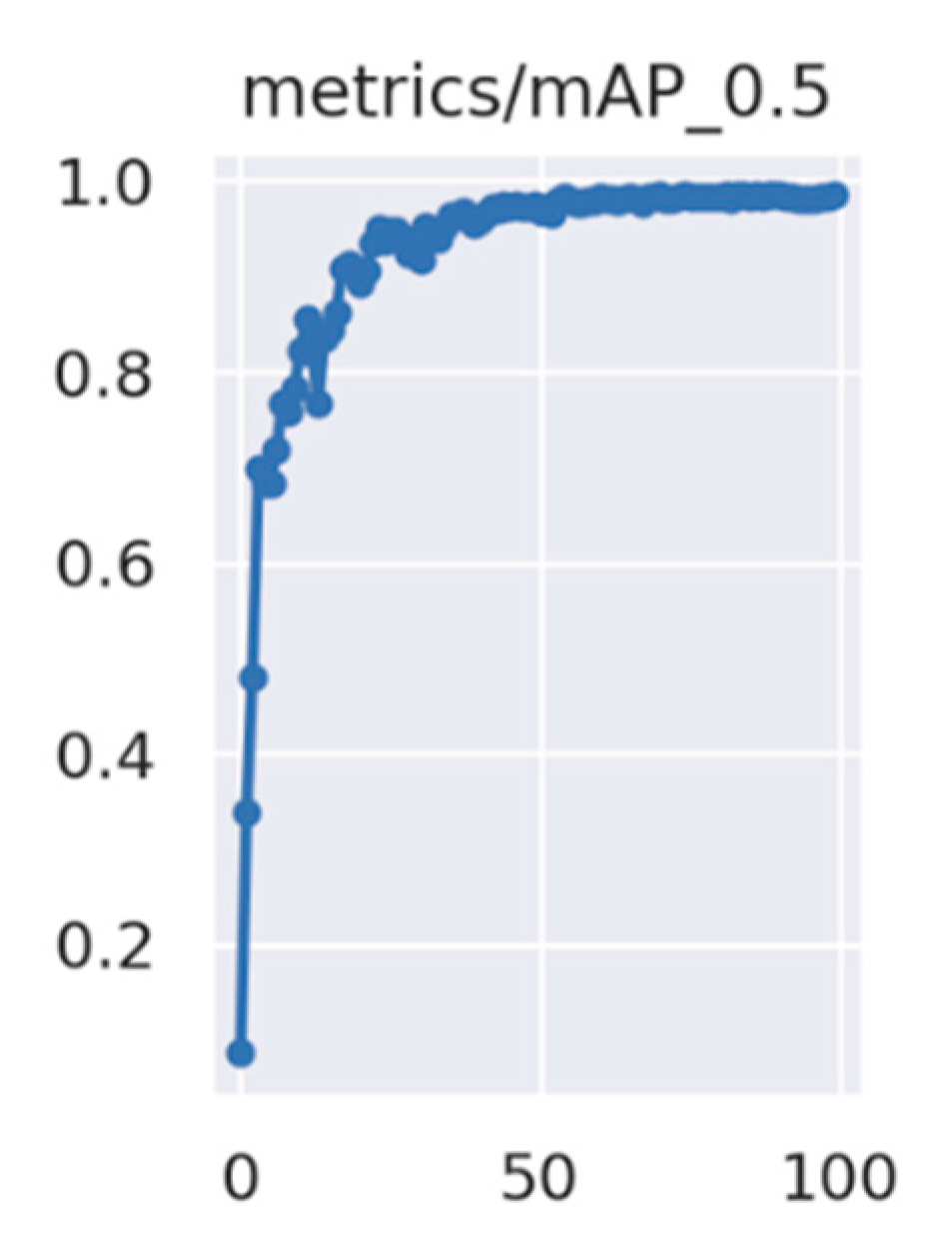
Extensive experiments were conducted on a bearing defect dataset that we produced, and the results demonstrated that the detection accuracy of the defect detection method proposed in this paper reached 97.3%, with an overall average precision improvement of 1.5%, especially for dents and black spot defects improved by 2.2% and 3.9%, respectively, and that the detection speed can reach 100 FPS. An ablation experiment demonstrated the effectiveness of the proposed improvements, and a comparison with other algorithms also demonstrated the superiority of the improved method, meeting industrial inspection requirements. On a fabric dataset, the proposed method also showed improvement, with the mAP of 99%.
The YOLO series of network architectures has good openness, making it easy to introduce new network architectures and modules. In future research, further network optimization can be carried out for fine cracks on bearing surfaces, as well as interferences such as dust and oil stains, to improve the performance of the model.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}