
Cross-Domain Sentiment Analysis Based on Feature Projection and Multi-Source Attention in IoT


Abstract
:1. Introduction
- We propose a method for cross-domain sentiment analysis based on feature projection and multi-source attention (FPMA). The model optimizes the representation of the private and shared features through orthogonal projection, which enables the sentiment to be predicted based on the attention mechanism.
- We suggest a multi-source selection strategy based on the domain discriminator’s selection of the source domains that more closely resemble the text features of the target domain, effectively alleviating the negative transfer problem caused by source domains of low relevance.
- The experimental results of FPMA for both English and Chinese datasets show that the model outperforms the baseline models. We also validated the effectiveness of FPMA through ablation experiments.
2. Related Work
2.1. Domain Adaptation
2.2. Attention Mechanism
2.3. Adversarial Training
3. Proposed Method
3.1. Task Description
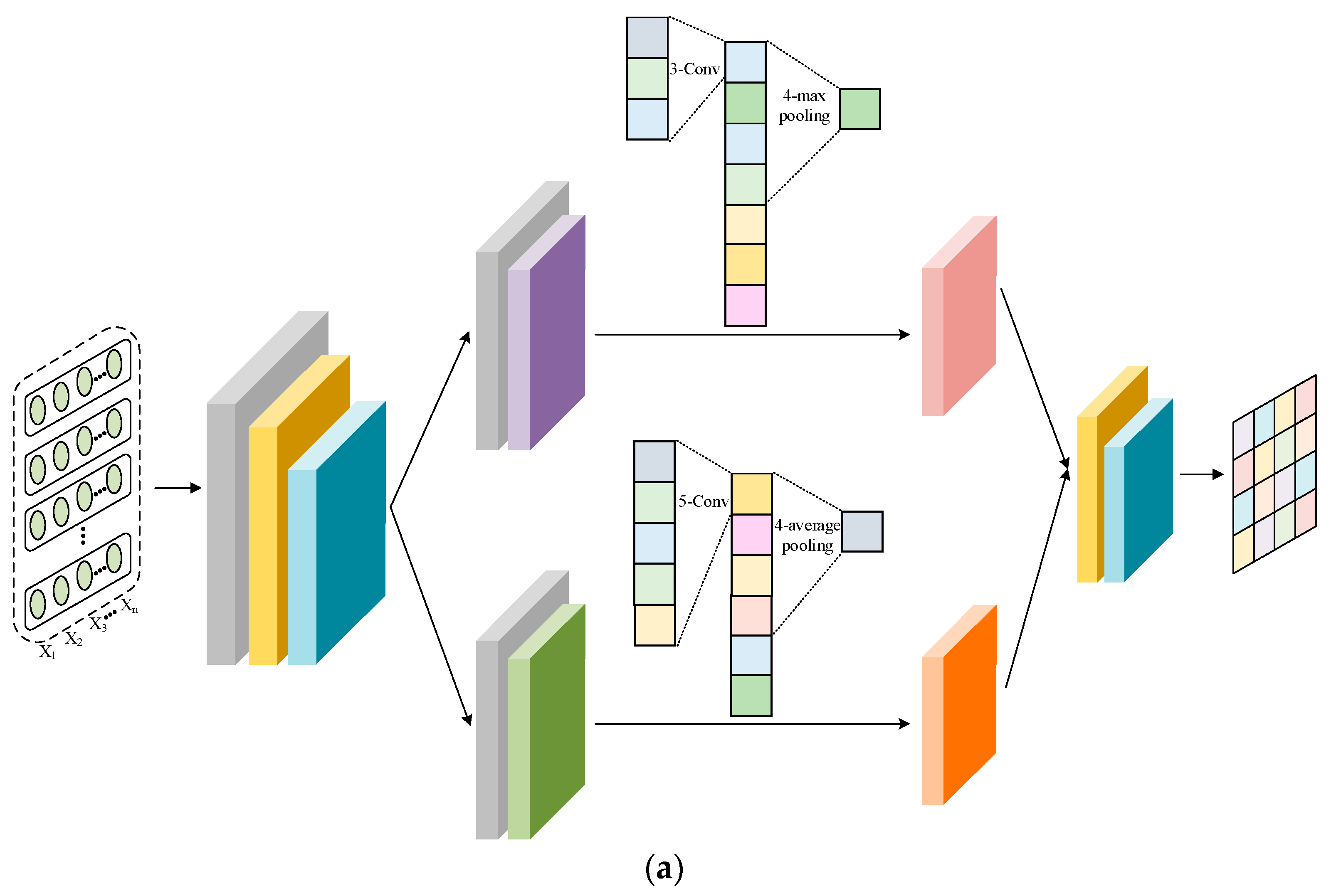
3.2. Framework Overview
3.3. Feature Processing
3.3.1. Feature Extraction
3.3.2. Feature Purification and Refusion
3.4. Multi-Source Classification Training
| Algorithm 1. Module training process |
| Input: samples with sentiment label for the source domains ; samples for the target domain ; samples with domain label for all the domains ; Output: Optimized parameter set ;
|
3.5. Multi-Source Selection Strategy
3.6. Attention-Weighted Prediction
4. Experiments
4.1. Datasets Used in the Experiment
4.2. Experiment Settings
4.3. Baseline Models
- mSDA [41]: marginalizes the noise through a domain adaptation edge denoising self-encoder without using any optimization algorithm to learn the parameters in the model.
- DANN [35]: extracts domain-invariant features via domain adversarial neural networks.
- MDAN(Hard-Max), MDAN(Soft-Max) [36]: two adversarial neural network models; the former optimizes the domain adaptation generalization boundary, and the latter is a smooth approximation of the former.
- MAN [10]: learns invariant features by reducing the difference between the distribution of features in each domain.
- MDAJL [22]: employs a framework with joint learning that uses soft parameter sharing for cross-task information transfer.
- HM-LTS [42]: combines a lexicon-based unsupervised method, a support vector machine-based supervised method, and topic modeling.
- SDA [11]: uses a shared–private structure to transfer knowledge from multi-source domains through two domain adaptation mechanisms.
- BTDNNs [43]: transfers the samples in the source and target domains to each other, constraining the distribution consistency between the transferred and desired domains via linear data reconstruction.
- MDAN [36]: uses domain adversarial neural networks to optimize the domain adaptation generalization boundary.
- WS-UDA [13]: an unsupervised framework based on a weighted scheme; the weight assigned to each source is acquired from the domain discriminator via adversarial training.
- 2ST-UDA [13]: further utilizes the pseudo labels of the target domain to train a target private extractor on the basis of WS-UDA.
- AdEA [23]: utilizes a weighted learning module to strengthen the relationship between domain features.
5. Experimental Results and Analysis
5.1. Main Experimental Results
5.2. Ablation Experiments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xiao, G.; Tu, G.; Zheng, L.; Zhou, T.; Li, X.; Ahmed, S.H.; Jiang, D. Multimodality sentiment analysis in social Internet of things based on hierarchical attentions and CSAT-TCN with MBM network. IEEE Internet Things J. 2020, 8, 12748–12757. [Google Scholar] [CrossRef]
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, K.; Martinez-Hernandez, V.; Meana, H.M.P.; Olivares-Mercado, J.; Sanchez, V. Social Sentiment Sensor in Twitter for Predicting Cyber-Attacks Using ℓ1 Regularization. Sensors 2018, 18, 1380. [Google Scholar] [CrossRef] [PubMed]
- Pereira-Kohatsu, J.C.; Sánchez, L.Q.; Liberatore, F.; Camacho-Collados, M. Detecting and Monitoring Hate Speech in Twitter. Sensors 2019, 19, 4654. [Google Scholar] [CrossRef]
- Sufi, F.K.; Alsulami, M.; Gutub, A. Automating global threat-maps generation via advancements of news sensors and AI. Arab. J. Sci. Eng. 2023, 48, 2455–2472. [Google Scholar] [CrossRef]
- Rahmah, U.; Mustapa, M.; Samad, P.I.; Budiarti, N.A.E. Internet of Things (IoT) in Defense and Security Systems: A Literature Review. Int. J. Sci. Eng. Sci. 2023, 7, 115–118. [Google Scholar]
- Liu, W.; Yang, Y.; Wang, E.; Wang, H.; Wang, Z.; Wu, J. Dynamic online user recruitment with (non-) submodular utility in mobile crowdsensing. IEEE/ACM Trans. Netw. 2021, 29, 2156–2169. [Google Scholar] [CrossRef]
- Zhang, X.; Yue, W.T. Transformative value of the Internet of Things and pricing decisions. Electron. Com. Res. Appl. 2019, 34, 100825. [Google Scholar] [CrossRef]
- Remus, R. Domain adaptation using domain similarity- and domain complexity-based instance selection for cross-domain sentiment analysis. In Proceedings of the 12th International Conference on Data Mining Workshops, Brussels, Belgium, 10 December 2012; pp. 717–723. [Google Scholar] [CrossRef]
- Liu, P.; Qiu, X.; Huang, X. Adversarial multi-task learning for text classification. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, QC, Canada, 30 July–4 August 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Chen, X.; Cardie, C. Multinomial adversarial networks for multi-domain text classification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LO, USA, 1–6 June 2018; pp. 1226–1240. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, J.; Zhang, J.; Fu, H.; Xu, Z. Unsupervised sentiment analysis by transferring multi-source knowledge. Cogn. Comput. 2021, 13, 1185–1197. [Google Scholar] [CrossRef]
- Chattopadhyay, R.; Sun, Q.; Fan, W.; Davidson, I.; Panchanathan, S.; Ye, J. Multisource domain adaptation and its application to early detection of fatigue. ACM Trans. Knowl. Discov. Data 2012, 6, 18. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, J.; Ren, X.; Xu, Z. Adversarial training based multi-source unsupervised domain adaptation for sentiment analysis. AAAI 2020, 34, 7618–7625. [Google Scholar] [CrossRef]
- Fu, Y.; Liu, Y. Contrastive transformer based domain adaptation for multi-source cross-domain sentiment classification. Knowl. Based Syst. 2022, 245, 108649. [Google Scholar] [CrossRef]
- Tang, H.; Mi, Y.; Xue, F.; Cao, Y. Graph domain adversarial transfer network for cross-domain sentiment classification. IEEE Access 2021, 9, 33051–33060. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Dredze, M.; Crammer, K. Online methods for multi-domain learning and adaptation. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 689–697. [Google Scholar] [CrossRef]
- Ghifary, M.; Kleijn, W.B.; Zhang, M. Domain adaptive neural networks for object recognition. In Proceedings of the PRICAI 2014: Trends in Artificial. Intelligence: 13th Pacific Rim International Conference on Artificial Intelligence, Gold Coast, QLD, Australia, 1–5 December 2014; Volume 13, pp. 898–904. [Google Scholar]
- Rozantsev, A.; Salzmann, M.; Fua, P. Beyond sharing weights for deep domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 801–814. [Google Scholar] [CrossRef]
- Xue, Q.; Zhang, W.; Zha, H. Improving domain-adapted sentiment classification by deep adversarial mutual learning. AAAI 2020, 34, 9362–9369. [Google Scholar] [CrossRef]
- Guo, J.; Shah, D.J.; Barzilay, R. Multi-source domain adaptation with mixture of experts. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4694–4703. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, S.; Li, D. Multi-source domain adaptation with joint learning for cross-domain sentiment classification. Knowl. Based Syst. 2020, 191, 105254. [Google Scholar] [CrossRef]
- Li, Q.; Wang, G.; Yang, G. Big data based transfer learning for sentiment classification with multiple source domains. In Proceedings of the 3rd International Conference on Big Data and Informatization Education (ICBDIE 2022), Beijing, China, 8–10 April 2022; Volume 2022, pp. 256–265. [Google Scholar]
- Zhang, J.; Zhou, W.; Chen, X.; Yao, W.; Cao, L. Multisource selective transfer framework in multiobjective optimization problems. IEEE Trans. Evol. Comput. 2020, 24, 424–438. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Zhao, C.; Wang, S.; Li, D.; Liu, X.; Yang, X.; Liu, J. Cross-domain sentiment classification via parameter transferring and attention sharing mechanism. Inf. Sci. 2021, 578, 281–296. [Google Scholar] [CrossRef]
- Ji, J.; Luo, C.; Chen, X.; Yu, L.; Li, P. Cross-domain sentiment classification via a bifurcated-LSTM. In Advances in Knowledge Discovery and Data Mining, Proceedings of the 22nd Pacific-Asia Conference, PAKDD 2018: Part I, Melbourne, Australia, 15–18 May 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 22, pp. 681–693. [Google Scholar]
- Gan, C.; Feng, Q.; Zhang, Z. Scalable multi-channel dilated CNN–BiLSTM model with attention mechanism for Chinese textual sentiment analysis. Future Gener. Comput. Syst. 2021, 118, 297–309. [Google Scholar] [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Dai, K.; Li, X.; Huang, X.; Ye, Y. SentATN: Learning sentence transferable embeddings for cross-domain sentiment classification. Appl. Intell. 2022, 52, 18101–18114. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, J.; Ren, Y.; Yang, Z. Chinese sentiment analysis of online education and Internet buzzwords based on BERT. J. Phys. Conf. Ser. 2020, 1631, 012034. [Google Scholar] [CrossRef]
- Areshey, A.; Mathkour, H. Transfer learning for sentiment classification using bidirectional encoder representations from transformers (BERT) model. Sensors 2023, 23, 5232. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Zhao, H.; Zhang, S.; Wu, G.; Costeira, J.; Moura, J.; Gordon, G. Multiple source domain adaptation with adversarial learning. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wu, Y.; Guo, Y. Dual adversarial co-learning for multi-domain text classification. AAAI 2020, 34, 6438–6445. [Google Scholar] [CrossRef]
- Wu, Y.; Inkpen, D.; El-Roby, A. Co-regularized adversarial learning for multi-domain text classification. In Proceedings of the 25th International Conference on Artificial Intelligence and Statistics, Virtual, 28–30 March 2022; Volume 151, pp. 6690–6701. [Google Scholar]
- Qin, Q.; Hu, W.; Liu, B. Feature projection for improved text classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8161–8171. [Google Scholar] [CrossRef]
- Blitzer, J.; Dredze, M.; Pereira, F. Biographies, Bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 440–447. [Google Scholar]
- Chen, M.; Xu, Z.; Weinberger, K.; Sha, F. Marginalized denoising autoencoders for domain adaptation. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012. [Google Scholar]
- Kalra, V.; Agrawal, R.; Sharma, S. Domain adaptable model for sentiment analysis. Mechatron. Syst. Control 2022, 2, 50. [Google Scholar]
- Zhou, G.; Xie, Z.; Huang, J.X.; He, T. Bi-transferring deep neural networks for domain adaptation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 322–332. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Review | Sentiment |
|---|---|---|
| Book | The book is rich in content and has a high cost–performance ratio. | positive |
| Electronics | The mobile phone offers a high cost–performance ratio, comprehensive functions, and a long standby time. | positive |
| Symbols | Definitions |
|---|---|
| -th text in the -th source domain | |
| sentiment label of the -th text in the -th source domain | |
| number of samples in the -th source domain | |
| -th text in the target domain | |
| number of samples in the target domain | |
| domain label corresponding to the -th text |
| Categories | Positive Samples | Negative Samples | Unlabeled Data |
|---|---|---|---|
| Book | 1000 | 1000 | 4465 |
| DVD | 1000 | 1000 | 3586 |
| Electronics | 1000 | 1000 | 5681 |
| Kitchen | 1000 | 1000 | 5945 |
| Categories | Positive Samples | Negative Samples |
|---|---|---|
| Books | 2100 | 1751 |
| Tablets | 5000 | 5000 |
| Mobile phones | 1165 | 1158 |
| Fruit | 5000 | 5000 |
| Shampoo | 5000 | 5000 |
| Water heaters | 475 | 100 |
| Mengniu | 992 | 1041 |
| Clothes | 5000 | 5000 |
| Computers | 1996 | 1996 |
| Hotels | 5000 | 5000 |
| Target Domain | Book | DVD | Electronics | Kitchen | Average |
|---|---|---|---|---|---|
| mSDA [41] | 76.98 | 78.61 | 81.98 | 84.26 | 80.46 |
| DANN [35] | 77.89 | 78.86 | 84.91 | 86.39 | 82.01 |
| MDAN (Hard-Max) [36] | 78.45 | 77.97 | 84.83 | 85.80 | 81.76 |
| MDAN (Soft-Max) [36] | 78.63 | 80.65 | 85.34 | 86.26 | 82.72 |
| MAN-L2 [10] | 78.45 | 81.57 | 83.37 | 85.57 | 82.24 |
| MAN-NLL [10] | 77.78 | 82.74 | 83.75 | 86.41 | 82.67 |
| MDAJL [22] | 78.80 | 80.20 | 81.20 | 54.30 | 73.60 |
| HM-LTS [42] | 74.00 | 76.00 | 79.00 | 80.00 | 77.25 |
| SDA [11] | 78.68 | 81.23 | 85.06 | 87.33 | 83.08 |
| FPMA | 80.07 | 82.81 | 85.96 | 87.35 | 84.05 |
| Target Domain | Books | Tablets | Mobile Phones | Fruit | Shampoo | Mengniu | Clothes | Computers | Hotels | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| BTDNNs [43] | 78.2 | 85.6 | 82.1 | 87.5 | 88.1 | 73.9 | 91.4 | 80.3 | 78.7 | 82.9 |
| MDAN [36] | 78.4 | 86.8 | 81.4 | 87.3 | 87.9 | 73.8 | 91.5 | 79.4 | 80.7 | 83 |
| WS-UDA [13] | 77.7 | 90 | 87 | 89.9 | 91.7 | 76.6 | 94.5 | 81.1 | 82.9 | 85.7 |
| 2ST-UDA [13] | 82.2 | 89.9 | 82.7 | 89.5 | 91.4 | 80.3 | 94.1 | 76.9 | 82.4 | 85.5 |
| AdEA [23] | 82 | 90.6 | 88.1 | 90.2 | 92.4 | 76.6 | 94.4 | 82.1 | 84.3 | 86.8 |
| FPMA | 76.6 | 92.2 | 93.1 | 90.4 | 92.8 | 82.9 | 94.8 | 89.4 | 83.6 | 88.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, Y.; Xu, Z.; Mei, M. Cross-Domain Sentiment Analysis Based on Feature Projection and Multi-Source Attention in IoT. Sensors 2023, 23, 7282. https://doi.org/10.3390/s23167282
Kong Y, Xu Z, Mei M. Cross-Domain Sentiment Analysis Based on Feature Projection and Multi-Source Attention in IoT. Sensors. 2023; 23(16):7282. https://doi.org/10.3390/s23167282
Chicago/Turabian StyleKong, Yeqiu, Zhongwei Xu, and Meng Mei. 2023. "Cross-Domain Sentiment Analysis Based on Feature Projection and Multi-Source Attention in IoT" Sensors 23, no. 16: 7282. https://doi.org/10.3390/s23167282