1. Introduction
Over the past few decades, agriculture has emerged as the primary source of income for several countries, significantly contributing to the global economy. As per the World Bank report of 2018, agriculture engaged over a billion population, representing 28.5% of the total labor force, and amounted to about 10 million tons of food a day [
1]. Although, the total potential of agriculture is prone to plant infections and diseases, food security is compromised by such infections. Major food crops, such as rice, wheat, potatoes, soybeans and maize can suffer losses of 10% to 40% due to plant viruses [
2]. Addressing these challenges necessitates frequent inspection of disease symptoms, often inefficient and time consuming, particularly for huge crop fields. In order to achieve precision agriculture, plant infections must be detected effectively. Research groups have been motivated to work on Machine Learning (ML) as a result of the proliferation of this field to explore its potential in automating the detection of plant diseases by analyzing images obtained from fields. To identify diseases, these groups analyze the images and extract significant features. For example, in Ref. [
3], Support Vector Machine (SVM) was applied after extracting image features using Scale Invariant Feature Transform (SIFT) to classify guava leaf diseases. Before applying SVM, Ref. [
4] used a Statistical Gray Level Co-occurrence Matrix instead of SIFT. A variety of feature extraction methods have been utilized by other studies to analyze plant diseases in order to achieve remarkable results, including [
5,
6,
7,
8].
To handle fiddly data designs and stupendous training data, some researchers used the k-Nearest Neighbors (k-NN) classifier instead of SVM. It was possible to classify Cotton Grey Mildew disease based on local statistical input features and k-NN in [
9]. There has also been use of the k-NN algorithm in [
10] for classifying paddy leaves and [
11] for classifying groundnut leaf diseases. However, every approach requires multiple steps in order to prepare the data for preprocessing and feature extraction. There is also no evidence that they are effective at classifying more than one class of data and that they are sensitive to predefined parameters, such as the kernel parameter k in SVM and the kernel parameter f in K-NN [
12]. To address these issues, some researchers have turned to Deep Learning (DL) methods for improved crop infection and disease detection. The authors in [
13] created a DL-based system called PlantVillage (PV), which can accurately identify 26 different plant diseases. In contrast to explicit feature extraction techniques, DL techniques automatically learn and extract relevant features from the input images. However, traditional ANN classifiers lose spatial information when converting 2D images to 1D vectors for classification, leading to increased computational complexity and storage requirements. The article in [
14] describes a method for defining diseases of plants based on a new dataset called DRLI.
Agricultural applications of neural networks, specifically convolutional neural networks (CNNs), have proven successful in overcoming previous limitations with Deep Neural Networks (DNNs) [
15]. For example, Ref. [
16] used the MaskRCNN model with transfer learning to detect fusarium head blight disease in wheat, achieving an average accuracy of 92.01% on the intended test data, which included around 450 images. In a similar manner, a process was applied to analyze [
17] and identify apple leaf diseases with 77.65%, 75.59% and 73.50% recognition accuracy using ResNet152, Inception V3 and MobileNet models. According to [
18], the authors proposed using the PV dataset to generate a custom DCNN to classify cucumber infections that performed up to 94% accurately, using a pretrained AlexNet model. In [
19], the authors developed a Custom-Net model for classifying pearl millet diseases using Raspberry Pi (RPi), achieving an accuracy of 98.78%. Additionally, DL models have been applied to detect further leaf infections, mostly established on the PV dataset. According to the mentioned methods, the accuracy of classification has been high, especially in the case of tomato leaf diseases, which obtained 97.49% results in [
20], and with banana leaf diseases, which obtained 99.72% results in [
21].
Moreover, AI models and ML techniques have been deployed on drones, which are unmanned aerial vehicles used to mitigate various malicious factors in agriculture, including lack of rain, nutrition abnormalities, infections, weeds and pests. Precision agriculture uses drones widely because they are affordable, have an extensive range of operation and are AI-compatible, according to [
22]. Based on the IoT architecture used by [
23], the researchers equipped a drone with an RPi 4 to classify plant infections early in crop production by using the IoT. As reported in [
24], a drone-based fidelity farming apparatus is being used to detect affected areas in open-field tomato crops using algorithmic neural networks. Depending on the level of infection, precise pesticides could be sprayed on afflicted areas. In a similar way, the [
25] project constructed an automated system to detect and spray chemicals on infected plants by combining high-quality cameras with disease detection models based on ResNet architecture.
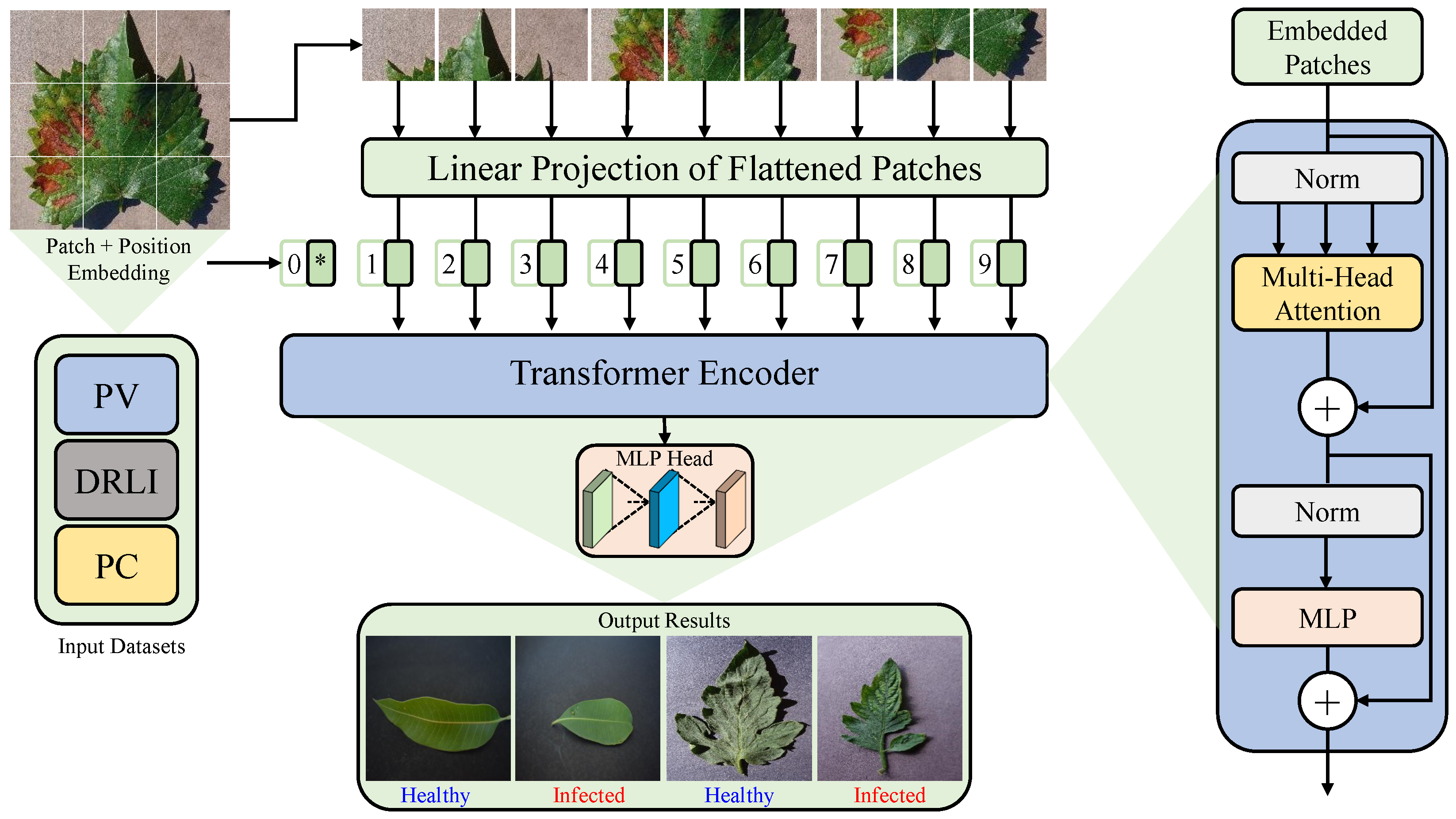
While SOTA DL models can achieve high-performance results and are suitable for use with drones, they require significant computational resources for training. In contrast, ViT which avoids CNN and has similar performance to SOTA CNN models, is a promising alternative [
26]. As a derivative of Transformer, ViT employs a self-attention mechanism that determines a global reference pixel-by-pixel during training. Each given image is split into equal patches and each patch is embedded with its position. After learning from patches, the self-attention block can accurately represent them for vision tasks. In the last layers of the ViT model, the cosine similarity between patch representations increases significantly, suggesting that increasing the layers does not enhance model performance [
27]. The memory requirements of ViT make handling high-resolution images difficult due to their four times length requirement.
Several studies have aimed to overcome the limitations of Transformer-based models, and in general, it falls into two categories: hybrid models and pure-Transformer enhancement. Hybrid models combine the strengths of CNN and Transformer to improve performance. A model based on CNN called Ghost-Enlightened Transformer, for example, was proposed by [
28] to construct intermediate feature maps. In the next step, the self-attention mechanism is used to convert those maps into deep semantic features. Based on 12,615 images collected by the author, this model achieved 98.14% accuracy. A similar system is outlined in [
29]. As is PlantXViT, it incorporates a VGG16 network, a transmission block and an encoder layer called Transformer. The VGG16 and inception block provide better capture of local image features than SOTA CNN models currently available. Furthermore, multiple studies have incorporated CNN layers into Transformer architectures to amplify the capability of extraction of most prominent features [
30,
31,
32]. As a result of this approach, the model becomes more accurate because it is able to learn local features through the CNN architecture, but the training and inference times are significantly extended and the memory used is huge.
In contrast, pure-Transformer enhancement variants operate primarily based on optimizing the self-attention mechanism to improve performance. Based on shifted windows, the Swin Transformer, for example, calculates local attention efficiently while maintaining connections across windows [
33]. Additionally, Ref. [
34] developed k-NN attention, which determines the attention matrix based on the top-k related tokens found in the keys, thereby reducing training time. In RegionViT, local self-attention is employed to retain global information through a regional-to-local concept [
35]. Several studies have also proposed modifying the self-attention mechanism by using feature channels instead of tokens in the calculation of the self-attention matrix [
36] and revamping the spatial attention mechanism to include small-distance, large-distance and all-inclusive information [
37]. It involves optimizing the attention matrix calculation process in order to decrease the model’s complexity while maintaining the global connection. There are, however, some studies that maintain the original architecture of the self-attention mechanism, leading to a huge number of trainable parameters in each self-attention head in comparison with previous studies. Thus, existing Transformer-based models retain their complexity while being larger. Transformer-based models have these limitations, which hinder their application to intelligent edge applications, such as drones and single-board computers, where resources are limited. We designed the models so that they could be deployed and operated on products that have limited resources, with the aim of minimizing transmission latency and network bandwidth consumption [
38]. In summary, this study made the following contributions:
Plant disease detection is now significantly improved using CNN-based models, based on the latest research findings. However, the particular models exhibit limitations such as translation invariance, locality sensitivity and a lack of global image comprehension. To address these shortcomings inherent in CNN-based approaches, this study introduces a new approach utilizing a Vision Transformer-based model for improved and effective plant disease classification.
Drawing inspiration from the Vision Transformer (ViT) proposed by Alexey Dosovitskiy et al. [
26], we conducted training and fine-tuning of the ViT model, specifically for fire detection, resulting in notable advancements surpassing the SOTA CNN models. By improving the architecture of the ViT model, it has been possible to reduce the number of learning parameters from 85 million to 21.65 million as a result of the fine-tuning process, which has resulted in an increase in the accuracy of the model at the same time.
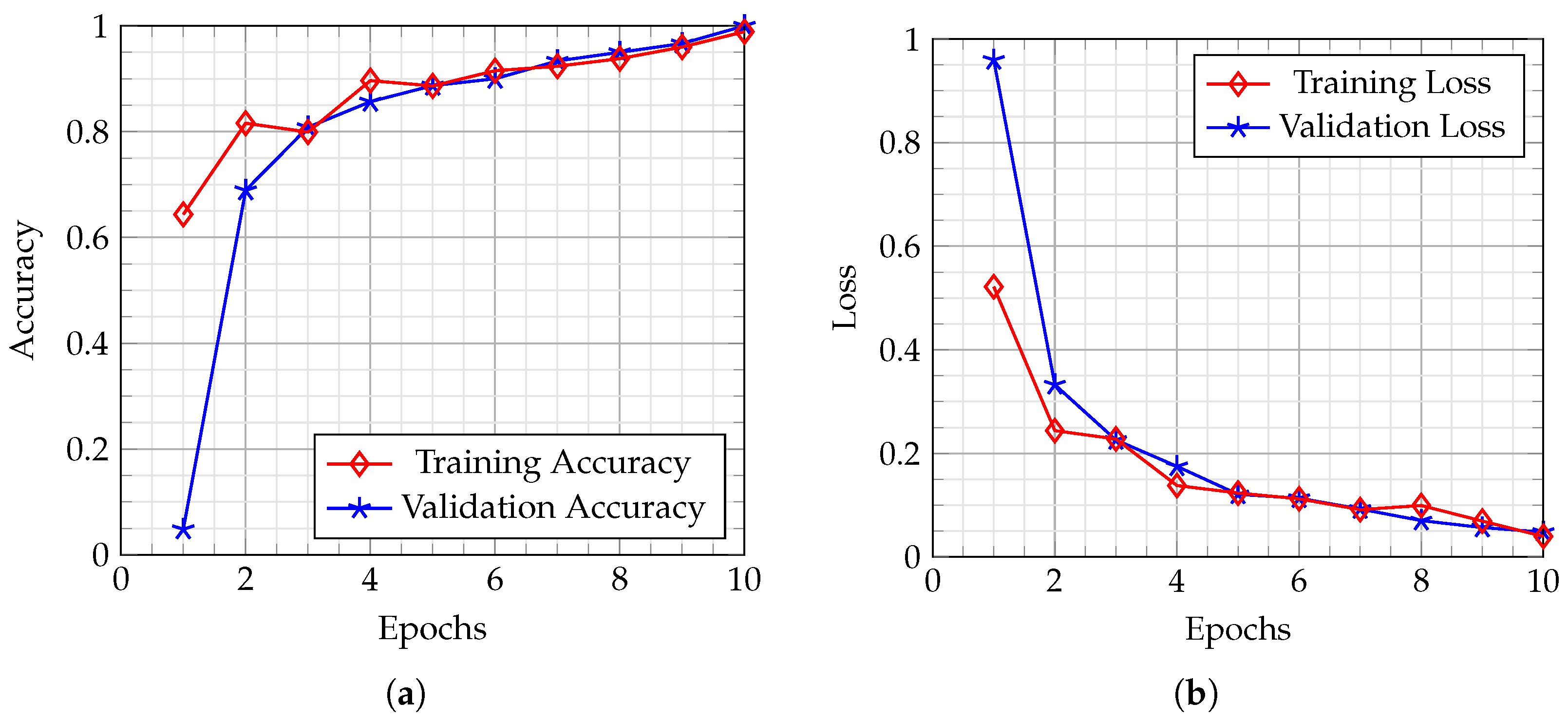
The proposed GreenViT model exhibits exceptional accuracy and effectively reduced the occurrence of false alarms. Consequently, the developed system proves to be highly suitable for accurate plant disease detection, ultimately mitigating the risks associated with food scarcity and security.
This paper is further divided into the following sections: In
Section 2, the proposed methodology is presented, outlining the key steps and techniques employed in the study.
Section 3 provides a brief description of the experimental results obtained from the conducted experiments. Finally, in
Section 4, the paper is concluded, summarizing the main findings, contributions and prospective approach for future work.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}