
IoT-Enabled Few-Shot Image Generation for Power Scene Defect Detection Based on Self-Attention and Global–Local Fusion

Abstract
:1. Introduction
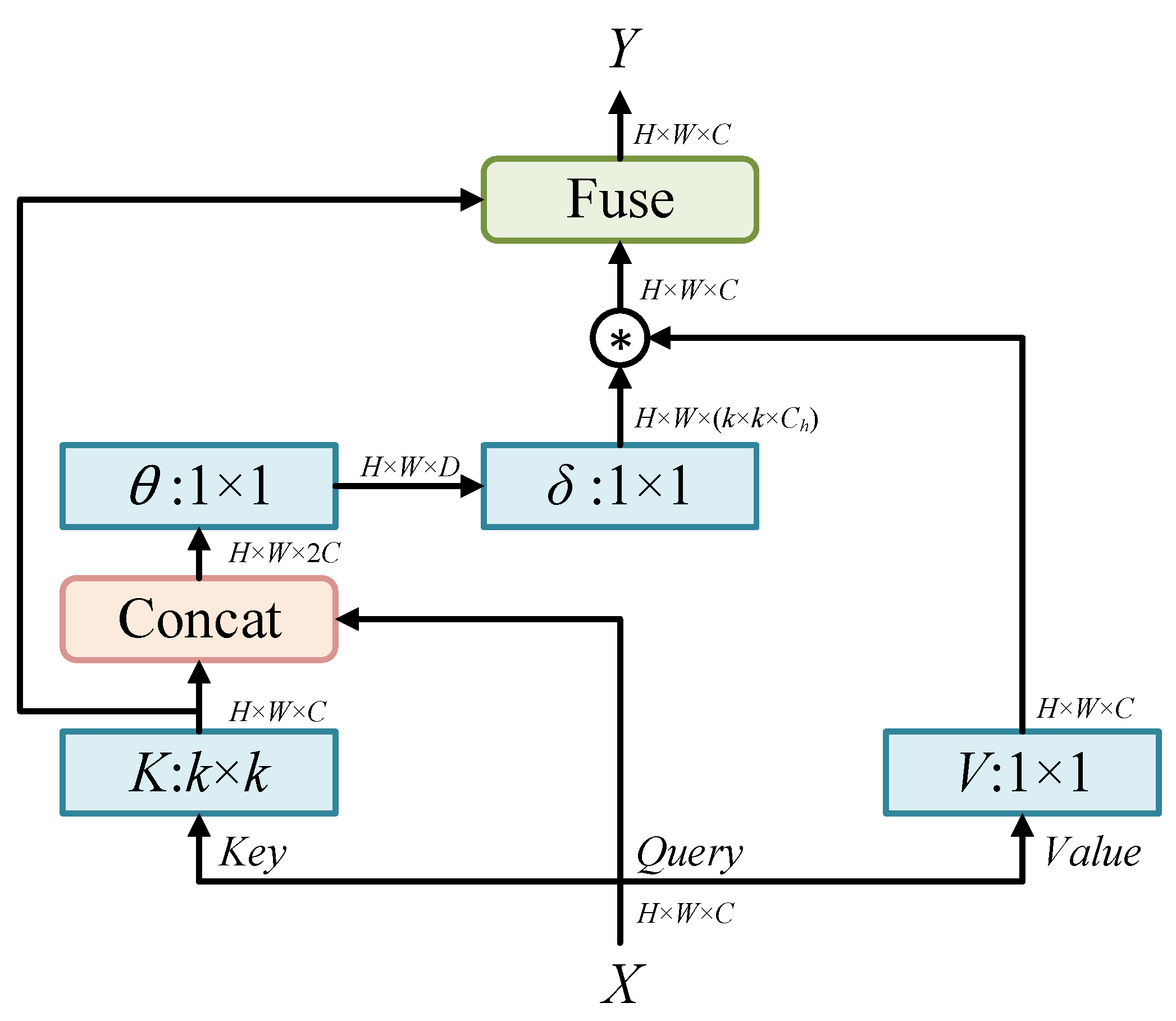
- A self-attention encoder (SAEncoder) is designed to help improve the quality of generated images via a more robust encoding of input images. By leveraging the self-attention mechanism, the encoder can effectively capture high-level features and contextual information of the input image, which can then be utilized to guide the image generation process.
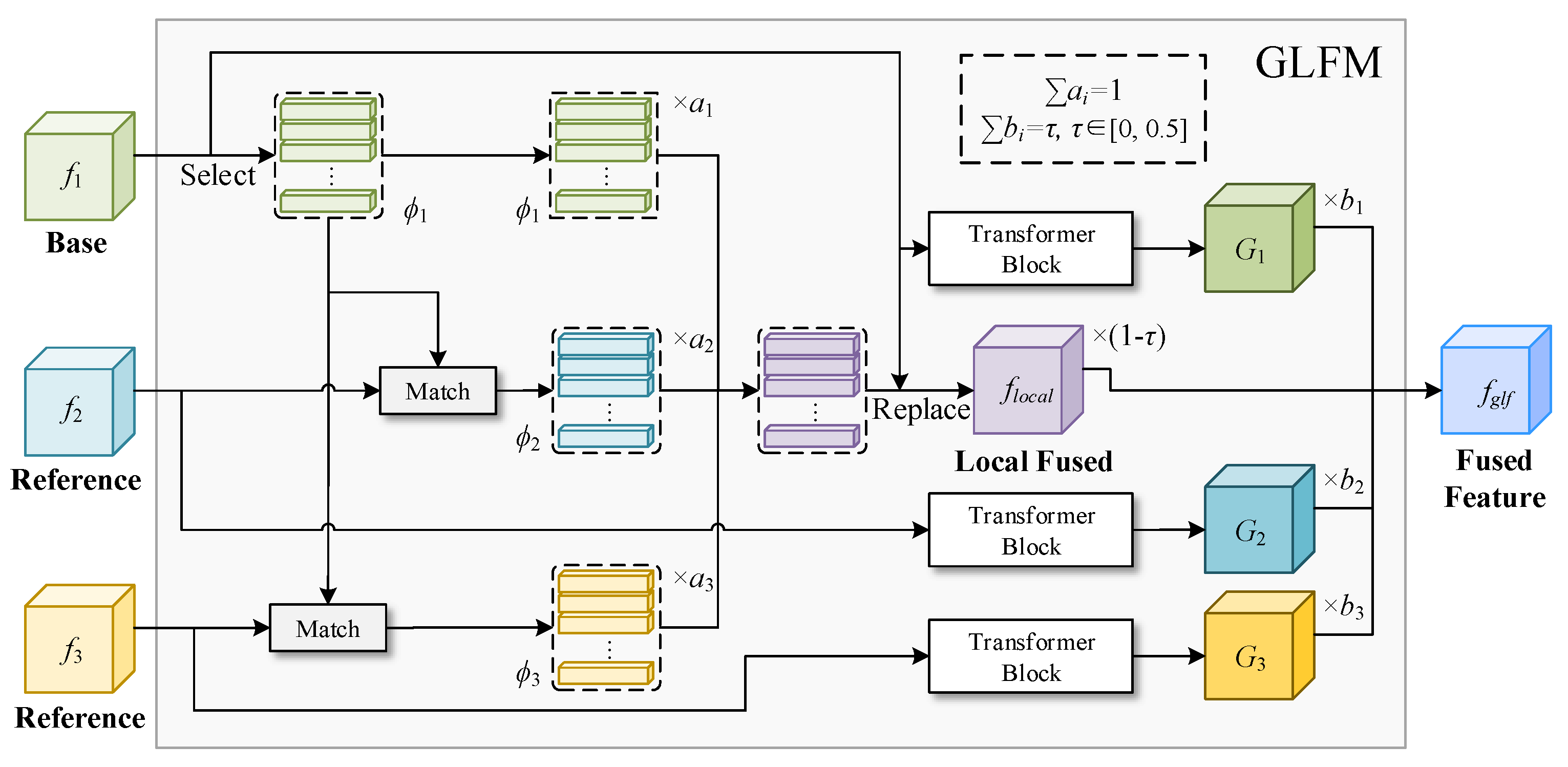
- A global–local fusion module (GLFM) is designed to enhance the quality, diversity, and realism of generated images. By capturing both global and local features of input images, the GLFM can effectively guide the image generation process, enabling the creation of high-quality images with improved visual fidelity.
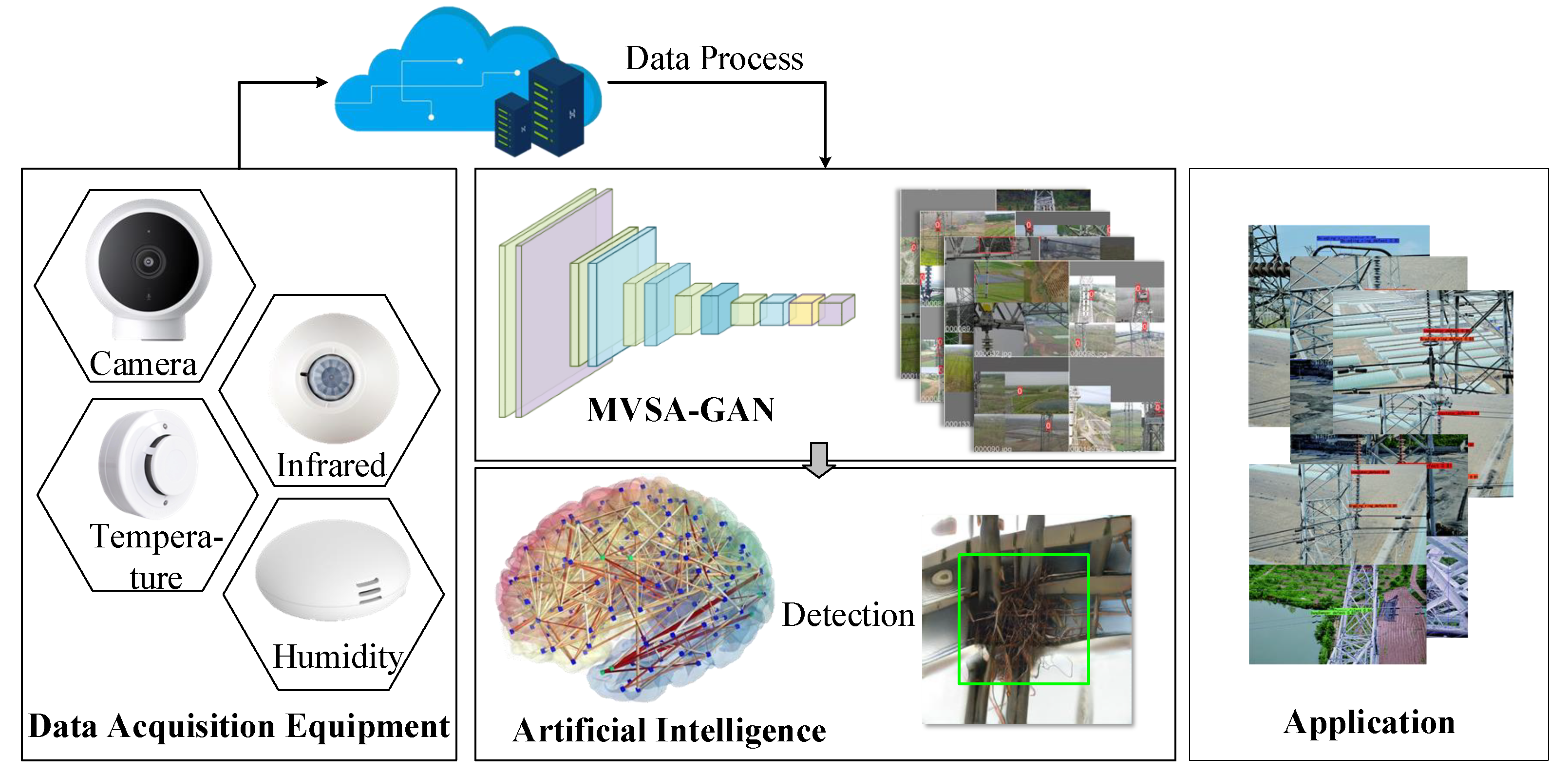
- Our study addresses the challenges of defect detection in electric power scenes by proposing a novel few-shot image generation network that leverages the self-attention mechanism and multi-view fusion, named MVSA-GAN. Specifically, our proposed network is designed to generate high-quality images with clear defect positions and diverse backgrounds, even when the available power defect scene data are limited.
2. Related Works
2.1. Generative Adversarial Networks
2.2. Few-Shot Image Generation
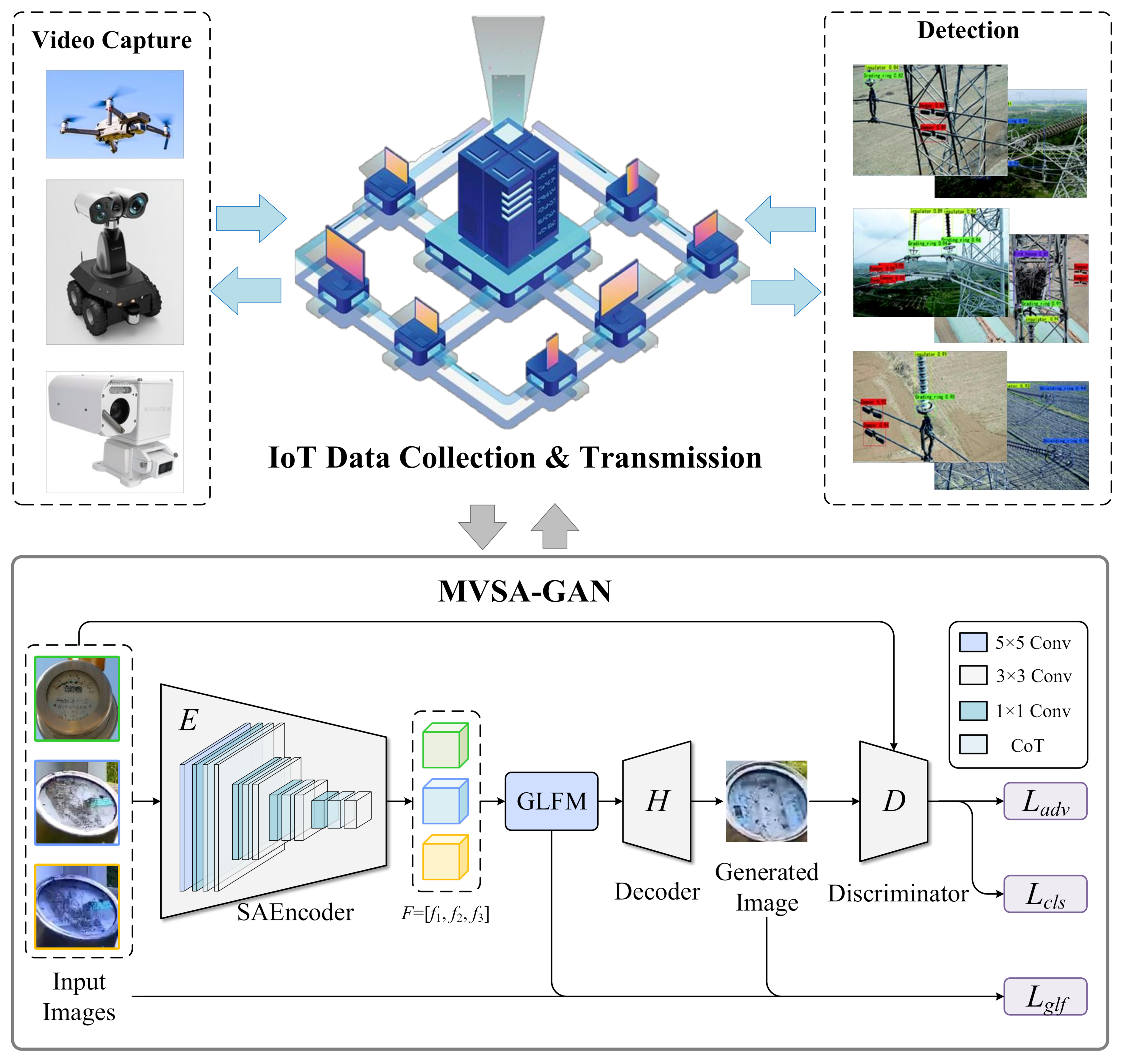
3. MVSA-GAN
3.1. Overall Framework
3.2. SAEncoder
3.3. Global and Local Fusion Module
4. Experiments
4.1. Datasets
4.2. Experiment Details
4.3. Evaluation Metrics
4.4. Evaluation Results
4.5. Ablation Experiment
4.6. Downstream Tasks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohamad Noor, M.B.; Hassan, W.H. Current research on Internet of Things (IoT) security: A survey. Comput. Netw. 2019, 148, 283–294. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, G.; He, W.; Fan, F.; Ye, X. Key target and defect detection of high-voltage power transmission lines with deep learning. Int. J. Electr. Power Energy Syst. 2022, 142, 108277. [Google Scholar] [CrossRef]
- Tao, X.; Zhang, D.; Wang, Z.; Liu, X.; Zhang, H.; Xu, D. Detection of Power Line Insulator Defects Using Aerial Images Analyzed With Convolutional Neural Networks. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 1486–1498. [Google Scholar] [CrossRef]
- Zhao, H.; Dai, R.; Xiao, C. A Machine Vision System for Stacked Substrates Counting With a Robust Stripe Detection Algorithm. IEEE Trans. Syst. Man, Cybern. Syst. 2019, 49, 2352–2361. [Google Scholar] [CrossRef]
- Tsai, D.M.; Wu, S.C.; Chiu, W.Y. Defect Detection in Solar Modules Using ICA Basis Images. IEEE Trans. Ind. Inform. 2013, 9, 122–131. [Google Scholar] [CrossRef]
- Velichko, A.; Korzun, D.; Meigal, A. Artificial Neural Networks for IoT-Enabled Smart Applications: Recent Trends. Sensors 2023, 23, 4853. [Google Scholar] [CrossRef]
- Weerasinghe, S.; Zaslavsky, A.; Loke, S.W.; Hassani, A.; Medvedev, A.; Abken, A. Adaptive Context Caching for IoT-Based Applications: A Reinforcement Learning Approach. Sensors 2023, 23, 4767. [Google Scholar] [CrossRef]
- Xiao, L.; Wan, X.; Lu, X.; Zhang, Y.; Wu, D. IoT Security Techniques Based on Machine Learning: How Do IoT Devices Use AI to Enhance Security? IEEE Signal Process. Mag. 2018, 35, 41–49. [Google Scholar] [CrossRef]
- Dong, Z.; He, Y.; Hu, X.; Qi, D.; Duan, S. Flexible memristor-based LUC and its network integration for Boolean logic implementation. IET Nanodielectr. 2019, 2, 61–69. [Google Scholar] [CrossRef]
- Zhang, Z.; Dong, Z.; Lin, H.; He, Z.; Wang, M.; He, Y.; Gao, X.; Gao, M. An improved bidirectional gated recurrent unit method for accurate state-of-charge estimation. IEEE Access 2021, 9, 11252–11263. [Google Scholar] [CrossRef]
- Davari, N.; Akbarizadeh, G.; Mashhour, E. Corona Detection and Power Equipment Classification Based on GoogleNet-AlexNet: An Accurate and Intelligent Defect Detection Model Based on Deep Learning for Power Distribution Lines. IEEE Trans. Power Deliv. 2022, 37, 2766–2774. [Google Scholar] [CrossRef]
- Geng, Z.; Shi, C.; Han, Y. Intelligent Small Sample Defect Detection of Water Walls in Power Plants Using Novel Deep Learning Integrating Deep Convolutional GAN. IEEE Trans. Ind. Inform. 2022, 19, 7489–7497. [Google Scholar] [CrossRef]
- Ojha, U.; Li, Y.; Lu, J.; Efros, A.A.; Lee, Y.J.; Shechtman, E.; Zhang, R. Few-shot image generation via cross-domain correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10743–10752. [Google Scholar]
- Zhao, Y.; Ding, H.; Huang, H.; Cheung, N.-M. A closer look at few-shot image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9140–9150. [Google Scholar]
- Liu, M.-Y.; Huang, X.; Mallya, A.; Karras, T.; Aila, T.; Lehtinen, J.; Kautz, J. Few-shot unsupervised image-to-image translation. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10551–10560. [Google Scholar]
- Gu, Z.; Li, W.; Huo, J.; Wang, L.; Gao, Y. Lofgan: Fusing local representations for few-shot image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 8463–8471. [Google Scholar]
- Dong, Z.; Ji, X.; Zhou, G.; Gao, M.; Qi, D. Multimodal Neuromorphic Sensory-Processing System with Memristor Circuits for Smart Home Applications. IEEE Trans. Ind. Appl. 2022, 59, 47–58. [Google Scholar] [CrossRef]
- Clouâtre, L.; Demers, M. Figr: Few-shot image generation with reptile. arXiv 2019, arXiv:1901.02199. [Google Scholar]
- Dong, Z.; Li, C.; Qi, D.; Luo, L.; Duan, S. Multiple memristor circuit parametric fault diagnosis using feedback-control doublet generator. IEEE Access 2016, 4, 2604–2614. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. Adv. Neural Inf. Proces. Syst. 2017, 6000–6010. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Ji, X.; Dong, Z.; Lai, C.S.; Qi, D. A physics-oriented memristor model with the coexistence of NDR effect and RS memory behavior for bio-inspired computing. Mater. Today Adv. 2022, 16, 100293. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. IEEE Trans. Knowl. Data Eng. 2021, 35, 3313–3332. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Ji, X.; Lai, C.S.; Zhou, G.; Dong, Z.; Qi, D.; Lai, L.L. A Flexible Memristor Model with Electronic Resistive Switching Memory Behavior and its Application in Spiking Neural Network. IEEE Trans. Nanobiosci. 2022, 22, 52–62. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Wang, J.; Chen, Y.; Dong, Z. SABV-Depth: A biologically inspired deep learning network for monocular depth estimation. Knowl.-Based Syst. 2023, 263, 110301. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Wang, D.; Cheng, Y.; Yu, M.; Guo, X.; Zhang, T. A hybrid approach with optimization-based and metric-based meta-learner for few-shot learning. Neurocomputing 2019, 349, 202–211. [Google Scholar] [CrossRef]
- Ding, G.; Han, X.; Wang, S.; Wu, S.; Jin, X.; Tu, D.; Huang, Q. Attribute Group Editing for Reliable Few-shot Image Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11194–11203. [Google Scholar]
- Ji, X.; Qi, D.; Dong, Z.; Lai, C.S.; Zhou, G.; Hu, X. TSSM: Three-State Switchable Memristor Model Based on Ag/TiO x Nanobelt/Ti Configuration. Int. J. Bifurc. Chaos 2021, 31, 2130020. [Google Scholar] [CrossRef]
- Liang, W.; Liu, Z.; Liu, C. Dawson: A domain adaptive few shot generation framework. arXiv 2020, arXiv:2001.00576. [Google Scholar]
- Nichol, A.; Schulman, J. Reptile: A scalable metalearning algorithm. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Antoniou, A.; Edwards, H.; Storkey, A. How to train your MAML. arXiv 2018, arXiv:1810.09502. [Google Scholar]
- Tseng, H.-Y.; Lee, H.-Y.; Huang, J.-B.; Yang, M.-H. Cross-domain few-shot classification via learned feature-wise transformation. arXiv 2020, arXiv:2001.08735. [Google Scholar]
- Li, X.; Yu, L.; Fu, C.-W.; Fang, M.; Heng, P.-A. Revisiting metric learning for few-shot image classification. Neurocomputing 2020, 406, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Dong, Z.; Ji, X.; Lai, C.S.; Qi, D. Design and Implementation of a Flexible Neuromorphic Computing System for Affective Communication via Memristive Circuits. IEEE Commun. Mag. 2022, 61, 74–80. [Google Scholar] [CrossRef]
- Assran, M.; Caron, M.; Misra, I.; Bojanowski, P.; Bordes, F.; Vincent, P.; Joulin, A.; Rabbat, M.; Ballas, N. Masked siamese networks for label-efficient learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 456–473. [Google Scholar]
- Hong, Y.; Niu, L.; Zhang, J.; Zhang, L. Matchinggan: Matching-Based Few-Shot Image Generation. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 2023, 35, 7853–7865. [Google Scholar] [CrossRef]
- Ji, X.; Dong, Z.; Han, Y.; Lai, C.S.; Zhou, G.; Qi, D. EMSN: An Energy-Efficient Memristive Sequencer Network for Human Emotion Classification in Mental Health Monitoring. IEEE Trans. Consum. Electron. 2023. [Google Scholar] [CrossRef]
- Bartunov, S.; Vetrov, D. Few-shot generative modelling with generative matching networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Spain, 9–11 April 2018; pp. 670–678. [Google Scholar]
- Li, X.; Yang, X.; Ma, Z.; Xue, J.H. Deep metric learning for few-shot image classification: A Review of recent developments. Pattern Recognit. 2023, 109381. [Google Scholar] [CrossRef]
- Hong, Y.; Niu, L.; Zhang, J.; Zhao, W.; Fu, C.; Zhang, L. F2gan: Fusing-and-filling gan for few-shot image generation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle WA, USA, 12–16 October 2020; pp. 2535–2543. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Chong, M.J.; Forsyth, D. Effectively unbiased fid and inception score and where to find them. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6070–6079. [Google Scholar]
- Talebi, H.; Milanfar, P. Learned perceptual image enhancement. In Proceedings of the 2018 IEEE International Conference on Computational Photography (ICCP), Pittsburgh, PA, USA, 4–6 May 2018; pp. 1–13. [Google Scholar]
- Barratt, S.; Sharma, R. A note on the inception score. arXiv 2018, arXiv:1801.01973. [Google Scholar]
- Wang, Y.; Li, J.; Lu, Y.; Fu, Y.; Jiang, Q. Image quality evaluation based on image weighted separating block peak signal to noise ratio. In Proceedings of the International Conference on Neural Networks and Signal Processing, Nanjing, China, 14–17 December 2003; pp. 994–997. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y. DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction. IEEE Trans. Med. Imaging 2017, 37, 1310–1321. [Google Scholar] [CrossRef] [Green Version]
- de la Rosa, F.L.; Gómez-Sirvent, J.L.; Sánchez-Reolid, R.; Morales, R.; Fernández-Caballero, A. Geometric transformation-based data augmentation on defect classification of segmented images of semiconductor materials using a ResNet50 convolutional neural network. Expert Syst. Appl. 2022, 206, 117731. [Google Scholar] [CrossRef]
- Duan, J.; Liu, X. Online monitoring of green pellet size distribution in haze-degraded images based on VGG16-LU-Net and haze judgment. IEEE Trans. Instrum. Meas. 2021, 70, 5006316. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoder 1 | Output Size | |
|---|---|---|
| Stage 1 | , 32 | |
| Stage 2 | ||
| Stage 3 | ||
| Stage 4 | ||
| Stage 5 |
| Category ID | Category Name | Number |
|---|---|---|
| 1 | Blurred Dial | 1756 |
| 2 | Broken Dial | 533 |
| 3 | Insulator Rupture | 953 |
| 4 | Insulator Crack | 678 |
| 5 | Oily Dirt on the Surface of Oil Leaking Parts | 5922 |
| 6 | Oil on the Ground | 1494 |
| 7 | Damaged Respirator Silicone Cartridge | 527 |
| 8 | Discoloration Silicone Respirator | 3225 |
| 9 | The Box Door is Closed Abnormally | 1405 |
| 10 | Suspended Solids | 2006 |
| 11 | The Bird’s Nest | 1316 |
| 12 | Damaged Cover | 556 |
| Method | The Smaller the Better | The Larger the Better | ||
|---|---|---|---|---|
| FID | LPIPS | IS | PSNR | |
| FIGR | 83.09 | 0.320 | 137.42 | 12.84 |
| MatchingGAN | 73.85 | 0.241 | 148.35 | 19.31 |
| DAWSON | 82.49 | 0.337 | 140.14 | 14.32 |
| LoFGAN | 86.98 | 0.362 | 133.95 | 12.47 |
| GMN | 79.14 | 0.292 | 141.33 | 14.85 |
| DAGAN | 75.75 | 0.265 | 152.70 | 18.46 |
| Ours | 67.87 | 0.179 | 164.23 | 23.41 |
| +GLFM | +SAEncoder | FID | IS | PSNR | |
|---|---|---|---|---|---|
| Net.1 | 86.98 | 133.95 | 12.47 | ||
| Net.2 | ✓ | 73.50 | 154.76 | 18.58 | |
| Net.3 | ✓ | 72.28 | 150.35 | 17.16 | |
| Net.4 | ✓ | ✓ | 67.87 | 164.23 | 23.41 |
| F Score | |||||
|---|---|---|---|---|---|
| Network | Dataset | Meter | Metal | Broken | Total |
| Breakage | Corrosion | Insulator | |||
| ResNet50 | Real | 89.0% | 79.7% | 90.4% | 87.1% |
| ResNet50 | Real+Sample | 92.8% | 84.4% | 94.2% | 90.8% |
| VGG16 | Real | 86.3% | 78.3% | 89.5% | 85.6% |
| VGG16 | Real+Sample | 88.1% | 85.0% | 94.1% | 89.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Yan, Y.; Wang, X.; Zheng, Y. IoT-Enabled Few-Shot Image Generation for Power Scene Defect Detection Based on Self-Attention and Global–Local Fusion. Sensors 2023, 23, 6531. https://doi.org/10.3390/s23146531
Chen Y, Yan Y, Wang X, Zheng Y. IoT-Enabled Few-Shot Image Generation for Power Scene Defect Detection Based on Self-Attention and Global–Local Fusion. Sensors. 2023; 23(14):6531. https://doi.org/10.3390/s23146531
Chicago/Turabian StyleChen, Yi, Yunfeng Yan, Xianbo Wang, and Yi Zheng. 2023. "IoT-Enabled Few-Shot Image Generation for Power Scene Defect Detection Based on Self-Attention and Global–Local Fusion" Sensors 23, no. 14: 6531. https://doi.org/10.3390/s23146531