
CoSOV1Net: A Cone- and Spatial-Opponent Primary Visual Cortex-Inspired Neural Network for Lightweight Salient Object Detection

Abstract
:1. Introduction
- 1.
- 2.
- We propose a novel approach to extract features from opposing color pairs in a neural network to exploit the strength of the color-opponent principle from human color perception. This approach permits the acceleration of neural network learning;
- We propose a novel strategy to integrate color in patterns in a neural network by extracting features locally and between color channels at the same time in successively grouped feature maps, which results in a reduction in the number of parameters and the depth of the neural network, while keeping good performance;
- We propose—for the first time, to our knowledge—a novel lightweight salient object-detection neural network architecture based on the proposed approach for learning opposing color pairs along with the strategy of integrating color in patterns. This model has few parameters, but its performance is comparable to state-of-the-art methods.
2. Related Work
2.1. Lightweight Salient Object Detection
2.2. Color-Opponent Models
3. Materials and Methods
3.1. Introduction
- L − M opponent for red–green;
- S − (L + M) opponent for blue–yellow.
- 1.
- The color-opponent encoding in the early stage of the HVS;
- 2.
- The fact that color and pattern are inextricably linked in human color perception
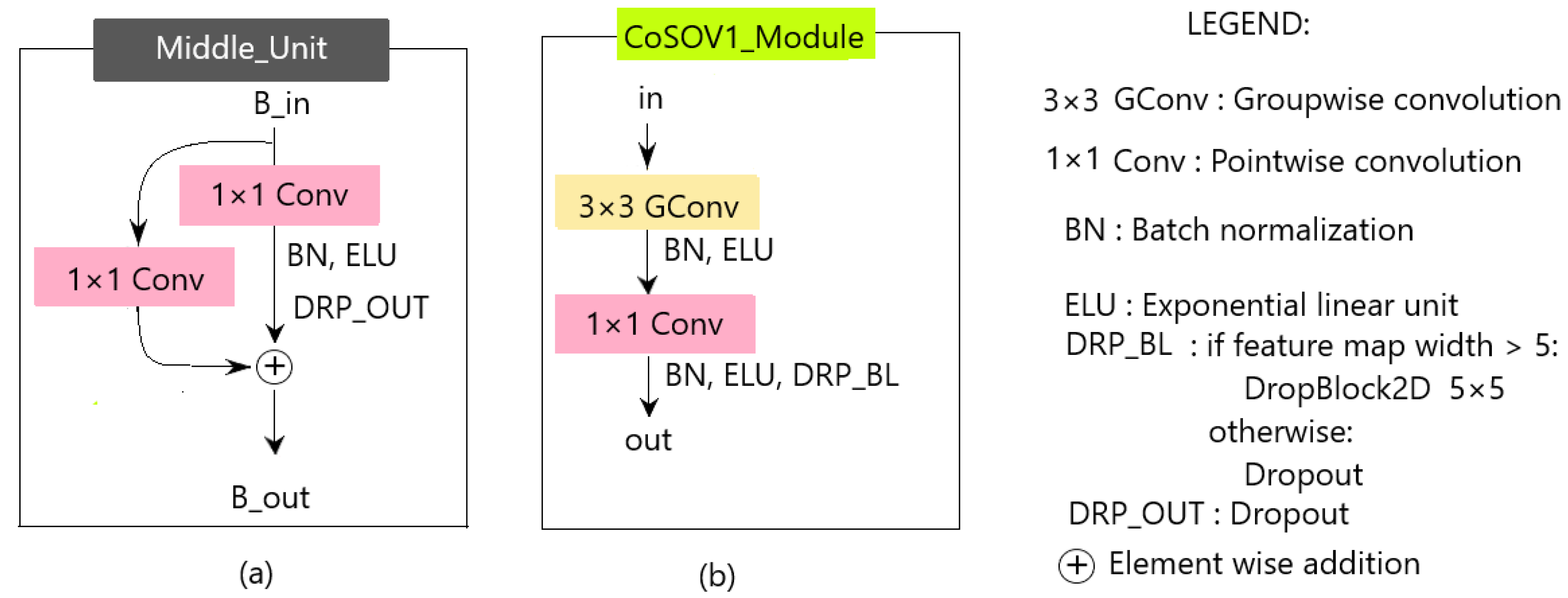
3.2. CoSOV1: Cone- and Spatial-Opponent Primary Visual Cortex Module
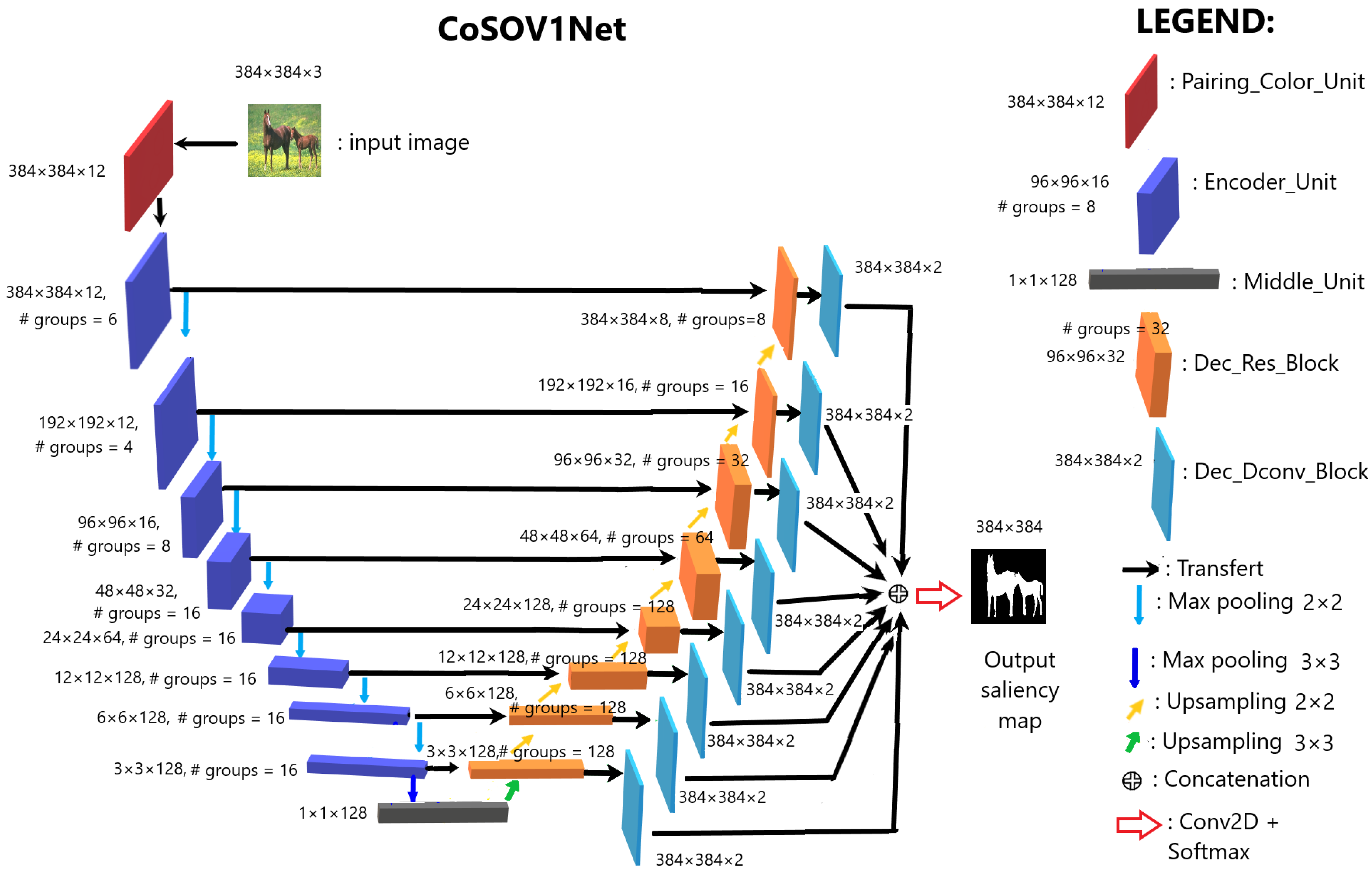
3.3. CoSOV1Net Neural Network Model Architecture
- 1.
- The input RGB color channel pairing;
- 2.
- The encoder;
- 3.
- The decoder.
3.3.1. Input RGB Color Channel Pairing
3.3.2. Encoder
3.3.3. Decoder
4. Experimental Results
4.1. Implementation Details
4.2. Datasets
4.3. Model Training Settings
- The first stage is with data augmentation, which is applied to each batch with random transformation ( zoom in or horizontal flip or vertical flip). This stage has 480 epochs: 240 epochs with learning rate = and 240 epochs with learning rate = ;
- The second stage is without data augmentation. It has 620 epochs: 240 epochs with learning rate = , followed by 140 epochs with learning rate = and 240 epochs with learning rate = .
4.4. Hyperparameters
- Image size: The best image size was . We did not choose a small size because we expected to have a small salient object. As we also wanted to have a low computational cost, we did not go beyond this size.
- Number of levels for the encoder: We empirically obtained eight levels as the best number. The choice of image size permitted us to have a maximum of eight levels for the encoder part, given that . The size of the feature maps of each level corresponds to the size of those of the previous level divided by 2, except the last level, where the division is by 3.
- Number of levels for the decoder: Eight levels. The number of levels is the same for the encoder part and the decoder part.
- Number of layers: At each level, we chose to use an encoder unit that has an equal number of layers for all levels and a decoder unit that has an equal number of layers for all levels. The number of layers was obtained experimentally.
- Number of filters: We also experimentally chose the number of filters keeping in mind the minimum parameters; the encoder’s number of filters was 12, 16, 32, 64, 128, 128, 128 and 128, respectively, for the first, second, …, seventh and eighth levels; the decoder residual bloc number of filters was 128, 128, 128, 128, 64, 32, 16 and 8, respectively, for the eighth, seventh, sixth, …, second and first levels. For the decoder deconvolution blocs, at each level, the number of filters was 2.
- Use of dropout: The dropout process injects noise in the resulting feature maps during the neural network learning stage (but not in the prediction stage) to facilitate the learning process. In this model, we used DropBlock [46] if the width of the feature map was greater than 5; otherwise, we used the common dropout [47]. The best results were obtained for DropBlock size = and rate = (the authors’ paper suggested a value between 0.05 and 0.25). For the common dropout, the best rate was 0.2, obtained experimentally.
4.5. Evaluation Metrics
4.5.1. Accuracy
4.5.2. Lightweight Measures
- For a convolution layer with n filters of size applied to feature maps (W: width; H: height; C: channels), with P: number of parameters:
- For a max-pooling layer or an upsampling layer with a window of size on feature maps (W: width; H: height; C: channels):
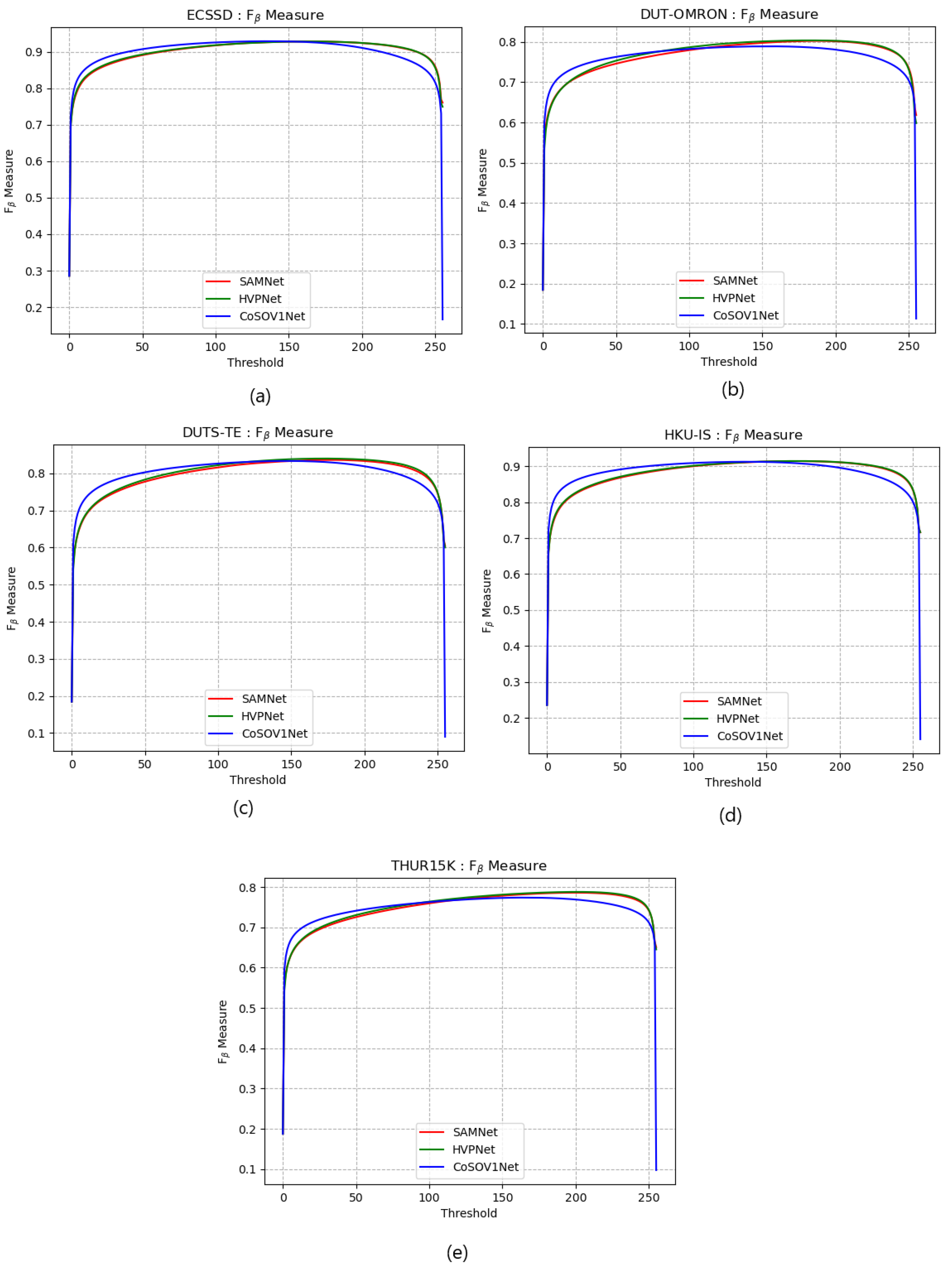
4.6. Comparison with State of the Art
4.7. Comparison with SAMNet and HVPNet State of the Art
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ndayikengurukiye, D.; Mignotte, M. Salient Object Detection by LTP Texture Characterization on Opposing Color Pairs under SLICO Superpixel Constraint. J. Imaging 2022, 8, 110. [Google Scholar] [CrossRef] [PubMed]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Pieters, R.; Wedel, M. Attention capture and transfer in advertising: Brand, pictorial and text-size effects. J. Mark. 2004, 68, 36–50. [Google Scholar] [CrossRef] [Green Version]
- Itti, L. Automatic foveation for video compression using a neurobiological model of visual attention. IEEE Trans. Image Process. 2004, 13, 1304–1318. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Feng, X.; Fan, H. Saliency-based image correction for colorblind patients. Comput. Vis. Media 2020, 6, 169–189. [Google Scholar] [CrossRef]
- Pinciroli Vago, N.O.; Milani, F.; Fraternali, P.; da Silva Torres, R. Comparing CAM algorithms for the identification of salient image features in iconography artwork analysis. J. Imaging 2021, 7, 106. [Google Scholar] [CrossRef]
- Gao, Y.; Shi, M.; Tao, D.; Xu, C. Database saliency for fast image retrieval. IEEE Trans. Multimed. 2015, 17, 359–369. [Google Scholar] [CrossRef]
- Wong, L.K.; Low, K.L. Saliency-enhanced image aesthetics class prediction. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 997–1000. [Google Scholar]
- Liu, H.; Heynderickx, I. Studying the added value of visual attention in objective image quality metrics based on eye movement data. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 3097–3100. [Google Scholar]
- Chen, L.Q.; Xie, X.; Fan, X.; Ma, W.Y.; Zhang, H.J.; Zhou, H.Q. A visual attention model for adapting images on small displays. Multimed. Syst. 2003, 9, 353–364. [Google Scholar] [CrossRef]
- Chen, T.; Cheng, M.M.; Tan, P.; Shamir, A.; Hu, S.M. Sketch2photo: Internet image montage. ACM Trans. Graph. (TOG) 2009, 28, 1–10. [Google Scholar]
- Huang, H.; Zhang, L.; Zhang, H.C. Arcimboldo-like collage using internet images. In Proceedings of the 2011 SIGGRAPH Asia Conference, Hong Kong, China, 12–15 December 2011; pp. 1–8. [Google Scholar]
- Gupta, A.K.; Seal, A.; Prasad, M.; Khanna, P. Salient object detection techniques in computer vision—A survey. Entropy 2020, 22, 1174. [Google Scholar] [CrossRef]
- Wang, W.; Lai, Q.; Fu, H.; Shen, J.; Ling, H.; Yang, R. Salient object detection in the deep learning era: An in-depth survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3239–3259. [Google Scholar] [CrossRef]
- Gao, S.H.; Tan, Y.Q.; Cheng, M.M.; Lu, C.; Chen, Y.; Yan, S. Highly efficient salient object detection with 100k parameters. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI. Springer: Berlin/Heidelberg, Germany, 2020; pp. 702–721. [Google Scholar]
- Liu, Y.; Zhang, X.Y.; Bian, J.W.; Zhang, L.; Cheng, M.M. SAMNet: Stereoscopically attentive multi-scale network for lightweight salient object detection. IEEE Trans. Image Process. 2021, 30, 3804–3814. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Ruan, X. Amulet: Aggregating multi-level convolutional features for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Liu, Y.; Gu, Y.C.; Zhang, X.Y.; Wang, W.; Cheng, M.M. Lightweight salient object detection via hierarchical visual perception learning. IEEE Trans. Cybern. 2020, 51, 4439–4449. [Google Scholar] [CrossRef] [PubMed]
- Shapley, R.; Hawken, M.J. Color in the cortex: Single-and double-opponent cells. Vis. Res. 2011, 51, 701–717. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kruger, N.; Janssen, P.; Kalkan, S.; Lappe, M.; Leonardis, A.; Piater, J.; Rodriguez-Sanchez, A.J.; Wiskott, L. Deep hierarchies in the primate visual cortex: What can we learn for computer vision? IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1847–1871. [Google Scholar] [CrossRef]
- Nunez, V.; Shapley, R.M.; Gordon, J. Cortical double-opponent cells in color perception: Perceptual scaling and chromatic visual evoked potentials. i-Perception 2018, 9, 2041669517752715. [Google Scholar] [CrossRef] [Green Version]
- Conway, B.R. Color vision, cones and color-coding in the cortex. Neuroscientist 2009, 15, 274–290. [Google Scholar] [CrossRef]
- Conway, B.R. Spatial structure of cone inputs to color cells in alert macaque primary visual cortex (V-1). J. Neurosci. 2001, 21, 2768–2783. [Google Scholar] [CrossRef] [Green Version]
- Hunt, R.W.G.; Pointer, M.R. Measuring Colour; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Engel, S.; Zhang, X.; Wandell, B. Colour tuning in human visual cortex measured with functional magnetic resonance imaging. Nature 1997, 388, 68–71. [Google Scholar] [CrossRef]
- Shapley, R. Physiology of color vision in primates. In Oxford Research Encyclopedia of Neuroscience; Oxford University Press: Oxford, UK, 2019. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Frintrop, S.; Werner, T.; Martin Garcia, G. Traditional saliency reloaded: A good old model in new shape. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 82–90. [Google Scholar]
- Mäenpää, T.; Pietikäinen, M. Classification with color and texture: Jointly or separately? Pattern Recognit. 2004, 37, 1629–1640. [Google Scholar] [CrossRef] [Green Version]
- Chan, C.H.; Kittler, J.; Messer, K. Multispectral local binary pattern histogram for component-based color face verification. In Proceedings of the 2007 First IEEE International Conference on Biometrics: Theory, Applications and Systems, Crystal City, Virginia, 27–29 September 2007; pp. 1–7. [Google Scholar]
- Faloutsos, C.; Lin, K.I. FastMap: A Fast Algorithm for Indexing, Data-Mining and Visualization of Traditional and Multimedia Datasets; ACM: Rochester, NY, USA, 1995; Volume 24. [Google Scholar]
- Jain, A.; Healey, G. A multiscale representation including opponent color features for texture recognition. IEEE Trans. Image Process. 1998, 7, 124–128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, K.F.; Gao, S.B.; Guo, C.F.; Li, C.Y.; Li, Y.J. Boundary detection using double-opponency and spatial sparseness constraint. IEEE Trans. Image Process. 2015, 24, 2565–2578. [Google Scholar] [CrossRef] [PubMed]
- Hurvich, L.M.; Jameson, D. An opponent-process theory of color vision. Psychol. Rev. 1957, 64, 384. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1915–1929. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning. Pmlr, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? Adv. Neural Inf. Process. Syst. 2018, 31, 2483–2493. [Google Scholar]
- Chollet, F. Deep Learning with Python; Simon and Schuster: Manhattan, NY, USA, 2021. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. Adv. Neural Inf. Process. Syst. 2018, 31, 10727–10737. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Pietikäinen, M.; Hadid, A.; Zhao, G.; Ahonen, T. Computer Vision Using Local Binary Patterns; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011; Volume 40. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 9 June 2023).
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, J.; Yan, Q.; Xu, L.; Jia, J. Hierarchical image saliency detection on extended CSSD. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 717–729. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–145. [Google Scholar]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Hu, S.M. Salientshape: Group saliency in image collections. Vis. Comput. 2014, 30, 443–453. [Google Scholar] [CrossRef]
- Feng, W.; Li, X.; Gao, G.; Chen, X.; Liu, Q. Multi-scale global contrast CNN for salient object detection. Sensors 2020, 20, 2656. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 248–255. [Google Scholar]
- Varadarajan, V.; Garg, D.; Kotecha, K. An efficient deep convolutional neural network approach for object detection and recognition using a multi-scale anchor box in real-time. Future Internet 2021, 13, 307. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, J.; Yuan, Z.; Wu, Y.; Zheng, N.; Li, S. Salient object detection: A discriminative regional feature integration approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2083–2090. [Google Scholar]
- Li, G.; Yu, Y. Deep contrast learning for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 478–487. [Google Scholar]
- Liu, N.; Han, J. Dhsnet: Deep hierarchical saliency network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 678–686. [Google Scholar]
- Wei, J.; Zhong, B. Saliency detection using fully convolutional network. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 3902–3907. [Google Scholar]
- Luo, Z.; Mishra, A.; Achkar, A.; Eichel, J.; Li, S.; Jodoin, P.M. Non-local deep features for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6609–6617. [Google Scholar]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Wang, H.; Yin, B. Learning uncertain convolutional features for accurate saliency detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 212–221. [Google Scholar]
- Wang, T.; Borji, A.; Zhang, L.; Zhang, P.; Lu, H. A stagewise refinement model for detecting salient objects in images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4019–4028. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect globally, refine locally: A novel approach to saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3127–3135. [Google Scholar]
- Li, X.; Yang, F.; Cheng, H.; Liu, W.; Shen, D. Contour knowledge transfer for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 355–370. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse attention for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Zhang, X.Y.; Nie, G.Y.; Wang, M. DNA: Deeply supervised nonlinear aggregation for salient object detection. IEEE Trans. Cybern. 2021, 52, 6131–6142. [Google Scholar] [CrossRef]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Feng, M.; Lu, H.; Ding, E. Attentive feedback network for boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1623–1632. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8779–8788. [Google Scholar]
- Su, J.; Li, J.; Zhang, Y.; Xia, C.; Tian, Y. Selectivity or invariance: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3799–3808. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9522–9531. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | # Param (M) ↓ | FLOPS (G) ↓ | Speed (FPS) ↑ | ECSSD | DUT-OMRON | DUTS-TE | HKU-IS | THUR15K |
|---|---|---|---|---|---|---|---|---|
| DRFI [64] | - | - | 0.1 | 0.777 | 0.652 | 0.649 | 0.774 | 0.670 |
| DCL [65] | 66.24 | 224.9 | 1.4 | 0.895 | 0.733 | 0.785 | 0.892 | 0.747 |
| DHSNet [66] | 94.04 | 15.8 | 10.0 | 0.903 | - | 0.807 | 0.889 | 0.752 |
| RFCN [67] | 134.69 | 102.8 | 0.4 | 0.896 | 0.738 | 0.782 | 0.892 | 0.754 |
| NLDF [68] | 35.49 | 263.9 | 18.5 | 0.902 | 0.753 | 0.806 | 0.902 | 0.762 |
| DSS [69] | 62.23 | 114.6 | 7.0 | 0.915 | 0.774 | 0.827 | 0.913 | 0.770 |
| Amulet [18] | 33.15 | 45.3 | 9.7 | 0.913 | 0.743 | 0.778 | 0.897 | 0.755 |
| UCF [70] | 23.98 | 61.4 | 12.0 | 0.901 | 0.730 | 0.772 | 0.888 | 0.758 |
| SRM [71] | 43.74 | 20.3 | 12.3 | 0.914 | 0.769 | 0.826 | 0.906 | 0.778 |
| PiCANet [17] | 32.85 | 37.1 | 5.6 | 0.923 | 0.766 | 0.837 | 0.916 | 0.783 |
| BRN [72] | 126.35 | 24.1 | 3.6 | 0.919 | 0.774 | 0.827 | 0.910 | 0.769 |
| C2S [73] | 137.03 | 20.5 | 16.7 | 0.907 | 0.759 | 0.811 | 0.898 | 0.775 |
| RAS [74] | 20.13 | 35.6 | 20.4 | 0.916 | 0.785 | 0.831 | 0.913 | 0.772 |
| DNA [75] | 20.06 | 82.5 | 25.0 | 0.935 | 0.799 | 0.865 | 0.930 | 0.793 |
| CPD [76] | 29.23 | 59.5 | 68.0 | 0.930 | 0.794 | 0.861 | 0.924 | 0.795 |
| BASNet [77] | 87.06 | 127.3 | 36.2 | 0.938 | 0.805 | 0.859 | 0.928 | 0.783 |
| AFNet [78] | 37.11 | 38.4 | 21.6 | 0.930 | 0.784 | 0.857 | 0.921 | 0.791 |
| PoolNet [79] | 53.63 | 123.4 | 39.7 | 0.934 | 0.791 | 0.866 | 0.925 | 0.800 |
| EGNet [80] | 108.07 | 270.8 | 12.7 | 0.938 | 0.794 | 0.870 | 0.928 | 0.800 |
| BANet [81] | 55.90 | 121.6 | 12.5 | 0.940 | 0.803 | 0.872 | 0.932 | 0.796 |
| CoSOV1Net (OURS) | 1.14 | 1.4 | 211.2 | 0.931 | 0.789 | 0.833 | 0.912 | 0.773 |
| Methods | # Param (M) ↓ | FLOPS (G) ↓ | Speed (FPS) ↑ | ECSSD | DUT-OMRON | DUTS-TE | HKU-IS | THUR15K |
|---|---|---|---|---|---|---|---|---|
| DRFI [64] | - | - | 0.1 | 0.161 | 0.138 | 0.154 | 0.146 | 0.150 |
| DCL [65] | 66.24 | 224.9 | 1.4 | 0.080 | 0.095 | 0.082 | 0.063 | 0.096 |
| DHSNet [66] | 94.04 | 15.8 | 10.0 | 0.062 | - | 0.066 | 0.053 | 0.082 |
| RFCN [67] | 134.69 | 102.8 | 0.4 | 0.097 | 0.095 | 0.089 | 0.080 | 0.100 |
| NLDF [68] | 35.49 | 263.9 | 18.5 | 0.066 | 0.080 | 0.065 | 0.048 | 0.080 |
| DSS [69] | 62.23 | 114.6 | 7.0 | 0.056 | 0.066 | 0.056 | 0.041 | 0.074 |
| Amulet [18] | 33.15 | 45.3 | 9.7 | 0.061 | 0.098 | 0.085 | 0.051 | 0.094 |
| UCF [70] | 23.98 | 61.4 | 12.0 | 0.071 | 0.120 | 0.112 | 0.062 | 0.112 |
| SRM [71] | 43.74 | 20.3 | 12.3 | 0.056 | 0.069 | 0.059 | 0.046 | 0.077 |
| PiCANet [17] | 32.85 | 37.1 | 5.6 | 0.049 | 0.068 | 0.054 | 0.042 | 0.083 |
| BRN [72] | 126.35 | 24.1 | 3.6 | 0.043 | 0.062 | 0.050 | 0.036 | 0.076 |
| C2S [73] | 137.03 | 20.5 | 16.7 | 0.057 | 0.072 | 0.062 | 0.046 | 0.083 |
| RAS [74] | 20.13 | 35.6 | 20.4 | 0.058 | 0.063 | 0.059 | 0.045 | 0.075 |
| DNA [75] | 20.06 | 82.5 | 25.0 | 0.041 | 0.056 | 0.044 | 0.031 | 0.069 |
| CPD [76] | 29.23 | 59.5 | 68.0 | 0.044 | 0.057 | 0.043 | 0.033 | 0.068 |
| BASNet [77] | 87.06 | 127.3 | 36.2 | 0.040 | 0.056 | 0.048 | 0.032 | 0.073 |
| AFNet [78] | 37.11 | 38.4 | 21.6 | 0.045 | 0.057 | 0.046 | 0.036 | 0.072 |
| PoolNet [79] | 53.63 | 123.4 | 39.7 | 0.048 | 0.057 | 0.043 | 0.037 | 0.068 |
| EGNet [80] | 108.07 | 270.8 | 12.7 | 0.044 | 0.056 | 0.044 | 0.034 | 0.070 |
| BANet [81] | 55.90 | 121.6 | 12.5 | 0.038 | 0.059 | 0.040 | 0.031 | 0.068 |
| CoSOV1Net (OURS) | 1.14 | 1.4 | 211.2 | 0.051 | 0.064 | 0.057 | 0.045 | 0.076 |
| Methods | # Param (M) ↓ | FLOPS (G) ↓ | Speed (FPS) ↑ | ECSSD | DUT-OMRON | DUTS-TE | HKU-IS | THUR15K |
|---|---|---|---|---|---|---|---|---|
| DRFI [64] | - | - | 0.1 | 0.548 | 0.424 | 0.378 | 0.504 | 0.444 |
| DCL [65] | 66.24 | 224.9 | 1.4 | 0.782 | 0.584 | 0.632 | 0.770 | 0.624 |
| DHSNet [66] | 94.04 | 15.8 | 10.0 | 0.837 | - | 0.705 | 0.816 | 0.666 |
| RFCN [67] | 134.69 | 102.8 | 0.4 | 0.725 | 0.562 | 0.586 | 0.707 | 0.591 |
| NLDF [68] | 35.49 | 263.9 | 18.5 | 0.835 | 0.634 | 0.710 | 0.838 | 0.676 |
| DSS [69] | 62.23 | 114.6 | 7.0 | 0.864 | 0.688 | 0.752 | 0.862 | 0.702 |
| Amulet [18] | 33.15 | 45.3 | 9.7 | 0.839 | 0.626 | 0.657 | 0.817 | 0.650 |
| UCF [70] | 23.98 | 61.4 | 12.0 | 0.805 | 0.573 | 0.595 | 0.779 | 0.613 |
| SRM [71] | 43.74 | 20.3 | 12.3 | 0.849 | 0.658 | 0.721 | 0.835 | 0.684 |
| PiCANet [17] | 32.85 | 37.1 | 5.6 | 0.862 | 0.691 | 0.745 | 0.847 | 0.687 |
| BRN [72] | 126.35 | 24.1 | 3.6 | 0.887 | 0.709 | 0.774 | 0.875 | 0.712 |
| C2S [73] | 137.03 | 20.5 | 16.7 | 0.849 | 0.663 | 0.717 | 0.835 | 0.685 |
| RAS [74] | 20.13 | 35.6 | 20.4 | 0.855 | 0.695 | 0.739 | 0.849 | 0.691 |
| DNA [75] | 20.06 | 82.5 | 25.0 | 0.897 | 0.729 | 0.797 | 0.889 | 0.723 |
| CPD [76] | 29.23 | 59.5 | 68.0 | 0.889 | 0.715 | 0.799 | 0.879 | 0.731 |
| BASNet [77] | 87.06 | 127.3 | 36.2 | 0.898 | 0.751 | 0.802 | 0.889 | 0.721 |
| AFNet [78] | 37.11 | 38.4 | 21.6 | 0.880 | 0.717 | 0.784 | 0.869 | 0.719 |
| PoolNet [79] | 53.63 | 123.4 | 39.7 | 0.875 | 0.710 | 0.783 | 0.864 | 0.724 |
| EGNet [80] | 108.07 | 270.8 | 12.7 | 0.886 | 0.727 | 0.796 | 0.876 | 0.727 |
| BANet [81] | 55.90 | 121.6 | 12.5 | 0.901 | 0.736 | 0.810 | 0.889 | 0.730 |
| CoSOV1Net (OURS) | 1.14 | 1.4 | 211.2 | 0.861 | 0.696 | 0.731 | 0.834 | 0.688 |
| Methods | # Param (M) ↓ | FLOPS (G) ↓ | Speed (FPS) ↑ | ECSSD | DUT-OMRON | DUTS-TE | HKU-IS | THUR15K |
|---|---|---|---|---|---|---|---|---|
| MobileNet * [30] | 4.27 | 2.2 | 295.8 | 0.906 | 0.753 | 0.804 | 0.895 | 0.767 |
| MobileNetV2 * [31] | 2.37 | 0.8 | 446.2 | 0.905 | 0.758 | 0.798 | 0.890 | 0.766 |
| ShuffleNet * [32] | 1.80 | 0.7 | 406.9 | 0.907 | 0.757 | 0.811 | 0.898 | 0.771 |
| ShuffleNetV2 * [33] | 1.60 | 0.5 | 452.5 | 0.901 | 0.746 | 0.789 | 0.884 | 0.755 |
| ICNet [82] | 6.70 | 6.3 | 75.1 | 0.918 | 0.773 | 0.810 | 0.898 | 0.768 |
| BiSeNet R18 [83] | 13.48 | 25.0 | 120.5 | 0.909 | 0.757 | 0.815 | 0.902 | 0.776 |
| BiSeNet X39 [83] | 1.84 | 7.3 | 165.8 | 0.901 | 0.755 | 0.787 | 0.888 | 0.756 |
| DFANet [84] | 1.83 | 1.7 | 91.4 | 0.896 | 0.750 | 0.791 | 0.884 | 0.757 |
| HVPNet [19] | 1.23 | 1.1 | 333.2 | 0.925 | 0.799 | 0.839 | 0.915 | 0.787 |
| SAMNet [16] | 1.33 | 0.5 | 343.2 | 0.925 | 0.797 | 0.835 | 0.915 | 0.785 |
| CoSOV1Net (OURS) | 1.14 | 1.4 | 211.2 | 0.931 | 0.789 | 0.833 | 0.912 | 0.773 |
| Methods | # Param (M) ↓ | FLOPS (G) ↓ | Speed (FPS) ↑ | ECSSD | DUT-OMRON | DUTS-TE | HKU-IS | THUR15K |
|---|---|---|---|---|---|---|---|---|
| MobileNet * [30] | 4.27 | 2.2 | 295.8 | 0.064 | 0.073 | 0.066 | 0.052 | 0.081 |
| MobileNetV2 * [31] | 2.37 | 0.8 | 446.2 | 0.066 | 0.075 | 0.070 | 0.056 | 0.085 |
| ShuffleNet * [32] | 1.80 | 0.7 | 406.9 | 0.062 | 0.069 | 0.062 | 0.050 | 0.078 |
| ShuffleNetV2 * [33] | 1.60 | 0.5 | 452.5 | 0.069 | 0.076 | 0.071 | 0.059 | 0.086 |
| ICNet [82] | 6.70 | 6.3 | 75.1 | 0.059 | 0.072 | 0.067 | 0.052 | 0.084 |
| BiSeNet R18 [83] | 13.48 | 25.0 | 120.5 | 0.062 | 0.072 | 0.062 | 0.049 | 0.080 |
| BiSeNet X39 [83] | 1.84 | 7.3 | 165.8 | 0.070 | 0.078 | 0.074 | 0.059 | 0.090 |
| DFANet [84] | 1.83 | 1.7 | 91.4 | 0.073 | 0.078 | 0.075 | 0.061 | 0.089 |
| HVPNet [19] | 1.23 | 1.1 | 333.2 | 0.055 | 0.064 | 0.058 | 0.045 | 0.076 |
| SAMNet [16] | 1.33 | 0.5 | 343.2 | 0.053 | 0.065 | 0.058 | 0.045 | 0.077 |
| CoSOV1Net (OURS) | 1.14 | 1.4 | 211.2 | 0.051 | 0.064 | 0.057 | 0.045 | 0.076 |
| Methods | # Param (M) ↓ | FLOPS (G) ↓ | Speed (FPS) ↑ | ECSSD | DUT-OMRON | DUTS-TE | HKU-IS | THUR15K |
|---|---|---|---|---|---|---|---|---|
| MobileNet * [30] | 4.27 | 2.2 | 295.8 | 0.829 | 0.656 | 0.696 | 0.816 | 0.675 |
| MobileNetV2 * [31] | 2.37 | 0.8 | 446.2 | 0.820 | 0.651 | 0.676 | 0.799 | 0.660 |
| ShuffleNet * [32] | 1.80 | 0.7 | 406.9 | 0.831 | 0.667 | 0.709 | 0.820 | 0.683 |
| ShuffleNetV2 * [33] | 1.60 | 0.5 | 452.5 | 0.812 | 0.637 | 0.665 | 0.788 | 0.652 |
| ICNet [82] | 6.70 | 6.3 | 75.1 | 0.838 | 0.669 | 0.694 | 0.812 | 0.668 |
| BiSeNet R18 [83] | 13.48 | 25.0 | 120.5 | 0.829 | 0.648 | 0.699 | 0.819 | 0.675 |
| BiSeNet X39 [83] | 1.84 | 7.3 | 165.8 | 0.802 | 0.632 | 0.652 | 0.784 | 0.641 |
| DFANet [84] | 1.83 | 1.7 | 91.4 | 0.799 | 0.627 | 0.652 | 0.778 | 0.639 |
| HVPNet [19] | 1.23 | 1.1 | 333.2 | 0.854 | 0.699 | 0.730 | 0.839 | 0.696 |
| SAMNet [16] | 1.33 | 0.5 | 343.2 | 0.855 | 0.699 | 0.729 | 0.837 | 0.693 |
| CoSOV1Net (OURS) | 1.14 | 1.4 | 211.2 | 0.861 | 0.696 | 0.731 | 0.834 | 0.688 |
| Measure | # Param (M) ↓ | FLOPS (G) ↓ | Speed (FPS) ↑ | ECSSD | DUT-OMRON | DUTS-TE | HKU-IS | THUR15K |
|---|---|---|---|---|---|---|---|---|
| 1st | 1st | 1st | 6th | 7th | 9th | 11th | 11th | |
| MAE | 1st | 1st | 1st | 10th | 10th | 11th | 11th | 10th |
| 1st | 1st | 1st | 11th | 9th | 11th | 15th | 11th |
| Measure | # Param (M) ↓ | FLOPS (G) ↓ | Speed (FPS) ↑ | ECSSD | DUT-OMRON | DUTS-TE | HKU-IS | THUR15K |
|---|---|---|---|---|---|---|---|---|
| 1st | 6th | 7th | 1st | 3rd | 3rd | 3rd | 4th | |
| MAE | 1st | 6th | 7th | 1st | 1st | 1st | 1st | 2nd |
| 1st | 6th | 7th | 1st | 3rd | 1st | 3rd | 3rd |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ndayikengurukiye, D.; Mignotte, M. CoSOV1Net: A Cone- and Spatial-Opponent Primary Visual Cortex-Inspired Neural Network for Lightweight Salient Object Detection. Sensors 2023, 23, 6450. https://doi.org/10.3390/s23146450
Ndayikengurukiye D, Mignotte M. CoSOV1Net: A Cone- and Spatial-Opponent Primary Visual Cortex-Inspired Neural Network for Lightweight Salient Object Detection. Sensors. 2023; 23(14):6450. https://doi.org/10.3390/s23146450
Chicago/Turabian StyleNdayikengurukiye, Didier, and Max Mignotte. 2023. "CoSOV1Net: A Cone- and Spatial-Opponent Primary Visual Cortex-Inspired Neural Network for Lightweight Salient Object Detection" Sensors 23, no. 14: 6450. https://doi.org/10.3390/s23146450