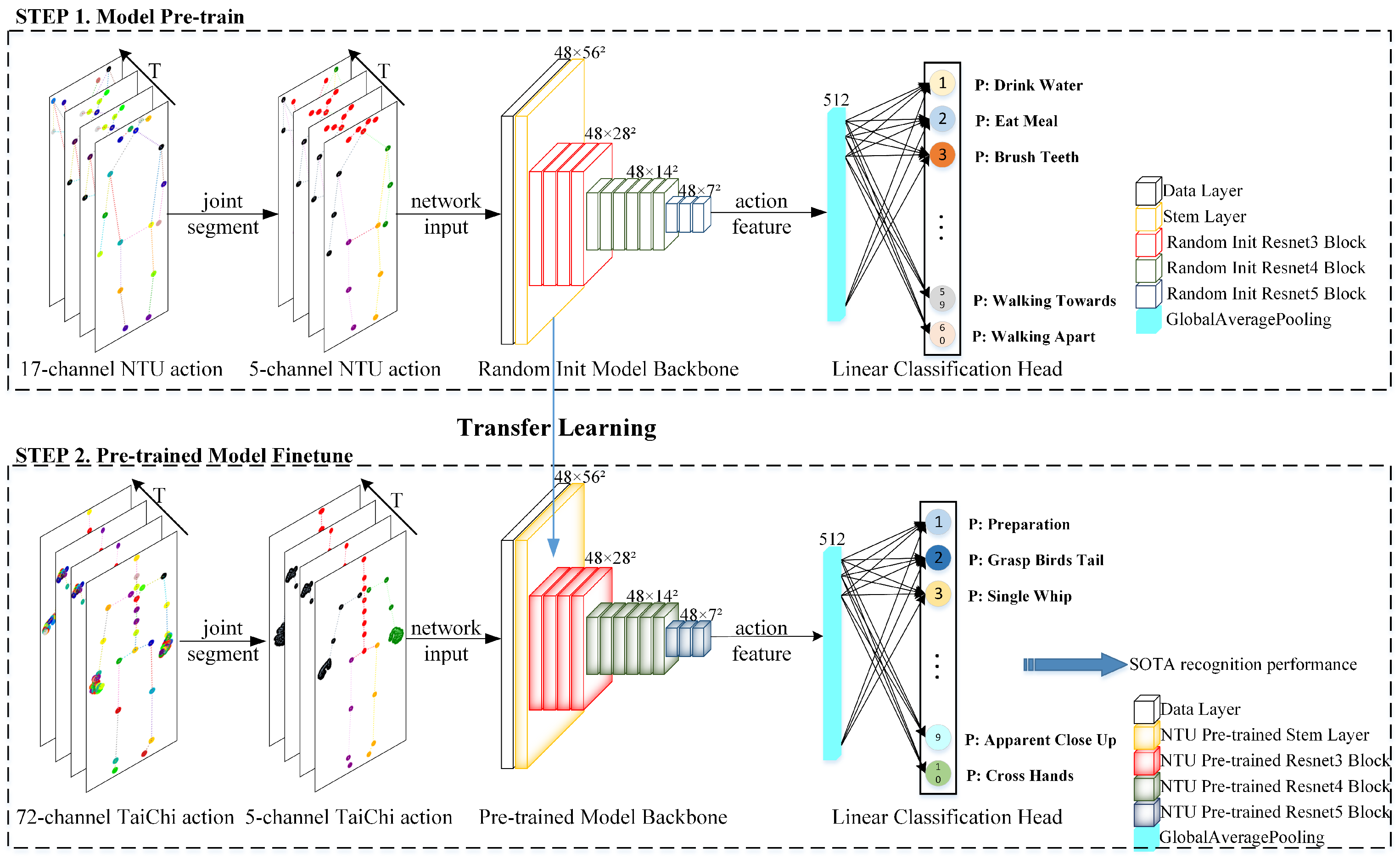
Figure 1.
SSCLS model framework. The segmentation of skeleton joints into five parts, denoted by ’black’, ’green’, ’purple’, ’yellow’, and ’red’, encoding for four limbs and the trunk, respectively, is shown. A pre-training period was employed to train an action feature extraction network using large-scale datasets. During the fine-tuning period, the pre-trained model backbone, represented by padded-color cubes for distinction, was utilized for small-scale fine-grained action recognition tasks.
Figure 1.
SSCLS model framework. The segmentation of skeleton joints into five parts, denoted by ’black’, ’green’, ’purple’, ’yellow’, and ’red’, encoding for four limbs and the trunk, respectively, is shown. A pre-training period was employed to train an action feature extraction network using large-scale datasets. During the fine-tuning period, the pre-trained model backbone, represented by padded-color cubes for distinction, was utilized for small-scale fine-grained action recognition tasks.
Figure 2.
Heatmap visualization extracted from two modalities. For video images, we perform human detection and estimate 2D poses for each frame. For skeleton coordinates, we plot (x,y) coordinates on the heatmap canvas. (a) Estimated 2D poses; (b) 2D keypoint heatmap; (c) 2D limb heatmap; (d) original 3D coordinates; (e) 2D keypoint heatmap; (f) 2D limb heatmap.
Figure 2.
Heatmap visualization extracted from two modalities. For video images, we perform human detection and estimate 2D poses for each frame. For skeleton coordinates, we plot (x,y) coordinates on the heatmap canvas. (a) Estimated 2D poses; (b) 2D keypoint heatmap; (c) 2D limb heatmap; (d) original 3D coordinates; (e) 2D keypoint heatmap; (f) 2D limb heatmap.
Figure 3.
Skeleton image before and after rotation and shear operation. Rotated skeleton coordinates are transformed by rotating along the y axis, and the sheared skeleton can be regarded as projecting the skeleton into a new non-vertical platform. (a) Original skeleton; (b) rotated skeleton; (c) sheared skeleton.
Figure 3.
Skeleton image before and after rotation and shear operation. Rotated skeleton coordinates are transformed by rotating along the y axis, and the sheared skeleton can be regarded as projecting the skeleton into a new non-vertical platform. (a) Original skeleton; (b) rotated skeleton; (c) sheared skeleton.
Figure 4.
Three-dimensional joint coordinates and 2D heatmaps of Tai Chi action. We transform the sequence of the skeleton-based coordinates into a heatmap-based pseudo video, which is more suitable for our network model. (a) The 3D skeleton coordinates under the pn system; (b) 2D keypoint heatmap under the cv2 system; (c) 2D limb heatmap under the cv2 system.
Figure 4.
Three-dimensional joint coordinates and 2D heatmaps of Tai Chi action. We transform the sequence of the skeleton-based coordinates into a heatmap-based pseudo video, which is more suitable for our network model. (a) The 3D skeleton coordinates under the pn system; (b) 2D keypoint heatmap under the cv2 system; (c) 2D limb heatmap under the cv2 system.
Figure 5.
Illustration when calculating the heatmap of limb modality. For two joints of a bone a and b, we calculate the heatmap value of pixels at the intersection of all grid lines as shown in the figure.
Figure 5.
Illustration when calculating the heatmap of limb modality. For two joints of a bone a and b, we calculate the heatmap value of pixels at the intersection of all grid lines as shown in the figure.
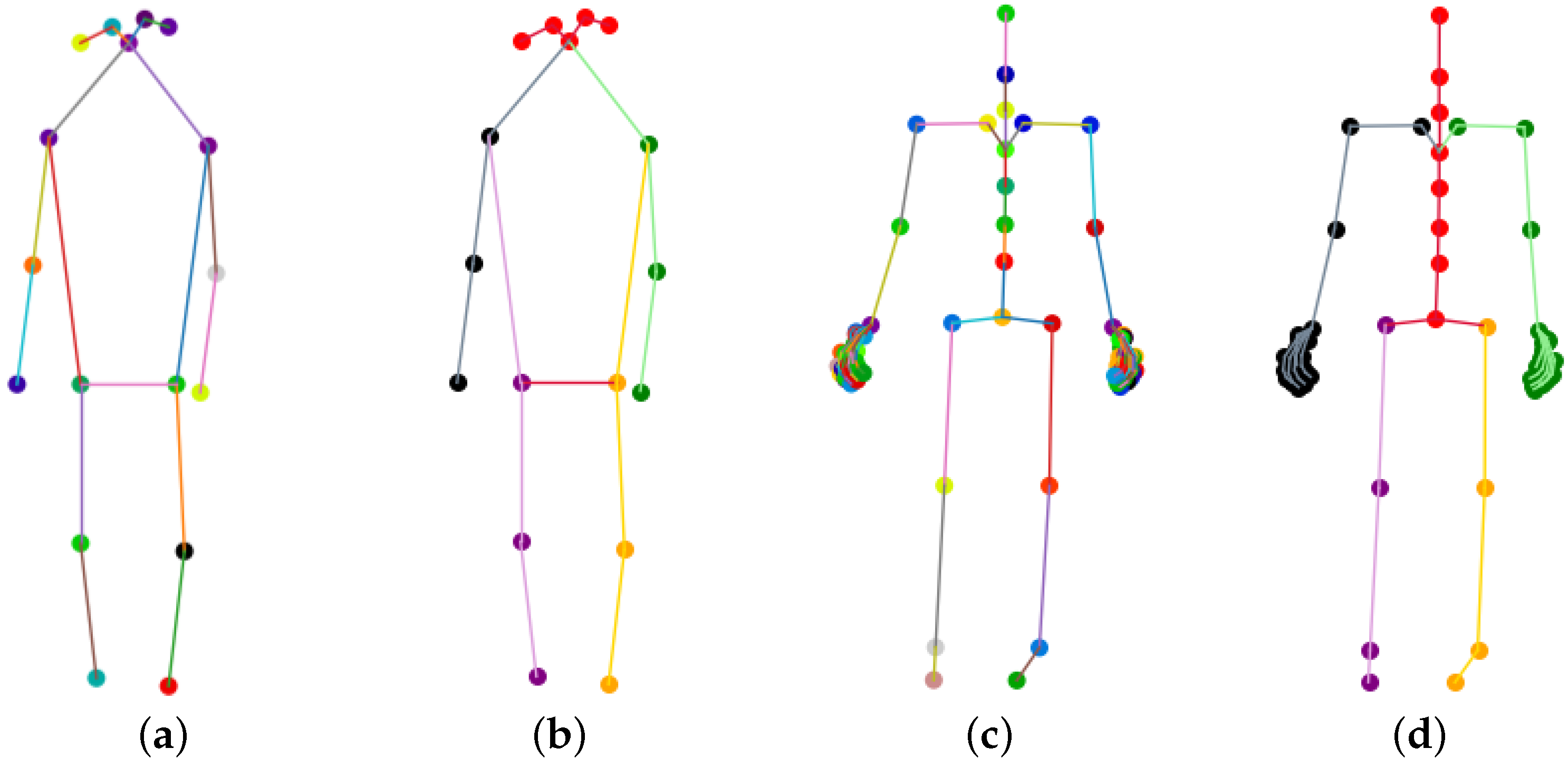
Figure 6.
Skeleton joints comparison between datasets. COCO-17 contains more facial keypoints but lacks hand features. Our perception neuron system can capture abundant hand expressions, but only one head joint is included. Therefore, our joint segmentation method split the whole skeleton into five parts, shown in (b,d). (a) Seventeen channel COCO-17 skeleton coordinates; (b) 5 channel COCO-17 skeleton coordinates; (c) 72 channel perception neuron skeleton coordinates; (d) 5 channel perception neuron skeleton coordinates.
Figure 6.
Skeleton joints comparison between datasets. COCO-17 contains more facial keypoints but lacks hand features. Our perception neuron system can capture abundant hand expressions, but only one head joint is included. Therefore, our joint segmentation method split the whole skeleton into five parts, shown in (b,d). (a) Seventeen channel COCO-17 skeleton coordinates; (b) 5 channel COCO-17 skeleton coordinates; (c) 72 channel perception neuron skeleton coordinates; (d) 5 channel perception neuron skeleton coordinates.
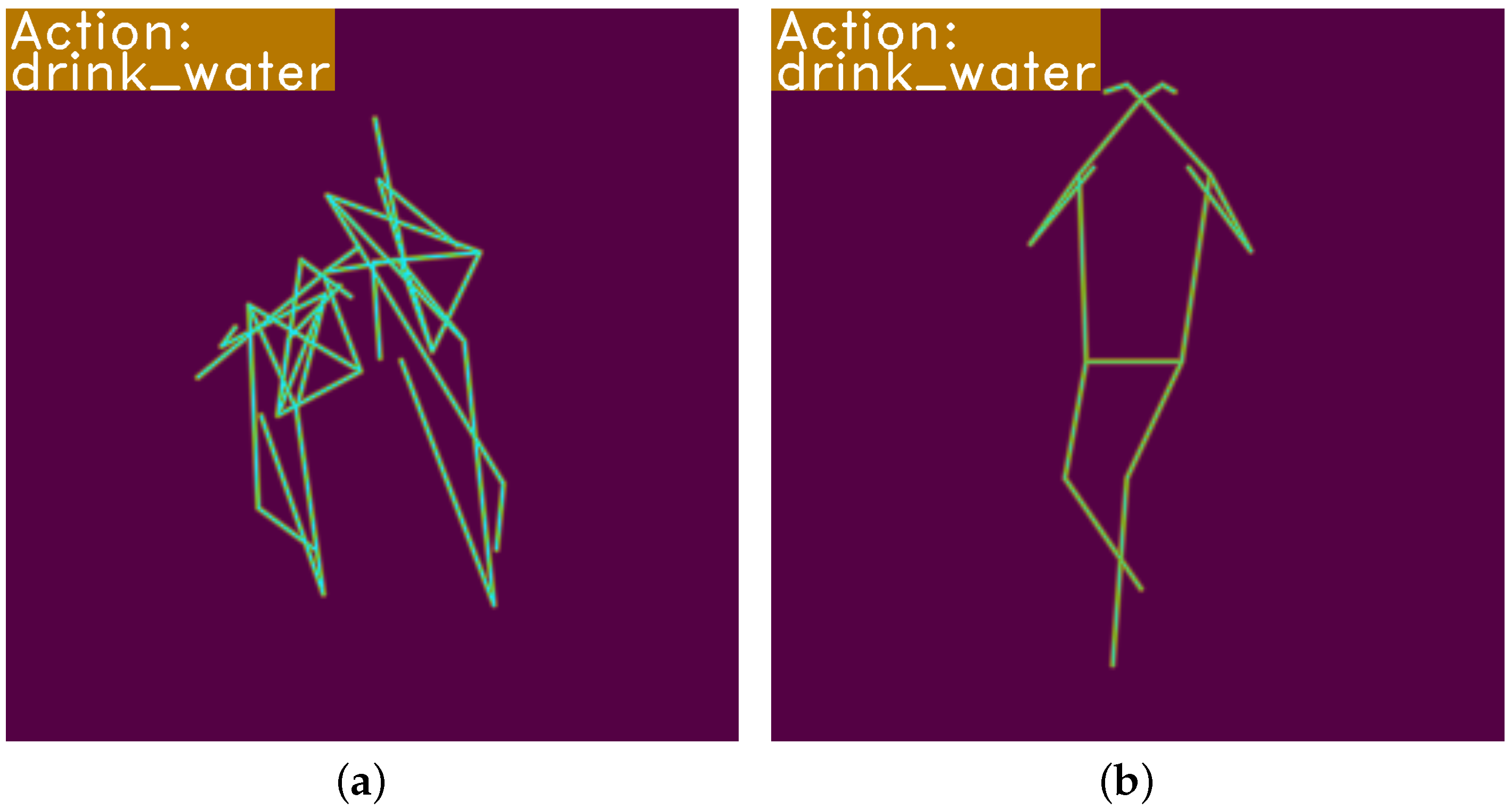
Figure 7.
Comparison of original 3D skeleton coordinates and extracted 2D poses for sample ‘S012C002P017R002A001’. The heatmap in (
a) is constructed by Kinect-collected 3D skeleton coordinates with method noted in
Section 3.1, whereas the heatmap in (
b) is directly extracted from videos with model HRNet [
10]. (
a) Heatmap from skeleton data; (
b) heatmap from pose extraction.
Figure 7.
Comparison of original 3D skeleton coordinates and extracted 2D poses for sample ‘S012C002P017R002A001’. The heatmap in (
a) is constructed by Kinect-collected 3D skeleton coordinates with method noted in
Section 3.1, whereas the heatmap in (
b) is directly extracted from videos with model HRNet [
10]. (
a) Heatmap from skeleton data; (
b) heatmap from pose extraction.
Figure 8.
Illustration of name and the iconic frame of 10 Tai Chi actions. Actions among the Tai Chi dataset are similar, especially for actions ‘Brush Knee and Twist Step’, ‘Hold the Lute’, ‘Pulling, Blocking and Pounding’, and ‘Apparent Close Up’.
Figure 8.
Illustration of name and the iconic frame of 10 Tai Chi actions. Actions among the Tai Chi dataset are similar, especially for actions ‘Brush Knee and Twist Step’, ‘Hold the Lute’, ‘Pulling, Blocking and Pounding’, and ‘Apparent Close Up’.
Figure 9.
Skeleton sequence illustration of four similar Tai Chi actions. Unlike mainstream datasets, fine-grained Tai Chi actions bring more recognition difficulties for the proposed network. (a) Illustration of Action “Brush Knee and Twist Step”. (b) Illustration of Action “Hold the Lute”. (c) Illustration of Action “Pulling, Blocking and Pounding”. (d) Illustration of Action “Apparent Close Up”.
Figure 9.
Skeleton sequence illustration of four similar Tai Chi actions. Unlike mainstream datasets, fine-grained Tai Chi actions bring more recognition difficulties for the proposed network. (a) Illustration of Action “Brush Knee and Twist Step”. (b) Illustration of Action “Hold the Lute”. (c) Illustration of Action “Pulling, Blocking and Pounding”. (d) Illustration of Action “Apparent Close Up”.
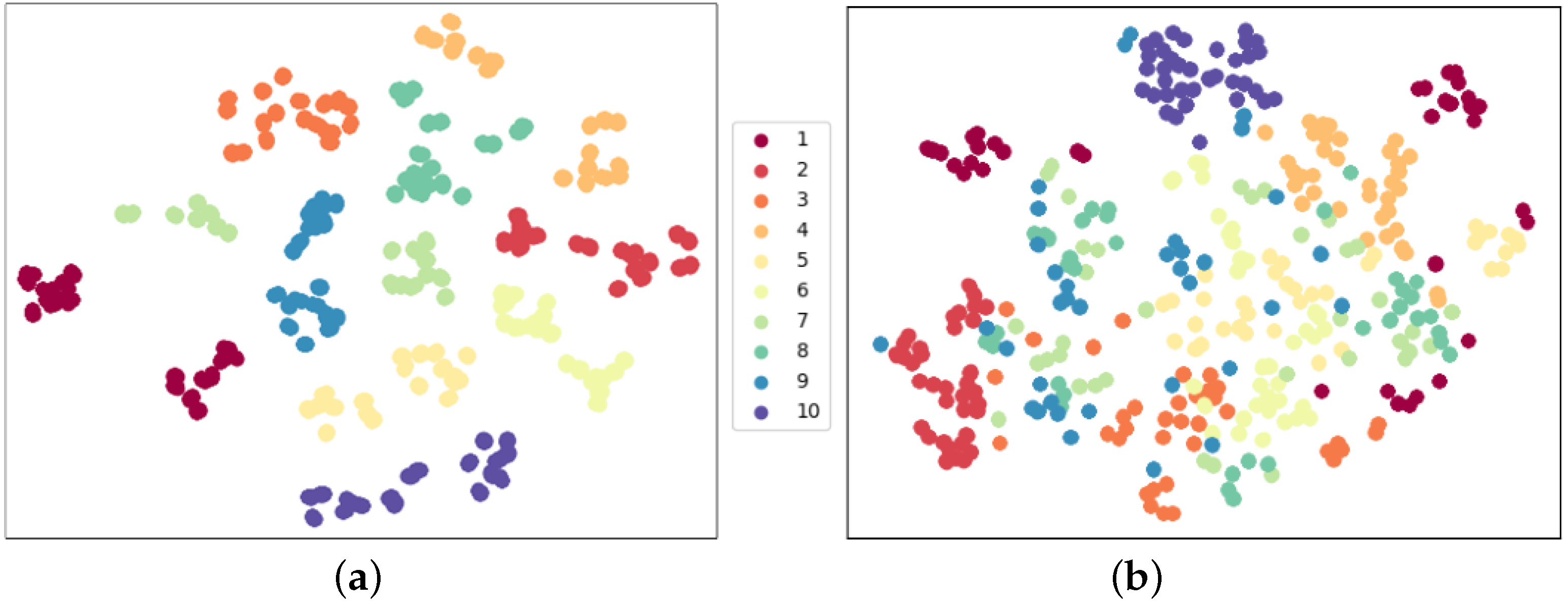
Figure 10.
Feature distribution comparison using two joint matching strategies in linear evaluation protocol. The same color stands for the same action class. The specific action names corresponding to the category labels are listed in
Section 4.1. (
a) 5-channel-kp with acc 87.22%; (
b) 17-channel-kp with acc 82.22%.
Figure 10.
Feature distribution comparison using two joint matching strategies in linear evaluation protocol. The same color stands for the same action class. The specific action names corresponding to the category labels are listed in
Section 4.1. (
a) 5-channel-kp with acc 87.22%; (
b) 17-channel-kp with acc 82.22%.
Figure 11.
Feature distribution comparison with/without pre-training process. The same color stands for the same action class. The pre-trained model backbone can easily separate Tai Chi actions, whereas the random backbone collapses. (a) Pre-trained model backbone outputs; (b) random init model backbone outputs.
Figure 11.
Feature distribution comparison with/without pre-training process. The same color stands for the same action class. The pre-trained model backbone can easily separate Tai Chi actions, whereas the random backbone collapses. (a) Pre-trained model backbone outputs; (b) random init model backbone outputs.
Figure 12.
Feature distribution comparison with/without pre-training process in fine-tune evaluation. The non pre-trained model has an obviously severe over-fitting problem that t-SNE features with different actions stack in the same embedding space. (a) WITH pre-training process; (b) WITHOUT pre-training process.
Figure 12.
Feature distribution comparison with/without pre-training process in fine-tune evaluation. The non pre-trained model has an obviously severe over-fitting problem that t-SNE features with different actions stack in the same embedding space. (a) WITH pre-training process; (b) WITHOUT pre-training process.
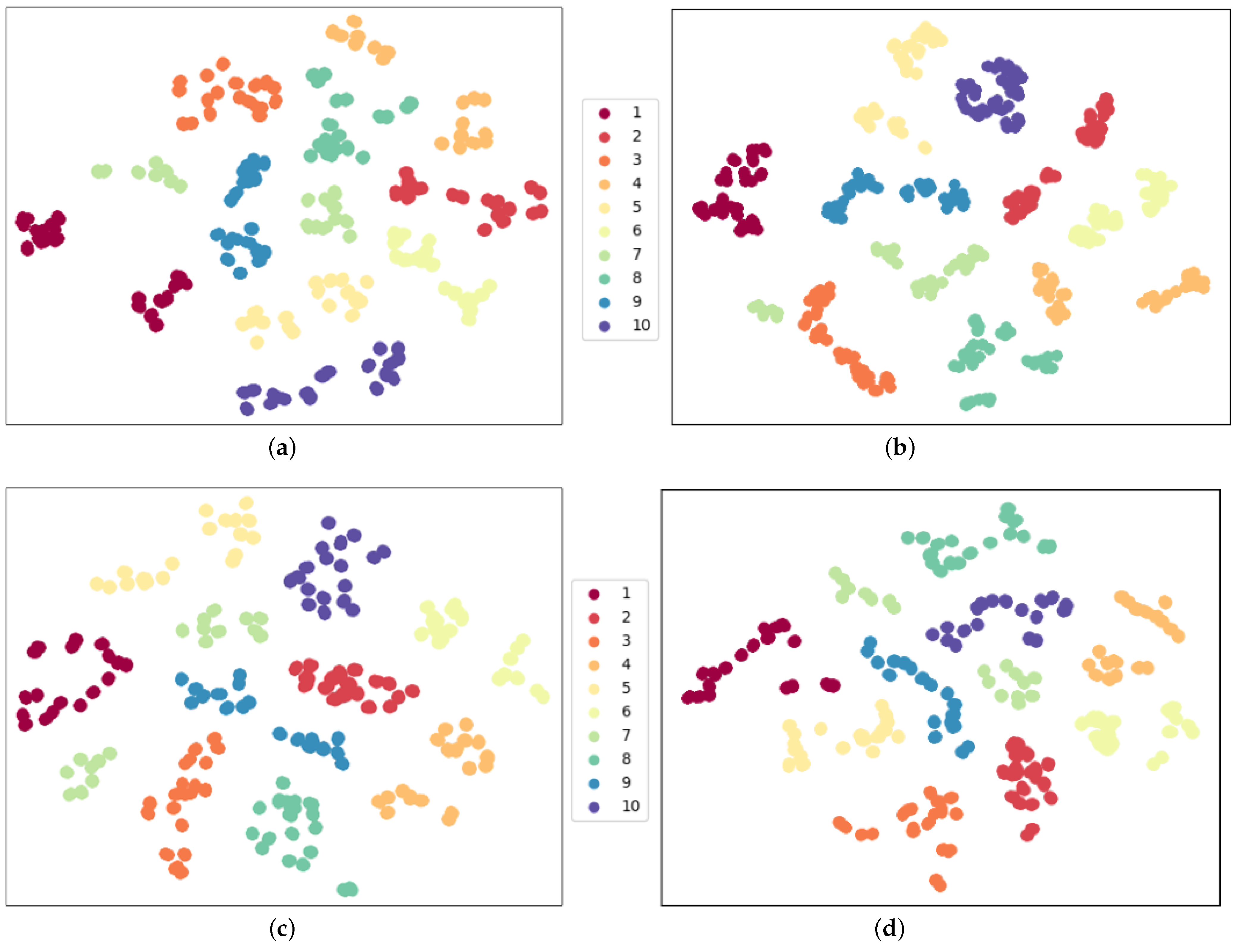
Figure 13.
Feature distribution with different data pre-processing configurations in fine-tune evaluation. This supplements the t-SNE visualization of fine-tune recognition results in
Table 7 and illustrates the robustness of our model framework. (
a) WSWRNFNC accuracy = 94.44%; (
b) WSWRNFWC accuracy = 94.44%; (
c) WSWRWFNC accuracy = 96.67%; (
d) WSWRWFWC accuracy = 98.33%.
Figure 13.
Feature distribution with different data pre-processing configurations in fine-tune evaluation. This supplements the t-SNE visualization of fine-tune recognition results in
Table 7 and illustrates the robustness of our model framework. (
a) WSWRNFNC accuracy = 94.44%; (
b) WSWRNFWC accuracy = 94.44%; (
c) WSWRWFNC accuracy = 96.67%; (
d) WSWRWFWC accuracy = 98.33%.
Figure 14.
Confusion matrices of Nursing Activity dataset recognition using MMT and SSCLS methods. Activity index of the axis are 0: vital signs measurement, 1: blood collection, 2: blood glucose measurement, 3: indwelling drip retention and connection, 4: oral care, 5: diaper exchange and cleaning of area.
Figure 14.
Confusion matrices of Nursing Activity dataset recognition using MMT and SSCLS methods. Activity index of the axis are 0: vital signs measurement, 1: blood collection, 2: blood glucose measurement, 3: indwelling drip retention and connection, 4: oral care, 5: diaper exchange and cleaning of area.
Table 1.
Configurations of our model backbone. The dimensions of kernels are denoted by {} for temporal, spatial, and channel sizes. Strides are denoted as {temporal stride, spatial stride2}.
Table 1.
Configurations of our model backbone. The dimensions of kernels are denoted by {} for temporal, spatial, and channel sizes. Strides are denoted as {temporal stride, spatial stride2}.
| Stage | Model Backbone | Output Size |
|---|
| Data layer | uniform | |
| Stem layer | conv
stride | |
| ResNet3 | | |
| ResNet4 | | |
| ResNet5 | | |
| GAP | Global Average Pooling | 512 |
| FC | Fully Connected Layer | Num Classes |
Table 2.
Grid search of initial learning rate under two evaluation configurations. We take the two bold initial learning rates in subsequent experiments for a fair comparison.
Table 2.
Grid search of initial learning rate under two evaluation configurations. We take the two bold initial learning rates in subsequent experiments for a fair comparison.
| Initial Learning Rate | Accuracy (%) | Epoch |
|---|
| Grid Search in Linear Evaluation Protocol: |
| 30 | 82.78 | 23 |
| 3 | 84.44 | 23 |
| 1 | 83.89 | 16 |
| 0.4 | 87.22 | 13 |
| 0.1 | 85.00 | 18 |
| 0.01 | 78.89 | 7 |
| Grid Search in Fine-tune Evaluation: |
| 1 | 52.22 | 23 |
| 0.1 | 87.22 | 24 |
| 0.01 | 94.44 | 5 |
| 0.001 | 93.89 | 11 |
| 0.0001 | 71.11 | 18 |
Table 3.
NTU RGB+D 120 recognition results under ‘X-Sub’ criteria. e.g., ‘5-channel-kp’ stands for taking segmented 5-part keypoint format samples as network inputs.
Table 3.
NTU RGB+D 120 recognition results under ‘X-Sub’ criteria. e.g., ‘5-channel-kp’ stands for taking segmented 5-part keypoint format samples as network inputs.
| Config | Accuracy (%) |
|---|
| 5-channel-kp | 85.12 |
| 5-channel-lb | 85.00 |
| 17-channel-kp | 85.42 |
| 10-channel-kplb | 85.30 |
Table 4.
Data augmentation recognition results in linear evaluation protocol. Abbreviations of ‘N’, ‘W’ means ‘not with’ and ‘with’; ‘F’, ‘C’ indicate operation of ‘flipping’ and‘cropping’, respectively. We use 10% of total samples as training dataset to train the classifier.
Table 4.
Data augmentation recognition results in linear evaluation protocol. Abbreviations of ‘N’, ‘W’ means ‘not with’ and ‘with’; ‘F’, ‘C’ indicate operation of ‘flipping’ and‘cropping’, respectively. We use 10% of total samples as training dataset to train the classifier.
| Config | Accuracy (%) | F1-Score (%) | Precision (%) | Recall (%) |
|---|
| NFNC | 72.78 | 72.53 | 80.84 | 72.78 |
| WFNC | 73.33 | 72.87 | 78.33 | 73.33 |
| NFWC | 85.00 | 84.37 | 86.67 | 85.00 |
| WFWC | 87.22 | 85.54 | 89.74 | 87.22 |
Table 5.
Fine-grained Tai Chi action recognition results in linear evaluation protocol. We experiment using keypoint modality from 10% training samples (‘TEST9’) to 70% samples (‘TEST3’) with fixed model backbone.
Table 5.
Fine-grained Tai Chi action recognition results in linear evaluation protocol. We experiment using keypoint modality from 10% training samples (‘TEST9’) to 70% samples (‘TEST3’) with fixed model backbone.
| Config | Accuracy (%) | F1-Score (%) | Precision (%) | Recall (%) |
|---|
| TEST9 | 87.22 | 85.54 | 89.74 | 87.22 |
| TEST7 | 96.43 | 96.40 | 96.90 | 96.43 |
| TEST5 | 96.67 | 96.66 | 96.90 | 96.67 |
| TEST3 | 98.00 | 97.99 | 98.18 | 98.00 |
Table 6.
Fine-grained Tai Chi action recognition results across fusion methods in linear evaluation protocol. We experiment under ‘TEST9’ configuration with early fusion and late fusion methods. The ‘+’ indicates early fusion configuration, whereas ‘√’ indicates late fusion.
Table 6.
Fine-grained Tai Chi action recognition results across fusion methods in linear evaluation protocol. We experiment under ‘TEST9’ configuration with early fusion and late fusion methods. The ‘+’ indicates early fusion configuration, whereas ‘√’ indicates late fusion.
| Config | Keypoint | Limb | Accuracy (%) | F1-Score (%) | Precision (%) |
|---|
| TEST9 | √ | | 87.22 | 85.54 | 89.74 |
| TEST9 | | √ | 88.33 | 87.95 | 89.24 |
| TEST9 | + | + | 85.00 | 82.58 | 87.80 |
| TEST9 | √ | √ | 90.56 | 89.82 | 91.55 |
Table 7.
Tai Chi action recognition results in fine-tune evaluation under TEST9. Abbreviations of ‘N’, ‘W’ mean ‘not with’ and ‘with’; ‘S’, ‘R’, ‘F’, and ‘C’ indicate operation of ‘shear’, ‘rotation’, ‘flipping’, and ‘cropping’, respectively. Our model framework achieves stable recognition performance under all data pre-processing configurations.
Table 7.
Tai Chi action recognition results in fine-tune evaluation under TEST9. Abbreviations of ‘N’, ‘W’ mean ‘not with’ and ‘with’; ‘S’, ‘R’, ‘F’, and ‘C’ indicate operation of ‘shear’, ‘rotation’, ‘flipping’, and ‘cropping’, respectively. Our model framework achieves stable recognition performance under all data pre-processing configurations.
| Config | Accuracy (%) | F1-Score (%) | Precision (%) | Recall (%) |
|---|
| WSWRNFNC | 94.44 | 93.80 | 95.87 | 94.44 |
| WSWRWFNC | 94.44 | 93.66 | 95.48 | 94.44 |
| WSWRNFWC | 96.67 | 96.43 | 97.05 | 96.67 |
| WSWRWFWC | 98.33 | 98.29 | 98.47 | 98.33 |
Table 8.
Comparison of Tai Chi action recognition accuracies using our Tai Chi dataset. We compare with SVM [
19] and spatial Transformer [
12] under four configurations: ‘TEST9’, ‘TEST7’, ‘TEST5’, and ‘TEST3’.
Table 8.
Comparison of Tai Chi action recognition accuracies using our Tai Chi dataset. We compare with SVM [
19] and spatial Transformer [
12] under four configurations: ‘TEST9’, ‘TEST7’, ‘TEST5’, and ‘TEST3’.
| Config | SVM [19] | Spatial Transformer [12] | SSCLS (Ours) |
|---|
| TEST9 | 72.78% | 87.22% | 94.44% |
| TEST7 | 80.05% | 90.71% | 100.00% |
| TEST5 | 90.71% | 93.00% | 100.00% |
| TEST3 | 93.86% | 98.33% | 100.00% |
Table 9.
Recognition performance comparison with the SOTA methods. Our method outperforms these method in all evaluation metrics, which illustrates the superiority of our method.
Table 9.
Recognition performance comparison with the SOTA methods. Our method outperforms these method in all evaluation metrics, which illustrates the superiority of our method.
| Methods | Accuracy (%) | F1-Score (%) | Precision (%) | Recall (%) |
|---|
| ST-GCN [81] | 56.59 | 56.61 | 56.55 | 59.41 |
| MMT (skeleton) [6] | 76.72 | 74.64 | 76.02 | 75.15 |
| MMT (fuse) [6] | 79.31 | 78.34 | 78.99 | 78.30 |
| SSCLS (Ours) | 82.76 | 83.27 | 85.90 | 82.80 |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}