
AGDF-Net: Attention-Gated and Direction-Field-Optimized Building Instance Extraction Network

Abstract
:1. Introduction
- Contradictions arise from intraclass heterogeneity and interclass homogeneity. The differences in scale, spectrum, texture, and style within building classes make many special buildings difficult to detect in a complex environment. For example, small buildings are easily missed, large buildings cannot be extracted completely, two parts of a building are recognized as separate individuals, and buildings too close to each other are recognized as the same individual.
- The angular morphology of buildings is difficult to maintain. Unlike other objects, buildings generally have a regular and sharp morphology. Most of the existing instance segmentation methods are based on convolutional neural networks, where the convolutional kernel operates on the neighbourhood of each pixel, which loses accurate detail information at the boundaries. Similarly, the pooling layer in the network exacerbates this deficiency, and the predicted buildings have difficulty maintaining accurate, regular, and clear boundaries.
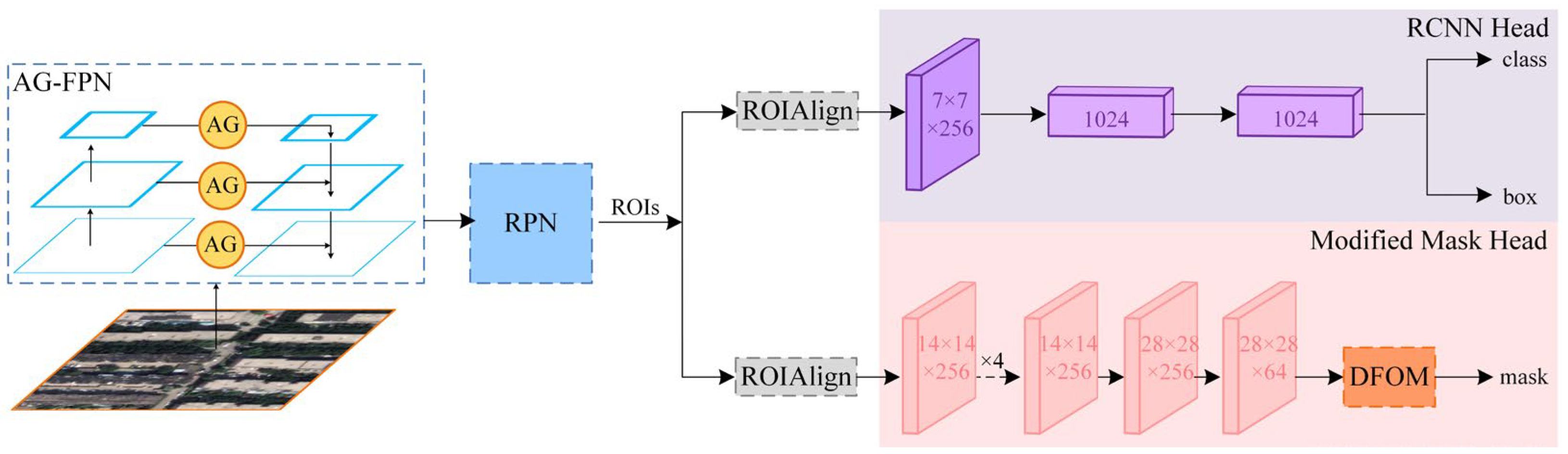
- An instance segmentation network is proposed which effectively distinguishes foreground from background and optimizes building contours in complex environments. Compared to previous approaches, it integrates an Attention-Gated Feature Pyramid Network (AG-FPN) and a Direction Field Optimization Module (DFOM) at the feature extraction and segmentation stages.
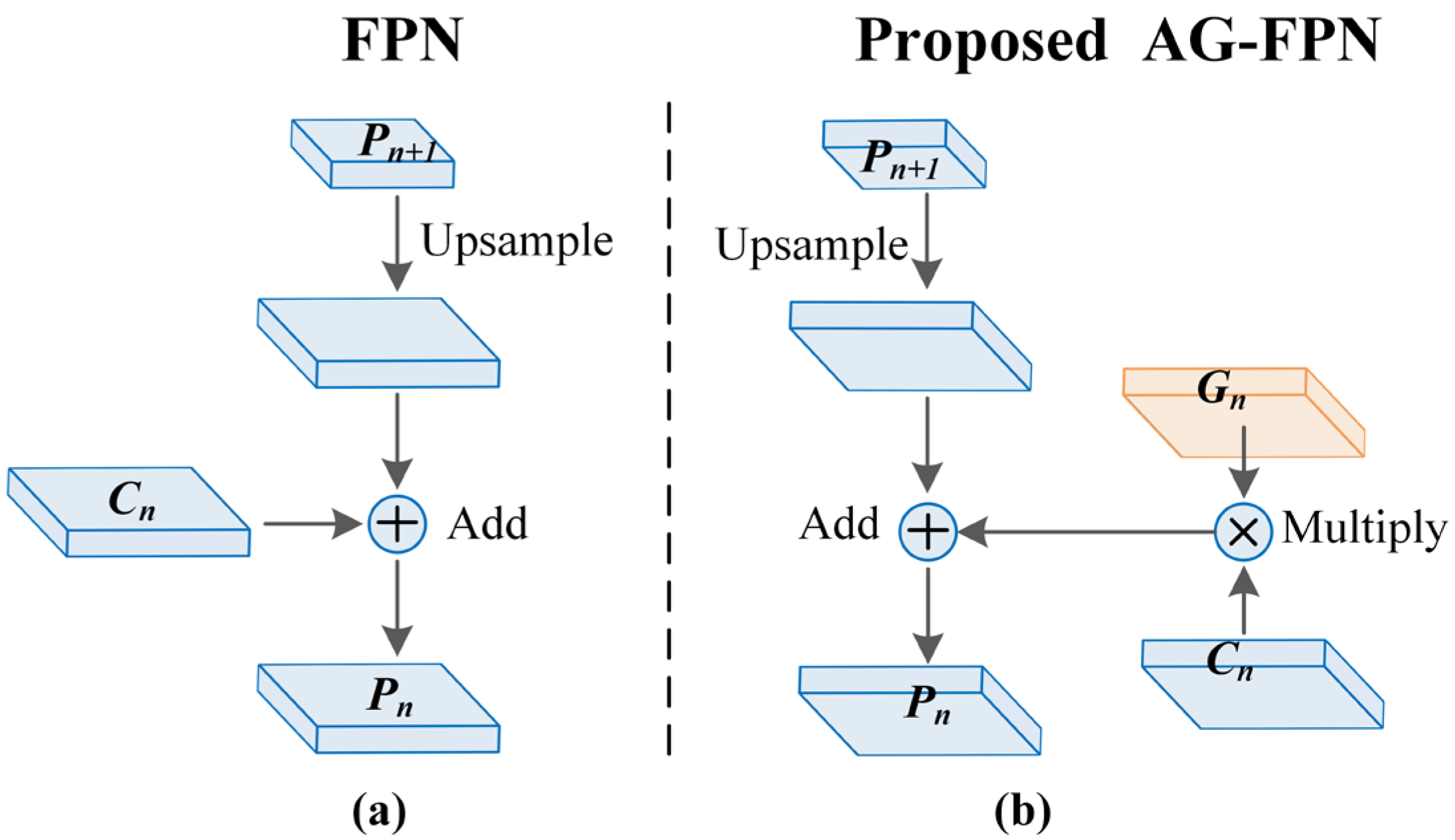
- The AG-FPN is designed to introduce a gated attention mechanism to control the flow between bottom-up and top-down information flows in the feature pyramid network to selectively focus on helpful information and suppress disruptive information.
- The DFOM is deployed on the mask head to predict the instance-level direction field from the feature map, and the expected direction field assigns a motion orientation to each pixel.
2. Methods
2.1. Overall Architecture
2.2. Attention-Gated Feature Pyramid Network
2.3. Directional Field Optimization Module
2.4. Loss Function
3. Experiments and Analysis
3.1. Experimental Setup
3.1.1. Dataset
3.1.2. Implementation Details
3.1.3. Evaluation Metrics
3.2. Comparison Experiments
3.2.1. Qualitative Analysis
3.2.2. Quantitative Analysis
3.3. Ablation Study
3.3.1. Ablation for AG-FPN
3.3.2. Ablation for DFOM
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, H.; Wu, P.; Yao, X.; Wu, Y.; Wang, B.; Xu, Y. Building Extraction in Very High Resolution Imagery by Dense-Attention Networks. Remote Sens. 2018, 10, 1768. [Google Scholar] [CrossRef] [Green Version]
- Sun, G.; Huang, H.; Zhang, A.; Li, F.; Zhao, H.; Fu, H. Fusion of Multiscale Convolutional Neural Networks for Building Extraction in Very High-Resolution Images. Remote Sens. 2019, 11, 227. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Persello, C.; Stein, A. Building Outline Delineation: From Aerial Images to Polygons with an Improved End-to-End Learning Framework. ISPRS J. Photogramm. Remote Sens. 2021, 175, 119–131. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Crooks, A.; See, L. Leveraging Street Level Imagery for Urban Planning. Environ. Plan. B Urban Anal. City Sci. 2022, 49, 773–776. [Google Scholar] [CrossRef]
- Li, X.; Meng, Q.; Li, W.; Zhang, C.; Jancso, T.; Mavromatis, S. An Explorative Study on the Proximity of Buildings to Green Spaces in Urban Areas Using Remotely Sensed Imagery. Ann. GIS 2014, 20, 193–203. [Google Scholar] [CrossRef]
- Xu, L.; Kong, M.; Pan, B. Building Extraction by Stroke Width Transform from Satellite Imagery. In Proceedings of the Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2017; Volume 773. [Google Scholar]
- Guo, Z.; Du, S. Mining Parameter Information for Building Extraction and Change Detection with Very High-Resolution Imagery and GIS Data. GIScience Remote Sens. 2017, 54, 38–63. [Google Scholar] [CrossRef]
- Teimouri, M.; Mokhtarzade, M.; Zoej, M.J.V. Optimal Fusion of Optical and SAR High-Resolution Images for Semiautomatic Building Detection. GIScience Remote Sens. 2016, 53, 45–62. [Google Scholar] [CrossRef]
- Chai, D. A Probabilistic Framework for Building Extraction from Airborne Color Image and DSM. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 948–959. [Google Scholar] [CrossRef]
- Grosse, P.; van Wyk de Vries, B.; Euillades, P.A.; Kervyn, M.; Petrinovic, I.A. Systematic Morphometric Characterization of Volcanic Edifices Using Digital Elevation Models. Geomorphology 2012, 136, 114–131. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Volume 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Rethinking Atrous Convolution for Semantic Image Segmentation Liang-Chieh. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar]
- Peng, X.; Yin, Z.; Yang, Z. Deeplab_v3_plus-Net for Image Semantic Segmentation with Channel Compression. In Proceedings of the International Conference on Communication Technology Proceedings ICCT, Nanning, China, 28–31 October 2020; Volume 2020. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the ECCV; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Yuan, S.; Zhong, R.; Li, Q.; Dong, Y. MFGFNet: A Multi-Scale Remote Sensing Change Detection Network Using the Global Filter in the Frequency Domain. Remote Sens. 2023, 15, 1682. [Google Scholar] [CrossRef]
- Zheng, J.; Tian, Y.; Yuan, C.; Yin, K.; Zhang, F.; Chen, F.D.; Chen, Q. MDESNet: Multitask Difference-Enhanced Siamese Network for Building Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3775. [Google Scholar] [CrossRef]
- Peng, F.; Lu, W.; Tan, W.; Qi, K.; Zhang, X.; Zhu, Q. Multi-Output Network Combining GNN and CNN for Remote Sensing Scene Classification. Remote Sens. 2022, 14, 1478. [Google Scholar] [CrossRef]
- Shen, J.; Yu, T.; Yang, H.; Wang, R.; Wang, Q. An Attention Cascade Global-Local Network for Remote Sensing Scene Classification. Remote Sens. 2022, 14, 2042. [Google Scholar] [CrossRef]
- Sánchez, A.-M.S.; González-Piqueras, J.; de la Ossa, L.; Calera, A. Convolutional Neural Networks for Agricultural Land Use Classification from Sentinel-2 Image Time Series. Remote Sens. 2022, 14, 5373. [Google Scholar] [CrossRef]
- Wenger, R.; Puissant, A.; Weber, J.; Idoumghar, L.; Forestier, G. Multimodal and Multitemporal Land Use/Land Cover Semantic Segmentation on Sentinel-1 and Sentinel-2 Imagery: An Application on a MultiSenGE Dataset. Remote Sens. 2022, 15, 151. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017. [Google Scholar]
- Is, M.; For, R.; At, E. An Image Is Worth 16 × 16 Words. Int. Conf. Learn. Represent. 2021. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Y.; Zeng, Y. Transformer with Transfer CNN for Remote-Sensing-Image Object Detection. Remote Sens. 2022, 14, 984. [Google Scholar] [CrossRef]
- Liu, Y.; He, G.; Wang, Z.; Li, W.; Huang, H. NRT-YOLO: Improved YOLOv5 Based on Nested Residual Transformer for Tiny Remote Sensing Object Detection. Sensors 2022, 22, 4953. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient Transformer for Remote Sensing Image Segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Wang, G.; Li, B.; Zhang, T.; Zhang, S. A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection. Remote Sens. 2022, 14, 2228. [Google Scholar] [CrossRef]
- Ma, J.; Wu, L.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Building Extraction of Aerial Images by a Global and Multi-Scale Encoder-Decoder Network. Remote Sens. 2020, 12, 2350. [Google Scholar] [CrossRef]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building Extraction Based on U-Net with an Attention Block and Multiple Losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Chen, D.Y.; Peng, L.; Li, W.C.; Wang, Y. Da Building Extraction and Number Statistics in WUI Areas Based on UNet Structure and Ensemble Learning. Remote Sens. 2021, 13, 1172. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Hua, Y.; Sun, Y.; Jin, P.; Shi, Y.; Zhu, X.X. Instance Segmentation of Buildings Using Keypoints. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Waikoloa, HI, USA, 26 September–2 October 2020. [Google Scholar]
- Zhao, K.; Kang, J.; Jung, J.; Sohn, G. Building Extraction from Satellite Images Using Mask R-CNN with Building Boundary Regularization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; Volume 2018. [Google Scholar]
- Wen, Q.; Jiang, K.; Wang, W.; Liu, Q.; Guo, Q.; Li, L.; Wang, P. Automatic Building Extraction from Google Earth Images under Complex Backgrounds Based on Deep Instance Segmentation Network. Sensors 2019, 19, 333. [Google Scholar] [CrossRef] [Green Version]
- Cheng, D.; Liao, R.; Fidler, S.; Urtasun, R. Darnet: Deep Active Ray Network for Building Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019. [Google Scholar]
- Iglovikov, V.; Seferbekov, S.; Buslaev, A.; Shvets, A. TernausNetV2: Fully Convolutional Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; Volume 2018. [Google Scholar]
- Wagner, F.H.; Dalagnol, R.; Tarabalka, Y.; Segantine, T.Y.F.; Thomé, R.; Hirye, M.C.M. U-Net-Id, an Instance Segmentation Model for Building Extraction from Satellite Images-Case Study in the Joanopolis City, Brazil. Remote Sens. 2020, 12, 1544. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. Pointrend: Image Segmentation as Rendering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Cheng, F.; Chen, C.; Wang, Y.; Shi, H.; Cao, Y.; Tu, D.; Zhang, C.; Xu, Y. Learning Directional Feature Maps for Cardiac MRI Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Lima, Peru, 2020; pp. 108–117. [Google Scholar]
- Embrechts, H.; Roose, D. A Parallel Euclidean Distance Transformation Algorithm. Comput. Vis. Image Underst. 1996, 63, 15–26. [Google Scholar] [CrossRef]
- Fang, F.; Wu, K.; Zheng, D. A Dataset of Building Instances of Typical Cities in China. Sci. Data Bank 2021. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. SOLOv2: Dynamic and Fast Instance Segmentation. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 2020. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Volume 2019. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; Volume 2019. [Google Scholar]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | AP | AP50 | AP75 | AP↑(%) | AP50↑(%) | AP75↑(%) |
|---|---|---|---|---|---|---|
| Mask R-CNN | 0.411 | 0.657 | 0.451 | - | - | - |
| MS R-CNN | 0.453 | 0.698 | 0.501 | 4.2 | 4.1 | 5.0 |
| PointRend | 0.465 | 0.722 | 0.515 | 5.4 | 6.5 | 6.4 |
| HTC | 0.466 | 0.721 | 0.517 | 5.5 | 6.4 | 6.6 |
| YOLACT | 0.383 | 0.653 | 0.401 | −2.8 | −0.4 | −5.0 |
| SOLOv2 | 0.451 | 0.720 | 0.492 | 4.0 | 6.3 | 4.1 |
| Ours | 0.477 | 0.730 | 0.527 | 6.6 | 7.3 | 7.6 |
| Methods | Modules | Metrics | Improvements | |||||
|---|---|---|---|---|---|---|---|---|
| AG-FPN | DFOM | AP | AP50 | AP75 | AP↑(%) | AP50↑(%) | AP75↑(%) | |
| Baseline | 0.411 | 0.657 | 0.451 | - | - | - | ||
| Baseline+AG-FPN |  | 0.443 | 0.714 | 0.481 | 3.2 | 5.7 | 3.0 | |
| Baseline+DFOM | | 0.432 | 0.672 | 0.493 | 2.1 | 1.5 | 4.2 | |
| Baseline+AG-FPN+DFOM | | | 0.477 | 0.730 | 0.527 | 6.6 | 7.3 | 7.6 |
| Methods | OA (%) | IoU (%) | F1-Score (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|---|
| UNet | 92.18 | 74.32 | 84.51 | 84.21 | 86.24 |
| DeepLabv3+ | 93.19 | 72.81 | 83.47 | 86.63 | 81.97 |
| BRRNet | 92.95 | 73.24 | 83.75 | 82.73 | 86.39 |
| Ours | 94.22 | 77.87 | 87.14 | 84.48 | 91.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Liu, H.; Liu, C.; Kong, J.; Zhang, C. AGDF-Net: Attention-Gated and Direction-Field-Optimized Building Instance Extraction Network. Sensors 2023, 23, 6349. https://doi.org/10.3390/s23146349
Liu W, Liu H, Liu C, Kong J, Zhang C. AGDF-Net: Attention-Gated and Direction-Field-Optimized Building Instance Extraction Network. Sensors. 2023; 23(14):6349. https://doi.org/10.3390/s23146349
Chicago/Turabian StyleLiu, Weizhi, Haixin Liu, Chao Liu, Junjie Kong, and Can Zhang. 2023. "AGDF-Net: Attention-Gated and Direction-Field-Optimized Building Instance Extraction Network" Sensors 23, no. 14: 6349. https://doi.org/10.3390/s23146349