
A Novel Data-Driven Fault Detection Method Based on Stable Kernel Representation for Dynamic Systems

Abstract
:1. Introduction
- Compared with traditional SKR-based FD approaches, the proposed method is more sensitive to fault information by introducing the Hellinger distance (HD) in the residual signal.
- The consensus algorithm is embedded in the information interaction among sensor blocks. Therefore, each sensor block can obtain FD results without global fusion operations, thus remarkably improving FD efficiency.
- It has superior flexibility in the design of FD framework, particularly when the system models are not accurately obtained.
2. Preliminaries
2.1. System Descriptions
2.2. Hellinger Distance
2.3. Average Consensus Algorithm
3. Methodology
3.1. SKR
3.2. Data-Driven Distributed Fault Detection
| Algorithm 1: Off-Line Phase. |
S1. Load the normal (fault-free) data.; S2: Set two indices where and ; S3: while do S4: Constuct I/O data model at each node via (23); S5: Perform QR-decomposition (26) and SVD (27); S6: Identify SKR via (29) and (30); S7: Obtain the residual signals at each sensor node; S8: Calculate Hellinger distance for each residual signal via (34); S9: end while S10: Constuct weight matrix V via (11). |
| Algorithm 2: Online Phase. |
S1. Load the actual test data.; S2: while do S3: Obtain the residual signals under the acutal fault case; S4: Calculate Hellinger distance for each residual signal via (34); S5: end while S6: Calculate using the average consensus algorithm (36); S7: Obtain the identical test statistic via (39); S8: Make a FD logic decision whether a fault has occurred based on (41). |

4. Case Study
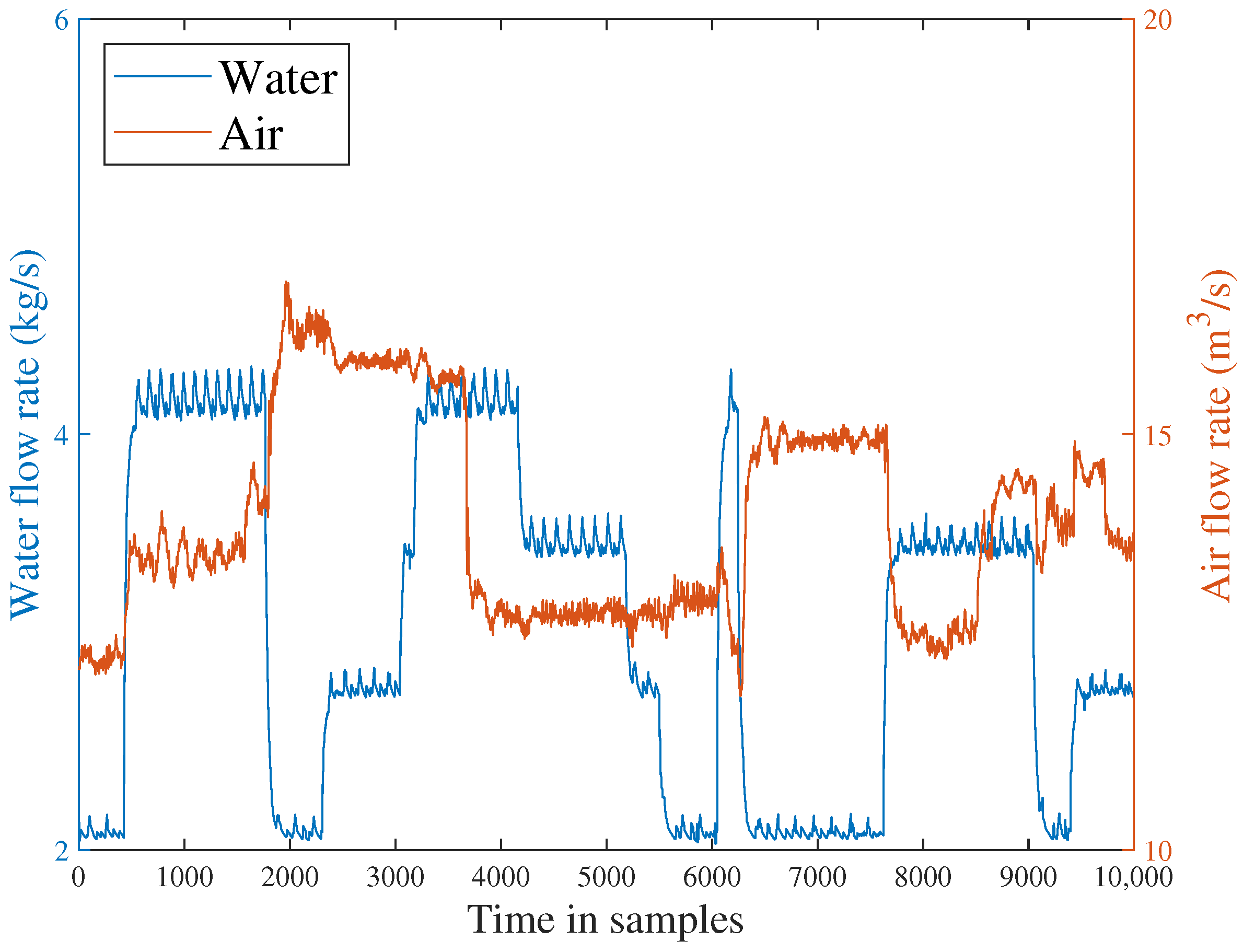
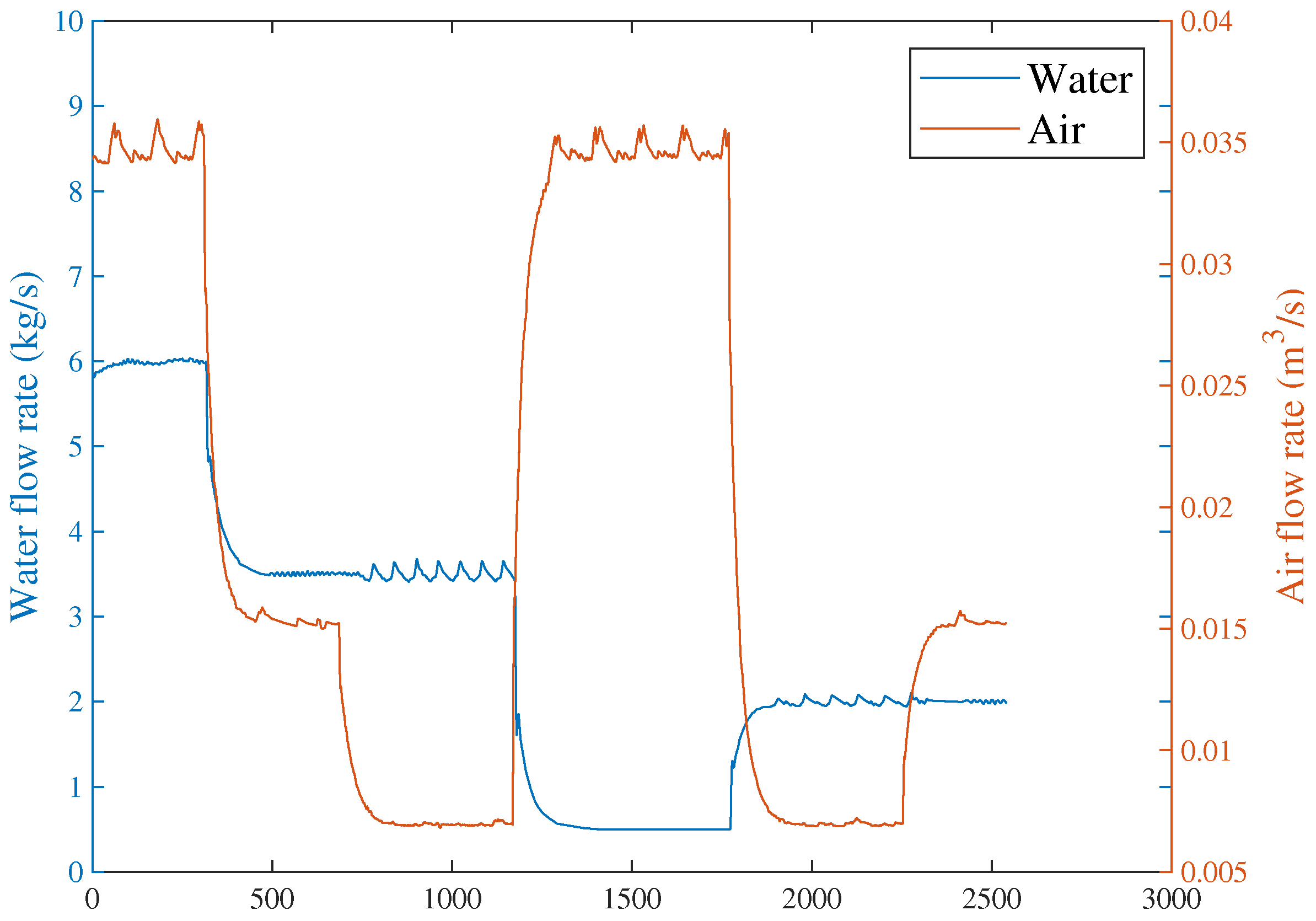
4.1. Facility Description
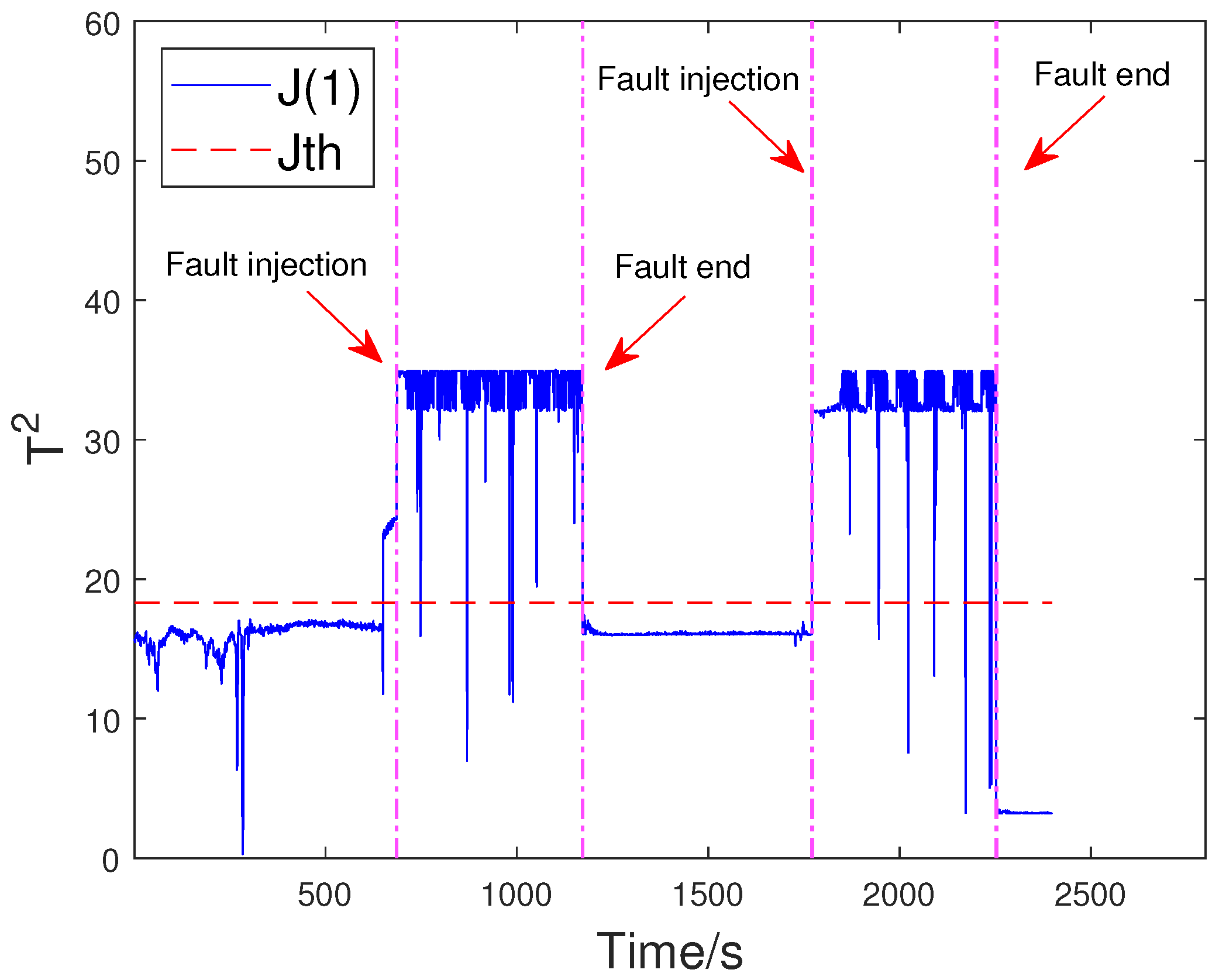
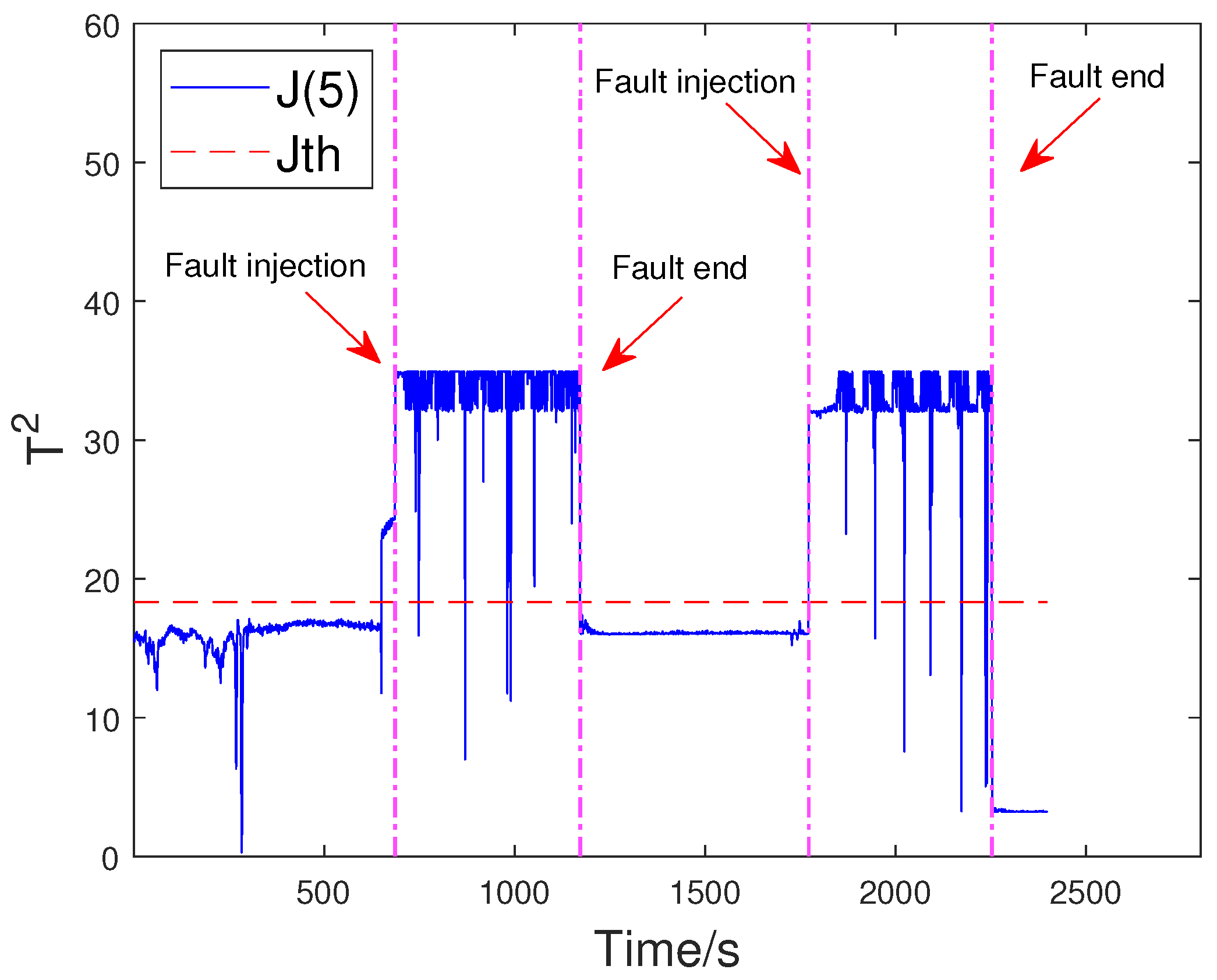
4.2. Fault Injection and Distributed Fault Detection
4.3. Comparison Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, X.P.; Shao, F.; Zhang, Y.H. A Novel Joint Adversarial Domain Adaptation Method for Rotary Machine Fault Diagnosis under Different Working Conditions. Sensors 2022, 22, 9007. [Google Scholar] [CrossRef] [PubMed]
- Leite, D.; Martins, A.; Rativa, D. An Automated Machine Learning Approach for Real-Time Fault Detection and Diagnosis. Sensors 2022, 22, 6138. [Google Scholar] [CrossRef]
- Schmidt, S.; Oberrath, J.; Mercorelli, P. A Sensor Fault Detection Scheme as a Functional Safety Feature for DC-DC Converters. Sensors 2021, 21, 6516. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.T.; Jiang, B. A Review of Fault Detection and Diagnosis for the Traction System in High-Speed Trains. IEEE Trans. Intell. Transp. Syst. 2019, 21, 450–465. [Google Scholar] [CrossRef]
- Petrone, R.; Zheng, Z.; Hissel, D. A review on model-based diagnosis methodologies for PEMFCs. Int. J. Hydrogen Energy 2013, 38, 7077–7709. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Mao, Z.H. Deep PCA Based Real-time Incipient Fault Detection and Diagnosis Methodology for Electrical Drive in High-Speed Trains. IEEE Trans. Veh. Technol. 2018, 67, 4819–4830. [Google Scholar] [CrossRef]
- Tariq, M.F.; Khan, A.Q.; Abid, M. Data-Driven Robust Fault Detection and Isolation of Three-Phase Induction Motor. IEEE Trans. Ind. Electron. 2019, 66, 4707–4715. [Google Scholar] [CrossRef]
- Dong, Y.Y.; Qin, S.J. A novel dynamic PCA algorithm for dynamic data modeling and process monitoring. J. Process Control 2017, 67, 1–11. [Google Scholar] [CrossRef]
- Luo, H.; Yin, S. A Data-Driven Realization of the Control-Performance-Oriented Process Monitoring System. IEEE Trans. Ind. Electron. 2019, 67, 521–530. [Google Scholar] [CrossRef]
- Dong, Y.Y.; Qin, S.J. Dynamic-Inner Partial Least Squares for Dynamic Data Modeling. IFAC-PapersOnLine 2015, 48, 117–122. [Google Scholar] [CrossRef]
- Freeman, P.; Pandita, R.; Srivastava, N. Model-Based and Data-Driven Fault Detection Performance for a Small UAV. IEEE/ASME Trans. Mechatron. 2013, 18, 1300–1309. [Google Scholar] [CrossRef]
- Taouali, O.J. A new online fault detection method based on PCA technique. IMA J. Math. Control Inform. 2014, 31, 487–499. [Google Scholar]
- Zhang, Y.; Yang, Z. Fault detection of non-Gaussian processes based on modified independent component analysis. Chem. Eng. Sci. 2010, 65, 4630–4639. [Google Scholar] [CrossRef]
- Chen, Z.Z.; Steven, D. Canonical correlation analysis-based fault detection methods with application to alumina evaporation process. Control Eng. Pract. 2016, 46, 51–58. [Google Scholar] [CrossRef]
- Chen, H.T.; Chen, Z.; Chai, Z. A Single-Side Neural Network-Aided Canonical Correlation Analysis with Applications to Fault Diagnosis. IEEE Trans. Cybern. 2021, 52, 9454–9466. [Google Scholar] [CrossRef]
- Chen, H.T.; Yi, H.; Jiang, B. Data-Driven Detection of Hot Spots in Photovoltaic Energy Systems. IEEE Trans. Syst. 2019, 49, 1731–1738. [Google Scholar] [CrossRef]
- Wang, C.C.; Too, G. Rotating machine fault detection based on HOS and artificial neural networks. J. Intell. Manuf. 2002, 13, 283–293. [Google Scholar] [CrossRef]
- Liu, X.Q.; Qiu, Y.; Zhang, H.Y. Fault detection and diagnosis of Aero-Starter-Generator based on spectrum analysis and neural network method. Acta Agron. Sin. 2004, 30, 483–487. [Google Scholar]
- Huo, M.M.; Luo, H.; Wang, H. A Distributed Closed-loop Monitoring Approach for Interconnected Industrial System. IEEE Trans. Ind. Electron. 2023, 70, 7362–7372. [Google Scholar] [CrossRef]
- Qin, S.J. An overview of subspace identification. Comput. Chem. Eng. 2006, 30, 1502–1513. [Google Scholar] [CrossRef]
- Yu, C.P.; Verhaegen, M. Subspace Identification of Distributed Homogeneous Systems. IEEE Trans. Autom. Control 2017, 62, 463–468. [Google Scholar] [CrossRef] [Green Version]
- Steven, X.D. A characterization of parity space and its application to robust fault detection. IEEE Trans. Autom. Control 1999, 44, 337–343. [Google Scholar]
- Steven, X.D. Data-driven design of monitoring and diagnosis systems for dynamic processes: A review of subspace technique based schemes and some recent results. J. Process Control 2014, 24, 431–449. [Google Scholar]
- Wang, J.; Qin, S.J. A new subspace identification approach based on principle component analysis. J. Process Control 2002, 42, 841–855. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, M.; Chadli, M.; Wang, Z.; Zhao, D. Unknown input functional observer design for discrete time interval type-2 Takagi-Sugeno fuzzy systems. IEEE Trans. Fuzzy Syst. 2022, 30, 4690–4701. [Google Scholar] [CrossRef]
- Chen, H.T.; Dogru, O.; Huang, B. Distributed Process Monitoring for Multi-Agent Systems Through Cognitive Learning. IEEE Trans. Cognit. Dev. Syst. 2022, 1, 1–12. [Google Scholar] [CrossRef]
- Choi, S.W.; Lee, I.B. Multiblock PLS-based localized process diagnosis. J. Process Control 2005, 15, 295–306. [Google Scholar] [CrossRef]
- Jiang, Q.C.; Yan, X.F. Plant-wide process monitoring based on mutual information–multiblock principal component analysis. ISA Trans. 2014, 53, 1516–1527. [Google Scholar] [CrossRef]
- Chen, Z.W.; Cao, Y.; Zhang, K. A Distributed Canonical Correlation Analysis-based Fault Detection Method for Plant-wide Process Monitoring. IEEE Trans. Ind. Inform. 2019, 15, 2710–2720. [Google Scholar] [CrossRef]
- Jiang, Q.C.; Steven, X.D. Data-Driven Distributed Local Fault Detection for Large-Scale Processes Based on the GA-Regularized Canonical Correlation Analysis. IEEE Trans. Ind. Electron. 2017, 64, 8148–8157. [Google Scholar] [CrossRef]
- Tao, Y.; Shi, H.B.; Tan, S. Hierarchical Latent Variable Extraction and Multisegment Probability Density Analysis Method for Incipient Fault Detection. IEEE Trans. Ind. Inform. 2022, 18, 2244–2254. [Google Scholar] [CrossRef]
- Cong, T.; Tan, R.M. Anomaly Detection and Mode Identification in Multimode Processes Using the Field Kalman Filter. IEEE Control Syst. 2021, 29, 2192–2205. [Google Scholar] [CrossRef]
- Tan, R.M.; Ottewill, J.R.; Thornhill, N.F. Nonstationary Discrete Convolution Kernel for Multimodal Process Monitoring. IEEE Trans. Neural. Netw. Learn. Syst. 2020, 31, 3670–3681. [Google Scholar] [CrossRef] [Green Version]
- Ruiz, C.; Cao, Y.; Samuel, T. Statistical process monitoring of a multiphase flow facility. Control Eng. Pract. 2015, 42, 74–88. [Google Scholar] [CrossRef] [Green Version]
- Stief, A.; Tan, R.M. A heterogeneous benchmark dataset for data analytics: Multiphase flow facility case study. J. Process Control 2019, 79, 41–55. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B. A Newly Robust Fault Detection and Diagnosis Method for High-Speed Trains. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2198–2208. [Google Scholar] [CrossRef]
- Xiao, L.; Boyd, S.; Kim, S.J. Distributed average consensus with least-mean-square deviation. J. Parallel Distrib. Comput. 2007, 67, 33–46. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Boyd, S. Fast linear iterations for distributed averaging. In Proceedings of the 42nd IEEE International Conference on Decision and Control, Maui, HI, USA, 9–12 December 2003. [Google Scholar]
- Olshevsky, A.; Tsitsiklis, J.N. Convergence Speed in Distributed Consensus and Averaging. SIAM Rev. 2011, 53, 747–772. [Google Scholar] [CrossRef] [Green Version]
- Steven, X.D. Data-driven design of fault diagnosis fystem in dynamic process. In Data-Driven Design of Fault Diagnosis and Fault-Tolerant Control Systems; Springer: London, UK, 2014; pp. 107–139. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Location | Description | Units |
|---|---|---|
| PIC501 | Placement of PIC501 valve | (%) |
| PT417 | Pressure in the blending area | barg |
| FIC302 | Placement of FIC302 valve | (%) |
| FIC101 | Placement of FIC101 valve | (%) |
| FT404 | Air flow rate from 2-phase splitter | m/h |
| FT406 | Water flow rate from 2-phase splitter | kg/s |
| PT501 | Pressure in 3-phase splitter | barg |
| LI101 | Level of water tank | m |
| LI502 | Level of 3-phase splitter | (%) |
| LI503 | Level of watercoalescer | (%) |
| FT302 | Air intake velocity | Sm/h |
| FT102 | Water intake velocity | kg/s |
| Detection Framework | FD Strategies | Blockage in the Input Block Separator | Slugging Situation | Obtain FD Result’s Way | |||
|---|---|---|---|---|---|---|---|
| MAR | FAR | MAR | FAR | ||||
| Centralized | Traditional SKR [40] | 0.0452 | 0.0729 | 0.5036 | 0.1693 | Central node | |
| Dynamic principal component analysis [36] | 0.6417 | 0.3461 | 0.5826 | 0.2754 | Central node | ||
| Distributed | The developed HSKR | 0.0323 | 0.0391 | 0.0610 | 0.0454 | Any node | |
| Distributed CCA [29] | 0.3881 | 0.2668 | 0.2076 | 0.3045 | Any node | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Peng, B.; Xie, P.; Cheng, C. A Novel Data-Driven Fault Detection Method Based on Stable Kernel Representation for Dynamic Systems. Sensors 2023, 23, 5891. https://doi.org/10.3390/s23135891
Wang Q, Peng B, Xie P, Cheng C. A Novel Data-Driven Fault Detection Method Based on Stable Kernel Representation for Dynamic Systems. Sensors. 2023; 23(13):5891. https://doi.org/10.3390/s23135891
Chicago/Turabian StyleWang, Qiang, Bo Peng, Pu Xie, and Chao Cheng. 2023. "A Novel Data-Driven Fault Detection Method Based on Stable Kernel Representation for Dynamic Systems" Sensors 23, no. 13: 5891. https://doi.org/10.3390/s23135891