
Proposal of a New System for Essential Oil Classification Based on Low-Cost Gas Sensor and Machine Learning Techniques

Abstract
:1. Introduction
- Proposal of a new system for essential oil characterisation based on a low-cost sensor network and ML techniques;
- Comparison of results includes a larger dataset of essential value data, including five sorts of essential oils and an adulterated sample;
- Evaluate the suitability of using individual data or the mean data for classification;
- Assess the best classification algorithm for the obtained data;
- Calculate metrics, precision, accuracy, recall, and F1-score to allow fair comparison of results with existing, ongoing, and future studies;
- Inclusion of the sensor in a sensor network allowing cloud computing.
2. Related Work
2.1. Sensors of the MQ for Detection of Adulteration in Essential Oils and Applications in Food
2.2. Other Applications of MQ Family Sensors
3. Test Bench
3.1. Prototype Description
3.2. Oil Samples
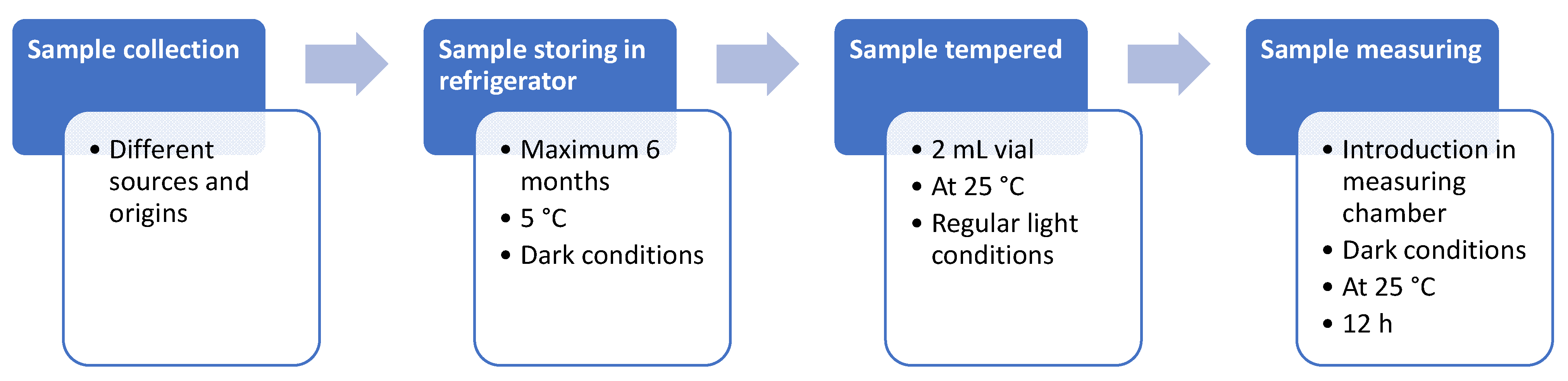
3.3. Measurement Methodology
3.4. Data Preprocessing
3.5. Classification
4. Results
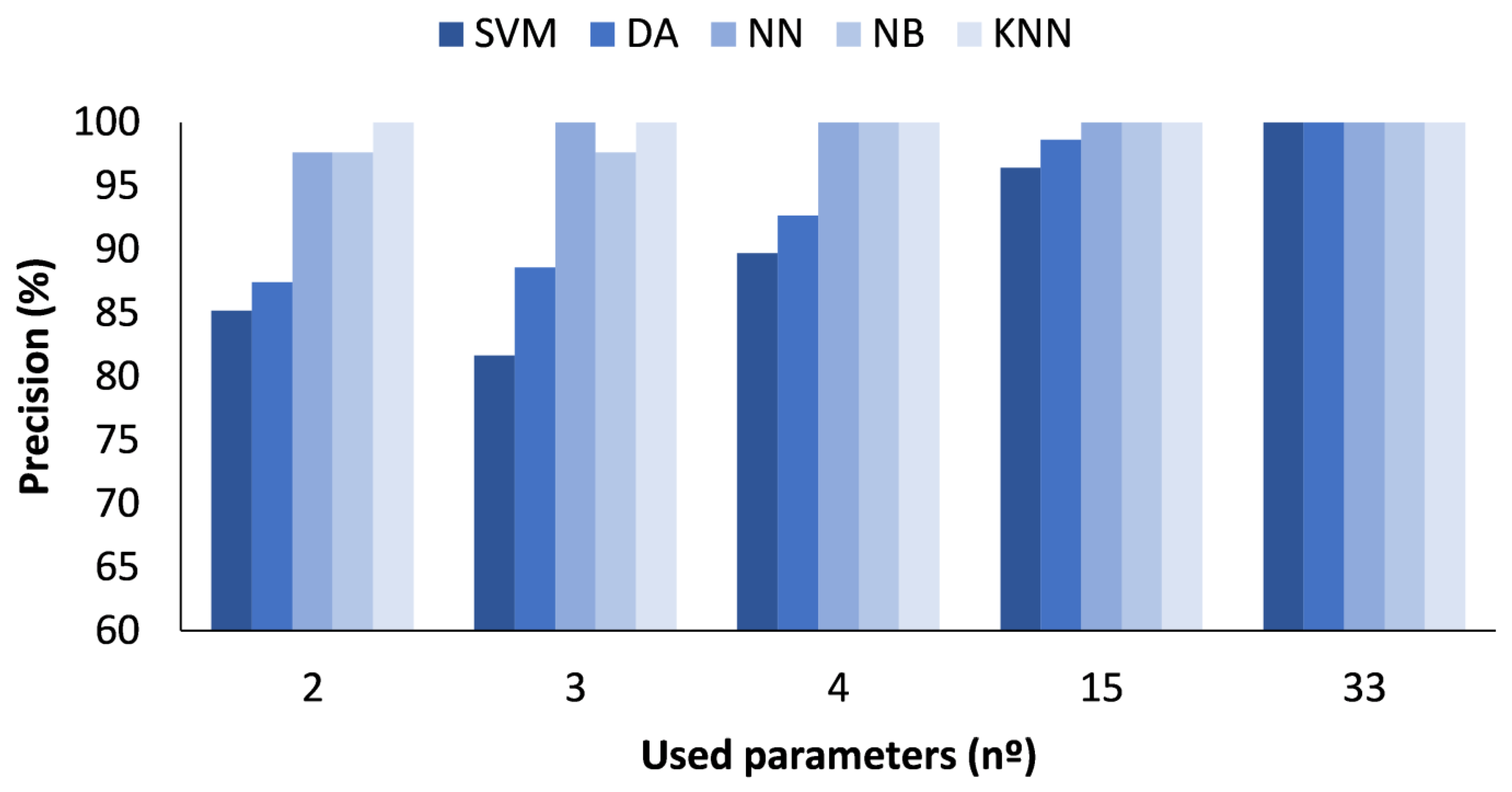
4.1. Data Classification with All Measured Values
4.2. Data Classification with Calculated Mean Values
5. Discussion
5.1. Discussion of Obtained Results and Selection of the Most Suitable Configuration
5.2. Comparison with Existing eNoses for Similar Applications
5.3. Relevance of Proposed Sensor for Essential Oil Characterisation
5.4. Limitations of Performed Tests
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sharmeen, J.B.; Mahomoodally, F.M.; Zengin, G.; Maggi, F. Essential oils as natural sources of fragrance compounds for cosmetics and cosmeceuticals. Molecules 2021, 26, 666. [Google Scholar] [CrossRef] [PubMed]
- Sharifi-Rad, J.; Sureda, A.; Tenore, G.C.; Daglia, M.; Sharifi-Rad, M.; Valussi, M.; Iriti, M. Biological activities of essential oils: From plant chemoecology to traditional healing systems. Molecules 2017, 22, 70. [Google Scholar] [CrossRef] [PubMed]
- Aziz, Z.A.; Ahmad, A.; Setapar, S.H.M.; Karakucuk, A.; Azim, M.M.; Lokhat, D.; Ashraf, G.M. Essential oils: Extraction techniques, pharmaceutical and therapeutic potential-a review. Curr. Drug Metab. 2018, 19, 1100–1110. [Google Scholar] [CrossRef]
- Do TK, T.; Hadji-Minaglou, F.; Antoniotti, S.; Fernandez, X. Authenticity of essential oils. Trends Anal. Chem. 2015, 66, 146–157. [Google Scholar]
- Capetti, F.; Marengo, A.; Cagliero, C.; Liberto, E.; Bicchi, C.; Rubiolo, P.; Sgorbini, B. Adulteration of essential oils: A multitask issue for quality control. Three case studies: Lavandula angustifolia Mill., Citrus limon (L.) Osbeck and Melaleuca alternifolia (Maiden & Betche) cheel. Molecules 2021, 26, 5610. [Google Scholar] [PubMed]
- Tisserand, R.; Young, R. Essential Oil Safety: A Guide for Health Care Professionals; Elsevier Health Sciences: Mumbai, India, 2013. [Google Scholar]
- Lemmens-Gruber, R. Adverse Effects and Intoxication with Essential Oils. In Handbook of Essential Oils; CRC Press: Boca Raton, FL, USA, 2020; pp. 517–541. [Google Scholar]
- Dubnicka, M.; Cromwell, B.; Levine, M. Investigation of the Adulteration of Essential Oils by GC-MS. Curr. Anal. Chem. 2020, 16, 965–969. [Google Scholar] [CrossRef]
- Jalali-Heravi, M.; Moazeni-Pourasil, R.S.; Sereshti, H. Elimination of chromatographic and mass spectrometric problems in GC–MS analysis of Lavender essential oil by multivariate curve resolution techniques: Improving the peak purity assessment by variable size moving window-evolving factor analysis. J. Chromatogr. B 2015, 983, 83–89. [Google Scholar] [CrossRef]
- Wojnowski, W.; Majchrzak, T.; Dymerski, T.; Gębicki, J.; Namieśnik, J. Portable electronic nose based on electrochemical sensors for food quality assessment. Sensors 2017, 17, 2715. [Google Scholar] [CrossRef] [Green Version]
- Burgués, J.; Esclapez, M.D.; Doñate, S.; Marco, S. RHINOS: A lightweight portable electronic nose for real-time odor quantification in wastewater treatment plants. IScience 2021, 24, 103371. [Google Scholar] [CrossRef]
- Yan, J.; Guo, X.; Duan, S.; Jia, P.; Wang, L.; Peng, C.; Zhang, S. Electronic nose feature extraction methods: A review. Sensors 2015, 15, 27804–27831. [Google Scholar] [CrossRef] [Green Version]
- Deshmukh, S.; Bandyopadhyay, R.; Bhattacharyya, N.; Pandey, R.A.; Jana, A. Application of electronic nose for industrial odors and gaseous emissions measurement and monitoring—An overview. Talanta 2015, 144, 329–340. [Google Scholar] [CrossRef] [PubMed]
- Wilson, D. Chemical sensors for farm-to-table monitoring of fruit quality. Sensors 2021, 21, 1634. [Google Scholar] [CrossRef] [PubMed]
- Khorramifar, A.; Karami, H.; Wilson, A.D.; Sayyah AH, A.; Shuba, A.; Lozano, J. Grape cultivar identification and classification by machine olfaction analysis of leaf volatiles. Chemosensors 2022, 10, 125. [Google Scholar] [CrossRef]
- Khorramifar, A.; Rasekh, M.; Karami, H.; Lozano, J.; Gancarz, M.; Łazuka, E.; Łagód, G. Determining the shelf life and quality changes of potatoes (Solanum tuberosum) during storage using electronic nose and machine learning. PLoS ONE 2023, 18, e0284612. [Google Scholar] [CrossRef] [PubMed]
- Tatli, S.; Mirzaee-Ghaleh, E.; Rabbani, H.; Karami, H.; Wilson, A.D. Rapid detection of urea fertiliser effects on voc emissions from cucumber fruits using a MOS E-Nose Sensor Array. Agronomy 2022, 12, 35. [Google Scholar] [CrossRef]
- Rusinek, R.; Siger, A.; Gawrysiak-Witulska, M.; Rokosik, E.; Malaga-Toboła, U.; Gancarz, M. Application of an electronic nose for determination of pre-pressing treatment of rapeseed based on the analysis of volatile compounds contained in pressed oil. Int. J. Food Sci. Technol. 2020, 55, 2161–2170. [Google Scholar] [CrossRef]
- Rasekh, M.; Karami, H.; Wilson, A.D.; Gancarz, M. Classification and identification of essential oils from herbs and fruits based on a MOS electronic-nose technology. Chemosensors 2021, 9, 142. [Google Scholar] [CrossRef]
- Viciano-Tudela, S.; Sendra, S.; Parra, L.; Jimenez, J.M.; Lloret, J. Proposal of a Gas Sensor-Based Device for Detecting Adulteration in Essential Oil of Cistus ladanifer. Sustainability 2023, 15, 3357. [Google Scholar] [CrossRef]
- Rasekh, M.; Karami, H.; Wilson, A.D.; Gancarz, M. Performance analysis of MAU-9 electronic-nose MOS sensor array components and ANN classification methods for discrimination of herb and fruit essential oils. Chemosensors 2021, 9, 243. [Google Scholar] [CrossRef]
- Fuentes, S.; Viejo, C.G. Novel use of e-noses for digital agriculture, food, and beverage applications. In Nanotechnology-Based E-Noses; Woodhead Publishing: Sawston, UK, 2023; pp. 415–432. [Google Scholar]
- Mahmood, L.; Ghommem, M.; Bahroun, Z. Smart Gas Sensors: Materials, Technologies, Practical Applications, and Use of Machine Learning—A Review. J. Appl. Comput. Mech. 2023, 9, 775–803. [Google Scholar]
- Nunes, C.A.; Ribeiro, M.N.; de Carvalho TC, L.; Ferreira, D.D.; de Oliveira, L.L.; Pinheiro AC, M. Artificial intelligence in sensory and consumer studies of food products. Curr. Opin. Food Sci. 2023, 50, 101002. [Google Scholar] [CrossRef]
- Mohammadian, N.; Ziaiifar, A.M.; Mirzaee-Ghaleh, E.; Kashaninejad, M.; Karami, H. Nondestructive Technique for Identifying Adulteration and Additives in Lemon Juice Based on Analysing Volatile Organic Compounds (VOCs). Processes 2023, 11, 1531. [Google Scholar] [CrossRef]
- Cervera-Gascó, J.; Rabadán, A.; López-Mata, E.; Álvarez-Ortí, M.; Pardo, J.E. Development of the POLIVAR model using neural networks as a tool to predict and identify monovarietal olive oils. Food Control. 2023, 143, 109278. [Google Scholar] [CrossRef]
- Liu, W.; Sun, S.; Liu, Y.; Deng, H.; Hong, F.; Liu, C.; Zheng, L. Determination of benzo (a) pyrene in peanut oil based on Raman spectroscopy and machine learning methods. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 299, 122806. [Google Scholar] [CrossRef] [PubMed]
- Karami, H.; Rasekh, M.; Mirzaee-Ghaleh, E. Application of the Enose machine system to detect adulterations in mixed edible oils using chemometrics methods. J. Food Process. Preserv. 2020, 44, e14696. [Google Scholar] [CrossRef]
- Yavuzer, E. Determination of fish quality parameters with low cost electronic nose. Food Biosci. 2021, 41, 100948. [Google Scholar] [CrossRef]
- Wakhid, S.; Sarno, R.; Sabilla, S.I. The effect of gas concentration on detection and classification of beef and pork mixtures using Enose. Comput. Electron. Agric. 2022, 195, 106838. [Google Scholar] [CrossRef]
- Wonohardjo, E.P.; Kusuma, G.P. Air pollution mapping using mobile sensor based on internet of things. Procedia Comput. Sci. 2019, 157, 638–645. [Google Scholar] [CrossRef]
- Salinas Alvarez, C.; Sierra-Sosa, D.; Garcia-Zapirain, B.; Yoder-Himes, D.; Elmaghraby, A. Detection of volatile compounds emitted by bacteria in wounds using gas sensors. Sensors 2019, 19, 1523. [Google Scholar] [CrossRef] [Green Version]
- Subandri, M.A.; Sarno, R. Enose sensor array optimisation based on volatile compound concentration data. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2019; Volume 1201, No. 1, p. 012003. [Google Scholar]
- Fakra, D.A.H.; Andriatoavina, D.A.S.; Razafindralambo, N.A.M.N.; Abdallah Amarillis, K.; Andriamampianina, J.M.M. A simple and low-cost integrative sensor system for methane and hydrogen measurement. Sens. Int. 2020, 1, 100032. [Google Scholar] [CrossRef]
- Abdulrazzak, I.A.; Bierk, H.M.; Ahmed, A.F. Detection of H 2 S Gas Concentration in Oil Refinery Stations by Using Drone. In Artificial Intelligence and Renewables Towards an Energy Transition 4; Springer International Publishing: Parañaque City, The Philippines, 2021; pp. 649–658. [Google Scholar]
- Sanger, J.B.; Sitanayah, L.; Ahmad, I. A Sensor-based Garbage Gas Detection System. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Virtual, 27–30 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1347–1353. [Google Scholar]
- Kiki MP, A.; Ahouandjinou SA, R.; Assogba, K.M.; Sama, Y.N. An Enose Using Metal Oxide Semiconductor Sensors Array to Recognise the Odors of Fall Armyworm Pest for Its Early Detection in the Farm. In Innovations and Interdisciplinary Solutions for Underserved Areas, Proceedings of the 5th EAI International Conference, InterSol 2022, Abuja, Nigeria, 23–24 March 2022; Springer Nature: Cham, Switzerland, 2023; pp. 69–81. [Google Scholar]
- Lee, J.H.; Vo, H.T.; Kwon, G.J.; Kim, H.G.; Kim, J.Y. Multi-Camera-Based Sorting System for Surface Defects of Apples. Sensors 2023, 23, 3968. [Google Scholar] [CrossRef] [PubMed]
- Zarezadeh, M.R.; Aboonajmi, M.; Varnamkhasti, M.G.; Azarikia, F. Olive oil classification and fraud detection using Enose and ultrasonic system. Food Anal. Methods 2021, 14, 2199–2210. [Google Scholar] [CrossRef]
- Zarezadeh, M.R.; Aboonajmi, M. The Effect of Data Fusion on Improving the Accuracy of Olive Oil Quality Measurement. Food Chem. X 2023, 18, 100622. [Google Scholar] [CrossRef] [PubMed]
- Schroeder, V.; Evans, E.D.; Wu, Y.C.M.; Voll, C.C.A.; McDonald, B.R.; Savagatrup, S.; Swager, T.M. Chemiresistive sensor array and machine learning classification of food. ACS Sens. 2019, 4, 2101–2108. [Google Scholar] [CrossRef]
- Huang, Y.; Doh, I.J.; Bae, E. Design and validation of a portable machine learning-based electronic nose. Sensors 2021, 21, 3923. [Google Scholar] [CrossRef]
- Oates, M.J.; González-Teruel, J.D.; Ruiz-Abellon, M.C.; Guillamon-Frutos, A.; Ramos, J.A.; Torres-Sánchez, R. Using a low-cost Components enose for Basic Detection of Different Foodstuffs. IEEE Sens. J. 2022, 22, 13872–13881. [Google Scholar] [CrossRef]
- Amkor, A.; El Barbri, N. Artificial intelligence methods for classification and prediction of potatoes harvested from fertilised soil based on a sensor array response. Sens. Actuators A Phys. 2023, 349, 114106. [Google Scholar] [CrossRef]
- Yousfi, S.; Marín, J.; Parra, L.; Lloret, J.; Mauri, P.V. Remote sensing devices as key methods in the advanced turfgrass phenotyping under different water regimes. Agric. Water Manag. 2022, 266, 107581. [Google Scholar] [CrossRef]
- García, L.; Parra, L.; Jimenez, J.M.; Parra, M.; Lloret, J.; Mauri, P.V.; Lorenz, P. Deployment strategies of soil monitoring WSN for precision agriculture irrigation scheduling in rural areas. Sensors 2021, 21, 1693. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Acronym | Nº of Individual Measurements |
|---|---|---|
| Cistus ladanifer | Cla | 1813 |
| Pinus pinaster | Pp | 1213 |
| Cistus ladanifer + Pinus pinaster | CP | 1241 |
| Melaleuca alternifolia | Ma | 410 |
| Citrus limonum | Cli | 2062 |
| Red fruits | Rf | 375 |
| Parameter | Maximum Value | Minimum Value | Mean Value | Standard Deviation |
|---|---|---|---|---|
| MQ2–1 | 116,856.0 | 0.0 | 434.8 | 3010.0 |
| MQ2–2 | 933.0 | 31.0 | 160.1 | 146.8 |
| MQ2–3 | 11,741.0 | 1.0 | 1164.1 | 1693.3 |
| MQ2–4 | 2591.0 | 1.0 | 326.8 | 384.8 |
| MQ2–6 | 1157.0 | 41.0 | 210.2 | 186.0 |
| MQ3–2 | 266.0 | 0.0 | 9.3 | 13.1 |
| MQ3–3 | 788.0 | 0.0 | 8.8 | 10.8 |
| MQ3–8 | 36,118.0 | 0.0 | 15.0 | 441.0 |
| MQ4–2 | 153,780.0 | 24.0 | 1308.9 | 2059.9 |
| MQ4–3 | 878,916.0 | 0.0 | 763.0 | 11,344.1 |
| MQ4–4 | 85,719.0 | 0.0 | 456.9 | 1602.7 |
| MQ4–5 | 3012.0 | 79.0 | 607.2 | 422.1 |
| MQ4–9 | 100,708.0 | 0.0 | 1861.9 | 3164.3 |
| MQ5–1 | 332.0 | 19.0 | 96.8 | 56.0 |
| MQ5–2 | 1183.0 | 32.0 | 160.4 | 148.0 |
| MQ5–3 | 7033.0 | 81.0 | 1223.1 | 1153.1 |
| MQ5–4 | 20,971.0 | 1.0 | 1220.1 | 1014.9 |
| MQ5–5 | 356.0 | 59.0 | 155.8 | 56.4 |
| MQ6–1 | 34,088.0 | 664.0 | 2540.4 | 1659.9 |
| MQ6–2 | 2811.0 | 212.0 | 475.0 | 173.1 |
| MQ6–3 | 153,519,925.0 | 44.0 | 92,054.9 | 3,167,065.0 |
| MQ6–4 | 2,501,354.0 | 1.0 | 7710.1 | 35,559.1 |
| MQ6–5 | 3939.0 | 288.0 | 670.6 | 265.1 |
| MQ7–1 | 280.0 | 14.0 | 94.3 | 34.3 |
| MQ7–2 | 903.0 | 0.0 | 13.3 | 33.0 |
| MQ7–3 | 297.0 | 51.0 | 87.7 | 37.1 |
| MQ7–4 | 1,891,349.0 | 1.0 | 3331.7 | 27,593.2 |
| MQ7–5 | 25,483,977.0 | 1.0 | 4139.3 | 302,144.1 |
| MQ8–1 | 10,450.0 | 3298.0 | 6410.1 | 1894.5 |
| MQ8–2 | 7005.0 | 17.0 | 1554.7 | 1023.7 |
| MQ8–3 | 7,913,118.0 | 1.0 | 232,761.3 | 293,845.6 |
| MQ8–4 | 6031.0 | 134.0 | 2269.8 | 970.0 |
| MQ8–5 | 70,742.0 | 0.0 | 3622.5 | 3862.6 |
| ML Technique | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| DA | 0.91 | 0.91 | 0.82 | 0.97 |
| NB | 0.94 | 0.97 | 0.95 | 0.99 |
| SVM | 0.89 | 0.85 | 0.85 | 0.97 |
| KNN | 1.00 | 0.99 | 0.99 | 1.00 |
| NN | 0.97 | 0.96 | 0.96 | 0.99 |
| Year | Nº of Tech. | Used ML | Type | Applications | Products | Nº of Sensors | For | Accuracy | Precision | Recall | F1-Score | Ref. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020 | 5 | ANN and LDA | Multiclass | Adulterated products | Edible oils | 8 | ANN | 0.9893 | 0.975 | - | - | [28] |
| LDA | 0.942 | 0.897 | - | - | ||||||||
| 2021 | 3 | ANN | Multiclass | Adulterated products | Essential oils | 9 | Mult. | 0.989 | - | - | - | [21] |
| Binary | Bin. | 1 | - | - | - | |||||||
| 2021 | 7 | GBC, SVM, NB, KNN, NN, and AB | Multiclass | Adulterated products | Olive oil | 8 | GBC | - | - | - | - | [39] |
| SVM | - | - | - | - | ||||||||
| NB | - | - | - | - | ||||||||
| KNN | - | - | - | - | ||||||||
| ANN | - | - | - | - | ||||||||
| AB | - | - | - | - | ||||||||
| 2022 | 4 | SVM, DTC, and NN | Multiclass | Adulterated products | Beef and pork meat | 9 | SVM | 0.8742 | - | - | - | [30] |
| DTC | 0.8541 | - | - | - | ||||||||
| ANN | 0.8885 | - | - | - | ||||||||
| 2023 | 2 | ANN | Multiclass | Adulterated products | Essential oil | 7 | ANN | - | - | - | - | [20] |
| 2023 | 6 | ANN, SVM, KNN, NB, and AB | Multiclass | Adulterated products | Olive oil | 8 | ANN | 0.6752 | - | - | - | [40] |
| SVM | 0.8652 | - | - | - | ||||||||
| KNN | 0.8989 | - | - | - | ||||||||
| BN | 0.8202 | - | - | - | ||||||||
| AB | 0.3483 | - | - | - | ||||||||
| 2019 | 2 | KNN and f-RF | Multiclass | Identify products | General food | 16 | KNN | 0.69 | - | - | - | [43] |
| RF | 0.78 | - | - | - | ||||||||
| 2019 | 7 | KNN, CART, NB, SVM, LSVM, and RF | Binary | Identify products | Banana | 10 | KNN | 0.72 | - | - | - | [33] |
| CART | 0.654 | - | - | - | ||||||||
| NB | 0.602 | - | - | - | ||||||||
| SVM | 0.494 | - | - | - | ||||||||
| LSVM | 0.628 | - | - | - | ||||||||
| RF | 0.718 | - | - | - | ||||||||
| 2021 | 4 | QDA, QSVM, CSVM, and KNN | Multiclass | Identify products | Edible oils | 4 | QDA | 0.589 | - | 0.69 | - | [44] |
| QSVM | 0.953 | - | 0.966 | - | ||||||||
| CSVM | 0.802 | - | 0.851 | - | ||||||||
| KNN | 0.811 | - | 0.858 | - | ||||||||
| 2022 | 3 | DA and RF | Multiclass | Identify products | Fish and meat | 8 | RF | 0.95 | - | - | - | [41] |
| DA | - | - | - | - | ||||||||
| 2023 | 1 | KNN | Binary | Identify products | Potatoes | 5 | KNN | 0.90 | - | - | - | [42] |
| 2023 | 5 | DA, SVM, BN, KNN, and NN | Multiclass | Identify product | Essential oils | 7 | DA | 0.9112 | 0.9092 | 0.4105 | 97.46 | Proposed |
| NB | 0.9401 | 0.9651 | 0.4734 | 98.83 | ||||||||
| SVM | 0.8874 | 0.8519 | 0.4234 | 96.82 | ||||||||
| KNN | 0.9982 | 0.9893 | 0.4960 | 99.89 | ||||||||
| NN | 0.9671 | 0.9609 | 0.4816 | 99.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viciano-Tudela, S.; Parra, L.; Navarro-Garcia, P.; Sendra, S.; Lloret, J. Proposal of a New System for Essential Oil Classification Based on Low-Cost Gas Sensor and Machine Learning Techniques. Sensors 2023, 23, 5812. https://doi.org/10.3390/s23135812
Viciano-Tudela S, Parra L, Navarro-Garcia P, Sendra S, Lloret J. Proposal of a New System for Essential Oil Classification Based on Low-Cost Gas Sensor and Machine Learning Techniques. Sensors. 2023; 23(13):5812. https://doi.org/10.3390/s23135812
Chicago/Turabian StyleViciano-Tudela, Sandra, Lorena Parra, Paula Navarro-Garcia, Sandra Sendra, and Jaime Lloret. 2023. "Proposal of a New System for Essential Oil Classification Based on Low-Cost Gas Sensor and Machine Learning Techniques" Sensors 23, no. 13: 5812. https://doi.org/10.3390/s23135812