

A Scalable Approach to Independent Vector Analysis by Shared Subspace Separation for Multi-Subject fMRI Analysis
 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. JBSS Problem Formulation
3. Methods for JBSS
3.1. MCCA
3.2. IVA
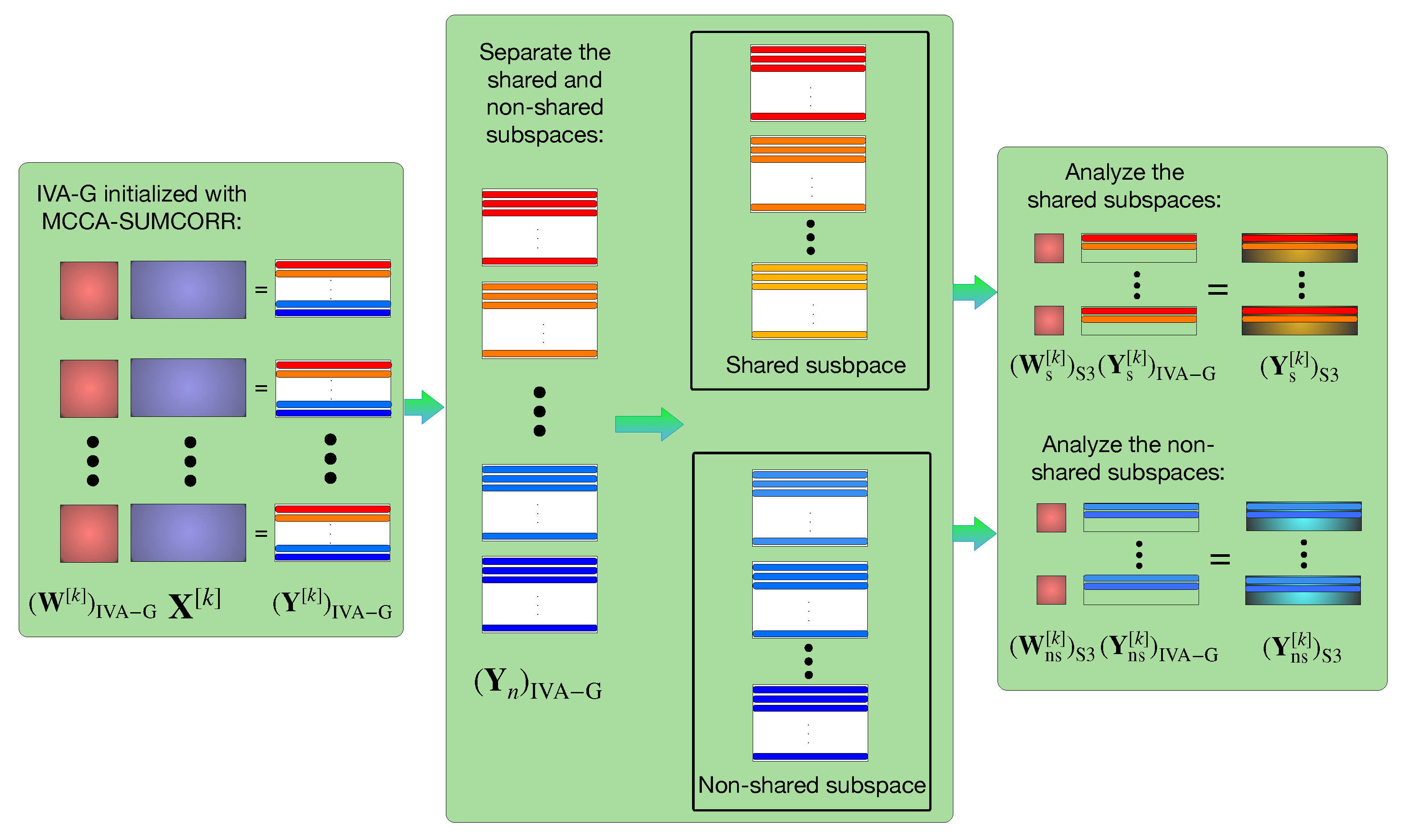
4. IVA by Shared Subspace Separation
4.1. IVA with SUMCORR Initialization
4.2. Shared Subspace Identification and Separation
4.3. IVA-S3 Framework
| Algorithm 1 IVA-S3 |
| Require: datasets = , …, MCCA SUMCORR () IVA-G () for do if then Shared subspace ← else Non-shared subspace ← end if end for shared subspace, non-shared subspace IVA (), IVA () , |
5. Results
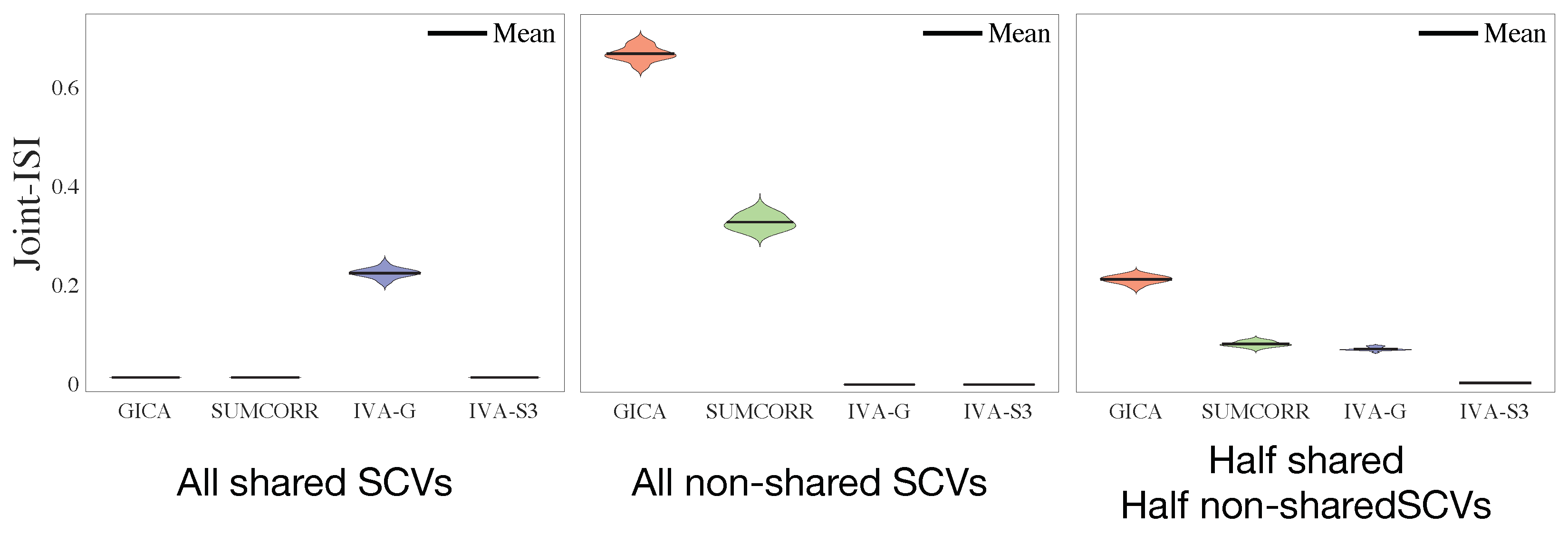
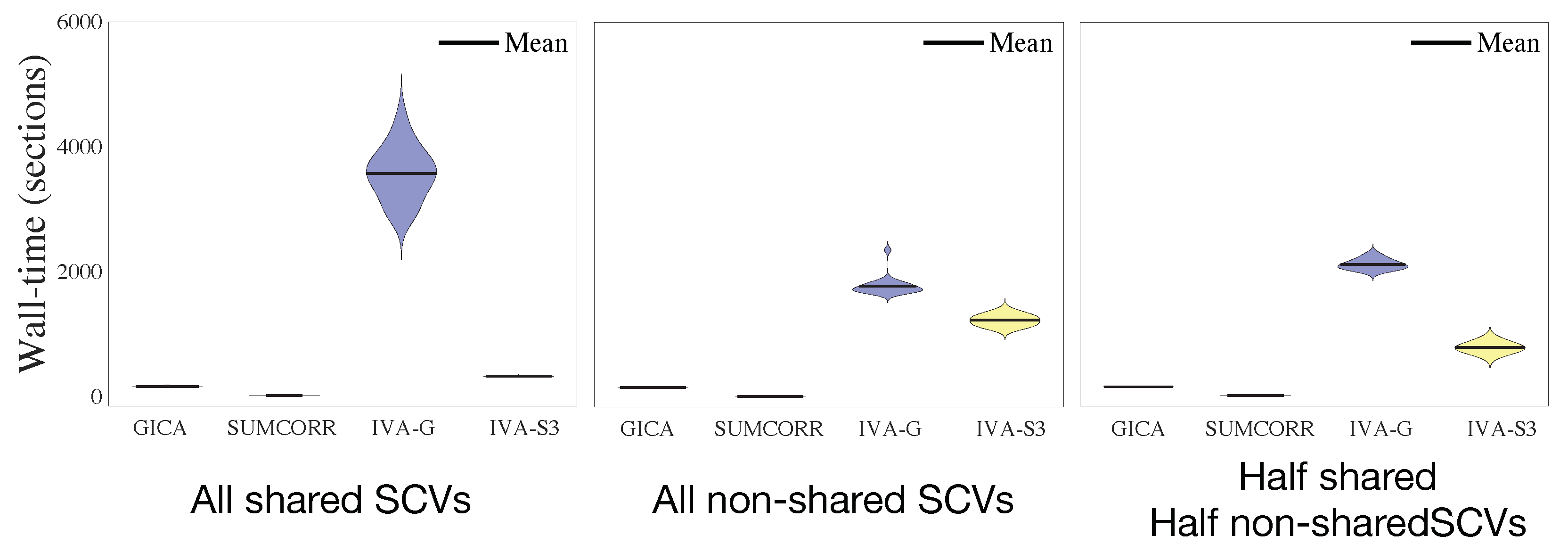
5.1. Performance with Simulated Data
- All 50 SCVs are shared;
- All 50 SCVs are non-shared;
- Half (25) are shared, and half (25) are non-shared.
- When all SCVs are shared, group-ICA and SUMCORR perform well, as their assumption that all SCVs are shared is a perfect model match with the simulated data. However, the IVA-G performs poorly because it heavily overparameterizes the SCVs (representing each effectively one-dimensional SCV by a K = 100 dimensional multivariate Gaussian). In contrast, the IVA-S3 provides a better estimation, as the SUMCORR initialization compensates for the shared SCVs.
- When all SCVs are non-shared, group-ICA and SUMCORR fail due to a complete model mismatch, whereas both the IVA-G and the IVA-S3 perform well because they are better suited to the estimation of more complex SCVs where greater variability exists across the datasets.
- When half of the SCVs are shared and half are non-shared, group-ICA and SUMCORR perform poorly, strictly because of the non-shared SCVs, whereas the IVA-G performs poorly, strictly because of the shared SCVs. In contrast, the IVA-S3 is able to estimate both shared and non-shared SCVs well. This is because the IVA-S3 leverages the strengths of both the SUMCORR and IVA by initializing the IVA with the SUMCORR estimation.
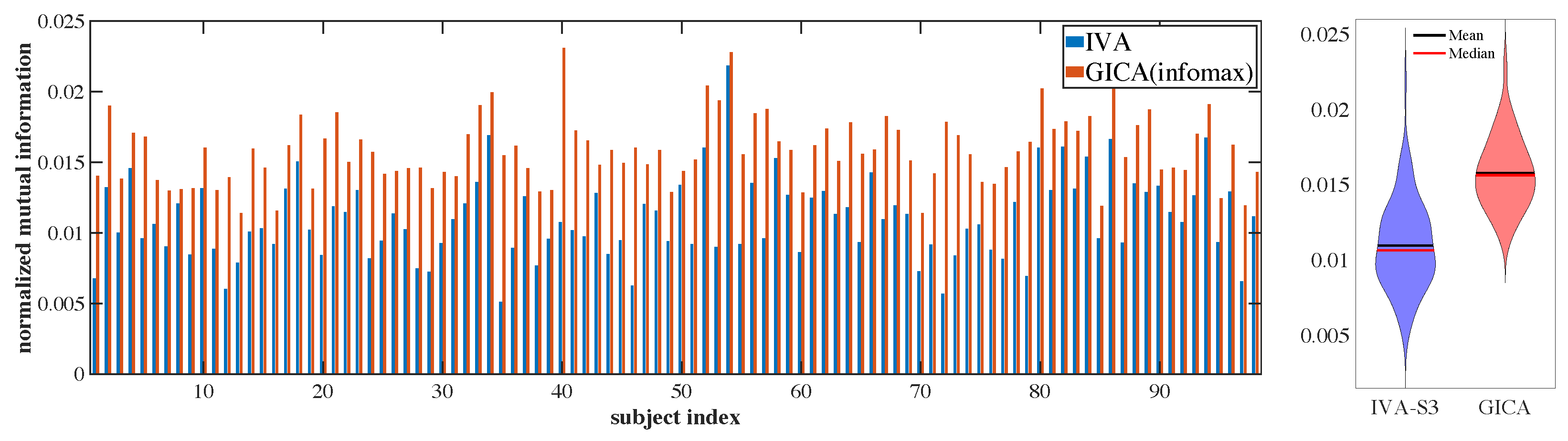
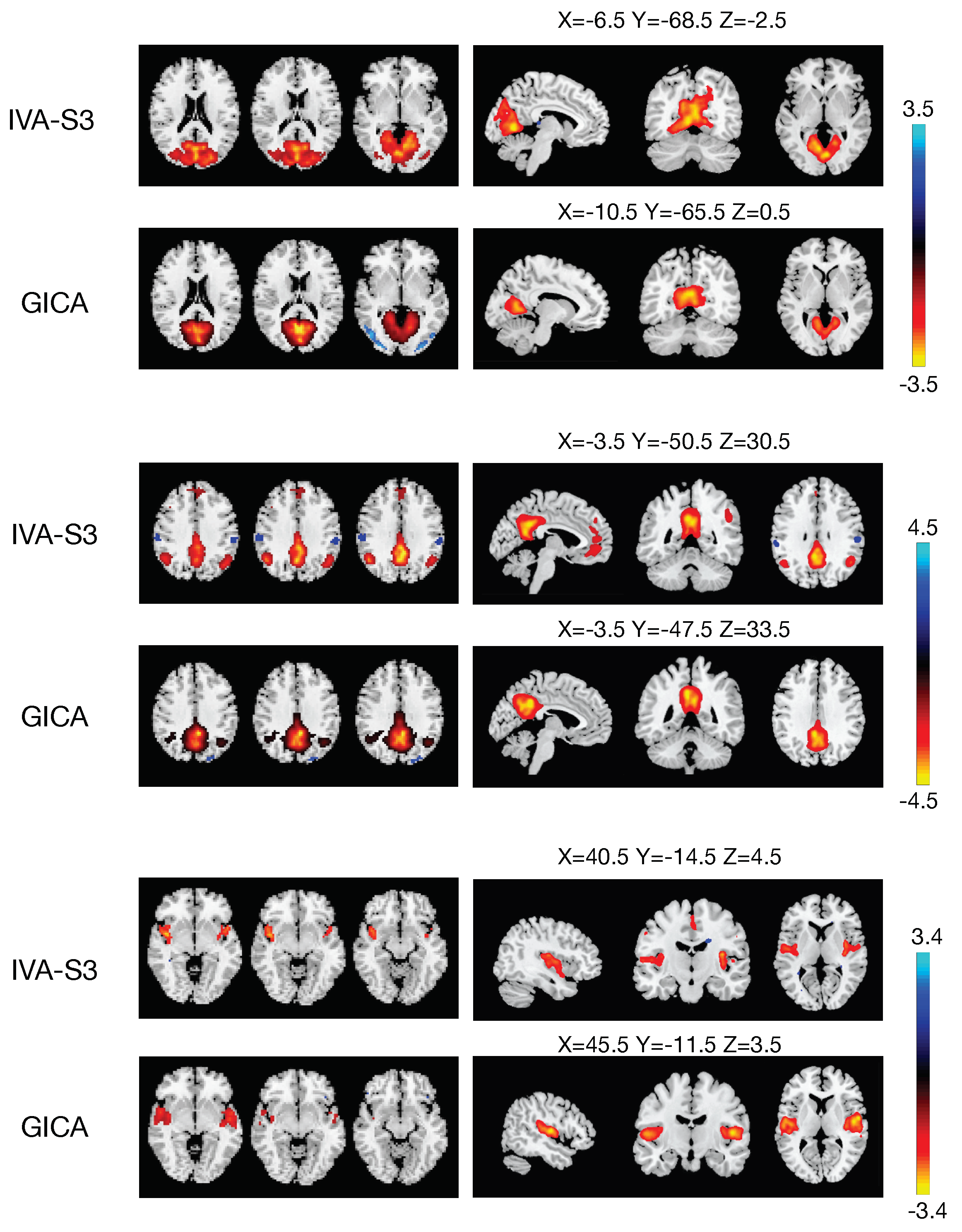
5.2. Results with Real FMRI Data
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BSS | Blind source separation |
| JBSS | Joint blind source separation |
| fMRI | Functional magnetic resonance imaging |
| CCA | Canonical correlation analysis |
| CVs | Canonical variate |
| MCCA | Multi-set canonical correlation analysis |
| SUMCORR | Maximizing the sum of correlations |
| ICA | Independent component analysis |
| Group-ICA | Group independent component analysis |
| IVA | Independent vector analysis |
| IVA-G | Independent vector analysis with a multivariate Gaussian source prior |
| IVA-L-SOS | Independent vector analysis with a multivariate Laplacian distribution and second-order statistics |
| SCV | Source component vector |
| PCA | Principal component analysis |
| PC | Principal component |
| DMN | Default-mode networks |
| VN | Visual networks |
| MGGD | Multivariate generalized Gaussian distributed |
| IVA-S3 | Independent vector analysis |
References
- Comon, P.; Jutten, C. Handbook of Blind Source Separation, Independent Component Analysis and Applications; Academic Press: Cambridge, MA, USA, 2010. [Google Scholar] [CrossRef]
- Choi, S.; Cichocki, A.; Park, H.M.; Lee, S.Y. Blind Source Separation and Independent Component Analysis: A Review. Neural Inf. Process.-Lett. Rev. 2005, 6, 1–57. [Google Scholar]
- Adali, T.; Anderson, M.; Fu, G.S. Diversity in Independent Component and Vector Analyses: Identifiability, algorithms, and applications in medical imaging. IEEE Signal Process. Mag. 2014, 31, 18–33. [Google Scholar] [CrossRef]
- Long, Q.; Bhinge, S.; Calhoun, V.D.; Adali, T. Independent vector analysis for common subspace analysis: Application to multi-subject fMRI data yields meaningful subgroups of schizophrenia. NeuroImage 2020, 216, 116872. [Google Scholar] [CrossRef] [PubMed]
- Akhonda, M.; Gabrielson, B.; Bhinge, S.; Calhoun, V.D.; Adali, T. Disjoint subspaces for common and distinct component analysis: Application to the fusion of multi-task FMRI data. J. Neurosci. Methods 2021, 358, 109214. [Google Scholar] [CrossRef]
- Anderson, M.; Adali, T.; Li, X.L. Joint Blind Source Separation with Multivariate Gaussian Model: Algorithms and Performance Analysis. IEEE Trans. Signal Process. 2012, 60, 1672–1683. [Google Scholar] [CrossRef]
- Anderson, M.; Fu, G.S.; Phlypo, R.; Adalı, T. Independent Vector Analysis: Identification Conditions and Performance Bounds. IEEE Trans. Signal Process. 2014, 62, 4399–4410. [Google Scholar] [CrossRef] [Green Version]
- Kettenring, J.R. Canonical analysis of several sets of variables. Biometrika 1971, 58, 433–451. [Google Scholar] [CrossRef]
- Li, Y.O.; Adali, T.; Wang, W.; Calhoun, V.D. Joint Blind Source Separation by Multiset Canonical Correlation Analysis. IEEE Trans. Signal Process. 2009, 57, 3918–3929. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.; Eltoft, T.; Lee, T.W. Independent Vector Analysis: An Extension of ICA to Multivariate Components. In Proceedings of the International Conference on Agents, Perth, Australia, 27–28 November 2006. [Google Scholar]
- Nielsen, A. Multiset canonical correlations analysis and multispectral, truly multitemporal remote sensing data. IEEE Trans. Image Process. 2002, 11, 293–305. [Google Scholar] [CrossRef] [Green Version]
- Parra, L.C. Multi-set Canonical Correlation Analysis simply explained. arXiv 2018, arXiv:1802.03759. [Google Scholar]
- Calhoun, V.; Adali, T.; Pearlson, G.; Pekar, J. Erratum: A method for making group inferences from functional MRI data using independent component analysis. Hum. Brain Mapp. 2001, 14, 140–151. [Google Scholar] [CrossRef] [PubMed]
- Beckmann, C.; Mackay, C.; Filippini, N.; Smith, S. Group comparison of resting-state FMRI data using multi-subject ICA and dual regression. NeuroImage 2009, 47, S148. [Google Scholar] [CrossRef]
- Allen, E.A.; Erhardt, E.B.; Wei, Y.; Eichele, T.; Calhoun, V.D. Capturing inter-subject variability with group independent component analysis of fMRI data: A simulation study. NeuroImage 2012, 59, 4141–4159. [Google Scholar] [CrossRef] [Green Version]
- Erhardt, E.; Rachakonda, S.; Bedrick, E.; Allen, E.; Adali, T.; Calhoun, V. Comparison of Multi-Subject ICA Methods for Analysis of fMRI Data. Hum. Brain Mapp. 2011, 32, 2075–2095. [Google Scholar] [CrossRef] [Green Version]
- Laney, J.; Westlake, K.; Ma, S.; Woytowicz, E.; Adali, T. Capturing subject variability in data driven fMRI analysis: A graph theoretical comparison. In Proceedings of the 2014 48th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 19–21 March 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Ma, S.; Calhoun, V.; Phlypo, R.; Adali, T. Dynamic changes of spatial functional network connectivity in healthy individuals and schizophrenia patients using independent vector analysis. NeuroImage 2014, 90, 196–206. [Google Scholar] [CrossRef] [Green Version]
- Bhinge, S.; Long, Q.; Levin-Schwartz, Y.; Boukouvalas, Z.; Calhoun, V.D.; Adalı, T. Non-orthogonal constrained independent vector analysis: Application to data fusion. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2666–2670. [Google Scholar]
- Levin-Schwartz, Y.; Song, Y.; Schreier, P.J.; Calhoun, V.D.; Adalı, T. Sample-poor estimation of order and common signal subspace with application to fusion of medical imaging data. NeuroImage 2016, 134, 486–493. [Google Scholar] [CrossRef] [Green Version]
- Richard, H.; Ablin, P.; Thirion, B.; Gramfort, A.; Hyvarinen, A. Shared Independent Component Analysis for Multi-Subject Neuroimaging. In Advances in Neural Information Processing Systems, Proceedings of the NeurIPS 2021, Online, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 34, pp. 29962–29971. [Google Scholar]
- Bhinge, S.; Mowakeaa, R.; Calhoun, V.D.; Adalı, T. Extraction of Time-Varying Spatiotemporal Networks Using Parameter-Tuned Constrained IVA. IEEE Trans. Med. Imaging 2019, 38, 1715–1725. [Google Scholar] [CrossRef]
- Calhoun, V.; Adali, T. Unmixing fMRI with independent component analysis. IEEE Eng. Med. Biol. Mag. 2006, 25, 79–90. [Google Scholar] [CrossRef]
- Adali, T.; Kantar, F.; Akhonda, M.A.B.S.; Strother, S.; Calhoun, V.D.; Acar, E. Reproducibility in Matrix and Tensor Decompositions: Focus on model match, interpretability, and uniqueness. IEEE Signal Process. Mag. 2022, 39, 8–24. [Google Scholar] [CrossRef] [PubMed]
- Long, Q.; Jia, C.; Boukouvalas, Z.; Gabrielson, B.; Emge, D.; Adali, T. Consistent Run Selection for Independent Component Analysis: Application to Fmri Analysis. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2581–2585. [Google Scholar] [CrossRef]
- Gómez, E.; Gomez-Viilegas, M.; Marín, J. A multivariate generalization of the power exponential family of distributions. Commun. Stat.-Theory Methods 1998, 27, 589–600. [Google Scholar] [CrossRef]
- Iqbal, A.; Seghouane, A.K.; Adalı, T. Shared and Subject-Specific Dictionary Learning (ShSSDL) Algorithm for Multisubject fMRI Data Analysis. IEEE Trans. Biomed. Eng. 2018, 65, 2519–2528. [Google Scholar] [CrossRef] [PubMed]
- Tamminga, C.A.; Ivleva, E.I.; Keshavan, M.S.; Pearlson, G.D.; Clementz, B.A.; Witte, B.P.; Morris, D.W.; Bishop, J.R.; Thaker, G.K.; Sweeney, J.A. Clinical phenotypes of psychosis in the Bipolar-Schizophrenia Network on Intermediate Phenotypes (B-SNIP). Am. J. Psychiatry 2013, 170, 1263–1274. [Google Scholar] [CrossRef] [PubMed]
- Meda, S.; Ruaño, G.; Windemuth, A.; O’Neil, K.; Berwise, C.; Dunn, S.; Boccaccio, L.; Narayanan, B.; Kocherla, M.; Sprooten, E.; et al. Multivariate analysis reveals genetic associations of the resting default mode network in psychotic bipolar disorder and schizophrenia. Proc. Natl. Acad. Sci. USA 2014, 111, E2066–E2075. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Du, Y.; Fu, Z.; Xing, Y.; Lin, D.; Pearlson, G.; Kochunov, P.; Qi, S.; Salman, M.; Abrol, A.; Calhoun, V. Evidence of shared and distinct functional and structural brain signatures in schizophrenia and autism spectrum disorder. Commun. Biol. 2021, 4, 1073. [Google Scholar] [CrossRef]
- Du, Y.; Pearlson, G.; Lin, D.; Sui, J.; Chen, J.; Salman, M.; Tamminga, C.; Ivleva, E.; Sweeney, J.; Keshavan, M.; et al. Identifying dynamic functional connectivity biomarkers using GIG-ICA: Application to schizophrenia, schizoaffective disorder, and psychotic bipolar disorder: Identify Dynamic Connectivity States via GIG-ICA. Hum. Brain Mapp. 2017, 38, 2683–2708. [Google Scholar] [CrossRef] [Green Version]
- Friston, K.J.; Holmes, A.; Worsley, K.J.; Poline, J.B.; Frith, C.D.; Frackowiak, R.S.J. Statistical parametric maps in functional imaging: A general linear approach. Hum. Brain Mapp. 1994, 2, 189–210. [Google Scholar] [CrossRef]
- Shin, J.; Ahn, S.; Hu, X. Correction for the T1 effect incorporating flip angle estimated by Kalman filter in cardiac-gated functional MRI. Magn. Reson. Med. 2013, 70, 1626–1633. [Google Scholar] [CrossRef] [Green Version]
- Fu, G.S.; Anderson, M.; Adalı, T. Likelihood Estimators for Dependent Samples and Their Application to Order Detection. IEEE Trans. Signal Process. 2014, 62, 4237–4244. [Google Scholar] [CrossRef]
- Li, Y.O.; Adali, T.; Calhoun, V. Estimating the number of independent components for functional magnetic resonance Imaging data. Hum. Brain Mapp. 2007, 28, 1251–1266. [Google Scholar] [CrossRef]
- Long, Q.; Bhinge, S.; Levin-Schwartz, Y.; Boukouvalas, Z.; Calhoun, V.; Adali, T. The role of diversity in data-driven analysis of multi-subject fMRI data: Comparison of approaches based on independence and sparsity using global performance metrics. Hum. Brain Mapp. 2018, 40, 489–504. [Google Scholar] [CrossRef] [Green Version]
- Meng, X.; Iraji, A.; Fu, Z.; Kochunov, P.; Belger, A.; Ford, J.M.; McEwen, S.; Mathalon, D.H.; Mueller, B.A.; Pearlson, G.; et al. Multi-model Order ICA: A Data-driven Method for Evaluating Brain Functional Network Connectivity within and between Multiple Spatial Scales. bioRxiv 2021. [Google Scholar] [CrossRef]
- Jackson, R.L.; Cloutman, L.L.; Lambon Ralph, M.A. Exploring distinct default mode and semantic networks using a systematic ICA approach. Cortex 2019, 113, 279–297. [Google Scholar] [CrossRef] [PubMed]
- Salman, M.S.; Du, Y.; Lin, D.; Fu, Z.; Fedorov, A.; Damaraju, E.; Sui, J.; Chen, J.; Mayer, A.R.; Posse, S.; et al. Group ICA for identifying biomarkers in schizophrenia: ‘Adaptive’ networks via spatially constrained ICA show more sensitivity to group differences than spatio-temporal regression. Neuroimage Clin. 2019, 22, 101747. [Google Scholar] [CrossRef] [PubMed]
- Geisler, D.; Walton, E.; Naylor, M.; Roessner, V.; Lim, K.; Charles Schulz, S.; Gollub, R.; Calhoun, V.; Sponheim, S.; Ehrlich, S. Brain structure and function correlates of cognitive subtypes in schizophrenia. Psychiatry Res.-Neuroimaging 2015, 234, 74–83. [Google Scholar] [CrossRef] [Green Version]
- Ma, S.; Calhoun, V.D.; Eichele, T.; Du, W.; Adalı, T. Modulations of functional connectivity in the healthy and schizophrenia groups during task and rest. NeuroImage 2012, 62, 1694–1704. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Vu, T.; Long, Q.; Calhoun, V.; Adali, T. Identification of Homogeneous Subgroups from Resting-State fMRI Data. Sensors 2023, 23, 3264. [Google Scholar] [CrossRef]
- Kwak, S.; Kim, M.; Kim, T.; Kwak, Y.B.; Oh, S.; Lho, S.K.; Moon, S.Y.; Lee, T.Y.; Kwon, J.S. Defining data-driven subgroups of obsessive–compulsive disorder with different treatment responses based on resting-state functional connectivity. Transl. Psychiatry 2020, 10, 359. [Google Scholar] [CrossRef]
- De Nadai, A.; Fitzgerald, K.; Norman, L.; Block, S.; Mannella, K.; Himle, J.; Taylor, S. Defining brain-based OCD patient profiles using task-based fMRI and unsupervised machine learning. Neuropsychopharmacology 2022, 48, 402–409. [Google Scholar] [CrossRef]
- Yang, H.; Ghayem, F.; Gabrielson, B.; Akhonda, M.A.B.S.; Calhoun, V.D.; Adali, T. Constrained Independent Component Analysis Based on Entropy Bound Minimization for Subgroup Identification from Multi-subject fMRI Data. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, M.; Gabrielson, B.; Akhonda, M.A.B.S.; Yang, H.; Laport, F.; Calhoun, V.; Adali, T. A Scalable Approach to Independent Vector Analysis by Shared Subspace Separation for Multi-Subject fMRI Analysis. Sensors 2023, 23, 5333. https://doi.org/10.3390/s23115333
Sun M, Gabrielson B, Akhonda MABS, Yang H, Laport F, Calhoun V, Adali T. A Scalable Approach to Independent Vector Analysis by Shared Subspace Separation for Multi-Subject fMRI Analysis. Sensors. 2023; 23(11):5333. https://doi.org/10.3390/s23115333
Chicago/Turabian StyleSun, Mingyu, Ben Gabrielson, Mohammad Abu Baker Siddique Akhonda, Hanlu Yang, Francisco Laport, Vince Calhoun, and Tülay Adali. 2023. "A Scalable Approach to Independent Vector Analysis by Shared Subspace Separation for Multi-Subject fMRI Analysis" Sensors 23, no. 11: 5333. https://doi.org/10.3390/s23115333