

SALSA-Net: Explainable Deep Unrolling Networks for Compressed Sensing

Abstract
:1. Introduction
1.1. Traditional Methods
1.2. Network-Based Methods
2. Method
2.1. SALSA
- 1.
- Augmented Lagrangian term minimization:where is a threshold function used to shrink the value of to a nonzero value or zero. Its definition is
- 2.
- Data term minimization:where I is the identity matrix.
- 3.
- Updated the Lagrange multiplier:where are the results obtained by data term minimization.
2.2. SALSA-Net
2.2.1. Sampling
2.2.2. Initial Reconstruction
2.2.3. Deep Reconstruction
- 1.
- The thresholding denoising module is designed to map the first iteration of the traditional SALSA algorithm onto the deep network architecture, aiming to eliminate the artifact noise in using convolutional neural networks and the thresholding functions. The process can be expressed as:where is designed as a sequence of convolutional operations, which are specifically defined as:The implementation of this module is illustrated in Figure 3, where is a one-shot convolutional operation that performs a linear transformation to increase the dimensionality of the input using 32 convolutional kernels; is designed to consist of two convolutional layers and a ReLU non-linear transformation layer to transform the output of into the desired domain and then perform denoising using a soft thresholding function . The output is then transformed back to the original domain using the transformation , satisfying . Finally, a series of convolutional operations are used to achieve dimensionality reduction and obtain the final output u. The reconstructed results of and are stacked with the previous image residual information to obtain the updated reconstruction results. Unlike ISTA-Net, our is a deep network that learns the sparse representation of the input image using multiple convolutional layers and ReLU activation functions. Thus, becomes a trainable module that can adapt to different image scenes and tasks to improve the CS reconstruction performance.
- 2.
- The gradient update module is utilized in the SALSA algorithm to map the update process of to the neural network. This module enables the learned from the sampling network to replace the sampling matrix in the SALSA algorithm and the learned from the initial reconstruction network to replace . This approach eliminates the need for manual design of the sampling matrix in traditional algorithms and allows for sharing of the convolutional kernel parameters with those of the sampling and initial reconstruction, thereby improving network performance. Moreover, the module utilizes the network training parameter step size to avoid manual parameter tuning. The process can be expressed as:
- 3.
- The auxiliary update module is a linear combination of the previous two modules. Its main purpose is to accelerate the convergence speed of the algorithm, enabling a faster search for the optimal solution. Moreover, this module utilizes the computed value as the initial value for the next iteration, which is integrated into the iterative computation. The process can be expressed as:
2.2.4. Parameter and Loss Function Design
- 1.
- Parameters: The set of learnable parameters in our model comprises the transformation parameters , , , , , and . In addition, the step size and the shrinkage threshold are also learnable, without the need for manual tuning. These parameters are shared across all steps of the reconstruction stage and are part of the deep neural network.To ensure the correct convergence of the parameters and , we introduce some constraints in the following manner:Considering the decreasing noise variance during the iterative process, the shrinkage threshold is gradually decreased, and the step size should decrease smoothly during iterations. We enforce this constraint using the soft thresholding function . Since the network is fully shared and is independent of iterations, we can use a different number of iterations for image reconstruction, as described in Section 3.
- 2.
- The design of the loss function: we define the original training set as and the recovered images as , where is the number of images in the training set and is the total number of stages in the reconstruction network.
3. Results
3.1. Training Configuration
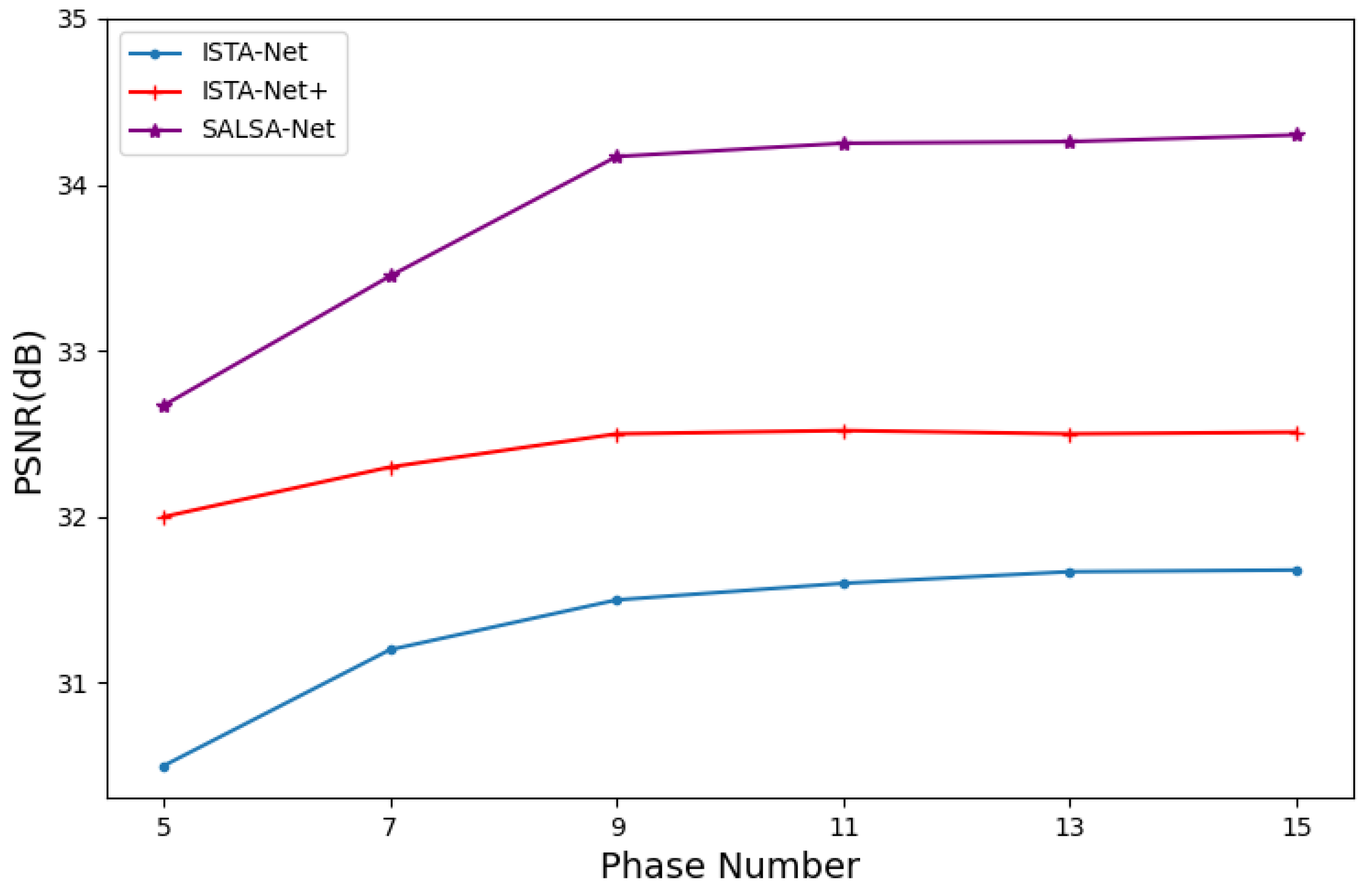
3.2. Analysis of Experimental Results
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candes, E.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Candes, E.; Tao, T. Near-optimal signal recovery from random projections: Universal encoding strategies? IEEE Trans. Inf. Theory 2006, 52, 5406–5425. [Google Scholar] [CrossRef]
- Wang, L.; Lu, K.; Liu, P. Compressed sensing of a remote sensing image based on the priors of the reference image. IEEE Geosci. Remote Sens. Lett. 2015, 12, 736–740. [Google Scholar] [CrossRef]
- Duarte, M.F.; Davenport, M.A.; Takhar, D.; Laska, J.N.; Sun, T.; Kelly, K.F.; Baraniuk, R.G. Single-pixel imaging via compressive sampling. IEEE Signal Process. Mag. 2008, 25, 83–91. [Google Scholar] [CrossRef]
- Wen, B.; Ravishankar, S.; Pfister, L.; Bresler, Y. Transform learning for magnetic resonance image reconstruction: From model-based learning to building neural networks. IEEE Signal Process. Mag. 2020, 37, 41–53. [Google Scholar] [CrossRef]
- Li, S.; Da Xu, L.; Wang, X. Compressed sensing signal and data acquisition in wireless sensor networks and internet of things. IEEE Trans. Ind. Inform. 2012, 9, 2177–2186. [Google Scholar] [CrossRef]
- Potter, L.; Ertin, E.; Parker, J.; Cetin, M. Sparsity and compressed sensing in radar imaging. Proc. IEEE 2010, 98, 1006–1020. [Google Scholar] [CrossRef]
- Duarte, M.F.; Baraniuk, R.G. Spectral compressive sensing. Appl. Comput. Harmon. Anal. 2013, 35, 111–129. [Google Scholar] [CrossRef]
- Wright, J.; Ma, Y.; Mairal, J.; Sapiro, G.; Huang, T.; Yan, S. Sparse representation for computer vision and pattern recognition. Proc. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef]
- Gan, L. Block Compressed Sensing of Natural Images. In Proceedings of the International Conference on Digital Signal Processing (ICDSP), Cardiff, UK, 1–4 July 2007. [Google Scholar]
- Eftekhari, A.; Yap, H.L.; Rozell, C.J.; Wakin, M.B. The restricted isometry property for random block diagonal matrices. Appl. Comput. Harmon. Anal. 2015, 38, 1–31. [Google Scholar] [CrossRef]
- Bruckstein, A.M.; Donoho, D.L.; Elad, M. From Sparse Solutions of Systems of Equations to Sparse Modeling of Signals and Images. Siam Rev. 2009, 51, 34–81. [Google Scholar] [CrossRef]
- Tropp, J.; Wright, S. Computational methods for sparse solution of linear inverse problems. Proc. IEEE 2010, 98, 948–958. [Google Scholar] [CrossRef]
- Wang, Y.; Meng, D.; Yuan, M. Sparse recovery: From vectors to tensors. Natl. Sci. Rev. 2018, 5, 756–767. [Google Scholar] [CrossRef]
- Song, H.; Ai, Z.; Lai, Y.; Meng, H.; Mao, Q. Sparse signal reconstruction via generalized two-stage thresholding. Sci. China Inf. Sci. 2022, 65, 139303. [Google Scholar] [CrossRef]
- Donoho, D.; Maleki, A.; Montanari, A. Message-passing algorithms for compressed sensing. Proc. Natl. Acad. Sci. USA 2009, 106, 18914–18919. [Google Scholar] [CrossRef]
- Parikh, N.; Boyd, S. Proximal Algorithms. Found. Trends Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Li, C.; Yin, W.; Jiang, H.; Zhang, Y. An efficient augmented Lagrangian method with applications to total variation minimization. Comput. Optim. Appl. 2013, 56, 507–530. [Google Scholar] [CrossRef]
- Needell, D.; Tropp, J.A. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef]
- Dai, W.; Milenkovic, O. Subspace pursuit for compressive sensing signal reconstruction. IEEE Trans. Inf. Theory 2009, 55, 2230–2249. [Google Scholar] [CrossRef]
- Blumensath, T.; Davies, M.E. Iterative hard thresholding for compressed sensing. Appl. Comput. Harmon. Anal. 2009, 27, 265–274. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Becker, S.; Bobin, J.; Candes, E. NESTA: A fast and accurate first-order method for sparse recovery. SIAM J. Imaging Sci. 2011, 4, 1–39. [Google Scholar] [CrossRef]
- Afonso, M.; Bioucas-Dias, J.; Figueiredo, M. Fast image recovery using variable splitting and constrained optimization. IEEE Trans. Image Process. 2010, 19, 2345–2356. [Google Scholar] [CrossRef]
- Afonso, M.; Bioucas-Dias, J.; Figueiredo, M. An augmented Lagrangian approach to the constrained optimization formulation of imaging inverse problems. IEEE Trans. Image Process. 2010, 20, 681–695. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Chen, B.; Xiong, R.; Zhang, Y. Physics-inspired compressive sensing: Beyond deep unrolling. IEEE Signal Process. Mag. 2023, 40, 58–72. [Google Scholar] [CrossRef]
- Monga, V.; Li, Y.; Eldar, Y.C. Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing. IEEE Signal Process. Mag. 2021, 38, 18–44. [Google Scholar] [CrossRef]
- Chen, T.; Chen, X.; Chen, W.; Heaton, H.; Liu, J.; Wang, Z.; Yin, W. Learning to optimize: A primer and a benchmark. J. Mach. Learn. Res. 2022, 23, 1–59. [Google Scholar]
- Mousavi, A.; Patel, A.B.; Baraniuk, R.G. A deep learning approach to structured signal recovery. In Proceedings of the 53rd Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 29 September–2 October 2015; pp. 1336–1343. [Google Scholar]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. Reconnet: Non-iterative reconstruction of images from compressively sensed measurements. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 449–458. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Yao, H.; Dai, F.; Zhang, S.; Zhang, Y.; Tian, Q.; Xu, C. DR2-Net: Deep residual reconstruction network for image compressive sensing. Neurocomputing 2019, 359, 483–493. [Google Scholar] [CrossRef]
- Shi, W.; Jiang, F.; Zhang, S.; Zhao, D. Deep networks for compressed image sensing. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 877–882. [Google Scholar]
- Sun, Y.; Yang, Y.; Liu, Q.; Chen, J.; Yuan, X.T.; Guo, G. Learning non-locally regularized compressed sensing network with half-quadratic splitting. IEEE Trans. Multimed. 2020, 22, 3236–3248. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, J. Content-aware scalable deep compressed sensing. IEEE Trans. Image Process. 2022, 31, 5412–5426. [Google Scholar] [CrossRef]
- Zhou, S.; He, Y.; Liu, Y.; Li, C.; Zhang, J. Multi-Channel Deep Networks for Block-Based Image Compressive Sensing. IEEE Trans. Multimed. 2021, 23, 2627–2640. [Google Scholar] [CrossRef]
- You, D.; Zhang, J.; Xie, J.; Chen, B.; Ma, S. Coast: Controllable arbitrary-sampling network for compressive sensing. IEEE Trans. Image Process. 2021, 30, 6066–6080. [Google Scholar] [CrossRef]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 399–406. [Google Scholar]
- Chen, X.; Liu, J.; Wang, Z.; Yin, W. Theoretical linear convergence of unfolded ISTA and its practical weights and thresholds. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QB, Canada, 2–8 December 2018; pp. 9061–9071. [Google Scholar]
- Liu, J.; Chen, X.; Wang, Z.; Yin, W. ALISTA: Analytic weights are as good as learned weights in LISTA. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wu, K.; Guo, Y.; Li, Z.; Zhang, C. Sparse coding with gated learned ISTA. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26 April–May 1 2020. [Google Scholar]
- Li, Y.; Kong, L.; Shang, F.; Liu, Y.; Liu, H.; Lin, Z. Learned extragradient ISTA with interpretable residual structures for sparse coding. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Online, 2–9 February 2021; Volume 35, pp. 8501–8509. [Google Scholar]
- Aberdam, A.; Golts, A.; Elad, M. Ada-LISTA: Learned Solvers Adaptive to Varying Models. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9222–9235. [Google Scholar] [CrossRef]
- Zheng, Z.; Dai, W.; Xue, D.; Li, C.; Zou, J.; Xiong, H. Hybrid ISTA: Unfolding ISTA with convergence guarantees using free-form deep neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 43, 3226–3242. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1828–1837. [Google Scholar]
- You, D.; Xie, J.; Zhang, J. ISTA-NET++: Flexible deep unfolding network for compressive sensing. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021. [Google Scholar]
- Xiang, J.; Dong, Y.; Yang, Y. FISTA-Net: Learning a Fast Iterative Shrinkage Thresholding Network for Inverse Problems in Imaging. IEEE Trans. Med. Imaging 2021, 40, 1329–1339. [Google Scholar] [CrossRef]
- Yang, Y.; Sun, J.; Li, H.; Xu, Z. ADMM-CSNet: A deep learning approach for image compressive sensing. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 521–538. [Google Scholar] [CrossRef]
- Liu, J.; Sun, Y.; Eldeniz, C.; Gan, W.; An, H.; Kamilov, U.S. RARE: Image reconstruction using deep priors learned without groundtruth. IEEE J. Sel. Top. Signal Process. 2020, 14, 1088–1099. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Y.; Liu, J.; Wen, F.; Zhu, C. AMP-Net: Denoising-based deep unfolding for compressive image sensing. IEEE Trans. Image Process. 2021, 30, 1487–1500. [Google Scholar] [CrossRef]
- Chen, J.; Sun, Y.; Liu, Q.; Huang, R. Learning memory augmented cascading network for compressed sensing of images. In Proceedings of the European Conference Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 513–529. [Google Scholar]
- Ye, D.; Ni, Z.; Wang, H.; Zhang, J.; Wang, S.; Kwong, S. CSformer: Bridging Convolution and Transformer for Compressive Sensing. arXiv 2021, arXiv:2112.15299. [Google Scholar] [CrossRef] [PubMed]
- Shen, M.; Gan, H.; Ning, C.; Hua, Y.; Zhang, T. TransCS: A Transformer-Based Hybrid Architecture for Image Compressed Sensing. IEEE Trans. Image Process. 2022, 31, 6991–7005. [Google Scholar] [CrossRef] [PubMed]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012; pp. 1–10. [Google Scholar]
- Sun, Y.; Chen, J.; Liu, Q.; Liu, B.; Guo, G. Dual-path attention network for compressed sensing image reconstruction. IEEE Trans. Image Process. 2020, 29, 9482–9495. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | 10% | 20% | 30% | 40% | 50% | Avg |
|---|---|---|---|---|---|---|
| PSNR(dB) | ||||||
| TVAL3 | 22.99 | 27.92 | 29.23 | 31.46 | 33.55 | 29.03 |
| ReconNet | 24.11 | 25.52 | 28.71 | 30.77 | 31.59 | 28.14 |
| ISTA-Net+ | 26.54 | 30.67 | 33.72 | 36.01 | 38.01 | 32.99 |
| AMP-Net | 28.65 | 31.05 | 32.91 | 35.31 | 37.45 | 33.07 |
| NL-CSNet | 28.11 | 31.43 | 33.82 | 35.60 | 37.13 | 33.22 |
| MAC-Net | 27.83 | 31.54 | 33.82 | 36.10 | 37.78 | 33.41 |
| ISTA-Net++ | 28.34 | 32.33 | 34.86 | 36.51 | 38.73 | 34.15 |
| SALSA-Net | 28.49 | 32.25 | 35.20 | 36.97 | 39.39 | 34.46 |
| Methods | 10% | 20% | 30% | 40% | 50% | Avg |
|---|---|---|---|---|---|---|
| PSNR(dB) | ||||||
| TVAL3 | 19.26 | 21.25 | 22.34 | 25.39 | 29.59 | 23.57 |
| ReconNet | 23.76 | 25.29 | 27.40 | 28.58 | 30.64 | 27.13 |
| ISTA-Net+ | 25.29 | 27.23 | 30.03 | 32.23 | 33.56 | 29.67 |
| AMP-Net | 25.32 | 27.37 | 30.56 | 32.11 | 32.78 | 29.63 |
| NL-CSNet | 25.18 | 27.53 | 29.61 | 31.32 | 32.48 | 29.22 |
| MAC-Net | 25.34 | 28.43 | 30.11 | 31.37 | 33.58 | 29.76 |
| ISTA-Net++ | 26.01 | 28.56 | 30.94 | 32.72 | 34.92 | 30.63 |
| SALSA-Net | 26.96 | 29.12 | 31.55 | 31.55 | 35.60 | 31.27 |
| Methods | 10% | 20% | 30% | 40% | 50% | Avg |
|---|---|---|---|---|---|---|
| PSNR(dB) | ||||||
| TVAL3 | 27.12 | 30.35 | 32.49 | 34.77 | 36.63 | 32.27 |
| ReconNet | 26.99 | 29.34 | 31.44 | 33.62 | 35.41 | 31.36 |
| ISTA-Net+ | 28.84 | 32.62 | 35.47 | 38.45 | 40.15 | 35.10 |
| AMP-Net | 33.31 | 36.92 | 39.14 | 41.12 | 42.07 | 38.51 |
| MAC-Net | 32.54 | 36.06 | 38.48 | 40.37 | 42.11 | 37.91 |
| ISTA-Net++ | 33.04 | 36.41 | 38.86 | 39.92 | 41.64 | 37.97 |
| SALSA-Net | 33.78 | 36.63 | 39.21 | 41.35 | 42.24 | 38.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, H.; Ding, Q.; Gong, J.; Meng, H.; Lai, Y. SALSA-Net: Explainable Deep Unrolling Networks for Compressed Sensing. Sensors 2023, 23, 5142. https://doi.org/10.3390/s23115142
Song H, Ding Q, Gong J, Meng H, Lai Y. SALSA-Net: Explainable Deep Unrolling Networks for Compressed Sensing. Sensors. 2023; 23(11):5142. https://doi.org/10.3390/s23115142
Chicago/Turabian StyleSong, Heping, Qifeng Ding, Jingyao Gong, Hongying Meng, and Yuping Lai. 2023. "SALSA-Net: Explainable Deep Unrolling Networks for Compressed Sensing" Sensors 23, no. 11: 5142. https://doi.org/10.3390/s23115142