

Marbling-Net: A Novel Intelligent Framework for Pork Marbling Segmentation Using Images from Smartphones

Abstract
:1. Introduction
2. Materials and Methods
2.1. Pork Marbling Dataset PMD2023
2.1.1. Data Collection
2.1.2. Data Annotation
2.1.3. Data Preprocessing
2.2. Patch-Based Training Framework for Pork Marbling Segmentation
2.2.1. Patch-Based Training
2.2.2. Data Augmentation
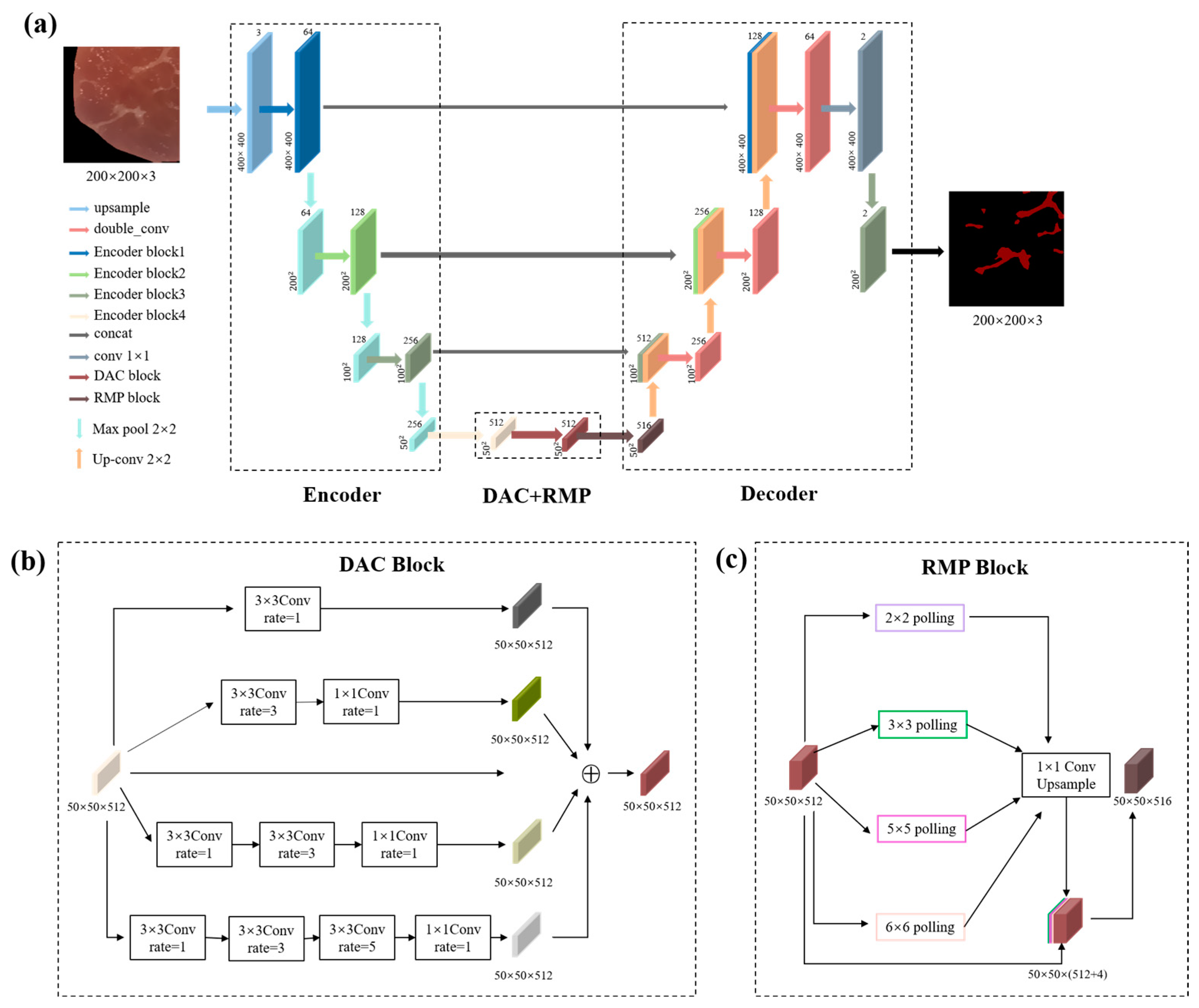
2.2.3. Fully Convolutional Networks for Marbling Segmentation (Marbling-Net)
- (1)
- encoder–decoder structure
- (2)
- Multi-scale feature extraction module
2.2.4. Loss Function
3. Experiments
3.1. Implementation Details
3.2. Evaluation Metrics
3.2.1. Intersection over Union
3.2.2. Precision
3.2.3. Recall
3.2.4. F1-Score
4. Result
4.1. Characterization of the PMD2023 Dataset
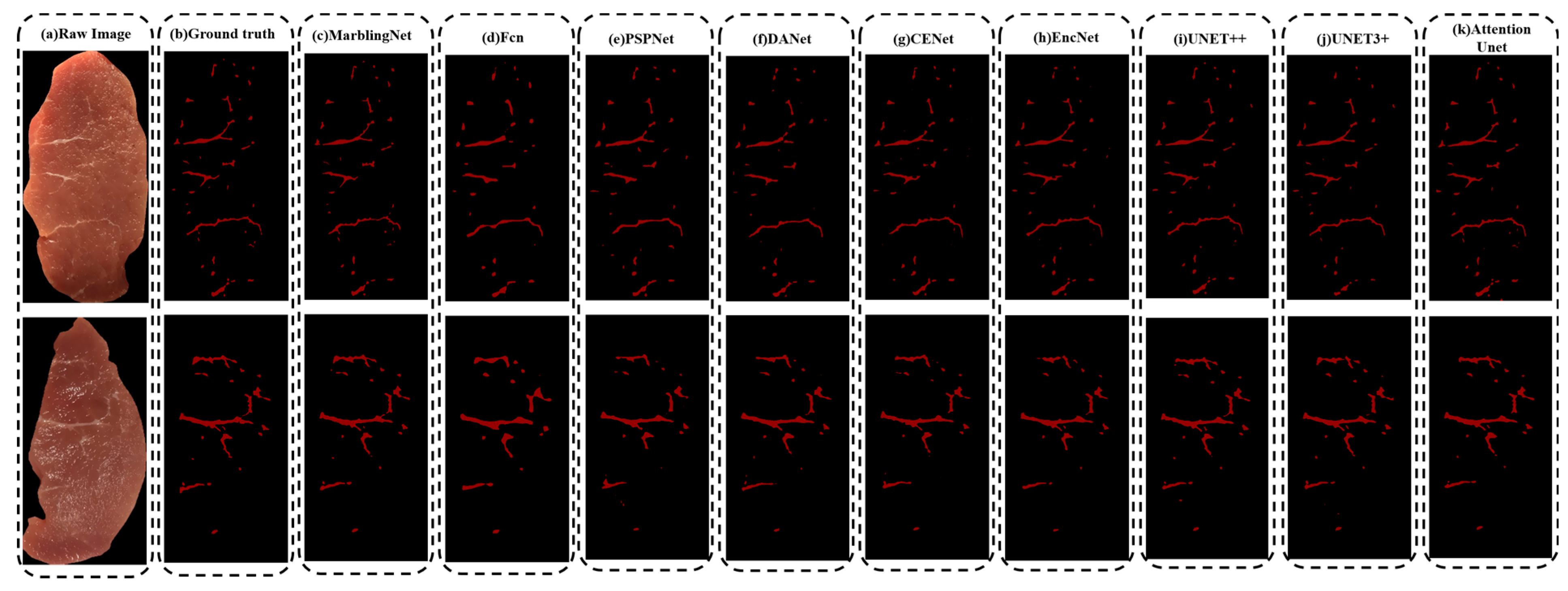
4.2. Comparison with Representative Methods
4.3. Ablation Study
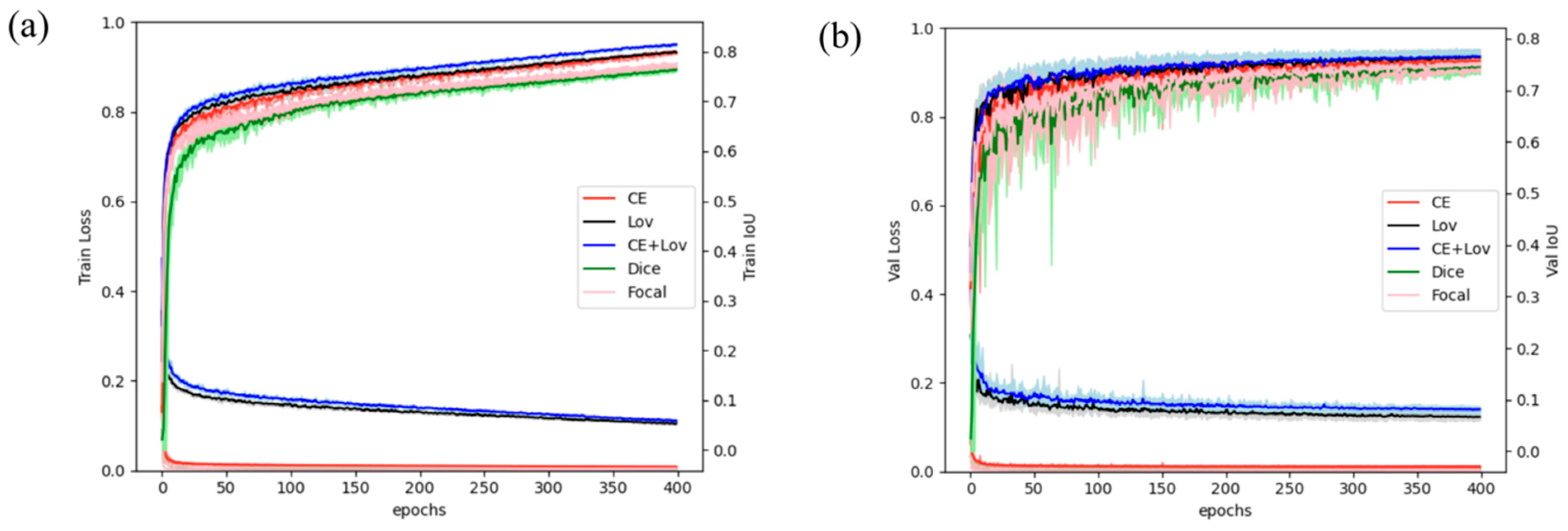
4.4. Comparison of Loss Functions
4.5. Comparison of Different Patch Sizes
4.6. Performance Evaluation of Marbling Features Measured by the Marbling-Net
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sanchez, P.D.C.; Arogancia, H.B.T.; Boyles, K.M.; Pontillo, A.J.B.; Ali, M.M. Emerging Nondestructive Techniques for the Quality and Safety Evaluation of Pork and Beef: Recent Advances, Challenges and Future Perspectives. AFR 2022, 2, 100147. [Google Scholar] [CrossRef]
- Murphy, M.M.; Spungen, J.H.; Bi, X.; Barraj, L.M. Fresh and fresh lean pork are substantial sources of key nutrients when these products are consumed by adults in the United States. Nutr. Res. 2011, 31, 776–783. [Google Scholar] [CrossRef] [PubMed]
- Moeller, S.; Miller, R.; Edwards, K.; Zerby, H.; Logan, K.; Aldredge, T.; Stahl, C.; Boggess, M.; Box-Steffensmeier, J. Consumer perceptions of pork eating quality as affected by pork quality attributes and end-point cooked temperature. Meat Sci. 2010, 84, 14–22. [Google Scholar] [CrossRef]
- Brewer, M.; Zhu, L.; McKeith, F. Marbling effects on quality characteristics of pork loin chops: Consumer purchase intent, visual and sensory characteristics. Meat Sci. 2001, 59, 153–163. [Google Scholar] [CrossRef]
- Chambaz, A.; Scheeder, M.; Kreuzer, M.; Dufey, P.-A. Meat quality of Angus, Simmental, Charolais and Limousin steers compared at the same intramuscular fat content. Meat Sci. 2003, 63, 491–500. [Google Scholar] [CrossRef] [PubMed]
- Miar, Y.; Plastow, G.; Wang, Z. Genomic selection, a new era for pork quality Improvement. Springer Sci. Rev. 2015, 3, 27–37. [Google Scholar] [CrossRef]
- Cross, H.; Gilliland, D.; Durland, P.; Seideman, S. Beef carcass evaluation by use of a video image analysis system. J. Anim. Sci. 1983, 57, 908–917. [Google Scholar] [CrossRef]
- Ferguson, D. Objective on-line assessment of marbling: A brief review. Aust. J. Exp. Agric. 2004, 44, 681–685. [Google Scholar] [CrossRef]
- Ma, J.; Jie, Y.; Zhou, L.; Zhang, Z.; Ma, H.; Xie, X.; Zhang, F.; Xiong, X.; Cui, L.; Yang, H. Genome-Wide Association Study of Meat Quality Traits in a White Duroc×Erhualian F2 Intercross and Chinese Sutai Pigs. PLoS ONE 2013, 8, e64047. [Google Scholar] [CrossRef]
- Zamora-Rojas, E.; Pérez-Marín, D.; De Pedro-Sanz, E.; Guerrero-Ginel, J.; Garrido-Varo, A. Handheld NIRS analysis for routine meat quality control: Database transfer from at-line instruments. Chemom. Intell. Lab. Syst. 2012, 114, 30–35. [Google Scholar] [CrossRef]
- Barlocco, N.; Vadell, A.; Ballesteros, F.; Galietta, G.; Cozzolino, D. Predicting intramuscular fat, moisture and Warner-Bratzler shear force in pork muscle using near infrared reflectance spectroscopy. Anim. Sci. J 2006, 82, 111–116. [Google Scholar] [CrossRef]
- Corrêa, C.C.; Forato, L.A.; Colnago, L.A. High-throughput non-destructive nuclear magnetic resonance method to measure intramuscular fat content in beef. Anal. Bioanal. Chem. 2009, 393, 1357–1360. [Google Scholar] [CrossRef] [PubMed]
- Qiao, J.; Ngadi, M.O.; Wang, N.; Gariépy, C.; Prasher, S.O. Pork quality and marbling level assessment using a hyperspectral imaging system. J. Food Eng. 2007, 83, 10–16. [Google Scholar] [CrossRef]
- Liu, L.; Ngadi, M. Predicting intramuscular fat content of pork using hyperspectral imaging. J. Food Eng. 2014, 134, 16–23. [Google Scholar] [CrossRef]
- Fukuda, O.; Nabeoka, N.; Miyajima, T. Estimation of marbling score in live cattle based on dynamic ultrasound image using a neural network. In Proceedings of the 2012 19th International Conference on Systems, Signals and Image Processing (IWSSIP), Vienna, Austria, 11–13 April 2012. [Google Scholar]
- Frisullo, P.; Marino, R.; Laverse, J.; Albenzio, M.; Del Nobile, M.A. Assessment of intramuscular fat level and distribution in beef muscles using X-ray microcomputed tomography. Meat Sci. 2010, 85, 250–255. [Google Scholar] [CrossRef]
- Jackman, P.; Sun, D.-W.; Allen, P. Automatic segmentation of beef longissimus dorsi muscle and marbling by an adaptable algorithm. Meat Sci. 2009, 83, 187–194. [Google Scholar] [CrossRef]
- Sun, D.W. Computer vision-an objective, rapid and non-contact quality evaluation tool for the food industry. J. Food Eng. 2004, 61, 1–2. [Google Scholar] [CrossRef]
- Cernadas, E.; Fernández-Delgado, M.; Fulladosa, E.; Muñoz, I. Automatic marbling prediction of sliced dry-cured ham using image segmentation, texture analysis and regression. Expert Syst. Appl. 2022, 206, 117765. [Google Scholar] [CrossRef]
- Chen, Y.; McDonald, T.; Crouse, J. Determining Percent Intra-Muscular Fat on Ribeye Surface by Image Processing; Paper-American Society of Agricultural Engineers: St. Joseph, MI, USA, 1989. [Google Scholar]
- Pang, B.; Sun, X.; Sun, X.; Chen, K. A fast beef marbling segmentation algorithm based on image resampling. Telkomnika Indones. J. Electr. Eng. 2014, 12, 3894–3901. [Google Scholar] [CrossRef]
- Liu, L.; Ngadi, M.; Prasher, S.; Gariépy, C. Categorization of pork quality using Gabor filter-based hyperspectral imaging technology. J. Food Eng. 2010, 99, 284–293. [Google Scholar] [CrossRef]
- Liu, L.; Ngadi, M.; Prasher, S.; Gariépy, C. Objective determination of pork marbling scores using the wide line detector. J. Food Eng. 2012, 110, 497–504. [Google Scholar] [CrossRef]
- Muñoz, I.; Rubio-Celorio, M.; Garcia-Gil, N.; Guàrdia, M.D.; Fulladosa, E. Computer image analysis as a tool for classifying marbling: A case study in dry-cured ham. J. Food Eng. 2015, 166, 148–155. [Google Scholar] [CrossRef]
- Liu, J.-H.; Sun, X.; Young, J.; Bachmeier, L.; Newman, D. Predicting pork loin intramuscular fat using computer vision system. Meat Sci. 2018, 143, 18–23. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018. Proceedings 4. [Google Scholar]
- Zhao, X.; Peng, Y.; Li, Y.; Li, L. Segmentation of beef marbling based on fully convolutional networks. In Proceedings of the 2020 ASABE Annual International Virtual Meeting, online meeting, 13–15 July 2020. [Google Scholar]
- Zhang, X.; Zheng, Z.; Xiao, P.; Li, Z.; He, G. Patch-Based Training of Fully Convolutional Network for Hyperspectral Image Classification With Sparse Point Labels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8884–8897. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef]
- Dong, R.; Pan, X.; Li, F. DenseU-net-based semantic segmentation of small objects in urban remote sensing images. IEEE Access 2019, 7, 65347–65356. [Google Scholar] [CrossRef]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. Salsanext: Fast, uncertainty-aware semantic segmentation of lidar point clouds for autonomous driving. arXiv 2020, arXiv:2003.03653. [Google Scholar]
- NPPC. Pork composition and quality assessment procedures. In National Pork Producer’s Council Composition and Quality Assessment Procedures Manual; University of Missouri Columbia: Columbia, MO, USA, 2000. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vision 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Domingos, P. A few useful things to know about machine learning. Commun. ACM 2012, 55, 78–87. [Google Scholar] [CrossRef]
- Meng, Z.; Fan, X.; Chen, X.; Chen, M.; Tong, Y. Detecting small signs from large images. In Proceedings of the 2017 IEEE International Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IoU (%) | Precision (%) | Recall (%) | F1-Score (%) | Parameter (M) | Inference Time (ms) |
|---|---|---|---|---|---|---|
| FCN | 31.4 | 63.7 | 38.5 | 46.2 | 134.3 | 47.37 |
| PSPNet | 54.3 | 75.0 | 66.5 | 67.0 | 51.4 | 30.30 |
| DANet | 58.5 | 76.6 | 71.2 | 73.8 | 47.6 | 60.52 |
| UperNet | 64.6 | 81.4 | 75.8 | 76.6 | 101.4 | 15.49 |
| CENet | 65.4 | 82.3 | 76.2 | 79.1 | 29.0 | 19.66 |
| EncNet | 68.7 | 84.8 | 78.3 | 81.4 | 34.7 | 115.44 |
| U-Net | 74.3 | 87.6 | 83.1 | 85.2 | 31.0 | 53.77 |
| U-Net++ | 73.7 | 86.7 | 83.0 | 84.8 | 9.2 | 49.59 |
| U-Net3+ | 70.1 | 88.2 | 77.4 | 82.4 | 27.0 | 169.18 |
| Attention U-Net | 74.7 | 88.3 | 82.9 | 85.5 | 34.9 | 71.29 |
| U-Net (VGG-16) | 73.6 | 87.3 | 82.5 | 84.8 | 41.9 | 62.40 |
| Marbling-Net (Ours) | 76.8 | 87.8 | 86.0 | 86.9 | 31.0 | 249.81 |
| Component | IoU (%) | Precision (%) | Recall (%) | F1-Score (%) | ||
|---|---|---|---|---|---|---|
| Patch-Based | Up-Sampling | Context Extraction Module | ||||
| × | × | × | 73.9 | 86.3 | 83.7 | 85.0 |
| × | × | √ | 74.3 | 86.1 | 84.5 | 85.3 |
| √ | × | × | 76.0 | 87.0 | 85.7 | 86.4 |
| √ | × | √ | 76.1 | 86.9 | 85.9 | 86.4 |
| √ | √ | × | 76.0 | 87.7 | 85.0 | 86.4 |
| √ | √ | √ | 76.8 | 87.8 | 86.0 | 86.9 |
| Loss Function | Evaluation Metrics | |||
|---|---|---|---|---|
| IoU (%) | Precision (%) | Recall (%) | F1-Score (%) | |
| Dice | 74.7 | 88.1 | 83.1 | 85.5 |
| Focal | 75.0 | 88.8 | 82.8 | 86.7 |
| CE | 76.2 | 88.5 | 84.6 | 86.5 |
| LS | 76.5 | 87.6 | 85.8 | 86.7 |
| CE-LS | 76.8 | 87.8 | 86.0 | 86.9 |
| λ | 0 | 0.05 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 1 |
|---|---|---|---|---|---|---|---|---|
| IoU (%) | 76.2 | 76.2 | 76.5 | 76.5 | 76.5 | 76.7 | 76.5 | 76.8 |
| Precision (%) | 88.5 | 88.3 | 88.3 | 87.7 | 87.5 | 87.3 | 87.8 | 87.8 |
| Recall (%) | 84.6 | 84.8 | 85.2 | 85.6 | 86.0 | 86.5 | 85.6 | 86.0 |
| F1-score (%) | 86.5 | 86.5 | 86.7 | 86.7 | 86.7 | 86.8 | 86.7 | 86.9 |
| Patch Size | MIoU (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| 50 × 50 | 73.7 | 85.0 | 84.8 | 84.8 |
| 100 × 100 | 76.2 | 87.7 | 85.4 | 86.5 |
| 200 × 200 | 76.8 | 87.8 | 86.0 | 86.9 |
| 400 × 400 | 76.3 | 87.9 | 85.2 | 86.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Chen, Y.; Liu, W.; Liu, B.; Zhou, X. Marbling-Net: A Novel Intelligent Framework for Pork Marbling Segmentation Using Images from Smartphones. Sensors 2023, 23, 5135. https://doi.org/10.3390/s23115135
Zhang S, Chen Y, Liu W, Liu B, Zhou X. Marbling-Net: A Novel Intelligent Framework for Pork Marbling Segmentation Using Images from Smartphones. Sensors. 2023; 23(11):5135. https://doi.org/10.3390/s23115135
Chicago/Turabian StyleZhang, Shufeng, Yuxi Chen, Weizhen Liu, Bang Liu, and Xiang Zhou. 2023. "Marbling-Net: A Novel Intelligent Framework for Pork Marbling Segmentation Using Images from Smartphones" Sensors 23, no. 11: 5135. https://doi.org/10.3390/s23115135