
Mixed Receptive Fields Augmented YOLO with Multi-Path Spatial Pyramid Pooling for Steel Surface Defect Detection

Abstract
:1. Introduction
- We propose a novel re-parameterized large kernel C3 (RepLK-C3) module with a large kernel design, which has a larger receptive field than the original C3 module and can pay more attention to shape features.
- We revisit the effectiveness of using spatial pyramid pooling in deep layers of the network and remove the spatial pyramid pooling module in the last layer of the backbone network. Additionally, we re-focus on the importance of recognizing complex objects at every scale feature map, we redesigned the re-parameterized large kernel spatial pyramid pooling (RepLK-SPP) module with multiple large kernel designs. This module can extract strong positional features and use them for lateral propagation. By using this module after each scale feature map, we constructed the multi-path RepLK-SPP neck structure, which improves the model’s detection ability in complex textures.
- We propose a training strategy that applies different kernel sizes to feature maps of different scales, allowing the network to capture the scale variations of steel surfaces to the greatest extent possible.
2. Related Work
2.1. Receptive Field
2.2. Multi-Scale Defect Detection
3. Methods
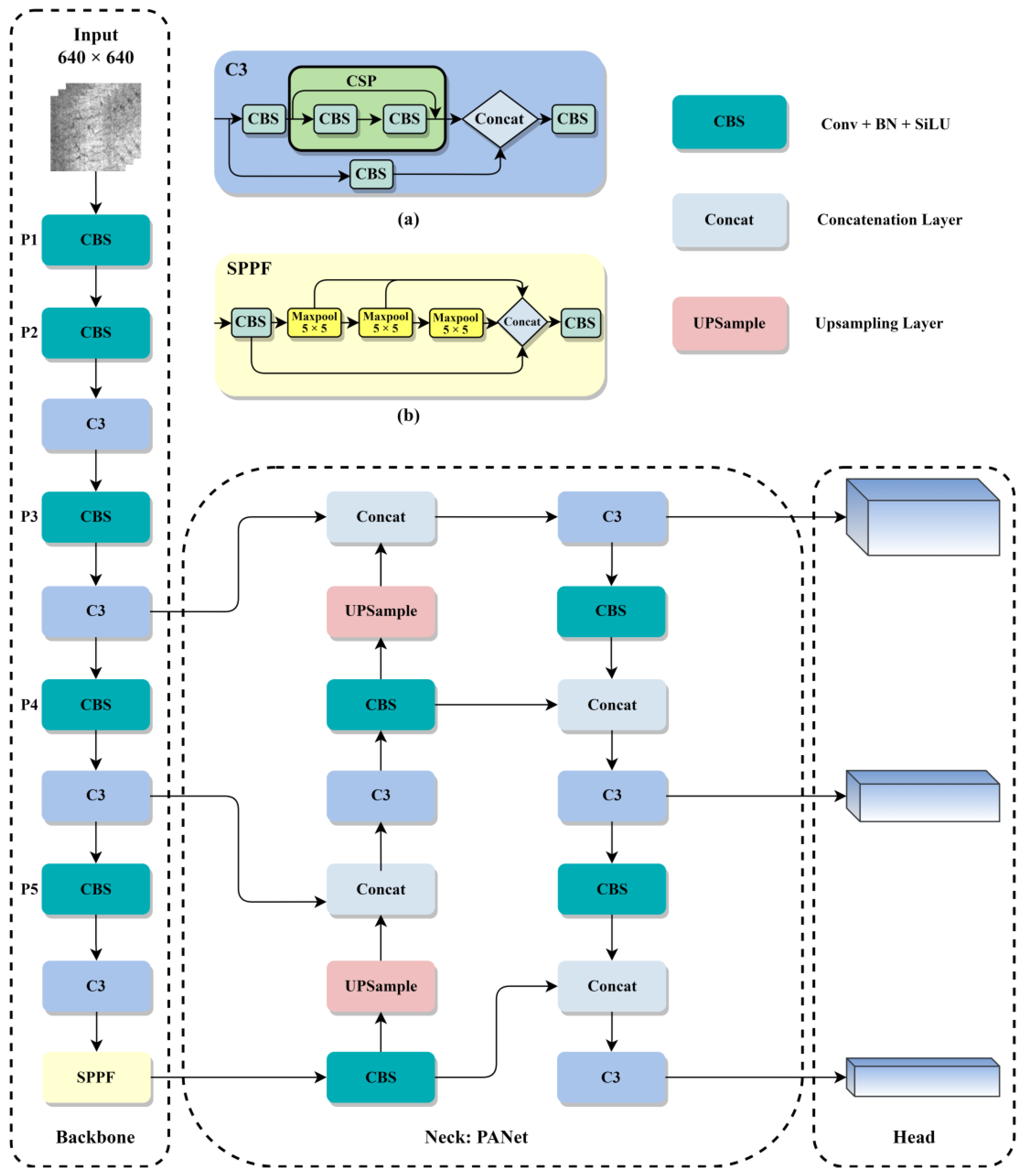
3.1. Review of YOLOv5
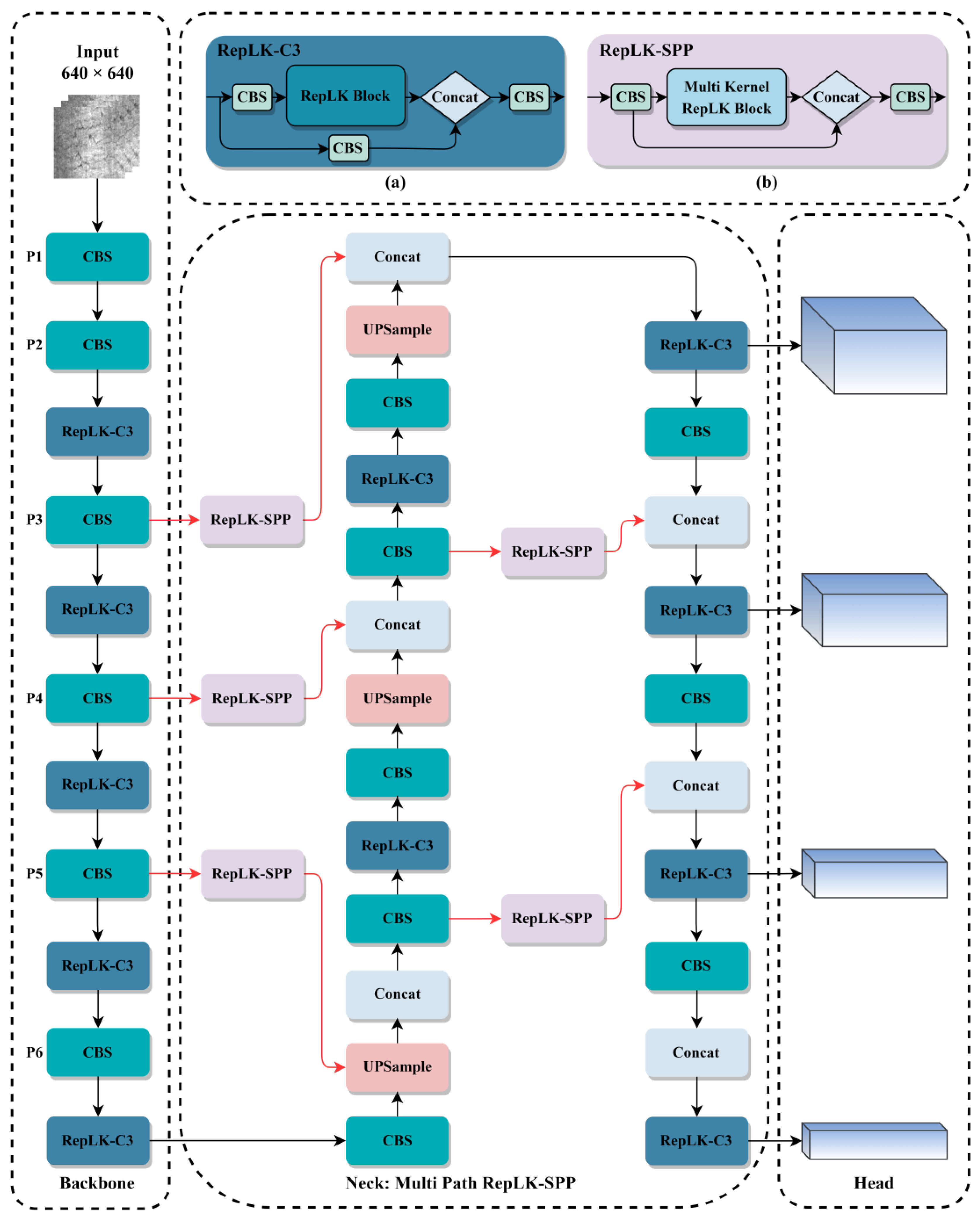
3.2. Improved Network Architecture
- According to statistics, there are a large number of large-scale, tiny textured defect images in the NEU-DET steel surface dataset. Therefore, we added an additional P6 layer with a smaller size to the backbone network and integrated it into the neck network. We also added a detection head to the head network to better adapt to multi-scale defect object detection.
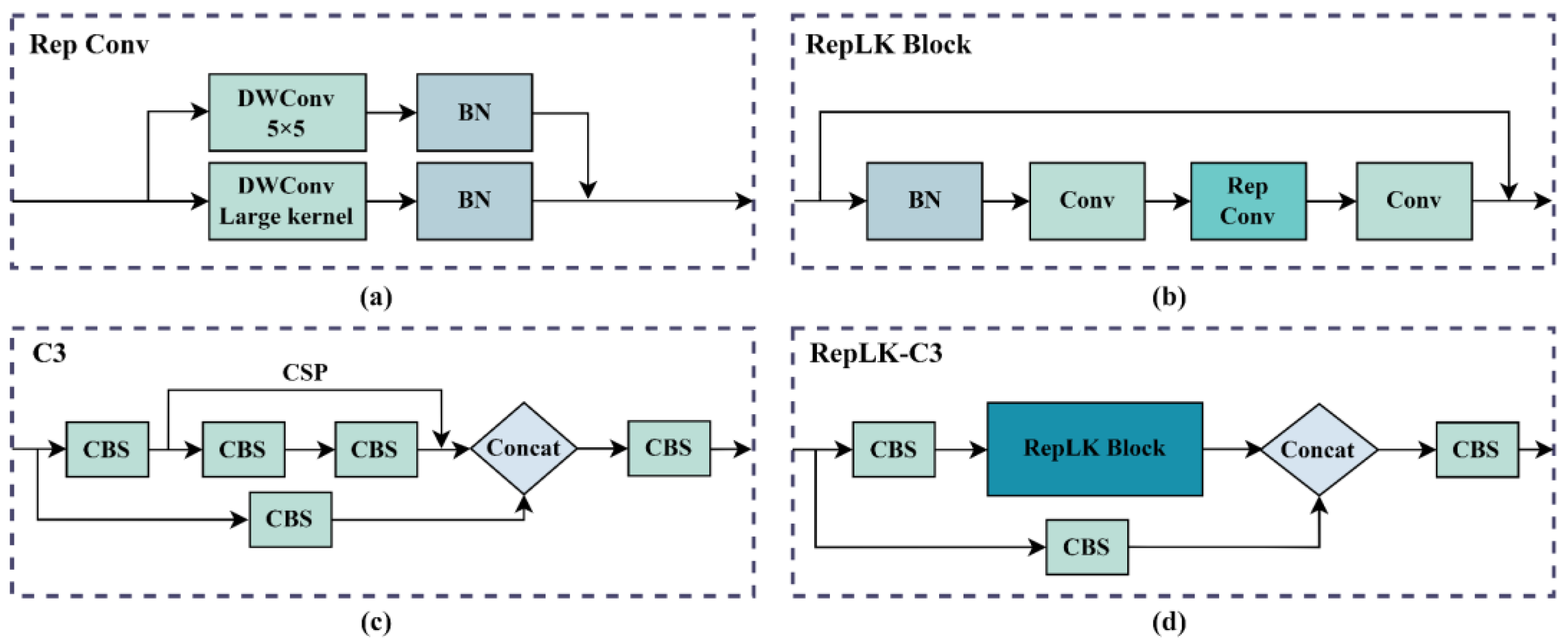
- Due to the interference of texture features on the surface of the steel, there are a large number of defects with subtle features. Therefore, in order to increase the receptive field of the model, we combine the re-parameterized large kernel convolution block with the C3 module, replace the original CSP layer, and introduce the newly designed re-parameterized large kernel C3 (RepLK-C3) module into the backbone and neck networks. The structure of RepLK-C3 is shown in Figure 2a.
- In order to improve the detection accuracy of multi-scale defects on the surface of the steel, we design a re-parameterized large kernel spatial pyramid pooling (RepLK-SPP) module with different receptive fields, which replaces maxpooling layers with re-parameterized large kernel convolutions and changes the connection structure to parallel architecture. The structure of RepLK-C3 is shown in Figure 2b.
- We revisit the effects of using SPPF modules in the deeper layers of the network and refocus on multi receptive field feature extraction for each scale feature map. Based on this idea, we propose a multi-path re-parameterized large kernel spatial pyramid pooling feature fusion path in the neck network. Specifically, we removed the SPPF module from the bottom layer of the backbone network and used the newly proposed RepLK-SPP module to connect the down-sampled feature maps after the CBS module. This connection is marked with a red line in Figure 2.
3.3. Re-Parameterized Large Kernel Convolution C3 Module
3.4. Multi-Path RepLK-SPP Neck
4. Experiment
4.1. Dataset
4.2. Training Environment and Parameters
4.3. Evaluation Metrics
4.4. Experiment of Multi Kernel Size Re-Parameterized Large Kernel C3 Module
4.5. Experiment of Multi-Path RepLK-SPP Neck
4.6. Comparison of Different Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mordia, R.; Verma, A.K. Visual techniques for defects detection in steel products: A comparative study. Eng. Fail. Anal. 2022, 134, 106047. [Google Scholar] [CrossRef]
- Tang, B.; Chen, L.; Sun, W.; Lin, Z. Review of surface defect detection of steel products based on machine vision. IET Image Process. 2023, 17, 303–322. [Google Scholar] [CrossRef]
- Ramírez, I.S.; Márquez, F.P.G.; Papaelias, M. Review on additive manufacturing and non-destructive testing. J. Manuf. Syst. 2023, 66, 260–286. [Google Scholar] [CrossRef]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-Based Defect Detection and Classification Approaches for Industrial Applications—A Survey. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Yoon, S.; Fuentes, A.; Park, D.S. A Comprehensive Survey of Image Augmentation Techniques for Deep Learning. Pattern Recognit. 2023, 137, 109347. [Google Scholar] [CrossRef]
- Guo, Z.; Shuai, H.; Liu, G.; Zhu, Y.; Wang, W. Multi-level feature fusion pyramid network for object detection. Vis. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Guo, M.; Xu, T.; Liu, J.; Liu, Z.; Jiang, P.; Mu, T.; Zhang, S.; Martin, R.R.; Cheng, M.; Hu, S. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Usamentiaga, R.; Lema, D.G.; Pedrayes, O.D.; Garcia, D.F. Automated surface defect detection in metals: A comparative review of object detection and semantic segmentation using deep learning. IEEE Trans. Ind. Appl. 2022, 58, 4203–4213. [Google Scholar] [CrossRef]
- Wen, X.; Song, K.; Huang, L.; Niu, M.; Yan, Y. Complex surface ROI detection for steel plate fusing the gray I mage and 3D depth information. Optik 2019, 198, 163313. [Google Scholar] [CrossRef]
- Xu, K.; Liu, S.; Ai, Y. Application of Shearlet transform to classification of surface defects for metals. Image Vis. Comput. 2015, 35, 23–30. [Google Scholar] [CrossRef]
- Yan, X.; Wen, L.; Gao, L. A fast and effective image preprocessing method for hot round steel surface. Math. Probl. Eng. 2019, 2019, 9457826. [Google Scholar] [CrossRef]
- Chu, M.; Liu, X.; Gong, R.; Liu, L. Multi-class classification method using twin support vector machines with multi-information for steel surface defects. Chemom. Intell. Lab. Syst. 2018, 176, 108–118. [Google Scholar] [CrossRef]
- Yue, X.; Ma, G.; Liu, F.; Gao, X. Research on image classification method of strip steel surface defects based on improved Bat algorithm optimized BP neural network. J. Intell. Fuzzy Syst. 2021, 41, 1509–1521. [Google Scholar] [CrossRef]
- Wang, Y.; Xia, H.; Yuan, X.; Li, L.; Sun, B. Distributed defect recognition on steel surfaces using an Improved random forest algorithm with optimal multi-feature-set fusion. Multimed. Tools Appl. 2018, 77, 16741–16770. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, Y.; Balta, C.; Liu, J. A light-weight deep-learning model with multi-scale features for steel surface defect classification. Materials 2020, 13, 4629. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A new steel defect detection algorithm based on deep learning. Comput. Intell. Neurosci. 2021, 2021, 5592878. [Google Scholar] [CrossRef]
- Cheng, X.; Yu, J. RetinaNet with difference channel attention and adaptively spatial feature fusion for steel surface defect detection. IEEE Trans. Instrum. Meas. 2020, 70, 2503911. [Google Scholar] [CrossRef]
- Kou, X.; Liu, S.; Cheng, K.; Qian, Y. Development of a YOLO-V3-based model for detecting defects on steel strip surface. Measurement 2021, 182, 109454. [Google Scholar] [CrossRef]
- Zhao, C.; Shu, X.; Yan, X.; Zuo, X.; Zhu, F. RDD-YOLO: A modified YOLO for detection of steel surface defects. Measurement 2023, 214, 112776. [Google Scholar] [CrossRef]
- Liu, G.; Ma, Q. Strip steel surface defect detecting method combined with a multi-layer attention mechanism network. Meas. Sci. Technol. 2023, 34, 055403. [Google Scholar] [CrossRef]
- Yu, Y.; Chan, S.; Tang, T.; Zhou, X.; Yao, Y.; Zhang, H. Surface Defect Detection of Hot Rolled Steel Based on Attention Mechanism and Dilated Convolution for Industrial Robots. Electronics 2023, 12, 1856. [Google Scholar] [CrossRef]
- Fu, M.; Wu, J.; Wang, Q.; Sun, L.; Ma, Z.; Zhang, C.; Guan, W.; Li, W.; Chen, N.; Wang, D.; et al. Region-based fully convolutional networks with deformable convolution and attention fusion for steel surface defect detection in industrial Internet of Things. IET Signal Process. 2023, 17, e12208. [Google Scholar] [CrossRef]
- Wang, X.; Zhuang, K. An improved YOLOX method for surface defect detection of steel strips. In Proceedings of the 2023 IEEE 3rd International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 29–31 January 2023; pp. 152–157. [Google Scholar]
- Zhang, Y.; Wang, W.; Li, Z.; Shu, S.; Lang, X.; Zhang, T.; Dong, J. Development of a cross-scale weighted feature fusion network for hot-rolled steel surface defect detection. Eng. Appl. Artif. Intell. 2023, 117, 105628. [Google Scholar] [CrossRef]
- Bi, Z.; Wu, Q.; Shan, M.; Zhong, W. Segmentation-based Decision Networks for Steel Surface Defect Detection. J. Internet Technol. 2022, 23, 1405–1416. [Google Scholar]
- Tian, R.; Jia, M. DCC-CenterNet: A rapid detection method for steel surface defects. Measurement 2022, 187, 110211. [Google Scholar] [CrossRef]
- Li, M.; Wang, H.; Wan, Z. Surface defect detection of steel strips based on improved YOLOv4. Comput. Electr. Eng. 2022, 102, 108208. [Google Scholar] [CrossRef]
- Zheng, Z.; Hu, Y.; Zhang, Y.; Yang, H.; Qiao, Y.; Qu, Z.; Huang, Y. Casppnet: A chained atrous spatial pyramid pooling network for steel defect detection. Meas. Sci. Technol. 2022, 33, 085403. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Zhou, Y.; Ding, G. Scaling Up Your Kernels to 31 × 31: Revisiting Large Kernel Design in CNNs. arXiv 2022, arXiv:2203.06717. [Google Scholar]
- Liu, S.; Chen, T.; Chen, X.; Chen, X.; Xiao, Q.; Wu, B.; Pechenizkiy, M.; Mocanu, D.; Wang, Z. More convnets in the 2020s: Scaling up kernels beyond 51 × 51 using sparsity. arXiv 2022, arXiv:2207.03620. [Google Scholar]
- Han, Z.; Jian, M.; Wang, G.G. ConvUNeXt: An efficient convolution neural network for medical image segmentation. Knowl. Based Syst. 2022, 253, 109512. [Google Scholar] [CrossRef]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. InceptionNeXt: When Inception Meets ConvNeXt. arXiv 2023, arXiv:2303.16900. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An efficient pyramid split attention block on convolutional neural network. arXiv 2021, arXiv:2105.14447. [Google Scholar]
- Tang, R.; Liu, Z.; Song, Y.; Duan, G.; Tan, J. Hierarchical multi-scale network for cross-scale visual defect detection. J. Intell. Manuf. 2023, 1–17. [Google Scholar] [CrossRef]
- Yeung, C.C.; Lam, K.M. Efficient fused-attention model for steel surface defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 2510011. [Google Scholar] [CrossRef]
- Li, K.; Wang, X.; Ji, L. Application of multi-scale feature fusion and deep learning in detection of steel strip surface defect. In Proceedings of the 2019 International Conference on Artificial Intelligence and Advanced Manufacturing(AIAM), Dublin, Ireland, 17–19 October 2019; pp. 656–661. [Google Scholar]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. Msft-yolo: Improved yolov5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef]
- Jocher, G.; Nishimura, K.; Mineeva, T. YOLOv5. Code Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 23 May 2023).
- NEU Surface Defect Database. Available online: http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/index.html (accessed on 12 December 2022).
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9759–9768. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 23 May 2023).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Samples |
|---|---|
| Training | 1440 |
| Validation | 180 |
| Test | 180 |
| Experimental Environment | |
|---|---|
| Processor | Intel(R)Xeon(R)Platinum8358P CPU |
| Operating system | Linux |
| Ram | 32GB |
| Graphics card | RTX3090 GPU |
| Programming language | Python3.8 |
| Deep learning libraries | PyTorch1.8.1 |
| Deep learning toolkit | CUDA11 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Learning Rate | 0.01 | Weight Decay | 0.0005 |
| Batch Size | 32 | Momentum | 0.937 |
| Image Size | 640 × 640 | Epoch | 300 |
| Dataloader | 16 | Optimizer | SGD |
| Parameter | Value |
|---|---|
| HSV-Hue | 0.015 |
| HSV-Saturation | 0.7 |
| HSV-Value | 0.4 |
| Image scale | 0.5 |
| Image flip left-right | 0.5 |
| Mosaic | 1.0 |
| Schemes | P2 | P3 | P4 | P5 | P6 |
|---|---|---|---|---|---|
| 1 | 3 × 3 | 3 × 3 | 3 × 3 | 3 × 3 | 3 × 3 |
| 2 | 9 × 9 | 9 × 9 | 9 × 9 | 9 × 9 | 9 × 9 |
| 3 | 15 × 15 | 15 × 15 | 15 × 15 | 15 × 15 | 15 × 15 |
| 4 | 25 × 25 | 25 × 25 | 25 × 25 | 25 × 25 | 25 × 25 |
| 5 | 35 × 35 | 35 × 35 | 35 × 35 | 35 × 35 | 35 × 35 |
| 6 | 41 × 41 | 41 × 41 | 41 × 41 | 41 × 41 | 41 × 41 |
| 7 | 33 × 33 | 23 × 23 | 13 × 13 | 9 × 9 | 7 × 7 |
| 8 | 35 × 35 | 25 × 25 | 15 × 15 | 9 × 9 | 7 × 7 |
| 9 | 41 × 41 | 35 × 35 | 25 × 25 | 15 × 15 | 9 × 9 |
| Schemes | Precision (%) | Recalls (%) | mAP@0.5 (%) | Parameters | GFLOPS (G) |
|---|---|---|---|---|---|
| 1 | 69.6 | 66.4 | 70.7 | 12,337,892 | 16.3 |
| 2 | 65.0 | 70.0 | 69.9 | 12,976,356 | 16.7 |
| 3 | 63.9 | 71.7 | 72.4 | 13,294,308 | 17.6 |
| 4 | 68.3 | 72.2 | 72.3 | 14,177,508 | 20.3 |
| 5 | 63.6 | 72.6 | 71.0 | 15,502,308 | 24.2 |
| 6 | 65.8 | 68.6 | 70.5 | 16,509,156 | 27.2 |
| 7 | 66.2 | 71.4 | 70.6 | 13,115,108 | 19.4 |
| 8 | 73.4 | 65.5 | 72.0 | 13,170,660 | 20.2 |
| 9 | 62.7 | 74.3 | 72.8 | 13,645,540 | 23.1 |
| Schemes | P3 | P4 | P5 |
|---|---|---|---|
| 1 | 5, 5, 5 | 5, 5, 5 | 5, 5, 5 |
| 2 | 9, 15, 25 | 7, 9, 15 | 5, 7, 9 |
| 3 | 15, 25, 35 | 9, 15, 25 | 7, 9, 15 |
| 4 | 9, 35, 41 | 9, 25, 35 | 9, 15, 25 |
| 5 | 25, 35, 41 | 15, 25, 35 | 9, 15, 25 |
| Schemes | Precision (%) | Recall (%) | mAP@0.5 (%) | Parameters | GFLOPS (G) |
|---|---|---|---|---|---|
| 1 | 71.4 | 69.2 | 73.2 | 14,027,684 | 24.9 |
| 2 | 71.1 | 66.7 | 73.3 | 14,256,868 | 26.1 |
| 3 | 75.0 | 69.5 | 75.1 | 14,504,676 | 27.4 |
| 4 | 69.9 | 73.3 | 75.6 | 14,739,364 | 28.9 |
| 5 | 76.1 | 70.7 | 76.8 | 14,905,572 | 29.7 |
| Types | Faster R-CNN | RetinaNet | RetinaNet-SW | YOLOv3 | YOLOv5 | YOLOv8 | OURS | |
|---|---|---|---|---|---|---|---|---|
| AP (%) | CR | 54.5 | 50.8 | 50.2 | 40.7 | 38.5 | 53.9 | 52.9 |
| IN | 81.1 | 77.8 | 77.3 | 78.0 | 77.0 | 78.0 | 87.5 | |
| PA | 89.3 | 89.5 | 87.7 | 90.5 | 90.7 | 90.4 | 92.4 | |
| PS | 79.8 | 80.4 | 84.5 | 78.7 | 75.0 | 89.0 | 82.0 | |
| RS | 62.5 | 62.8 | 62.4 | 52.3 | 57.1 | 42.1 | 68.2 | |
| SC | 82.6 | 55.3 | 72.5 | 71.4 | 70.9 | 85.2 | 77.5 | |
| mAP@0.5 (%) | 75.0 | 69.5 | 72.4 | 68.6 | 68.2 | 73.1 | 76.8 | |
| FPS (f/s) | 23.4 | 63.4 | 46.1 | 75.2 | 133.3 | 117.6 | 67.1 | |
| Parms (Mb) | 41.2 | 277.0 | 282.0 | 117.0 | 13.8 | 21.5 | 28.9 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, K.; Lv, Z.; Zhou, C.; Gu, G.; Zhao, Z.; Liu, K.; Li, Z. Mixed Receptive Fields Augmented YOLO with Multi-Path Spatial Pyramid Pooling for Steel Surface Defect Detection. Sensors 2023, 23, 5114. https://doi.org/10.3390/s23115114
Xia K, Lv Z, Zhou C, Gu G, Zhao Z, Liu K, Li Z. Mixed Receptive Fields Augmented YOLO with Multi-Path Spatial Pyramid Pooling for Steel Surface Defect Detection. Sensors. 2023; 23(11):5114. https://doi.org/10.3390/s23115114
Chicago/Turabian StyleXia, Kewen, Zhongliang Lv, Chuande Zhou, Guojun Gu, Zhiqiang Zhao, Kang Liu, and Zelun Li. 2023. "Mixed Receptive Fields Augmented YOLO with Multi-Path Spatial Pyramid Pooling for Steel Surface Defect Detection" Sensors 23, no. 11: 5114. https://doi.org/10.3390/s23115114