

Hardware–Software Partitioning for Real-Time Object Detection Using Dynamic Parameter Optimization


Abstract
:1. Introduction
2. Related Work
3. Proposed Method
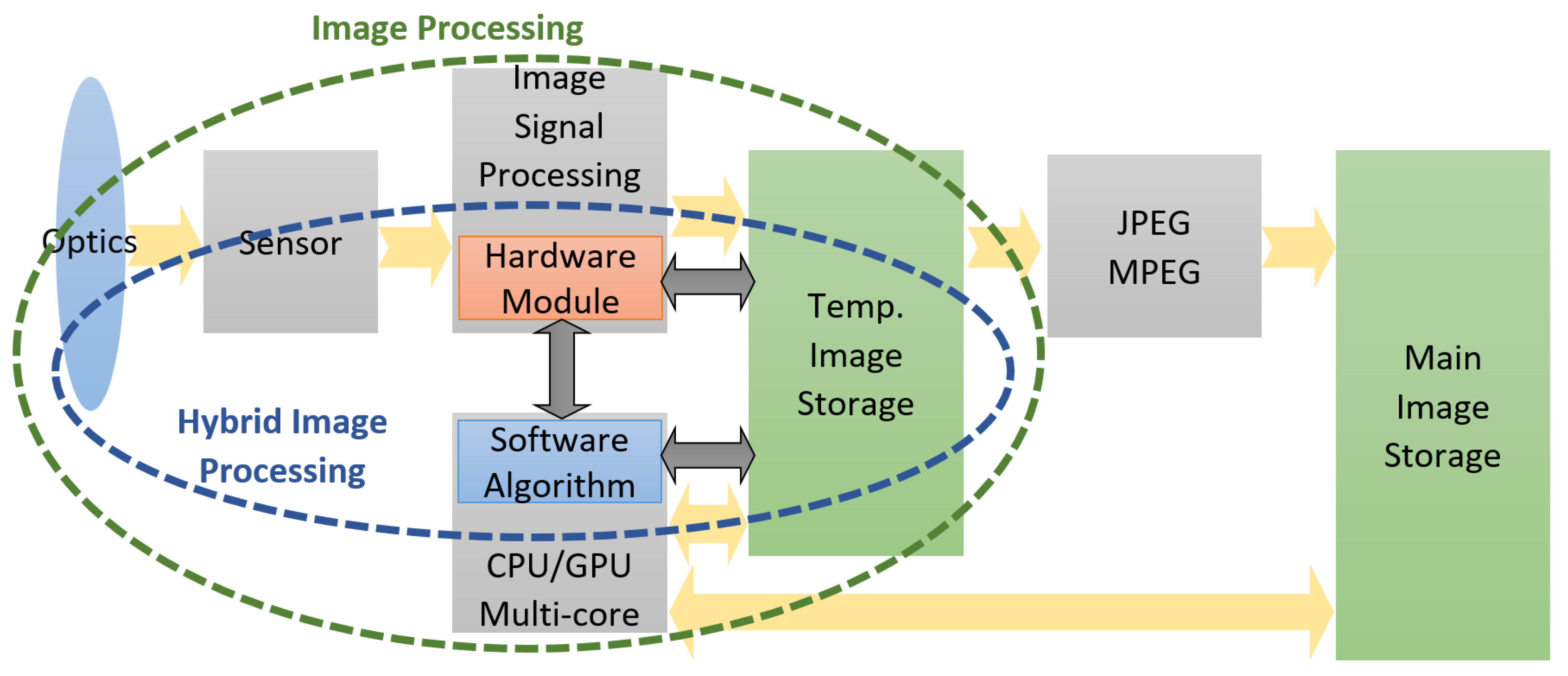
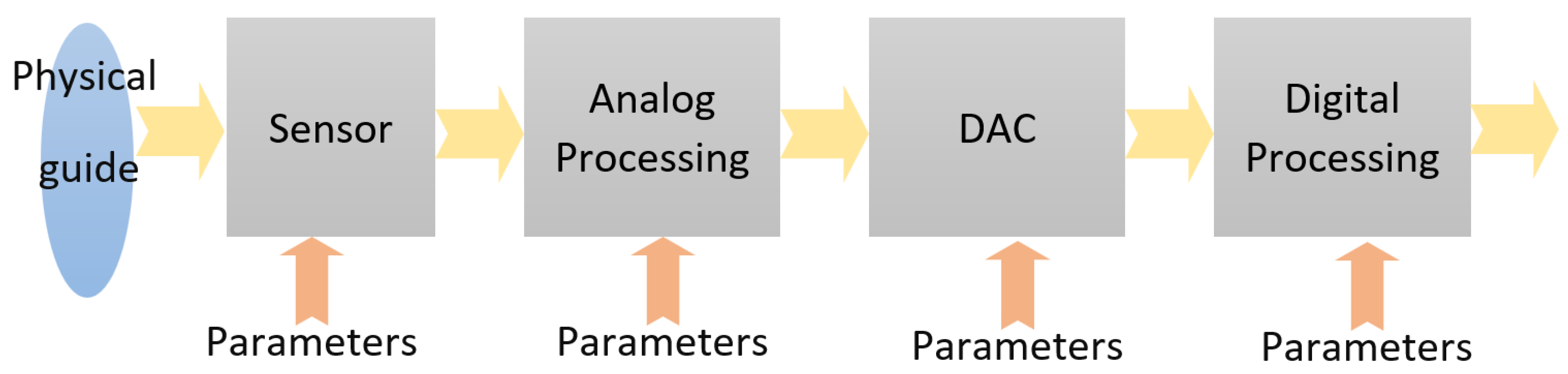
3.1. Rationale of a Hybrid HW–SW Solution for RT CV
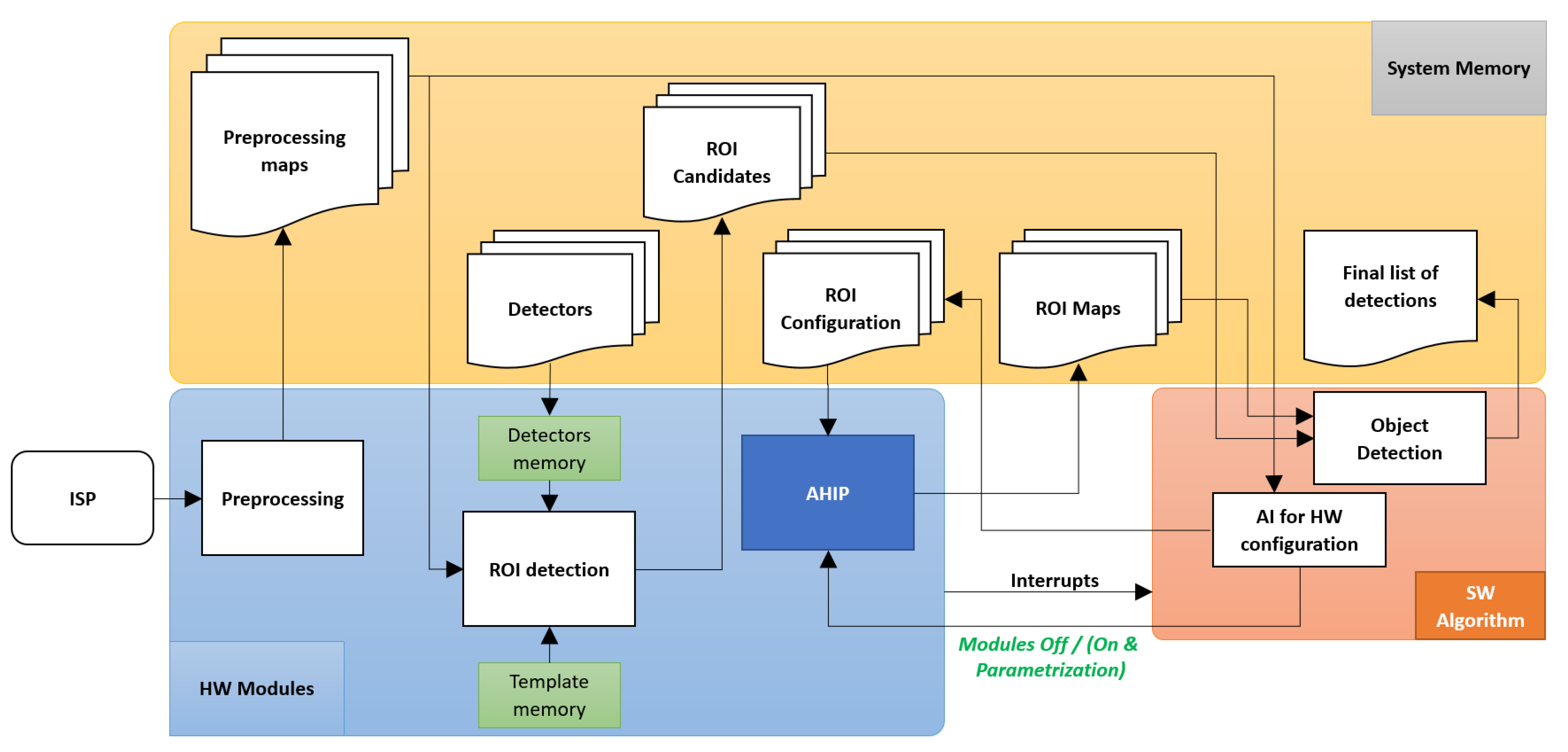
3.2. The Anticipative HW Parametrization by the AI
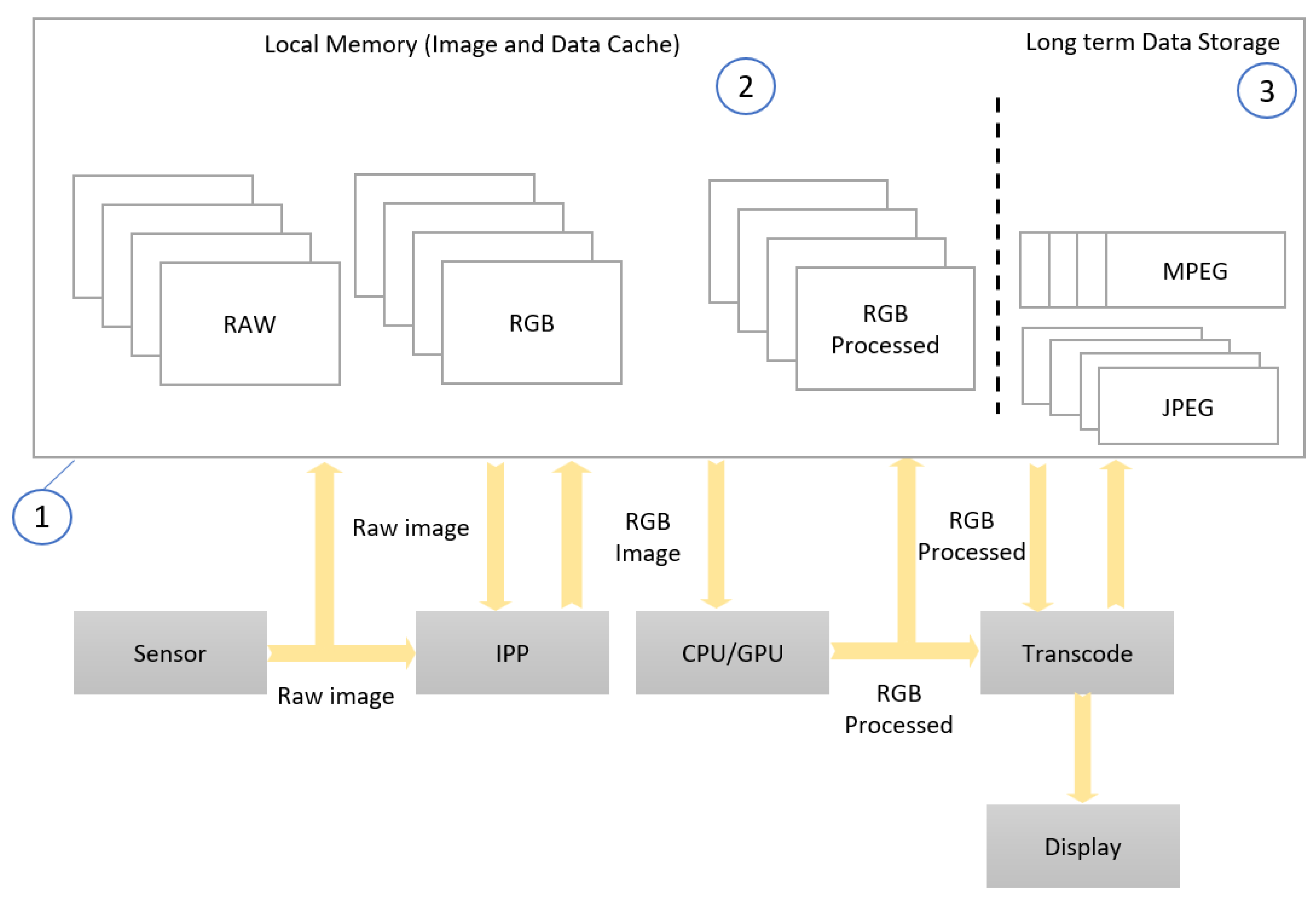
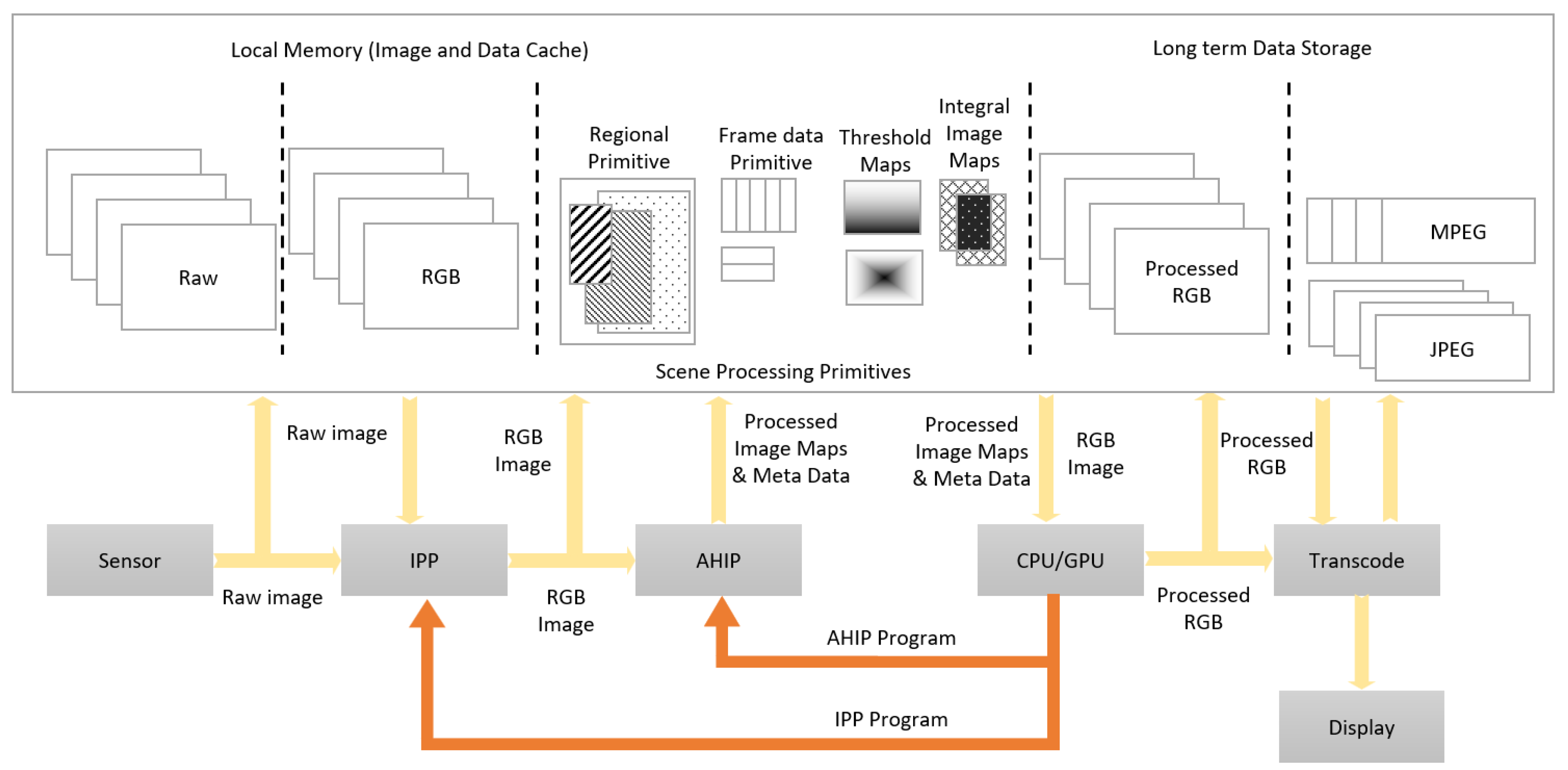
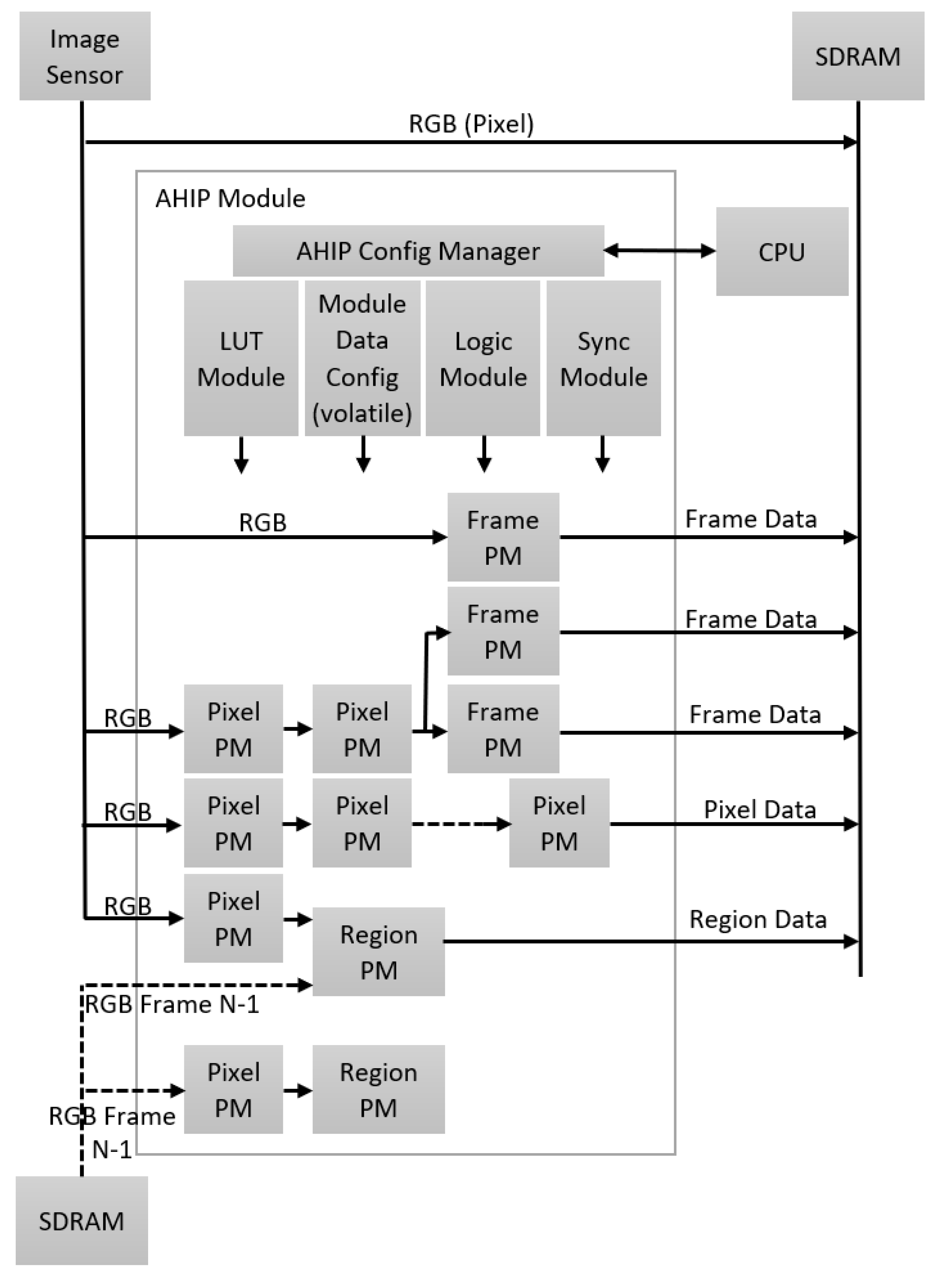
3.3. Implementing the HW–SW Partition Using AHIP
- -
- In case an unevenly illuminated face appears, the artificial intelligence runs several classifiers in parallel on the acquired data, in order to detect different lighting conditions—the classifier designated as the most suitable also computes the relevant lighting conditions and a specific correction to be applied so that the face acquired obtains an uniform illumination; the artificial intelligence can optionally further consider the unevenly illuminated face (as it is) to be tracked, edited, memorized, or processed accordingly.
- -
- In case lower light frames are observed in the input stream, the AI for configuration rewrites the LUT modules (inside AHIP) that provide the luminosity parameters for the Pixel PM blocks—see Figure 6.
- -
- In case there are not enough details in the input frames, the AI for hardware configuration concludes that the objects presented are very big, so the image scaling parameters are set for a high down-scaling factor for the Pixel PM block in Figure 6.
- -
- For a regular image exposure, the image data analyzed show enough information to be extracted by the ROI detector, so, in this case, artificial intelligence decides that most of the Pixel PM blocks are disabled (powered down—“off”).
- -
- In case perspective corrections are needed (when the ROI is deformed due to position outside the image plane), the AHIP computes the vertical and horizontal alignment characteristics as frame PM. The perspective parameters are computed by artificial intelligence for instantiation and are used for the ROI distortion correction module inside AHIP.
- -
- In the case of the ROI rotation in the plane, the region PMs are used to correct the rotation to a pre-defined angle. AI for instantiation determines the rotation angle for ROI and sets the proper rotation parameters per each ROI. In case the ROI does not need in-plane rotation, the region PMs are shut-down.
4. Results
4.1. FPGA-Based Proof of Concept
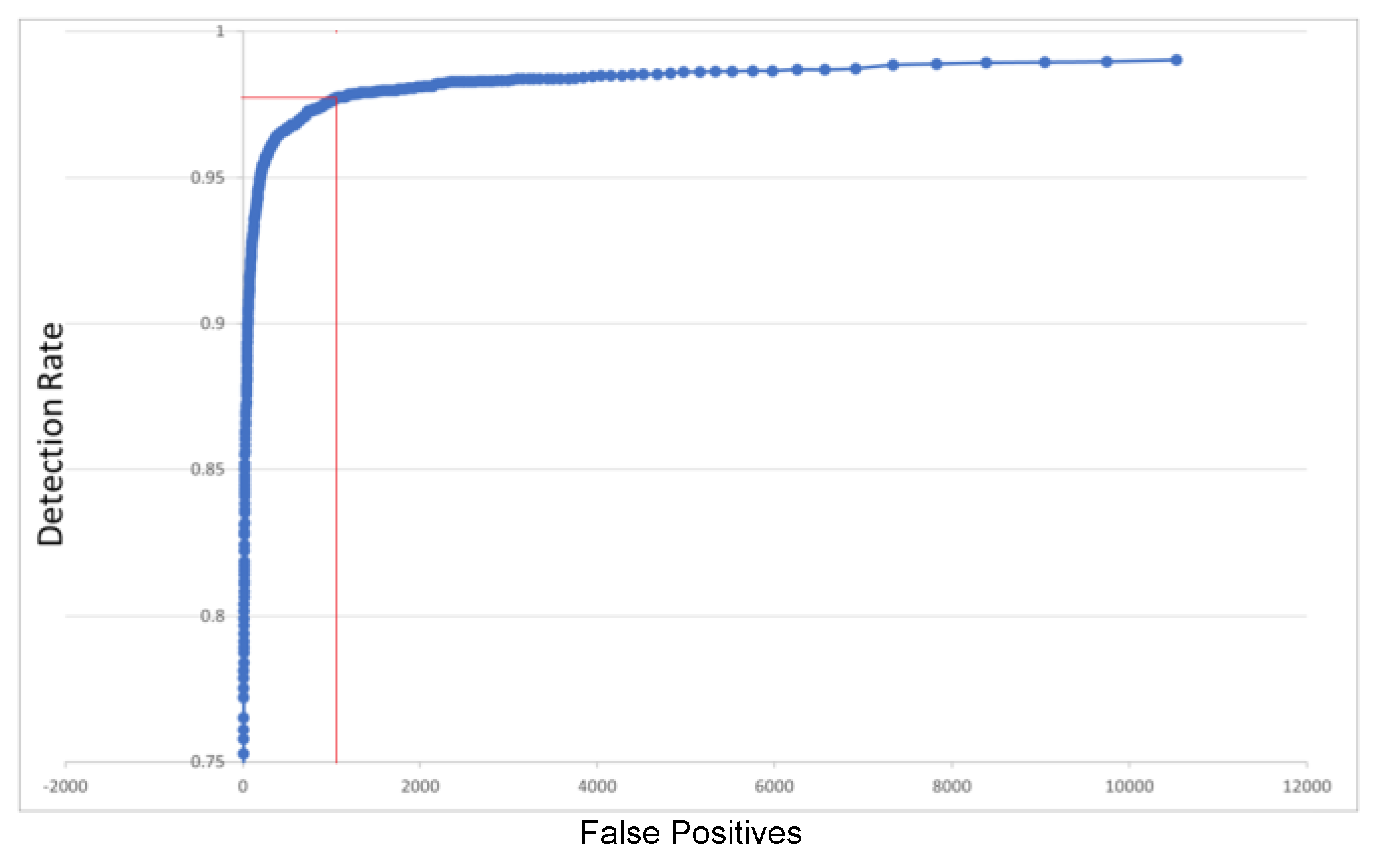
4.2. Face Detection Testing
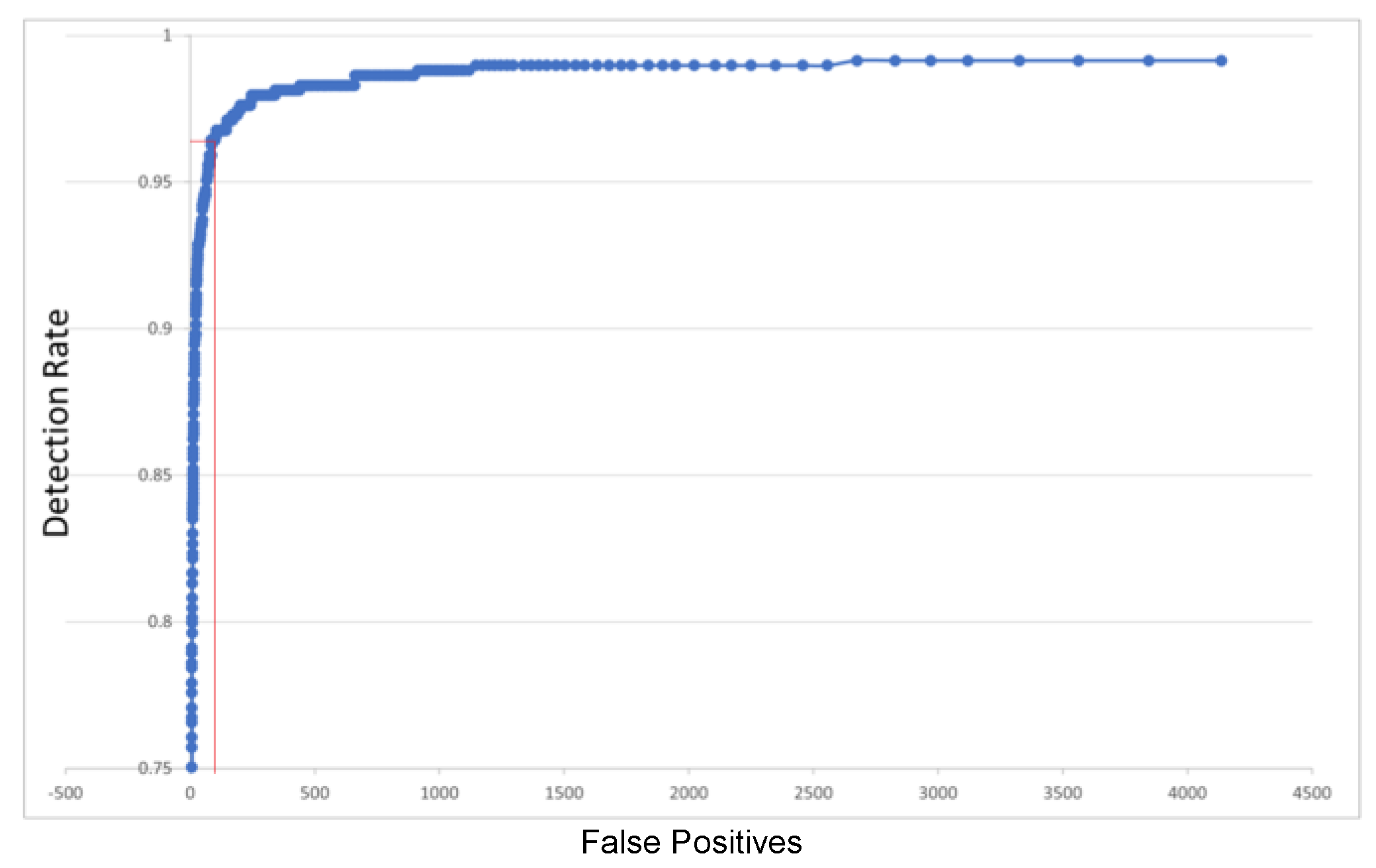
4.3. Person Detection Testing
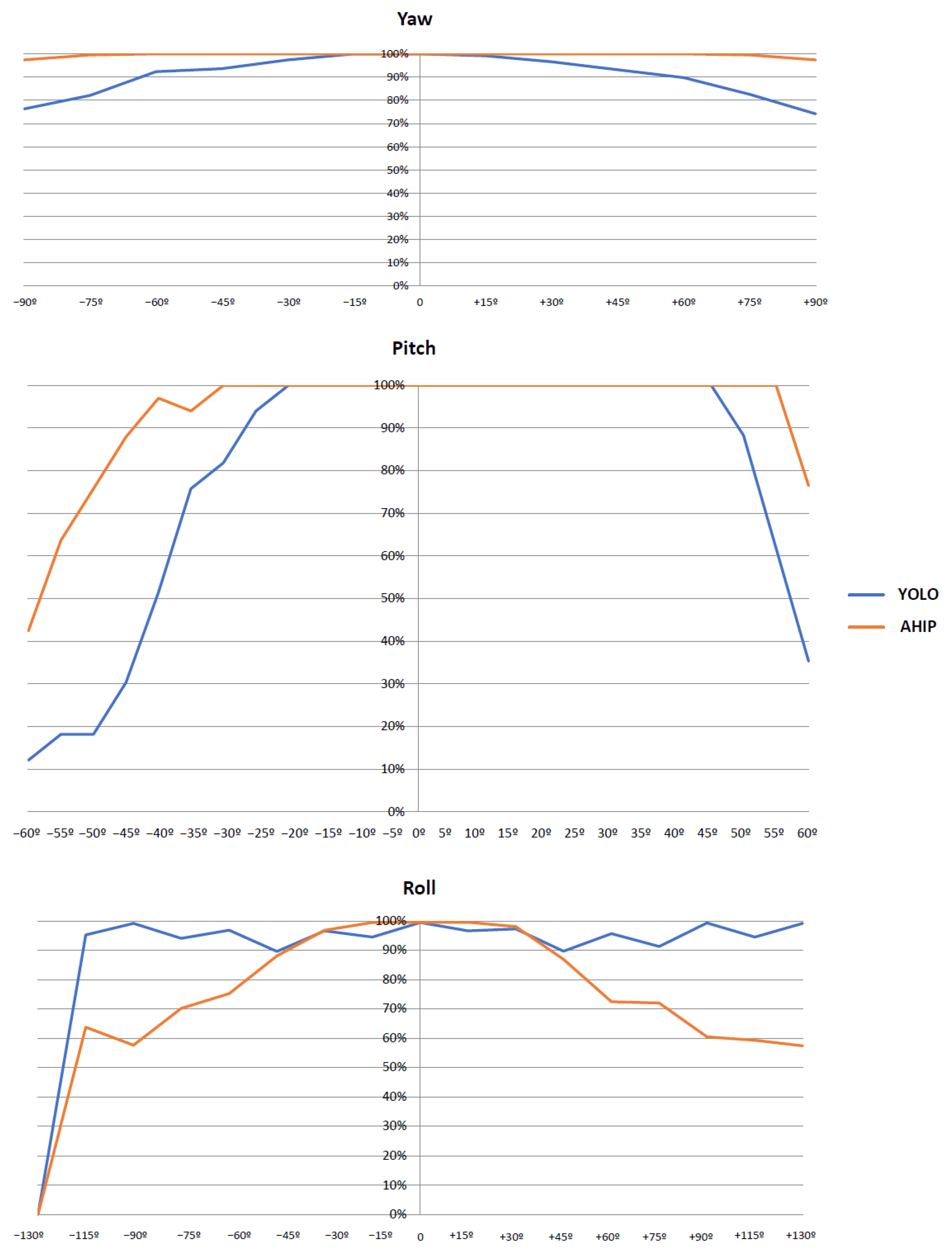
4.4. Object Detection for Different Orientations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- -
- TP (“True Positives”)—the number of existing objects detected (the algorithm response is correct)
- -
- TN (“True Negatives”)—the number of non-existent objects declared as undetected (the algorithm response is correct)
- -
- FP (“False Positives”)—the number of non-existent objects declared as detected (the algorithm response is incorrect)
- -
- FN (“False Negatives”)—the number of existing undetected objects (the algorithm response is incorrect).
Appendix B



Appendix C

References
- Gadepally, V.; Goodwin, J.; Kepner, J.; Reuther, A.; Reynolds, H.; Samsi, S.; Su, J.; Martinez, D. AI enabling technologies: A survey. arXiv 2019, arXiv:1905.03592. [Google Scholar]
- Turley, J. Introduction to Intel® Architecture: The Basics; Intel Corporation: Santa Clara, CA, USA, 2014. [Google Scholar]
- ARM7TDMI Technical Reference Manual r4p1. Available online: https://developer.arm.com/documentation/ddi0210/c/Introduction/Block--core--and-functional-diagrams (accessed on 15 February 2023).
- BA22-CE 32-bit Cache-Enabled Embedded Processor. Available online: https://www.cast-inc.com/processors/32-bit/ba22-ce (accessed on 15 February 2023).
- Waterman, A.; Lee, Y.; Patterson, D.; Asanovic, K. The RISC-V Compressed Instruction Set Manual. 2015. Available online: https://riscv.org/wp-content/uploads/2015/05/riscv-compressed-spec-v1.7.pdf (accessed on 15 February 2023).
- Ang, L.M.; Seng, K.P. GPU-Based Embedded Intelligence Architectures and Applications. Electronics 2021, 10, 952. [Google Scholar] [CrossRef]
- Qualcomm—DSP Processor. Available online: https://developer.qualcomm.com/software/hexagon-dsp-sdk/dsp-processor (accessed on 15 February 2023).
- Texas Instruments. Vision-Based Advanced Driver Assistance: TI Hopes You’ll Give Its Latest SoCs a Chance. Available online: https://www.bdti.com/InsideDSP/2013/10/23/TI (accessed on 16 February 2023).
- Vision DSP. CEVA-XM4—Intelligent Imaging and Vision Processor for Low-Power Embedded Systems. Available online: https://www.ceva-dsp.com/product/ceva-xm4/ (accessed on 16 February 2023).
- Harris, M. Inside Pascal: NVIDIA’s Newest Computing Platform. 2016. Available online: https://developer.nvidia.com/blog/inside-pascal/ (accessed on 16 February 2023).
- ARM. Mali-G72/-470. Available online: https://developer.arm.com/Processors/Mali-G72 (accessed on 16 February 2023).
- Beets, K. Imagination—Introducing Furian: The Architectural Changes. Available online: https://blog.imaginationtech.com/introducing-furian-the-architectural-changes/ (accessed on 16 February 2023).
- Movidius—VPU Product Brief. Available online: https://static6.arrow.com/aropdfconversion/5a53549959ba1304f155469049d98b3ade903558/1463156689-2016-04-29_vpu_productbrief.pdf (accessed on 16 February 2023).
- Jang, J.W.; Lee, S.; Kim, D.; Park, H.; Ardestani, A.S.; Choi, Y.; Kim, C.; Kim, Y.; Yu, H.; Abdel-Aziz, H.; et al. Sparsity-aware and re-configurable NPU architecture for Samsung flagship mobile SoC. In Proceedings of the ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; pp. 15–28. [Google Scholar]
- Schiesser, T. AMD Launches RYZEN 6000 Series for Laptops: What’s New with the Zen 3+ Architecture? Available online: https://www.techspot.com/news/93424-amd-launches-ryzen-6000-mobile-what-new-zen.html (accessed on 16 February 2023).
- Verisilicon—Neural Network Processor IP Series for AI Vision and AI Voice. Available online: https://verisilicon.com/en/IPPortfolio/VivanteVIP9000 (accessed on 16 February 2023).
- Boukhtache, S.; Blaysat, B.; Grédiac, M.; Berry, F. FPGA-based architecture for bi-cubic interpolation: The best trade-off between precision and hardware resource consumption. J. Real-Time Image Process. 2021, 18, 901–911. [Google Scholar] [CrossRef]
- Xilinx Zynq®-7000 SoC First Generation Architecture. Available online: https://www.mouser.co.uk/new/xilinx/xilinx-zynq-7000-socs/ (accessed on 16 February 2023).
- Intel® Arria® 10 FPGAs & SoCs. Available online: https://www.intel.com/content/www/us/en/products/details/fpga.html (accessed on 16 February 2023).
- Xilinx—Flexible DSP Solutions. Available online: https://www.xilinx.com/products/technology/dsp.html (accessed on 16 February 2023).
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, CA, USA, 24–28 June 2017; ACM: New York, NY, USA; pp. 1–12. [Google Scholar]
- IBM—The Brain’s Architecture, Efficiency… on a Chip. Available online: www.ibm.com/blogs/research/2016/12/the-brains-architecture-efficiency-on-a-chip (accessed on 17 February 2023).
- Intel—Lake Crest/Spring Crest/Spring Hill—Microarchitectures. Available online: https://en.wikichip.org/wiki/intel/microarchitectures/spring_hill (accessed on 16 February 2023).
- Buckler, M.; Jayasuriya, S.; Sampson, A. Reconfiguring the imaging pipeline for computer vision. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Hansen, P.; Vilkin, A.; Krustalev, Y.; Imber, J.; Talagala, D.; Hanwell, D.; Mattina, M.; Whatmough, P.N.J. ISP4ML: The Role of Image Signal Processing in Efficient Deep Learning Vision Systems. In Proceedings of the 25th IEEE International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2438–2445. [Google Scholar]
- Ao, H.; Guoyi, Y.; Qianjin, W.; Dongxiao, H.; Shilun, Z.; Bingqiang, L.; Yu, Y.; Yuwen, L.; Chao, W.; Xuecheng, Z. Efficient Hardware Accelerator Design of Non-Linear Optimization Correlative Scan Matching Algorithm in 2D LiDAR SLAM for Mobile Robots. Sensors 2022, 22, 8947. [Google Scholar] [CrossRef] [PubMed]
- Merolla, P.; Arthur, J.; Akopyan, F.; Imam, N.; Manohar, R.; Modha, D.S. A digital neurosynaptic core using embedded crossbar memory with 45pJ per spike in 45nm. In Proceedings of the IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 19–21 September 2011; pp. 1–4. [Google Scholar]
- Sandamirskaya, Y.; Kaboli, M.; Conradt, J.; Celikel, T. Neuromorphic computing hardware and neural architectures for robotics. Sci. Robot. 2022, 7, eabl8419. [Google Scholar] [CrossRef] [PubMed]
- Mittal, S.; Umesh, S. A survey on hardware accelerators and optimization techniques for RNNs. J. Syst. Archit. 2021, 112, 101839. [Google Scholar] [CrossRef]
- Ghaffari, S.; Soleimani, P.; Li, K.F.; Capson, D. FPGA-based implementation of HOG algorithm: Techniques and challenges. In Proceedings of the IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 21–23 August 2019. [Google Scholar]
- Long, X.; Hu, S.; Hu, Y.; Gu, Q.; Ishii, I. An FPGA-Based Ultra-High-Speed Object Detection Algorithm with Multi-Frame Information Fusion. Sensors 2019, 19, 3707. [Google Scholar] [CrossRef]
- Rzaev, E.; Khanaev, A.; Amerikanov, A. Neural Network for Real-Time Object Detection on FPGA. In Proceedings of the 2021 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russia, 17–21 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 719–723. [Google Scholar]
- Shimoda, M.; Sada, Y.; Kuramochi, R.; Nakahara, H. An FPGA Implementation of Real-time Object Detection with a Thermal Camera. In Proceedings of the 29th IEEE International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 413–414. [Google Scholar]
- Günay, B.; Okcu, S.B.; Bilge, H.S. LPYOLO: Low Precision YOLO for Face Detection on FPGA. arXiv 2022, arXiv:2207.10482. [Google Scholar]
- Wang, Z.; Xu, K.; Wu, S.; Liu, L.; Liu, L.; Wang, D. Sparse-YOLO: Hardware/software co-design of an FPGA accelerator for YOLOv2. IEEE Access 2020, 8, 116569–116585. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling cross stage partial network. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Yang, Z.; Shi, P.; Pan, D. A Survey of Super-Resolution Based on Deep Learning. In Proceedings of the 2020 International Conference on Culture-Oriented Science Technology (ICCST), Beijing, China, 30–31 October 2020; pp. 514–518. [Google Scholar]
- Talab, M.A.; Awang, S.; Najim, S.A.D.M. Super-Low Resolution Face Recognition using Integrated Efficient Sub-Pixel Convolutional Neural Network (ESPCN) and Convolutional Neural Network (CNN). In Proceedings of the 2019 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Selangor, Malaysia, 29 June 2019; pp. 331–335. [Google Scholar]
- Kang, J.S.; Kang, J.K.; Kim, J.J.; Jeon, K.W.; Chung, H.J.; Park, B.H. Neural Architecture Search Survey: A Computer Vision Perspective. Sensors 2023, 23, 1713. [Google Scholar] [CrossRef] [PubMed]
- Wu, A.; Han, Y.; Zhu, L.; Yang, Y. Instance-invariant domain adaptive object detection via progressive disentanglement. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4178–4193. [Google Scholar] [CrossRef] [PubMed]
- Wu, A.; Han, Y.; Zhu, L.; Yang, Y. Universal-prototype enhancing for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9567–9576. [Google Scholar]
- Wu, A.; Deng, C. Single-Domain Generalized Object Detection in Urban Scene via Cyclic-Disentangled Self-Distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 847–856. [Google Scholar]
- Jain, V.; Learned-Miller, E. FDDB: A Benchmark for Face Detection in Unconstrained Settings—UMass Amherst Technical Report. 2010, Volume 2. Available online: http://crowley-coutaz.fr/jlc/Courses/2020/PRML/fddb-DataBasePaper.pdf (accessed on 23 February 2023).
- Putro, M.D.; Priadana, A.; Nguyen, D.L.; Jo, K.H. A Faster Real-time Face Detector Support Smart Digital Advertising on Low-cost Computing Device. In Proceedings of the IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Sapporo, Japan, 11–15 July 2022; pp. 171–178. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Saeidi, M.; Arabsorkhi, A. A novel backbone architecture for pedestrian detection based on the human visual system. Vis. Comput. 2021, 38, 2223–2237. [Google Scholar] [CrossRef]
- Lan, W.; Dang, J.; Wang, Y.; Wang, S. Pedestrian Detection Based on YOLO Network Model. In Proceedings of the IEEE International Conference on Mechatronics and Automation ICMA 2018, Changchun, China, 5–9 August 2018; pp. 1547–1551. [Google Scholar]
- Li, R.; Zu, Y. Research on Pedestrian Detection Based on the Multi-Scale and Feature-Enhancement Model. Information 2023, 14, 123. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany; Volume 13, pp. 740–755. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20–25 June 2019; pp. 658–666. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Face Detector | Detection Rate * |
|---|---|
| ACETRON | 0.9752 |
| AHIP | 0.9750 |
| FlashNet | 0.9733 |
| LFFD (Light and Fast Face Detector) | 0.9731 |
| RetinaFace-mobile | 0.9725 |
| FCPU (Face-CPU) | 0.9700 |
| Pedestrian Detector | Miss Rate |
|---|---|
| AHIP | 3.468% |
| Saeidi-Arabsorkhi [46] | 6.18% |
| PCN (Part and Context Network) [46] | 6.86% |
| F-DNN (Fused DNN) [46] | 6.78% |
| YOLOv2 * [47] | 11.29% |
| SketchTokens * [46,47] | 13.32% |
| HikSVM* (Histogram Intersection Kernel) [47] | 42.82% |
| HOG * [46,47] | 45.98% |
| VJ * (Viola-Jones) [46,47] | 72.48% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaharia, C.; Popescu, V.; Sandu, F. Hardware–Software Partitioning for Real-Time Object Detection Using Dynamic Parameter Optimization. Sensors 2023, 23, 4894. https://doi.org/10.3390/s23104894
Zaharia C, Popescu V, Sandu F. Hardware–Software Partitioning for Real-Time Object Detection Using Dynamic Parameter Optimization. Sensors. 2023; 23(10):4894. https://doi.org/10.3390/s23104894
Chicago/Turabian StyleZaharia, Corneliu, Vlad Popescu, and Florin Sandu. 2023. "Hardware–Software Partitioning for Real-Time Object Detection Using Dynamic Parameter Optimization" Sensors 23, no. 10: 4894. https://doi.org/10.3390/s23104894