1. Introduction
Due to the presence of various objects in the working environment, path planning for robots is one of the most important topics in robotics research and is widely discussed [
1,
2,
3,
4]. If the robot does not have a good path planning method to choose a collision-free path, various collision situations may occur. Once a collision occurs, unpredictable or large losses may be caused. Therefore, many researchers devote themselves to the field of collision-free path planning. Based on differential search methods, path planning algorithms are divided into three categories: search-based, heuristic-based, and sampling-based. The A* algorithm proposed by Hart et al. is a search-based path planning algorithm [
5]. It first models the environment and then determines objective node information to avoid ineffective exploration of the environment and find a better solution efficiently. However, when exploring high-dimensional spaces or wide environments, the computing time of the A* algorithm increases significantly. The ant colony system proposed by Dorigo et al. is a heuristic-based path planning algorithm [
6]. It finds a better solution through a function, iteration by iteration, in each exploration of the environment. However, the convergence speed of the heuristic-based algorithm cannot be guaranteed. Due to the long computing times of search-based and heuristic-based path planning algorithms, they are not suitable for real-time system applications. The probabilistic roadmap algorithm proposed by Kavraki et al. is a sampling-based path planning algorithm [
7]. The advantage of the sampling-based algorithm is that it reduces the burden of modeling the environment by using sampling points to scatter the entire space into a partial area of the environment. This makes it easy to represent all the features of the environment. It can handle the path planning of robots in high-dimensional spaces. However, the search efficiency and success rate of the probabilistic roadmap will decrease when there are dense obstacles in space. The rapidly-exploring random tree (RRT) proposed by LaValle is also a sampling-based path planning algorithm [
8]. It combines the advantages of sampling and searching abilities in the environment. Random trees will randomly expand new nodes in the environment. This algorithm not only inherits the advantages of the fast search speed of the probabilistic roadmap algorithm but can also perform a wide range of exploration in the environment, which is more powerful to deal with the online path planning of high-dimensional spaces.
Although the basic RRT algorithm can find a better path in the search space relatively quickly, it still has some problems that need to be improved, such as spending a lot of time exploring some invalid areas. Therefore, there have been many studies aimed at improving the basic RRT algorithm. For example, Wang et al. proposed an RRT algorithm based on a node control mechanism [
9]. Based on this mechanism, the node expansion of the random tree is constrained by defined conditions, which reduces the generation of invalid nodes and thus finds a better solution more efficiently than most RRT algorithms, especially in narrow areas of the search space. Kang et al. proposed an RRT algorithm based on a goal-oriented mechanism [
10]. It improves the search efficiency by increasing the sampling probability of the search point that is near the target. In addition, the sampling strategy is appropriately switched through the node counting mechanism to adapt to the complex environment. In addition, sometimes the RRT algorithm will overfocus on the goal area, which makes it difficult to find a path when encountering a complex environment. On the other hand, if the algorithm only focuses on improving its adaptability, it will not be fast enough to find a path to the goal in simple environments. Therefore, there are still many ways to improve the path planning for robot applications. In order to improve the computing time and environmental adaptability of the existing RRT algorithm, an improved RRT algorithm is proposed in this paper.
Path planning is important for any robot. In addition, we can find a wide range of industrial applications for robot pick-and-place operations on robot manipulators [
11,
12,
13]. This research includes the discussion of path planning, object picking and placing, collision avoidance, and control of the robot manipulator. Many improved RRT algorithms have been used in robot manipulators to achieve good results. However, most of them only established a simulated environment to present simulation results. In order to illustrate the proposed RRT algorithm, let a real robot manipulator perform object pick-and-place tasks in real time. The robot operating system (ROS) is used to design and integrate the hardware and software of an object pick-and-place system. Since ROS can transmit or receive different types of data at the same time through “messages” and “services”, it is one of the most popular platforms for research in robotics. Moreover, MoveIt, which is open-source motion planning software, has been widely used in industry and research. It is easy to integrate with ROS to set up new robots, and it is already available for more than 150 robots. Therefore, in the design of motion planning, MoveIt is used to complete the required motion of the robot manipulator.
There are six sections in this paper. In
Section 1, the background is introduced. In
Section 2, an implemented object pick-and-place system based on ROS is described. In
Section 3, three sampling strategies used in the RRT algorithms are described. In
Section 4, a basic RRT algorithm and an improved RRT algorithm based on an existing RRT algorithm are described. In
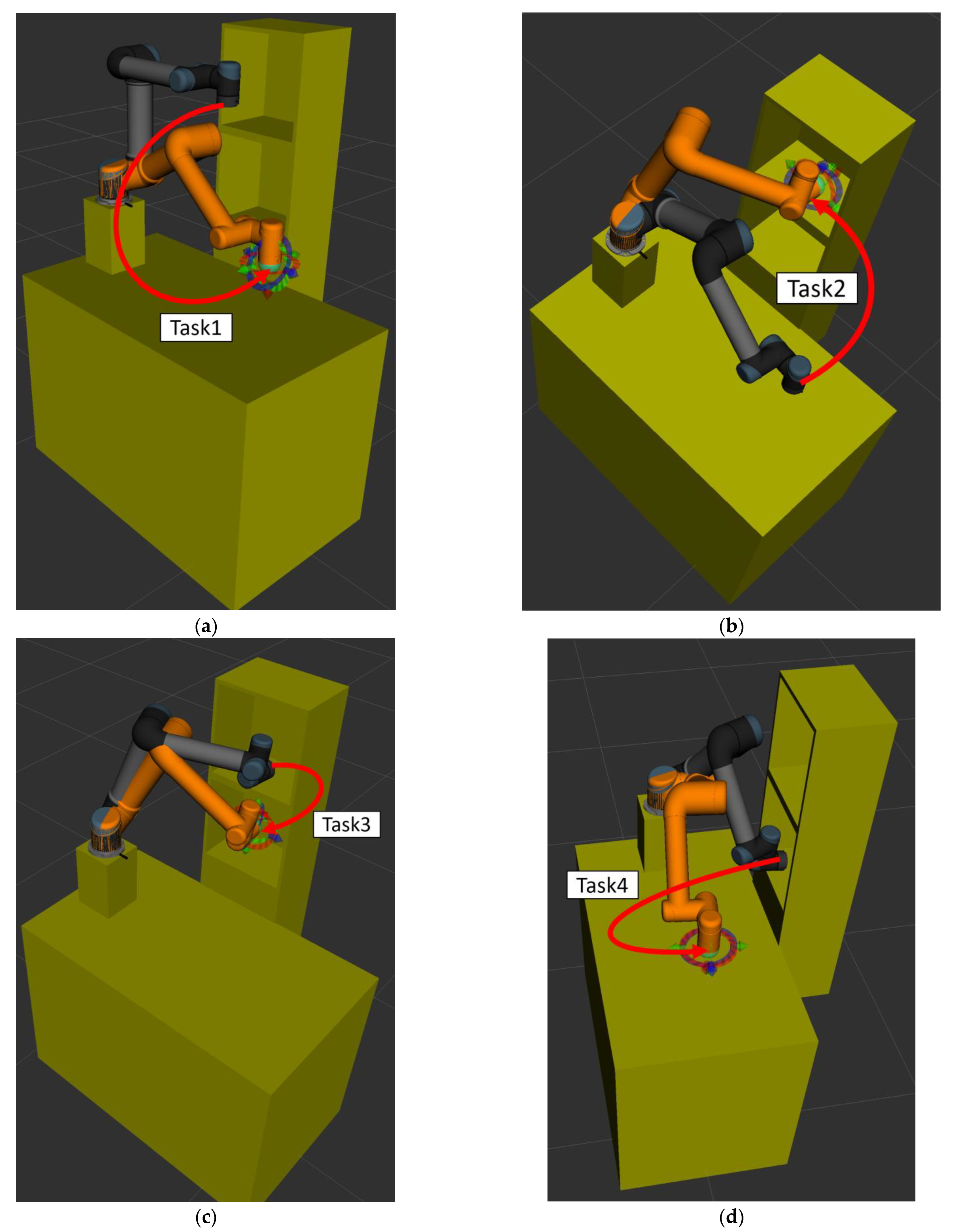
Section 5, an experimental environment with four pick-and-place tasks is setup, and some simulation and actual experimental results are presented to illustrate that the implemented object pick-and-place system using the proposed RRT algorithm can allow a robot manipulator to pick and place objects in real time. Finally, conclusions and future work are described in
Section 6.
2. ROS-Based Object Pick-and-Place System
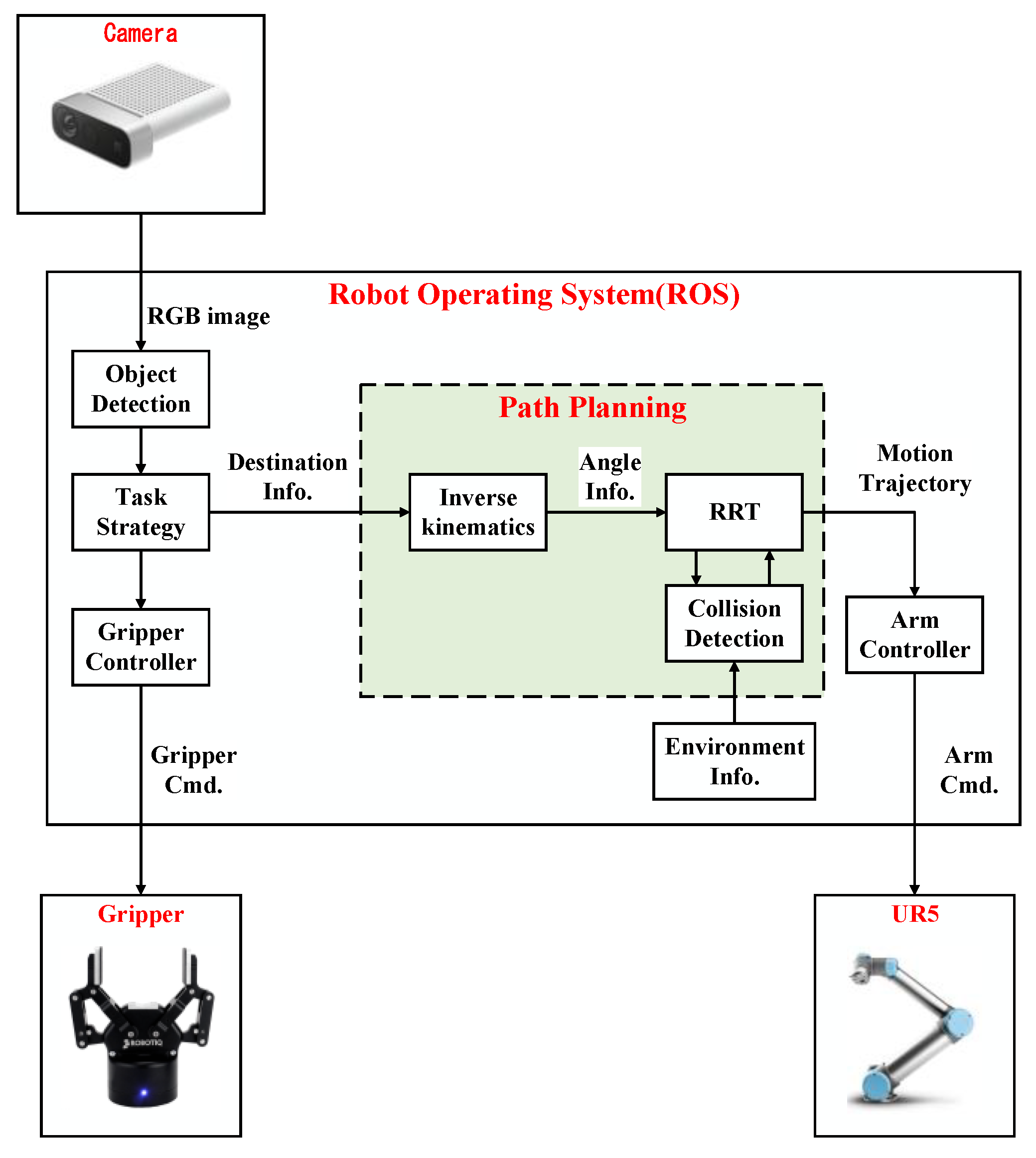
The system architecture diagram of the implemented ROS-based object pick-and-place system is shown in
Figure 1. The input of this system is the RGB image captured by Microsoft Azure Kinect DK (a RGB-D camera), and the outputs are the control commands of Universal Robots UR5 (six-degree-of-freedom (DOF) robot manipulator) and Robotiq 2F-85 (a two-finger parallel gripper). Azure Kinect DK has the features of a wide field of view and easy installation; it is directly installed on a bracket to capture images on the table. UR5 has some features, such as a light weight, a user-friendly interface, and collision detection capability. The related unified robot description format (URDF) files for the specific MoveIt applications are also provided. These features make experiments easy to perform and avoid collisions between the robot manipulator and surrounding objects during the experiment. Robotiq 2F-85 is easily integrated into robot manipulators. It has the feature that it can avoid damage to the gripper itself and prevent the robot manipulator from injuring the object during the grasping task.
The object detection module is implemented by the you only look once (YOLO) algorithm [
14] to obtain the position information of the object on the table from the captured RGB image. The task strategy module is used to decide the destination of the robot manipulator when a pick-and-place task is given. The path planning module is implemented by the improved RRT algorithm, which can quickly select a collision-free path so that the robot manipulator and the two-finger gripper can successfully complete the given tasks in real-time.
In the system integration of the proposed pick-and-place system, ROS is used to handle the communication between each module. The robot motion information is calculated by MoveIt through ROS. The version of ROS Melodic with Ubuntu 18.04 is used. MoveIt is an open-source motion planning software that is a state-of-the-art implementation of robot motion and path planning. Thus, it is used for the motion planning of the robot manipulator. MoveIt provides a variety of functional packages for users to choose from and integrates various functional plugins such as kinematics, collision detection, and motion planning so that it can provide the desired motion planning for various robots. Moreover, MoveIt is a package of ROS, and it is highly integrated with ROS so that the results of motion planning by MoveIt can be easily transmitted to the robot manipulator through ROS. Users can use the 3D visualization tool RViz to visually present the motion planning results in the ROS. For MoveIt, the unified robot description format (URDF) and semantic robot description format (SRDF) are used to describe robots. The proposed RRT algorithm is designed for the robot manipulator UR5 in this paper, but it can be used for the other six DOF robot manipulators. MoveIt imports the URDF file to set the parameters of the robot and the simulated environment, then sends a request to the default library, the open motion planning library (OMPL), to design a suitable motion trajectory. After calculating a path, MoveIt will divide this path into the same distances and add information such as speed, acceleration, and the consumed time of the robot at each piece of the path. In addition, OMPL is the main library of sampling-based planning algorithms, which includes many modules of common RRT algorithms. Because of its modular program design, it is easy for users to add custom motion planning algorithms. Therefore, MoveIt is adopted as the motion planning software for the robot manipulator in this paper.
As shown in
Figure 1, the image information is sent by the object detection module, and the motion information is calculated by MoveIt through ROS. Since ROS can transmit or receive different data through messages and services, the proposed system integrated through ROS can be applied to various input and output devices, so it has good applicability. In the communication mode between the object detection module, task strategy module, MoveIt, and UR5, there are mainly three two-way communication services in the implemented pick-and-place system, which are, respectively, named Service1, Service2, and Service3.
In order to ensure that the task strategy module can indeed receive the object position information from the object detection module, Service1 is used to make the control command of the task strategy module for the robot manipulator to move only after it has received the object position information. The nodes of the server and client of Service1 are the task strategy module and the object detection module, respectively. The request sent by the task strategy module to the server has a status value of 0 (false) or 1 (true) while the control command is received. The response is given by the object detection module as the client after it receives the request for the object coordinates (x, y) on the table. The nodes of the server and client of Service2 are the task strategy module and MoveIt, respectively. The request sent by the task strategy module as the server is the target position (x, y, z) of the end effector and the quaternion of the robot manipulator pose (w, x, y, z). The response given by MoveIt as the client after receiving the request is the result of forward and inverse kinematics and the motion trajectory obtained by RRT. The nodes of the server and client of Service3 are MoveIt and UR5, respectively. The request sent by MoveIt as the server is the joint motion trajectory of the robot manipulator. The response given by UR5 as the client after receiving the request is a status value of 0 (false) or 1 (true), depending on whether UR5 is busy or not.
4. Changing Strategy RRT Algorithm
In the design of the sampling-based path planning method, two items, such as computing time and path length, are usually considered. For offline path planning, the path length is usually the main consideration. On the other hand, for online path planning, computing time is the priority consideration. Real-time object picking and placing tasks require online path planning, so we mainly focus on how to reduce the computing time of the improved RRT algorithm.
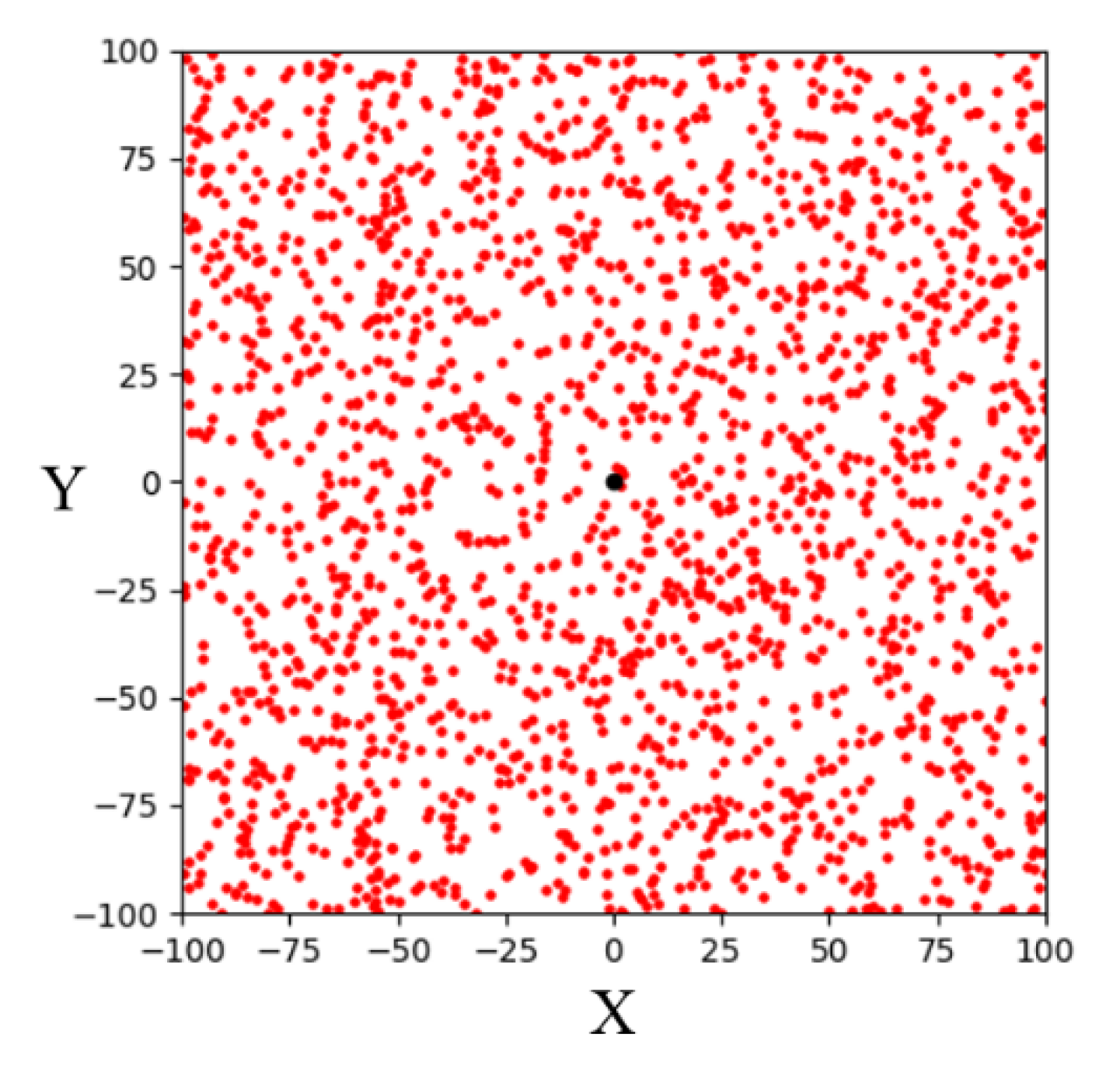
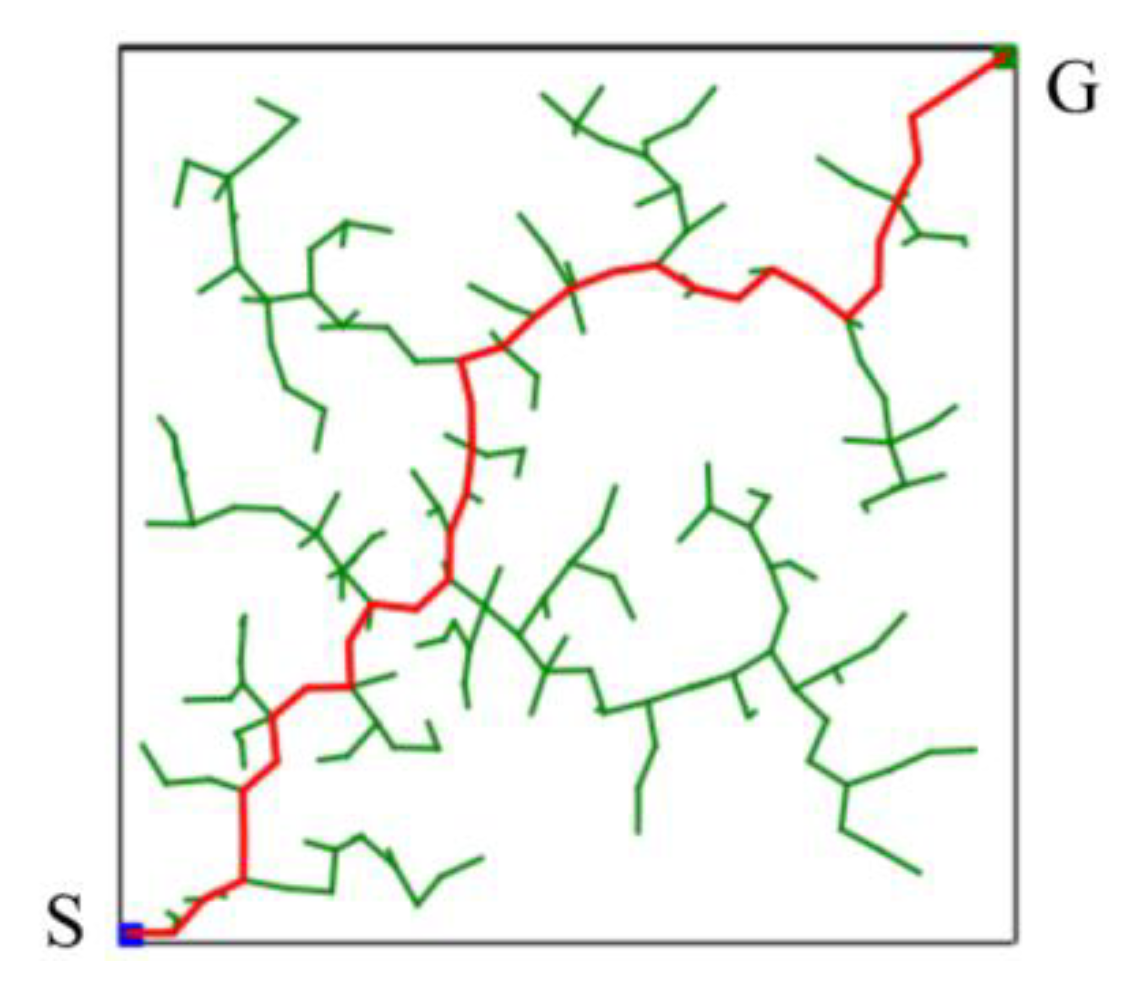
The basic RRT algorithm, as a sampling-based path planning method, is mainly designed to perform random sampling in the configuration space [
15]. A schematic illustration of the basic RRT algorithm for finding a path from a starting point (S) to a goal point (G) in a two-dimensional space is shown in
Figure 5. It can be seen that the random tree fully explores the environment. The advantage of this method is that it does not require modeling the entire environment. Such path planning algorithms can explore two-dimensional spaces faster than other path planning algorithms. Therefore, it is suitable for solving the path planning problem in complex or constrained environments.
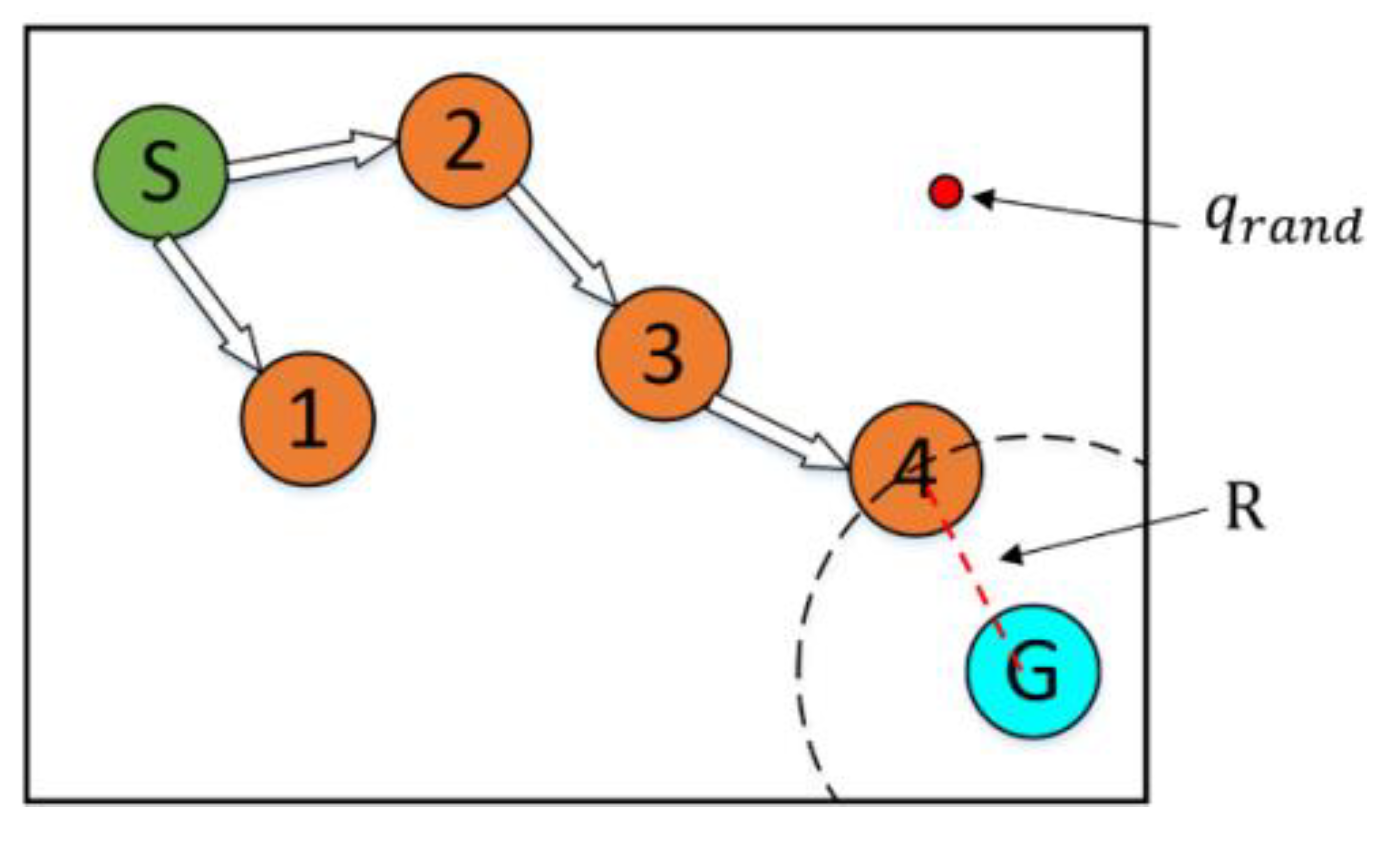
The proposed algorithm is named changing strategy RRT (CS-RRT), which is improved on the basis of the method of gradually changing the sampling area based on RRT (CSA-RRT) [
9]. The pseudocode of the CSA-RRT algorithm is shown in Algorithm 1. It needs to calculate the distance
between the two nodes
and
, where
is the node farthest from the goal point
. Since the tree only has the initial node
at the beginning, the algorithm will initially use
as
to calculate
, which is the initial sampling radius
of bounded sampling. When the dimension of the space is
, the maximum distance
is calculated by:
The CSA-RRT algorithm uses the random sampling method to randomly select a sampling point
in the space. The distance
between
and
is calculated by:
Compare the distance between
and
to make sure that the sampling point
is inside
. If
is less than
, then
is considered a valid sampling point. Conversely, if
is greater than
, it means that
is outside
, and the algorithm will resample until
is inside
. If a new node
is successfully added to the random tree in an iteration, it means that there is no obstacle between
and the nearest node
. When the new point
is closer to the goal point
, it becomes the nearest node. At this time, the value of
is changed to the distance from the new nearest node
to the goal point
. Conversely, it means that an obstacle is encountered during the expansion process. At this time, a step size ε of
times is added to
, which means that the sampling area is expanded so that the random tree can avoid nearby obstacles. The value of
is a positive integer for adjusting the sampling radius, which needs to be manually adjusted according to the complexity of the environment. This allows the algorithm to explore the direction of
as much as possible while having the ability to randomly explore the environment. The comparison results of the CSA-RRT algorithm and the 10% goal-biased RRT algorithm are shown in
Figure 6. It can be seen that the CSA-RRT algorithm can reduce the generation of invalid nodes more than the goal-biased RRT algorithm.
| Algorithm 1: CSA-RRT algorithm
|
← InitTree();
← ;
for = 1 to do
← RandomSample();
if Distance(,) > then
continue;
end if
← NearestNeighbor(, );
← Extend(,, ε);
if CollisionFree(,) then
AddNewNode(,);
← Distance(,);
else
← + ε;
continue;
end if
if Distance(,) < then
return ;
end if end for return Failed;
|
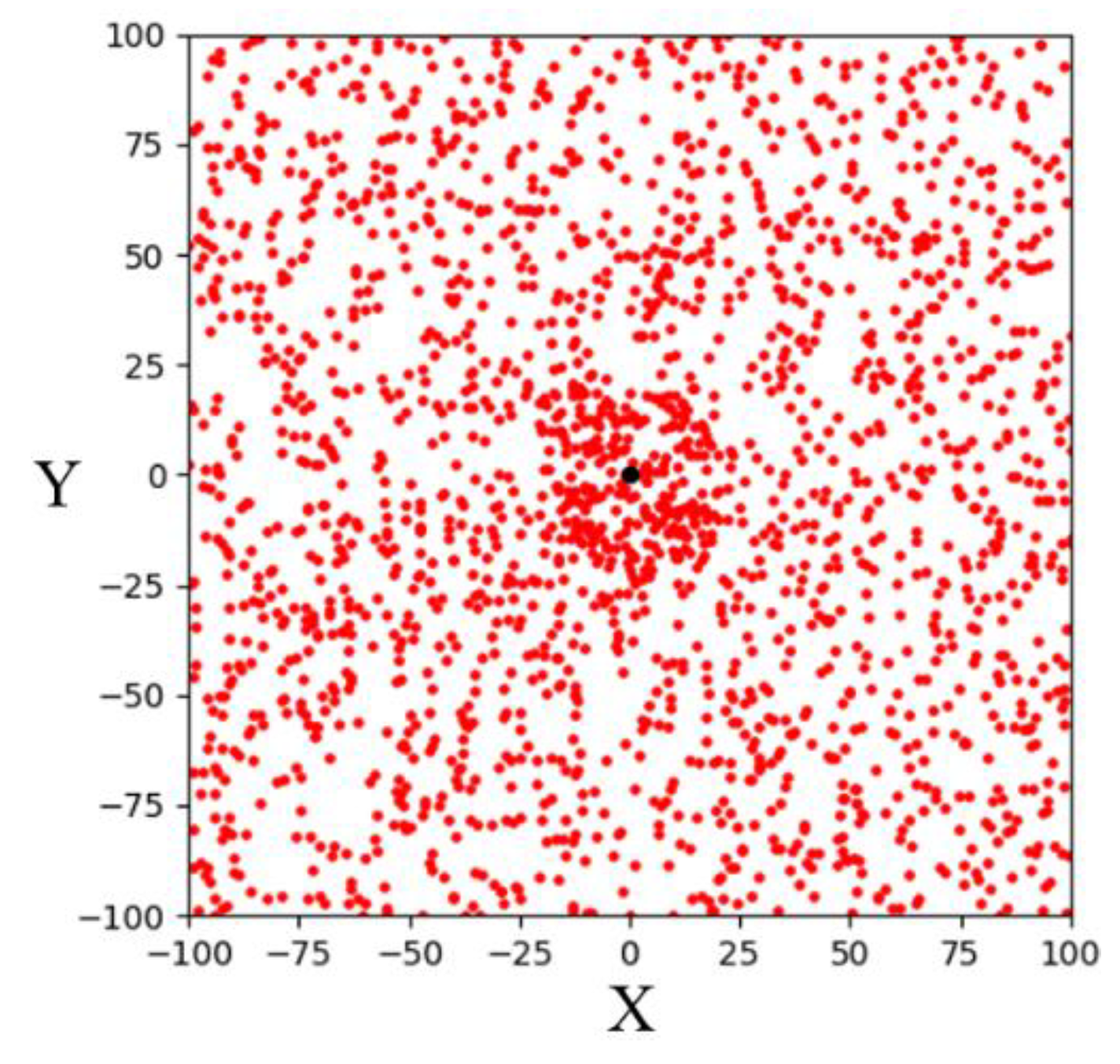
The CSA-RRT algorithm has the advantage that the invalid nodes of the CSA-RRT algorithm are much lower than those of the goal-biased RRT algorithm. However, the computing time of the CSA-RRT algorithm is not much faster than that of the goal-biased RRT algorithm. After observation, we found that although the sampling radius
will gradually shrink as
gets closer to the goal area, thereby reducing the generation of invalid points. However, on the other hand, because of the reduction in
,
selected by random sampling becomes more and more difficult to fall within
. As shown in
Figure 7, when the new point
is close to the goal point
,
will become smaller and smaller. This results in a very small chance that the sampling point
will fall within
. As a result, the CSA-RRT algorithm spends a lot of time doing computation at certain stages. Therefore, the CSA-RRT algorithm has the advantage of generating fewer invalid nodes, but it still cannot significantly reduce the computing time of path planning. This becomes more apparent when sampling in larger environments.
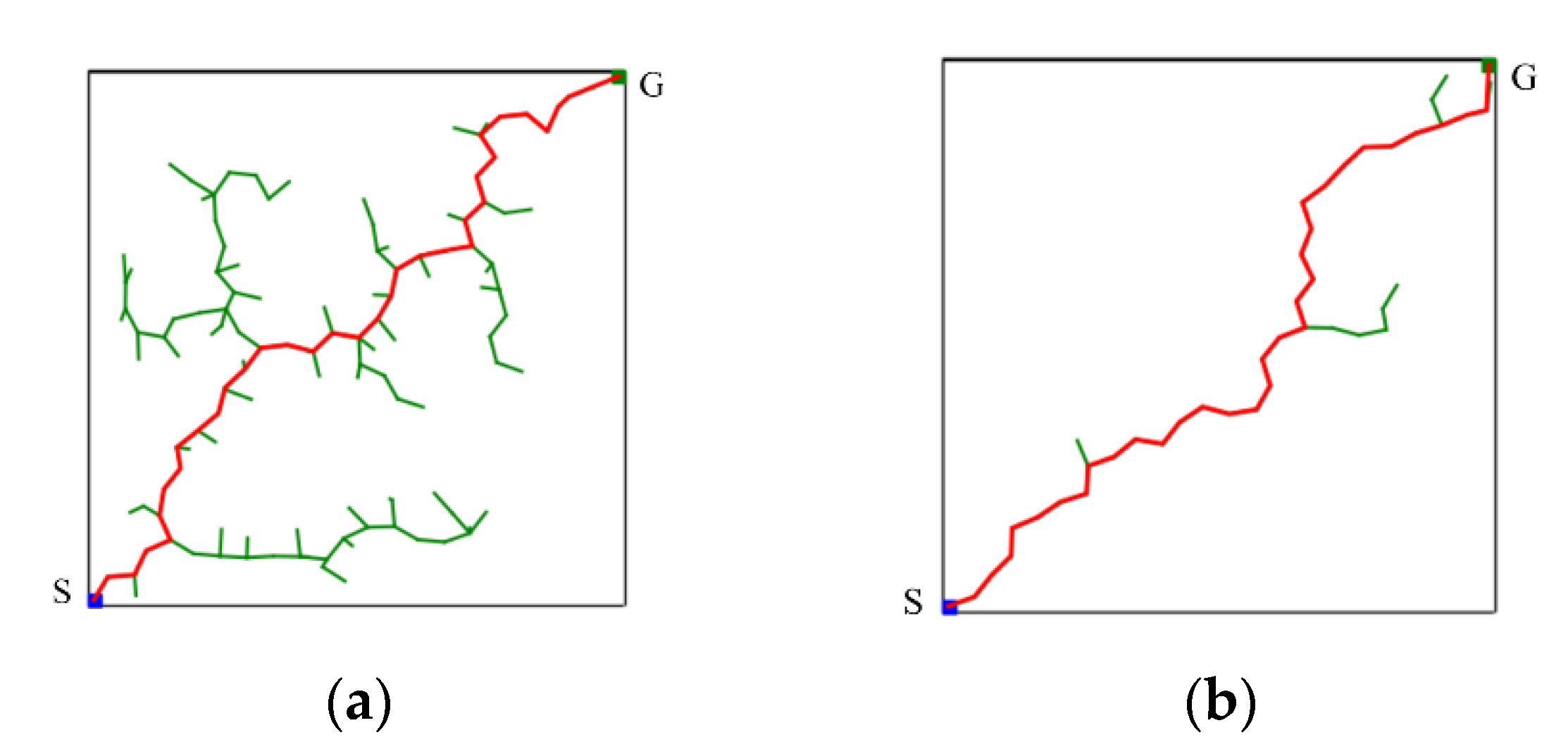
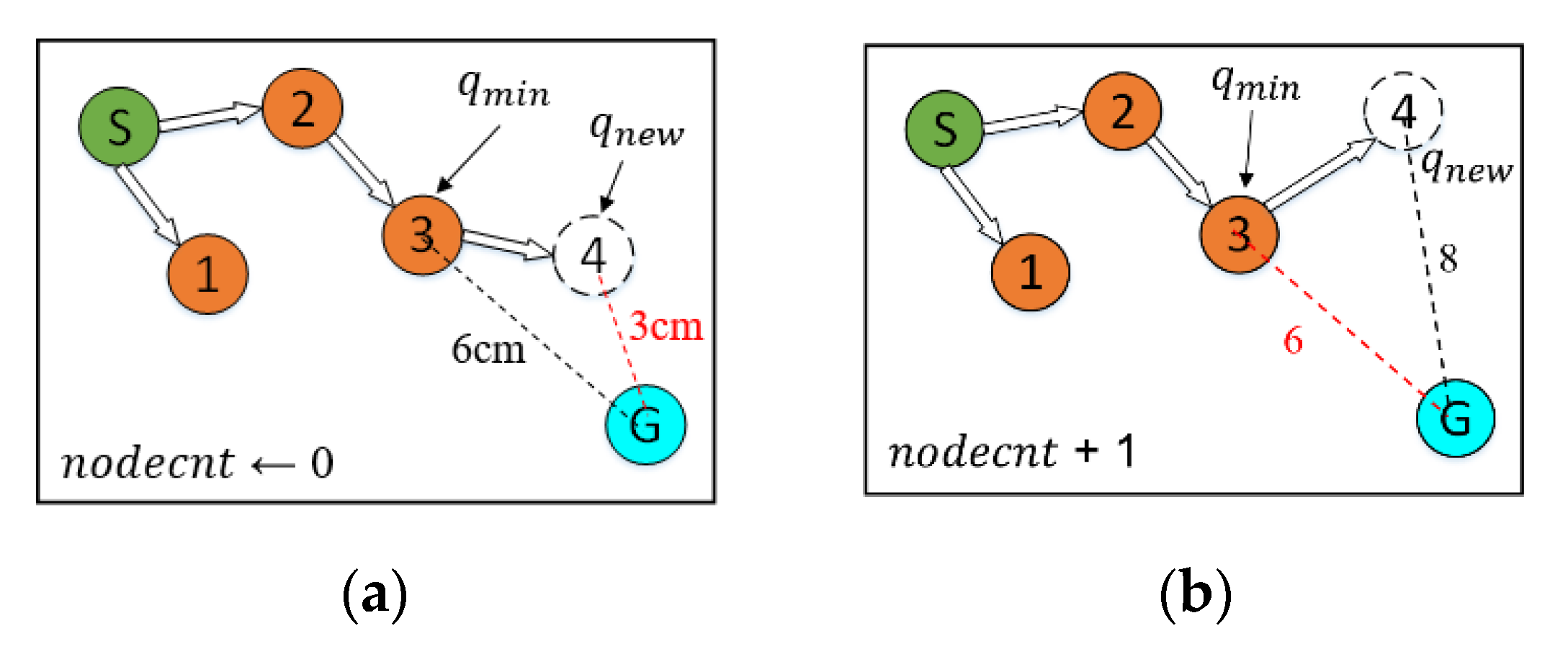
A sampling-radius limitation mechanism is adopted to solve this problem that is difficult to fall into when is close to . An additional statement is used to determine whether the random tree is approaching . Whenever is added to the random tree, R and are compared before the next sampling. If is greater than one-fifth of , it means that the random tree is still far away from . Thus, it continues to use the random sampling of the CSA-RRT algorithm to select . On the other hand, if R is smaller than one-fifth of , it means that the random tree is close to . At this time, a sampling-radius limitation mechanism based on bounded sampling is adopted to limit the sampling area within the radius from the goal point. In this way, the problem that cannot successfully fall within when it is close to the goal point can be solved. This makes the proposed CS-RRT algorithm not only quickly find valid nodes but also reduce the computing time of path planning. In the case of two-dimensional simulations, the CS-RRT algorithm improves by about 0.5 times compared with the CSA-RRT algorithm.
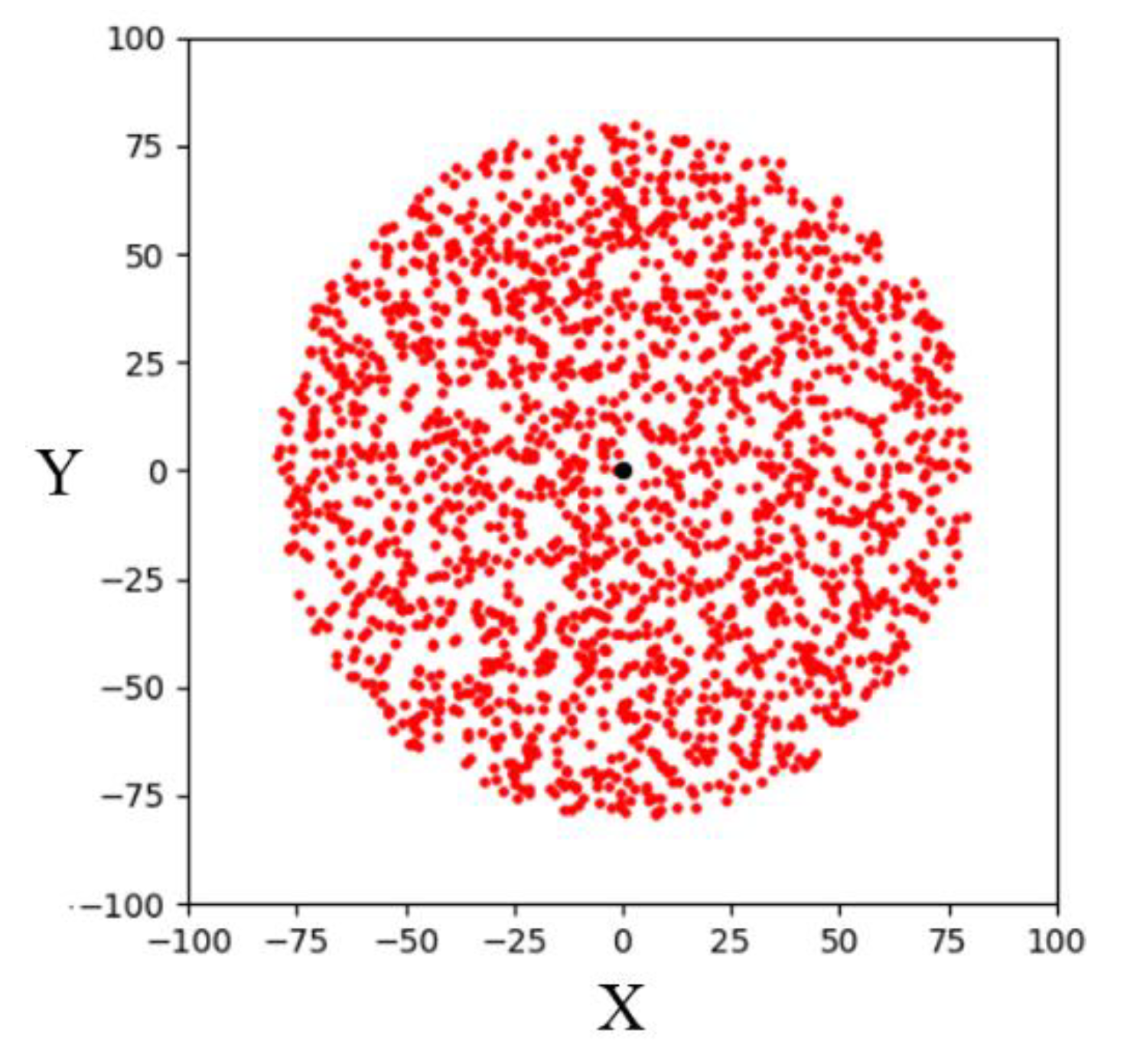
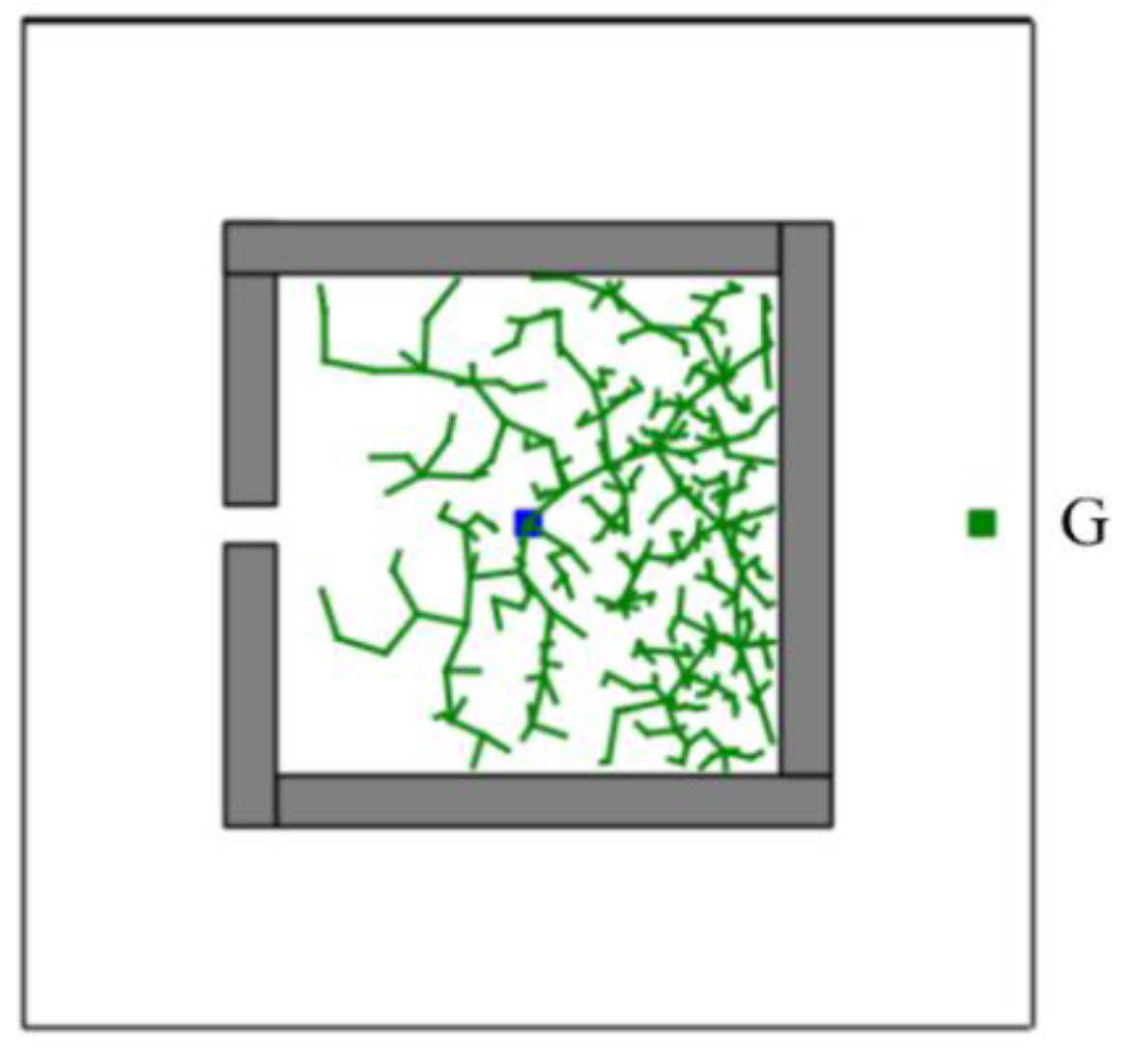
In addition, the CSA-RRT algorithm has the advantage that it can quickly find an initial path to the goal area. However, as shown in
Figure 8, if the CSA-RRT algorithm is performed in a complex environment and the value of
is not adjusted properly, the tree may be trapped due to focusing too much on the goal point. As a result, the random tree keeps expanding in the same area but cannot find an escape path until the number of node expansions of the algorithm reaches the maximum limit of expansions and fails. In order to solve this problem, a node counting mechanism is adopted to appropriately switch the sampling strategy to an appropriate sampling method in complex environments. It can avoid the search path being trapped in some constrained areas and improve the adaptability of the proposed CS-RRT algorithm to various environments.
The CSA-RRT algorithm with the node counting mechanism will calculate the distance from the node that is closest to the goal point and set the node count variable to zero during initialization. As shown in Algorithm 2, in the sampling stage, the algorithm will choose which sampling method to use according to the value of . If is less than the set threshold, the sampling method of CSA-RRT is used to make the random tree quickly extend to the goal point. Otherwise, the random sampling method, which fully explores the environment, is used.
| Algorithm 2: SelectSample(
,,
);
|
if < 20 then
← RandomSample();
if Distance(,) > then
continue;
end if else
← RandomSample();
end if return ;
|
After completing the collision detection stage in each iteration, the algorithm calculates the Euclidean distance
from
to
, no matter if
is successfully added to the random tree. After this, compare
with
in the CheckEnvironment() function. The pseudocode of the CheckEnvironment() function is shown in Algorithm 3. If
is smaller than
, then
is set to zero. At this time,
is closer to
, which means that the tree is approaching the goal area, so there is no need to change the sampling strategy. After that, change
into
as the basis for the next check of the expansion status. On the other hand, if
is greater than
, it means that
is not closer to
. At this time,
+1. If
continues to be greater than
for the next few times, it is considered that the random tree is trapped in the current area. Then the algorithm will switch the sampling method to random sampling in the SelectSample() function to try to escape the current area until
is smaller than
. In addition, an upper limit is set to avoid the algorithm wasting too much time using random sampling to explore the space. Therefore, when
reaches the set upper limit, it will reset to zero immediately. A schematic illustration of node count adjustment is shown in
Figure 9.
| Algorithm 3: CheckEnvironment(
, ,
)
|
if < then
← ;
← 0;
else
← + 1;
end if if > 100 then
← 0
end if
|
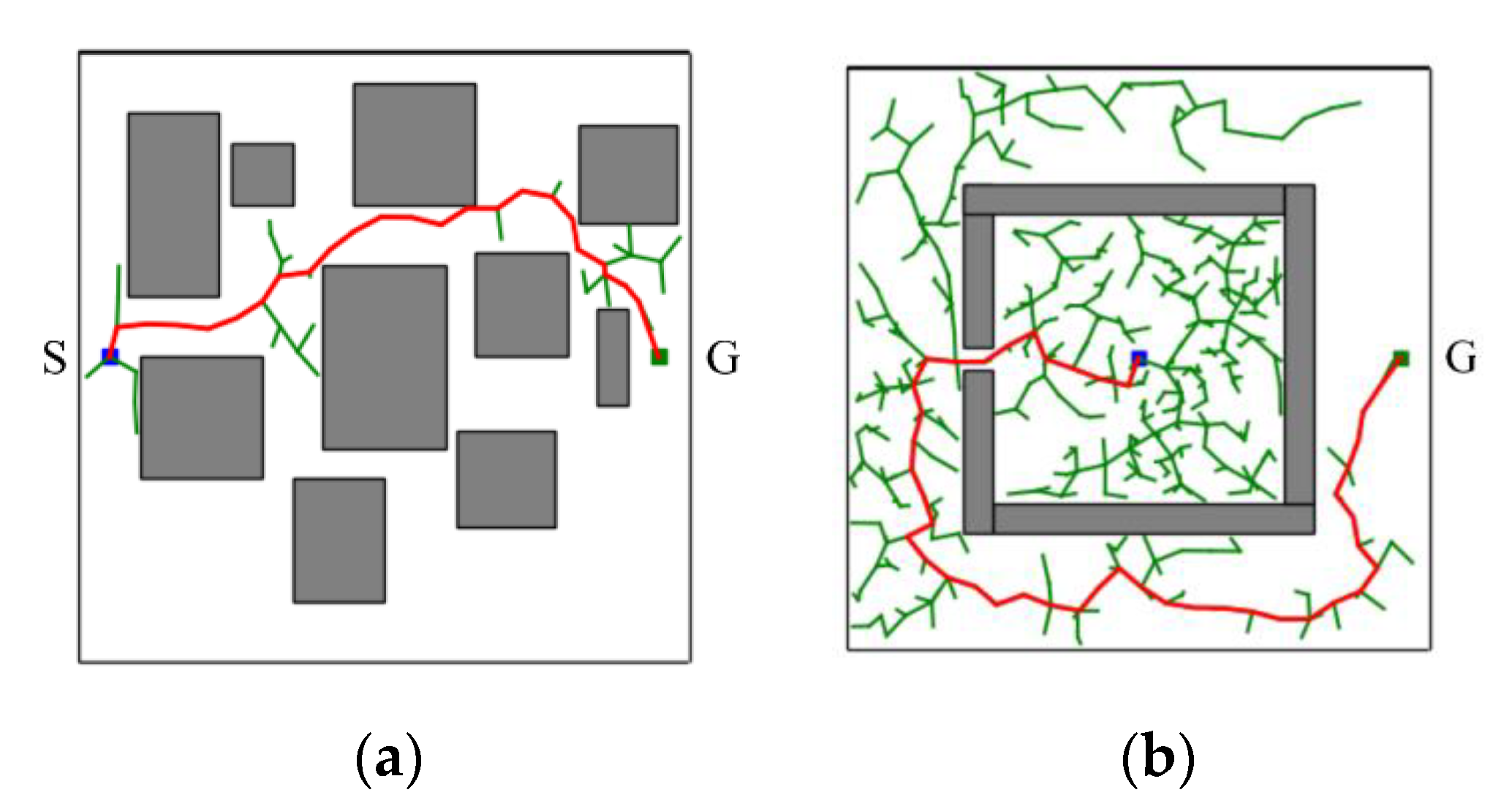
In short, the proposed CS-RRT algorithm is based on the CSA-RRT algorithm and uses the sampling-radius limitation mechanism and the node counting mechanism to solve the problems existing in the CSA-RRT algorithm. The sampling-radius limitation mechanism allows the random tree to finish the sampling stage more quickly when it is close to the goal area, so that the proposed CS-RRT algorithm can further reduce the computing time. The node counting mechanism makes the algorithm avoid overfocusing on the goal area, so the proposed CS-RRT algorithm also has good adaptability to the environment. The results of the proposed CS-RRT algorithm performed in two different environments are shown in
Figure 10. When encountering simple environments, as shown in
Figure 10a, the proposed CS-RRT algorithm can quickly find a path. When encountering complex environments, as shown in
Figure 10b, the proposed CS-RRT algorithm can also prevent trapping by switching sampling strategies. Comparing the results shown in
Figure 8, we can see that the CSA-RRT algorithm is trapped in this environment. With these improvements, the proposed CS-RRT algorithm indeed not only reduces computing time but also improves environmental adaptability.
6. Conclusions and Future Work
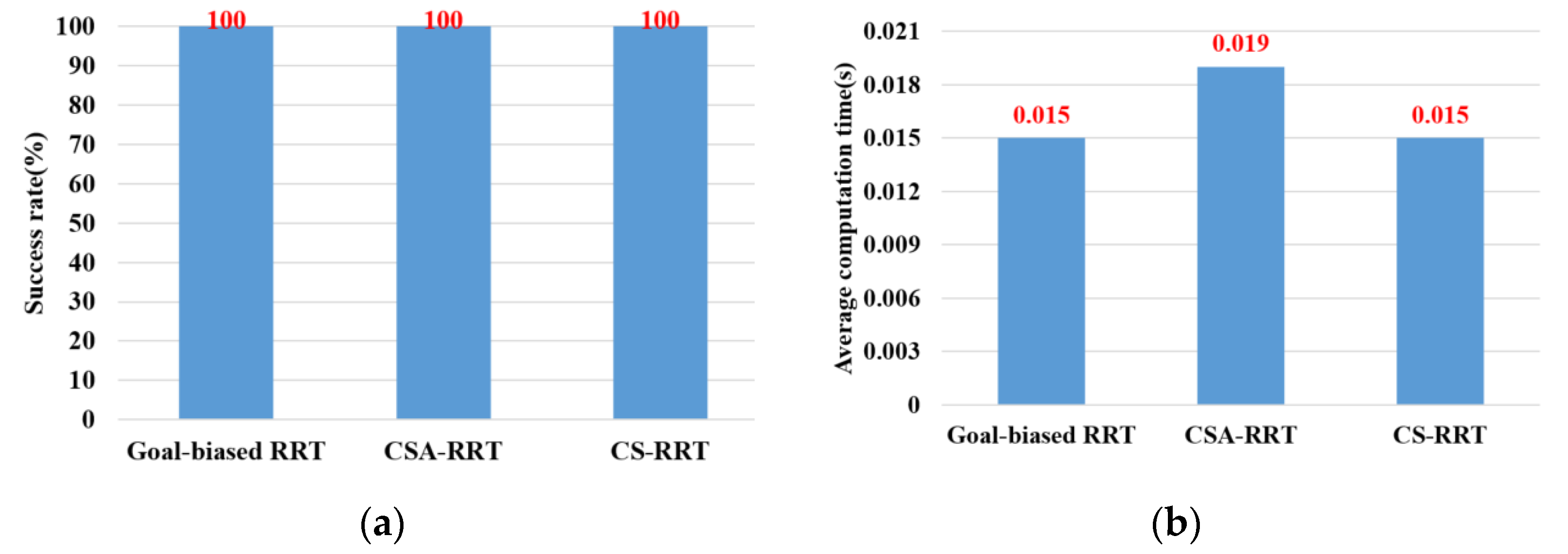
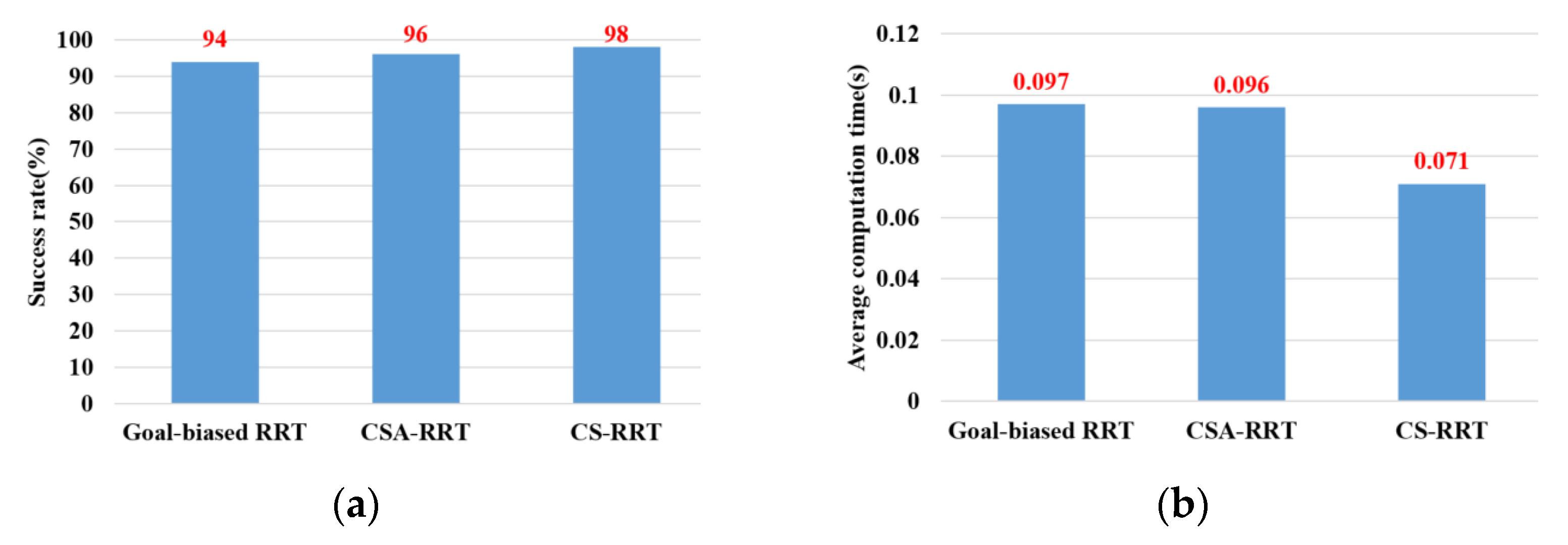
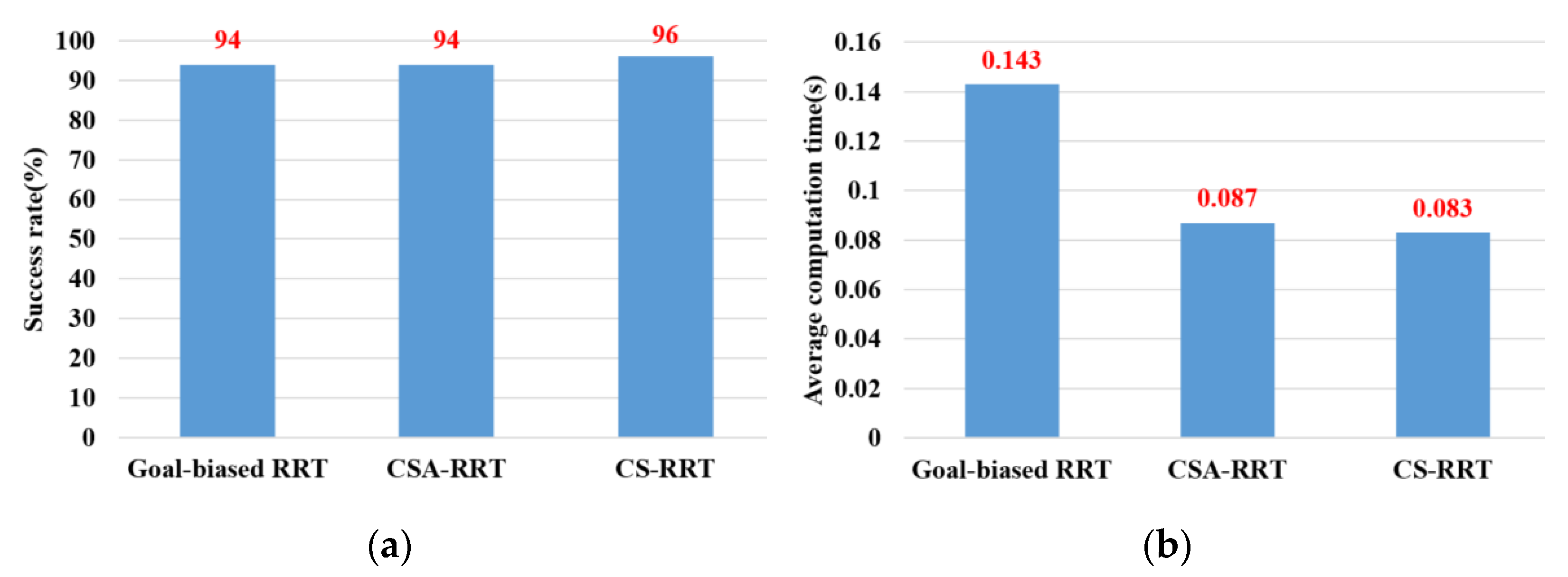
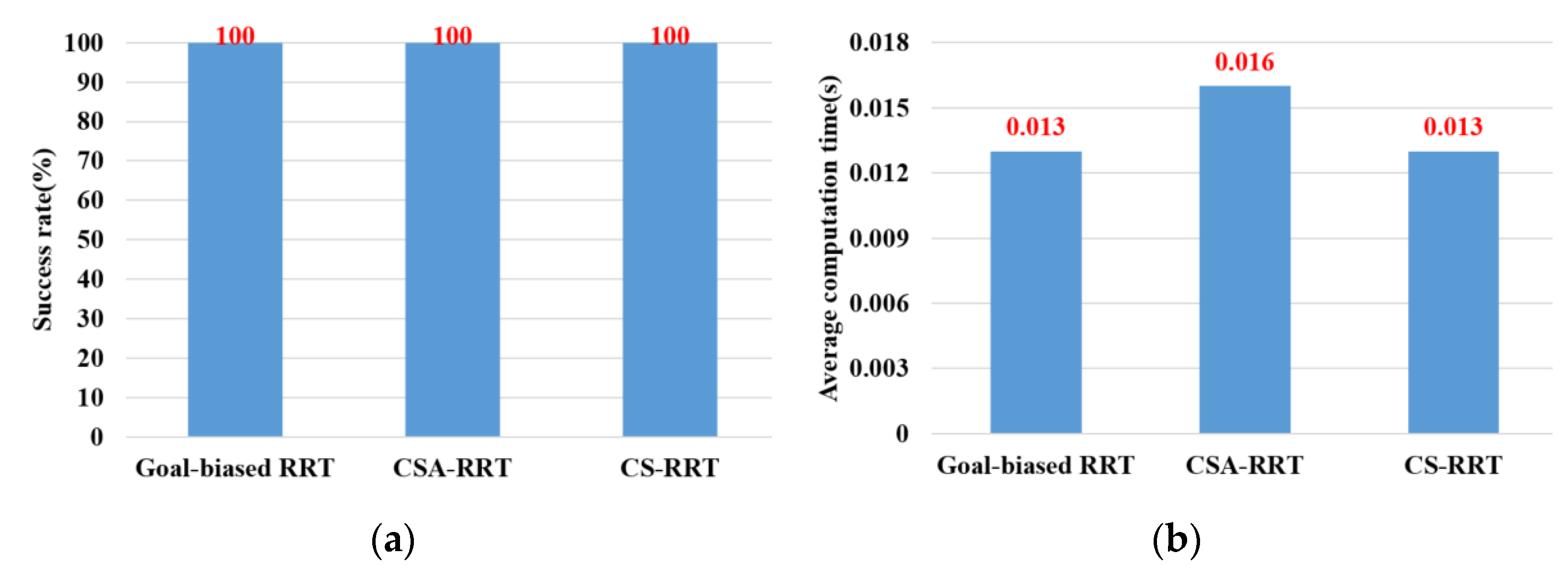
An ROS-based object pick-and-place system is implemented, and a CS-RRT algorithm is proposed so that the robot manipulator can efficiently pick-and-place objects in real time. There are three main contributions in this paper. (1) Path planning for robots is one of the most important topics in robotics research. In the research on robot manipulators for picking and placing objects in a constrained environment, most of the research only completed simulation results to verify the effectiveness of their path planning methods. Many improved RRT algorithms have been proposed, but they are rarely applied to actual robot manipulators for object pick-and-place tasks in real time. Both simulation and actual experiments are used to demonstrate that the proposed CS-RRT algorithm and the implemented system can allow the robot manipulator to effectively avoid obstacles and pick-and-place objects in real time. (2) Some disadvantages of existing RRT algorithms are addressed, and two mechanisms of sampling radius counting, and node counting are adopted in the proposed CS-RRT algorithm. The sampling-radius limitation mechanism, by limiting the sampling radius, can make the random tree finish the sampling stage faster when the tree is close to the goal point. It can reduce the computing time of the proposed CS-RRT algorithm. The node counting mechanism allows the algorithm to switch to an appropriate sampling method in a complex environment. It can avoid excessive exploration in the direction of the goal point so that the random tree does not trap itself in constrained areas. It can make the proposed CS-RRT algorithm have better environmental adaptability. In addition, an experimental environment with four object picking and placement tasks has been established. Experimental results show that the object pick-and-place system based on the proposed CS-RRT algorithm has a higher success rate and lower computing time compared with the other two path planning algorithms. (3) The robot operating system (ROS) is used to implement the object pick-and-place system. By implementing the proposed CS-RRT algorithm in the open motion planning library (OMPL), MoveIt can be used to plan the motion of the robot manipulator. According to the imported URDF file, MoveIt can also perform motion planning for different robot manipulators, so the proposed method can be easily applied to different robot manipulators.
There are two parts to the future work: (1) In the part of switching strategy and step size adjustment, switching sampling strategy can improve the adaptability of the proposed algorithm to the environment, but its own parameters need to be manually designed according to the environment. In addition, the step size also needs to be chosen according to the environment. Therefore, some optimization methods can be used in the future to select appropriate parameters for the switching strategy and step size according to the environment. (2) In the part of the sampling method where the distance needs to be calculated. In the path planning of the six-dimensional joint space of the robot manipulator, more parameters are needed to calculate the distance, which increases the computing time of the proposed algorithm. Therefore, the number of calculation distances can be reduced in the future to reduce the computing time needed to meet the system requirements.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}