


Implementation of a Bio-Inspired Neural Architecture for Autonomous Vehicles on a Multi-FPGA Platform †
 , ,
, ,
Abstract
:1. Introduction
- A design to port the LPMP model to the hardware using FPGAs.
- N-LOC, a hardware implementation of the LPMP bio-inspired model for navigation, including a set of benchmarks to compare the performance of N-LOC with the reference software implementation of LPMP.
- In particular and compared to our previous published work, we perform a comparison with the original (optimised) implementation running on a low-power, high-end embedded platform (Nvidia’s Jetson TX2).
- A design for a distributed hardware implementation in order to deal with larger neural networks.
2. Background
2.1. Visual Place Recognition
2.2. Hardware Implementation of a VPR Model
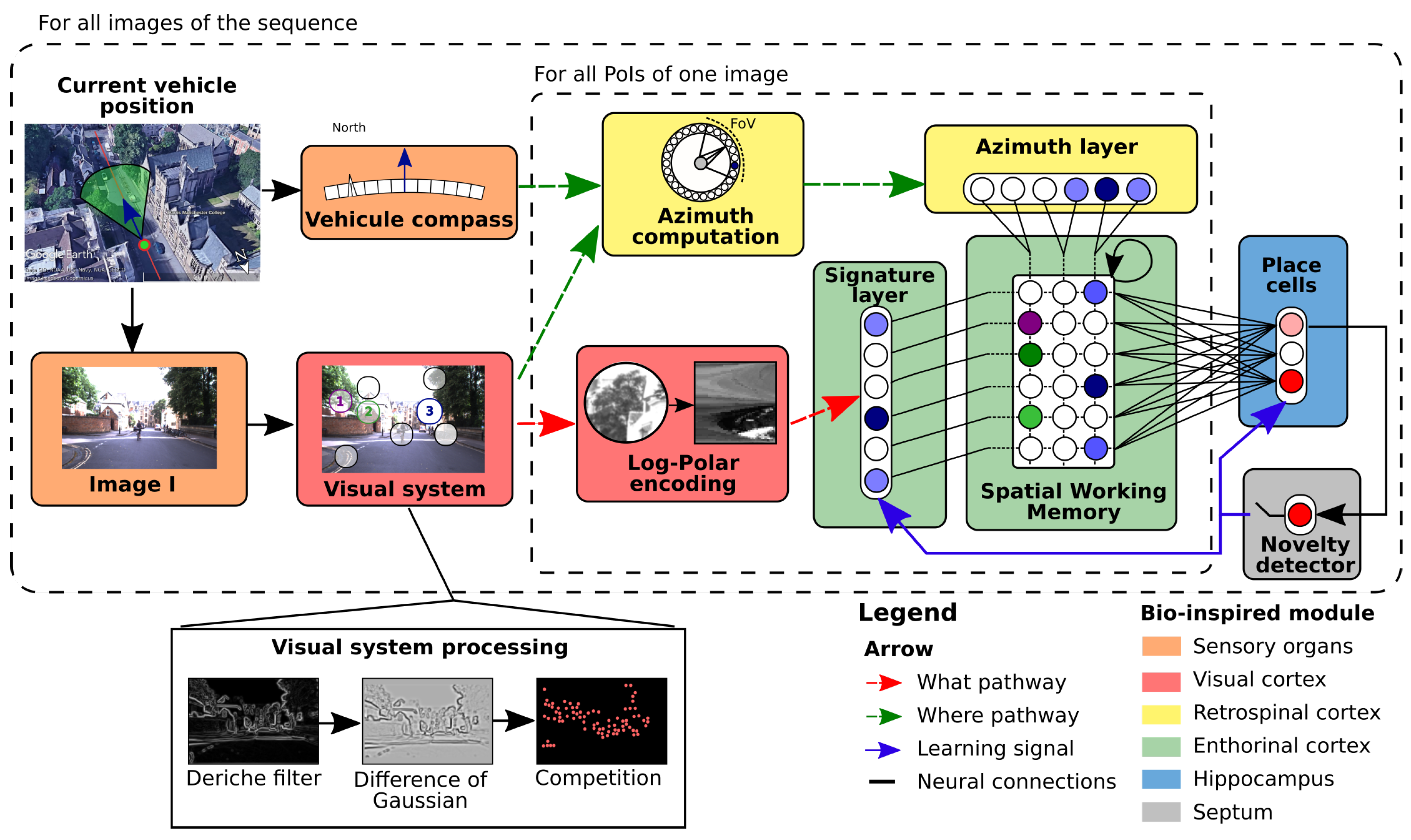
2.3. LPMP, A Bio-Inspired Model of Localisation
- Points of Interest detection
- Saliency points filtering
- Points of Interest encoding
- Memory querying
- Some Advantages and Limitations of LPMP
3. Computational Supports for Hardware Acceleration
- Necessity of prototyping complex algorithms that need to be scaled.
- Leveraging Dynamic partial reconfiguration with the aim of reducing energy, power consumption and space locality task placement.
- Facilitating the incorporation of such middle-ware for partitioning: if there is a need to schedule work on multiple devices, how much workload should be executed on each device? For instance, scheduling 25% of the threads on CPU and 75% of the threads on FPGA.
- Leveraging high-speed transceiver protocols as an intrinsic property of FPGAs to communicate over multiple ones.
3.1. Gigabit Transceivers Interface
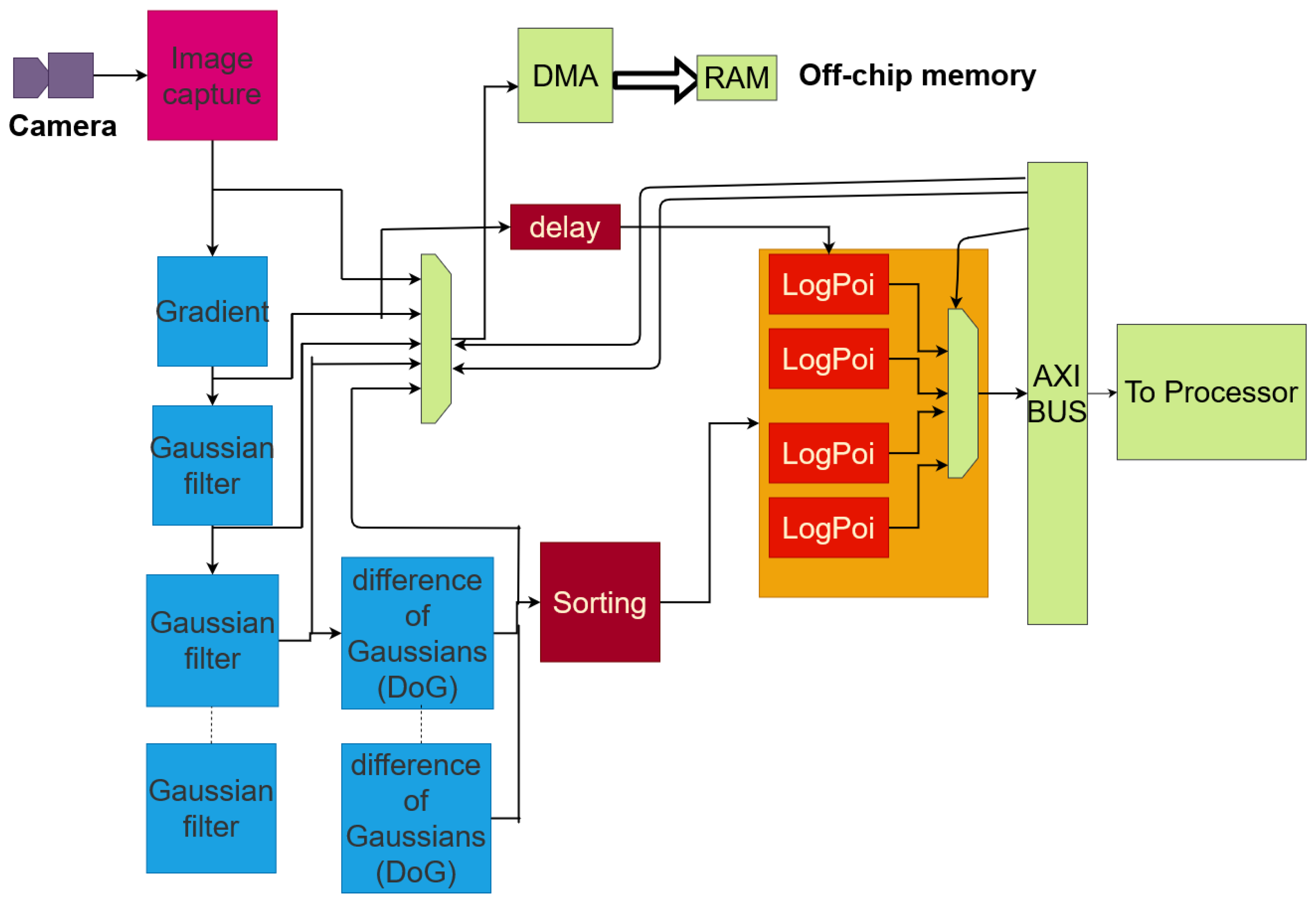
3.2. Difference of Gaussian IP for Feature Extraction
4. Modelling the Bio-Inspired Algorithm for FPGAs
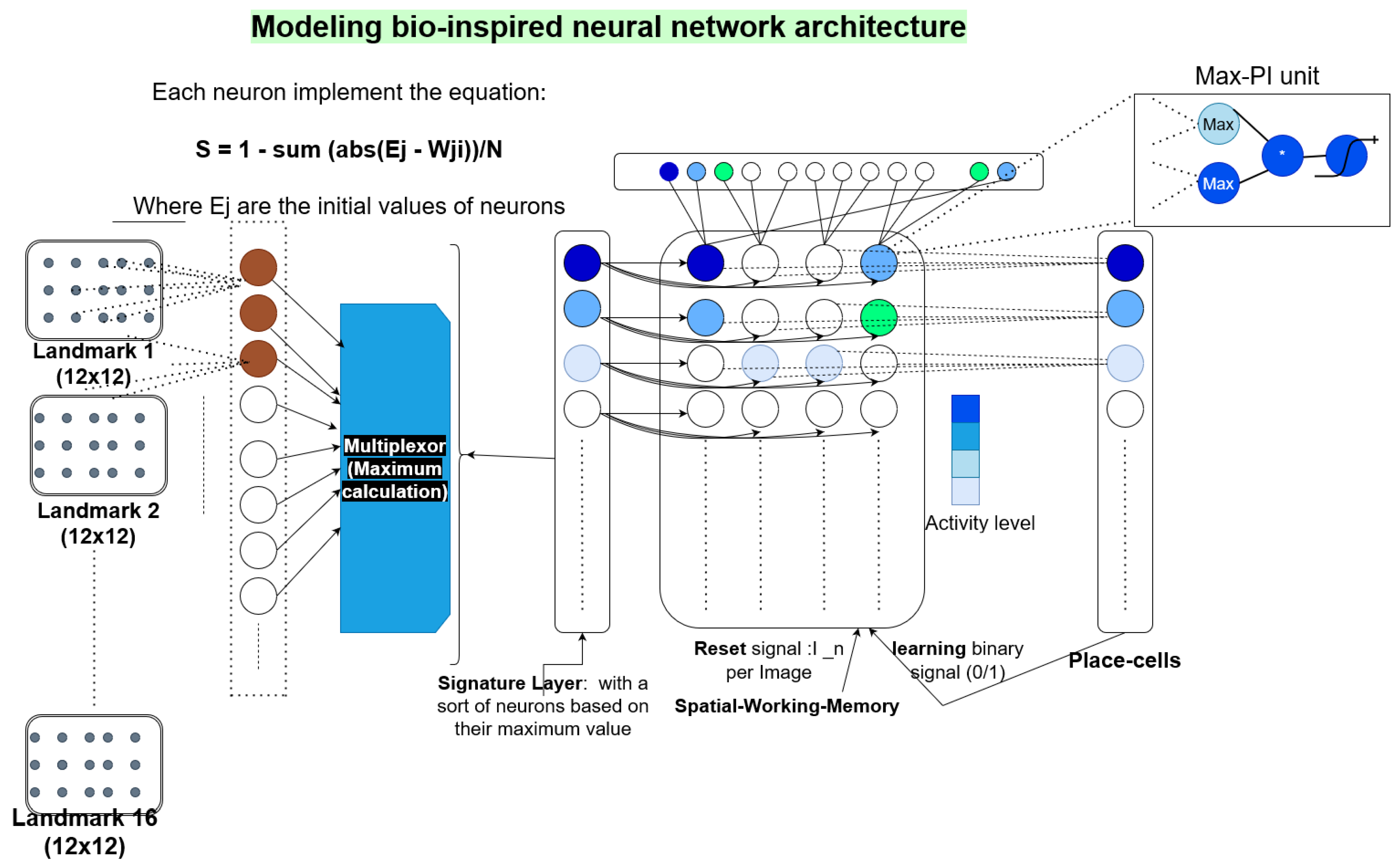
4.1. Visual Signature Computation
4.2. Angular Position Computation
4.3. Spatial Working Memory
4.4. The Place Cell Neuron Group
4.5. Modes of Operation
5. Hardware Implementation on the Wizarde Platform
5.1. Accelerating the Localisation Task: FPGA vs. GPU
5.2. Hardware Implementation on a Multi-FPGA Platform
- Unique, custom platform;
- Intent: help prototype complex applications, possibly requiring multiple SoCs/FPGAs;
- 2D tile mesh.
- A differences of Gaussian (DoG) or processed intermediate image, selectable thanks to a dedicated register.
- The list of pixel data extracted and sorted by the IP at the different frequency bands and the list of Log-Polar features associated with each keypoint, i.e., a set of computed pixels. They are gathered into landmarks. Each landmark contains pixels.

5.3. Fixed-Point Arithmetic
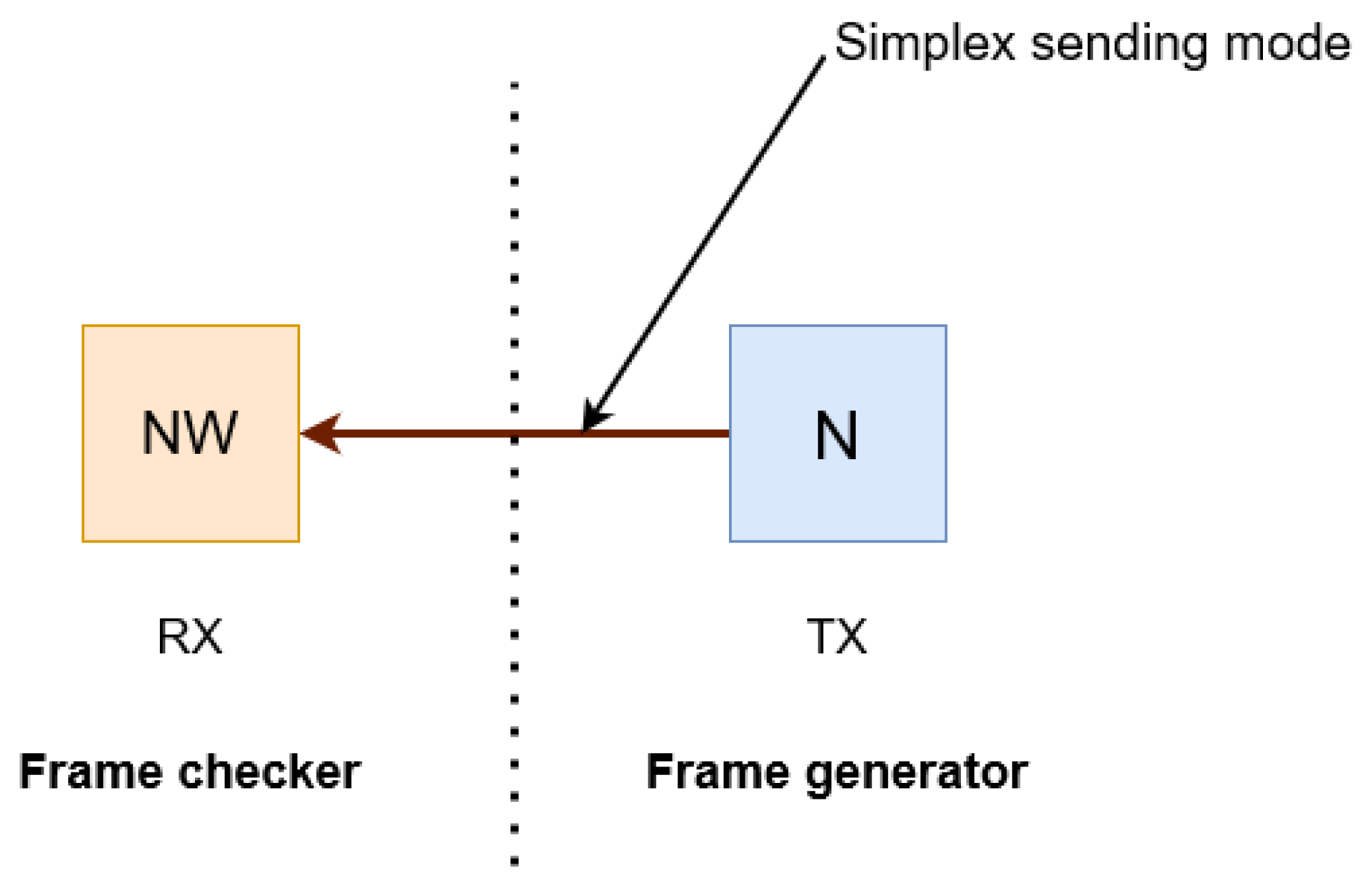
5.4. Towards Using GTX Transceivers for a Data-Transmission over Wizarde Platform
- Error_count: it should be NULL based on chosen frequency.
- Dynamic reconfiguration port (DRP) clock.
- Rx_reset_done: should be set to 1 when data are correctly received.
5.5. Experimental Results
5.5.1. Experimental Setup and Implementation Parameters
- On the target Zynq-7045 chip, the signature layer (SL) can fit at most 1600 neurons; the SWM 4800 neurons; the place cells vector 100 neurons, with 16 landmarks per image.
- The azimuth layer (which represents the angle orientation of each captured image) contains 180 neurons.
- The values of azimuth neurons are fixed for this experimentation; varying azimuths will be added in the future.
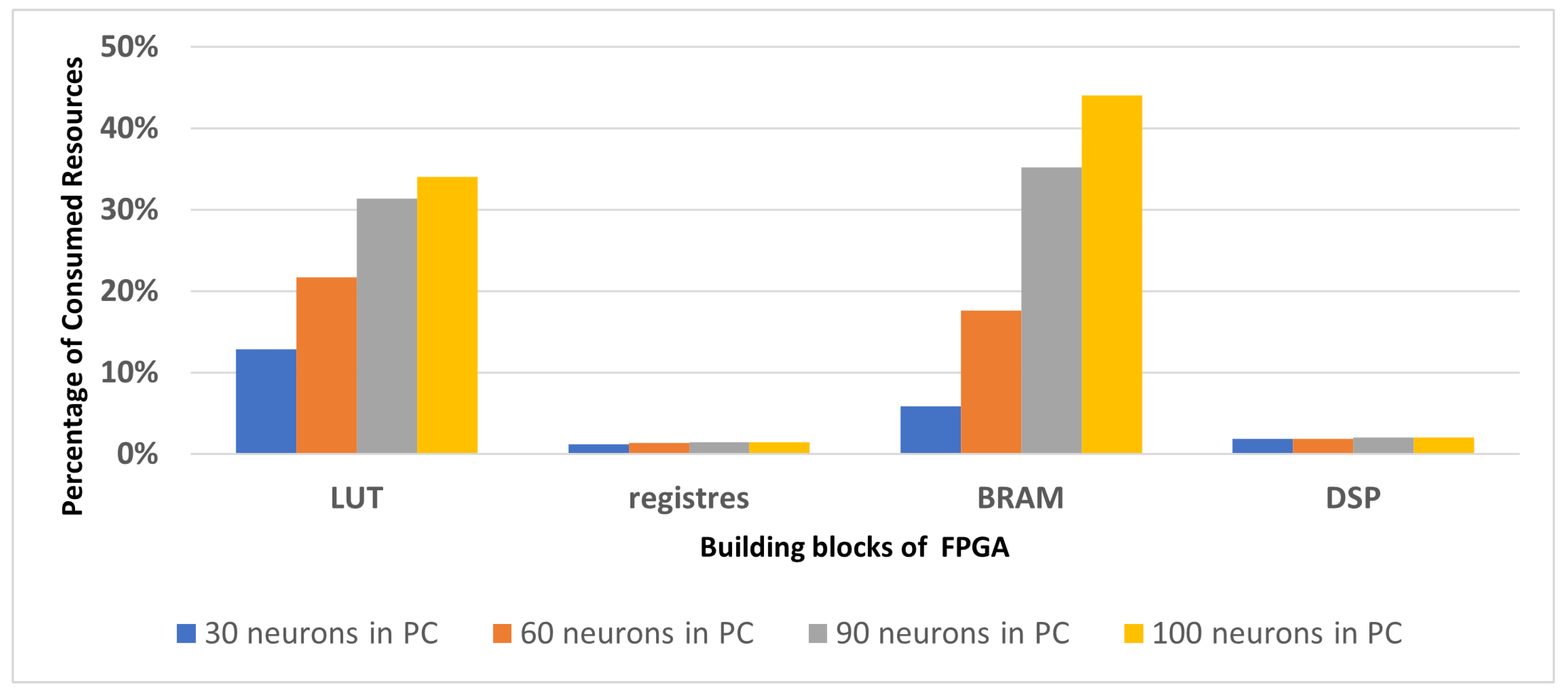
- We parameterised N-LOC with three configurations: 30, 60 and 90 place cell neurons. They represent the number of images that need to be learned in the localisation process.
- We used 100 images to “feed” N-LOC.
5.5.2. Resource Consumption and Performance Gains
6. A Distributed N-LOC Architecture
6.1. Distributed N-LOC: Principles
6.1.1. Distributed Learning and Using Phases
- Learning phase
- N-LOC IPs are duplicated and distributed on different tiles.
- The pixel stream is connected to the appropriate N-LOC block if its neurons’ weights are not saturated.
- If an N-LOC block is saturated during the learning phase (i.e., the maximum number of neurons to initialize has been reached), we switch to the next available N-LOC block, to carry on the ongoing or further learning of different captured images.
- The master controller is in charge of communicating with all N-LOCs, using a bidirectional communication protocol.
- Using phase
- The pixel stream is connected through all N-LOC blocks simultaneously.
- All N-LOC blocks simultaneously perform different computations based on different pre-learned information.
- A threshold-based comparison is set by the master controller, to select the highest activated neurons among the N-LOC blocks.
6.1.2. Experiments with Distributed N-LOC on a Single FPGA
- Experimental setup
- Experimental results
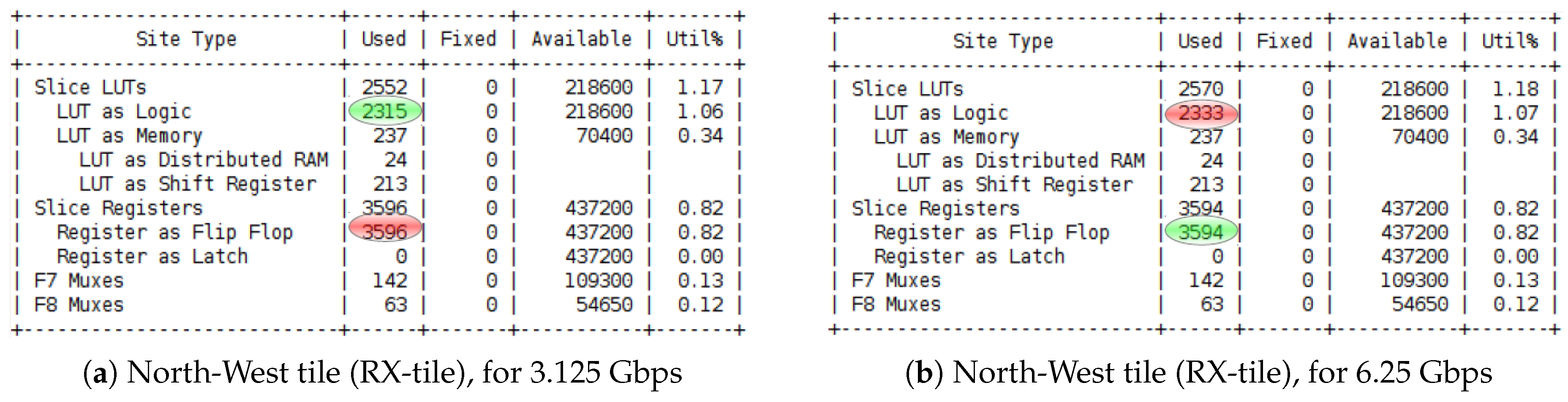
6.2. Communication Protocol via GTX Transceivers
6.2.1. Highspeed Transceivers on the Wizarde Platform
6.2.2. GTX Micro-Benchmarking in Wizarde
6.3. Toward a Distributed N-LOC Architecture on Wizarde
6.3.1. Changes to the Original Architecture
- The compass value (image orientation, i.e., azimuth values) is sent once for each image to process. Azimuth values are computed locally in each N-LOC block
- For each vignette ( pixels), the x coordinate of the keypoint is sent to the N-LOC block.
- For each pixel, the value of the most active neuron in SL (and its x coordinate, i.e., its “line number”) is sent to the relevant N-LOC block.
- Once all 16 vignettes have been processed, the value of the most active neuron in the PC layer of each N-LOC is sent back to the controller (PS).
- Receive a new compass value every 16 vignettes. The word size for the azimuth buffer takes 8 bits for each period of cycles of ref_clk cycle.
- Receive a new x coordinate value for each new vignette. The word size of the Azimuth landmark’s x coordinate also takes 8 bits for each 144 period of ref_clk cycle (144 × ref_clk period).
- Receive a new signature layer value every time a pixel is sent. The word size of signature layer pixels (block’s input) takes 8 bits for each ref_clk cycle.
- Send its most active place cell value every time a full image has been processed. The word size of the place cell (block’s output) takes 8 bits for each () ref_clk cycle. is a constant which varies with each target system.
6.3.2. Extending N-LOC’s Neural Network on Demand: Leveraging Dynamic Partial Reconfiguration
7. Related Work
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| FPGA | Field Programmable Gate Arrays |
| CPU | Central Processing Unit |
| GPU | Graphical Processing Unit |
| SoC | System-on-Chip |
| GTX | Gigabit Transceiver |
| N-LOC | Bio-inspired neural architecture Hardware implementation |
| LPMP | Bio-inspired neural architecture Software reference |
| VPR | Visual Place Recognition |
| DoG | Difference of Gaussian |
References
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey. 2015. Available online: http://www-nrd.nhtsa.dot.gov/Pubs/812115.pdf (accessed on 15 February 2015).
- Crayton, T.J.; Meier, B.M. Autonomous vehicles: Developing a public health research agenda to frame the future of transportation policy. J. Transp. Health 2017, 6, 245–252. [Google Scholar] [CrossRef]
- Kuffner, J. Systems and Methods for Detection by Autonomous Vehicles. U.S. Patent Application 15/701,695, 4 May 2021. [Google Scholar]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object Classification Using CNN-Based Fusion of Vision and LIDAR in Autonomous Vehicle Environment. IEEE Trans. Indus. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Ghallabi, F.; El-Haj-Shhade, G.; Mittet, M.A.; Nashashibi, F. LIDAR-Based road signs detection For Vehicle Localization in an HD Map. In Proceedings of the IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019. [Google Scholar]
- Espada, Y.; Cuperlier, N.; Bresson, G.; Romain, O. Application of a Bio-inspired Localization Model to Autonomous Vehicles. In Proceedings of the 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 7–14. [Google Scholar]
- Li, Y.; Liu, Z.; Xu, K.; Yu, H.; Ren, F. A GPU-Outperforming FPGA Accelerator Architecture for Binary Convolutional Neural Networks. J. Emerg. Technol. Comput. Syst. 2018, 14, 18:1–18:16. [Google Scholar] [CrossRef]
- Fiack, L.; Cuperlier, N.; Miramond, B. Embedded and real-time architecture for bio-inspired vision-based robot navigation. J. Real-Time Image Process. 2015, 10, 699–722. [Google Scholar] [CrossRef]
- Elouaret, T.; Colomer, S.; Demelo, F.; Cuperlier, N.; Romain, O.; Kessal, L.; Zuckerman, S. Implementation of a bio-inspired neural architecture for autonomous vehicle on a reconfigurable platform. In Proceedings of the 2022 IEEE 31st International Symposium on Industrial Electronics (ISIE), Anchorage, AK, USA, 1–3 June 2022; pp. 661–666. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Eskandarian, A. Handbook of Intelligent Vehicles; Springer: London, UK, 2012. [Google Scholar] [CrossRef]
- Van Brummelen, J.; O’Brien, M.; Gruyer, D.; Najjaran, H. Autonomous vehicle perception: The technology of today and tomorrow. Transp. Res. Part Emerg. Technol. 2018, 89, 384–406. [Google Scholar] [CrossRef]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and Decision-Making for Autonomous Vehicles. Annu. Rev. Control. Robot. Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Rosique, F.; Navarro, P.J.; Fernández, C.; Padilla, A. A Systematic Review of Perception System and Simulators for Autonomous Vehicles Research. Sensors 2019, 19, 648. [Google Scholar] [CrossRef]
- Bimbraw, K. Autonomous Cars: Past, Present and Future—A Review of the Developments in the Last Century, the Present Scenario and the Expected Future of Autonomous Vehicle Technology. In Proceedings of the 12th International Conference on Informatics in Control, Automation and Robotics, Colmar, Alsace, France, 21–23 July 2015; pp. 191–198. [Google Scholar] [CrossRef]
- Bertozzi, M.; Bombini, L.; Broggi, A.; Buzzoni, M.; Cardarelli, E.; Cattani, S.; Cerri, P.; Coati, A.; Debattisti, S.; Falzoni, A.; et al. VIAC: An out of ordinary experiment. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011; pp. 175–180. [Google Scholar] [CrossRef]
- Garg, S.; Fischer, T.; Milford, M. Where Is Your Place, Visual Place Recognition? In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 4416–4425. [Google Scholar] [CrossRef]
- Bresson, G.; Alsayed, Z.; Yu, L.; Glaser, S. Simultaneous Localization and Mapping: A Survey of Current Trends in Autonomous Driving. IEEE Trans. Intell. Veh. 2017, 2, 194–220. [Google Scholar] [CrossRef]
- Chen, Y.; Gan, W.; Zhang, L.; Liu, C.; Wang, X. A Survey on Visual Place Recognition for Mobile Robots Localization. In Proceedings of the 2017 14th Web Information Systems and Applications Conference (WISA), Guangxi, China, 11–12 November 2017; pp. 187–192. [Google Scholar] [CrossRef]
- Park, M.; Luo, J.; Collins, R.T.; Liu, Y. Beyond GPS: Determining the camera viewing direction of a geotagged image. In Proceedings of the International Conference on Multimedia—MM’10, Florence, Italy, 25–29 October 2010; p. 631. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2014, arXiv:1312.6229. [Google Scholar]
- Zaffar, M.; Ehsan, S.; Milford, M.; McDonald-Maier, K. CoHOG: A Light-Weight, Compute-Efficient and Training-Free Visual Place Recognition Technique for Changing Environments. IEEE Robot. Autom. Lett. 2020, 5, 1835–1842. [Google Scholar] [CrossRef]
- Colomer, S.; Cuperlier, N.; Bresson, G.; Romain, O. Forming a sparse representation for visual place recognition using a neurorobotic approach. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3002–3009. [Google Scholar] [CrossRef]
- Colomer, S.; Cuperlier, N.; Bresson, G.; Gaussier, P.; Romain, O. LPMP: A Bio-Inspired Model for Visual Localization in Challenging Environments. Front. Robot. AI 2022, 8, 422. [Google Scholar] [CrossRef] [PubMed]
- Zaffar, M.; Ehsan, S.; Milford, M.; Flynn, D.; McDonald-Maier, K. VPR-Bench: An Open-Source Visual Place Recognition Evaluation Framework with Quantifiable Viewpoint and Appearance Change. arXiv 2020, arXiv:2005.08135. [Google Scholar] [CrossRef]
- Grieves, R.M.; Jeffery, K.J. The representation of space in the brain. Behav. Process. 2017, 135, 113–131. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Guo, K.; Zeng, S.; Yu, J.; Wang, Y.; Yang, H. A survey of FPGA-based neural network accelerator. arXiv 2017, arXiv:1712.08934. [Google Scholar]
- Alveo U55C. Available online: https://www.nasdaq.com/press-release/xilinx-launches-alveo-u55c-its-most-powerful-accelerator-card-ever-purpose-built-for (accessed on 15 November 2021).
- Dreschmann, M.; Heisswolf, J.; Geiger, M.; Becker, J.; HauBecker, M. A framework for multi-FPGA interconnection using multi gigabit transceivers. In Proceedings of the 2015 28th Symposium on Integrated Circuits and Systems Design (SBCCI), Salvador, Brazil, 31 August–4 September 2015; pp. 1–6. [Google Scholar]
- 7 Series FPGAs Transceivers Wizard v3.6. Available online: https://www.xilinx.com/content/dam/xilinx/support/documentation/ip_documentation/gtWizard/v3_6/pg168-gtWizard.pdf (accessed on 30 November 2016).
- Liu, Y.; Liu, P.; Jiang, Y.; Yang, M.; Wu, K.; Wang, W.; Yao, Q. Building a multi-FPGA-based emulation framework to support networks-on-chip design and verification. Int. J. Electron. 2010, 97, 1241–1262. [Google Scholar] [CrossRef]
- Aloisio, A.; Cevenini, F.; Giordano, R.; Izzo, V. Characterizing jitter performance of multi gigabit FPGA-embedded serial transceivers. In Proceedings of the 2009 16th IEEE-NPSS Real Time Conference, Beijing, China, 10–15 May 2009; pp. 96–101. [Google Scholar] [CrossRef]
- Moser, M.B.; Rowland, D.C.; Moser, E.I. Place Cells, Grid Cells and Memory. Cold Spring Harb. Perspect. Biol. 2015, 7, a021808. [Google Scholar] [CrossRef]
- Qasaimeh, M.; Denolf, K.; Lo, J.; Vissers, K.; Zambreno, J.; Jones, P.H. Comparing Energy Efficiency of CPU, GPU and FPGA Implementations for Vision Kernels. In Proceedings of the 2019 IEEE International Conference on Embedded Software and Systems (ICESS), Las Vegas, NV, USA, 2–3 June 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Elouaret, T.; Zuckerman, S.; Kessal, L.; Espada, Y.; Cuperlier, N.; Bresson, G.; Ouezdou, F.B.; Romain, O. Position Paper: Prototyping Autonomous Vehicles Applications with Heterogeneous Multi-Fpga Systems. In Proceedings of the 2019 UK/ China Emerging Technologies (UCET), Glasgow, UK, 21–22 August 2019; pp. 1–2. [Google Scholar]
- Bergeron, M.; Elzinga, S.; Szedo, G.; Jewett, G.; Hill, T. 1080p60 Camera Image Processing Reference Design. XAPP794 (v1.3). 2013. Available online: https://www.eeweb.com/1080p60-camera-image-processing-reference-design-2/ (accessed on 20 March 2023).
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford RobotCar dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Espada, Y.; Cuperlier, N.; Bresson, G.; Romain, O. From Neurorobotic Localization to Autonomous Vehicles. Unmanned Syst. 2019, 7, 183–194. [Google Scholar] [CrossRef]
- Colomer, S. Approches Neuro-Robotique Intégrées pour la Localisation et la Navigation d’un Véhicule Autonome. Ph.D. Thesis, CY Cergy Paris Université, Ecole Doctorale EM2PSI, 2 avenue Adolphe-Chauvin, BP 222, 95302 Pontoise Cedex. Cergy-Pontoise, France, 2022. (Available upon request to the CY University Library). [Google Scholar]
- Aurora 8B/10B v11.0, LogiCORE IP Product Guide. Available online: https://docs.xilinx.com/v/u/11.0-English/pg046-aurora-8b10b (accessed on 5 October 2016).
- Mittal, P.; Singh, R.; Sharma, A. Deep Learning-based object detection in low-altitude UAV datasets: A survey. J. Img. Vis. Comp. 2020, 104, 104046. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, G.; Feng, X.; Li, X.; Fang, H.; Zhang, J.; Bai, X.; Tao, M.; He, Y. Detecting wheat heads from UAV low-altitude remote sensing images using Deep Learning based on transformer. Remote Sens. 2022, 14, 5141. [Google Scholar] [CrossRef]
- Imad, M.; Hassan, M.A.; Junaid, H.; Ahmad, I. Navigation System for Autonomous Vehicle: A Survey. J. Comput. Sci. Technol. Stud. 2020, 2, 20–35. [Google Scholar]
- Shi, W.; Alawieh, M.B.; Li, X.; Yu, H. Algorithm and hardware implementation for visual perception system in autonomous vehicle: A survey. Integration 2017, 59, 148–156. [Google Scholar] [CrossRef]
- Rathi, A. Real-Time Adaptation of Visual Perception. Ph.D. Thesis, University of California, Riverside, CA, USA, 2022. [Google Scholar]
- Lai, L.; Suda, N. Rethinking Machine Learning development and deployment for edge devices. arXiv 2018, arXiv:1806.07846. [Google Scholar]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef]
- Arif, A.; Barrigon, F.; Gregoretti, F.; Iqbal, J.; Lavagno, L.; Lazarescu, M.T.; Ma, L.; Palomino, M. Performance and energy-efficient implementation of a smart city application on FPGAs. J. Real-Time Image Proc. 2020, 17, 729–743. [Google Scholar] [CrossRef]
- Mittal, S. A survey of FPGA-based accelerators for convolutional neural networks. Neural Comput. Appl. 2020, 32, 1109–1139. [Google Scholar] [CrossRef]
- Abdelouahab, K.; Pelcat, M.; Serot, J.; Berry, F. Accelerating CNN inference on FPGAs: A Survey. 2018. Available online: http://xxx.lanl.gov/abs/1806.01683 (accessed on 20 March 2023).
- Umuroglu, Y.; Akhauri, Y.; Fraser, N.J.; Blott, M. LogicNets: Co-Designed Neural Networks and Circuits for Extreme-Throughput Applications. In Proceedings of the 2020 30th International Conference on Field-Programmable Logic and Applications (FPL), Gothenburg, Sweden, 31 August–4 September 2020; pp. 291–297. [Google Scholar] [CrossRef]
- Blott, M.; Fraser, N.J.; Gambardella, G.; Halder, L.; Kath, J.; Neveu, Z.; Umuroglu, Y.; Vasilciuc, A.; Leeser, M.; Doyle, L. Evaluation of Optimized CNNs on Heterogeneous Accelerators Using a Novel Benchmarking Approach. IEEE Trans. Comput. 2021, 70, 1654–1669. [Google Scholar] [CrossRef]
- Mirsadeghi, M.; Shalchian, M.; Kheradpisheh, S.R.; Masquelier, T. STiDi-BP: Spike time displacement based error backpropagation in multilayer spiking neural networks. Neurocomputing 2021, 427, 131–140. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Visual Place Recognition for Simultaneous Localization and Mapping. In Autonomous Vehicles Volume 2: Smart Vehicles; Wiley Online Library: Hoboken, NJ, USA, 2022; pp. 47–79. [Google Scholar]
- Cuperlier, N.; Demelo, F.; Miramond, B. FPGA-based bio-inspired architecture for multi-scale attentional vision. In Proceedings of the 2016 Conference on Design and Architectures for Signal and Image Processing (DASIP), Rennes, France, 12–14 October 2016; pp. 231–232. [Google Scholar]
- Abdoli, B.; Safari, S. A reconfigurable real-time neuromorphic hardware for spiking winner-takes-all network. Int. J. Circ. Theory Appl. 2020, 48, 2141–2152. [Google Scholar] [CrossRef]
- Guo, K.; Li, W.; Zhong, K.; Zhu, Z.; Zeng, S.; Han, S.; Xie, Y.; Debacker, P.; Verhelst, M.; Wang, Y. Neural Network Accelerator Comparison. Available online: https://nicsefc.ee.tsinghua.edu.cn/project.html (accessed on 10 November 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zynq-7045 | Nvidia Jetson TX2 | Nvidia Jetson Xavier AGX | |
|---|---|---|---|
| Overhead (ms) |
| Zynq SoC | A9 + Kintex-7 |
|---|---|
| LUTs | 218,600 |
| FlipFlops | 437,200 |
| Block RAMs | 545 |
| SMA connector | 1 port |
| DDR3 SDRAM | 1 GB (connected to PS) |
| DDR3 SODIMM | 1 GB (connected to PL) |
| Gbit Transceivers | 16 |
| USB 2.0/UART | 1 port |
| Gbit Ethernet | 1 port |
| Max. # Landmarks/Img | 8 | 16 | 32 | 48 |
|---|---|---|---|---|
| LUTs (%) | 8.89 | 13.56 | 25.3 | 39.91 |
| Registers (%) | 4.46 | 6.8 | 13.68 | 23.58 |
| BRAMs (%) | 38.07 | 46.88 | 64.5 | 82.11 |
| DSPs (%) | 21.56 | 32.22 | 53.56 | 74.89 |
| # Neurons | 50 | 80 | 90 | 100 | 150 | 170 | 180 |
|---|---|---|---|---|---|---|---|
| 8 Landmarks | |||||||
| LUTs (%) | 11.68 | 15.56 | 18.08 | 19.79 | 29.12 | 31.99 | 27.41 |
| BRAMs (%) | 16.70 | 31.38 | 49.72 | 53.39 | 86.42 | 93.76 | 132.29 |
| FLIP FLOP (%) | 2.69 | 1.67 | 2.85 | 2.89 | 3.16 | 3.27 | 2.03 |
| DSPs (%) | 1.33 | 0.33 | 1.33 | 1.33 | 1.33 | 1.33 | 1.44 |
| 16 landmarks | |||||||
| LUTs (%) | 16.73 | 24.51 | 28.37 | 31.41 | 41.75 | 46.67 | 52.32 |
| BRAMs (%) | 35.05 | 60.73 | 97.43 | 104.77 | 110.28 | 124.95 | 150.41 |
| FLIP FLOP (%) | 3.21 | 2.55 | 3.45 | 3.50 | 2.13 | 4.16 | 4.76 |
| DSPs (%) | 1.33 | 0.33 | 1.33 | 1.33 | 1.67 | 2.37 | 2.89 |
| 32 landmarks | |||||||
| LUTs (%) | 33.62 | 48.21 | 55.45 | 60.90 | 88.19 | 99.08 | 104.53 |
| BRAMs (%) | 24.04 | 94.50 | 94.50 | 94.50 | 376.33 | 376.33 | 376.33 |
| FLIP FLOP (%) | 2.68 | 1.33 | 2.71 | 2.71 | 2.75 | 2.75 | 2.76 |
| DSPs (%) | 1.89 | 2.44 | 1.89 | 1.89 | 1.89 | 1.89 | 1.89 |
| Number of Neurons in Place Cells | 30 | 60 | 90 |
|---|---|---|---|
| N-LOC | |||
| Learning: Latency (ms) | |||
| Using: Latency (ms) | |||
| Total Throughput (img/s) | 82 | 45 | 31 |
| Total Power consumption | ≈2.8 | ≈2.8 | ≈2.8 |
| static + dynamic (W) | |||
| Baseline reference | |||
| Learning: Latency (ms) | |||
| Using: Latency (ms) | |||
| Total Throughput (img/s) | 9 | 7 | 6 |
| Optimised reference | |||
| Learning: Latency (ms) | |||
| Using: Latency (ms) | |||
| Total Throughput (img/s) | 13 | 12 | 11 |
| Total Power consumption | ≈7.5–15 | ≈7.5–15 | ≈7.5–15 |
| static + dynamic (W) |
| IP Block | Slice LUTs | BRAM Tile | FLIP FLOPs | DSPs |
|---|---|---|---|---|
| Image processing | 29,647 (13.6%) | 255 (46.8%) | 30,553 (7.0%) | 298 (33.1%) |
| Single N-LOC | 62,377 (28.5%) | 164 (30.0%) | 7879 (1.8%) | 4 (0.4%) |
| (IP) Block | Description | Power (W) |
|---|---|---|
| Image processing | Image acquisition and landmark identification | 0.783 |
| Bio-inspired neural accelerator | Neuron activation; place cell recognition | 0.141 |
| Processing system | Hardcore processor (ARM Cortex A9) | 1.567 |
| Total power on chip (static + dynamic) | 2.749 |
| Baseline Ref | Optimised Ref | N-LOC | N-LOC | |
|---|---|---|---|---|
| Learning Latency (ms) | 18.99 | 17.6 | 2.6 | 3.57 |
| Using Latency (ms) | 146.66 | 72.60 | 29.2 | 9.81 |
| Total Throughput (img/s) | 6 | 11 | 31 | 70 |
| Speedups | N-LOC | N-LOC |
|---|---|---|
| Learning Latency | 8 | 4 |
| Using Latency | 3 | 7 |
| Total Throughput | 4 | 6 |
| IP Block | N-LOC | N-LOC | vs. |
|---|---|---|---|
| N-LOC | 0.472 | 0.993 | 2.10 |
| Processing System | 1.629 | 1.639 | 1.00 |
| TOTAL | 2.101 | 2.638 | 1.25 |
| # Neurons | Slice LUTs | BRAM Tile | FLIP FLOPs | DSPs |
|---|---|---|---|---|
| N-LOC | 68,209 (31.2%) | 192 (35.2%) | 3039 (0.7%) | 18 (2.0%) |
| N-LOC | 28,869 (13.2%) | 32 (5.9%) | 2614 (0.6%) | 17 (3.4%) |
| N-LOC | 84,198 (38.51%) | 96 (17.61%) | 8199 (3.75%) | 51 (10.2%) |
| Ref | 769 KOPS |
|---|---|
| N-LOC | 239 MOPs |
| Ref | 820 KOPS |
| N-LOC | 269 MOPs |
| N-LOC | 299 MOPs |
| North FPGA | North-W FPGA | |
|---|---|---|
| Lane Width (Bytes) | 2 | 2 |
| Line Rate (Gbps) | 6.25 | 6.25 |
| GT Refclk (Mhz) | 125 | 125 |
| Init clk (Mhz) | 50 | 50 |
| DRP clk (Mhz) | 50 | 50 |
| DRP clk (Mhz) | TX-only | RX-only |
| simplex | simplex |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elouaret, T.; Colomer, S.; De Melo, F.; Cuperlier, N.; Romain, O.; Kessal, L.; Zuckerman, S. Implementation of a Bio-Inspired Neural Architecture for Autonomous Vehicles on a Multi-FPGA Platform. Sensors 2023, 23, 4631. https://doi.org/10.3390/s23104631
Elouaret T, Colomer S, De Melo F, Cuperlier N, Romain O, Kessal L, Zuckerman S. Implementation of a Bio-Inspired Neural Architecture for Autonomous Vehicles on a Multi-FPGA Platform. Sensors. 2023; 23(10):4631. https://doi.org/10.3390/s23104631
Chicago/Turabian StyleElouaret, Tarek, Sylvain Colomer, Frédéric De Melo, Nicolas Cuperlier, Olivier Romain, Lounis Kessal, and Stéphane Zuckerman. 2023. "Implementation of a Bio-Inspired Neural Architecture for Autonomous Vehicles on a Multi-FPGA Platform" Sensors 23, no. 10: 4631. https://doi.org/10.3390/s23104631