
Comparing State-of-the-Art Deep Learning Algorithms for the Automated Detection and Tracking of Black Cattle



Abstract
:1. Introduction
- We compared the use of the cutting-edge detector YOLO v7 with the two-stage detection and instance segmentation of Detectron-2;
- We developed a customized tracking algorithm after comparing two state-of-the-art MOT algorithms, Deep-SORT and Strong-SORT;
- We used ResNet 50 as the backbone and modified the Strong-SORT algorithm by building a re-identification network structure for feature extraction in the appearance feature stage to make it more suitable for the black cattle dataset;
- We built the Re-ID dataset and presented a process for producing a semi-automatic nested dataset;
- We conducted extensive experiments on a large-scale dataset to validate the proposed approach. The results have indicated that our customized tracking algorithm enables high accuracy in tracking livestock.
2. Materials and Methods
2.1. Self-Built Dataset Acquisition
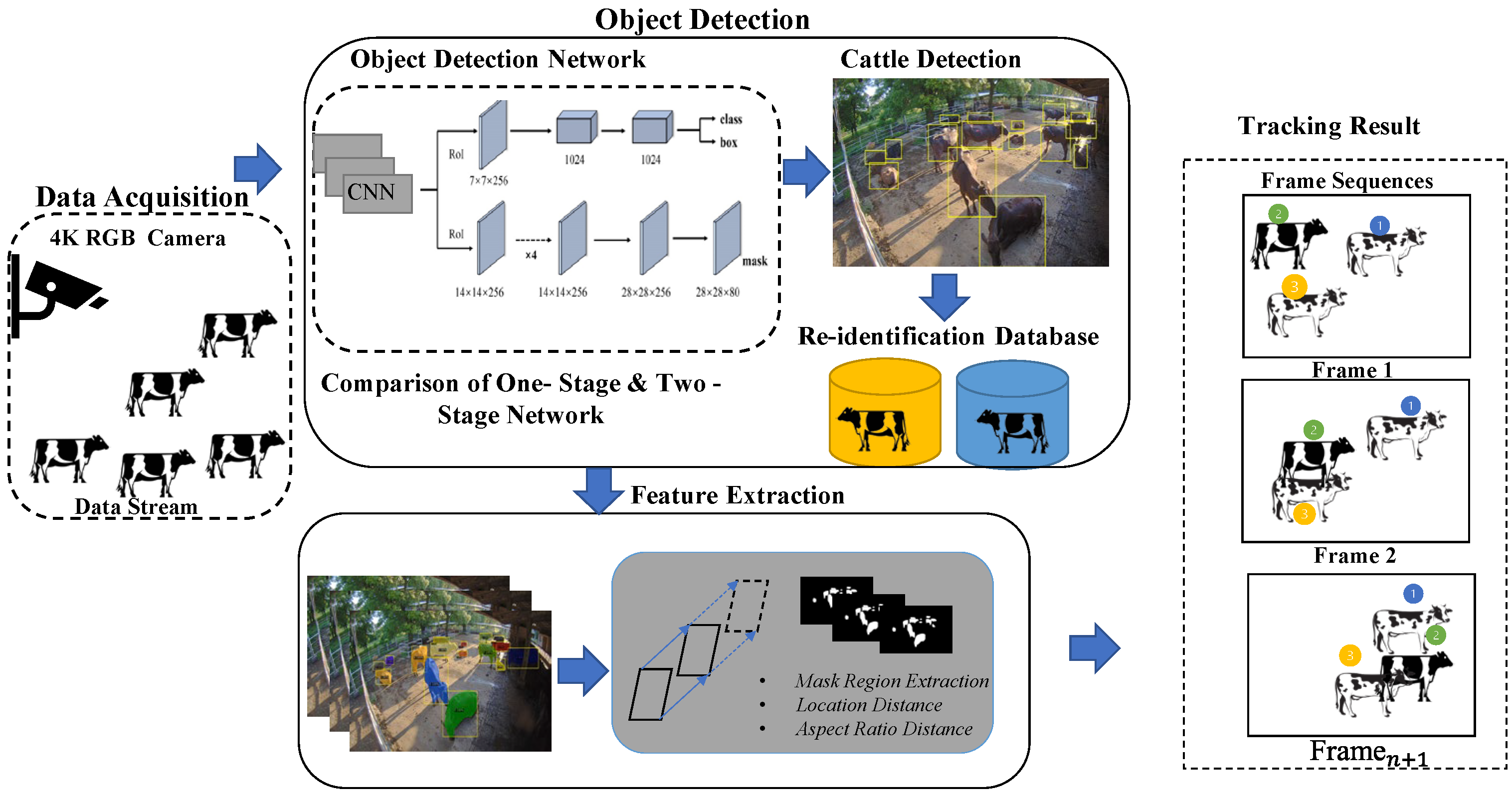
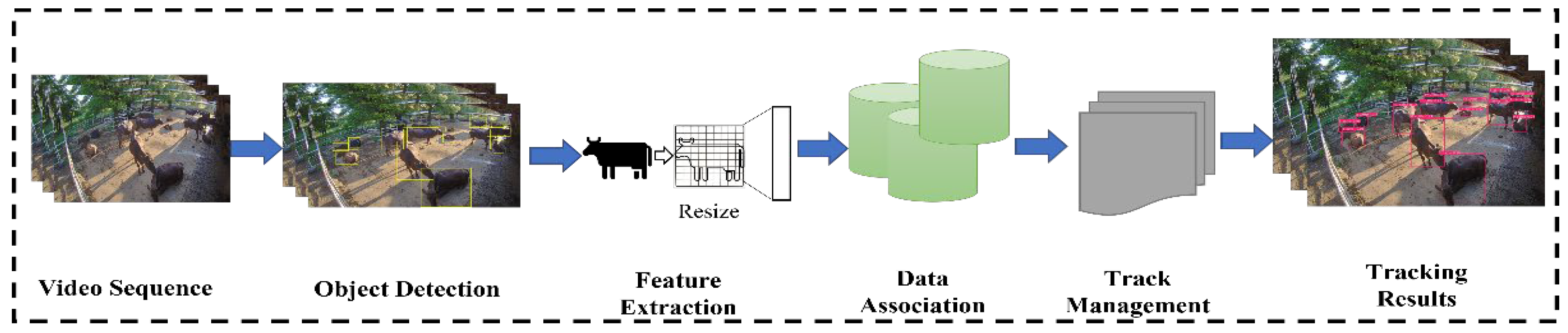
2.2. The Proposed System
2.3. The Object Detection
2.4. Object Tracking
2.5. Evaluation Methods
3. Experimental Design
3.1. Experimental Setup
3.2. Choice of Detection Model
3.3. Fitting the Detection Model in the Tracking Process
3.3.1. The MOT Network for Automatic Tracking
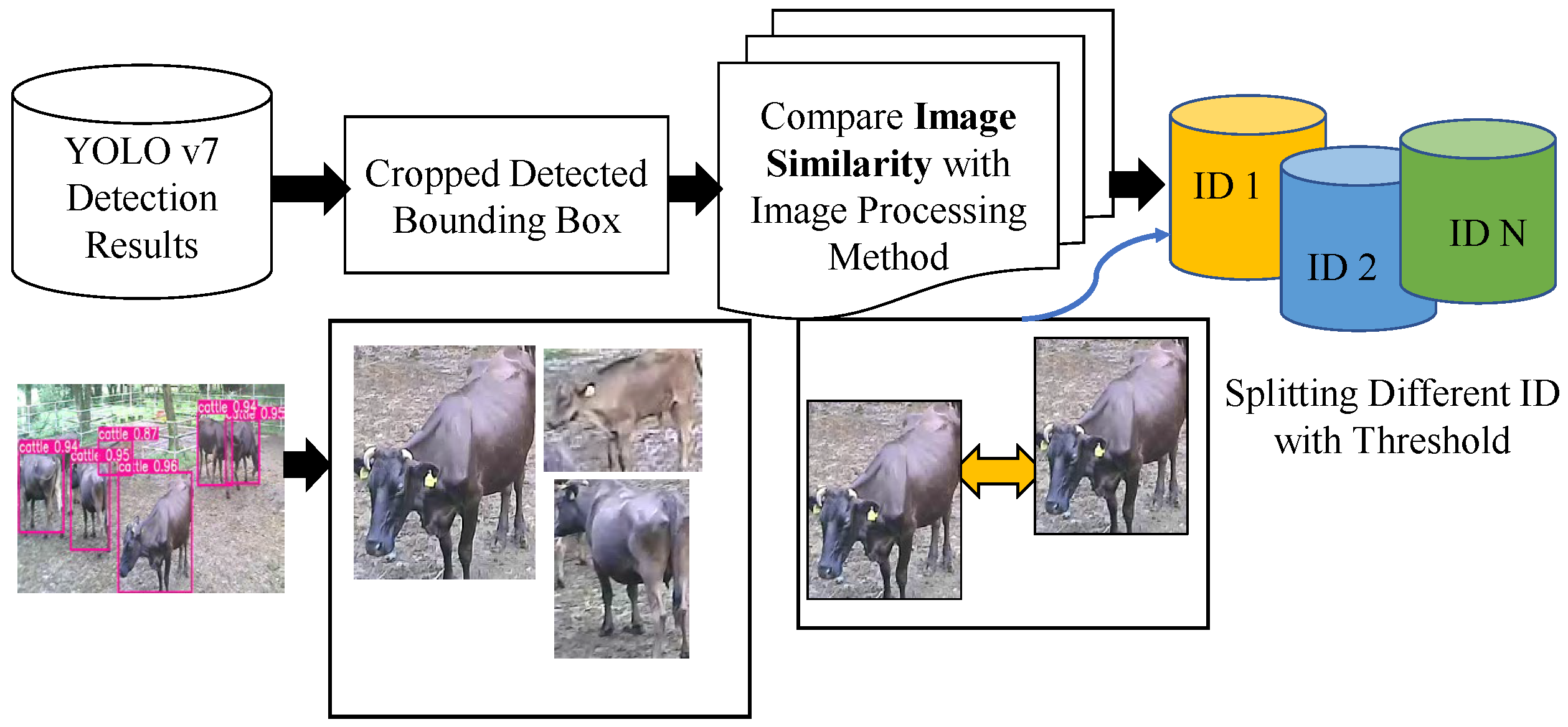
3.3.2. The Cattle Re-Identification Dataset
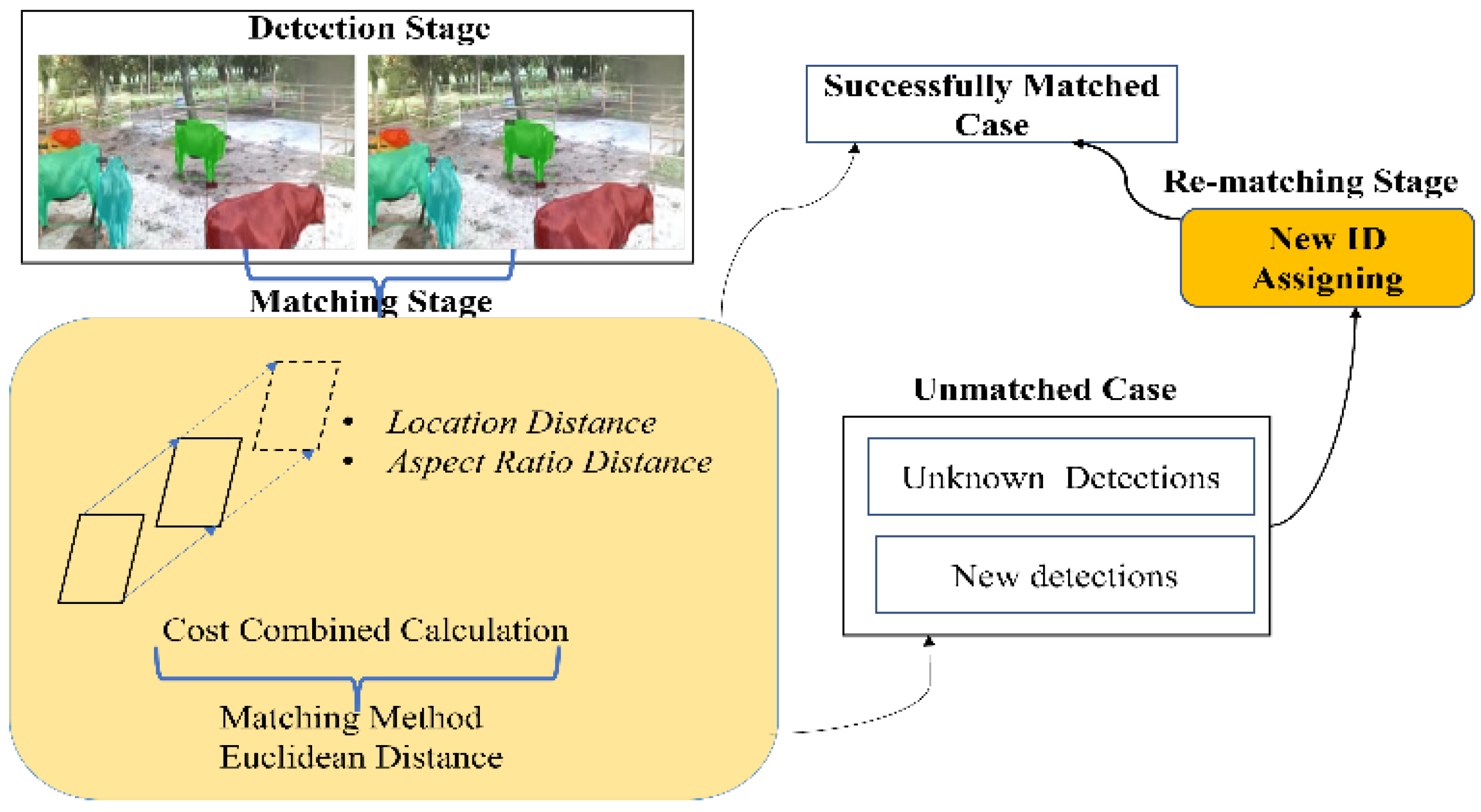
3.3.3. The Proposed Customized Light-Weight Tracking Mechanism
3.3.4. Matching
3.3.5. Re-Matching
| Algorithm 1. Cattle Tracking |
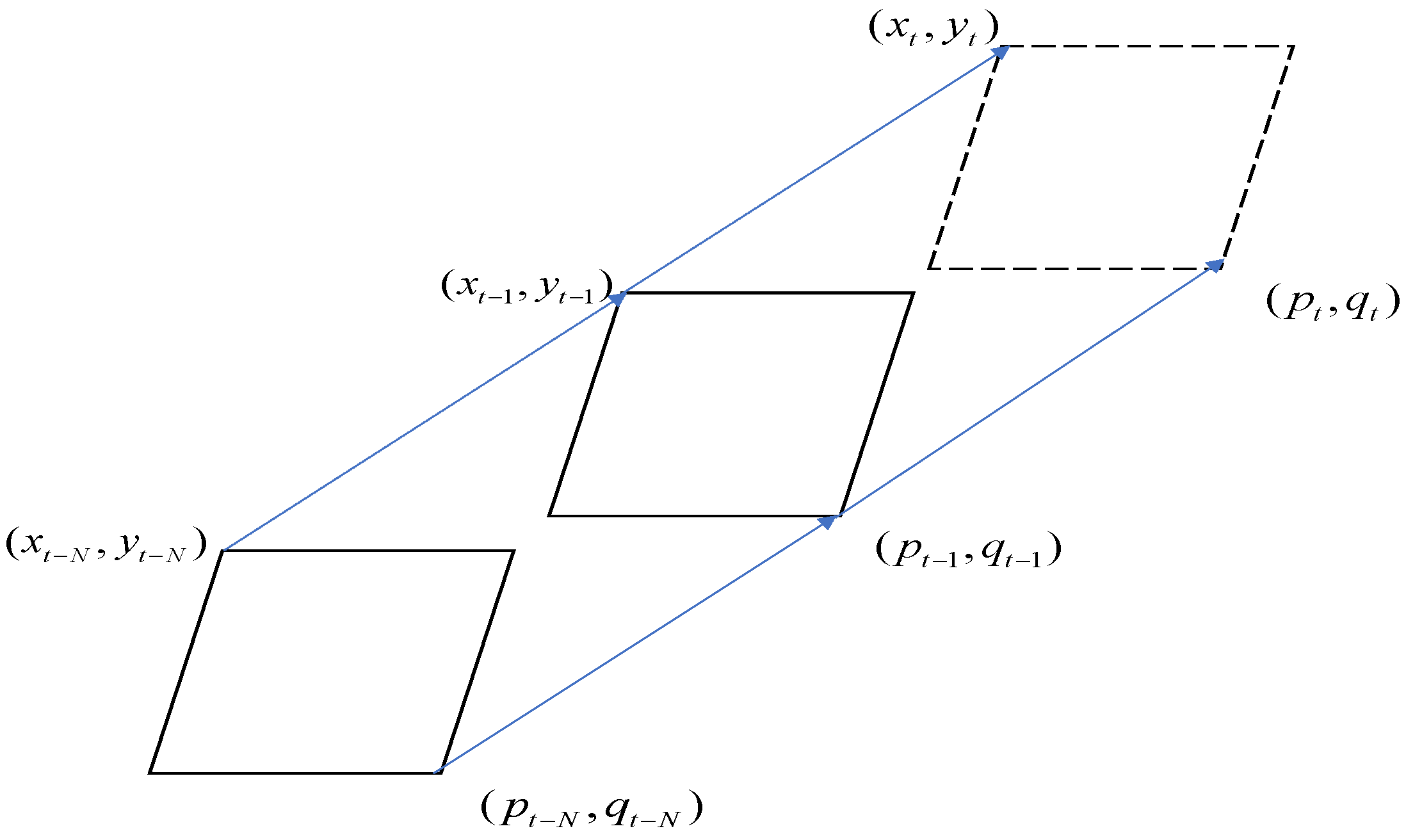
| Input: Bounding Boxes and mask-regions for each cow from Detectron-2 detection Output: IDs, the list of cow IDs 1: Function: Cattle_Tracking (Bounding Boxes, Mask Region): 2: Calculate Euclidean Distance for Aspect Ratio, Centroid values, and differences in Mask Area for each cow from frame to frame. 3: Perform the following steps for each cow 4. Assign each cow a tracking ID, calculating the distance between the previous and current frames using the cost function (8): |
| is the Location Distance; t is the current frame; x, y is the bounding box location; is the Average Euclidean Distance from current to N frames; Ar is the Aspect Ratio (Ar = w/ℎ); and COST is the combination of two distances (Location Distance and Aspect Ratio Distance). 5: Calculate to check the tracking database for the same detected object. 6: Compute the same object-to-tracking ID values from the tracking database. 7: Assign new tracking IDs for new cattle in the tracking database. 8: Return IDs 9: End Function |
4. Experimental Results and Discussion
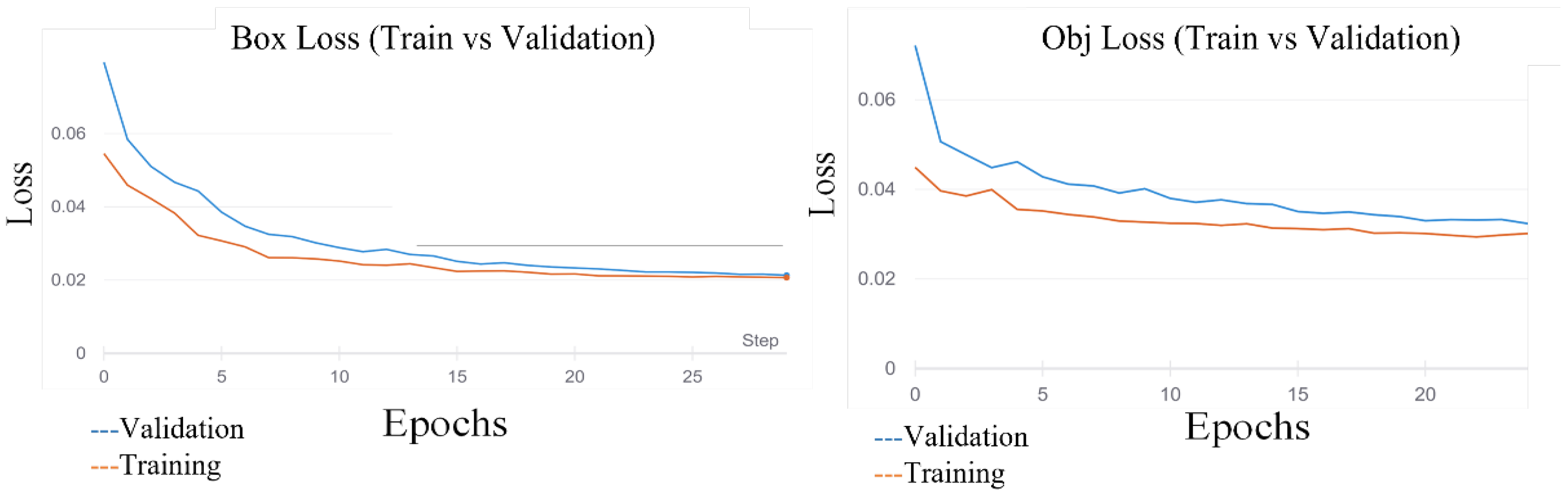
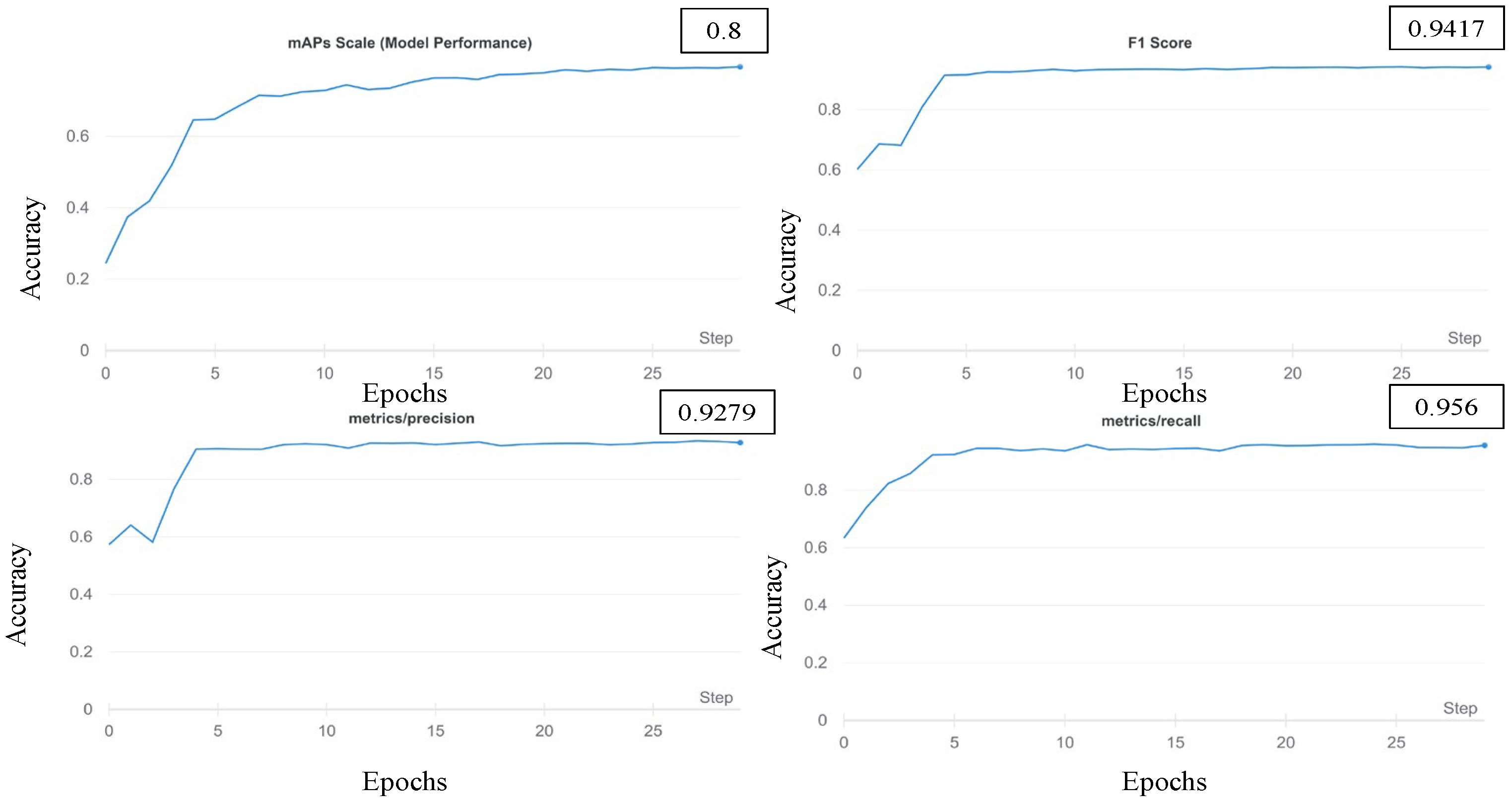
4.1. Detection Results
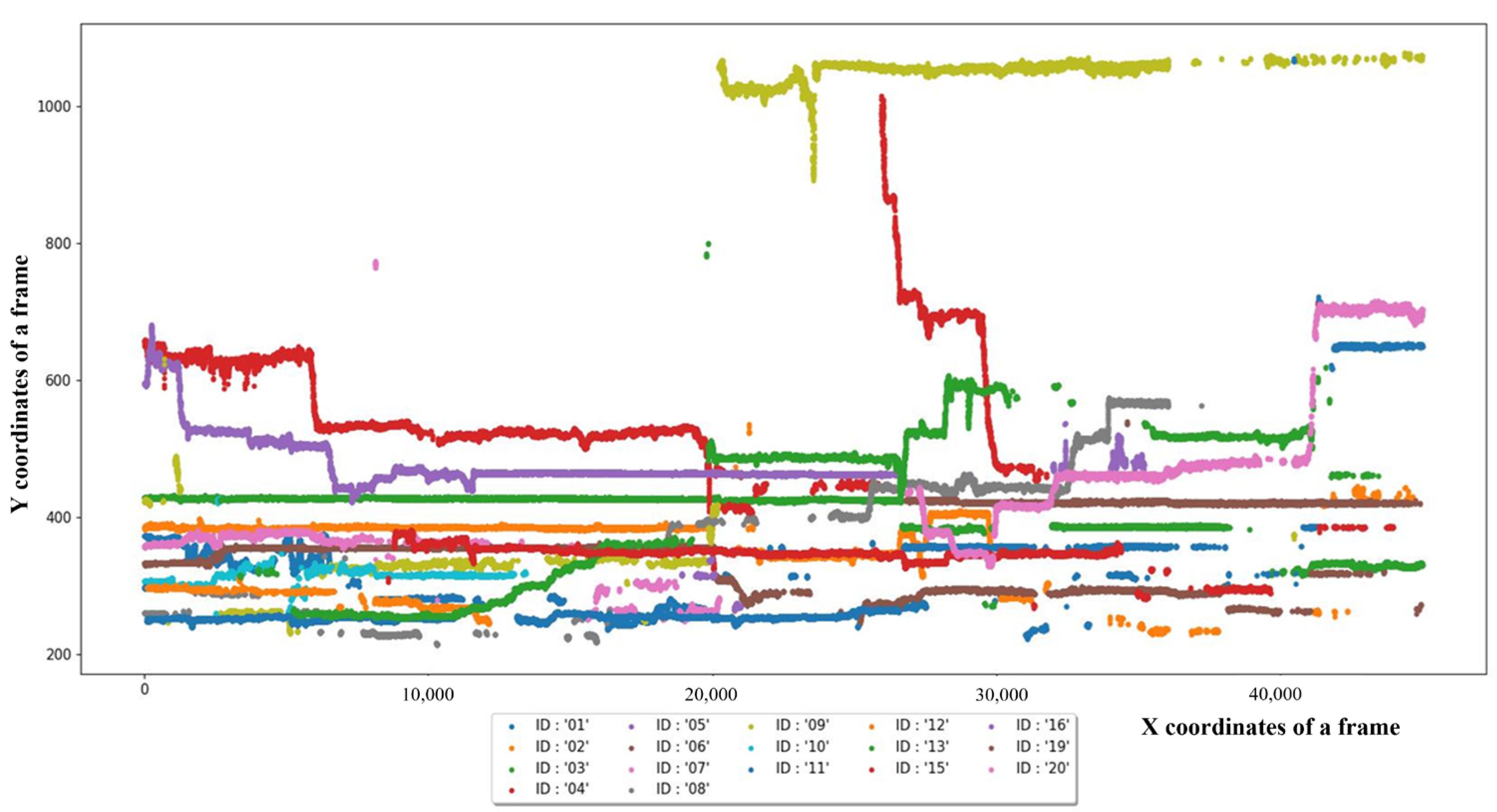
4.2. Tracking Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guo, Y.; He, D.; Chai, L. A machine vision-based method for monitoring scene-interactive behaviors of dairy calf. Animals 2020, 10, 190. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morrone, S.; Dimauro, C.; Gambella, F.; Cappai, M.G. Industry 4.0 and Precision Livestock Farming (PLF): An up-to-Date Overview across Animal Productions. Sensors 2022, 22, 4319. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2015; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Couturier, R.; Noura, H.N.; Salman, O.; Sider, A. A deep learning object detection method for an efficient cluster’s initialization. arXiv 2021, arXiv:2104.13634. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multi Box Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems, 28; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017; pp. 2961–2969. [Google Scholar]
- Zhang, Y.; Yu, C.; Liu, H.; Chen, X.; Lei, Y.; Pang, T.; Zhang, J. An Integrated Goat Head Detection and Automatic Counting Method Based on Deep Learning. Animals 2022, 12, 1810. [Google Scholar] [CrossRef]
- Kim, J.; Suh, Y.; Lee, J.; Chae, H.; Ahn, H.; Chung, Y.; Park, D. EmbeddedPigCount: Pig Counting with Video Object Detection and Tracking on an Embedded Board. Sensors 2022, 22, 2689. [Google Scholar] [CrossRef]
- Wang, R.; Gao, Z.; Li, Q.; Zhao, C.; Gao, R.; Zhang, H.; Li, S.; Feng, L. Detection Method of Cow Estrus Behavior in Natural Scenes Based on Improved YOLOv5. Agriculture 2022, 12, 1339. [Google Scholar] [CrossRef]
- Guo, Q.; Sun, Y.; Min, L.; van Putten, A.; Knol, E.F.; Visser, B.; Rodenburg, T.; Bolhuis, L.; Bijma, P. Video-based Detection and Tracking with Improved Re-identification Association for Pigs and Laying Hens in Farms. In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, SciTePress, Online-Streaming, 6–8 February 2022. [Google Scholar]
- Noe, S.M.; Zin, T.T.; Tin, P.; Kobayashi, I. Automatic detection and tracking of mounting behavior in cattle using a deep learning-based instance segmentation model. Int. J. Innov. Comput. Inf. Control 2022, 18, 211–220. [Google Scholar]
- Noe, S.M.; Zin, T.T.; Tin, P.; Hama, H. Detection of Estrus in Cattle by using Image Technology and Machine Learning Methods. In Proceedings of the 2020 IEEE 9th Global Conference on Consumer Electronics (GCCE), Kobe, Japan, 13–16 October 2020; pp. 320–321. [Google Scholar]
- Noe, S.M.; Zin, T.T.; Tin, P.; Kobayashi, I. Automatic Detection of Mounting Behavior in Cattle using Semantic Segmentation and Classification. In Proceedings of the 2021 IEEE 3rd Global Conference on Life Sciences and Technologies (Life-Tech), Nara, Japan, 9–11 March 2021; pp. 227–228. [Google Scholar]
- Du, Y.; Song, Y.; Yang, B.; Zhao, Y. Strong-SORT: Make Deep-SORT great again. arXiv 2022, arXiv:2202.13514. [Google Scholar]
- Abhishek, A.V.S.; Kotni, S. Detectron2 Object Detection & Manipulating Images using Cartoonization. Int. J. Eng. Res. Technol. (IJERT) 2021, 10. [Google Scholar] [CrossRef]
- Mekonnen, A.A.; Lerasle, F. Comparative evaluations of selected tracking-by-detection approaches. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 996–1010. [Google Scholar] [CrossRef] [Green Version]
- Milan, A.; Leal-Taixé, L.; Schindler, K.; Reid, I. Joint Tracking and Segmentation of Multiple Targets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5397–5406. [Google Scholar]
- Montella, C. The Kalman filter and related algorithms: A literature review. Res. Gate 2011. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and Realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Li, Z.; Tian, X.; Liu, Y.; Shi, X. Vehicle Tracking Method Based on Attention-YOLOv5 and Optimized DeepSORT Models. In Proceedings of the 2022 IEEE 11th Data Driven Control and Learning Systems Conference (DDCLS), Chengdu, China, 3–5 August 2022; pp. 114–121. [Google Scholar]
- Dendorfer, P.; Osep, A.; Milan, A.; Schindler, K.; Cremers, D.; Reid, I.; Roth, S.; Leal-Taixé, L. MOT challenge: A benchmark for single-camera multiple target tracking. Int. J. Comput. Vis. 2021, 129, 845–881. [Google Scholar] [CrossRef]
- Bernardin, K.; Elbs, A.; Stiefelhagen, R. Multiple Objects Tracking Performance Metrics and Evaluation in a Smart Room Environment. In Proceedings of the Sixth IEEE International Workshop on Visual Surveillance, in Conjunction with ECCV, Graz, Austria, 13 May 2006; Volume 90. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep Learning for Person Re-Identification: A Survey and Outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef]
- Gou, M.; Karanam, S.; Liu, W.; Camps, O.; Radke, R.J. DukeMTMC4ReID: A Large-Scale Multi-Camera Person Re-Identification Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 10–19. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Henderson, P.; Ferrari, V. End-to-End Training of Object Class Detectors for Mean Average Precision. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2017; pp. 198–213. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the ResNet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Wang, S.; Zuo, X.; Yang, R. Angus Cattle Recognition using Deep Learning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4169–4175. [Google Scholar]
- Tassinari, P.; Bovo, M.; Benni, S.; Franzoni, S.; Poggi, M.; Mammi, L.M.E.; Mattoccia, S.; Di Stefano, L.; Bonora, F.; Barbaresi, A.; et al. A Computer Vision Approach Based on Deep Learning for the Detection of Dairy Cows in Free Stall Barn. Comput. Electron. Agric. 2021, 182, 106030. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Falzon, G.; Kwan, P.; Guo, L.; Chen, G.; Tait, A.; Schneider, D. Automated cattle counting using Mask R-CNN in quadcopter vision system. Comput. Electron. Agric. 2020, 171, 105300. [Google Scholar] [CrossRef]
- Han, L.; Tao, P.; Martin, R.R. Livestock detection in aerial images using a fully convolutional network. Comput. Vis. Media 2019, 5, 221–228. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Chen, C.; Lai, C. Object Detection Algorithm Based AdaBoost Residual Correction Fast R-CNN on Networks. In Proceedings of the 2019 3rd International Conference on Deep Learning Technologies, Xiamen, China, 5–7 July 2019; pp. 42–46. [Google Scholar]
- Qiao, Y.; Su, D.; Kong, H.; Sukkarieh, S.; Lomax, S.; Clark, C. Individual cattle identification using a deep learning-based framework. IFAC-Pap. Online 2019, 52, 318–323. [Google Scholar] [CrossRef]
- Nguyen, C.; Wang, D.; Von Richter, K.; Valencia, P.; Alvarenga, F.A.; Bishop-Hurley, G. Video-based cattle identification and action recognition. arXiv 2021, arXiv:2110.07103. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Videos | Number of Images | Image Enhancement Method | Image Resolution |
|---|---|---|---|---|
| Training set | 30 | 3086 | Mosaic augmentation | 2560 × 2048 |
| Validation set | 5 | 771 | - | 2560 × 2048 |
| Total | 35 | 3857 | - | 2560 × 2048 |
| Layer No. | Name | Patch Size/Stride | Output Size |
|---|---|---|---|
| 1 | Conv 1 | 3 × 3/1 | 32 × 128 × 128 |
| 2 | Conv 2 | 3 × 3/1 | 32 × 128 × 128 |
| 3 | Max Pool | 3 × 3/2 | 32 × 64 × 64 |
| 4 | Residual 4 | 3 × 3/1 | 32 × 64 × 64 |
| 5 | Residual 5 | 3 × 3/1 | 64 × 32 × 32 |
| 6 | Residual 6 | 3 × 3/2 | 64 × 32 × 32 |
| 7 | Residual 7 | 3 × 3/1 | 128 × 16 × 16 |
| 8 | Dense 8 | - | 128 |
| 9 | Batch Normalization | 3 × 3/1 | 128 |
| 10 | Relu | 3 × 3/1 | 128 |
| Parameters | Value |
|---|---|
| MAX_DIST | 0.9 |
| MAX_IOU_DISTANCE | 0.8 |
| MAX_AGE | 1500 |
| N_INIT | 1 |
| NN_BUDGET | 100 |
| Model | Precision % | Recall% | mAP% (IOU = 0.5:0.95) | mAP% (IOU = 0.5:) | Inference Time (s) |
|---|---|---|---|---|---|
| YOLO v5s | 0.999 | 0.985 | 0.928 | 0.995 | 3500 |
| YOLO v5m | 0.999 | 0.985 | 0.936 | 0.994 | 3880 |
| YOLO v5n | 0.998 | 0.985 | 0.884 | 0.993 | 3500 |
| YOLO v5l | 0.998 | 0.985 | 0.994 | 0.947 | 4548 |
| Model | Precision % | Recall% | mAP% (IOU = 0.5:0.95) | mAP% (IOU = 0.5:) | Inference Time (s) |
|---|---|---|---|---|---|
| YOLO v7 | 0.999 | 0.985 | 0.871 | 0.997 | 18,292 |
| YOLO v7-X | 0.999 | 0.985 | 0.891 | 0.997 | 7998 |
| YOLO v7-W6 | 1.000 | 0.985 | 0.896 | 0.997 | 7815 |
| Model | Precision % | Recall% | mAP% (IOU = 0.5:0.95) | mAP% (IOU = 0.5:) | Epoch | Inference Time (s) |
|---|---|---|---|---|---|---|
| Faster RCNN | 0.835 | 0.907 | 0.953 | 0.987 | 1500 | 2724 |
| YOLO v5s | 0.999 | 0.985 | 0.928 | 0.995 | 100 | 3500 |
| YOLO v7s | 0.999 | 0.985 | 0.871 | 0.997 | 55 | 18,292 |
| Methods | Depth | Iteration | Inference Time (s) | Validation Accuracy |
|---|---|---|---|---|
| ResNet 18 | 18 | 1000 | 3500 | 0.894 |
| ResNet 50 | 50 + FPN | 1000 | 3800 | 0.916 |
| ResNet 101 | Original | 800 | 2500 | 0.914 |
| 900 | 3200 | 0.921 | ||
| 1000 | 3340 | 0.948 | ||
| 1100 | 3500 | 0.948 | ||
| C4 3x | 1000 | 4200 | 0.929 | |
| 32 × 8d FPN 3 × | 1000 | 4300 | 0.948 |
| Methods | mAP @ 0.5 (%) | Inference Time (s) |
|---|---|---|
| Detectron-2 | 0.927 | 6300 |
| Methods | MOTA | ID-Switch | Inference Time (s) |
|---|---|---|---|
| YOLO v5 + Deep-SORT | 92.52% | 10 | 1260 |
| YOLO v7 + Strong-SORT | 95.32% | 7 | 1800 |
| Ours (YOLO v7 + Modified Strong-SORT) | 96.88% | 4 | 3600 |
| Ours (Detectron-2 + Tracking) | 96.88% | 4 | 3900 |
| Videos | #Cattle Ground Truth | #Tracked Cattle | MOTA (%) |
|---|---|---|---|
| Clip 1 | 20 | 19 | 98 |
| Clip 2 | 21 | 20 | 98 |
| Clip 3 | 22 | 21 | 98 |
| Clip 4 | 21 | 21 | 100 |
| Clip 5 | 25 | 23 | 97 |
| Modules | Inference Time (s) |
|---|---|
| Detection module | 1700 |
| Tracking module | 7200 |
| Total | 8400 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Myat Noe, S.; Zin, T.T.; Tin, P.; Kobayashi, I. Comparing State-of-the-Art Deep Learning Algorithms for the Automated Detection and Tracking of Black Cattle. Sensors 2023, 23, 532. https://doi.org/10.3390/s23010532
Myat Noe S, Zin TT, Tin P, Kobayashi I. Comparing State-of-the-Art Deep Learning Algorithms for the Automated Detection and Tracking of Black Cattle. Sensors. 2023; 23(1):532. https://doi.org/10.3390/s23010532
Chicago/Turabian StyleMyat Noe, Su, Thi Thi Zin, Pyke Tin, and Ikuo Kobayashi. 2023. "Comparing State-of-the-Art Deep Learning Algorithms for the Automated Detection and Tracking of Black Cattle" Sensors 23, no. 1: 532. https://doi.org/10.3390/s23010532