

Lightweight Super-Resolution with Self-Calibrated Convolution for Panoramic Videos
 ,
,
Abstract
:1. Introduction
- We propose the first lightweight panoramic video super-resolution (LWPVSR) method for panoramic video super-resolution, which can achieve a good balance between performance and complexity. To the best of our knowledge, this is the first proposition of a lightweight panoramic VSR framework.
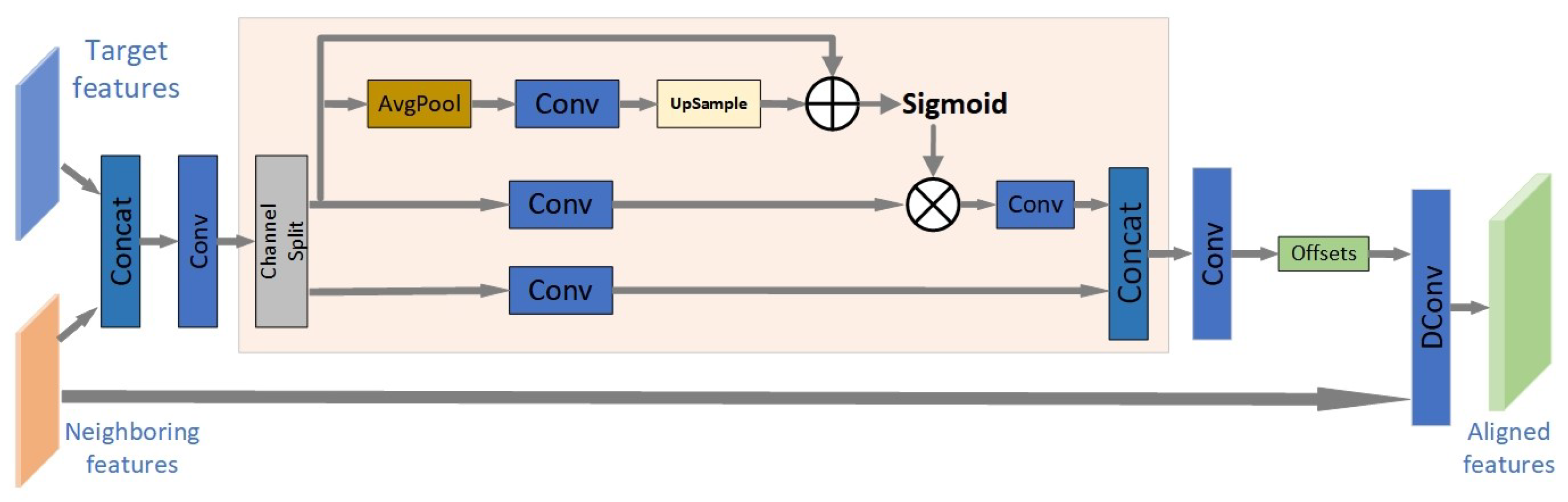
- Moreover, we present a new pooled, self-calibrated convolution for frame alignment. The self-calibrated convolution is introduced to make the learned offset more accurate in a progressive manner and reduce the complexity of the proposed network.
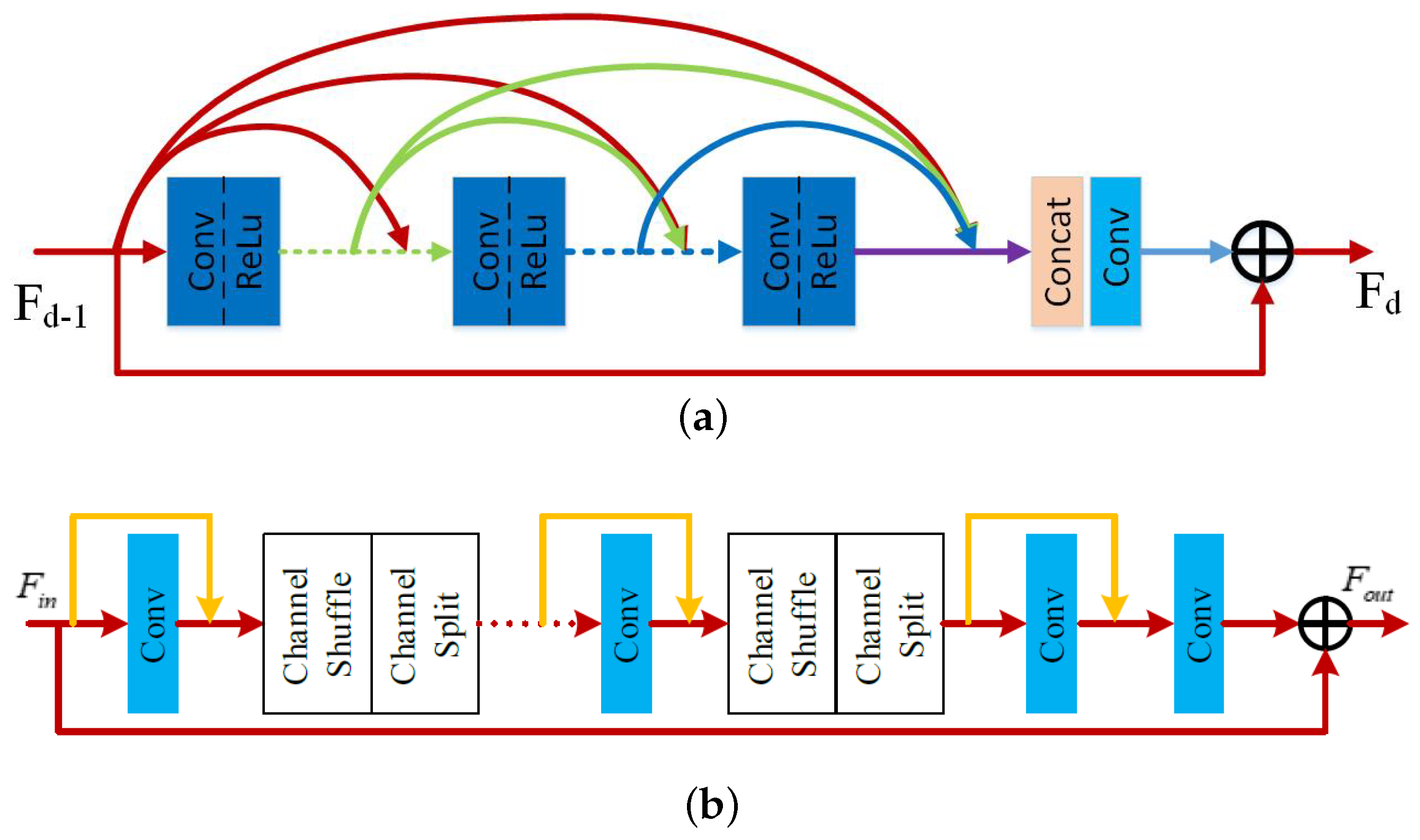
- Finally, we design a new significantly lighter residual dense block (LWRDB) for feature reconstruction, which achieves the purpose of reducing the complexity of the model while maintaining the performance of our method. Many experimental results verify the advantage of the proposed LWPVSR method against state-of-the-art methods.
2. Related Work
2.1. Super-Resolution Methods for Ordinary Videos
2.2. Super-Resolution Methods for Panoramic Videos
3. The Proposed Lightweight Architecture for Panoramic Video Super-Resolution
3.1. Our Network Architecture
3.2. The Feature Extraction Module
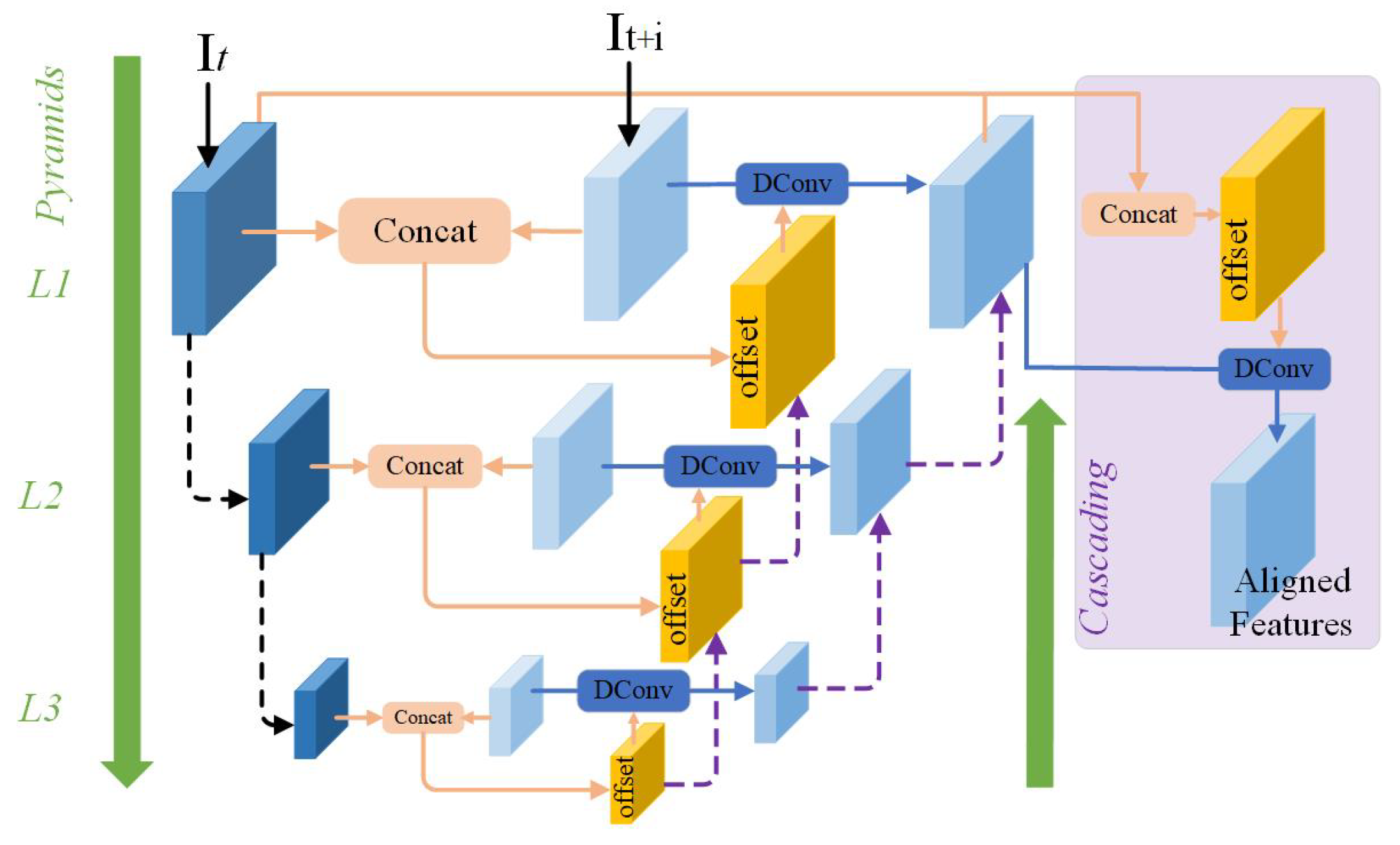
3.3. The Proposed Feature Alignment Module
3.4. Our Reconstruction Module
3.5. Our Dual Network Module and Loss Function
4. Experimental Results
4.1. Datasets
4.2. Training Setting
- (1)
- SR360 [8]: The batch size is set to 16. The weights of all the layers were initialized randomly and the network was trained from the scratch. The network used the Adam solver with a learning rate, .
- (2)
- (3)
- FRVSR [22]: The Adam is an optimizer. The learning rate is fixed at . Each sample in the batch is a set of 10 consecutive video frames, i.e., 40 video frames are passed through the networks in each iteration.
- (4)
- VESPVN [5]: The initial batch size is 1. Every 10 epochs the batch size is doubled until it reaches a maximum size of 128. The optimizer is Adam with a learning rate, .
- (5)
- TDAN [2]: The batch size is set to 64. The Adam is the optimizer. The learning rate is initialized to for all layers and decreases half for every 100 epochs.
- (6)
- SOFVSR [6]: The batch size is 32. The optimizer is Adam. The initial learning rate is and divided by 10 after every 80 K iterations.
- (7)
- EDVR [3]: The batch size is set to 32. The learning rate is initialized to , and initializes deeper networks by parameters from shallower ones for faster convergence.
- (8)
- OVSR [7]: The batch size is 16. The optimizer is Adam. The initial learning rate is and decays linearly to after 120 K iterations, which keeps the same until 200 K iterations. Then the learning rate is further decayed to and until convergence.
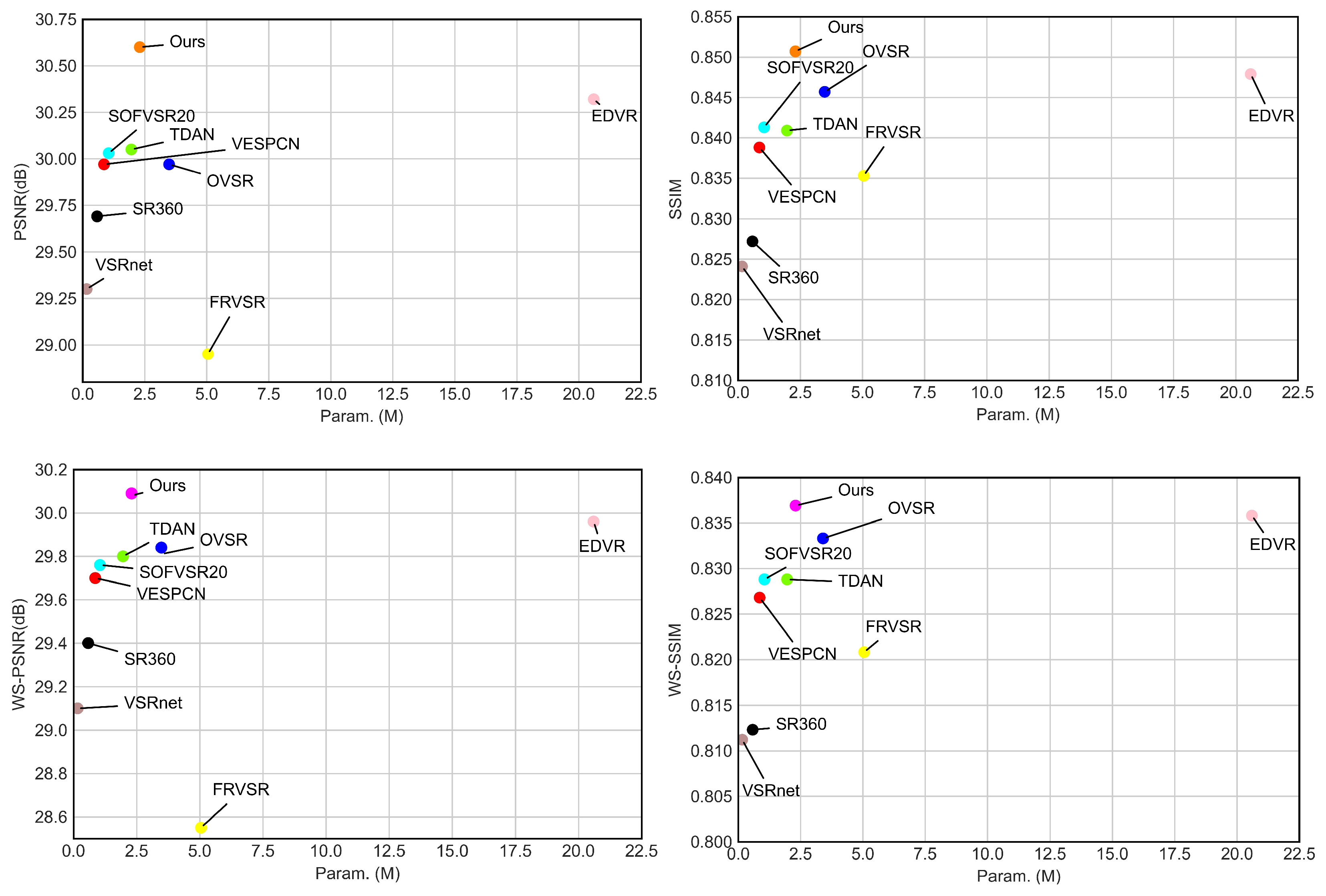
4.3. Quantitative Comparison
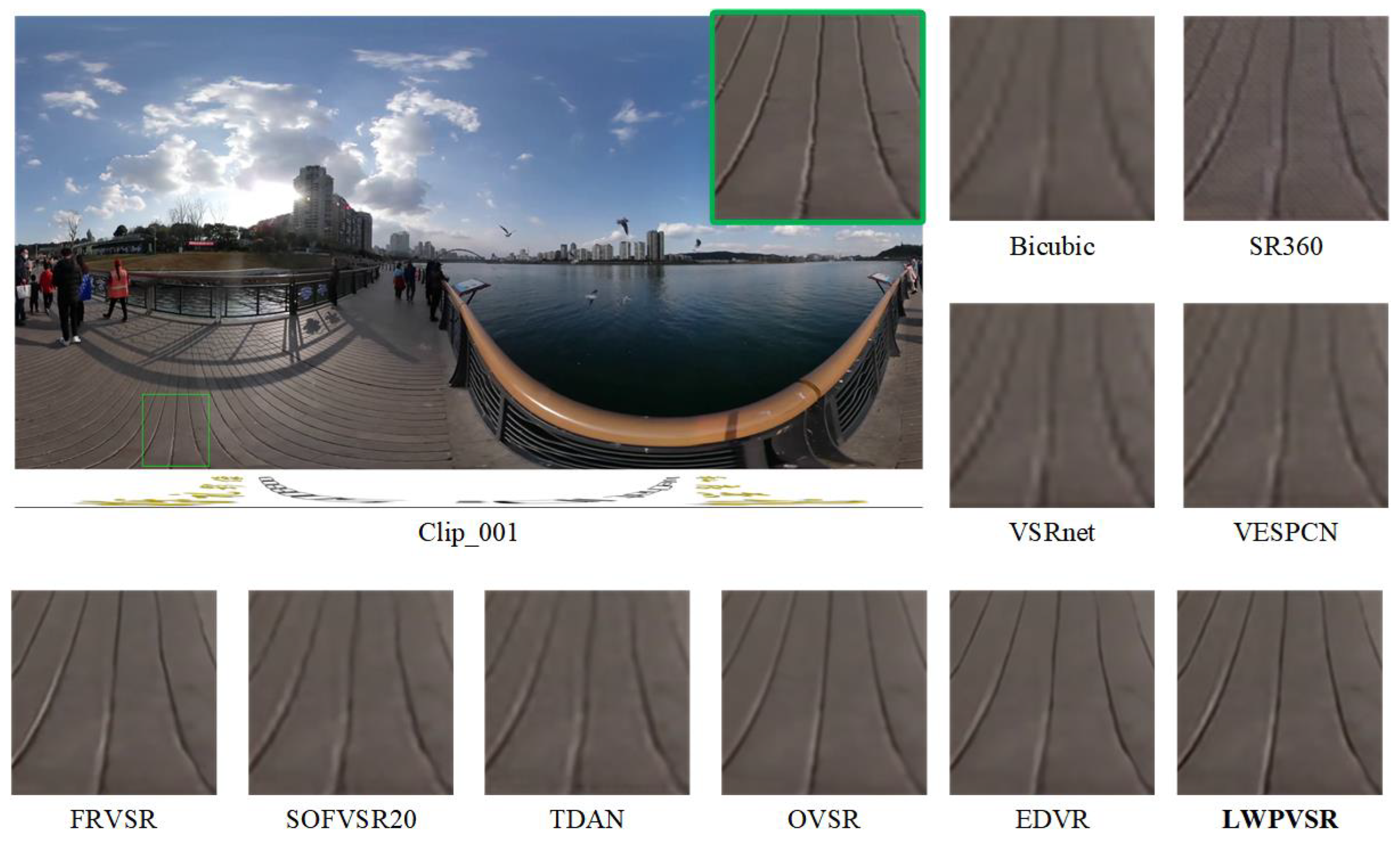
4.4. Qualitative Comparison
4.5. Ablation Studies
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, L.; Guo, Y.; Lin, Z.; Deng, X.; An, W. Learning for video super-resolution through HR optical flow estimation. In Proceedings of the Asian Conference on Computer Vision (ACCV), Perth, Australia, 2–6 December 2018; pp. 514–529. [Google Scholar]
- Tian, Y.; Zhang, Y.; Fu, Y.; Xu, C. TDAN: Temporally-deformable alignment network for video super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3360–3369. [Google Scholar]
- Wang, X.; Chan, K.C.K.; Yu, K.; Dong, C.; Loy, C.C. EDVR: Video restoration with enhanced deformable convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 1954–1963. [Google Scholar]
- Liu, H.; Ruan, Z.; Fang, C.; Zhao, P.; Shang, F.; Liu, Y.; Wang, L. A single frame and multi-frame joint network for 360-degree panorama video super-resolution. arXiv 2020, arXiv:2008.10320. [Google Scholar]
- Caballero, J.; Ledig, C.; Aitken, A.; Acosta, A.; Totz, J.; Wang, Z.; Shi, W. Real-time video super-resolution with spatio-temporal networks and motion compensation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4778–4787. [Google Scholar]
- Wang, L.; Guo, Y.; Liu, L.; Lin, Z.; Deng, X.; An, W. Deep video super-resolution using HR optical flow estimation. IEEE Trans. Image Process. 2020, 29, 4323–4336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yi, P.; Wang, Z.; Jiang, K.; Jiang, J.; Lu, T.; Tian, X.; Ma, J. Omniscient video super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 10–17 October 2021; pp. 4409–4418. [Google Scholar]
- Ozcinar, C.; Rana, A.; Smolic, A. Super-resolution of omnidirectional images using adversarial learning. In Proceedings of the 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Arican, Z.; Frossard, P. Joint registration and super-resolution with omnidirectional images. IEEE Trans. Image Process. 2011, 20, 3151–3162. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bagnato, L.; Boursier, Y.; Frossard, P.; Vandergheynst, P. Plenoptic based super-resolution for omnidirectional image sequences. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Hong Kong, China, 26–29 September 2010; pp. 2829–2832. [Google Scholar]
- Rivadeneira, R.E.; Sappa, A.D.; Vintimilla, B.X.; Hammoud, R. A Novel Domain Transfer-Based Approach for Unsupervised Thermal Image Super-Resolution. Sensors 2022, 12, 2254. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Jin, Y.; Lee, J.; Kim, S. High-Efficiency Super-Resolution FMCW Radar Algorithm Based on FFT Estimation. Sensors 2021, 21, 4018. [Google Scholar] [CrossRef] [PubMed]
- Fakour-Sevom, V.; Guldogan, E.; Kämäräinen, J.-K. 360 panorama super-resolution using deep convolutional networks. In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP), Funchal, Portugal, 27–29 January 2018; Volume 1. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Li, S.; Lin, C.; Liao, K.; Zhao, Y.; Zhang, X. Panoramic image quality-enhancement by fusing neural textures of the adaptive initial viewport. In Proceedings of the IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Atlanta, GA, USA, 22–26 March 2020; pp. 816–817. [Google Scholar]
- Liu, J.-J.; Hou, Q.; Cheng, M.; Wang, C.; Feng, J. Improving convolutional networks with self-calibrated convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10093–10102. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. Shufflenet V2: Practical guidelines for efficient CNN architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Video super-resolution with convolutional neural networks. IEEE Trans. Comput. Imaging 2016, 2, 109–122. [Google Scholar] [CrossRef]
- Sajjadi, M.S.M.; Vemulapalli, R.; Brown, M. Frame-recurrent video super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6626–6634. [Google Scholar]
- Du, J.; Cheng, K.; Yu, Y.; Wang, D.; Zhou, H. Panchromatic Image super-resolution via self attention-augmented wasserstein generative adversarial network. Sensors 2021, 21, 2158. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bicubic | SR360 [8] | VSRnet [21] | FRVSR [22] | VESPCN [5] | TDAN [2] | SOFVSR20 [6] | EDVR [3] | OVSR [7] | LWPVSR | |
|---|---|---|---|---|---|---|---|---|---|---|
| Clip_005 | 26.38 | 26.58 | 26.59 | 25.36 | 26.71 | 26.73 | 26.72 | 26.73 | 26.69 | 26.81 |
| 0.6868 | 0.7101 | 0.7075 | 0.7095 | 0.7203 | 0.7213 | 0.7203 | 0.7217 | 0.7207 | 0.7251 | |
| Clip_006 | 30.09 | 30.69 | 30.39 | 29.70 | 31.04 | 31.11 | 31.16 | 31.48 | 29.72 | 31.58 |
| 0.8494 | 0.8580 | 0.8573 | 0.8700 | 0.8723 | 0.8740 | 0.8775 | 0.8685 | 0.8902 | 0.8902 | |
| Clip_007 | 27.65 | 29.29 | 28.10 | 28.90 | 29.50 | 29.61 | 29.54 | 30.18 | 29.31 | 30.99 |
| 0.8119 | 0.8406 | 0.8245 | 0.8458 | 0.8490 | 0.8534 | 0.8527 | 0.8630 | 0.8622 | 0.8700 | |
| Clip_008 | 31.88 | 32.22 | 32.15 | 31.83 | 32.63 | 32.74 | 32.70 | 32.91 | 32.81 | 33.02 |
| 0.9005 | 0.9001 | 0.9069 | 0.9162 | 0.9134 | 0.9150 | 0.9147 | 0.9186 | 0.9183 | 0.9183 | |
| Average | 29.00 | 29.69 | 29.30 | 28.95 | 29.97 | 30.05 | 30.03 | 30.32 | 29.97 | 30.60 |
| 0.8121 | 0.8272 | 0.8241 | 0.8353 | 0.8388 | 0.8409 | 0.8413 | 0.8479 | 0.8457 | 0.8507 | |
| Params. (M) | - | 0.58 | 0.16 | 5.05 | 0.86 | 1.96 | 1.05 | 20.60 | 3.48 | 2.30 |
| Time (ms) | - | 64.30 | 2.52 | 71.57 | 122.59 | 16.11 | 76.86 | 670.80 | 69.55 | 92.31 |
| FLOPs (T) | - | 0.457 | 0.018 | 0.348 | 0.007 | 0.558 | 0.135 | 0.954 | 0.201 | 0.204 |
| Bicubic | SR360 [8] | VSRnet [21] | FRVSR [22] | VESPCN [5] | TDAN [2] | SOFVSR20 [6] | EDVR [3] | OVSR [7] | LWPVSR | |
|---|---|---|---|---|---|---|---|---|---|---|
| Clip_005 | 26.39 | 26.62 | 26.60 | 25.37 | 26.75 | 26.78 | 26.77 | 26.80 | 26.73 | 26.84 |
| 0.6888 | 0.7131 | 0.7118 | 0.7257 | 0.7263 | 0.7267 | 0.7257 | 0.7293 | 0.7260 | 0.7298 | |
| Clip_006 | 28.64 | 29.37 | 28.94 | 28.27 | 29.63 | 29.71 | 29.74 | 30.04 | 29.72 | 30.15 |
| 0.8274 | 0.8422 | 0.8386 | 0.8574 | 0.8569 | 0.8594 | 0.8622 | 0.8744 | 0.8685 | 0.8759 | |
| Clip_007 | 29.75 | 30.76 | 30.15 | 30.23 | 31.24 | 31.42 | 31.29 | 31.57 | 31.55 | 31.86 |
| 0.8009 | 0.8214 | 0.8165 | 0.8374 | 0.8379 | 0.8406 | 0.8392 | 0.8464 | 0.8465 | 0.8482 | |
| Clip_008 | 30.46 | 30.85 | 30.72 | 30.34 | 31.19 | 31.28 | 31.24 | 31.43 | 31.34 | 31.52 |
| 0.8685 | 0.8726 | 0.8779 | 0.8869 | 0.8854 | 0.8885 | 0.8880 | 0.8929 | 0.8924 | 0.8938 | |
| Average | 28.81 | 29.40 | 29.10 | 28.55 | 29.70 | 29.80 | 29.76 | 29.96 | 29.84 | 30.09 |
| 0.7964 | 0.8123 | 0.8112 | 0.8268 | 0.8266 | 0.8288 | 0.8288 | 0.8358 | 0.8333 | 0.8369 | |
| Params. (M) | - | 0.58 | 0.16 | 5.05 | 0.86 | 1.96 | 1.05 | 20.60 | 3.48 | 2.30 |
| Time (ms) | - | 64.30 | 2.52 | 71.57 | 122.59 | 16.11 | 76.86 | 670.80 | 69.55 | 92.31 |
| FLOPs (T) | - | 0.457 | 0.018 | 0.348 | 0.007 | 0.558 | 0.135 | 0.954 | 0.201 | 0.204 |
| Bicubic | SR360 [8] | VSRnet [21] | FRVSR [22] | VESPCN [5] | TDAN [2] | SOFVSR20 [6] | EDVR [3] | OVSR [7] | LWPVSR | |
|---|---|---|---|---|---|---|---|---|---|---|
| Clip_001 | 27.57 | 29.06 | 27.75 | 28.80 | 28.56 | 29.20 | 29.08 | 29.44 | 29.25 | 29.68 |
| 0.8659 | 0.8833 | 0.8742 | 0.8920 | 0.8909 | 0.8965 | 0.9004 | 0.9108 | 0.9122 | 0.9176 | |
| Clip_002 | 26.06 | 27.26 | 26.54 | 27.42 | 27.20 | 27.43 | 27.39 | 27.58 | 27.87 | 27.75 |
| 0.7426 | 0.7866 | 0.7650 | 0.8045 | 0.7976 | 0.8052 | 0.8073 | 0.8138 | 0.8378 | 0.8231 | |
| Clip_003 | 25.68 | 26.45 | 25.95 | 26.39 | 26.52 | 26.63 | 26.55 | 26.66 | 26.57 | 26.82 |
| 0.8240 | 0.8495 | 0.8359 | 0.8551 | 0.8568 | 0.8623 | 0.8607 | 0.8663 | 0.8737 | 0.8700 | |
| Clip_004 | 30.61 | 31.46 | 31.08 | 32.25 | 32.17 | 32.44 | 32.46 | 33.03 | 32.72 | 33.66 |
| 0.8889 | 0.8931 | 0.8983 | 0.9220 | 0.9196 | 0.9257 | 0.9280 | 0.9379 | 0.9404 | 0.9412 | |
| Clip_009 | 26.03 | 27.23 | 26.50 | 27.40 | 27.16 | 27.40 | 27.36 | 27.56 | 27.79 | 29.41 |
| 0.7515 | 0.7957 | 0.7717 | 0.8123 | 0.8044 | 0.8131 | 0.8136 | 0.8224 | 0.8637 | 0.8801 | |
| Average | 27.19 | 28.29 | 27.56 | 28.45 | 28.32 | 28.62 | 28.57 | 28.85 | 28.84 | 29.46 |
| 0.8146 | 0.8416 | 0.8290 | 0.8572 | 0.8539 | 0.8606 | 0.8620 | 0.8702 | 0.8856 | 0.8864 | |
| Params. (M) | - | 0.58 | 0.16 | 5.05 | 0.86 | 1.96 | 1.05 | 20.60 | 3.48 | 2.30 |
| Time (ms) | - | 64.30 | 2.52 | 71.57 | 122.59 | 16.11 | 76.86 | 670.80 | 69.55 | 92.31 |
| FLOPs (T) | - | 0.457 | 0.018 | 0.348 | 0.007 | 0.558 | 0.135 | 0.954 | 0.201 | 0.204 |
| Bicubic | SR360 [8] | VSRnet [21] | FRVSR [22] | VESPCN [5] | TDAN [2] | SOFVSR20 [6] | EDVR [3] | OVSR [7] | LWPVSR | |
|---|---|---|---|---|---|---|---|---|---|---|
| Clip_001 | 29.84 | 30.86 | 30.19 | 30.95 | 31.12 | 31.35 | 31.35 | 31.89 | 31.67 | 32.04 |
| 0.9630 | 0.8771 | 0.8731 | 0.8909 | 0.8901 | 0.8948 | 0.8969 | 0.9082 | 0.9053 | 0.9071 | |
| Clip_002 | 25.81 | 27.02 | 26.27 | 27.12 | 26.89 | 27.12 | 27.03 | 27.32 | 27.59 | 27.45 |
| 0.7416 | 0.7792 | 0.7626 | 0.7975 | 0.7916 | 0.7978 | 0.8003 | 0.8082 | 0.8226 | 0.8112 | |
| Clip_003 | 24.49 | 25.17 | 24.75 | 25.12 | 25.23 | 25.33 | 25.26 | 25.37 | 25.26 | 25.48 |
| 0.7807 | 0.8134 | 0.7972 | 0.8197 | 0.8212 | 0.8275 | 0.8252 | 0.8339 | 0.8308 | 0.8312 | |
| Clip_004 | 29.88 | 30.87 | 30.39 | 31.66 | 31.59 | 31.91 | 31.90 | 32.45 | 32.18 | 32.89 |
| 0.8666 | 0.8802 | 0.8796 | 0.9077 | 0.9053 | 0.9122 | 0.9143 | 0.9249 | 0.9242 | 0.9263 | |
| Clip_009 | 25.78 | 26.99 | 26.24 | 27.09 | 26.87 | 27.09 | 27.03 | 27.29 | 27.98 | 28.11 |
| 0.7448 | 0.7815 | 0.7617 | 0.7971 | 0.7907 | 0.7972 | 0.7993 | 0.8076 | 0.8312 | 0.8387 | |
| Average | 27.16 | 28.18 | 27.57 | 28.39 | 28.34 | 28.56 | 28.51 | 28.86 | 28.94 | 29.20 |
| 0.7993 | 0.8263 | 0.8148 | 0.8426 | 0.8398 | 0.8459 | 0.8472 | 0.8566 | 0.8628 | 0.8629 | |
| Params. (M) | - | 0.58 | 0.16 | 5.05 | 0.86 | 1.96 | 1.05 | 20.60 | 3.48 | 2.30 |
| Time (ms) | - | 64.30 | 2.52 | 71.57 | 122.59 | 16.11 | 76.86 | 670.80 | 69.55 | 92.31 |
| FLOPs (T) | - | 0.457 | 0.018 | 0.348 | 0.007 | 0.558 | 0.135 | 0.954 | 0.201 | 0.204 |
| PSNR | SSIM | Parameters (M) | |
|---|---|---|---|
| Ours | 30.60 | 0.8507 | 2.30 |
| Ours PSCC | 30.30 | 0.8471 | 2.26 |
| Ours LWRDB | 29.68 | 0.8290 | 1.49 |
| Ours PSCC and LWRDB | 29.64 | 0.8285 | 1.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shang, F.; Liu, H.; Ma, W.; Liu, Y.; Jiao, L.; Shang, F.; Wang, L.; Zhou, Z. Lightweight Super-Resolution with Self-Calibrated Convolution for Panoramic Videos. Sensors 2023, 23, 392. https://doi.org/10.3390/s23010392
Shang F, Liu H, Ma W, Liu Y, Jiao L, Shang F, Wang L, Zhou Z. Lightweight Super-Resolution with Self-Calibrated Convolution for Panoramic Videos. Sensors. 2023; 23(1):392. https://doi.org/10.3390/s23010392
Chicago/Turabian StyleShang, Fanjie, Hongying Liu, Wanhao Ma, Yuanyuan Liu, Licheng Jiao, Fanhua Shang, Lijun Wang, and Zhenyu Zhou. 2023. "Lightweight Super-Resolution with Self-Calibrated Convolution for Panoramic Videos" Sensors 23, no. 1: 392. https://doi.org/10.3390/s23010392