

Crowdsourced Reconstruction of Cellular Networks to Serve Outdoor Positioning: Modeling, Validation and Analysis †
 , , and
, , and
Abstract
:1. Introduction
2. An Overview of the Cellular Networks
2.1. General Features of Cellular Networks
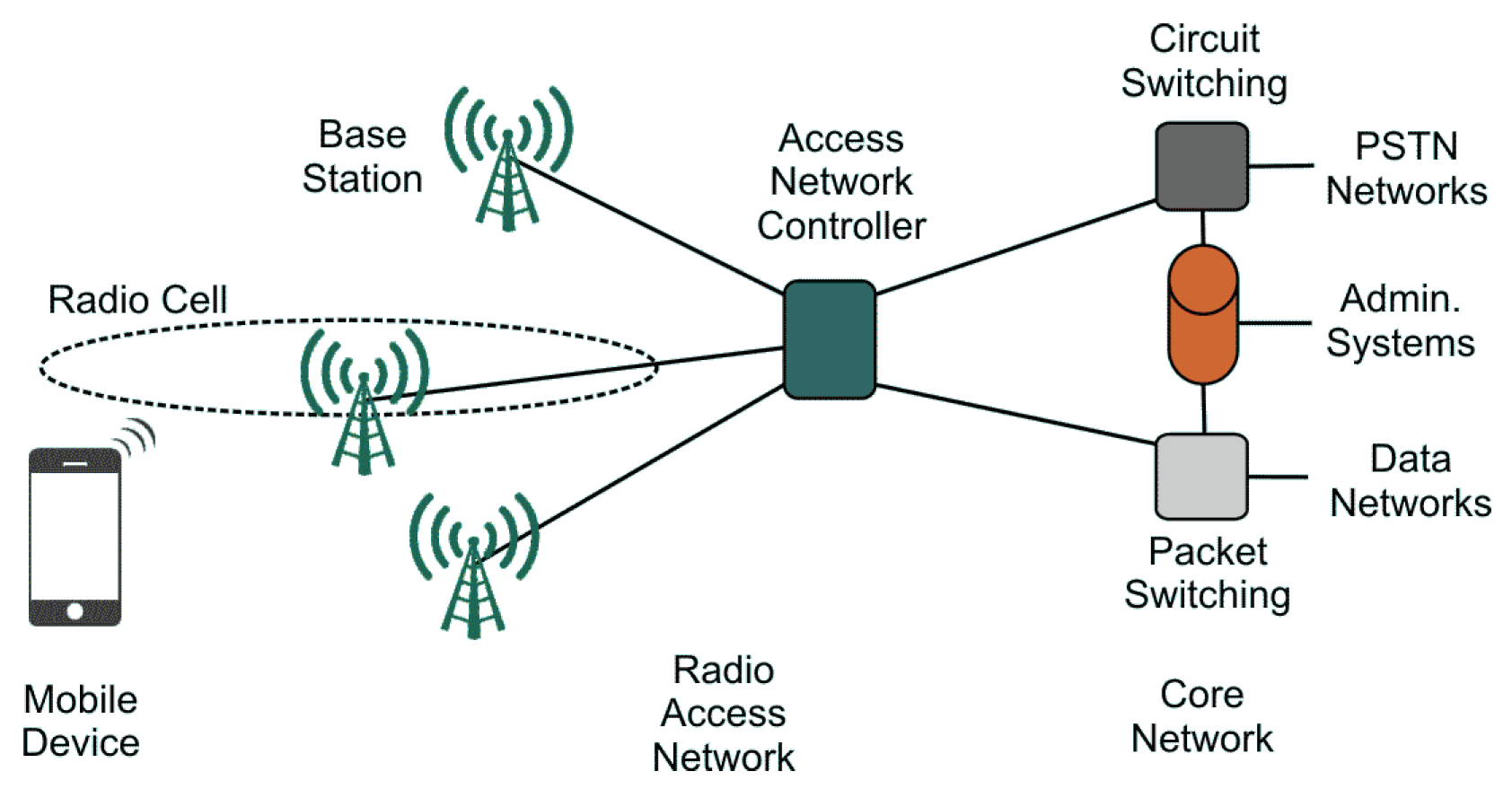
2.1.1. Architecture
2.1.2. Cells and Their Administrative Organization
2.1.3. Cell Identifiers
- The mobile country code (MCC), which identifies the country where a network is located. It consists of 12 bits, or equivalently, three digits, and is assigned by the International Telecommunication Union (ITU). Some countries, e.g., USA and India, have more than one MCC;
- The mobile network code (MNC), which identifies a network in a country. It consists of 8–12 bits, or equivalently, 2–3 digits, and is assigned by the national authority.
2.2. Common Issues Related to the Management of the Networks
3. Cellular Network Modeling
3.1. The Cellular Networks
3.2. GSM Networks
3.3. UMTS Networks
3.4. LTE Networks
3.5. The Overall Schema
3.6. The Temporal Aspects
- Scenario 1. On 2022-09-01, a new observation is added to the database, which, for the first time, reports the presence of a cell, say , which has never seen before. Thus, a tuple that describes the cell is inserted with both transaction and valid time intervals starting from 2022-09-01:
- Scenario 2. Valid and transaction times play a central role also in the management of a cell renaming or relocation. To reliably identify such an event, often multiple observations witnessing the change of parameters are needed, collected over an extended time frame (in general, the fewer the measurements related to a given area, the longer the period). Let us assume that a cell, named
3.7. Relational Database Development
3.7.1. Logical Schema
- Administrative area: two entities were introduced to deal with administrative areas: registration area and routing area.
- –
- The first entity focuses on the registration service (LA for GSM and UMTS, and TA for LTE); the attribute code_reg_area represents lac for 2G/3G and tac for 4G.
- –
- The second entity deals with the routing service, where differently from the first one (only for RA in GSM and UMTS), the attribute code_rout_area represents rac.
- For all the following specializations, it was decided to keep just the parent entity:
- –
- Network controller: the attribute code_ctrl groups the partial identifiers of the (former) children and type_ctrl denotes the type of controller (based on the considered cellular technology).
- –
- Base station: the attribute code_base groups the partial identifiers of the (former) children and type_base indicates the type of base station (based on the considered cellular technology).
- –
- SubPLMN: the optional attribute ncc represents the homonymous value considered in GSM technology only.
- –
- Cell: all the physical-layer cell identifiers values of different technologies are now modeled as optional attributes in the parent entity. Moreover, without loss of generality, a single attribute ci is used to represent both ci and eci.
- –
- Observation: the attribute id_device actually replaces the entity device.
3.7.2. Notes on the Physical Implementation
4. Cellular Network Reconstruction and Validation
4.1. Considered Datasets
- OpenCellID. It is a collaborative community project that collects measurements and cell towers’ data by means of an API and a ready-to-use mobile phone application. In spring 2017, the project was acquired by Unwired Labs, a geolocation service provider enterprise. This step changed privacy policies and also the kind of published data. Regardless, we worked on a dataset downloaded from the site project in April 2017. The data are in csv tabular format, and each measurement is characterized by the following attributes: mcc, net, area, cell, lon, lat, signal, measured, created, rating, speed, direction, radio, ta, rnc, cid, psc, tac, pci, sid, nid, and bid. Clearly, depending on the specific technology, some features may not be available, and their meanings may even be different. The problem of missing data is also exacerbated by the fact that the hetereogeneous devices which contributed to the dataset may have provided different subsets of information. The original dataset includes 42,952,377 measurements based on three different cellular technologies: GSM (26,896,809), UMTS (6,195,903), and LTE (9,859,665). The dataset covers the entire world, as can be seen in Figure 9a, where different densities in different areas can also be appreciated. OpenCellID dataset makes no distinction between serving and neighbor cells; thus, all measurements are considered as to be distinct, and all entries are serving cells.
- u-blox. For further testing the generality of our proposal, we extended the OpenCellID data with a proprietary dataset gathered by the company u-blox. For privacy reasons, we have obtained only information about the cellular networks, and not any details about devices and users. The dataset was assembled by parsing raw measurements logs. Each measurement contains a set of cells that are explicitly identified as serving and neighbors. Differently from OpenCellID, this dataset includes only GSM and UMTS cell information. GSM serving cells might contain a TA value, whereas UMTS neighbor cells do not usually have the logical parameters but only the physical ones. Measurements include the GNSS position with the time to first fix (TTFF), and the number of detected satellites. Overall, the dataset includes 12,492,545 measurements, partitioned into GSM (11,998,811) and UMTS (493,734). Figure 9b shows that, with respect to the OpenCellID dataset, u-blox data have lower worldwide coverage, although some areas are more densely sampled—for instance, South Africa. A high density of observations is also present in Europe, which, as we shall see, is useful for comparison and integration with data from OpenCellID.
4.2. Measurements Validation
4.3. Automatic Generation of the Network Database
4.4. Continuous and Periodic Validation
5. Cellular Network Analysis
5.1. Basic Analyses
5.2. Spatial Analyses
- subPLMNs. This is the case where one wants to inspect the coverage for a given area with respect to a single PLMN and/or a specific technology. Analyses like these may, e.g., point out which PLMN has the best coverage with respect to a specific cellular technology. While comparing different technologies and working at the level of subPLMN, it is immediately clear that around 50% of PLMNs (combination of mcc and mnc) were detected to have all three considered technologies (457 out of 996). Note that 302 had two technologies, and only 237 had only one. As an example, Figure 15 (top part) shows the coverages associated with the three different technologies considered in this work for a German PLMN (mcc = 262, mnc = 1). Although their areas may look very similar, if we calculate the bounding boxes at the cell level (still grouping them by subPLMN), we obtain a very different picture, as shown in Figure 15 (bottom part). This remarks on the usefulness of structuring the information at different granularity levels, modeled within a flexible hierarchy.
- Administrative areas. Proceeding down the hierarchy of the network, we find the logical grouping of cells represented by administrative areas. These play a major role in localization at a coarser granularity, as described in [37,38,39]. Some works [37,40,41] point out that the density of the cells within an area is likely useful to distinguish between urban and rural environments. In such a context, administrative areas are a simple way to sample the territory for computing the density and check whether it is a rural or an urban area: our model makes it easy to compute the density of cells following the administrative partitioning. As an example, considering the GSM network with and , Figure 16 shows some administrative areas close to the city of Berlin, each one being characterized by at least 9000 related observations. The violet and pink polygons correspond, respectively, to administrative areas identified by 21493 and 20473 covering two urban areas, and the green polygon on the left is the administrative area with 25503—in essence a rural area. It can be easily seen that the pink and violet polygons are characterized by a density of cells far higher than the green one.
- Cells. As described in [40] cells can be split into two categories: macrocells and microcells. Macrocells are usually related to a higher transmitting power, leading to a larger coverage area, whereas microcells are smaller and low-powered. The latter are typically used as support for extending networks’ capacity for specific areas, such as malls or crowded places. Urban areas are likely to contain more microcells than rural areas [40]. Finding an optimal strategy to discriminate microcells against macrocells is out of the scope of this paper; anyway, by restricting our attention to cells characterized by an area of at most 5 km and containing more than 30 observations, we can get an idea about this difference, as reported in Figure 17.
5.3. Temporal Analyses
- Cell coverage evolution. The presence of both transaction time and valid time dimensions allows us to easily track the evolution of the coverage of a cell over time. The idea is to exploit the transaction time of the involved instances to easily rollback the state of a cell. Figure 18 illustrates the coverage of a cell in the province of Bolzano (Italy) as it changes over time. Specifically, we report the resulting shape as new observations for such a cell are made. At the beginning, the coverage is just a single point, as only one observation is detected in such a cell. Then, the area progressively grows till it reaches the extension of the bright cyan polygon on 2017-03-12 at 08:50:38, i.e., when the last observation of the cell is added to the database. It is worth pointing out how the overall knowledge about the cell dramatically changed over a very short time interval.
- Cellular technology coverage evolution. Let us now turn to another practical scenario where the temporality of the data shows its usefulness: based on the valid time recorded for each instance, we can easily inspect the evolution of the coverage of the UMTS network in Germany at two different time points (2016-03-17 and 2017-03-17), as shown in Figure 19. Note how the coverage increased over time. Similar analyses can extract the evolution of the coverage of several mobile operators considering different technologies. In turn, those data may allow one to detect deficiencies in an operator’s network, to compare competitors’ coverages, and to build machine learning models able of predicting their future extension.
- Cell renaming. Here we present the case of an actual cell that has been obtained after a renaming operation, detected thanks to the developed system. In such a case, it may still be useful to investigate how the network arrangement was before the renaming operation. Figure 20 depicts the coverage of a cell in the city of Polokwane (South Africa) as currently stored in the database. Thanks again to the support of valid and transaction times offered by the system, we can easily roll back the renaming operation, showing the previous situation where two cells are visible (red and blue polygons).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Cellular Network Technologies
Appendix A.1. 2G Global System for Mobile Communications (GSM)
Appendix A.1.1. Architecture

Appendix A.1.2. Cell Global Identifiers
- The LAC is a fixed-length code (16 bits/4 digits) that characterizes a location area (LA) in a GSM network;
- The CI is used to uniquely identify a cell in a given LAC (this means that the same value for CI can occur in different LACs). It consists of 16 bits and can thus assume 65,535 different values. In the early years of the GSM technology, due to the small number of cells in a network, the CI was unique for all the LACs.
Appendix A.1.3. Physical-Layer Cell Identifiers
- The three most significant bits are the network color code (NCC), which can be used to distinguish one operator from the other, as in a country, a distinct NCC is assigned to each operator;
- The latter three bits are the base station color code (BCC), which can be used to discriminate among the cells associated with the same network operator.
Appendix A.2. 3G Universal Mobile Telecommunications System (UMTS)
Appendix A.2.1. Architecture

Appendix A.2.2. Cell Global Identifiers
Appendix A.2.3. Physical-Layer Cell Identifiers
- The UTRA absolute radio frequency channel number (UARFCN), which is the radio carrier identifier, as in GSM; it is equal to five times the carrier frequency in MHz and ranges from 0 to 16,383 (14 bits);
- The primary scrambling code (PSC), which is the first part of the synchronization channel (SCH), a downlink signal used for cell search; it ranges from 0 to 511 (9 bits), and it allows one to identify the transmission in each cell.
Appendix A.3. 4G Long-Term Evolution (LTE)
Appendix A.3.1. Architecture

Appendix A.3.2. Cell Global Identifiers
- eNB-ID, which identifies the eNB responsible for managing the cell;
- cell_ID, which identifies a cell/sector within a specific eNB.
Appendix A.3.3. Physical-Layer Cell Identifiers
- Evolved absolute radio frequency channel number (EARFCN), a 16-bit code that represents the channel number and is bound to the used frequency by a formula;
- Physical cell identifier (PCI), a 9-bit code which is composed of the physical group ID and the physical cell ID. A typical LTE deployment scenario is a three-sector installation on same EARFCN, where each sector has a sequential PCI. The standard defines 168 cell identity groups, each having three identities; thus, there are 168 × 3 = 504 PCI values available.
Appendix A.4. Summary of Identifiers

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Country | Operator | Administrative Area | Cell | |
|---|---|---|---|---|---|
| Voice | Data | ||||
| 2G GSM | MCC | MNC | LAC | RAC | CI |
| 3G UMTS | MCC | MNC | LAC | RAC | CI |
| 4G LTE | MCC | MNC | TAC | eCI | |
| Technology | Channel | Physical-Layer |
|---|---|---|
| GSM | ARFCN | BSIC (NCC+BCC) |
| UMTS | UARFCN | PSC |
| LTE | EARFCN | PCI |
References
- Mazimpaka, J.D.; Timpf, S. Trajectory Data Mining: A Review of Methods and Applications. J. Spat. Inf. Sci. 2016, 2016, 61–99. [Google Scholar] [CrossRef]
- Teunissen, P.J.; Montenbruck, O. Springer Handbook of Global Navigation Satellite Systems; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10. [Google Scholar]
- Vo, Q.D.; De, P. A Survey of Fingerprint-based Outdoor Localization. IEEE Commun. Surv. Tutor. 2015, 18, 491–506. [Google Scholar] [CrossRef]
- Lv, M.; Chen, L.; Shen, Y.; Chen, G. Measuring Cell-ID Trajectory Similarity for Mobile Phone Route Classification. Knowl.-Based Syst. 2015, 89, 181–191. [Google Scholar] [CrossRef]
- Lin, K.; Chen, M.; Deng, J.; Hassan, M.M.; Fortino, G. Enhanced Fingerprinting and Trajectory Prediction for IoT Localization in Smart Buildings. IEEE Trans. Autom. Sci. Eng. 2016, 13, 1294–1307. [Google Scholar] [CrossRef]
- Li, X.; Zhang, X.; Chen, K.; Feng, S. Measurement and Analysis of Energy Consumption on Android Smartphones. In Proceedings of the IEEE 4th International Conference on Information Science and Technology (ICIST), Shenzhen, China, 26–28 April 2014; pp. 242–245. [Google Scholar] [CrossRef]
- Zhuang, Z.; Kim, K.H.; Singh, J.P. Improving Energy Efficiency of Location Sensing on Smartphones. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services (MobiSys), San Francisco, CA, USA, 15–18 June 2010; ACM: New York, NY, USA, 2010; pp. 315–330. [Google Scholar]
- Liu, H.; Darabi, H.; Banerjee, P.; Liu, J. Survey of Wireless Indoor Positioning Techniques and Systems. IEEE Trans. Syst. Man Cybern. Part C 2007, 37, 1067–1080. [Google Scholar] [CrossRef]
- Chen, M.Y.; Sohn, T.; Chmelev, D.; Haehnel, D.; Hightower, J.; Hughes, J.; LaMarca, A.; Potter, F.; Smith, I.; Varshavsky, A. Practical Metropolitan-scale Positioning for GSM Phones. In Proceedings of the 8th International Conference on Ubiquitous Computing (UbiComp), Orange County, CA, USA, 17–21 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 225–242. [Google Scholar]
- Benikovsky, J.; Brida, P.; Machaj, J. Localization in Real GSM Network with Fingerprinting Utilization. In Proceedings of the 2nd International Conference on Mobile Lightweight Wireless Systems (MOBILIGHT), Barcelona, Spain, 10–12 May 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 699–709. [Google Scholar]
- Paek, J.; Kim, K.H.; Singh, J.P.; Govindan, R. Energy-efficient Positioning for Smartphones using Cell-ID Sequence Matching. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services (MobiSys), Bethesda, MD, USA, 28 June–1 July 2011; ACM: New York, NY, USA,, 2011; pp. 293–306. [Google Scholar]
- Ibrahim, M.; Youssef, M. CellSense: A Probabilistic RSSI-Based GSM Positioning System. In Proceedings of the IEEE 2010 Global Communications Conference (GLOBECOM), Miami, FL, USA, 6–10 December 2010; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Varshavsky, A.; Liu, H.; Chen, Y.; Gruteser, M. Accuracy Characterization of Cell Tower Localization. In Proceedings of the 12th International Conference on Ubiquitous Computing (UbiComp 2010), Copenhagen, Denmark, 26–29 September 2010; Bardram, J.E., Langheinrich, M., Truong, K.N., Nixon, P., Eds.; ACM: New York, NY, USA, 2010. ACM International Conference Proceeding Series. pp. 223–226. [Google Scholar] [CrossRef]
- Yadav, K.; Naik, V.; Singh, A.; Singh, P.; Chandra, U. Low Energy and Sufficiently Accurate Localization for Non-smartphones. In Proceedings of the 13th IEEE International Conference on Mobile Data Management, Bengaluru, India, 23–26 July 2012; pp. 212–221. [Google Scholar]
- Viel, A.; Gallo, P.; Montanari, A.; Gubiani, D.; Dalla Torre, A.; Pittino, F.; Marshall, C. Dealing with Network Changes in Cellular Fingerprint Positioning Systems. In Proceedings of the IEEE 2017 International Conference on Localization and GNSS (ICL-GNSS), Tampere, Finland, 7–9 June 2017; pp. 1–6. [Google Scholar]
- Eli-Chukwu, N.C.; Aloh, J.; Ezeagwu, C.O. A Systematic Review of Artificial Intelligence Applications in Cellular Networks. Eng. Technol. Appl. Sci. Res. 2019, 9, 4504–4510. [Google Scholar] [CrossRef]
- Laiho, J.; Raivio, K.; Lehtimaki, P.; Hatonen, K.; Simula, O. Advanced Analysis Methods for 3G Cellular Networks. IEEE Trans. Wirel. Commun. 2005, 4, 930–942. [Google Scholar] [CrossRef]
- Di Francesco, P.; Malandrino, F.; DaSilva, L.A. Assembling and Using a Cellular Dataset for Mobile Network Analysis and Planning. IEEE Trans. Big Data 2017, 4, 614–620. [Google Scholar] [CrossRef]
- Frota, R.A.; Barreto, G.A.; Mota, J. Anomaly Detection in Mobile Communication Networks using the Self-organizing Map. J. Intell. Fuzzy Syst. 2007, 18, 493–500. [Google Scholar]
- Kumpulainen, P.; Hätönen, K. Local Anomaly Detection for Mobile Network Monitoring. Inf. Sci. 2008, 178, 3840–3859. [Google Scholar] [CrossRef]
- Sukkhawatchani, P.; Usaha, W. Performance Evaluation of Anomaly Detection in Cellular Core Networks using Self-organizing Map. In Proceedings of the IEEE 5th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTICON), Krabi, Thailand, 14–17 May 2008; Volume 1, pp. 361–364. [Google Scholar]
- Szilágyi, P.; Nováczki, S. An Automatic Detection and Diagnosis Framework for Mobile Communication Systems. IEEE Trans. Netw. Serv. Manag. 2012, 9, 184–197. [Google Scholar] [CrossRef]
- Chernogorov, F.; Chernov, S.; Brigatti, K.; Ristaniemi, T. Sequence-based Detection of Sleeping Cell Failures in Mobile Networks. Wirel. Netw. 2016, 22, 2029–2048. [Google Scholar] [CrossRef] [Green Version]
- Slimen, Y.B.; Allio, S.; Jacques, J. Anomaly Prevision in Radio Access Networks using Functional Data Analysis. In Proceedings of the 2017 IEEE Global Communications Conference(GLOBECOM), Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Muñoz, P.; Barco, R.; Cruz, E.; Gómez-Andrades, A.; Khatib, E.J.; Faour, N. A Method for Identifying Faulty Cells using a Classification Tree-based UE Diagnosis in LTE. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 130. [Google Scholar] [CrossRef]
- Qin, X.; Tang, S.; Chen, X.; Miao, D.; Wei, G. SQoE KQIs Anomaly Detection in Cellular Networks: Fast Online Detection Framework with Hourglass Clustering. China Commun. 2018, 15, 25–37. [Google Scholar] [CrossRef]
- Brunello, A.; Montanari, A.; Saccomanno, N. A Framework for Indoor Positioning Including Building Topology. IEEE Access 2022, 10, 114959–114974. [Google Scholar] [CrossRef]
- Sauter, M. From GSM to LTE: An Introduction to Mobile Networks and Mobile Broadband; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Hoy, J. Forensic Radio Survey for Cell Site Analysis; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Pahlavan, K.; Krishnaumurty, P. Principles of Wireless Access and Localization; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Gallo, P.; Gubiani, D.; Montanari, A.; Saccomanno, N. A New Similarity Measure for Low-sampling Cellular Fingerprint Trajectories. In Proceedings of the 21st IEEE International Conference on Mobile Data Management (MDM), Versailles, France, 30 June–3 July 2020; pp. 9–18. [Google Scholar]
- European Telecommunications Standards Institute. Technical Specification—Network Architecture, TS 23.002 v11.6.0; Technical Report, 3GPP; European Telecommunications Standards Institute: Sophia Antipolis, France, 2013. [Google Scholar]
- Gubiani, D.; Montanari, A. ChronoGeoGraph: An Expressive Spatio-Temporal Conceptual Model. In Proceedings of the 15th Italian Symposium on Advanced Database Systems (SEBD), Fasano, Italy, 17–20 June 2007; pp. 160–171. [Google Scholar]
- Gubiani, D.; Montanari, A. A Tool for the Visual Synthesis and the Logical Translation of Spatio-Temporal Conceptual Schemas. In Proceedings of the 15th Italian Symposium on Advanced Database Systems (SEBD), Fasano, Italy, 17–20 June 2007; pp. 495–498. [Google Scholar]
- Viel, A. Methods, Techniques, and Algorithms for the Management of Cellular Fingerprints in Positioning Systems. Ph.D. Thesis, Università degli Dtudi di Udine, Udine, Italy, 2018. [Google Scholar]
- Elmasri, R.; Navathe, S. Fundamentals of Database Systems, 7th ed.; Pearson: London, UK, 2016. [Google Scholar]
- Shad, S.A.; Chen, E. Precise Location Acquisition of Mobility Data Using Cell-ID. arXiv 2012, arXiv:1206.6099. [Google Scholar] [CrossRef]
- Laitinen, H.; Lahteenmaki, J.; Nordstrom, T. Database correlation method for GSM Location. In Proceedings of the IEEE VTS 53rd Vehicular Technology Conference, Rhodes, Greece, 6–9 May 2001; Volume 4, pp. 2504–2508. [Google Scholar] [CrossRef]
- Dvorsky, M.; Michalek, L.; Moravec, P.; Sebesta, R. Improved GSM-based localization by incorporating secondary network characteristics. In Proceedings of the International Conference on Research in Networking: NETWORKING 2012 Workshops, Fukuoka-shi, Japan, 21–25 May 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 139–144. [Google Scholar]
- Zhou, Y.; Zhao, Z.; Louët, Y.; Ying, Q.; Li, R.; Zhou, X.; Chen, X.; Zhang, H. Large-Scale Spatial Distribution Identification of Base Stations in Cellular Networks. IEEE Access 2015, 3, 2987–2999. [Google Scholar] [CrossRef]
- Ricciato, F.; Widhalm, P.; Craglia, M.; Pantisano, F. Estimating Population Density Distribution from Network-Based Mobile Phone Data; Publications Office of the European Union: Luxembourg, 2015. [Google Scholar] [CrossRef]
- Johnson, C. Radio Access Networks for UMTS: Principles and Practice; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Kaaranen, H.; Ahtianinen, A.; Laitinen, L.; Naghian, S.; Niemi, V. UMTS Networks: Architecture, Mobility and Services, 2nd ed.; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- ElNashar, A.; El-saidny, M.; Sherif, M. Design, Deployment and Performance of 4G-LTE Networks: A Practical Approach; Wiley: Hoboken, NJ, USA, 2014. [Google Scholar]




















| Acronym | Technology | Description | Acronym | Technology | Description |
|---|---|---|---|---|---|
| ARFCN | GSM | Absolute Radio Frequency Channel Number | PCI | 4G | Physical Cell Identifier |
| BCC | GSM | Base station Color Code | PCU | GSM | Packet Control Unit |
| BSC | GSM | Base Station Controller | PLMN | All | Public Land Mobile Network |
| BSIC | GSM | Base Station Id Code | PSC | UMTS | Primary Scrambling Code |
| BTS | GSM | Base Transceiver System | RA | GSM, UMTS | Routing Area |
| CGI | GSM, UMTS | Cell Global Identifier | RAC | GSM | Routing Area Code |
| CI | GSM, UMTS | Cell Identifier | RAI | GSM | Routing Area Identifier |
| EARFCN | LTE | Evolved ARFCN | RNC | UMTS | Radio Network Controller |
| ECI | LTE | E-UTRAN Cell Identifier | RSCP | UMTS | Received Signal Code Power |
| LA | GSM, UMTS | Location Area | RSRP | LTE | Reference Signal Received Power |
| LAC | GSM, UMTS | Location Area Code | RXLEV | GSM | Receiving Level |
| LAI | GSM, UMTS | Local Area Identifier | TA | LTE | Tracking Area |
| MCC | All | Mobile Country Code | TAC | LTE | Tracking Area Code |
| MNC | All | Mobile Network Code | TAI | LTE | Tracking Area Identifier |
| NCC | GSM | Network Control Code | UARCFN | UMTS | UTRA ARFCN |
| GSM | UMTS | LTE | |
|---|---|---|---|
| MCC | 0–999 (3 digits) | ||
| MNC | 0–999 (3 digits) | ||
| LAC/TAC | 0–65,535 | ||
| CI/eCI | 0–65,535 | 0–268,435,455 | |
| RNC | - | 0–4095 | - |
| (U/E)ARFCN | 0–1023 | 0–16,383 | 0–65,535 |
| BSIC/PSC/PCI | 0–63 | 0–511 | 0–503 |
| TA | 0–219 | - | 0–1282 |
| Dataset | Tech. | Observations | Valid Observations | % | Neighbors | Valid Neighbors | % |
|---|---|---|---|---|---|---|---|
| 1 | GSM | 26,896,809 | 26,840,087 | 99.79 | 0 | 0 | 0 |
| 1 | UMTS | 6,195,903 | 6,177,024 | 99.70 | 0 | 0 | 0 |
| 1 | LTE | 9,859,665 | 9,848,455 | 99.89 | 0 | 0 | 0 |
| 2 | GSM | 2,522,483 | 2,258,522 | 89.54 | 9,476,328 | 6,768,116 | 71.42 |
| 2 | UMTS | 62,318 | 55,723 | 89.42 | 431,416 | 102,568 | 23.77 |
| 1 | 42,952,377 | 42,865,566 | 99.80 | 0 | 0 | 0 | |
| 2 | 2,584,801 | 2,314,245 | 89.53 | 9,907,744 | 6,870,684 | 69.34 | |
| 1&2 | 45,537,178 | 45,179,811 | 99.21 | 9,907,744 | 6,870,684 | 69.34 |
| CELL | REGISTRATION AREA | SubPLMN | PLMN | |
|---|---|---|---|---|
| GSM | 1,553,523 (1,553,523) | 45,970 (35,157) | 811 (743) | |
| UMTS | 2,001,145 (693,622) | 43,147 (29,139) | 794 (746) | 993 (925) |
| LTE | 2,240,032 (864,673) | 48,098 (40,787) | 607 (559) | |
| 5,794,700 (3,111,818) | 137,215 (105,083) | 2212 (2048) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brunello, A.; Dalla Torre, A.; Gallo, P.; Gubiani, D.; Montanari, A.; Saccomanno, N. Crowdsourced Reconstruction of Cellular Networks to Serve Outdoor Positioning: Modeling, Validation and Analysis. Sensors 2023, 23, 352. https://doi.org/10.3390/s23010352
Brunello A, Dalla Torre A, Gallo P, Gubiani D, Montanari A, Saccomanno N. Crowdsourced Reconstruction of Cellular Networks to Serve Outdoor Positioning: Modeling, Validation and Analysis. Sensors. 2023; 23(1):352. https://doi.org/10.3390/s23010352
Chicago/Turabian StyleBrunello, Andrea, Andrea Dalla Torre, Paolo Gallo, Donatella Gubiani, Angelo Montanari, and Nicola Saccomanno. 2023. "Crowdsourced Reconstruction of Cellular Networks to Serve Outdoor Positioning: Modeling, Validation and Analysis" Sensors 23, no. 1: 352. https://doi.org/10.3390/s23010352