

Image Generation from Text Using StackGAN with Improved Conditional Consistency Regularization
Abstract
:1. Introduction
2. Related Work
2.1. Generative Adversarial Networks
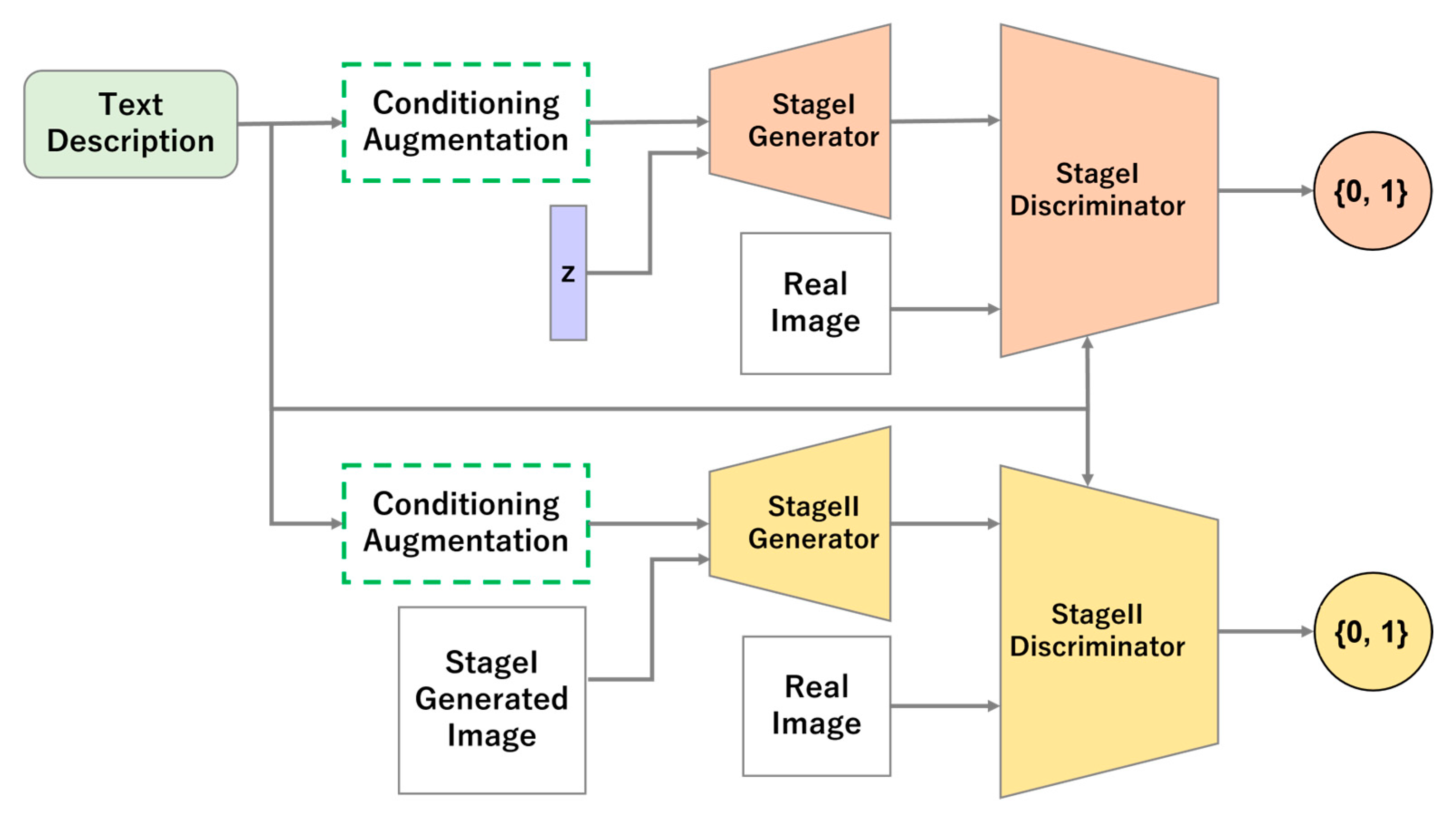
2.2. Stacked Generative Adversarial Networks
2.2.1. Conditioning Augmentation
2.2.2. Stage I
2.2.3. Stage II
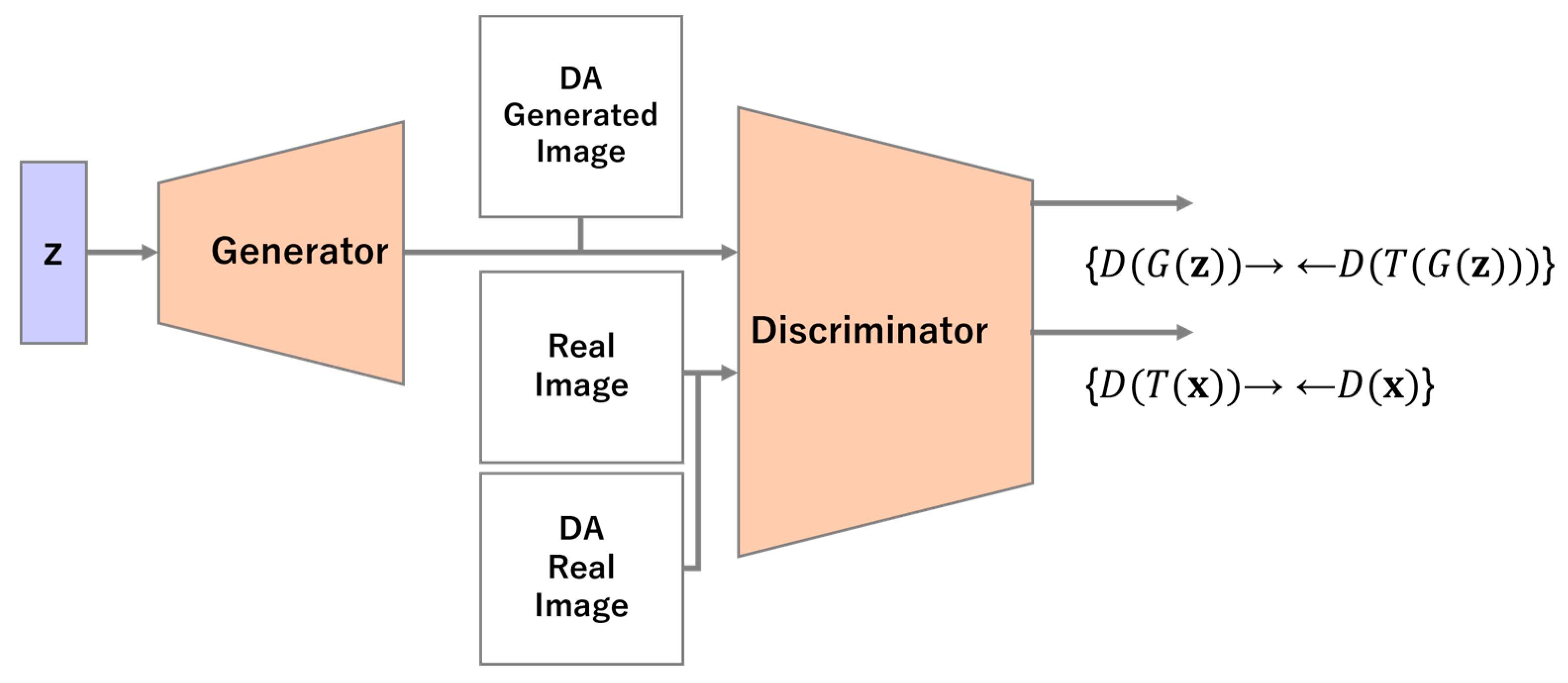
2.3. Improved Consistency Regularization
2.3.1. Balanced Consistency Regularization
2.3.2. Latent Consistency Regularization
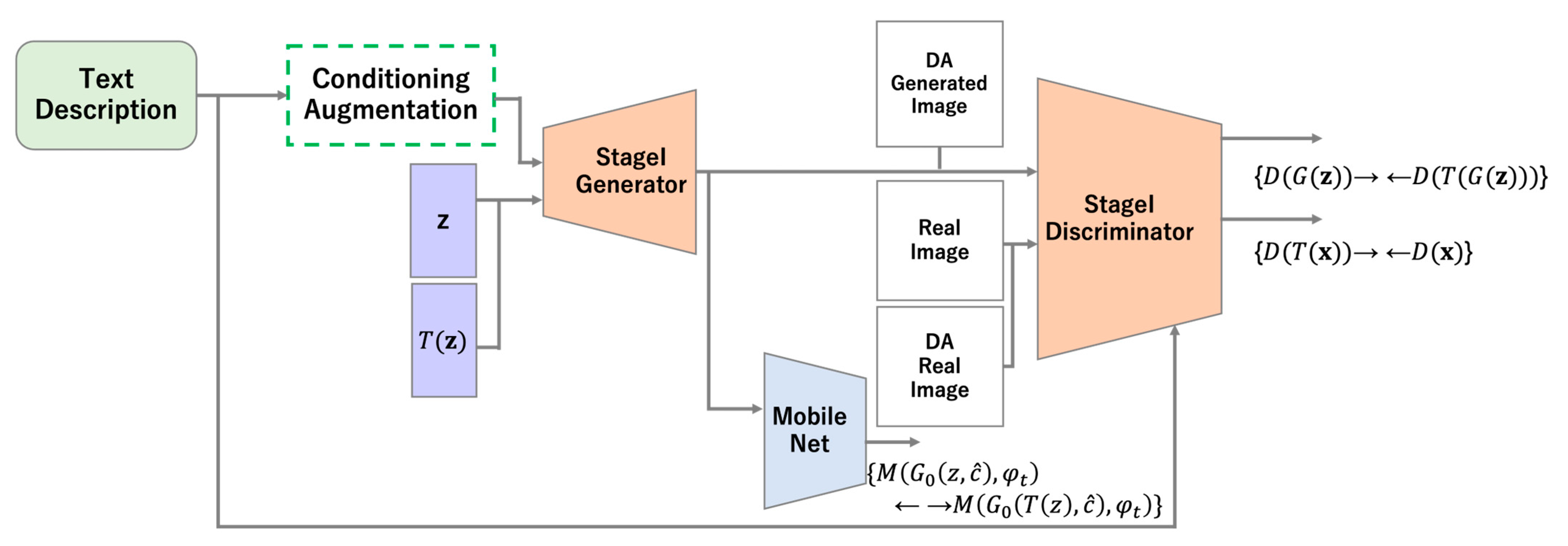
3. StackGAN with ICCR
3.1. Stage I
3.2. Stage II
4. Experiments
4.1. Experimental Setup
4.1.1. Data Set
- This bird has a dark brown crown, a white superciliary, and a spotted back with spotted tail feathers.
4.1.2. Network Setup
4.2. Evaluation Metrics
4.3. Experimental Results
4.3.1. Comparison of Generated Images
- This black bird has no crest, a medium-pointed bill, and a short tail.
- This is a white bird with black wings and a small beak.
- This small bird has a white belly and breast, and is mostly speckled otherwise.
4.3.2. Incidence of Mode Collapse
4.3.3. Comparison of Inception Score
4.3.4. Comparison by Questionnaire Survey
5. Discussion
5.1. Conclusions
5.2. Recommendation
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations, Banff, AL, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Curran Associates, Inc.: Red Hook, NY, USA, 2014. [Google Scholar]
- DALL-E 2. Available online: https://openai.com/dall-e-2/ (accessed on 17 December 2022).
- Stable Diffusion Online. Available online: https://stablediffusionweb.com/ (accessed on 17 December 2022).
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhao, Z.; Singh, S.; Lee, H.; Zhang, Z.; Odena, A.; Zhang, H. Improved Consistency Regularization for GANs. arXiv 2020, arXiv:2002.04724. [Google Scholar] [CrossRef]
- Tominaga, R.; Seo, M. Image Generation from Text using StackGAN with Consistency Regularization. In Proceedings of the 19th International Conference on Distributed Computing and Artificial Intelligence, L’Aquila, Italy, 13–15 July 2022. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of the International Conference on Machine Learning PMLR, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Ho, J.; Ajay, J.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Advances in Neural Information Processing Systems 33; Curran Associates, Inc.: Red Hook, NY, USA, 2020; pp. 6840–6851. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Karras, T. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Advances in Neural Information Processing Systems 29; Curran Associates, Inc.: Red Hook, NY, USA, 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Inception Score |
|---|---|
| StackGAN | 4.75 ± 0.16 |
| StackGAN with ICR | 5.30 ± 0.15 |
| StackGAN with ICCR | 5.51 ± 0.05 |
| AttnGAN | 5.32 ± 0.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tominaga, R.; Seo, M. Image Generation from Text Using StackGAN with Improved Conditional Consistency Regularization. Sensors 2023, 23, 249. https://doi.org/10.3390/s23010249
Tominaga R, Seo M. Image Generation from Text Using StackGAN with Improved Conditional Consistency Regularization. Sensors. 2023; 23(1):249. https://doi.org/10.3390/s23010249
Chicago/Turabian StyleTominaga, Rihito, and Masataka Seo. 2023. "Image Generation from Text Using StackGAN with Improved Conditional Consistency Regularization" Sensors 23, no. 1: 249. https://doi.org/10.3390/s23010249