1. Introduction
Reliable 3D object detection is the primary step to ensure the proper working of autonomous driving systems. Current autonomous driving systems commonly use camera and LiDAR for 3D object detection in order to get more accurate detection results and more applicable scenarios. The camera can output high-resolution pictures, providing rich color and texture information, but it is not easy to extract the spatial position of the object. LiDAR can provide accurate spatial point cloud information, therefore most 3D object detection algorithms [
1,
2,
3,
4,
5] are based on LiDAR and achieve better detection performance. However, both sensors are susceptible to weather noise: the camera is susceptible to image texture noise and the LiDAR is susceptible to spatial point coordinate noise [
6,
7,
8,
9]. This paper focuses on rainy scenarios, as it is the most common dynamic challenging weather condition that effects vision sensors. These effects can directly blur object colors and contours in images, and produce multiple reflections to affect the observability of spatial boundaries in point clouds, which seriously degrades the performance of the object detector. Therefore, effectively fusing the information provided by both sensors is an important approach to improve the robustness of environment perception. In this paper, we propose a camera and LiDAR fusion 3D object detection algorithm based on point-guided sampling of point cloud spatial features and image semantic features, which shows significant performance improvement in rain noise datasets.
In recent years, there are some studies on 3D object detection based on camera and LiDAR fusion, which can be classified into serial type [
10,
11,
12,
13,
14,
15,
16] and parallel type [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38] according to the stage of fusion. The serial type method is represented by F-PointNet [
13] which usually takes the image of the camera as input first and uses image object detection or semantic segmentation algorithm to get the spatial location of the object, then projects it to the LiDAR point cloud to extract the point cloud of the frustum region around the object, and finally uses the normal point cloud 3D object detection algorithm to get 3D bounding boxes. F-PointPillars [
10] replaced the point cloud detection network with PointPillars on this basis and improved the detection speed. F-ConvNet [
14] encoded the grouping within the frustum region and achieved better detection accuracy. This type of method can effectively reduce the number of point clouds and improve the computational efficiency, but requires high image detection performance of the front. The parallel type method, on the other hand, starts with MV3D [
30], which extracts the image features of the LiDAR point cloud and camera separately, and then fuses them at different stages, and finally obtains the 3D object detection results through the fully connected layer. Another approach of parallel type methods is to introduce the correspondence between spatial points and pixel points into the feature fusion, which can improve the feature correlation. Both MVP [
31] and EPNet [
20] take advantage of this and achieve better detection performance. Most of the subsequent parallel type methods use this fusion method, which requires the establishment of a projection relationship between spatial and pixel points by sensor calibration, and then fusing the point or voxel features with the image features of the corresponding pixel points. However, since the point cloud is sparse while the image has higher pixel point density, it will cause the problems of resolution mismatch and uneven sampling of image features. Therefore, this paper proposes a P-FPS algorithm to project the point cloud onto the image plane and then downsample the point cloud by farthest point sampling (FPS). This method can improve the sampling rate of image features for close objects.
Attention-based methods [
39] can aggregate information from different feature spaces, and DETR [
40] introduced self-attention into the field of image-based 2D object detection. Some studies [
41,
42,
43] since then have attempted to apply attention mechanisms to image-based perception, and others [
44,
45,
46,
47] have used attention mechanisms in point cloud-based applications. For image and point cloud feature fusion, the heterogeneity of the two sensors can lead to the features obtained by the feature extraction network not to be in the same feature space. In order to enable the point cloud features to fuse the most associated image features, an MFA module is proposed in this paper. This module allows point cloud features to be adaptively fused with image features from different feature spaces.
The contributions of this paper are as follows:
Aiming at the mismatch resolution between point cloud and image, a point-guided 3D object detection algorithm based on point cloud and image fusion is proposed. The algorithm is based on the point-guided strategy of PV-RCNN, which fuses the multi-stage features of two sensors and enriches the raw point cloud features. Compared with other 3D object detection algorithms, this algorithm achieves significant robustness when point clouds and images contain rain noise, and can utilize image and point cloud information more sufficiently.
An MFA module is proposed for the problem of fused information interference caused by different feature spaces of images and point clouds. This module uses an attention mechanism to calculate the attention weights of multiple image features and point cloud features corresponding to each point. Based on the correlation between point cloud features and spatial features, different image features are fused adaptively.
To solve the problem of insufficient image features of close objects extracted from point clouds obtained by FPS, a P-FPS algorithm is proposed. By projecting the LiDAR point cloud onto the image plane before implementing FPS, uniform sampling of the point cloud in the image plane is achieved and the image feature sampling rate of the object is improved.
The remainder of this paper is as follows: In
Section 2, the related background research work is discussed. The proposed algorithmic framework and key modules are presented in detail in
Section 3.
Section 4 describes the experimental setup and experimental results. Finally,
Section 5 presents an ablation study of the method proposed in this paper.
2. Related Work
Image-driven fusion. Currently, camera-based 2D object detection has been able to achieve an average accuracy of over 90% in publicly available datasets. However, in 3D object detection, better results can be achieved by using LiDAR. Some studies have attempted to utilize the advantage of both sensors and used a serial form of 2D detection followed by 3D detection. Qi et al. [
13] proposed F-PointNets for RGB-D data, and used Fast R-CNN to generate 2D bounding boxes and delineate a frustum region in 3D space, and then performed 3D detection of point clouds in this region based on PointNet. This approach reduces the computational requirements for point cloud search on the one hand, and reduces the interference of background point clouds on detection on the other hand. However, the frustum region obtained by this method will still contain background points behind the object; Wang et al. [
14] made further improvements to address this problem by using sliding regions for point cloud feature extraction separately. To solve the heterogeneity problem in camera-LiDAR fusion, some works inspired by Pseudo-LiDAR [
48] fuse the pseudo point cloud generated from the camera with the point cloud acquired by LiDAR. Pseudo-LiDAR++ [
49], based on Pseudo-LiDAR [
48], uses the binocular camera disparity estimation principle to generate pseudo point clouds and improve the quality of pseudo point clouds by matching them with LiDAR point clouds through K-Nearest Neighbor (KNN).
Feature fusion. Unlike the image-driven approach, MV3D [
30] and AVOD [
26] use the projection map of the LiDAR point cloud and the camera image as inputs, extract image and point cloud features separately, and fuse the proposal regions to obtain the final 3D detection results, avoiding the dependence on the camera detection performance. 3D-CVF [
17] first transforms image features from multiple perspective to the Bird Eye View (BEV) plane, and then selects the fusion degree of the two types features by an adaptive gate fusion network. ContFuse [
50] uses continuous convolution to aggregate images and BEV features at different resolutions based on geometric position relationships. This method uses dense image features to enrich the sparse LiDAR point cloud to enhance the 3D detection performance. These methods ignore the matching between features, although they use multi-layer fusion.
Project-based fusion. Fusing complementary information from point clouds and images would benefit 3D detection. However, the inherent heterogeneous nature between sensors created difficulties in information fusion, and many studies projected point clouds onto the images for data sampling. If these data are processed directly, some problems are encountered: (1) sparse point clouds do not correspond to high-resolution image features one by one, resulting in incomplete data fusion; (2) point cloud data are missing depth or height information after projection. To address these problems, many attempts have been made in recent studies. Zhu et al. [
37] proposed VPFNet, a network that first generates 3D proposal regions from point clouds and divides them into multiple small grids again, with the corner points of each grid as virtual points, and next projects these points onto the image for image feature sampling and point cloud feature extraction, which reduces the computation and compensates the lack of sparse point clouds. Huang et al. [
20] proposed a LI-Fusion module for fusing point cloud and image information at different scales in the feature extraction stage, and then associating the image features to the corresponding point cloud locations, while adding a consistency forcing loss for balancing the impact of classification loss and location loss on the detection results. Wen et al. [
36] combined the fusion framework of MV3D [
30] and AVOD [
26], and proposed to project the height information of the point cloud into the image to obtain RGB-D data, and then fused it with the bird’s-eye view to construct a single-stage detector while using an adaptive attention mechanism in feature extraction. Projection-based fusion methods usually capture image features based on keypoints after FPS downsampling. Due to the affine transformation, the point cloud is no longer uniform in the image plane, and the feature-rich close objects cannot be extracted completely. Therefore, this paper proposes to project the point cloud onto the image plane followed by FPS in order to sample uniform image features. Meanwhile, unlike the concat fusion of previous methods, an MFA module is proposed to make the point cloud adaptively fuse image features with different weights.
3. Framework of Proposed 3D Detection Algorithm
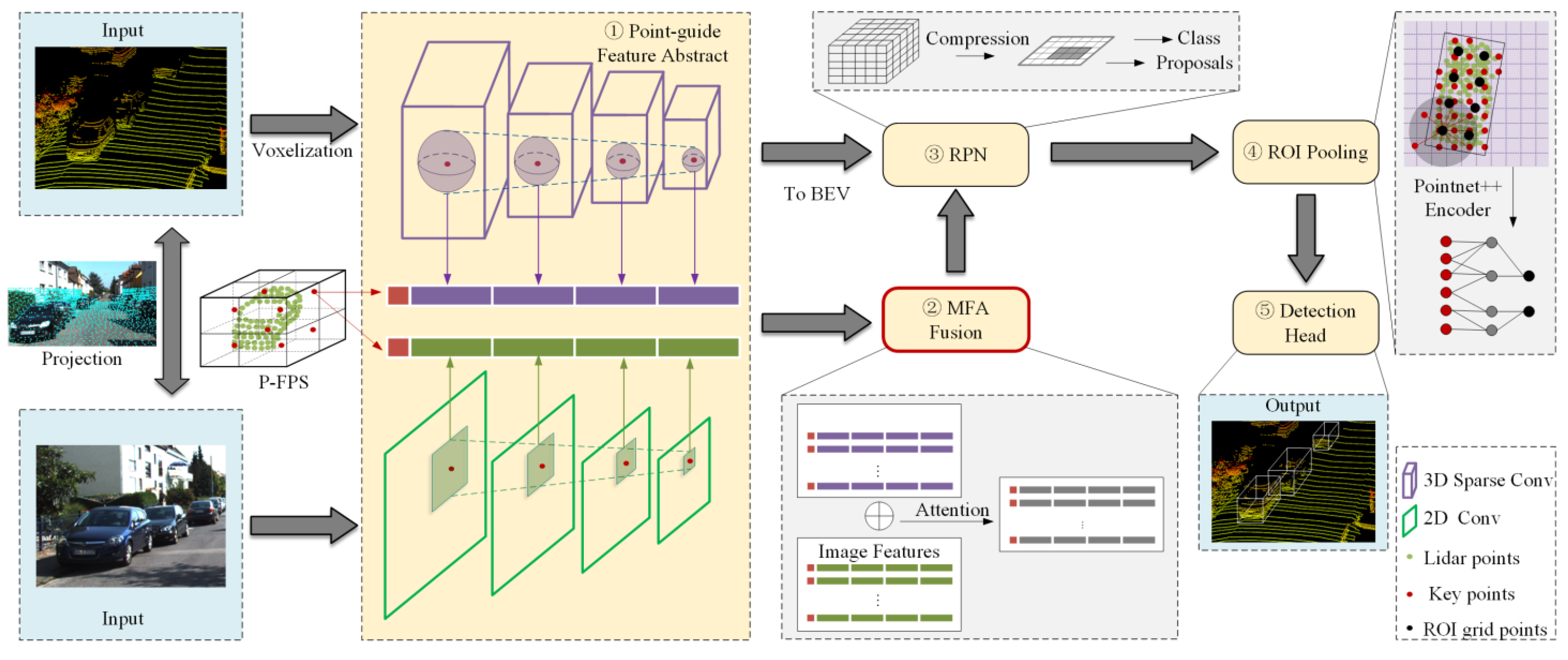
For the above problems, this paper proposes a 3D object detection method that fuses LiDAR and camera. The method can adaptively fuse image and point cloud features based on the attention mechanism to cope with the performance degradation when the point cloud or image contain rain noise. As shown in
Figure 1, the network is based on PV-RCNN [
1], and image features are fused into the raw LiDAR features. When using cameras and LiDAR for 3D object detection, the difference in the spatial location of the two sensors can cause the results to be in different reference coordinate systems. To associate the point cloud and image features, a projection of the point cloud to the image plane is used to map each point to the corresponding pixel location. The projection of the point
of the LiDAR to the pixel point
is expressed as:
where
is the camera focal length,
and
are the length and width of a single pixel at the image plane,
and
are offset of the pixel coordinate system,
is rotation matrix,
is translation matrix,
is the depth of the point to the image plane, K is the camera internal reference matrix, and M is the transformation matrix from the LiDAR coordinate system to the camera coordinate system.
By keypoints guidance, point cloud features and image features of different scales can be merged into the same point at the same time. Due to the heterogeneity of images and point clouds, the two types of features are not in the same feature space. To address this problem, the proposed MFA module can effectively fuse the two types of features to get fused features. Subsequently, the fusion features guided by keypoints are processed by the region proposal network (RPN) module to get ROIs. Finally, ROIs are further reduced by ROI pooling, and the location and class information of the object is obtained by the refinement network.
3.1. P-FPS
Many point-based LiDAR 3D object detection algorithms [
51,
52] downsample the raw point cloud by FPS to get the keypoints to reduce the computational effort. Projection-based fusion algorithms [
20,
53] will project the LiDAR point cloud onto the image and often use this downsampling method to process the raw point cloud. However, FPS uniformly samples point clouds in 3D space, which results in uneven distribution of point clouds when projected onto an image. As shown in
Figure 2, distant objects contain little feature information because they contain relatively few pixels. In contrast, the close object contains more pixels and can provide rich features. The key points obtained by FPS are mostly distributed in the distance. The image features sampled in this way lose considerable detail.
To solve the above problems, a P-FPS is proposed for point cloud sampling. As shown in
Figure 3, suppose there are
M 3D spatial coordinates
in the raw point cloud, which can be projected onto the image plane by Equation (2) to obtain the corresponding 2D pixel coordinates
. In 3D space, the FPS requires the calculation of the 3D Euclidean distance between the coordinates of two points,
and
. Correspondingly, in the image plane, the 2D Euclidean distance
between the pixel coordinates
and
is required to be calculated, which can be expressed as:
where
is the projection transformation relationship from the point cloud to the image plane, which can be obtained from Equation (2). After the image plane is processed by 2D FPS, the close object can contain more points. With the index information of these points, the keypoints in 3D space can be obtained. The specific content of the algorithm is shown in Algorithm 1.
The sampling method above allows closer points to be obtained, but results in a slight reduction of distant points. To balance this loss, the number of points obtained by FPS and 2D-FPS is divided by the following equation:
| Algorithm 1 2D FPS |
|
|
| 1 Suppose t keypoints has been sampled and (t + 1)th keypoint is sampled as follows |
| 2 for to by 1 do |
| 3 for to by 1 do |
| 4 Calculate the distance between point and point : |
| 5 if last minimum dist then |
| 6 dist = |
| 7 end if |
| 8 end for |
| 9 end for |
| 10 Select the point with minimum dist as the keypoint |
| 11 return Keypoints set |
3.2. Point-Guide Feature Abstract
3D Feature Abstraction. The raw point cloud is first divided into many voxels of size d × w × h. The feature vector of each non-empty voxel is encoded as:
where
Point_num is the number of points contained within each voxel and
is the reflection intensity of that point. Then, the 3D sparse convolution of 3 × 3 × 3 is used to obtain spatial features at four different downsampling scales (1×, 2×, 4×, 8×).
2D Feature Abstraction. Image features contain rich texture and color information. In order to be consistent with 3D feature extraction, ResNet-18 [
54] is utilized to extract image features. The network uses a series of 3 × 3 2D convolutional kernels to downsample the feature maps at four different scales. The four scales of feature maps focus on different feature details, and the same downsample scale as the 3D backbone is adopted.
Point Feature Sample. After obtaining T keypoints
by P-FPS, each point will aggregate 3D and 2D features, respectively. For 3D features, each scale feature is first sampled using ball query. Suppose that the kth layer Voxel-wise features are expressed as:
The 3D coordinates of the kth layer are expressed as:
The feature vectors of all voxels within the radius
r are encoded as:
where
denotes the local space features. Subsequently, these voxel features are aggregated to the keypoint
as follows:
where
denotes the random sampling of t voxels features. The feature vectors of all 4 scales are concatenated to the keypoint
as follows:
For 2D features, the keypoints cannot be accurately corresponded to individual pixel points, although they have been projected onto the pixel plane. The reason is that the projection point coordinates are continuous, while the pixel point coordinates are discrete. Therefore, bilinear interpolation is employed to sample the four pixels around the projection point, and this process can be expressed as:
where
B denotes the bilinear interpolation function and
denote the feature vectors of the four neighboring pixel points around the projection point. Finally, as with the 3D features, the 2D features are stitched to the same keypoint
3.3. MFA Fusion
Since DETR [
40] introduced the self-attention transformer [
39] into the field of object detection, many studies [
36,
41,
42,
45] have attempted to use the attention mechanism for 2D or 3D object detection. Most of these approaches focus on spatial attention, and in this paper, we propose an MFA module based on the attention of feature channels. The purpose of this module is to allow point cloud features to adaptively fuse image features based on feature correlations. This module improves the robustness of the detection algorithm when the image or point cloud contain noise.
As shown in
Figure 4, for a keypoint
, the image features
at the
kth layer scale are encoded by two sets of
N 1D convolution kernels to obtain
N Image value
and Image key
, respectively, while the point cloud features
are encoded by 1D convolution kernels to obtain Point query
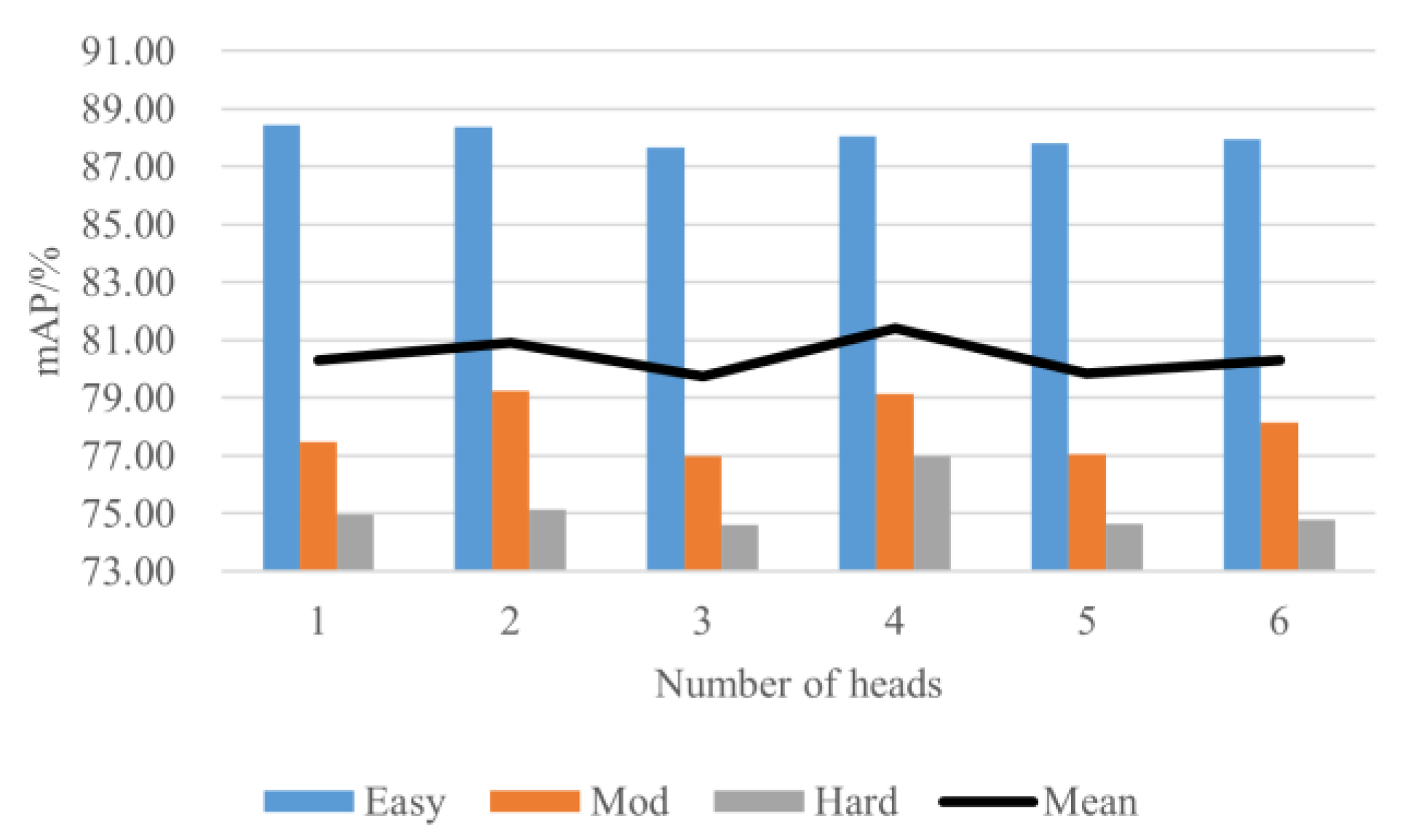
. Each feature point is sampled to obtain a 1D feature vector, therefore a 1D convolution kernel is used to encode the image feature vector and the point cloud feature vector to obtain the same feature space. The vector length of each layer is set to [32,32,64,128] after the 1D convolution kernel encoding.
In the spatial self-attention mechanism of DETR [
40], a positional encoding is added to the feature vector to enable the network to learn positional features. In the MFA module, the feature vectors used for attention calculation come from the same location, thus there is no need to add position encoding. Image key and Point query are used to calculate the feature weights. The correlation vector
and feature weight
are obtained by summation of the dot product, and the formula is as follows:
where
is the dimension of Image key and Point query, which is used as a scale factor to prevent extreme values after the summation of the dot product. Then the softmax function is used to score the
N elements in the correlation vector
to get the feature weight
, which represents the correlation between different image features and point cloud features. Feature weight is weighted and summed with
N Image values
to obtain the final image feature vector, which is summed with Point query
to obtain the final fusion feature vector
.
where
J(∙) denotes the summation of the dot product.
The raw point-cloud feature is aggregated as in Equation (8). For the BEV, we project the keypoint to the 2D bird-view coordinate system, and utilize bilinear interpolation to obtain the features from the bird-view feature. Finally, to enrich the features, each keypoint-guided feature vector is joined with feature vectors representing the raw point cloud and BEV. It can be expressed as:
After downsampling by P-FPS, although more points fall within the object, there are still many background points that do not contribute much to the detection task. Therefore, following the design of PV-RCNN, the predicted keypoint weighting (PKW) module is used to predict the probability of each keypoint being a foreground point. The difference is that the keypoint features processed by PKW contain information from images and point clouds. The process of predicting keypoints can be expressed as:
where
denotes a three-layer MLP network with a sigmoid function to predict foreground confidence between [0, 1].
3.4. ROI Pooling and Detection Head
The RPN structure is the same as PV-RCNN, where many ROIs are predicted based on 3D spatial features. As shown in
Figure 5, the keypoints feature vectors contained within each ROI are aggregated to a fixed 6 × 6 × 6 grid point in order to obtain a more accurate prediction of the bounding boxes. The process is similar to the point feature abstraction process, where the keypoints around the grid points are sampled by using ball queries at different scales. The final ROI contains 216 grid point feature vectors within each ROI, and then the class and 3D bounding boxes of the object are predicted by two layers of MLP.
4. Experiments
4.1. Datasets
KITTI [
55] is a common benchmark for outdoor 3D object detection. There are 7481 training samples and 7518 test samples, where the training samples are generally divided into the train split (3712 samples) and the val split (3769 samples). In the 3D object detection task, Car, Pedestrian and Cyclist were evaluated separately. KITTI presents three object detection tasks (Easy, Moderate and Hard) of different difficulty according to the size of the object, the degree of occlusion and the degree of truncation. In the experimental results, we adopted “Easy”, “Mod.” and “Hard” to represent these three tasks.
Most of the KITTI data are collected in good weather, however there are many real scenarios with bad weather (e.g., rain) that can affect the accuracy of LiDAR and camera outputs. To simulate the rainy scenarios, two noises are added separately. The camera is often influenced by rain which causes blurring and occlusion of the output image, resulting in the loss of detailed features of the object [
7]. In this paper, this blurring is simulated using Gaussian blurring as follows:
where
u,
v denote the local coordinates of the Gaussian kernel and
denote the variance in both directions. The Gaussian kernel is a two-dimensional normally distributed matrix containing a set of pixel weights that can smooth the pixels inside the Gaussian kernel. For the occlusion effect of raindrops, we randomly generated different raindrop traces through image processing.
LiDAR is prone to noise in rainy environments [
56,
57], because raindrops can cause multiple reflections to LiDAR. The result of this is that the 3D contour boundary of the object is less obvious. Random noise is added to the 3D coordinates of the raw point cloud to simulate this effect.
Figure 6 shows the effect after adding the noise. It can be observed that the vehicle textures in the images become blurred and the vehicle contours in the point cloud are no longer regular. These changes increase the difficulty of object detection because the object specific features are weakened.
4.2. Training and Inference Details
Since the camera FOV is in front of the vehicle, this paper takes the camera FOV as the boundary and removes the point clouds beyond the boundary. Meanwhile, a rectangular area is set to filter the remaining point clouds. The range of this region is (0 m < x < 70.4 m, −40 m < y < 40 m, −1 m < z < 3 m), which is divided into many voxels of size (0.05 m, 0.05 m, 0.1 m).
For training, both the 2D backbone and 3D backbone use pretrained parameters directly, and the parameters are not updated. In addition, since there is a fixed transformation relationship between LiDAR and camera, and the fusion data augmentation scheme is not mature, conventional data augmentation methods are not used in this paper. The network is built using OpenPCDet and trained on a GTX3090 with batchsize 4, epoch 80, and learning rate 0.01.
4.3. Results on the KITTI Dataset with Rain Noise
The mainstream object detection algorithms are tested on the generated KITTI with rain noise.
Table 1 shows the test results of each algorithm in a KITTI validation split with rain noise. For better evaluation, all algorithms are retrained on data with rain noise, and the same training method is used. As can be seen in
Table 1, the proposed algorithm shows the best results in all three detection tasks of Car, Pedestrian and Cyclist. Compared with the baseline algorithm PV-RCNN in this paper, the mAP is improved by 5.86%, 21.15% and 41.17% in the three categories of the 3D detection task, respectively. Meanwhile,
Table 2 demonstrated that the proposed algorithm is still the optimal result in the BEV task. Compared with PV-RCNN, the mAPs of the three categories are improved by 3.76%, 16.80% and 40.00%, respectively. In the detection tasks of Pedestrian and Cyclist, the algorithm in this paper shows a relatively large lead. The reason is that Pedestrian and Cyclist contain few point clouds and their features are more affected by rain noise. It causes difficulties in point cloud-based algorithms in both training and detection, and the proposed algorithm can aggregate image features as a complement to enrich the overall feature information.
Figure 7 shows the comparison of PR curves for different detection algorithms on KITTI with rain noise. Recall is the proportion of the number of objects that are correctly detected among all ground truths. The precision in the
Figure 7 indicates the percentage of detected objects that are correctly detected at different recall rates. From the figure, it can be observed that the proposed algorithm achieves the highest accuracy rate at the recall rate of [1–0.6]. The high accuracy is also maintained at the recall rate of [0.6–0].
In order to compare the robustness of the algorithms to the effects of rain noise, pre-trained models are directly used for testing on noisy datasets. The proposed algorithm is trained on the raw KITTI without rain noise. As can be seen in
Table 3, the proposed algorithm still achieves the best results even without training on noisy data.
4.4. Results on the NUSCENES Dataset
To validate the effectiveness of the proposed algorithm, it was evaluated and compared on the NUSCENES dataset. The dataset uses six cameras, one 32-line LiDAR, five millimeter wave radars, IMU and GPS with 1000 different urban scenes, including scenes with visual impact such as night and rain. As shown in
Table 4, the proposed algorithm in the NUSCENES dataset achieves a competitive performance. The proposed algorithm achieves the highest results in the mAP metric. The rainy and night scenes contained in the dataset affect the camera more, and the proposed algorithm adaptively learns the association of image features with point cloud features in different feature spaces, thus achieving a high robustness.
4.5. Results on Physical Test Platform
As shown in
Figure 8, a physical test platform was built to verify the algorithm proposed in this paper. The platform is installed with a 32-line LiDAR, an IMU, a monocular camera, and a 77 GHz millimeter wave radar. Data from all sensors were collected by VECTOR VN5640 and aligned to the same timestamp with same time source. The proposed algorithm was tested on LiDAR and camera data, which were converted to the format of the KITTI dataset.
As shown in
Figure 9, a slice of data collected by the actual physical test platform shows that the proposed algorithm obtains better 3D detection performance. Our algorithm and PV-RCNN are trained on KITTI data with noise, while noise is added on the actual test data. The results in the first row are output by the camera, the results in the second row are obtained by the proposed algorithm, and the results in the third row are obtained by the PV-RCNN. It can be observed that the proposed algorithm is able to detect more objects. It is important to note that testing the algorithm on the collected data is a cross-domain problem. This is due to the fact that the KITTI sensor models and scenarios are not the same as the collected data, and random noise simulating the effects of weather is added during the testing. The proposed algorithm incorporates information from different stage features and different feature spaces to effectively alleviate this problem.
6. Conclusions
In this paper, a new camera and LiDAR-based 3D object detection algorithm is proposed, which is based on point-guided sampling of point cloud features and image features. The multi-head attention mechanism is introduced into the feature fusion task, and the proposed MFA mechanism is used to realize the adaptive fusion of point cloud features and image features. A projection-based sampling method, P-FPS, is proposed, which can significantly improve the sampling rate of image features and obtains more abundant image information to the fused features. In some scenes, the proposed F-FPS can extract about three times the number of effective feature points, compared with traditional FPS. In order to simulate the scene where the sensor contain rain noise, the KITTI dataset with rain noise is established. The proposed method shows better detection performance and robustness when tested on KITTI and NUSCENES datasets. Compared with the baseline algorithm PV-RCNN in this paper, the mAP is improved by 5.86%, 21.15% and 41.17% in the three categories of the 3D detection task, respectively. Finally, the algorithm is tested on the physical test platform, which further verifies the effectiveness of the algorithm. In future work, more real extreme weather data will be collected, and weather simulation tests in virtual environments will be used to test the robustness of the algorithm. In addition, the domain adaptation problem caused by the different distributions of the training dataset and the testing dataset will also be studied to improve the generalization of the feature extraction network.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}