
An Anomaly Intrusion Detection for High-Density Internet of Things Wireless Communication Network Based Deep Learning Algorithms

 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Related Work and Literature Review
- It developed a deep learning-based IDS architecture for anomaly detection by conducting asynchronous security scans on a variety of IoT devices and evaluating the traffic patterns on those devices. The deep learning approach that was proposed can be used to give Internet-of-Things devices the ability to adapt to the dynamic and ad hoc environments in which they operate. After that, the suggested model is subjected to a series of tests to determine whether or not it is accurate and whether or not it is ready for deployment. It offered us outstanding findings which guarantee that the model will be superior to the traditional alternatives that are already in place. We were able to keep our model lightweight while also improving its accuracy, precision, and f-score.
- For the anomaly-based IDS, a second DL model based on a Convolutional Neural Network (CNN) and long-short term memory (LSTM [47]) combination was developed. This second structure was trained and evaluated using various measures.
- The performance of the ANN will be shown to be a technique that is more practical than DNN (CNN plus LSTM combination) for the purpose of IDS when using UNSW-NB15-dataset than others.
3. Proposed Models
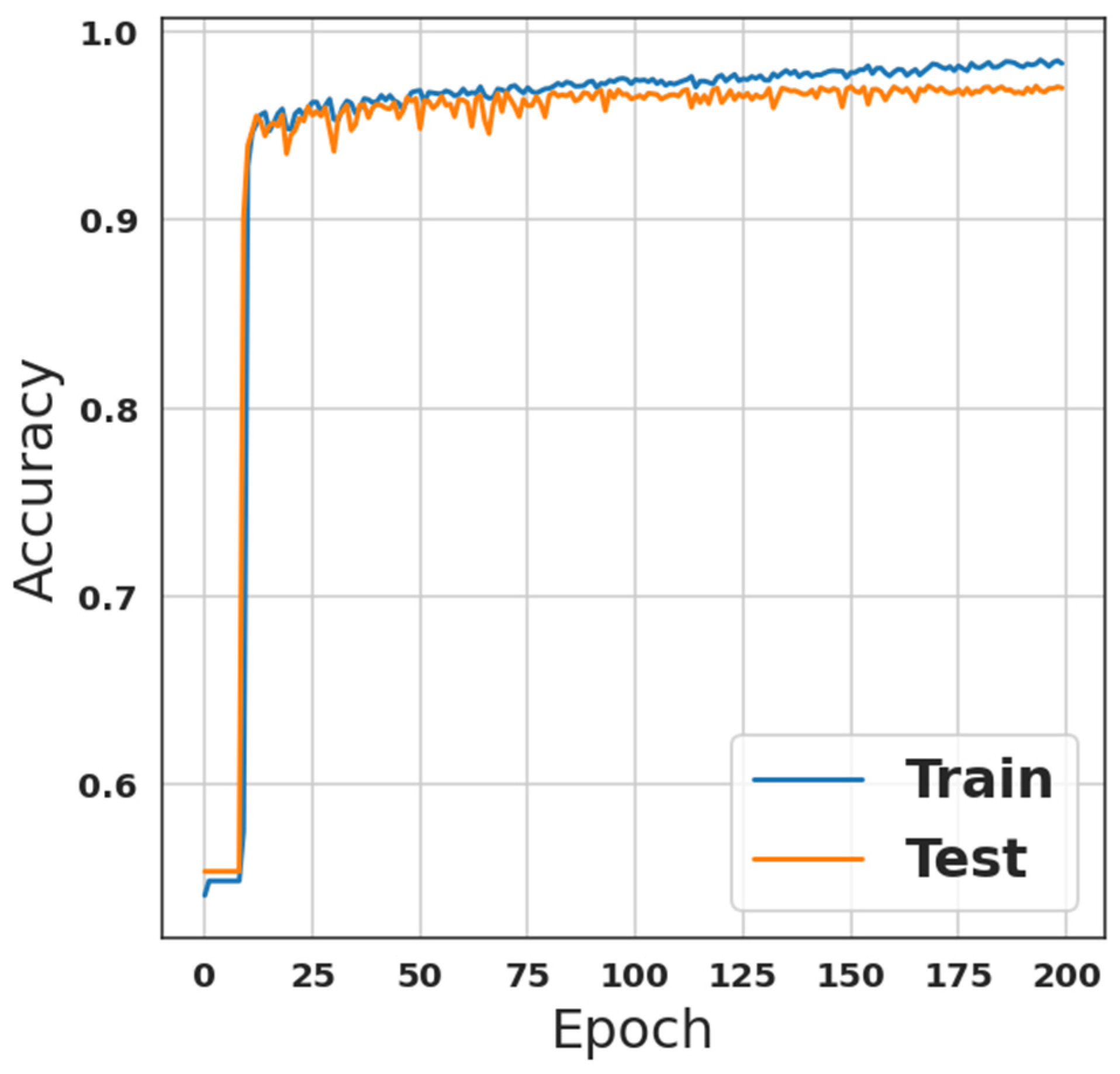
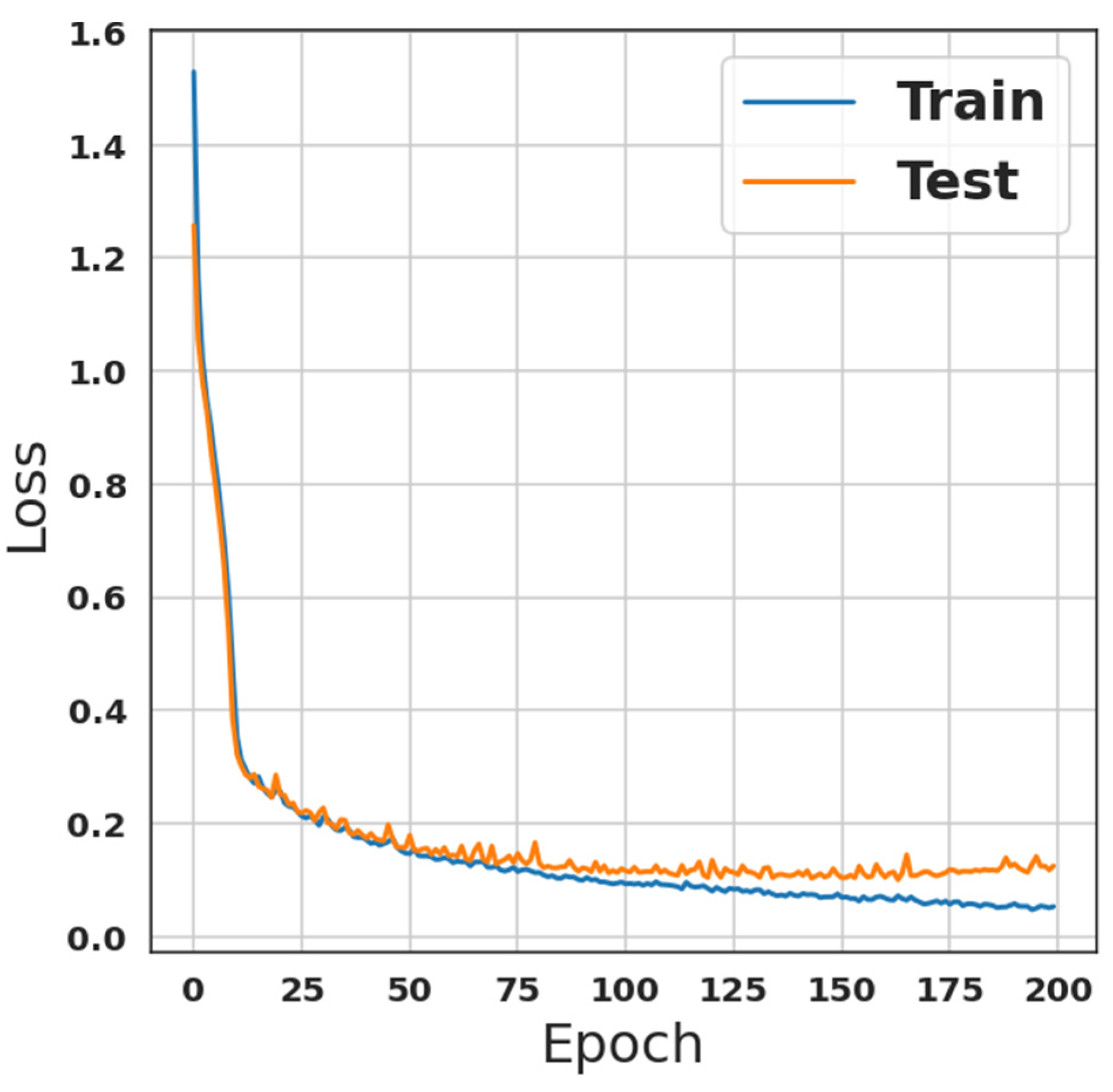
4. Simulation Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Smith, S. IoT Connections to Reach 83 Billion by 2024, Driven by Maturing Industrial Use Cases. Accessed Apr. 2020, 10, 2021. [Google Scholar]
- Awotunde, J.B.; Chakraborty, C.; Adeniyi, A.E. Intrusion Detection in Industrial Internet of Things Network-Based on Deep Learning Model with Rule-Based Feature Selection. Wirel. Commun. Mob. Comput. 2021, 2021, 7154587. [Google Scholar] [CrossRef]
- Wazzan, M.; Algazzawi, D.; Albeshri, A.; Hasan, S.; Rabie, O.; Asghar, M.Z. Cross Deep Learning Method for Effectively Detecting the Propagation of IoT Botnet. Sensors 2022, 22, 3895. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Liu, Q. A comprehensive review study of cyber-attacks and cyber security; Emerging trends and recent developments. Energy Rep. 2021, 7, 8176–8186. [Google Scholar] [CrossRef]
- Kasongo, S.M.; Sun, Y. A deep learning method with wrapper based feature extraction for wireless intrusion detection system. Comput. Secur. 2020, 92, 101752. [Google Scholar] [CrossRef]
- Jithu, P.; Shareena, J.; Ramdas, A.; Haripriya, A.P. Intrusion Detection System for IOT Botnet Attacks Using Deep Learning. SN Comput. Sci. 2021, 2, 205. [Google Scholar] [CrossRef]
- Derhab, A.; Aldweesh, A.; Emam, A.Z.; Khan, F.A. Intrusion Detection System for Internet of Things Based on Temporal Convolution Neural Network and Efficient Feature Engineering. Wirel. Commun. Mob. Comput. 2020, 2020, 6689134. [Google Scholar] [CrossRef]
- Huma, Z.E.; Latif, S.; Ahmad, J.; Idrees, Z.; Ibrar, A.; Zou, Z.; Alqahtani, F.; Baothman, F. A hybrid deep random neural network for cyberattack detection in the industrial internet of things. IEEE Access 2021, 9, 55595–55605. [Google Scholar] [CrossRef]
- Moustafa, N. A new distributed architecture for evaluating AI-based security systems at the edge: Network TON_IoT datasets. Sustain. Cities Soc. 2021, 72, 102994. [Google Scholar] [CrossRef]
- Al-Zewairi, M.; Almajali, S.; Awajan, A. Experimental Evaluation of a Multi-layer Feed-Forward Artificial Neural Network Classifier for Network Intrusion Detection System. In Proceedings of the 2017 International Conference on New Trends in Computing Sciences (ICTCS), Amman, Jordan, 11–13 October 2017. [Google Scholar]
- Pfahringer, B. Winning the KDD99 classification cup: Bagged boosting. SIGKDD Explor. Newsl. 2000, 1, 65–66. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015. [Google Scholar]
- Hajisalem, V.; Babaie, S. A hybrid intrusion detection system based on ABC-AFS algorithm for misuse and anomaly detection. Comput. Netw. 2018, 136, 37–50. [Google Scholar] [CrossRef]
- Khammassi, C.; Krichen, S. A GA-LR wrapper approach for feature selection in network intrusion detection. Comput. Secur. 2017, 70, 255–277. [Google Scholar] [CrossRef]
- Eesa, A.S.; Orman, Z.; Brifcani, A.M.A. A novel feature-selection approach based on the cuttlefish optimization algorithm for intrusion detection systems. Expert Syst. Appl. 2015, 42, 2670–2679. [Google Scholar] [CrossRef]
- Al-Yaseen, W.L.; Othman, Z.A.; Nazri, M.Z.A. Multi-level hybrid support vector machine and extreme learning machine based on modified K-means for intrusion detection system. Expert Syst. Appl. 2017, 67, 296–303. [Google Scholar] [CrossRef]
- Laftah Al-Yaseen, W.; Ali Othman, Z.; Ahmad Nazri, M.Z. Hybrid Modified k-Means with C4.5 for Intrusion Detection Systems in Multiagent Systems. Sci. World J. 2015, 2015, 294761. [Google Scholar] [CrossRef] [Green Version]
- Al-Yaseen, W.L.; Othman, Z.A.; Nazri, M.Z.A. Real-time multi-agent system for an adaptive intrusion detection system. Pattern Recognit. Lett. 2017, 85, 56–64. [Google Scholar] [CrossRef]
- Araújo, N.; De Oliveira, R.; Shinoda, A.A.; Bhargava, B. Identifying important characteristics in the KDD99 intrusion detection dataset by feature selection using a hybrid approach. In Proceedings of the 2010 17th International Conference on Telecommunications, Doha, Qatar, 4–7 April 2010. [Google Scholar]
- Essid, M.; Jemili, F. Combining intrusion detection datasets using MapReduce. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016. [Google Scholar]
- Jing, D.; Chen, H.-B. SVM based network intrusion detection for the UNSW-NB15 dataset. In Proceedings of the 2019 IEEE 13th international conference on ASIC (ASICON), Chongqing, China, 29 October–1 November 2019. [Google Scholar]
- Kadis, M.R.; Abdullah, A. Global and local clustering soft assignment for intrusion detection system: A comparative study. Asia-Pac. J. Inf. Technol. Multimed 2017, 6, 30–38. [Google Scholar] [CrossRef]
- Kuang, F.-J.; Zhang, S.-Y. A Novel Network Intrusion Detection Based on Support Vector Machine and Tent Chaos Artificial Bee Colony Algorithm. J. Netw. Intell. 2017, 2, 195–204. [Google Scholar]
- ISCX, U. NSL-KDD: Information Security Centre of Excellence (ISCX), University of New Brunswick 2015. Available online: http://www.unb.ca/cic/research/datasets/nsl.html (accessed on 25 September 2022).
- Mahoney, M.V.; Chan, P.K. An analysis of the 1999 DARPA/Lincoln Laboratory evaluation data for network anomaly detection. In International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Balasaraswathi, V.; Sugumaran, M.; Hamid, Y. Chaotic cuttle fish algorithm for feature selection of intrusion detection system. Int. J. Pure Appl. Math 2018, 119, 921–935. [Google Scholar]
- Al Daweri, M.S.; Abdullah, S.; Ariffin, K.Z. A migration-based cuttlefish algorithm with short-term memory for optimization problems. IEEE Access 2020, 8, 70270–70292. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Kumar, V.; Sinha, D.; Das, A.K.; Pandey, S.C.; Goswami, R.T. An integrated rule based intrusion detection system: Analysis on UNSW-NB15 data set and the real time online dataset. Clust. Comput. 2020, 23, 1397–1418. [Google Scholar] [CrossRef]
- Shah, A.A.; Khan, Y.D.; Ashraf, M.A. Attacks Analysis of TCP and UDP of UNCW-NB15 Dataset. VAWKUM Trans. Comput. Sci. 2020, 8, 48–54. [Google Scholar] [CrossRef]
- Ruan, Z.; Miao, Y.; Pan, L.; Patterson, N.; Zhang, J. Visualization of big data security: A case study on the KDD99 cup data set. Digit. Commun. Netw. 2017, 3, 250–259. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. The Significant Features of the UNSW-NB15 and the KDD99 Data Sets for Network Intrusion Detection Systems. In Proceedings of the 2015 4th International Workshop on Building Analysis Datasets and Gathering Experience Returns for Security (BADGERS), Kyoto, Japan, 5 November 2015. [Google Scholar]
- Kayacik, H.G.; Zincir-Heywood, A.N.; Heywood, M.I. Selecting Features for Intrusion Detection: A Feature Relevance Analysis on KDD 99. In Proceedings of the Third Annual Conference on Privacy, Security and Trust, St. Andrews, NB, Canada, 12–14 October 2005. [Google Scholar]
- Olusola, A.A.; Oladele, A.S.; Abosede, D.O. Analysis of KDD’99 intrusion detection dataset for selection of relevance features. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 20–22 October 2010. [Google Scholar]
- Alwan, M.H.; Hammadi, Y.I.; Mahmood, O.A.; Muthanna, A.; Koucheryavy, A. High Density Sensor Networks Intrusion Detection System for Anomaly Intruders Using the Slime Mould Algorithm. Electronics 2022, 11, 3332. [Google Scholar] [CrossRef]
- Ring, M.; Wunderlich, S.; Scheuring, D.; Landes, D.; Hotho, A. A survey of network-based intrusion detection data sets. Comput. Secur. 2019, 86, 147–167. [Google Scholar] [CrossRef] [Green Version]
- Hamid, Y.; Balasaraswathi, V.R.; Journaux, L.; Sugumaran, M. Benchmark Datasets for Network Intrusion Detection: A Review. Int. J. Netw. Secur. 2018, 20, 645–654. [Google Scholar]
- Choudhary, S.; Kesswani, N. Analysis of KDD-Cup’99, NSL-KDD and UNSW-NB15 Datasets using Deep Learning in IoT. Procedia Comput. Sci. 2020, 167, 1561–1573. [Google Scholar] [CrossRef]
- Binbusayyis, A.; Vaiyapuri, T. Comprehensive analysis and recommendation of feature evaluation measures for intrusion detection. Heliyon 2020, 6, e04262. [Google Scholar] [CrossRef]
- Rajagopal, S.; Hareesha, K.S.; Kundapur, P.P. Feature Relevance Analysis and Feature Reduction of UNSW NB-15 Using Neural Networks on MAMLS. In Proceedings of the 3rd International Conference on Advanced Computing and Intelligent Engineering (ICACIE 2018), Singapore, 22–24 December 2018. [Google Scholar]
- Almomani, O. A Feature Selection Model for Network Intrusion Detection System Based on PSO, GWO, FFA and GA Algorithms. Symmetry 2020, 12, 1046. [Google Scholar] [CrossRef]
- Sarnovsky, M.; Paralic, J. Hierarchical Intrusion Detection Using Machine Learning and Knowledge Model. Symmetry 2020, 12, 203. [Google Scholar] [CrossRef] [Green Version]
- Iwendi, C.; Khan, S.; Anajemba, J.H.; Mittal, M.; Alenezi, M.; Alazab, M. The Use of Ensemble Models for Multiple Class and Binary Class Classification for Improving Intrusion Detection Systems. Sensors 2020, 20, 2559. [Google Scholar] [CrossRef] [PubMed]
- Dunn, C.; Moustafa, N.; Turnbull, B. Robustness Evaluations of Sustainable Machine Learning Models against Data Poisoning Attacks in the Internet of Things. Sustainability 2020, 12, 6434. [Google Scholar] [CrossRef]
- Meghdouri, F.; Zseby, T.; Iglesias, F. Analysis of Lightweight Feature Vectors for Attack Detection in Network Traffic. Appl. Sci. 2018, 8, 2196. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.-Y.; Chen, C.-M.; Sun, X.; Liu, S.; Lin, J.C.-W. A Countermeasure to SQL Injection Attack for Cloud Environment. Wirel. Pers. Commun. 2017, 96, 5279–5293. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017. [Google Scholar]
- Al-Daweri, M.S.; Zainol Ariffin, K.A.; Abdullah, S.; Senan, M.F.E.M. An Analysis of the KDD99 and UNSW-NB15 Datasets for the Intrusion Detection System. Symmetry 2020, 12, 1666. [Google Scholar] [CrossRef]
- Kramer, O. Scikit-learn. In Machine Learning for Evolution Strategies; Springer: Berlin/Heidelberg, Germany, 2016; pp. 45–53. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Layer Type | Output Shape | No. Learnable Parameters |
|---|---|---|---|
| 1 | Convolution (1D) | (1, 32) | 8992 |
| 2 | Activation (ReLU) | (1, 32) | 0 |
| 3 | Convolution (1D) | (1, 32) | 3104 |
| 4 | Activation (ReLU) | (1, 32) | 0 |
| 5 | Convolution (1D) | (1, 64) | 10,304 |
| 6 | Activation (ReLU) | (1, 64) | 0 |
| 7 | Dropout (0.2) | (1, 64) | 0 |
| 8 | Convolution (1D) | (1, 64) | 20,544 |
| 9 | Activation (ReLU) | (1, 64) | 0 |
| 10 | Dropout (0.2) | (1, 64) | 0 |
| 11 | LSTM | (1, 40) | 16,800 |
| 12 | LSTM | (1, 30) | 8520 |
| 13 | Fully Connected (Dense) (output) | (1, 10) | 310 |
| Sequence | Layer Type | Output Shape | No. Learnable Parameters |
|---|---|---|---|
| 1 | Fully Connected (Dense) | (1, 300) | 17,100 |
| 2 | Fully Connected (Dense) | (1, 400) | 120,400 |
| 3 | Fully Connected (Dense) | (1, 600) | 240,600 |
| 4 | Fully Connected (Dense) | (1, 800) | 480,800 |
| 5 | Fully Connected (Dense) | (1, 1) | 801 |
| 6 | Fully Connected (Dense) | (1, 500) | 1000 |
| 7 | Fully Connected (Dense) | (1, 400) | 200,400 |
| 8 | Fully Connected (Dense) | (1, 1) | 401 |
| 9 | Fully Connected (Dense) | (1, 10) | 20 |
| Attribute | Term | Type | Attribute | Term | Type | Attribute | Term | Type |
|---|---|---|---|---|---|---|---|---|
| F1 | Dur | Float-64 | F16 | Sinpkt | Float-64 | F31 | ct_srv_src | Int-64 |
| F2 | Proto | Object | F17 | Dinpkt | Float-64 | F32 | ct_state_ttl | Int-64 |
| F3 | Service | Object | F18 | Sjit | Float-64 | F33 | ct_dst_ltm | Int-64 |
| F4 | State | Object | F19 | Djit | Float-64 | F34 | ct_src_dport_ltm | Int-64 |
| F5 | Spkts | Int-64 | F20 | Swin | Int-64 | F35 | ct_dst_sport_ltm | Int-64 |
| F6 | Dpkts | Int-64 | F21 | Stcpb | Int-64 | F36 | ct_dst_src_ltm | Int-64 |
| F7 | Sbytes | Int-64 | F22 | Dtcpb | Int-64 | F37 | is_ftp_login | Int-64 |
| F8 | Dbytes | Int-64 | F23 | Dwin | Int-64 | F38 | ct_ftp_cmd | Int-64 |
| F9 | Rate | Float-64 | F24 | Tcprtt | Float-64 | F39 | ct_flw_http_mthd | Int-64 |
| F10 | Sttl | Int-64 | F25 | Synack | Float-64 | F40 | ct_src_ltm | Int-64 |
| F11 | Dttl | Int-64 | F26 | Ackdat | Float-64 | F41 | ct_srv_dst | Int-64 |
| F12 | Sload | Float-64 | F27 | Smean | Int-64 | F42 | is_sm_ips_ports | Int-64 |
| F13 | Dload | Float-64 | F28 | Dmean | Int-64 | F43 | attack_cat | Object |
| F14 | Sloss | Int-64 | F29 | trans_depth | Int-64 | F44 | Label | Int-64 |
| F15 | Dloss | Int-64 | F30 | response_body_len | Int-64 |
| Feature | Score (×103) | Feature | Score (×103) | Feature | Score (×103) |
|---|---|---|---|---|---|
| F16 | 1719.167 | F11 | 52.38466 | F26 | 5.255736 |
| F19 | 1422.332 | F36 | 51.71041 | F13 | 5.078488 |
| F6 | 1191.638 | F29 | 48.28637 | F3 | 3.278490 |
| F9 | 122.0820 | F24 | 42.79038 | F20 | 0.3157251 |
| F17 | 118.2373 | F10 | 34.03161 | F21 | 0.255003 |
| F18 | 117.9835 | F14 | 24.79605 | F35 | 0. 2291240 |
| F7 | 113.8066 | F5 | 24.78945 | F25 | 0.2284359 |
| F30 | 110.4150 | F2 | 20.64451 | F22 | 0.1100448 |
| F31 | 105.2134 | F8 | 17.47411 | F23 | 0.09680493 |
| F32 | 99.98646 | F15 | 11.57659 | F34 | 0.02468076 |
| F37 | 82.63284 | F12 | 9.971425 | F33 | 0.02169648 |
| F27 | 78.87113 | F1 | 7.812781 | ||
| F4 | 61.40787 | F28 | 6.947356 | ||
| Approach | Accuracy | Recall | Precision | F1-Score |
|---|---|---|---|---|
| LR | 92.8% | 92.8% | 92.83% | 92.8% |
| Custom CNN + LSTM model | 96.08% | 96.08% | 96.08% | 96.08% |
| ANN model | 97.01% | 97.01% | 97.01% | 97.01% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salman, E.H.; Taher, M.A.; Hammadi, Y.I.; Mahmood, O.A.; Muthanna, A.; Koucheryavy, A. An Anomaly Intrusion Detection for High-Density Internet of Things Wireless Communication Network Based Deep Learning Algorithms. Sensors 2023, 23, 206. https://doi.org/10.3390/s23010206
Salman EH, Taher MA, Hammadi YI, Mahmood OA, Muthanna A, Koucheryavy A. An Anomaly Intrusion Detection for High-Density Internet of Things Wireless Communication Network Based Deep Learning Algorithms. Sensors. 2023; 23(1):206. https://doi.org/10.3390/s23010206
Chicago/Turabian StyleSalman, Emad Hmood, Montadar Abas Taher, Yousif I. Hammadi, Omar Abdulkareem Mahmood, Ammar Muthanna, and Andrey Koucheryavy. 2023. "An Anomaly Intrusion Detection for High-Density Internet of Things Wireless Communication Network Based Deep Learning Algorithms" Sensors 23, no. 1: 206. https://doi.org/10.3390/s23010206