1. Introduction
Neural network-based object detection models outperform traditional ones and have become a milestone in object detection techniques. However, the prodigious performance of neural network-based models is derived from millions of parameters and a tremendous amount of training data, which allow sufficient training of models. MS COCO and Pascal VOC are well-known datasets in general object detection tasks [
1,
2]. These datasets contain numerous images of ordinary objects and accurate annotations, which alleviates the concerns of researchers regarding the datasets they use and allows them to focus on their research. However, creating high-quality datasets is a labor-intensive, time-consuming, and expensive task. Therefore, datasets for infrequently occurring incidents are insufficient. This lack of datasets triggers small-dataset and class imbalance problems, which limits the model performance.
Image data augmentation methods have been proposed increase the dataset size at a lower cost by using images from existing datasets. One approach to image data augmentation is basic image manipulation, which involves simple operations such as cropping or flipping images. Although this approach has a low computational cost and can increase the size of the dataset, it can cause overfitting problems if the size of the dataset is insufficient [
3]. Another method is image data augmentation using deep learning, and the most frequently used ones are based on generative adversarial networks (GANs). After training the GAN model with the image dataset to be augmented, these approaches augment the dataset by sampling the images from the trained model. Some studies have proposed image data augmentation methods based on GAN [
4], and they obtain better object detection performance than those trained with the existing dataset.
Although any object can be targeted through GAN-based image data augmentation, most studies have been conducted in the medical field [
4]. One reason is that it is difficult to obtain a large amount of data for medical images because of the characteristics of the medical domain, such as privacy and disease rarity. Images of fire experience a similar data shortage problem. In the case of a fire, it is difficult to generate data owing to safety issues, and existing datasets comprise an insufficient number of images. Moreover, unlike general objects, fire is difficult to create because a flame is an unstructured object without clear edges. Therefore, a smooth transition between the fire and the background is important. Additionally, because a fire results from burning an object, many real-world fire images appear blended with background objects. Therefore, if there is an object at the location targeted for flame insertion, the approach to create a fire image using the cut-and-paste method is not suitable because the object and fire should appear naturally harmonized.
This study targets labeled data generation by augmenting an object detection dataset with a small amount of general data. Structured objects have sufficient data and are easy to label, but unstructured objects do not. To alleviate these problems, we focus on improving the detection performance by data augmentation when a small dataset of an unstructured object is given. We select fire as the representative of unstructured objects. In this study, we used fire images showing various fire situations, as shown in
Figure 1. These images contain occlusions, and the scale variances of flames are significant. To solve these problems, we propose a novel GAN-based model for data augmentation, called the robust data augmentation GAN (RDAGAN). RDAGAN converts clean fire-free images into fire images using a dataset containing a small number of fire images with strong occlusions. Because the generated images are used for training object detection models, RDAGAN must insert a flame into the target area that will be used as the bounding box for the generated images. By making the best use of the given dataset, it generates realistic fire images that can enhance the performance of object detection models. The contributions of this study can be summarized as follows.
- 1.
We propose RDAGAN to solve the small-dataset problem in object detection tasks. The RDAGAN includes two networks: an object generation network and an image translation network. The object generation network reduces the burden on the image translation network by generating a flame patch, which acts as a guideline for the image translation network. The image translation network translates the entire image into a fire scene by blending the generated flames and clean images.
- 2.
We propose the concept of information loss that binds two networks by maximizing the mutual information of the outputs of the two networks to retain the information of the generated flame patch in the image translation network.
- 3.
Background loss is proposed to improve the performance of RDAGAN. The background loss compares the difference between an input image and the image generated through the image translation network, and makes them as similar as possible. Consequently, the generated images have sharp edges and diverse color distributions.
- 4.
A quantitative experiment demonstrates that the dataset augmented using RDAGAN can achieve better flame detection performance than baseline models. Moreover, through comparative experiments and ablation studies, we show that RDAGAN can generate labeled data for fire images.
2. Related Work
2.1. Disentangled Representation Learning and InfoGAN
Disentangled representation learning is an unsupervised learning technique. Its goal is to find a disentangled representation that affects only one aspect of the data, while leaving others untouched [
5].
To find a disentangled representations, InfoGAN [
6] was proposed, which is a variation of GAN that finds interpretable disentangled representations instead of unknown noise. InfoGAN allows the model to learn a disentangled representation by employing constraints during representation learning. Moreover, it divides the input into incompressible noise and latent code, and maximizes the mutual information between the latent code and generator distribution. That is, the latent code information is retained during the generation process.
2.2. Image-to-Image Translation
The Image-to-Image (I2I) translation technique maps images of one domain to another. Although this task may seem similar to style transfer, they have a key difference. Style transfer aims to translate images such that they have the style of one target image while maintaining the contents of the image. In contrast, I2I translation aims to create a map between groups of images [
7].
Pix2Pix [
8] was the first supervised I2I conditional GAN-based model used for learning mappings between two paired image groups. However, because Pix2Pix has an objective function based on the L1 loss between translated and real images, unpaired datasets cannot be used for training. Unsupervised I2I translation models have been proposed to solve this problem. Cycle-consistent adversarial network (CycleGAN) [
9] is one of the best-known unsupervised I2I translation models. It contains two pairs of generators and discriminators. Each generator and discriminator pair learns to map an image onto the opposite domain. Additionally, cycle-consistency loss have been proposed, which is defined using the L1 distance between the original image and that recovered from the image translated into another domain. Cycle-consistency loss can alleviate the problem caused by the absence of a paired dataset [
10]. Contrastive learning for unpaired image-to-image translation (CUT) [
11] is an unsupervised I2I translation model based on contrastive learning. Its goal is to ensure that a patch of translated image contains the content of the input image. CUT achieves this goal by maximizing mutual information through contrastive loss. Contrastive loss maximizes the similarity of patches for the same location in both the input and output images and minimizes patch similarity at different locations.
2.3. GAN-Based Image Data Augmentation
An image data augmentation method based on GAN is widely used in many fields such as medical imaging or remote sensing. These fields are hard to obtain sufficient data in to train neural networks because they require a large amount of training data. When the number of data points is small, it is easy for models to be overfitted or fall into the class imbalance problem. The GAN-based image data augmentation methods can relieve these problems by generating new samples from a data distribution. Frid-Adar et al. proposed a method to generate liver lesion images using GANs [
12]. In the study, even though they utilized only 182 liver lesion computed tomography images to train the GAN model, the performance of a convolutional neural network-based model was improved for liver lesion classification.
Furthermore, because the I2I translation model translates an image of one domain into that of another, some studies have generated labeled datasets for object detection and image segmentation using I2I translation. In this case, the target domain of translation becomes the dataset to be augmented, and the image that is the subject of the translation becomes the source image. Lv et al. proposed a GAN-based model augmenting remote sensing images for the image segmentation task [
13]. They proposed deeply supervised GAN (D-sGAN) that automatically generates remote sensing images and their labels. The D-sGAN accepts random noise and target segmentation maps, and synthesizes remote sensing images corresponding to the input segmentation map. The generated images from D-sGAN increased the remote sensing interpretation model accuracy by 9%. Pedestrian-Synthesis-GAN (PS-GAN) [
14] was proposed to reduce the cost of pedestrian image annotations. The PS-GAN uses an image with inserted noise. The object is placed in the noisy area, a pedestrian image is inserted into a noise box, and the generated image is evaluated using one discriminator for the entire image and another for the generated pedestrian patch. The dataset augmented using this model has been shown to improve the detection performance of a region-based convolutional neural network [
15].
2.4. Fire-Image Generation for Image Data Augmentation
Few studies have been conducted on creating fire images for specific tasks. Some of them were studied to improve performance of fire classification. Campose and Silva proposed a CycleGAN-based model to translates non-fire aerial images into aerial ones with fire [
16]. This model translates non-fire aerial images into aerial ones with fire. The model works based on the cut-and-paste algorithm to control the fire generation area. Park et al. proposed a CycleGAN-based model to relieve a class imbalance problem for wildfire detection [
17]. This model translates non-fire images into wildfire ones. Because image classification tasks do not require annotations for fire regions, there is no need to control flame generation. Thus, these studies used the barely modified CycleGAN architectures that are only able to translate clean images to fire images.
Other studies have been conducted to improve image segmentation performance. Yang et al. proposed a model for creating a flame image to improve the flame segmentation performance in a warehouse [
18]. A limitation of their study is that the boundary between the square area and the background of a generated image can be clearly distinguished because the model performs image translation only on the square area around the inserted flame. Qin et al. proposed a model for creating realistic fire images, including the effects of flames [
19]. Their model uses a cut-and-paste algorithm to paste the flame onto the image and then creates natural fire images that include light-source effects, such as halo by image translation. In this study, more natural fire images were created by solving the problems encountered in previous studies. Both studies had limitations in that, rather than modeling general fire images, they only considered indoor images, and the images had little clutter and occlusion between the flame and background objects.
3. Methods and Materials
In this section, we introduce the proposed RDAGAN model. The goal was to build a model that maps clean images in a clean image domain () to target images in the target image domain (). The proposed model was trained using an object detection dataset containing few images, and most images had occlusions.
The proposed model employs the divide-and-conquer approach, where the model is divided into two networks: an object generation network and an image translation network. The model not only endeavors to insert realistic object in the image () but also transforms the entire image to appear such as those in the target domain (). These goals are hard to be achieved using a single GAN model because the training becomes unstable.
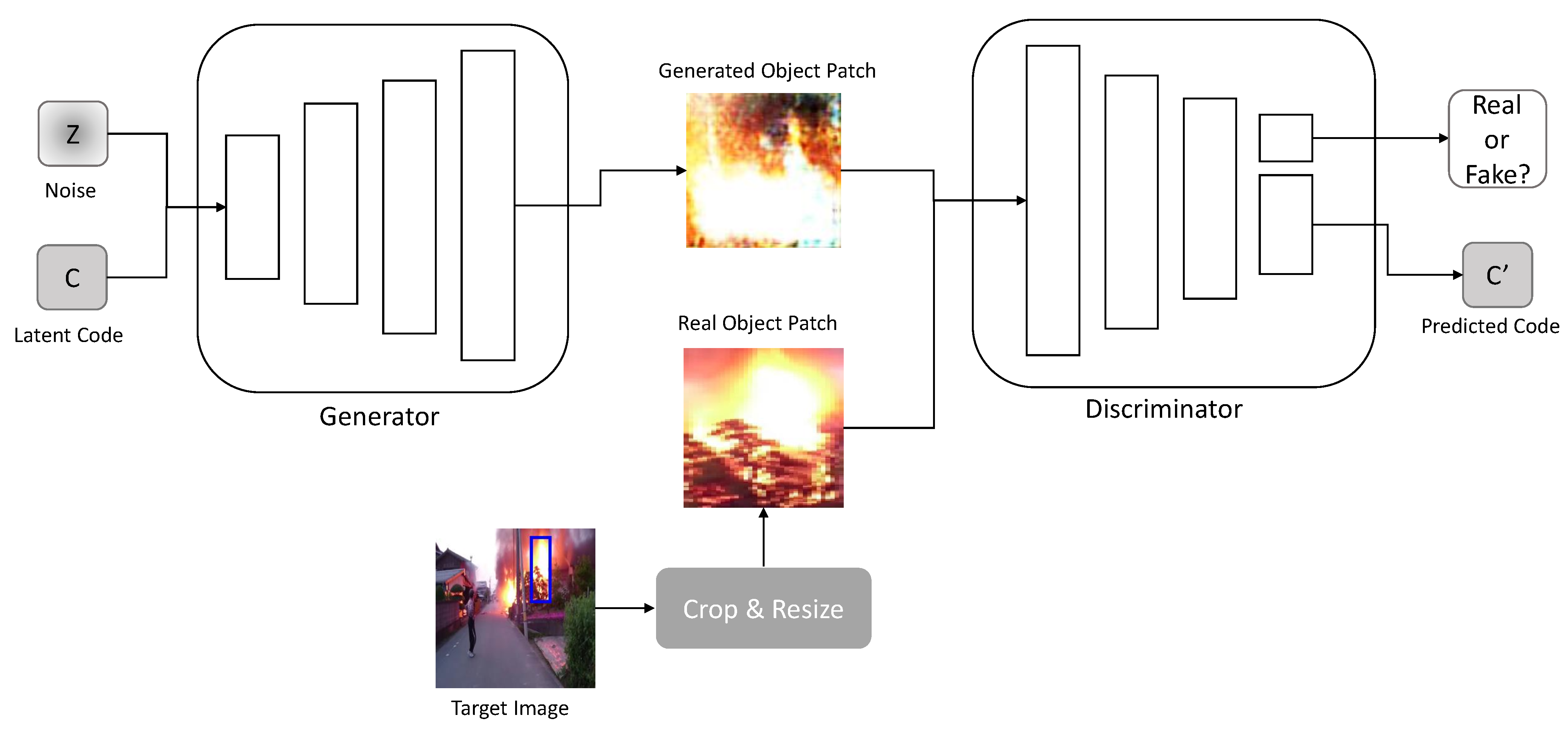
3.1. Object Generation Network
The object generation network creates an image of the target object to be inserted into
. The image generated from the object generation network is used as an input for the image translation network. The image mitigates the training instability in the image translation network owing to the goals of object creation and image translation. The network adopts the InfoGAN [
6] architecture to obtain a disentangled representation of the target object. The disentangled representation obtained from the object generation network is used in the image translation network to build a loss function. We trained the network with object images
that were cropped and resized from image
using the crop and resize module
R.
As shown in
Figure 2, generator
accepts the incompressible noise
z and latent code
c as inputs, which are sampled from a normal distribution. The discriminator
not only validates the input images but predicts the input latent code
.
Objectives
Because the object generation network uses the InfoGAN architecture, the model objective comprises two losses: adversarial loss and information loss .
The adversarial loss
[
20] is used to make the generated patch
similar to that of the target domain images
as follows:
Information loss
[
6] measures the mutual information between latent code
c and generated image
. It is calculated using the mean squared error of input latent code
c and predicted code
from the discriminator
, as follows:
The full objective
is the sum of previous losses:
where
represents the strength of the information loss. The model was trained by minimizing the full objective.
3.2. Image Translation Network
The image translation network merges the clean images
and object patch
generated from the object patch network, while making image
similar to the target image
. However, it is challenging to perform these complicated tasks simultaneously using the vanilla GAN model [
20] and a single adversarial loss. Hence, the proposed model includes a local discriminator [
21] and additional loss functions to reduce the burdens of complicated tasks.
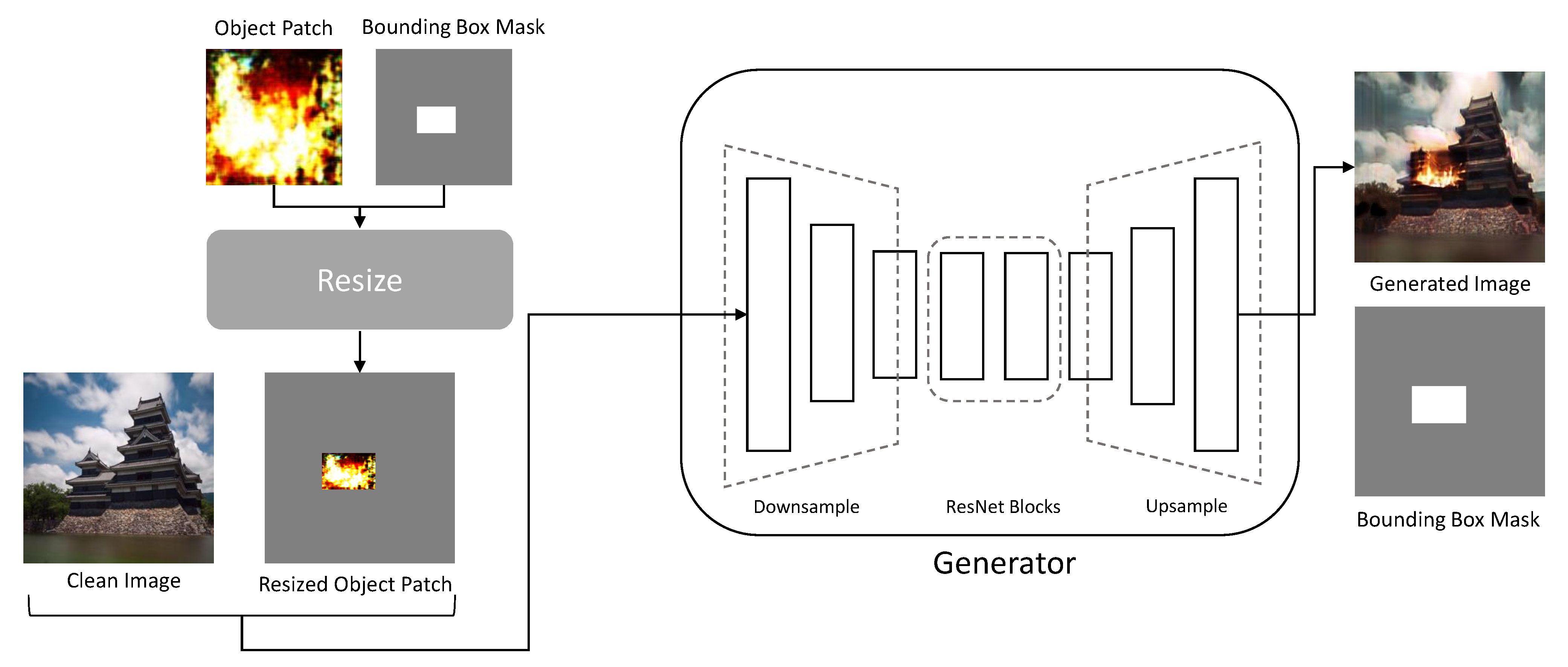
3.2.1. Generator
As shown in
Figure 3, the the image translation network generator
has an encoder–decoder architecture comprising residual network (ResNet) [
22] blocks in the middle, similar to the generator used in CycleGAN [
9]. However, unlike [
23], the generator has flexibility in the shape variance of the generated image because all features are downsampled and upsampled.
To create the image, the generator requires a bounding box mask
, which indicates the location of flame insertion. As shown in Equation (
4), the position where the value of the mask is 0 indicates the background, and that where the value is 1 indicates the flame. There are no particular algorithms used to determine the bounding box region. Each point of the bounding box area is randomly sampled from the discrete uniform random distribution within the height and width of the images.
The resized object patch is obtained by resizing the object patch, wherein the patch is positioned in the area where the value of the bounding box mask is one. The resized object patch is concatenated with a clean image and used as the generator input. The generator creates the generated image by naturally blending the six-channel combined images and translating them such that they are similar to the target domain image
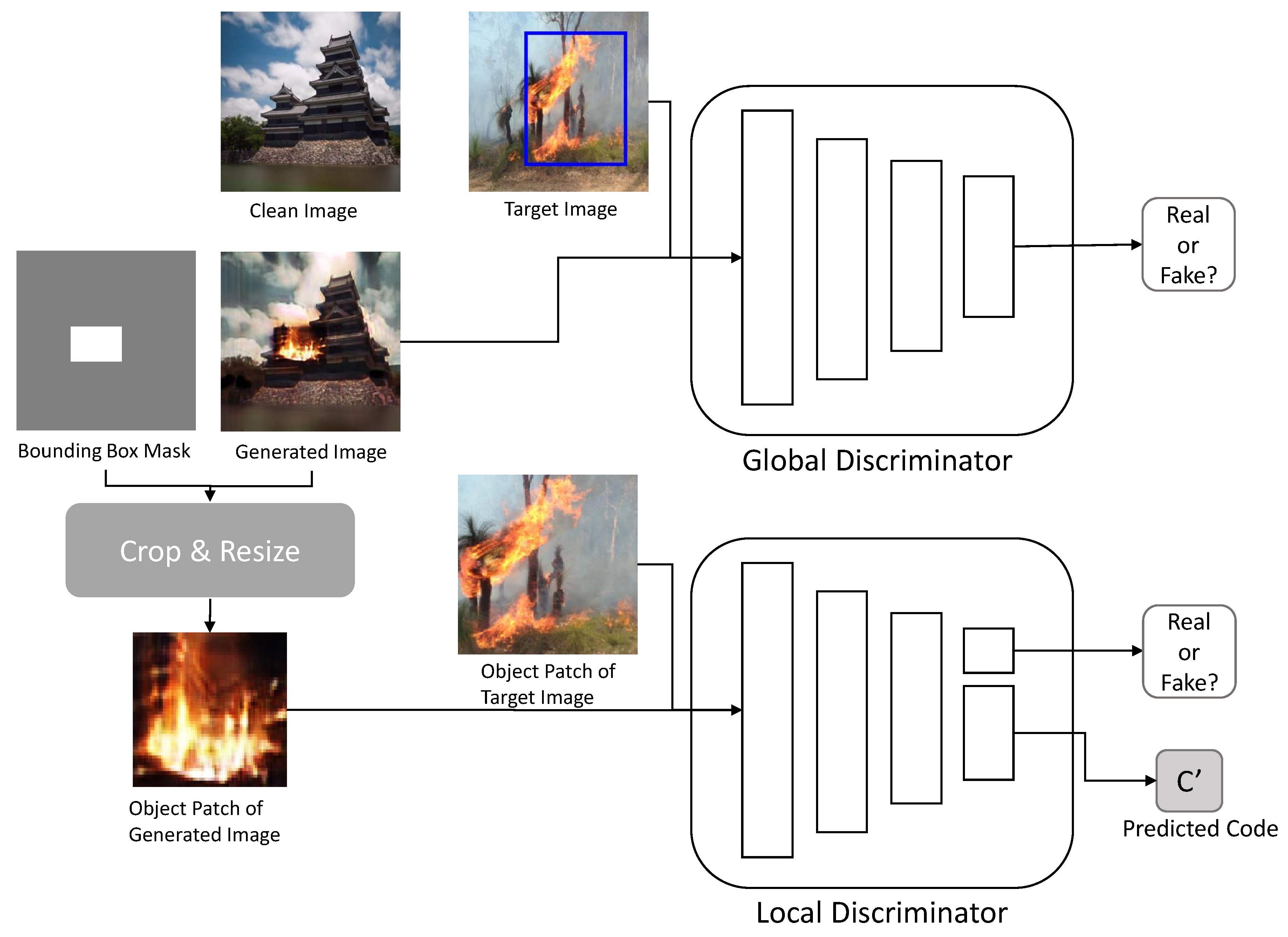
3.2.2. Discriminator
As shown in
Figure 4, the image translation network comprises two discriminators: global
and local
. These discriminators perform the image translation network tasks of image translation and natural blending.
The global discriminator
evaluates the images
generated by the generator. Its structure is based on the PatchGAN [
8] discriminator that evaluates patches of the image rather than the whole one. It evaluates whether the image is similar to the image of the target domain image
. This evaluation result constitutes an adversarial loss.
The local discriminator
determines whether the object patch
is realistic, and whether the object patch
can be obtained through the cropping and resizing operation
R using the mask of the generated image
. The structure of the local discriminator is similar to the structure of the global discriminator. However, like the InfoGAN [
6] discriminator, it contains an additional auxiliary layer that produces the predicted code
from feature maps of the image. The authenticity evaluation result of the local discriminator is contained in the adversarial loss, and the predicted code is used to construct an information loss.
3.2.3. Adversarial Loss
We used adversarial loss
[
20] to allow the generator to learn the mapping from
to
. The objective is expressed as follows:
where
tries to generate images similar to those obtained from the target domain
and target objects appear as real objects, whereas the global discriminator
aims to distinguish the generated image
from the images obtained from
. The local discriminator
endeavors to differentiate the generated object
from the object obtained from
.
3.2.4. Information Loss
The goal of the image translation network cannot be achieved using adversarial loss alone because the target image contains both target objects and occlusions. Therefore, the local discriminator simultaneously learns not only the shape and texture of the object itself, but also occlusions caused by other objects. This hinders the generator from using and blending the object patch with the clean image and creates artifacts in the generated images. Additionally, it causes the generator to fall into mode collapse. To solve this problem, we introduce information loss to constrain the input object patch and the cropped object of the generated image to have similar characteristics, which allows the generator to blend the object patch with the clean image .
However, it is difficult to create two images with similar characteristics by directly using the input object patch and the generated image object patch . Therefore, we achieved this by maximizing the mutual information between the two. The mutual information is denoted as , where is the mutual information between random variables X and Y. The mutual information is defined as , where and are the marginal and conditional entropies, respectively.
Maximizing
is also problematic, because
and
have the same dimensionality. Maximizing
means making the two images as identical as possible, and it can be achieved by replacing the generated image patch
with
. Thus, we attempted to maximize
instead of
. This is because the object generation network
is trained to maximize the mutual information between
c and
. In [
6], it was demonstrated that maximizing the mutual information
is the same as minimizing the difference between the latent code
c and the predicted code
from the local discriminator
.
Therefore, we formulated the information loss
as the difference between latent code
c of
and predicted code
of
using the mean squared error, and the objective is defined as follows:
3.2.5. Background Loss
The background loss was used to find the difference between the input image and the generated image , except for the bounding box mask area . Owing to the nature of the generator with an encoder-decoder structure, the image is first compressed into a low-dimensional representation and then recovered. This has the advantage in that the structure of the generated image is relatively free; however, there is a trade-off in that the fidelity of the image is lowered. Therefore, the edge components of the image are blurred, the tint of the image is significantly changed, and the color variance in the generated image is reduced.
To eliminate the reconstruction problem of the generator, background loss was introduced. Background loss is the pixel-wise L1 distance between the input clean image
and the generated image
, except for the mask
area. This is because the flame merges in the region indicated by the mask. To exclude the flame region, we obtain the inverted mask
and multiply it by the generated image
and the clean image
. The background loss strongly guides to the generator
, stabilizes training, and allows
to produce sharp images [
8]. The objective function
is expressed as follows:
3.2.6. Full Objective
Finally, the full objective of the image translation network is formulated as follows:
where
and
are the strengths of the background and information losses, respectively.
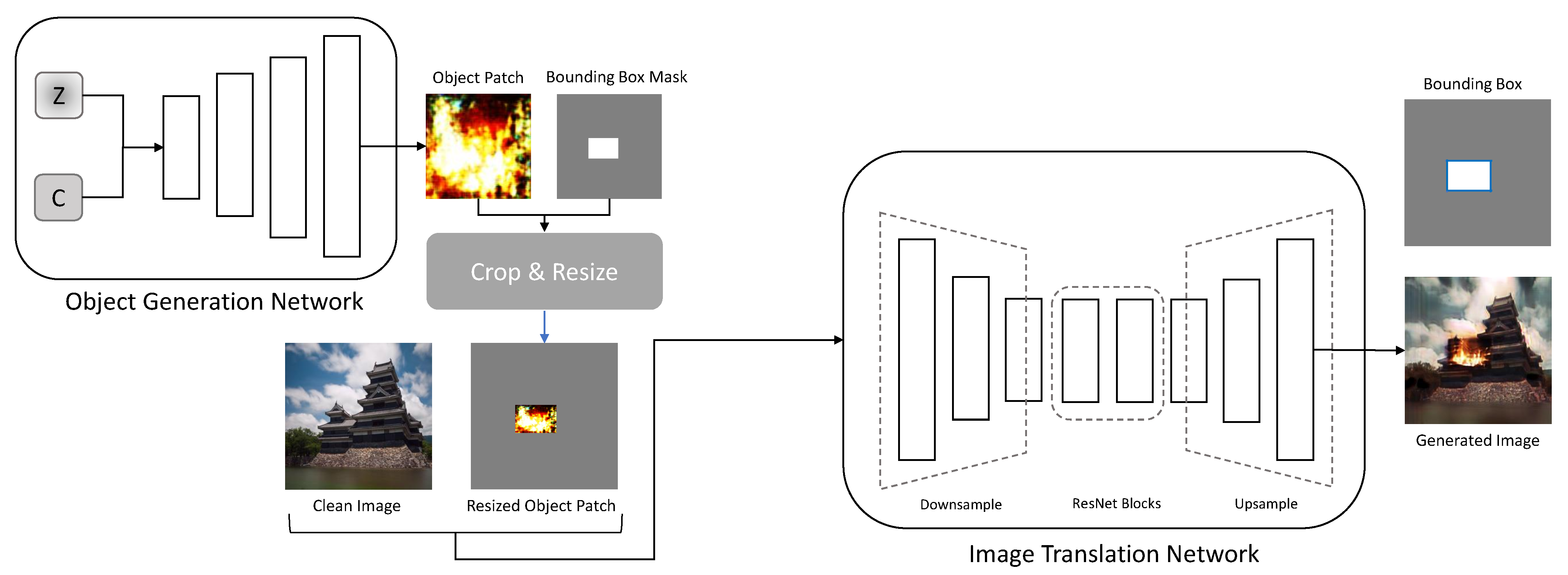
3.3. Overall Architecture
The overall architecture of RDAGAN is shown in
Figure 5. For RDAGAN data generation, the generators of the image generation and translation networks are used.
receives incompressible noise
z and latent code
c and creates an object patch
.
The RDAGAN samples the bounding box mask from the uniform distribution and uses it to create a resized object patch . The resized object patch is passed to with the clean image , which is used as the background to create the generated image . After performing fire-image generation to generate images for the object detection dataset, mask is converted into a bounding box.
4. Experiments
We conducted qualitative and quantitative evaluations to demonstrate the image generation performance of RDAGAN and verify whether it can boost objective detection performance.
First, we designed a quantitative evaluation to prove that RDAGAN can generate labeled data that are sufficient to improve the detection performance of a deep learning model. We then performed a qualitative evaluation to confirm the image-generation ability of the image translation network. The qualitative evaluation comprised of a comparative evaluation and ablation studies. In the comparative evaluation, the abilities of the image translation model and baseline models were compared. In ablation studies, RDAGAN and its ablations were compared.
4.1. Implementation Details
For all the experiments, the object generation network included 112-dimensional noise and 16-dimensional latent code, and the size of the generated object patch was pixels. The generator of the image translation network comprised two downsample layers, 11 ResNet blocks, and two upsample layers. The image translation network uses pixel images for the generator and global discriminator and pixel images as cropped object images for the local discriminator.
To evaluate the proposed model, we conducted experiments by using two datasets: FiSmo and Google Landmarks v2 dataset [
24,
25]. FiSmo dataset is a fire dataset that contains images of fire situations and annotations for object detection and segmentation task. In experiments, we used images and bounding boxes of FiSmo dataset as the source of fire images. Google Landmarks v2 dataset is a large-scale dataset comprising about 5 million landmark images. The Google Landmarks v2 dataset was used as a non-fire background image for generating fire images in our model.
In the quantitative experiment, the YOLOv5 [
26] model with 86.7 million parameters was used to evaluate the object detection performance. Two datasets were constructed to train the models: one dataset comprising 800 images sampled from the FiSmo dataset, and the other comprising images augmented from the first dataset. The second dataset was composed of 800 FiSmo images and 3000 images sampled from RDAGAN. To test the YOLOv5 model, a dataset with 200 images sampled from the FiSmo dataset was used.
In the qualitative evaluation, the FiSmo dataset was used as the target image dataset to train all models. The Google Landmarks v2 dataset was used as the clean image dataset. For training the RDAGAN, we used 1500 samples that were randomly selected from the datasets. For generating images through RDAGAN, images sampled from the Google Landmarks v2 dataset were used as input. None of the images in the datasets used in the experiments overlapped with the others.
The baseline models used in the comparative experiment were the CycleGAN [
9] and CUT [
11], which are widely used unsupervised I2I translation models. To ensure a fair comparison, we provided object patches and clean images to the network during training. These patches reduce the burden of object generation. For CycleGAN, the generator network was provided with an additional object mask, which mapped the target domain
to a clean image domain
. This allowed the network to locate the target object easily.
4.2. Quantitative Evaluation
For the quantitative evaluation, the YOLOv5 model was trained using the FiSmo dataset and that augmented using RDAGAN. The augmented dataset was inflated with images sampled using RDAGAN, which was trained with the same datasets as those used in the comparative experiment. We evaluated the performance of the trained models to confirm whether the generated images and bounding boxes could improve the detection performance.
4.2.1. Evaluation Metrics
To evaluate the proposed model, we focused on the accuracy of the YOLOv5 model. We adopted four metrics to measure the accuracy of the YOLOv5 model: precision, recall, F1 score, and average precision (AP). Object detection includes two subtasks: bounding box-regression and object classification. We evaluated the classification performance by measuring the precision and recall. The bounding box regression capacity can be scaled using the AP.
Precision is the percentage of true positives (
) among the total number of true and false positives (
). Recall is the percentage of (
) among the total number of (
) and false negatives (
). These metrics are calculated as follows:
Precision and recall vary with the confidence threshold of the detector. In this evaluation, we set the threshold as the value at which the F1 score was maximized.
There is a trade-off relationship between precision and recall. That is, in most cases, if precision increases, recall is suppressed. To evaluate the classification results, the F1 score can be used as a holistic evaluation metric of accuracy instead of precision and recall. It can be derived by calculating the harmonic mean of precision and recall as follows:
Owing to the trade-off relationship between precision and recall, we instead used the F1 score to quantify the results.
Average precision (AP) is a widely used precision metric for evaluating object detection models. The AP is obtained by computing the area of the precision–recall curve obtained by varying the model confidence [
27]. It can be considered with the overlap threshold, intersection over union (IOU), which is defined as the fraction of the intersection of the overlapped area between the ground truth bounding box
and the predicted bounding box
over the union of the areas [
2] as follows:
Using the IOU threshold, predictions wherein IOUs are less than the threshold are considered false positives [
27]. We obtained AP by applying two IOU threshold settings. In the first setting, the IOU threshold was set to 0.5, and in the other, it varied from 0.5–0.95 with a step size of 0.5. We denote these IOUs as AP@0.5 and AP@0.5:0.95, respectively.
4.2.2. Comparative Experiment
We compared the images and the object patches generated by RDAGAN and baseline models, CycleGAN and CUT. We evaluated the translation of the entire image, and the localization and quality of the generated flame.
4.3. Ablation Studies
4.3.1. Image Generation
We compared the images generated by RDAGAN with those generated by its ablations. The ablations included four models with various parts eliminated: one without the background loss, one without the object patches and information loss, one without the local discriminator and information loss, and one without the object patches and local discriminator.
4.3.2. Object Generation
The importance of information loss, background loss, and the local discriminator was evaluated by comparing the objects generated by RDAGAN and its ablations.
5. Results and Discussion
5.1. Quantitative Evaluation Results
Table 1 lists the performance of the trained YOLOv5 model. The dataset augmented with the data generated through RDAGAN shows an improvement in AP@0.5 from 0.5082 to 0.5493 and in AP@0.5:0.95 from 0.2917 to 0.3182, wherein the IOU threshold ranged from 0.5–0.95.
Although the recall of the model trained with the augmented dataset was slightly decreased by 2.6%, the precision showed a substantial improvement from 0.5497 to 0.6922, which was an improvement of 14.2%. Moreover, the F1 score of the model trained with augmented data increased from 0.5465 to 0.5921. Thus, RDAGAN can augment data and increase the performance of object detection models without requiring additional target datasets or images.
5.2. Comparative Experiment Result
Figure 6 shows the images and the object patches generated by the RDAGAN and baseline models.
Figure 6a–c show the images and object patches generated using RDAGAN, CycleGAN, and CUT, respectively. We evaluated the translation of the entire image, and the localization and quality of the generated flame.
Regarding the translation of the entire image, RDAGAN showed a slight change in the image tint. However, it is evident that the overall characteristics of the background were maintained. In contrast, CycleGAN changed the entire image significantly. The area with the generated flame turned red and the background changed to a halo and became dark. Although CUT did not change the background of most images, it failed to generate flames in them. Regarding flame localization, RDAGAN generated a flame exactly within the given area, but CycleGAN generated flames in different locations and CUT either generated flames in a different locations or did not generate one at all. Moreover, CUT struggled to blend the flames; hence, only one sample in
Figure 6c has a flame.
In conclusion, RDAGAN created flames exactly at the target locations while maintaining background characteristics. However, although CycleGAN generated flames in all images, the background was degraded and localization was completely ignored. Although some samples from CUT displayed flame and maintained the background characteristics to some extent, it obtained inadequate results for flame generation and localization.
5.3. Ablation Results
5.3.1. Comparison of Image Generation Performance
Figure 7 shows the image generation results of RDAGAN and its ablations.
Figure 7a shows images generated by the RDAGAN,
Figure 7b shows images generated by the model without
,
Figure 7c shows images generated by the model without
and
,
Figure 7d shows images generated by the model without
and
, and
Figure 7e shows images generated by the model without
,
, and
. First, we evaluated the overall images and flame quality.
We compared the differences between the overall images generated by RDAGAN and its ablations. In
Figure 7b, the tint of the background is fixed, and the background itself is almost unrecognizable. The images in
Figure 7c show background translations similar to those of RDAGAN. In
Figure 7d, flames are generated at the target points, but the localization is poor, which deteriorates object detection performance. Moreover, the images in
Figure 7d contain the background degradation. The images in
Figure 7e appear to be strongly affected by
, and thus flames are generated in the given areas. However, the shape of the flames indicates that the generator experienced mode collapsed.
Thus, we can confirm that is a vital for maintaining the sharpness of the background, is crucial for object generation, and is important for the localization of the generated flame.
5.3.2. Comparison of Generated Objects
Figure 8 shows the generated objects cropped from
Figure 7. The images were sorted in the same order as those in
Figure 7. We evaluated the quality of the generated flames and the relations between the inputs and generated flames.
The images in
Figure 8a,b are affected by
, whereas those in
Figure 8c–e do not. The impact of
can be determined by evaluating the relationship between the input and output images. Although the input image is not a perfect patch that only requires refinement, RDAGAN generates flame patches while maintaining the characteristics of the input images. The area that appears dark in the generated patch also appears dark in the input image and vice versa. The model that generated the object shown in
Figure 8d was provided
as input; however, the object show less relation with the input because the model did not experience
. The impact of
can be determined by comparing
Figure 8a,b. Owing to
, they exhibit a similar flame pattern, but the lack of
makes the generated flames in
Figure 8b appear unrealistic. The images in
Figure 8c demonstrate the importance of
. The model used to generate images shown in
Figure 8c imparted a bright color to the given area, but it failed to synthesize a realistic flame, even though it comprised
that teaches
whether the generated object appears like a real flame. In the model used to generate the images shown in
Figure 8e,
was removed. The images in
Figure 8e show similar shapes and colors. This indicates that mode collapse occurred in the model.
Therefore, we can confirm that , , and play a crucial role in target object generation, and without even one of them, the quality of the generated object is significantly damaged.
6. Conclusions
In this paper, we proposed a novel approach, called RDAGAN, to augment image data for object detection models. RDAGAN generates training data for an object detection model using a small dataset. To achieve this, we introduced two subnetworks: an object generation network and an image translation network. The object generation network generates object images to reduce the burden on the image translation network for generating new objects. The image translation network performs image-to-image translation using local and global discriminators. Additionally, we introduced information loss () to guide the blending of object patches and clean images, and the background loss () to maintain the background information of the clean images.
A quantitative evaluation proved that compared to the original FiSmo dataset, that generated using RDAGAN can enhance the flame detection performance of the YOLOv5 model. In particular, the augmented dataset increased the object localization performance of the YOLOv5 model. Comparative evaluations showed that RDAGAN can not only generate realistic fire images but also confine the area of flame generation, whereas the baseline models cannot. The ablation studies revealed that the absence of one or more components of the RDAGAN can severely damage the model’s generation ability, which indicates the importance of all the components included in the RDAGAN.
In summary, RDAGAN can augment an object detection dataset in a relatively short time and at a low cost without requiring manual collection and labeling of new data to increase the size of the dataset.
Author Contributions
Conceptualization, H.L., S.K. and K.C.; methodology, H.L.; software, H.L. and S.K.; validation, H.L. and K.C.; investigation, H.L. and K.C.; resources, H.L.; data curation, H.L.; writing—original draft preparation, H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Institute for Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No. 2020-0-00959, Development of 5G Environments On-device IoT High-speed Intelligent HW and SW Engine Technology to Drones and Robots).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Liu, L.; Muelly, M.; Deng, J.; Pfister, T.; Li, L.J. Generative Modeling for Small-Data Object Detection. In Proceedings of the International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Higgins, I.; Amos, D.; Pfau, D.; Racaniere, S.; Matthey, L.; Rezende, D.; Lerchner, A. Towards a Definition of Disentangled Representations. arXiv 2018, arXiv:1812.02230. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal Unsupervised Image-to-image Translation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pang, Y.; Lin, J.; Qin, T.; Chen, Z. Image-to-Image Translation: Methods and Applications. IEEE Trans. Multimed. 2022, 24, 3859–3881. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive Learning for Unpaired Image-to-Image Translation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based Synthetic Medical Image Augmentation for Increased CNN Performance in Liver Lesion Classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Lv, N.; Ma, H.; Chen, C.; Pei, Q.; Zhou, Y.; Xiao, F.; Li, J. Remote Sensing Data Augmentation Through Adversarial Training. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9318–9333. [Google Scholar] [CrossRef]
- Ouyang, X.; Cheng, Y.; Jiang, Y.; Li, C.L.; Zhou, P. Pedestrian-Synthesis-GAN: Generating Pedestrian Data in Real Scene and Beyond. arXiv 2018, arXiv:1804.02047. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Sandro Campos, D.S. Aerial Fire Image Synthesis and Detection. In Proceedings of the International Conference on Agents and Artificial Intelligence, Online, 3–5 February 2022. [Google Scholar]
- Park, M.; Tran, D.Q.; Jung, D.; Park, S. Wildfire-Detection Method Using DenseNet and CycleGAN Data Augmentation-Based Remote Camera Imagery. Remote Sens. 2020, 12, 3715. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, T.; Bu, L.; Ouyang, J. Training with Augmented Data: GAN-based Flame-Burning Image Synthesis for Fire Segmentation in Warehouse. Fire Technol. 2022, 58, 183–215. [Google Scholar] [CrossRef]
- Qin, K.; Hou, X.; Yan, Z.; Zhou, F.; Bu, L. FGL-GAN: Global-Local Mask Generative Adversarial Network for Flame Image Composition. Sensors 2022, 22, 6332. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Li, Y.; Liu, S.; Yang, J.; Yang, M.H. Generative Face Completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Cazzolato, M.T.; Avalhais, L.P.S.; Chino, D.Y.T.; Ramos, J.S.; de Souza, J.A.; Rodrigues, J.F., Jr.; Traina, A.J.M. FiSmo: A Compilation of Datasets from Emergency Situations for Fire and Smoke Analysis. In Proceedings of the Brazilian Symposium on Databases, Uberlandia, Brazil, 4–7 October 2017. [Google Scholar]
- Weyand, T.; Araujo, A.; Cao, B.; Sim, J. Google Landmarks Dataset v2—A Large-Scale Benchmark for Instance-Level Recognition and Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; NanoCode012; Xie, T.; Kwon, Y.; Michael, K.; Changyu, L.; Fang, J.; et al. ultralytics/yolov5: v6.0–YOLOv5x ’XLarge’ models, Roboflow integration, TensorFlow export, OpenCV DNN support. Zenodo Tech. Rep. 2021. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}