
Corroded Bolt Identification Using Mask Region-Based Deep Learning Trained on Synthesized Data




Abstract
:1. Introduction
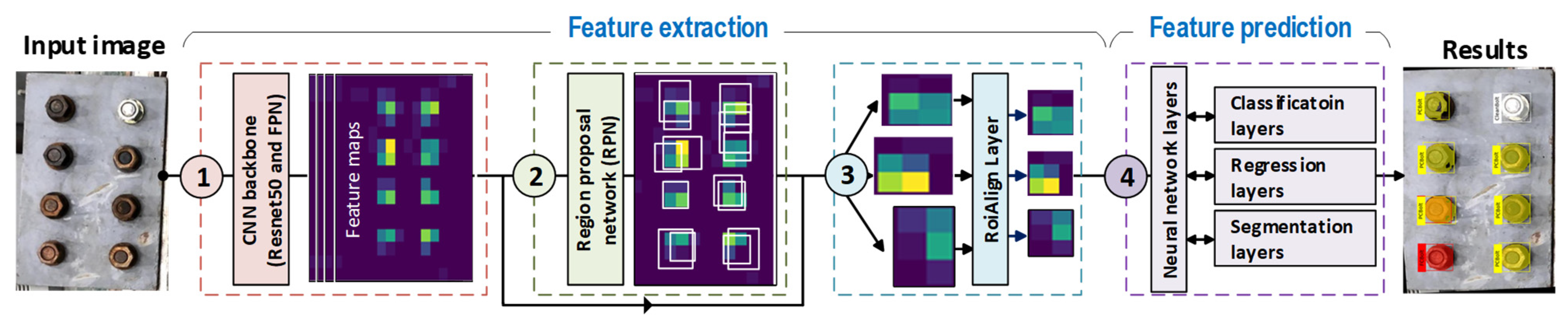
2. Mask-RCNN-Based Corroded Bolt Detector
2.1. Architecture of the Detector
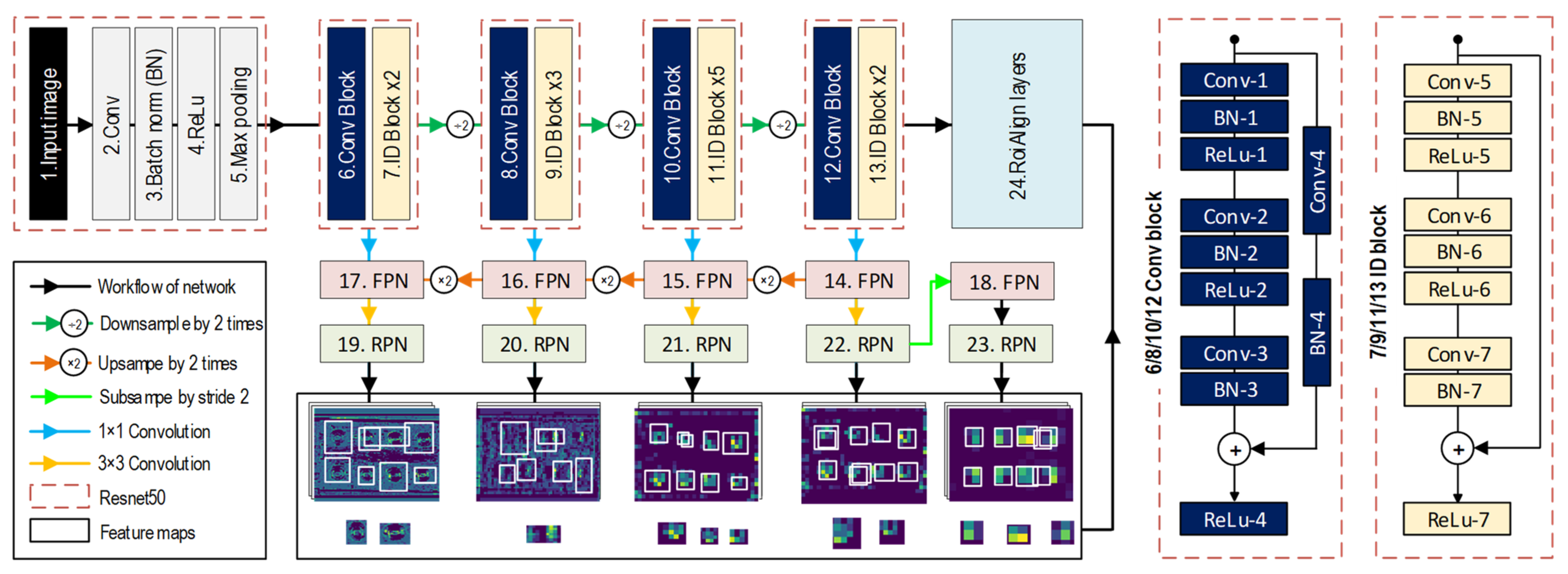
2.1.1. Feature Extraction Module
Resnet50-FPN
RPN
RoiAlign Layer
2.1.2. Feature Prediction Module and Loss Functions
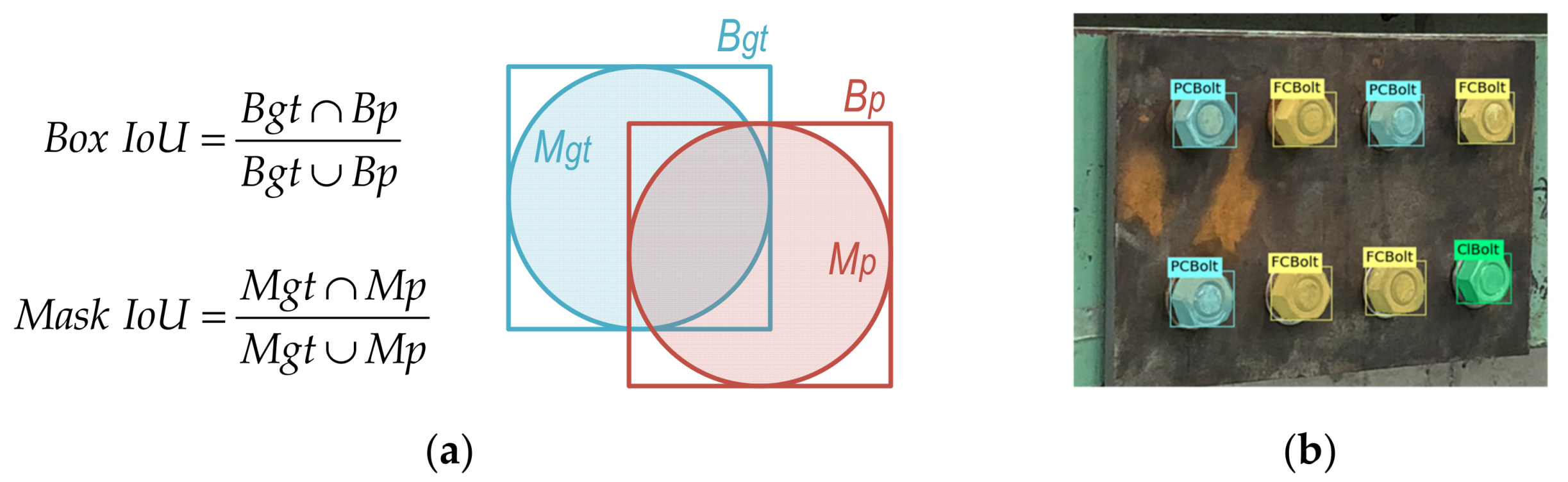
2.2. Evaluation Metrics
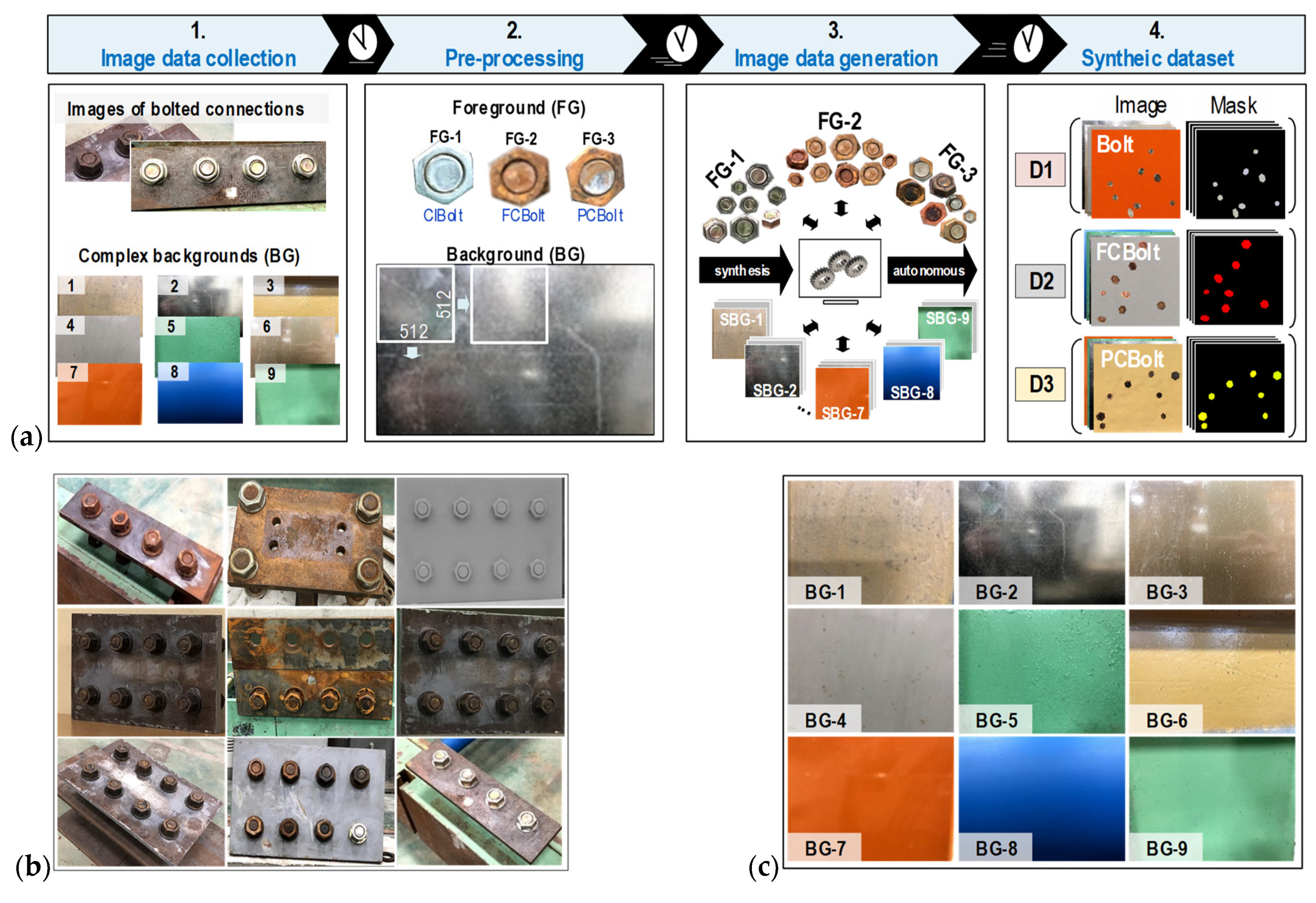
3. Synthesized Data Generation and Training Process
3.1. Synthesized Data Generation
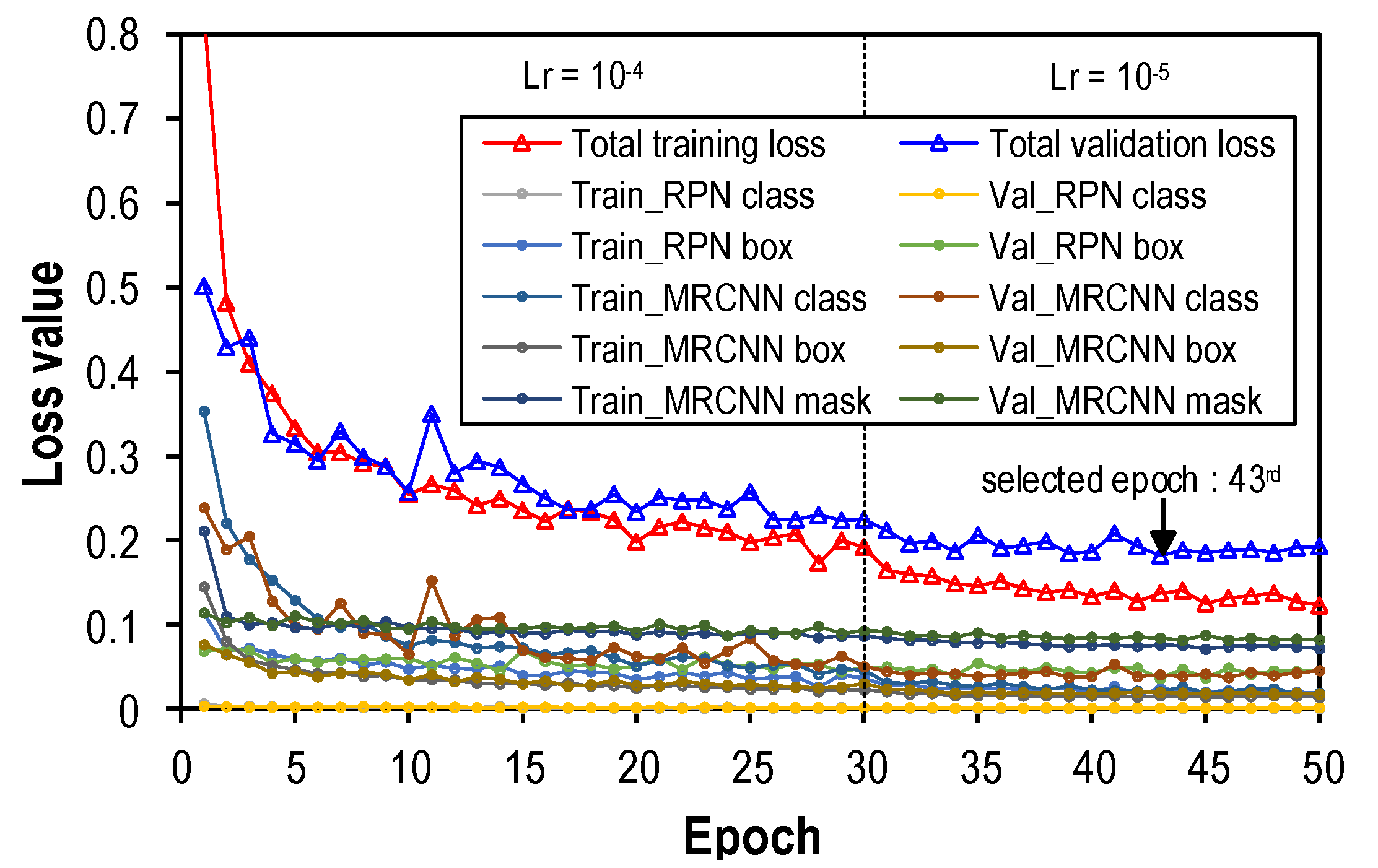
3.2. Training Process
4. Experiments on Bolted Girder Connections
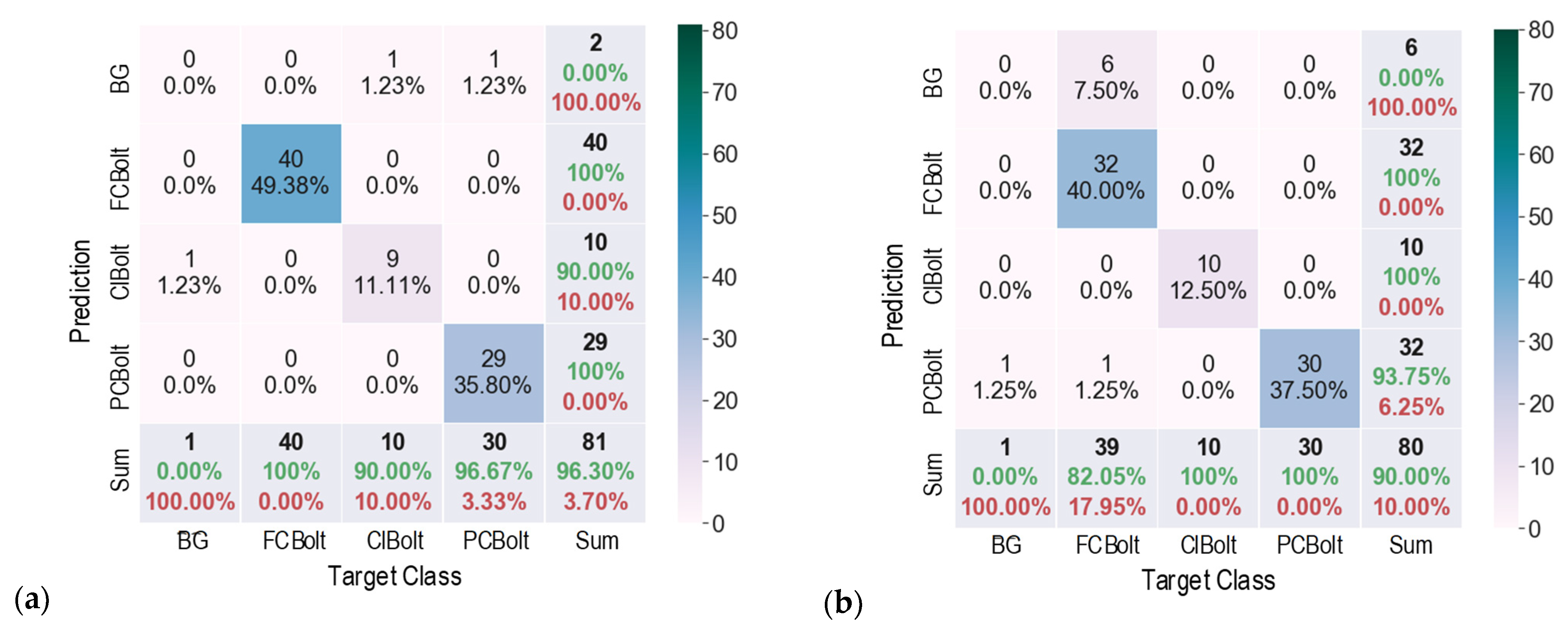
5. Corroded Bolt Detection Results
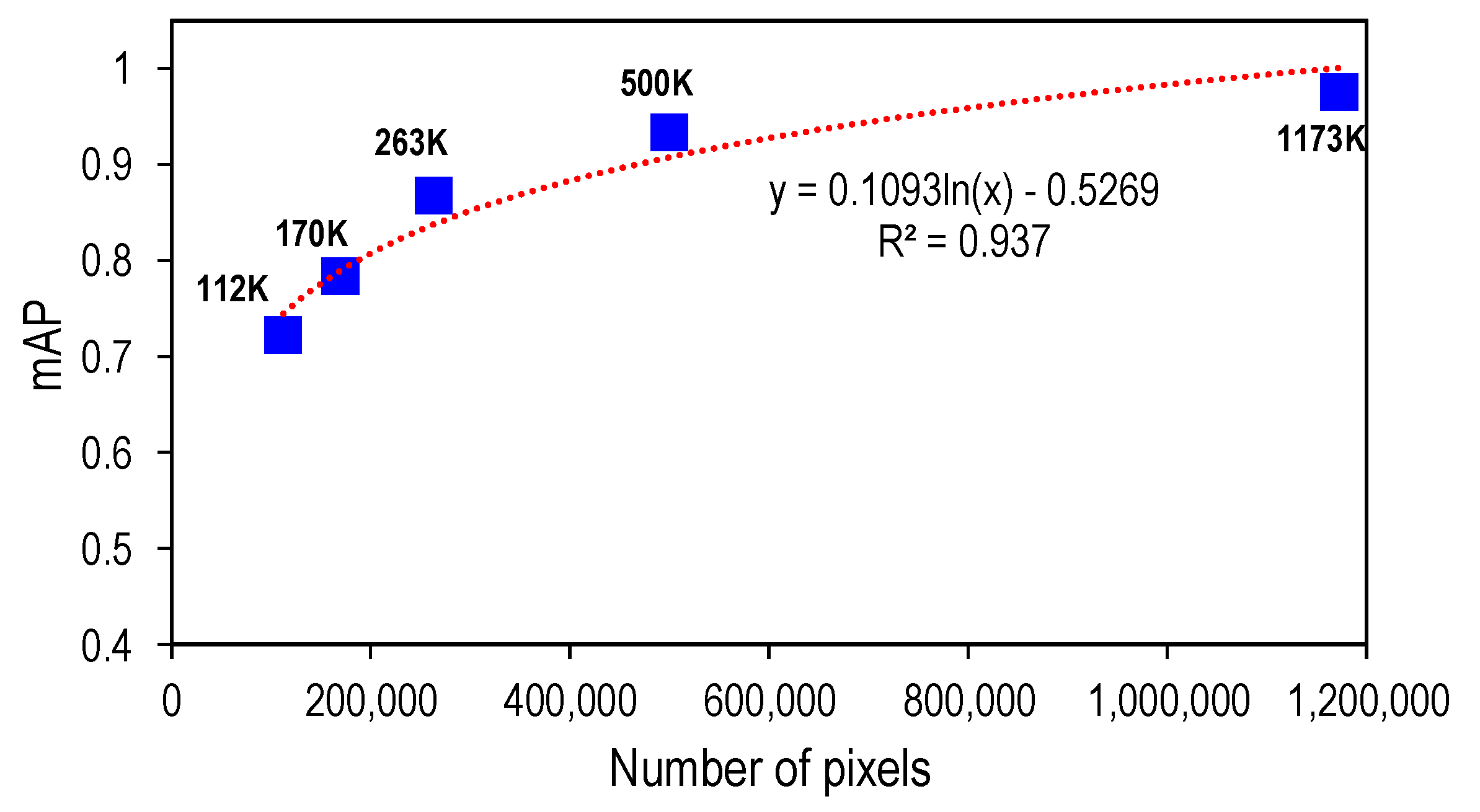
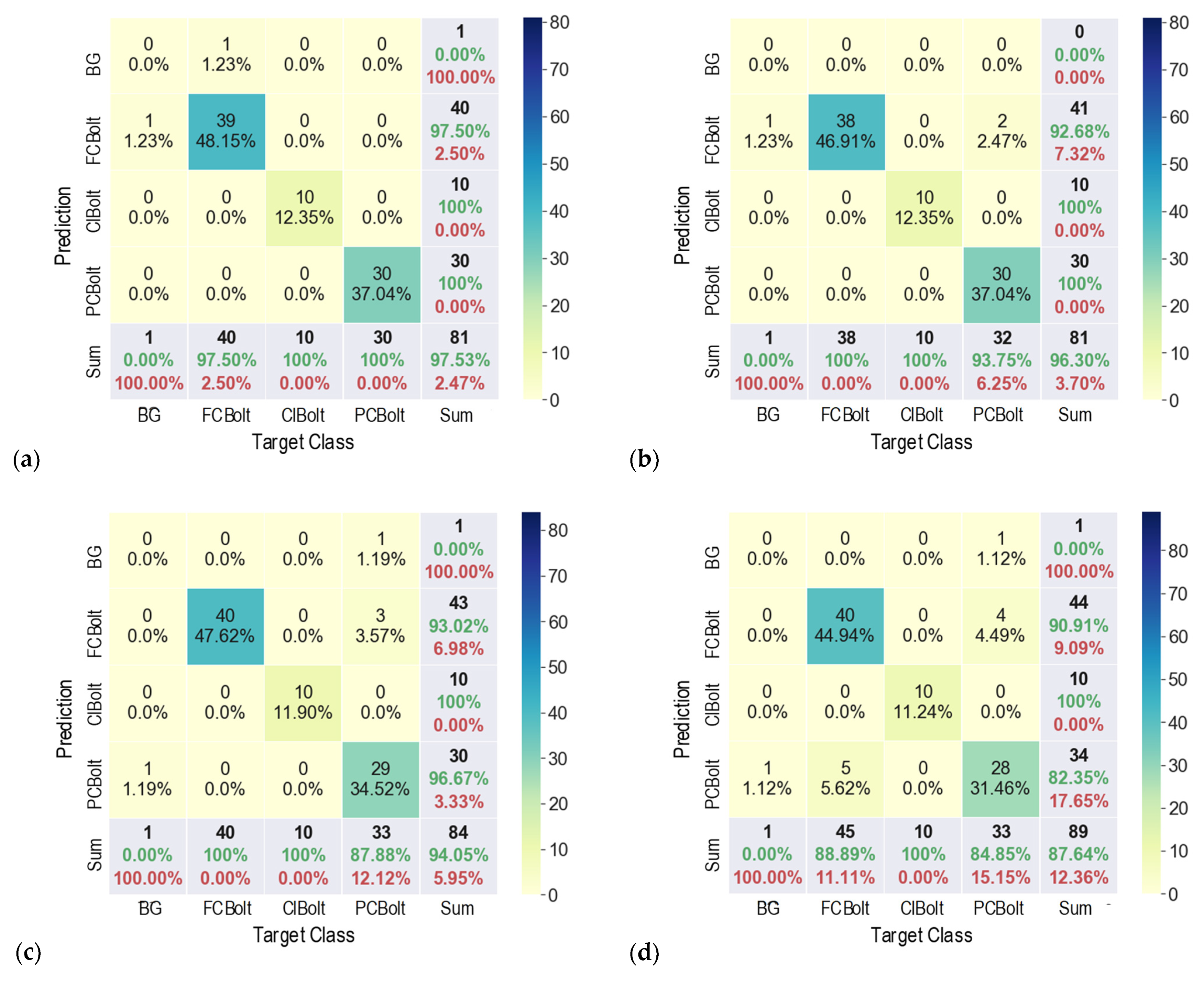
5.1. Corroded Bolt Detection under Various Capturing Distances
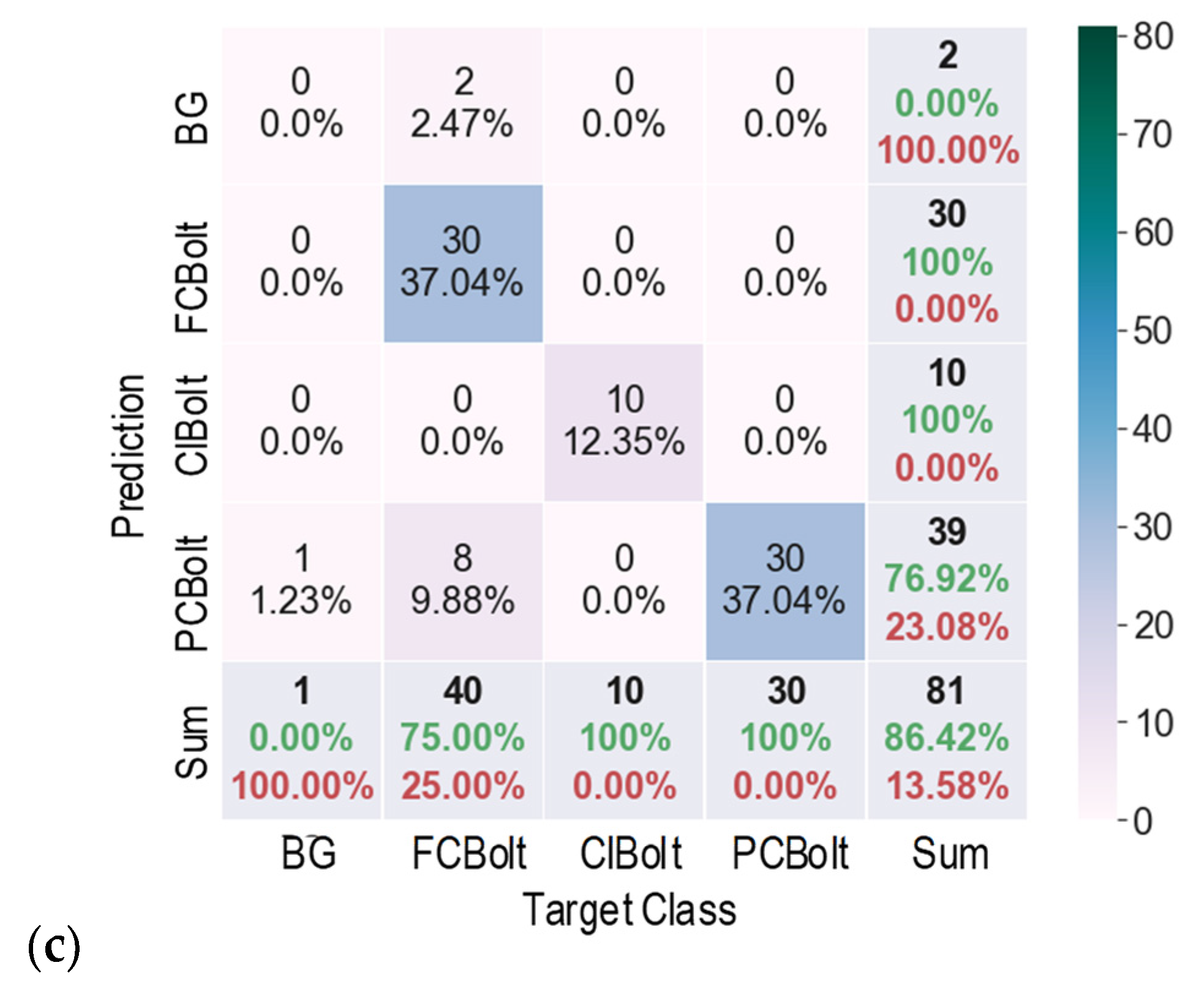
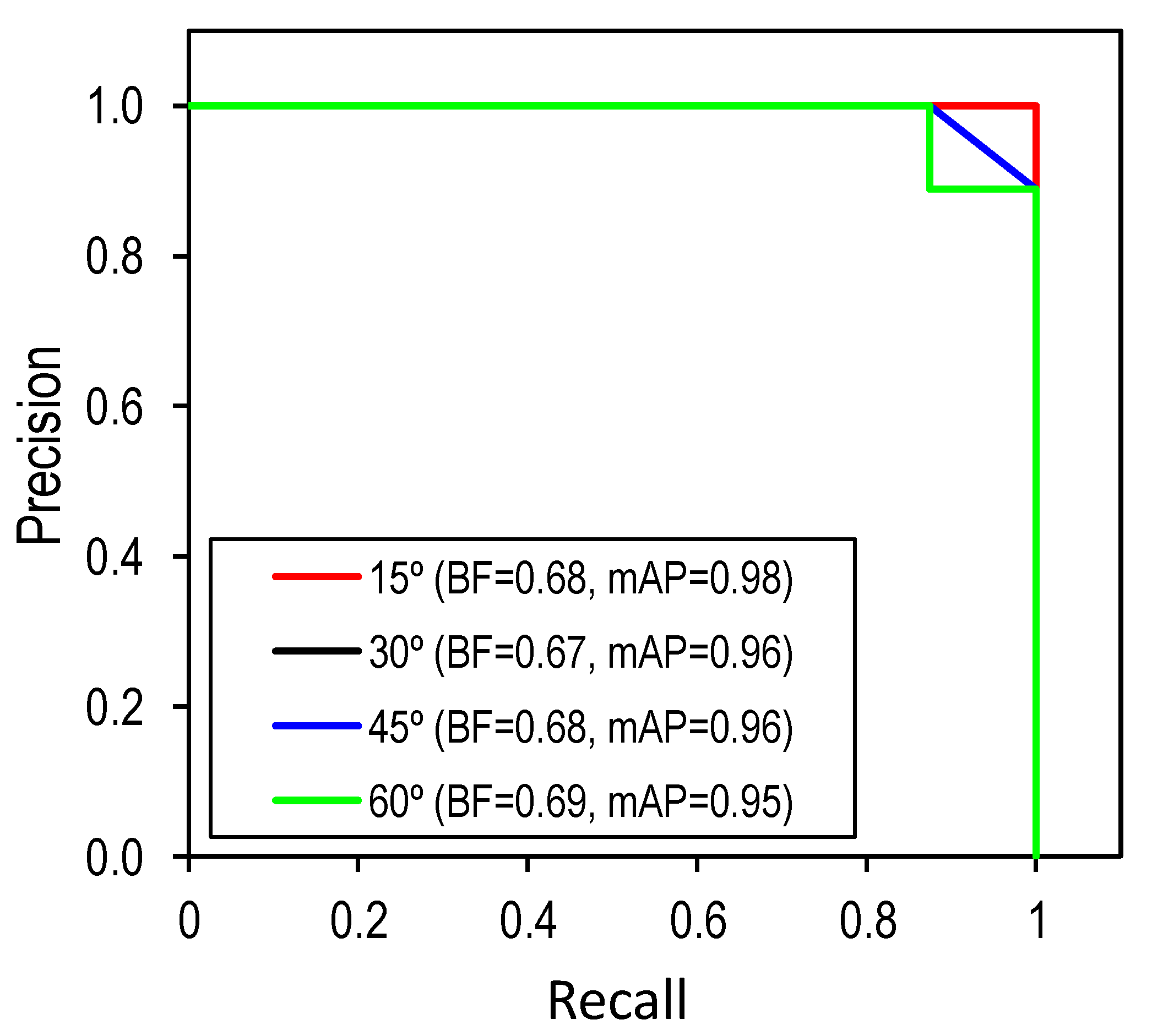
5.2. Corroded Bolt Detection under Various Perspective Distortions
6. Concluding Remarks
- (1)
- Clean bolt, partially and fully corroded bolts along with their corresponding masks were autonomously created by the proposed data synthesis method. The Mask-RCNN-based detector was successfully trained using the generated datasets.
- (2)
- The trained detector was accurate for corroded bolts in the tested structure. The corroded bolts and their corrosion levels were detected with the most desired accuracy of 96.3% for the 1.0-m capturing distance and 97.5% for the 15° perspective angle.
- (3)
- The number of pixels for the test image of the bolt connection should not be less than 263K to ensure the accuracy of the bolt identification results.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, T.; Song, G.; Liu, S.; Li, Y.; Xiao, H. Review of bolted connection monitoring. Int. J. Distrib. Sens. Netw. 2013, 9, 871213. [Google Scholar] [CrossRef]
- Reddy, M.S.B.; Ponnamma, D.; Sadasivuni, K.K.; Aich, S.; Kailasa, S.; Parangusan, H.; Ibrahim, M.; Eldeib, S.; Shehata, O.; Ismail, M.; et al. Sensors in advancing the capabilities of corrosion detection: A review. Sens. Actuators A Phys. 2021, 332, 113086. [Google Scholar] [CrossRef]
- Pidaparti, R.M. Structural corrosion health assessment using computational intelligence methods. Struct. Health Monit. Int. J. 2016, 6, 245–259. [Google Scholar] [CrossRef]
- Ye, X.-W.; Dong, C.-Z.; Liu, T. A review of machine vision-based structural health monitoring: Methodologies and applications. J. Sens. 2016, 2016, 7103039. [Google Scholar] [CrossRef] [Green Version]
- Spencer, B.F.; Hoskere, V.; Narazaki, Y. Advances in computer vision-based civil infrastructure inspection and monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Sun, L.; Shang, Z.; Xia, Y.; Bhowmick, S.; Nagarajaiah, S. Review of bridge structural health monitoring aided by big data and artificial intelligence: From condition assessment to damage detection. J. Struct. Eng. 2020, 146, 04020073. [Google Scholar] [CrossRef]
- Sidorov, M.; Nhut, P.V.; Matsumoto, Y.; Ohmura, R. LoRa-Based Precision Wireless Structural Health Monitoring System for Bolted Joints in a Smart City Environment. IEEE Access 2019, 7, 179235–179251. [Google Scholar] [CrossRef]
- Yang, J.; Chang, F.-K. Detection of bolt loosening in C–C composite thermal protection panels: II. Experimental verification. Smart Mater. Struct. 2006, 15, 591–599. [Google Scholar] [CrossRef]
- Blachowski, B.; Swiercz, A.; Pnevmatikos, N. Experimental verification of damage location techniques for frame structures assembled using bolted connections. In Proceedings of the 5th International Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Crete Island, Greece, 25–27 May 2015. [Google Scholar]
- Chen, D.; Huo, L.; Song, G. High resolution bolt pre-load looseness monitoring using coda wave interferometry. Struct. Health Monit. 2021. [Google Scholar] [CrossRef]
- Huynh, T.-C.; Dang, N.-L.; Kim, J.-T. Advances and Challenges in impedance-based structural health monitoring. Struct. Monit. Maint. 2017, 4, 301–329. [Google Scholar]
- Nguyen, T.-T.; Kim, J.T.; Ta, Q.B.; Ho, D.D.; Phan, T.T.V.; Huynh, T.C. Deep learning-based functional assessment of piezoelectric-based smart interface under various degradations. Smart Struct. Syst. 2021, 28, 69–87. [Google Scholar]
- Wang, P.; Zhang, N.; Kan, J.; Xie, Z.; Wei, Q.; Yao, W. Fiber Bragg Grating Monitoring of Full-bolt Axial Force of the Bolt in the Deep Strong Mining Roadway. Sensors 2020, 20, 4242. [Google Scholar] [CrossRef] [PubMed]
- Shabeeb, D.; Najafi, M.; Hasanzadeh, G.; Hadian, M.R.; Musa, A.E.; Shirazi, A. Electrophysiological measurements of diabetic peripheral neuropathy: A systematic review. Diabetes Metab. Syndr. 2018, 12, 591–600. [Google Scholar] [CrossRef] [PubMed]
- Park, J.H.; Huynh, T.C.; Choi, S.H.; Kim, J.T. Vision-based technique for bolt-loosening detection in wind turbine tower. Wind Struct. 2015, 21, 709–726. [Google Scholar] [CrossRef]
- Yu, T.; Gyekenyesi, A.L.; Shull, P.J.; Wu, H.F.; Nguyen, T.-C.; Huynh, T.-C.; Ryu, J.-Y.; Park, J.-H.; Kim, J.-T. Bolt-loosening identification of bolt connections by vision image-based technique. In Proceedings of the Nondestructive Characterization and Monitoring of Advanced Materials, Aerospace, and Civil Infrastructure, Las Vegas, NV, USA, 21–24 March 2016. [Google Scholar]
- Cha, Y.-J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Huynh, T.-C.; Nguyen, B.-P.; Pradhan, A.M.S.; Pham, Q.-Q. Vision-based inspection of bolted joints: Field evaluation on a historical truss bridge in Vietnam. Vietnam J. Mech. 2020, 55, 77. [Google Scholar] [CrossRef]
- Tomasi, C.; Kanade, T.J. Detection and tracking of point. Int. J. Comput. Vis. 1991, 9, 137–154. [Google Scholar] [CrossRef]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object detection and recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020. [Google Scholar]
- Kazemi, N.; Abdolrazzaghi, M.; Musilek, P. Comparative Analysis of Machine Learning Techniques for Temperature Compensation in Microwave Sensors. IEEE Trans. Microw. Theory Tech. 2021, 69, 4223–4236. [Google Scholar] [CrossRef]
- Nguyen, T.-T.; Tuong Vy Phan, T.; Ho, D.-D.; Man Singh Pradhan, A.; Huynh, T.-C. Deep learning-based autonomous damage-sensitive feature extraction for impedance-based prestress monitoring. Eng. Struct. 2022, 259, 114172. [Google Scholar] [CrossRef]
- Huynh, T.C.; Park, J.H.; Jung, H.J.; Kim, J.-T. Quasi-autonomous bolt-loosening detection method using vision-based deep learning and image processing. Autom. Constr. 2019, 105, 102844. [Google Scholar] [CrossRef]
- Ta, Q.B.; Kim, J.T. Monitoring of corroded and loosened bolts in steel structures via deep learning and Hough transforms. Sensors 2020, 20, 6888. [Google Scholar] [CrossRef]
- Huynh, T.-C. Vision-based autonomous bolt-looseness detection method for splice connections: Design, lab-scale evaluation, and field application. Autom. Constr. 2021, 124, 103591. [Google Scholar] [CrossRef]
- Pan, X.; Yang, T.Y. Image-based monitoring of bolt loosening through deep-learning-based integrated detection and tracking. Comput.-Aided Civ. Infrastruct. Eng. 2021. [Google Scholar] [CrossRef]
- Yang, X.; Gao, Y.; Fang, C.; Zheng, Y.; Wang, W. Deep learning-based bolt loosening detection for wind turbine towers. Struct. Control Health Monit. 2022, 29, e2943. [Google Scholar] [CrossRef]
- Chun, P.J.; Yamane, T.; Maemura, Y. A deep learning-based image captioning method to automatically generate comprehensive explanations of bridge damage. Comput.-Aided Civ. Infrastruct. Eng. 2021. [Google Scholar] [CrossRef]
- Pham, H.C.; Ta, Q.B.; Kim, J.T.; Ho, D.D.; Tran, X.L.; Huynh, T.C. Bolt-loosening monitoring framework using an image-based deep learning and graphical model. Sensors 2020, 20, 3382. [Google Scholar] [CrossRef]
- Hoskere, V.; Narazaki, Y.; Spencer, B.F.; Smith, M.D. Deep learning-based damage detection of miter gates using synthetic imagery from computer graphics. In Proceedings of the 12th International Workshop on Structural Health Monitoring: Enabling Intelligent Life-Cycle Health Management for Industry Internet of Things (IIOT), IWSHM 2019, Stanford, CA, USA, 10–12 September 2019. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep Convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Available online: https://image-net.org/challenges/LSVRC/2015/index (accessed on 4 January 2022).
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A.J. The PASCAL visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Georgakis, G.; Mousavian, A.; Berg, A.C.; Kosecka, J.J.A.P.A. Synthesizing training data for object detection in indoor scenes. arXiv 2017, arXiv:1702.07836. [Google Scholar]
- Inoue, T.; Choudhury, S.; De Magistris, G.; Dasgupta, S. Transfer learning from synthetic to real images using variational autoencoders for precise position detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Da Silva, L.A.; Bressan, P.O.; Gonçalves, D.N.; Freitas, D.M.; Machado, B.B.; Gonçalves, W.N. Estimating soybean leaf defoliation using convolutional neural networks and synthetic images. Comput. Electron. Agric. 2019, 156, 360–368. [Google Scholar] [CrossRef]
- Zhang, Y.; Yi, J.; Zhang, J.; Chen, Y.; He, L. Generation of Synthetic Images of Randomly Stacked Object Scenes for Network Training Applications. Intell. Autom. Soft Comput. 2021, 27, 425–439. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, J.; Jiang, H.; Fan, X. CNN training with twenty samples for crack detection via data augmentation. Sensors 2020, 20, 4849. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014, 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 4th ed.; Pearson: New York, NY, USA, 2018; Available online: https://www.imageprocessingplace.com (accessed on 4 March 2022).
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Salman, S.; Liu, X.J.a.P.A. Overfitting mechanism and avoidance in deep neural networks. arXiv 2019, arXiv:1901.06566. [Google Scholar]
- Toda, Y.; Okura, F.; Ito, J.; Okada, S.; Kinoshita, T.; Tsuji, H.; Saisho, D. Training instance segmentation neural network with synthetic datasets for crop seed phenotyping. Commun. Biol. 2020, 3, 173. [Google Scholar] [CrossRef] [Green Version]
- Yuan, C.; Chen, W.; Hao, H.; Kong, Q. Near real-time bolt-loosening detection using mask and region-based convolutional neural network. Struct. Control Health Monit. 2021, 28, e2741. [Google Scholar] [CrossRef]
- Available online: https://www.tensorflow.org/ (accessed on 4 January 2022).
- Available online: https://keras.io/ (accessed on 15 January 2022).
- Available online: https://opencv.org/ (accessed on 4 November 2021).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Type | Depth | Filter Size | Stride | Padding | Output Image Size |
|---|---|---|---|---|---|---|
| 1 | Input | 3 | - | - | - | [w × h] * |
| 2 | Conv | 64 | 7 × 7 | 2 | 3 | [w/2 × h/2] |
| 3 | Batch norm | - | - | - | - | [w/2 × h/2] |
| 4 | ReLu | - | - | - | - | [w/2 × h/2] |
| 5 | Max pool | 64 | 3 × 3 | 2 | 2 | [w/4 × h/4] |
| 6/8/10/12. Conv block | Conv-1 | 64/128/256/512 | 1 × 1 | 1/2/2/1 | 0/0/2/0 | [w/4 × h/4] for block #6 [w/8 × h/8] for block #8 [w/16 × h/16] for block #10 [w/32 × h/32] for block #12 |
| BN-1 | - | - | - | - | ||
| ReLu-1 | - | - | - | - | ||
| Conv-2 | 64/128/256/512 | 3 × 3 | 1 | 1 | ||
| BN-2 | - | - | - | - | ||
| ReLu-2 | - | - | - | - | ||
| Conv-3 | 256/512/1024/2048 | 1 × 1 | 1 | 0 | ||
| BN-3 | - | - | - | - | ||
| ReLu-4 | - | - | - | - | ||
| Conv-4 | 256/512/1024/2048 | 1 × 1 | 1/2/2/1 | 0/0/2/0 | ||
| BN-4 | - | - | - | - | ||
| 7/9/11/13. ID Block | Conv-5 | 64/128/256/512 | 1 × 1 | 1 | 0 | [w/4 × h/4] for block #7 [w/8 × h/8] for block #9 [w/16 × h/16] for block #11 [w/32 × h/32] for block #13 |
| BN-5 | - | - | - | - | ||
| ReLu-5 | - | - | - | - | ||
| Conv-6 | 64/128/256/512 | 3 × 3 | 1 | 1 | ||
| BN-6 | - | - | - | - | ||
| ReLu-6 | - | - | - | - | ||
| Conv-7 | 256/512/1024/2048 | 1 × 1 | 1 | 0 | ||
| BN-7 | - | - | - | - | ||
| ReLu-7 | - | - | - | - |
| Raw Images | Foreground (FG) | Sub-Background (SBG) | Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Image | BG | FG-1 | FG-2 | FG-3 | D1 | D2 | D3 | ||
| Number of images | 568 | 9 | 566 | 332 | 865 | 414 * | 1875 | 1875 | 1875 |
| Size | 3024 × 4032 × 3 | 34 × 42 × 3–173 × 187 × 3 | 512 × 512 × 3 | 512 × 512 × 3 | |||||
| Color | RGB ** | RGBA ** | RGB | RGB | |||||
| Format | .jpeg | .png | .jpeg | .jpeg | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ta, Q.-B.; Huynh, T.-C.; Pham, Q.-Q.; Kim, J.-T. Corroded Bolt Identification Using Mask Region-Based Deep Learning Trained on Synthesized Data. Sensors 2022, 22, 3340. https://doi.org/10.3390/s22093340
Ta Q-B, Huynh T-C, Pham Q-Q, Kim J-T. Corroded Bolt Identification Using Mask Region-Based Deep Learning Trained on Synthesized Data. Sensors. 2022; 22(9):3340. https://doi.org/10.3390/s22093340
Chicago/Turabian StyleTa, Quoc-Bao, Thanh-Canh Huynh, Quang-Quang Pham, and Jeong-Tae Kim. 2022. "Corroded Bolt Identification Using Mask Region-Based Deep Learning Trained on Synthesized Data" Sensors 22, no. 9: 3340. https://doi.org/10.3390/s22093340