1. Introduction
The International Energy Agency has identified energy efficiency in buildings as one of the five methods to secure long-term decarbonization of the energy sector [
1]. In addition to environmental benefits, the improvement of the building energy efficiency also presents vast economic benefits. Buildings with efficient energy systems and management strategies have much lower operating costs [
2]. The activities of humans in residences occupy a large portion of energy consumption and CO
2 emission [
3]. Residential load forecasting can assist sectors in balancing the generation and consumption of electricity, which improves energy efficiency through the management and conservation of energy.
Several uncertain factors, such as historical load records, weather conditions, population mobilities, social factors and emergencies, influence electricity usage. Due to the high volatility and uncertainties involved, short-term load forecasting for a single residential unit may be more challenging than for an industrial building [
4]. Machine-learning-based methods, driven by data, are applied to mitigate these challenges more and more frequently. However, the scope of machine-learning-based applications will be hindered due to the privacy and security concerns raised by more and more supervision departments and users. Even in some countries, many users refuse the installation of smart meters because users are reluctant to disclose their private data. In addition, newly built houses cannot provide sufficient data to build effective models. In summary, the data exist in the form of isolated islands, which makes it difficult to merge the data from different users to train a robust model. Hence, one of the problems in this paper we focused on is data availability and privacy.
A number of researches have achieved good results on STLF, such as support vector regression (SVR) [
5], the artificial neural network [
6] and boosted tree [
7]. Additionally, some hybrid methods that combine artificial intelligence methods with traditional methods are proposed to achieve better forecasting performance, such as hybridizing extended Kalman Filter and ELM [
8]. Fan et al. [
9] proposed a SVR model hybridized with differential empirical mode decomposition (DEMD) method and auto regression (AR) for electric load forecasting. Transformer is a novel time series prediction model based on the encoder–decoder structure. Originating from this structure, many methods have yielded good results in the field of energy forecasting, such as STA-AED [
10] and informer [
11]. However, these approaches do not consider user privacy and modeling with limited data.
A lot of privacy-preserving solutions relying on data aggregation and obfuscation have been proposed to ensure privacy [
12]. However, these solutions are not suitable for residential short-term energy forecasting since they often introduce extra procedures to obfuscate and reconstruct the data [
13]. In addition, as the solutions based on machine learning are computationally intensive in the step of model training, most works consider only centralized training approaches. Clients’ data should be collected onto a central server where the model is trained, which leads to a heavy burden on communication. Especially when the model needs to be constantly updated with new data, as the data from millions of distributed meters are required. Under this circumstance, federated learning has been proposed to overcome these challenges. Federated Learning is a distributed machine learning approach where a shared global model is trained, under the coordination of a central entity, by a federation of participating devices [
14]. The peculiarity of the approach is that each device trains a local model with the data never leaving each local machine. Only the parameters of models are sent to the central computing server for updating the shared global model. Hence, the federated architecture can protect privacy effectively. Federated learning has been demonstrated to be effective in the area of load forecasting, federated learning with clustered aggregation is proposed in [
15], and has good performance for individual load forecasting. Federated learning applied in heating load demand prediction of buildings also has a high capability of producing produce acceptable forecasts while preserving data privacy and eliminating the dependence of the model on the training data [
16]. Furthermore, federated learning has been applied in several application successfully, such as human–computer interaction [
17], natural language processing [
18], healthcare classification [
19], transportation [
20,
21], and so on, where privacy and scalability are essential.
Another critical problem for residential load forecasting is that the general model is not adapted to each house since the datasets are non-IID, which the federated architecture and conventional machine learning algorithms do not well handle with [
22]. The problem is particularly acute in the case of newly built houses. Even though the dataset bias and unbalance are inevitable [
23], many researchers classify users according to different attributes to deal with this challenge, but it does not fit well with a federated learning architecture [
24]. This situation is particularly suitable for applying transfer learning. Transfer learning aims at establishing knowledge transfer to bridge different domains of substantial distribution discrepancies. In other words, data from different houses have domain discrepancies which is a major obstacle in adapting the predictive model across users. STLF models based on transfer learning are discussed in [
4,
25,
26].
A representative transfer learning method is domain adaptation, which can leverage the data in the information-rich source domain to enhance the performance of the model in the data-limited target domain. As a well-known algorithm applied for domain adaptation, deep neural network [
27] is capable of discovering factors of variations underlying the houses’ historical data, and group features hierarchically in accordance with their relatedness to invariant factors, and it has been studied extensively. A lot of research has shown that deep neural networks can learn more transferable features for domain adaptation [
28]. It is shown that deep features must eventually transition from general to specific in the network, with the transferability of features decreasing significantly at higher levels as domain discrepancies increase. In other words, the common features between different users are captured in lower layers, and the features of the specific user hide in higher layers which depend greatly on the target datasets and are not safely transferable to another user.
In this article, we address the aforementioned challenges within a novel user adaptative load forecasting approach. The approach is the combination of federated learning and transfer learning. The architecture of federated learning in this approach aims at building a CNN-LSTM based general model, which does not compromise privacy and works well with the limited data. Then, MK-MMD, a distance to measure domain discrepancies, is used to calculate the domain discrepancies between houses, then optimize the general network which can reduce the domain discrepancies effectively and reduce the forecasting error. The contributions of this paper are summarized as follows:
We propose a novel federated transfer approach DFA for residential STLF, which adopts a federated architecture to address the problems of data availability and privacy, and leverages transfer learning to deal with the non-IID datasets for improving forecasting performance;
DFA is investigated for STLF of residential houses and has shown remarkable advantages in forecasting performance over other baseline models. Especially, the federated architecture is superior to the centralized architecture in computation time;
The framework of DFA is extended with alternative transfer learning methods and all of them achieve good performances on STLF.
2. Technical Background
2.1. Federated Learning Concepts
Due to security and privacy concerns, data exist in the form of isolated islands, making it difficult for data-driven models to leverage big data. One possible approach is federated learning, which can train a machine learning model in a distributed way.
Let matrix denote the data held by the partner i, each row of the matrix represents one sample, and each column is a feature. Since the feature and sample spaces of the data parties may not be identical, federated learning can be classified into three classes: horizontally federated learning, vertically federated learning and federated transfer learning.
Horizontal federated learning is applicable in the conditions in which different partners have the same or overlapped feature spaces but different spaces in samples. It is similar to the case of dividing data horizontally in a tabular view, hence horizontal federated learning is also known as sample-partitioned federated learning. Horizontal federated learning can be summarized as Formula (1):
let
,
,
denote the feature space, the label space and the sample ID space.
Different from horizontal federated learning, partners in the vertically federated learning share the same spaces in samples, but different ones in feature spaces. We can summarize vertically federated learning as shown in Formula (2):
Federated transfer learning is applied in the conditions in which datasets differ not only in sample spaces but also in feature spaces. For example, a common representation or model is learned from different feature spaces and later used to make predictions for samples with only one-side features. Federated transfer learning is summarized as shown in Formula (3):
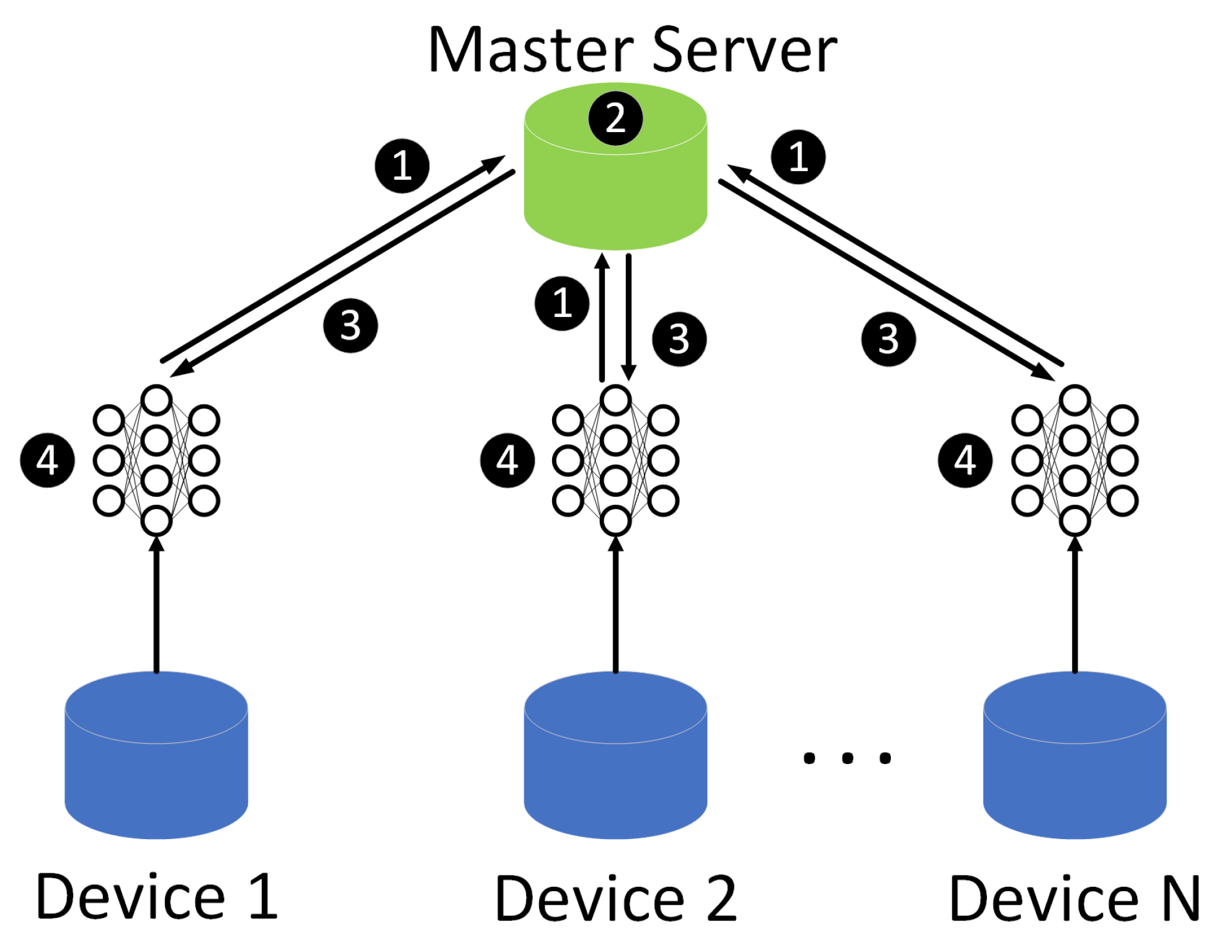
In this paper, the federated learning framework is a horizontal federated learning architecture since the data collected by devices is in the same feature space. It uses a master–slave architecture, as shown in
Figure 1. In this system, N participant devices collaborate to train a machine learning model with the help of the master server.
In step 1, each participant computes the model gradient locally and masks the gradient information using cryptographic techniques such as homomorphic encryption, and sends the results to the master server. In step 2, the master server performs a secure aggregation operation. In step 3, the server distributes the aggregated results to each participant. In step 4, each participant decrypts the received gradients and updates their respective model parameters using the decrypted gradients. The above steps continue iteratively until the loss function converges or the maximum number of iterations is reached. We can see that the data of the participants are not moved during the training process, so the federated learning can protect user privacy that distributed machine learning models trained on Hadoop do not have. In the training process, an arbitrary number of devices can concur to model training without the need of transferring collected data to a centralized location. The federated model can tackle the increasing data without consideration of communication bandwidth since only local gradients need to be sent.
2.2. Transfer Learning Concepts and MK-MMD
Firstly, it is hard to collect sufficient data from domains of interest, referred to as target domains. Meanwhile, a large number of data may be available for some related domains called source domains. Secondly, machine learning algorithms work well based on a fundamental assumption: the training and future data must be in the same feature space and follow the same distribution. However, this assumption is not held in real-world applications. For these reasons, transfer learning is introduced to address these problems. Transfer learning can leverage similarities between data, tasks, or models to conduct knowledge transfer from the source domain to the target domain. These similarities are considered a representation of the distance between domains. Then the key issue is to introduce the standard distribution distance metric and minimize the distance.
MK-MMD is a type of distance metrics. This distance is computed with respect to a particular representation
, a feature map function. This function can map the original data into a reproducing kernel Hilbert space (RKHS) endowed with a characteristic kernel
k. The RKHS may be infinite dimensions that can transform non-separable data to linearly separable. The distance between the source domain with probability
p and the target domain with probability
q is defined as
. The data distribution
iff
. Then, the squared expression of MK-MMD distance [
29] is denoted as Formula (4):
where
denotes the RKHS endowed with a characteristic kernel
k.
Kernel technique, as Formula (5) shows, can be used to compute Formula (4), which can convert the computation of the inner product of the feature map
to computing the the kernel function
instead.
As mean embedding matching is sensitive to the kernel choices, MK-MMD uses multi-kernel k to provide better learning capability and alleviate the burden of designing specific kernels to handle diverse multivariate data. It provides more flexibility to capture different kernels and leads to a principled method for optimal kernel selection.
Multi-kernel
is defined as the convex combination of kernels
as in Formula (6) [
28]:
where the constraints on coefficients
make the derived multi-kernel
k characteristic.
4. Experiments
4.1. Datasets Description and Pre-Processing
The experimental datasets are electricity consumption readings for a sample of 5567 London Households that took part in the UK Power Networks led Low Carbon London project between November 2011 and February 2014. Readings were taken at half-hourly intervals. The customers in the trial were recruited as a balanced sample representative of the Greater London population. The dataset contains electricity consumption, in kWh (per half hour), unique household identifier, date and time [
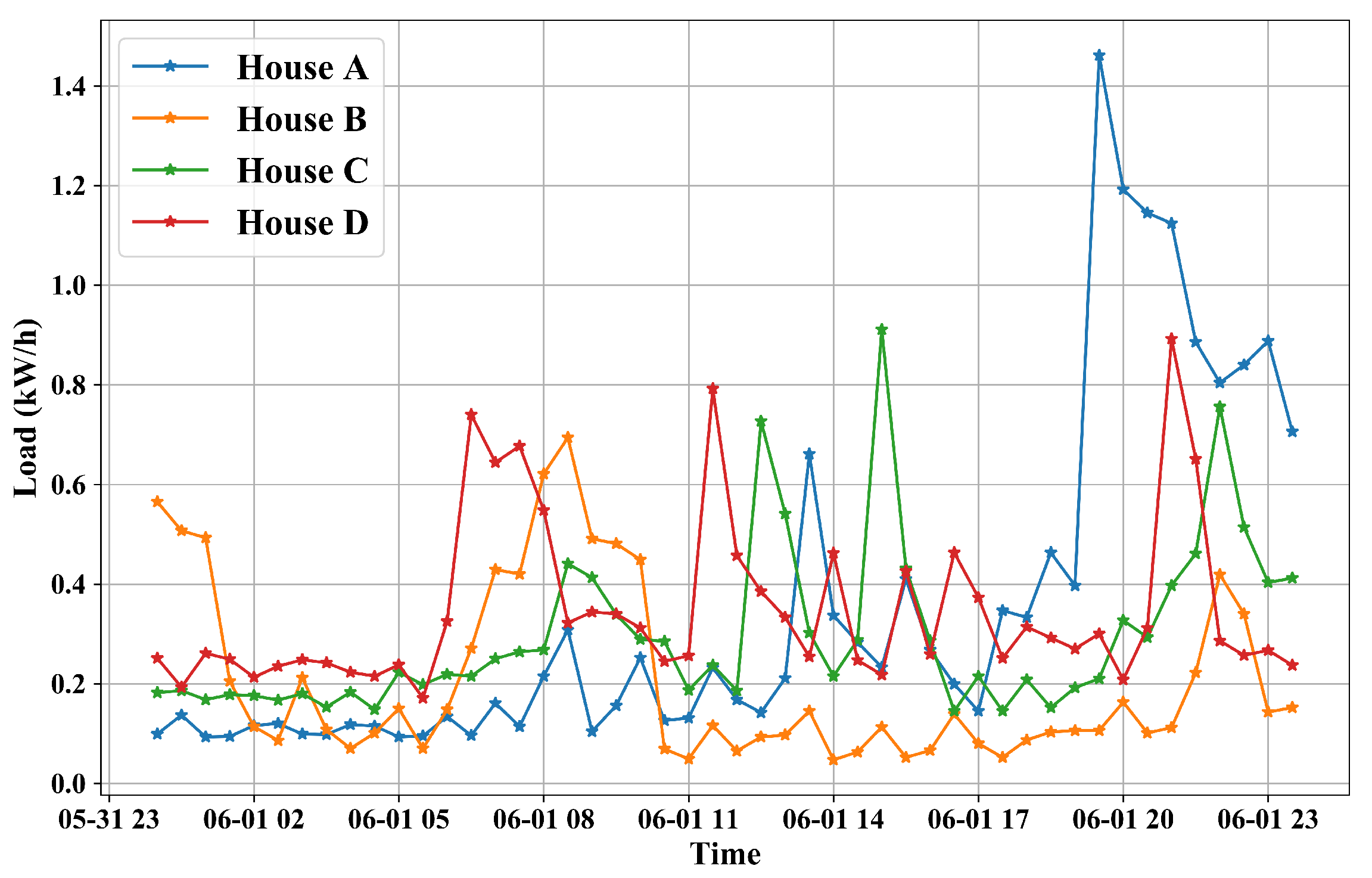
32]. As an example, a period of records from 4 households are shown in
Figure 4. It can be seen that the records are in different patterns which means a general model is not suitable for forecasting electricity consumption for a particular house. Meteorological variables recorded in London collected from Dark Sky API [
33] are introduced to enrich our datasets. We merge electricity consumption datasets and meteorological datasets in terms of timestamps to generate a new feature table for each household.
Some discrete features (e.g., ’weekday’, ’icon’) should be encoded to embedding features. Then, feature normalization is implemented for all features with min–max normalization, as shown in Formula (13):
where
denotes the value for feature
i at the time step
j,
and
denote the maximal and minimal value for feature
i, respectively.
is the value for
after normalization.
We consider the feature table as time-series data according to the timestamps, each row of the table denotes a record sampled at half-hourly intervals. We implement a sliding window with a look back at 24 records to forecast the next record. Hence, the proposed network can give a half-an-hour-later load value prediction, one training sample consists of features of 24 records and the value of the next electricity consumption. The input dimension is , where is the number of expected features in the merged table , L denotes the width of the sliding window.
4.2. Implementation Information
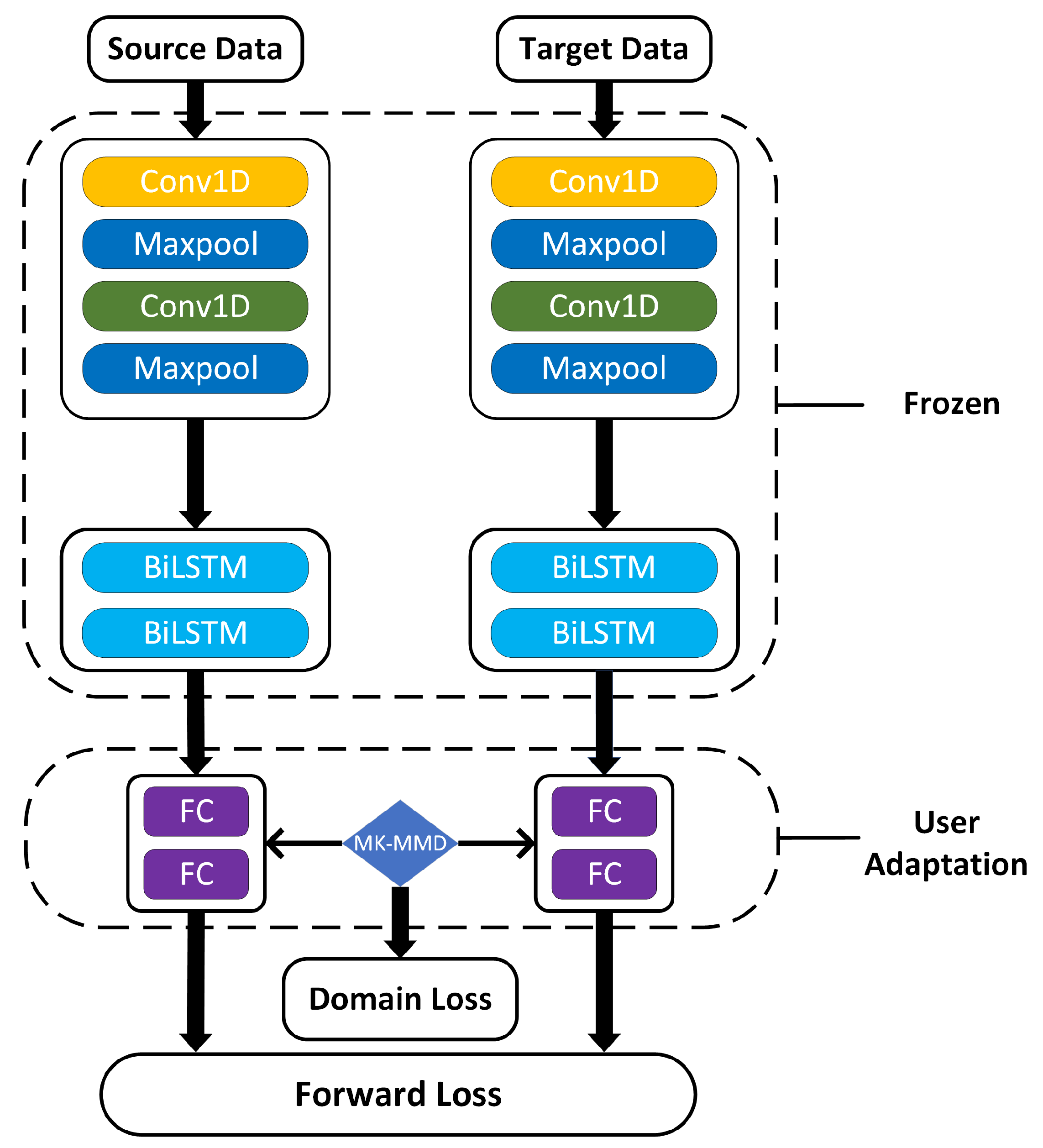
The proposed network is composed of two convolutional layers, two pooling layers, two BiLSTM layers and two FC layers. The network adopts a convolution size of and a kernel size of 3 for pooling layers. The proposed network is trained with the MSE loss and adopts stochastic gradient descent (SGD) with an initial learning rate of 0.01 and 0.9 momentum for optimization. Batch size is set to 32. The training process is early stopped within 10 epochs and the rate of dropout is set to 0.1 to prevent overfitting.
In the following experiments, cross validation and grid search are used to select the hyperparameters and the hyperparameters with the lowest average forecasting MAPE will be used. During the training process, we use 70% of the data for training while the rest 30% is for evaluation. All experiments are repeated five times to ensure reliability, implemented in Pytorch, and conducted on a single NVIDIA GeForce RTX 2080 GPU.
A single machine is used to simulate the federated learning process and we can set the number of user nodes
according to the experimental requirements.
Table 1 shows some symbol definitions of the experiments. Since a single machine is used to simulate the federated process, the training process is serial. However, this has no effect on comparing model forecasting accuracy and computation time between the federated architecture and the centralized architecture. Centralized learning means data are gathered from all devices to train a single model on the central server, which does not secure the privacy of users.
To evaluate the forecasting performance of DFA, four baseline models are used for comparison purposes. The following are simple introductions for these models.
LSTM network: the model is an artificial recurrent neural network (RNN) architecture with feedback connections used in the field of deep learning.
Double seasonal Holt–Winters (DSHW): DSHW is a kind of exponential smoothing method which can accommodate two seasonal patterns besides parts of trend and level.
Transformer: it is a deep learning model that adopts the mechanism of self-attention, differentially weighting the significance of each part of the input data.
Encoder–Decoder: the model encodes the input as embedding features which are decoded by the decoder, adopting a sequence-to-sequence architecture.
4.3. Model Evaluation Indexes
The mean absolute percentage error (MAPE) is used to evaluate forecasting accuracy. The evaluation equations are defined as shown in Formula (14):
where
is the forecast load consumption value,
is the actual load consumption value and
N is the total number of sampling points for evaluation.
To evaluate whether a particular model
m has skill with respect to a baseline model
r the MAE ratio, we use skill score, as shown in Formula (15):
where
is the mean absolute error.
is calculated as shown in Formula (16):
4.4. Experimental Forecasting Performance
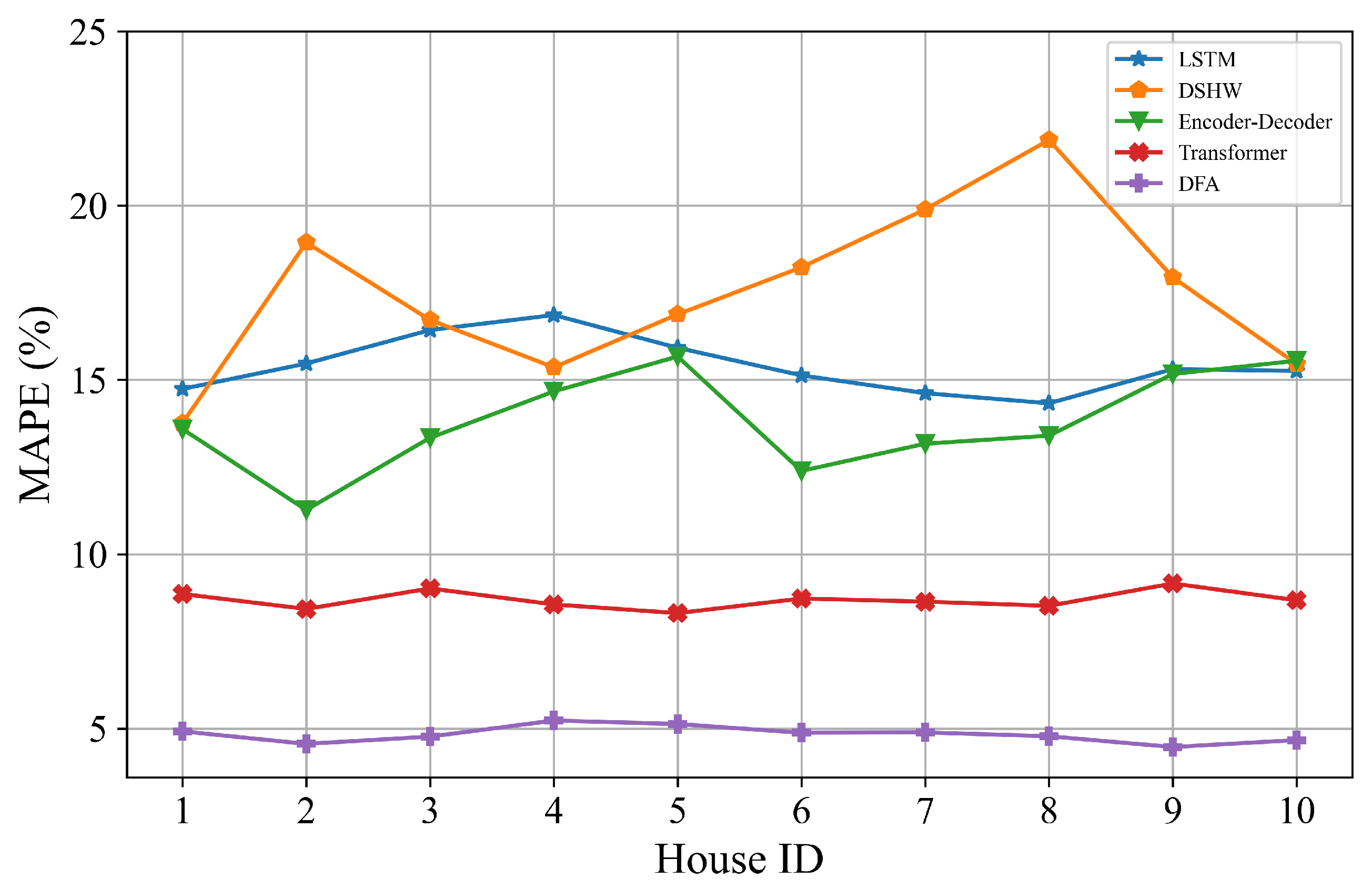
The proposed DFA and four baseline models are evaluated on 10 randomly chosen target houses. For each target house, the load records from June 2012 to June 2013 are used as training data, and 720 load records in September 2013 for prediction to calculate MAPE values. DFA makes use of all datasets of ten houses in the federated process and leverages the datasets from the target house to operate user adaptation. Baseline models are trained with the data from the target house.
Table 2 shows the MAPE values of DFA and baseline models for 10 houses.
Figure 5 shows the MAPE values for direct observation.
From
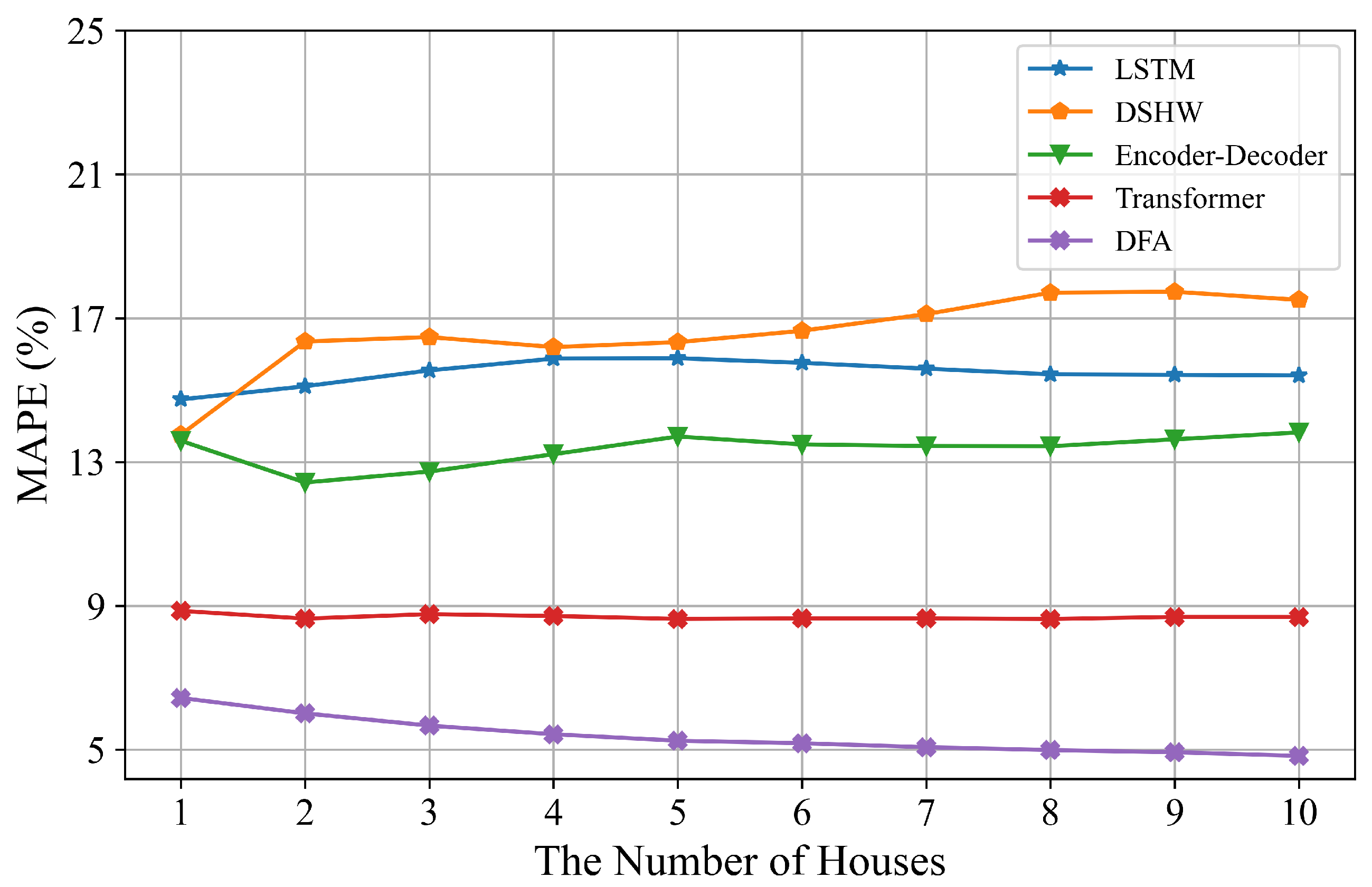
Table 2, we can see that the proposed DFA consistently outperforms the baseline models for ten houses. On average, it shows 38.28%, 69.83%, 58.81% and 63.65% relative improvements over Transformer, DSHW, Encoder–Decoder and LSTM, respectively, based on skill scores. The performances of LSTM and Encoder–Decoder are similar to each other and worse than Transformer since the number of parameters is less compared to Transformer. Performances of DSHW fluctuate widely and are inferior to the other models based on deep learning. We believe this is due to the differences in the cyclical characteristics in different spans which are influenced by many uncertain factors in residential loads. In summary, DFA has the best performance. We conclude that one of the reasons for the remarkable superiorities is DFA uses all datasets from ten houses to learn a model in the federated architecture. Additionally, we calculate the curve of MAPE values by varying the number of houses as shown in
Figure 6. It can be seen that MAPE values of DFA gradually decrease with the number of houses increasing whereas other models do not vary much. This means that the model will be more robust when more devices are connected to the systems in the reality. More discussions about the superiorities in forecasting performance can be found in
Section 4.6.
To evaluate the persistence of DFA, we conduct day-ahead and week-ahead forecasting tasks of DFA and four baseline models on one house, the results are shown in
Table 3. It can be observed that although the forecasting performance of DFA decreases as the period goes from one day to one week, DFA outperforms all baseline models no matter how long is the forecasting period. We attribute this decline to the fact that DFA uses a sliding window for training and forecasting: the value forecasted by DFA will be added to the end of the sliding window for the next forecasting. Forecasting errors are cumulative as the period grows.
4.5. Performance of Federated and Centralized Architecture
Table 4 shows the forecasting performance and computation time comparison of the federated and centralized architecture. CNN-LSTM, as shown in
Figure 3, is chosen as the test model. The different number of records in
Table 3 means how many records for each node are used to train the model. For federated learning, the training time can only be estimated, the training time can be estimated as shown in Formula (17):
where
denotes the training time,
indicates average computation time for all devices involved in each round.
From
Table 3, it can be seen that the forecasting performance of the federated architecture is superior to the centralized while making predictions for STLF in the conditions of the different numbers of local records with
. When
and records increase, the federated architecture can make use of more data to train the model, the forecasting performance will improve.
The federated architecture outperforms the centralized architecture on computation time comprehensively, with great advantage. As the federated architecture leverages devices involved in each round for training at the same time. It can be seen that the computation time fluctuates only slightly when increases. This is because in each round, each device only processes the local data simultaneously and does not care about data from other devices in the system. Meanwhile, it also can be observed that the computation time rises at a lower rate than the centralized method as the number of records increases because for the centralized architecture, the incremental data of each device should be collected for training, the increment of data is decided by .
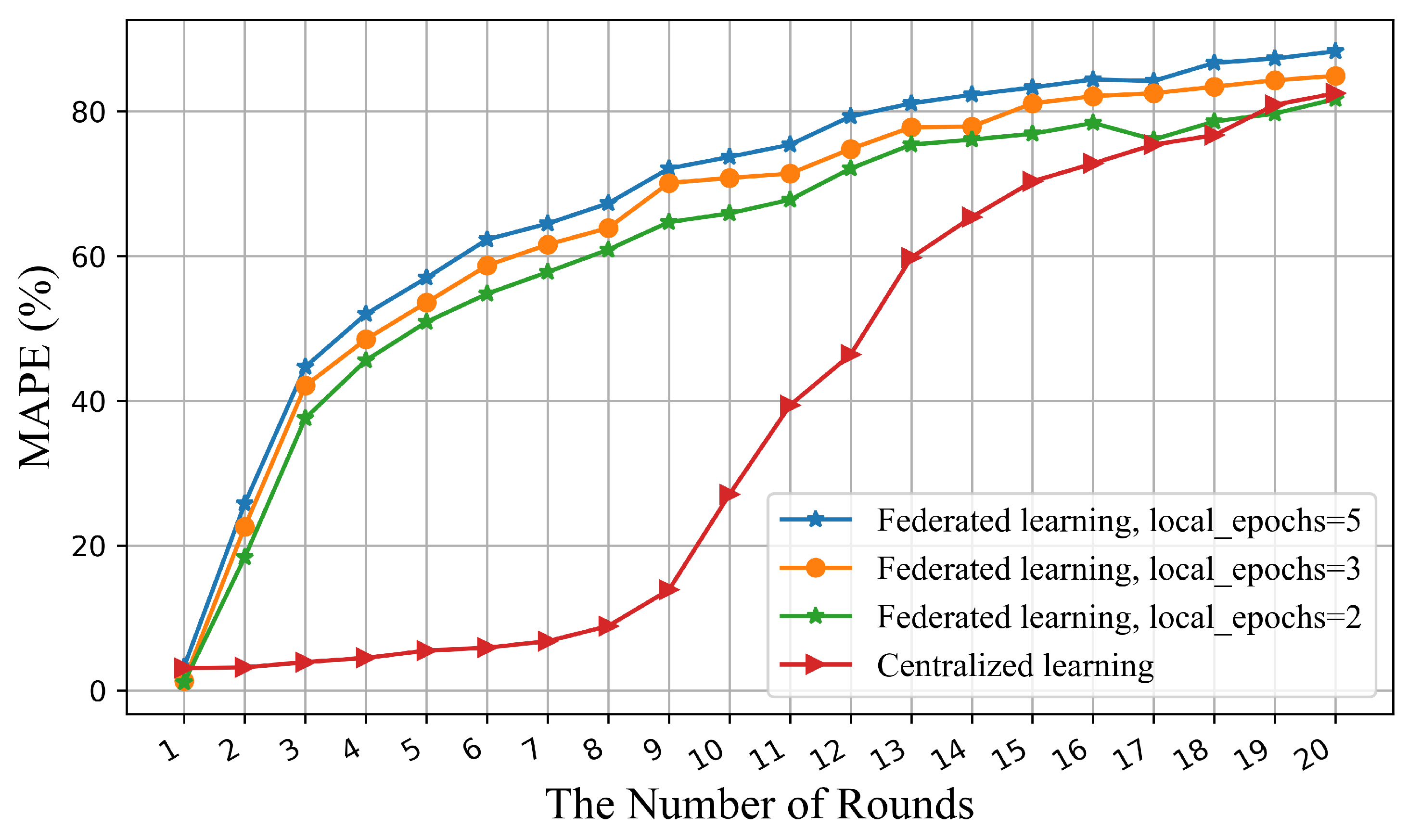
Figure 7 shows the correlation between accuracy and the number of rounds for these two architectures. Federated learning shows a higher rate rise at the beginning of the iterations while the centralized accuracy rises slowly because multiple devices compute simultaneously in one round of iterations of federation learning. As can be seen from the trend of the curves, the federated architecture uses fewer iterations to achieve a satisfactory accuracy and achieve the state of convergence, which is also reflected in the shorter computation time in
Table 3.
Now, we analyze the communication overhead of these two architectures. For the federated architecture, the calculation of communication overhead is defined in Formula (18):
meanwhile, the communication overhead of the centralized architecture is defined as shown in Formula (19):
From the aforementioned formulas, the communication complexity of the federated architecture is and the centralized architecture is . Since is presented in both equations, it can be reduced. Therefore, the complexity is and respectively. When the is much larger than , the federated architecture has less communication burden than the centralized, which is common in practical applications. We can easily infer that the computation time will increase in the reality since the incremental communication overhead. In a summary, DFA is scalable with increasing data and has lower computation time and communication bandwidth requirements.
4.6. Ablation and Extensibility Experiments
To validate the superiority of DFA, we conduct the ablation and extensibility experiments based on datasets of five houses, other experiment settings are consistent with
Section 4.4.
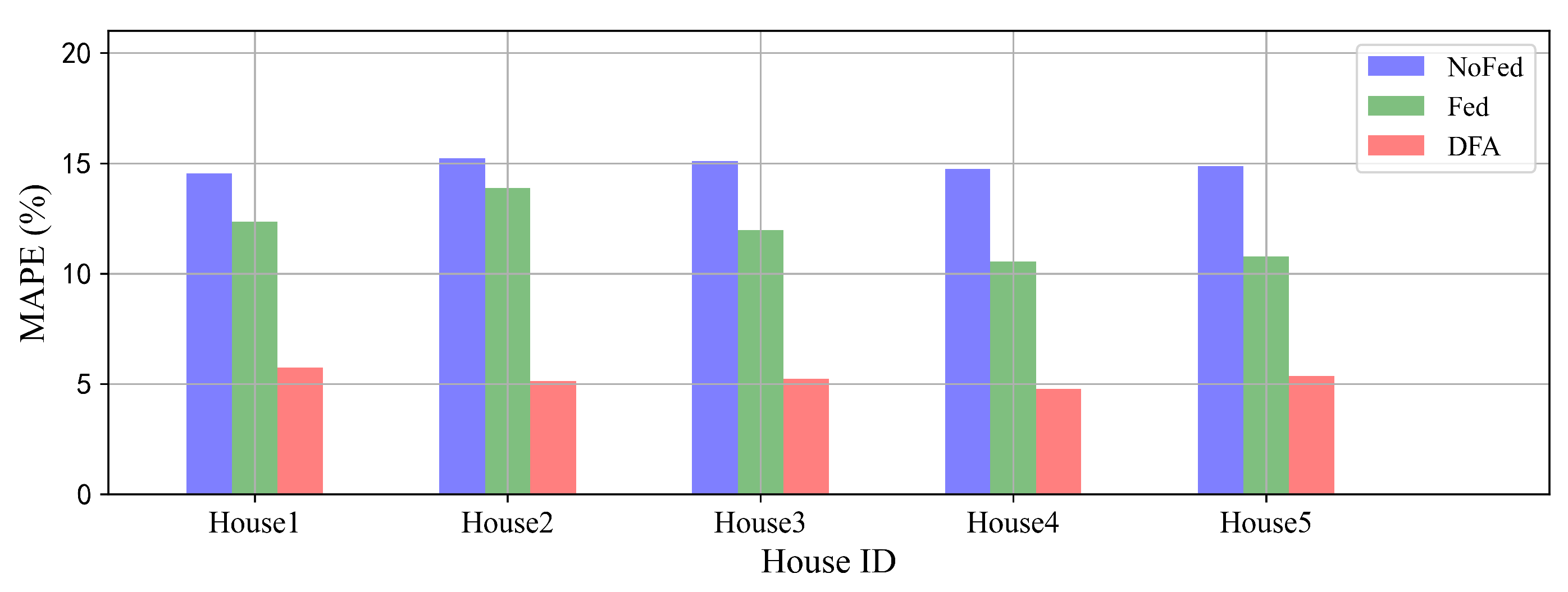
We use Fed to denote the DFA without MK-MMD optimization which is a CNN-LSTM network trained by the federated architecture. NoFed denotes the CNN-LSTM model trained by the centralized architecture with data only from the target house. We can see from
Figure 8 that Fed achieves a better performance than NoFed on each target house. This indicates that each target house benefits from the federated architecture which makes it possible to leverage datasets from other houses, ensuring privacy simultaneously. It also can be seen that DFA has remarkable improvements in performance compared with Fed. We conclude that the transfer learning method can successfully conduct knowledge transfer from the federated model to the target houses to improve forecasting performance.
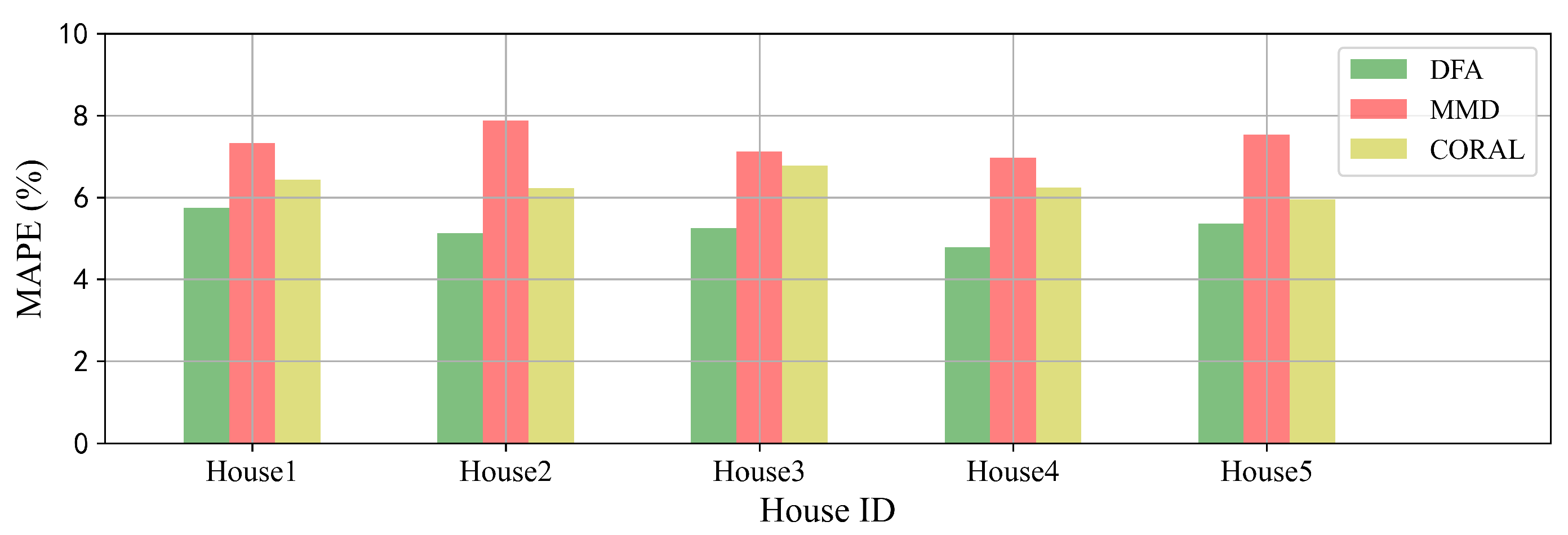
Furthermore, we extend DFA to different versions in which the part of MK-MMD is modified by the alternative transfer learning methods. Maximum mean discrepancy (MMD) is the single kernel version of MK-MMD. CORAL [
34] is one of transfer learning methods that use the covariance matrices of the source and target features to compute the domain loss. It can be seen from
Figure 9 that DFA can achieve satisfying performances on forecasting with different transfer learning methods. The results indicate that DFA is extensible with other transfer learning algorithms according to the real applications.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}