
Deep Residual Network for Smartwatch-Based User Identification through Complex Hand Movements



Abstract
:1. Introduction
- This article aims to investigate the possibility of the 1D-ResNet-SE for sensor-based user identification by analyzing complex hand movement signals captured by smartwatch sensors. We compared standard CNN-based deep learning models to RNN-based LSTM networks for sensor-based user identification using smartwatch sensor data to examine the algorithm’s effectiveness.
- We conducted comprehensive experiments using many smartwatch-based HAR datasets encompassing simple and complex hand movements to increase ecological validity. We observed the connection between hand motion patterns and the recognition of smartwatch owners using the 1D-ResNet-SE model. The SE blocks are combined with the residual network to increase the sensitivity to relevant features. Compared to CNN- and LSTM-based deep learning models, the model demonstrated here shower superior performance in user identification in complex hand movement situations.
2. Related Works
2.1. Sensor-Based User Identification
2.2. Deep Learning Approaches for User Identification
2.2.1. Convolutional Neural Network
2.2.2. Recurrent Neural Networks
2.2.3. Hybrid Neural Networks
2.3. Simple and Complex Human Activities
2.4. Available Sensor-Based Activity Datasets
3. Proposed Methodology
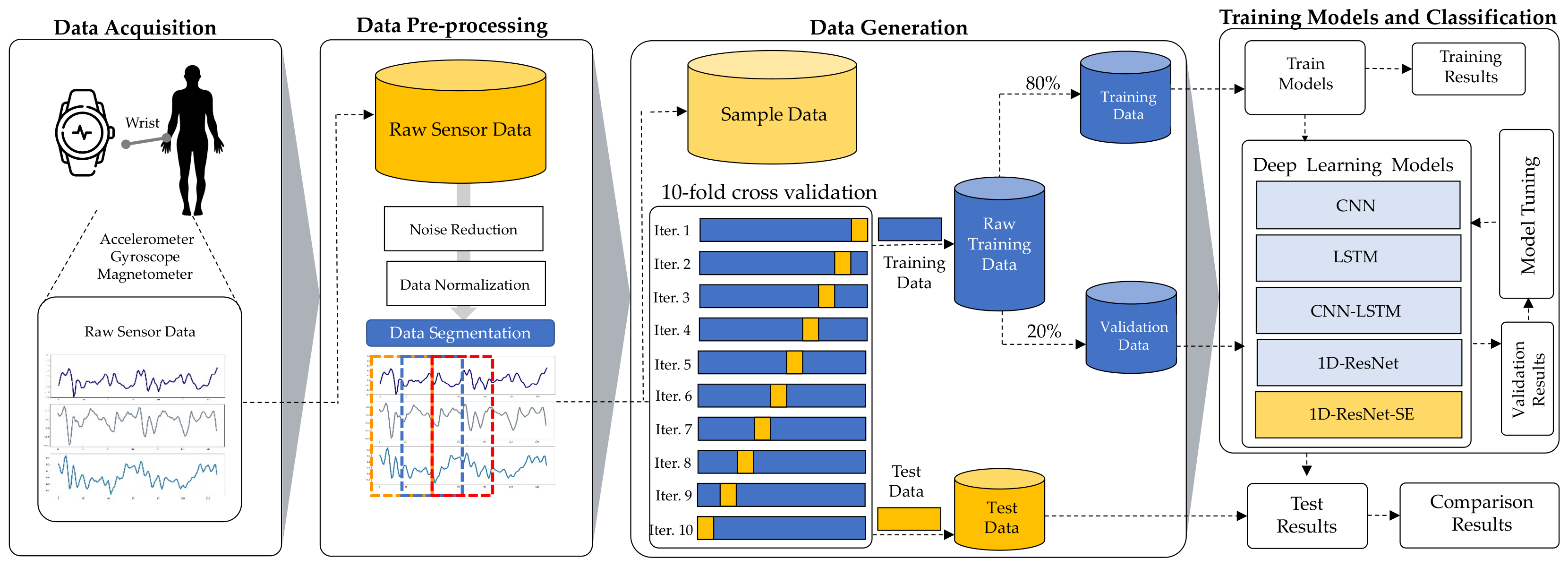
3.1. Data Acquisition
- A simple activity cannot be subdivided further at the atomic scale. For instance, walking, running, and ascending are all considered simple activities owing to their inability to be coupled with other activities.
- A complex activity is a high-level activity formed via the sequencing or overlapping of atomic-level activities. For example, the representation ”smoking while strolling” incorporates the two atomic actions of ”strolling” and ”smoking”.
3.1.1. UT-Smoke Dataset
3.1.2. WISDM-HARB Dataset
3.2. Data Pre-Processing
3.3. Data Generation
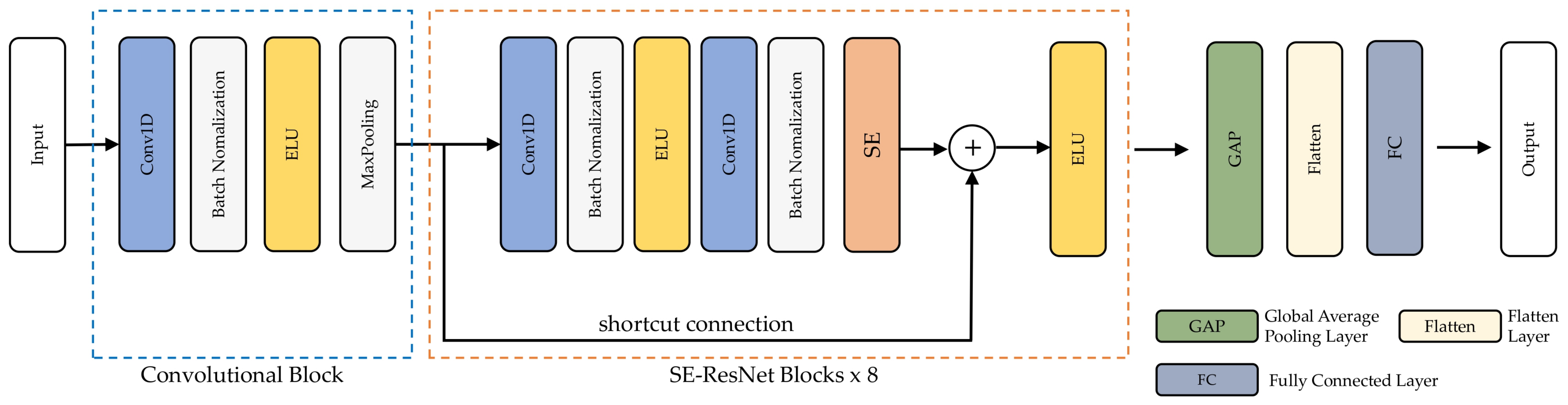
3.4. The Proposed 1D-ResNet-SE Model
3.4.1. Architecture of the Proposed Model
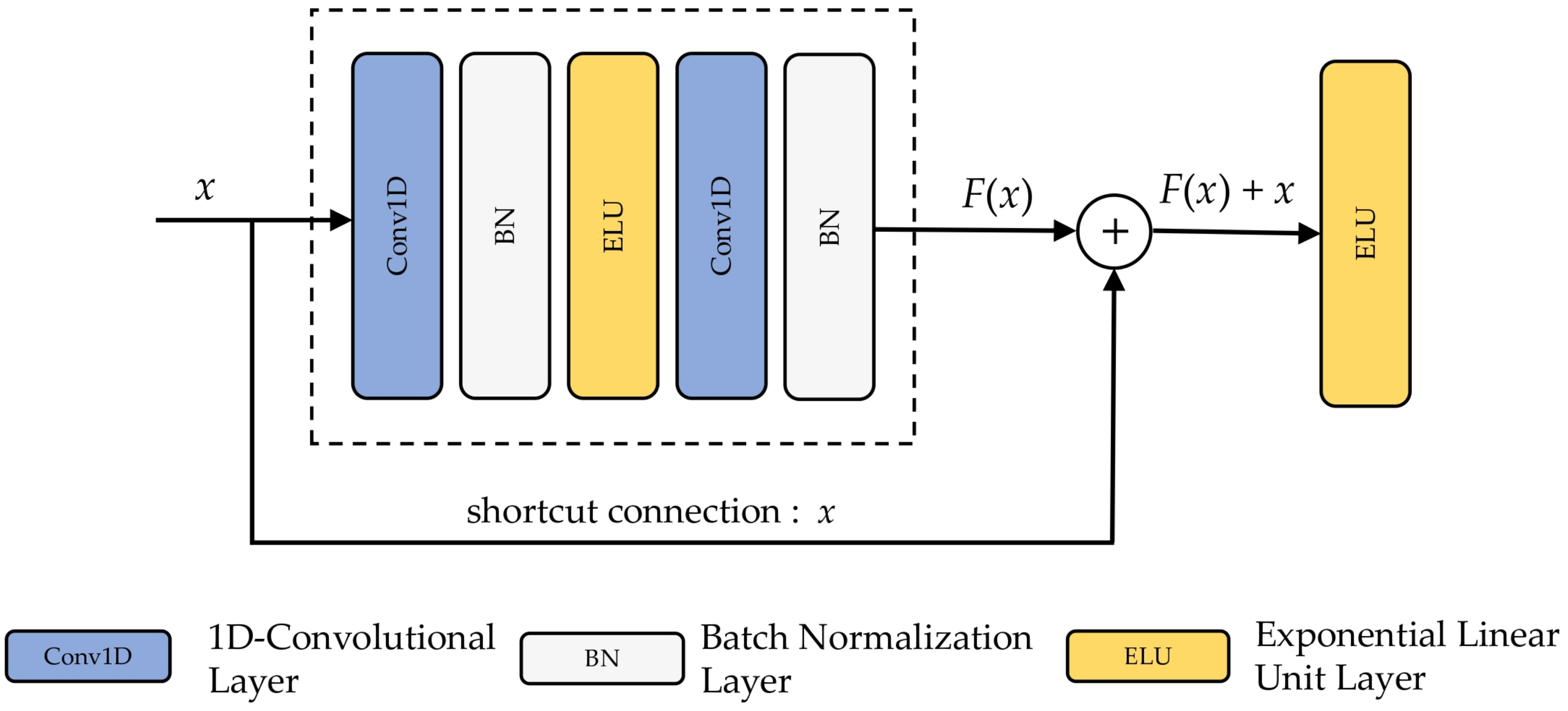
3.4.2. SE-ResNet Block
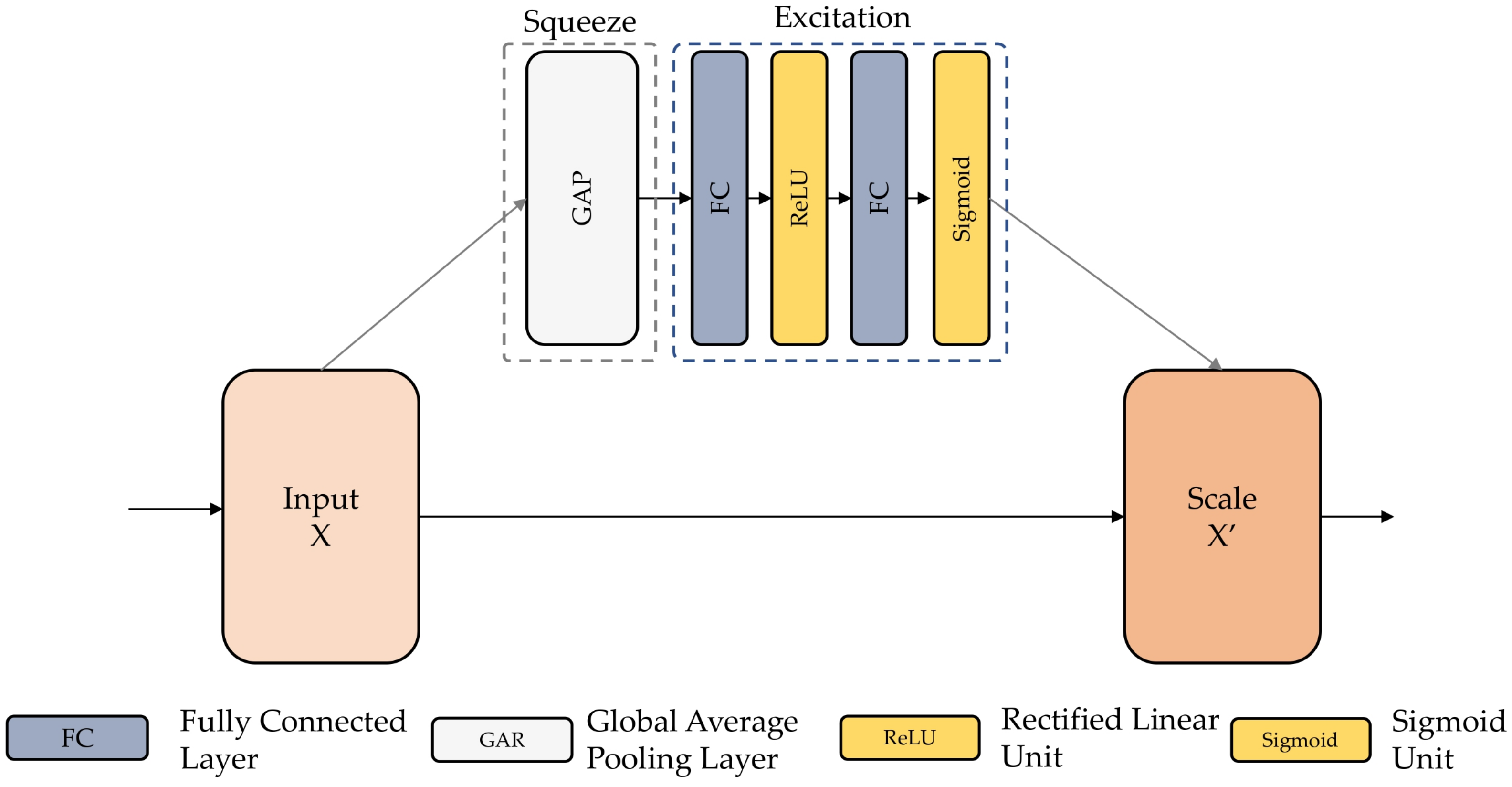
3.4.3. Squeeze-and-Excitation Module
3.4.4. Activation Function
- Sigmoid function:
- Rectified Linear Unit (ReLU):
- Exponential Linear Unit (ELU)
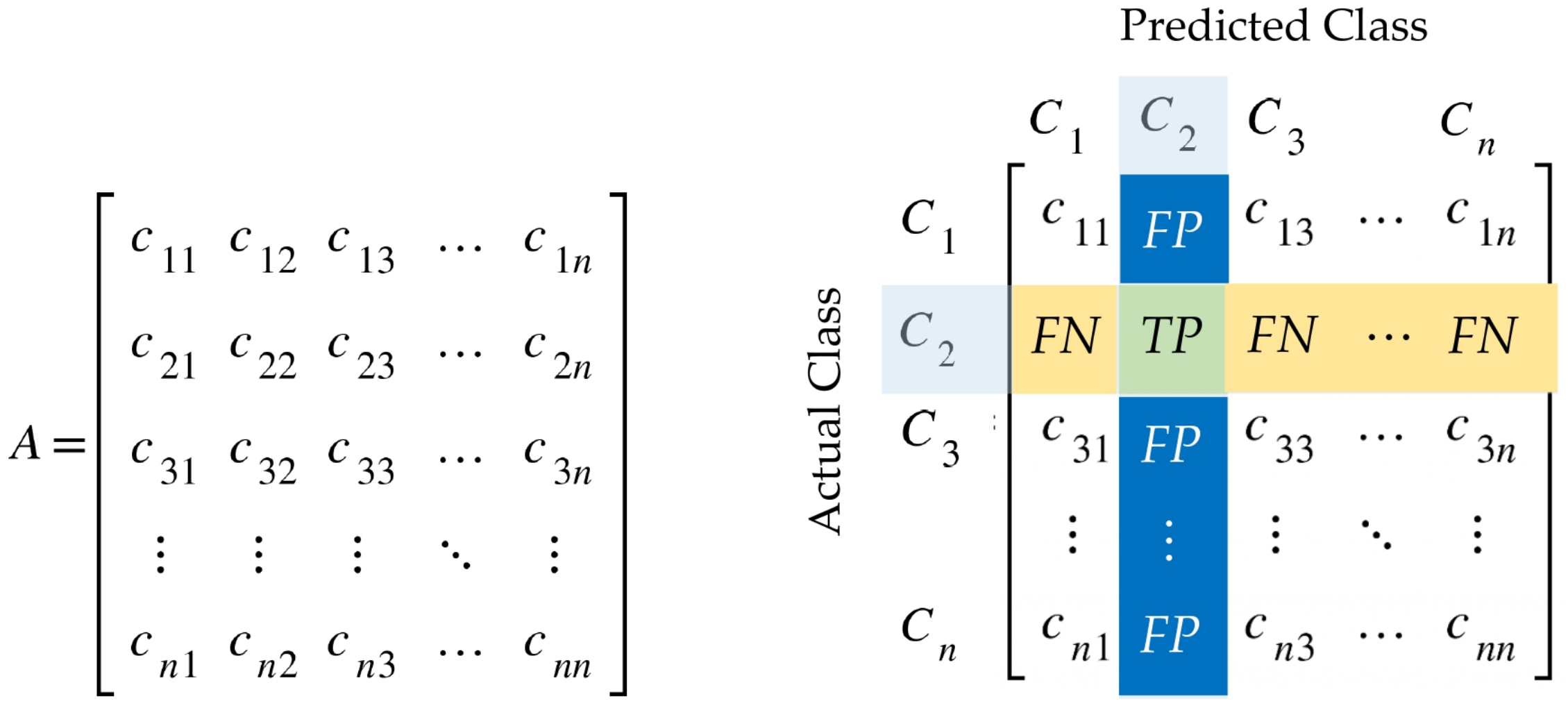
3.5. Evaluation Metrics
4. Experimental Results
4.1. Software Configuration
- When reading, manipulating, and interpreting sensor data, Numpy and Pandas were utilized for data management.
- For plotting and displaying the outcomes of data discovery and model assessment, Matplotlib and Seaborn were utilized.
- Scikit-learn (Sklearn) was used in experiments as a library for sampling and data generation.
- Deep learning models were implemented and trained using TensorFlow, Keras, and TensorBoard.
4.2. Experimental Findings
4.2.1. UT-Smoke
4.2.2. WISDM-HARB
5. Research Discussion
5.1. Impact of Squeeze-and-Excitation Modules
5.2. Impact of Sensor Combinations
5.3. Comparison with Previous Works
6. Conclusions and Future Studies
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Hyperparameters | Values | |
|---|---|---|---|
| Architecture | Convolution | Kernel Size | 5 |
| Stride | 1 | ||
| Filters | 64 | ||
| Dropout | 0.25 | ||
| Max Pooling | 2 | ||
| Flatten | - | ||
| Training | Loss Function | Cross-entropy | |
| Optimizer | Adam | ||
| Batch Size | 64 | ||
| Number of Epochs | 200 | ||
| Stage | Hyperparameters | Values |
|---|---|---|
| Architecture | LSTM Unit | 128 |
| Dropout | 0.25 | |
| Dense | 128 | |
| Training | Loss Function | Cross-entropy |
| Optimizer | Adam | |
| Batch Size | 64 | |
| Number of Epochs | 200 |
| Stage | Hyperparameters | Values | |
|---|---|---|---|
| Architecture | Convolutional Block | ||
| Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 64 | ||
| Batch Normalization | - | ||
| Activation | ReLU | ||
| Max Pooling | 2 | ||
| Residual Block × 8 | |||
| Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 32 | ||
| Batch Normalization | - | ||
| Activation | ReLU | ||
| Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 64 | ||
| Batch Normalization | - | ||
| Global Average Pooling | - | ||
| Flatten | - | ||
| Dense | 128 | ||
| Training | Loss Function | Cross-entropy | |
| Optimizer | Adam | ||
| Batch Size | 64 | ||
| Number of Epochs | 200 | ||
| Stage | Hyperparameters | Values | |
|---|---|---|---|
| Architecture | Convolutional Block | ||
| Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 64 | ||
| Batch Normalization | - | ||
| Activation | ELU | ||
| Max Pooling | 2 | ||
| SE-ResNet Block × 8 | |||
| Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 32 | ||
| Batch Normalization | - | ||
| Activation | ELU | ||
| Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 64 | ||
| Batch Normalization | - | ||
| SE Module | - | ||
| Global Average Pooling | - | ||
| Flatten | - | ||
| Dense | 128 | ||
| Training | Loss Function | Cross-entropy | |
| Optimizer | Adam | ||
| Batch Size | 64 | ||
| Number of Epochs | 200 | ||
References
- Ometov, A.; Shubina, V.; Klus, L.; Skibińska, J.; Saafi, S.; Pascacio, P.; Flueratoru, L.; Gaibor, D.Q.; Chukhno, N.; Chukhno, O.; et al. A Survey on Wearable Technology: History, State-of-the-Art and Current Challenges. Comput. Netw. 2021, 193, 108074. [Google Scholar] [CrossRef]
- Nickel, C.; Wirtl, T.; Busch, C. Authentication of Smartphone Users Based on the Way They Walk Using k-NN Algorithm. In Proceedings of the 2012 Eighth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Athens, Greece, 18–20 July 2012; pp. 16–20. [Google Scholar] [CrossRef]
- Lin, C.L.; Hwang, T. A password authentication scheme with secure password updating. Comput. Secur. 2003, 22, 68–72. [Google Scholar] [CrossRef]
- Merkle, R.C. A Digital Signature Based on a Conventional Encryption Function. Advances in Cryptology–CRYPTO ’87; Pomerance, C., Ed.; Springer: Berlin, Germany, 1988; pp. 369–378. [Google Scholar]
- Suh, G.E.; Devadas, S. Physical Unclonable Functions for Device Authentication and Secret Key Generation. In Proceedings of the 2007 44th ACM/IEEE Design Automation Conference, San Diego, CA, USA, 4–8 June 2007; pp. 9–14. [Google Scholar]
- Indu, I.; Anand, P.R.; Bhaskar, V. Identity and access management in cloud environment: Mechanisms and challenges. Eng. Sci. Technol. Int. J. 2018, 21, 574–588. [Google Scholar] [CrossRef]
- Ailisto, H.; Lindholm, M.; Mäntyjärvi, J.; Vildjiounaite, E.; Mäkelä, S.M. Identifying people from gait pattern with accelerometers. In Proceedings of the Biometric Technology for Human Identification II, Orlando, FL, USA, 28–29 March 2005; pp. 7–14. [Google Scholar]
- Derawi, M.O.; Nickel, C.; Bours, P.; Busch, C. Unobtrusive User-Authentication on Mobile Phones Using Biometric Gait Recognition. In Proceedings of the 2010 Sixth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Washington, DC, USA, 15–17 October 2010; pp. 306–311. [Google Scholar] [CrossRef]
- Sha, K.; Kumari, M. Patient Identification Based on Wrist Activity Data. In Proceedings of the 2018 IEEE/ACM International Conference on Connected Health: Applications, Systems and Engineering Technologies, Washington, DC, USA, 26–28 September 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 29–30. [Google Scholar]
- Wang, C.; Wang, Y.; Chen, Y.; Liu, H.; Liu, J. User authentication on mobile devices: Approaches, threats and trends. Comput. Netw. 2020, 170, 107118. [Google Scholar] [CrossRef]
- Zhang, S.; Sun, L.; Mao, X.; Hu, C.; Liu, P.; Herrera, L.J. Review on EEG-Based Authentication Technology. Comput. Intell. Neurosci. 2021, 2021, 1–20. [Google Scholar] [CrossRef]
- Burge, M.J.; Bowyer, K.W. Handbook of Iris Recognition; Springer Publishing Company, Incorporated: Cham, Switzerland, 2013. [Google Scholar]
- Kavitha, S.; Sripriya, P. A Review on Palm Vein Biometrics. Int. J. Eng. Technol. 2018, 7, 407. [Google Scholar] [CrossRef] [Green Version]
- Saevanee, H.; Clarke, N.; Furnell, S.; Biscione, V. Continuous user authentication using multi-modal biometrics. Comput. Secur. 2015, 53, 234–246. [Google Scholar] [CrossRef] [Green Version]
- Kumar, R.; Phoha, V.V.; Raina, R. Authenticating users through their arm movement patterns. arXiv 2016, arXiv:cs.CV/1603.02211. [Google Scholar]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-Based Activity Recognition. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Weiss, G.M.; Yoneda, K.; Hayajneh, T. Smartphone and Smartwatch-Based Biometrics Using Activities of Daily Living. IEEE Access 2019, 7, 133190–133202. [Google Scholar] [CrossRef]
- Ahmad, M.; Alqarni, M.; Khan, A.; Khan, A.; Chauhdary, S.; Mazzara, M.; Umer, T.; Distefano, S. Smartwatch-Based Legitimate User Identification for Cloud-Based Secure Services. Mob. Inf. Syst. 2018, 2018, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Angrisano, A.; Bernardi, M.L.; Cimitile, M.; Gaglione, S.; Vultaggio, M. Identification of Walker Identity Using Smartphone Sensors: An Experiment Using Ensemble Learning. IEEE Access 2020, 8, 27435–27447. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Biometric User Identification Based on Human Activity Recognition Using Wearable Sensors: An Experiment Using Deep Learning Models. Electronics 2021, 10, 308. [Google Scholar] [CrossRef]
- Benegui, C.; Ionescu, R.T. Convolutional Neural Networks for User Identification Based on Motion Sensors Represented as Images. IEEE Access 2020, 8, 61255–61266. [Google Scholar] [CrossRef]
- Neverova, N.; Wolf, C.; Lacey, G.; Fridman, L.; Chandra, D.; Barbello, B.; Taylor, G. Learning Human Identity From Motion Patterns. IEEE Access 2016, 4, 1810–1820. [Google Scholar] [CrossRef]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, L. Human Activity Recognition Based on Residual Network and BiLSTM. Sensors 2022, 22, 635. [Google Scholar] [CrossRef] [PubMed]
- Ronald, M.; Poulose, A.; Han, D.S. iSPLInception: An Inception-ResNet Deep Learning Architecture for Human Activity Recognition. IEEE Access 2021, 9, 68985–69001. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Mekruksavanich, S.; Jantawong, P.; Jitpattanakul, A. A Lightweight Deep Convolutional Neural Network with Squeeze-and-Excitation Modules for Efficient Human Activity Recognition using Smartphone Sensors. In Proceedings of the 2021 2nd International Conference on Big Data Analytics and Practices (IBDAP), Bangkok, Thailand, 26–27 August 2021; pp. 23–27. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Detection of Freezing of Gait in Parkinson’s Disease by Squeeze-and-Excitation Convolutional Neural Network with Wearable Sensors. In Proceedings of the 2021 15th International Conference on Open Source Systems and Technologies (ICOSST), Lahore, Pakistan, 15–16 December 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jantawong, P.; Charoenphol, A.; Jitpattanakul, A. Fall Detection from Smart Wearable Sensors using Deep Convolutional Neural Network with Squeeze-and-Excitation Module. In Proceedings of the 2021 25th International Computer Science and Engineering Conference (ICSEC), Chiang Rai, Thailand, 18–20 November 2021; pp. 448–453. [Google Scholar] [CrossRef]
- Zou, L.; Liu, W.; Lei, M.; Yu, X. An Improved Residual Network for Pork Freshness Detection Using Near-Infrared Spectroscopy. Entropy 2021, 23, 1293. [Google Scholar] [CrossRef]
- Park, J.; Kim, J.k.; Jung, S.; Gil, Y.; Choi, J.I.; Son, H.S. ECG-Signal Multi-Classification Model Based on Squeeze-and-Excitation Residual Neural Networks. Appl. Sci. 2020, 10, 6495. [Google Scholar] [CrossRef]
- Saini, B.s.; Kaur, N.; Bhatia, K. Authenticating Mobile Phone User using Keystroke Dynamics. Int. J. Comput. Sci. Eng. 2018, 6, 372–377. [Google Scholar] [CrossRef]
- Shi, W.; Yang, J.; Jiang, Y.; Yang, F.; Xiong, Y. SenGuard: Passive user identification on smartphones using multiple sensors. In Proceedings of the IEEE 7th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Shanghai, China, 10–12 October 2011; pp. 141–148. [Google Scholar] [CrossRef]
- De Luca, A.; Hang, A.; Brudy, F.; Lindner, C.; Hussmann, H. Touch Me Once and i Know It’s You! Implicit Authentication Based on Touch Screen Patterns. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 987–996. [Google Scholar] [CrossRef]
- Sae-Bae, N.; Memon, N.; Isbister, K. Investigating multi-touch gestures as a novel biometric modality. In Proceedings of the 2012 IEEE Fifth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 23–27 September 2012; pp. 156–161. [Google Scholar] [CrossRef]
- Frank, M.; Biedert, R.; Ma, E.; Martinovic, I.; Song, D. Touchalytics: On the Applicability of Touchscreen Input as a Behavioral Biometric for Continuous Authentication. IEEE Trans. Inf. Forensics Secur. 2013, 8, 136–148. [Google Scholar] [CrossRef] [Green Version]
- Rocha, C.C.; Lima, J.C.D.; Dantas, M.A.R.; Augustin, I. A2BeST: An adaptive authentication service based on mobile user’s behavior and spatio-temporal context. In Proceedings of the 2011 IEEE Symposium on Computers and Communications (ISCC), Corfu, Greece, 28 June–1 July 2011; pp. 771–774. [Google Scholar] [CrossRef]
- Sabharwal, M. Multi-Modal Biometric Authentication and Secure Transaction Operation Framework for E-Banking. Int. J. Bus. Data Commun. Netw. 2017, 13, 102–116. [Google Scholar] [CrossRef] [Green Version]
- Jakobsson, M.; Shi, E.; Golle, P.; Chow, R. Implicit Authentication for Mobile Devices. In Proceedings of the 4th USENIX Conference on Hot Topics in Security, Montreal, QC, Canada, 10–14 August 2009; USENIX Association: Berkeley, CA, USA, 2009. HotSec’09. p. 9. [Google Scholar]
- Casale, P.; Pujol, O.; Radeva, P. Personalization and User Verification in Wearable Systems Using Biometric Walking Patterns. Pers. Ubiquitous Comput. 2012, 16, 563–580. [Google Scholar] [CrossRef]
- Rong, L.; Jianzhong, Z.; Ming, L.; Xiangfeng, H. A Wearable Acceleration Sensor System for Gait Recognition. In Proceedings of the 2007 2nd IEEE Conference on Industrial Electronics and Applications, Harbin, China, 23–25 May 2007; pp. 2654–2659. [Google Scholar] [CrossRef]
- Mantyjarvi, J.; Lindholm, M.; Vildjiounaite, E.; Makela, S.M.; Ailisto, H. Identifying users of portable devices from gait pattern with accelerometers. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005; Volume 2. [Google Scholar]
- Parziale, A.; Carmona-Duarte, C.; Ferrer, M.A.; Marcelli, A. 2D vs 3D Online Writer Identification: A Comparative Study. In Document Analysis and Recognition—ICDAR 2021; Lladós, J., Lopresti, D., Uchida, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 307–321. [Google Scholar]
- Musale, P.; Baek, D.; Werellagama, N.; Woo, S.S.; Choi, B.J. You Walk, We Authenticate: Lightweight Seamless Authentication Based on Gait in Wearable IoT Systems. IEEE Access 2019, 7, 37883–37895. [Google Scholar] [CrossRef]
- Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; AAAI Press: Cambridge, MA, USA, 2015; pp. 3995–4001. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1307–1310. [Google Scholar]
- Huang, J.; Lin, S.; Wang, N.; Dai, G.; Xie, Y.; Zhou, J. TSE-CNN: A Two-Stage End-to-End CNN for Human Activity Recognition. IEEE J. Biomed. Health Inform. 2020, 24, 292–299. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:cs.CV/1505.04597. [Google Scholar]
- Zhang, Y.; Zhang, Z.; Zhang, Y.; Bao, J.; Zhang, Y.; Deng, H. Human Activity Recognition Based on Motion Sensor Using U-Net. IEEE Access 2019, 7, 75213–75226. [Google Scholar] [CrossRef]
- Mahmud, T.; Sazzad Sayyed, A.Q.M.; Fattah, S.A.; Kung, S.Y. A Novel Multi-Stage Training Approach for Human Activity Recognition From Multimodal Wearable Sensor Data Using Deep Neural Network. IEEE Sens. J. 2021, 21, 1715–1726. [Google Scholar] [CrossRef]
- Tang, Y.; Teng, Q.; Zhang, L.; Min, F.; He, J. Layer-Wise Training Convolutional Neural Networks With Smaller Filters for Human Activity Recognition Using Wearable Sensors. IEEE Sens. J. 2021, 21, 581–592. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, Y.; Liu, C.; Chen, H.; Xu, C.; Shi, B.; Xu, C.; Xu, C. LegoNet: Efficient Convolutional Neural Networks with Lego Filters. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 09–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; International Machine Learning Society: Stroudsburg, PA, USA, 2019; Volume 97, pp. 7005–7014. [Google Scholar]
- Zeng, M.; Gao, H.; Yu, T.; Mengshoel, O.J.; Langseth, H.; Lane, I.; Liu, X. Understanding and Improving Recurrent Networks for Human Activity Recognition by Continuous Attention. In Proceedings of the 2018 ACM International Symposium on Wearable Computers, Singapore, 8–12 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 56–63. [Google Scholar]
- Barut, O.; Zhou, L.; Luo, Y. Multitask LSTM Model for Human Activity Recognition and Intensity Estimation Using Wearable Sensor Data. IEEE Internet Things J. 2020, 7, 8760–8768. [Google Scholar] [CrossRef]
- Aljarrah, A.A.; Ali, A.H. Human Activity Recognition using PCA and BiLSTM Recurrent Neural Networks. In Proceedings of the 2019 2nd International Conference on Engineering Technology and its Applications (IICETA), Al-Najef, Iraq, 27–28 August 2019; pp. 156–160. [Google Scholar] [CrossRef]
- Steven Eyobu, O.; Han, D.S. Feature Representation and Data Augmentation for Human Activity Classification Based on Wearable IMU Sensor Data Using a Deep LSTM Neural Network. Sensors 2018, 18, 2892. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Jiang, C.; Xiang, S.; Ding, J.; Wu, M.; Li, X. Smartphone Sensor-Based Human Activity Recognition Using Feature Fusion and Maximum Full A Posteriori. IEEE Trans. Instrum. Meas. 2020, 69, 3992–4001. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, M.; Gao, K.; Wu, J.; Ding, J.; Zeng, Z.; Li, X. A Novel Ensemble Deep Learning Approach for Sleep-Wake Detection Using Heart Rate Variability and Acceleration. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 803–812. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A Deep Neural Network for Complex Human Activity Recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, M.; Cui, W.; Liu, C.; Li, X. An Attention Based CNN-LSTM Approach for Sleep-Wake Detection With Heterogeneous Sensors. IEEE J. Biomed. Health Inform. 2021, 25, 3270–3277. [Google Scholar] [CrossRef]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A Semisupervised Recurrent Convolutional Attention Model for Human Activity Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1747–1756. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Alo, U.R.; Nweke, H.F.; Teh, Y.W.; Murtaza, G. Smartphone Motion Sensor-Based Complex Human Activity Identification Using Deep Stacked Autoencoder Algorithm for Enhanced Smart Healthcare System. Sensors 2020, 20, 6300. [Google Scholar] [CrossRef]
- Peng, L.; Chen, L.; Ye, Z.; Zhang, Y. AROMA: A Deep Multi-Task Learning Based Simple and Complex Human Activity Recognition Method Using Wearable Sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2. [Google Scholar] [CrossRef]
- Liu, L.; Peng, Y.; Liu, M.; Huang, Z. Sensor-based human activity recognition system with a multilayered model using time series shapelets. Knowl.-Based Syst. 2015, 90, 138–152. [Google Scholar] [CrossRef]
- Chen, L.; Liu, X.; Peng, L.; Wu, M. Deep learning based multimodal complex human activity recognition using wearable devices. Appl. Intell. 2021, 51, 1–14. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J.M. Complex Human Activity Recognition Using Smartphone and Wrist-Worn Motion Sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef] [PubMed]
- Shoaib, M.; Scholten, H.; Havinga, P.J.M.; Incel, O.D. A hierarchical lazy smoking detection algorithm using smartwatch sensors. In Proceedings of the 2016 IEEE 18th International Conference on e-Health Networking, Applications and Services (Healthcom), Munich, Germany, 14–16 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Shoaib, M.; Incel, O.; Scholten, H.; Havinga, P. Smokesense: Online activity recognition framework on smartwatches. In Mobile Computing, Applications, and Services—9th International Conference, MobiCASE 2018; Ohmura, R., Murao, K., Inoue, S., Gotoh, Y., Eds.; Springer: Amsterdam, The Netherlands, 2018; Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering, LNICST; pp. 106–124. [Google Scholar] [CrossRef]
- Harris, E.J.; Khoo, I.H.; Demircan, E. A Survey of Human Gait-Based Artificial Intelligence Applications. Front. Robot. AI 2022, 8, 1–28. [Google Scholar] [CrossRef]
- Nguyen, B.; Coelho, Y.; Bastos, T.; Krishnan, S. Trends in human activity recognition with focus on machine learning and power requirements. Mach. Learn. Appl. 2021, 5, 100072. [Google Scholar] [CrossRef]
- Scheurer, S.; Tedesco, S.; O’Flynn, B.; Brown, K.N. Comparing Person-Specific and Independent Models on Subject-Dependent and Independent Human Activity Recognition Performance. Sensors 2020, 20, 3647. [Google Scholar] [CrossRef] [PubMed]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Roggen, D.; Calatroni, A.; Rossi, M.; Holleczek, T.; Förster, K.; Tröster, G.; Lukowicz, P.; Bannach, D.; Pirkl, G.; Ferscha, A.; et al. Collecting complex activity datasets in highly rich networked sensor environments. In Proceedings of the 2010 Seventh International Conference on Networked Sensing Systems (INSS), Kassel, Germany, 15–18 June 2010; pp. 233–240. [Google Scholar] [CrossRef] [Green Version]
- Mostayed, A.; Kim, S.; Mazumder, M.M.G.; Park, S.J. Foot Step Based Person Identification Using Histogram Similarity and Wavelet Decomposition. In Proceedings of the 2008 International Conference on Information Security and Assurance (ISA 2008), Busan, Korea, 24–26 April 2008; pp. 307–311. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra Perez, X.; Reyes Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition using Smartphones. In Proceedings of the Networks, Computational Intelligence and Machine Learning (ESANN 2013), Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity Recognition Using Cell Phone Accelerometers. SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: Berlin, Germany, 2009. [Google Scholar]
- Monti, R.P.; Tootoonian, S.; Cao, R. Avoiding Degradation in Deep Feed-Forward Networks by Phasing out Skip-Connections; ICANN: Los Angeles, CA, USA, 2018. [Google Scholar]
- Muqeet, A.; Iqbal, M.T.B.; Bae, S.H. HRAN: Hybrid Residual Attention Network for Single Image Super-Resolution. IEEE Access 2019, 7, 137020–137029. [Google Scholar] [CrossRef]
- Bisong, E. Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: New York, NY, USA, 2019. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:cs.DC/1603.04467. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Benavoli, A.; Corani, G.; Mangili, F. Should We Really Use Post-Hoc Tests Based on Mean-Ranks? J. Mach. Learn. Res. 2016, 17, 1–10. [Google Scholar]
- Hodges, J.L.; Lehmann, E.L. Rank Methods for Combination of Independent Experiments in Analysis of Variance. Ann. Math. Stat. 1962, 33, 403–418. [Google Scholar] [CrossRef]
- Finner, H. On a Monotonicity Problem in Step-Down Multiple Test Procedures. J. Am. Stat. Assoc. 1993, 88, 920–923. [Google Scholar] [CrossRef]





| Work (Year) | Classifier | Sensors | Device | Performance (% Accuracy) | Contribution | No. of Users |
|---|---|---|---|---|---|---|
| Parziale et al.(2021) [44] | Random Forest | 1 Acc. | Smartwatch | 89.77 | User identification based on writing activity performed in air | 98 |
| Mekruksavanich et al. (2021) [20] | CNN-LSTM | 2 Acc. 1 Gyro. | Smartphone | 94.57 | User identification based on smartphone sensor from dynamic activities (walking, walking upstairs, and walking downstairs) | 30 |
| Benegui et al. (2020) [21] | CNN | 1 Acc. 1 Gyro. | Smartphone | 90.75 | User identification based on motion sensor data of tapping on screen motion from smartphone | 50 |
| Angrisano et al. (2020) [19] | Random Forest | 1 Acc. 1 Gyro. | Smartphone | 93.8 | User identification based on walking activities using ensemble machine learning | 32 |
| Weiss et al. (2019) [17] | Random Forest | 1 Acc. 1 Gyro. | Smartphone | 92.7 | User identification based on simple activities and complex activities using machine learning approaches | 51 |
| 1 Acc. 1 Gyro. | Smartwatch | 71.7 | ||||
| Musale et al. (2019) [45] | Random Forest | 1 Acc. 1 Gyro. | Smartwatch | 91.8 | User identification based on statistical features and human-action-related features from sensor data | 51 |
| Ahmad et al. (2018) [18] | Decision Tree | 1 Acc. 1 Gyro. 1 Mag. | Smartwatch | 98.68 | User identification based on ambulatory activities using machine learning | 6 |
| Nevero et al. (2016) [22] | CNN | 1 Acc. 1 Gyro. 1 Mag. | Smartphone | 69.41 | User identification based on walking activities using dense convolutional clockwork RNNs | 587 |
| Dataset | Category | Activity | Description | Raw Sensor Data | Percentage |
|---|---|---|---|---|---|
| UT-Smoke | Simple | Sitting | Sitting | 649,000 | 14.28% |
| Standing | Standing | 649,000 | 14.29% | ||
| Complex | Smoking | Smoking | 1,298,000 | 28.57% | |
| Eating | Eating | 649,000 | 14.29% | ||
| Drinking | Drinking | 1,298,000 | 28.57% | ||
| WISDM-HARB | Simple | Walking | Walking | 192,531 | 5.60% |
| Jogging | Jogging | 187,833 | 5.46% | ||
| Stairs | Walking upstairs and downstairs | 180,416 | 5.24% | ||
| Sitting | Sitting | 195,050 | 5.67% | ||
| Standing | Standing | 194,103 | 5.64% | ||
| Kicking | Kicking a soccer ball | 191,535 | 5.57% | ||
| Complex | Dribbling | Dribbling a basketball | 194,845 | 5.66% | |
| Catch | Playing catch a tennis ball | 187,684 | 5.46% | ||
| Typing | Typing | 187,175 | 5.44% | ||
| Writing | Writing | 197,403 | 5.74% | ||
| Clapping | Clapping | 190,776 | 5.55% | ||
| Teeth | Brushing teeth | 190,759 | 5.54% | ||
| Folding | Folding clothes | 193,373 | 5.62% | ||
| Pasta | Eating pasta | 189,609 | 5.51% | ||
| Soup | Eating soup | 187,057 | 5.44% | ||
| Sandwich | Eating a sandwich | 190,191 | 5.53% | ||
| Chips | Eating chips | 192,085 | 5.58% | ||
| Drinking | Drinking from a cup | 197,917 | 5.75% |
| Metrics | Formulas |
|---|---|
| Accuracy | |
| Recall of class | |
| Precision of class | |
| F1-score of class | |
| Recall | |
| Precision | |
| F1-score | |
| False Acceptance Rate of class | |
| False Rejection Rate of class |
| Sensor | Activity | Recognition Achievement of DL Models Using Sensors Data from UT-Smoke Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CNN | LSTM | 1D-ResNet-SE | ||||||||
| Accuracy ± SD | F1 ± SD | EER | Accuracy ± SD | F1 ± SD | EER | Accuracy ± SD | F1 ± SD | EER | ||
| Acc. | Smoking | 69.42 (±0.530) | 69.35 (±0.545) | 32.41(±1.17) | 65.47 (±3.885) | 65.00 (±4.409) | 31.26 (±1.12) | 89.06 (±0.560) | 89.04 (±0.577) | 13.49 (±0.87) |
| Eating | 80.85 (±0.523) | 80.64 (±0.602) | 21.22 (±0.70) | 79.92 (±2.653) | 79.81 (±3.136) | 18.35 (±1.26) | 88.33 (±5.448) | 88.20 (±5.608) | 14.60 (±1.29) | |
| Drinking | 66.41 (±1.574) | 65.86 (±1.746) | 33.20 (±1.35) | 66.20 (±2.704) | 65.75 (±3.436) | 43.19 (±1.25) | 84.81 (±1.052) | 84.77 (±1.090) | 15.14 (±1.08) | |
| Inactive | 14.61 (±0.560) | 5.54 (±1.068) | 91.19 (±0.32) | 14.82 (±0.109) | 6.77 (±0.564) | 90.66 (±0.41) | 14.54 (±0.273) | 8.01 (±1.120) | 90.44 (±0.56) | |
| Avg. (all) | 57.82 | 55.35 | 44.51 | 56.60 | 54.33 | 45.87 | 69.19 | 67.53 | 33.42 | |
| Avg. (active) | 72.23 | 71.95 | 28.94 | 70.53 | 70.19 | 30.93 | 87.40 | 87.34 | 14.41 | |
| Gyro. | Smoking | 51.28 (±0.380) | 51.07 (±0.418) | 50.53 (±0.69) | 45.81 (±0.649) | 45.19 (±1.065) | 56.99 (±1.86) | 68.64 (±5.345) | 68.63 (±4.833) | 33.74 (±7.32) |
| Eating | 67.03 (±0.394) | 66.36 (±0.431) | 35.29 (±1.27) | 61.62 (±1.548) | 59.92 (±1.717) | 44.20 (±2.25) | 80.42 (±4.736) | 80.77 (±4.417) | 21.07 (±7.20) | |
| Drinking | 43.00 (±0.657) | 42.67 (±0.515) | 57.71 (±0.54) | 37.09 (±3.286) | 34.79 (±3.426) | 65.06 (±2.30) | 46.40 (±5.949) | 45.72 (±6.773) | 54.97 (±3.14) | |
| Inactive | 11.49 (±0.650) | 7.03 (±0.904) | 92.97 (±0.42) | 15.08 (±0.168) | 4.40 (±0.250) | 91.14 (±0.05) | 13.11 (±0.705) | 7.21 (±0.479) | 90.80 (±0.35) | |
| Avg. (all) | 43.20 | 41.78 | 59.13 | 39.90 | 36.08 | 64.35 | 52.14 | 50.58 | 50.15 | |
| Avg. (active) | 53.77 | 53.37 | 47.84 | 48.17 | 46.63 | 55.42 | 65.15 | 65.04 | 36.59 | |
| Mag. | Smoking | 54.77 (±3.998) | 53.79 (±4.619) | 48.86 (±2.92) | 57.85 (±2.779) | 56.77 (±3.134) | 40.62 (±1.43) | 78.06 (±10.695) | 78.18 (±10.496) | 21.49 (±8.35) |
| Eating | 76.10 (±3.206) | 76.10 (±3.163) | 25.01 (±1.02) | 78.77 (±2.733) | 78.34 (±2.959) | 22.21 (±3.35) | 89.81 (±3.266) | 89.85 (±3.194) | 15.08 (±5.63) | |
| Drinking | 44.09 (±4.993) | 42.58 (±6.440) | 53.45 (±3.64) | 63.66 (±1.984) | 63.69 (±2.074) | 40.68 (±1.62) | 76.82 (±7.711) | 76.92 (±7.568) | 24.07 (±4.91) | |
| Inactive | 15.41 (±0.006) | 4.11 (±0.003) | 90.92 (±0.02) | 14.59 (±0.230) | 8.64 (±1.611) | 90.43 (±0.51) | 14.34 (±0.343) | 8.69 (±1.485) | 89.95 (±0.67) | |
| Avg. (all) | 47.59 | 44.15 | 54.56 | 53.72 | 51.86 | 48.49 | 64.76 | 63.41 | 37.65 | |
| Avg. (active) | 58.32 | 57.49 | 42.44 | 66.76 | 66.27 | 34.50 | 81.56 | 81.65 | 20.21 | |
| Acc.+ Gyro. | Smoking | 71.11 (±0.928) | 70.92 (±1.067) | 29.13 (±0.78) | 69.24 (±2.088) | 69.29 (±2.119) | 9.58 (±1.61) | 91.20 (±0.610) | 91.19 (±0.612) | 9.74 (±1.94) |
| Eating | 83.27 (±0.420) | 83.10 (±0.425) | 17.74 (±1.23) | 84.12 (±2.734) | 84.42 (±2.471) | 15.51 (±0.38) | 91.65 (±1.781) | 91.69 (±1.756) | 8.42 (±1.66) | |
| Drinking | 67.92 (±0.905) | 67.58 (±1.027) | 32.90 (±1.46) | 65.87 (±3.575) | 66.06 (±3.352) | 31.38 (±2.72) | 84.78 (±2.265) | 84.73 (±2.367) | 13.63 (±0.41) | |
| Inactive | 14.21 (±0.829) | 6.77 (±1.379) | 91.48 (±0.34) | 14.61 (±0.352) | 8.01 (±0.966) | 90.96 (±0.11) | 14.14 (±0.608) | 8.47 (±1.316) | 90.24 (±0.65) | |
| Avg. (all) | 59.13 | 57.09 | 42.81 | 58.46 | 56.95 | 36.86 | 70.44 | 69.02 | 30.51 | |
| Avg. (active) | 74.10 | 73.87 | 26.59 | 73.08 | 73.26 | 18.82 | 89.21 | 89.20 | 10.60 | |
| Acc.+Mag. | Smoking | 87.14 (±1.329) | 87.14 (±1.329) | 11.82 (±0.98) | 82.27 (±2.381) | 82.24 (±2.449) | 18.64 (±2.91) | 96.63 (±0.489) | 96.63 (±0.490) | 3.07 (±0.51) |
| Eating | 96.08 (±0.462) | 96.07 (±0.449) | 4.81 (±0.58) | 93.34 (±3.324) | 93.40 (±3.181) | 5.66 (±2.15) | 97.98 (±0.088) | 97.96 (±0.082) | 2.88 (±0.79) | |
| Drinking | 86.80 (±0.974) | 86.90 (±0.906) | 12.66 (±1.00) | 78.65 (±6.253) | 78.69 (±6.262) | 20.23 (±4.56) | 96.47 (±0.237) | 96.46 (±0.245) | 3.41 (±0.36) | |
| Inactive | 15.26 (±0.181) | 4.54 (±0.710) | 90.94 (±0.04) | 14.81 (±0.197) | 7.05 (±0.460) | 89.98 (±0.42) | 14.54 (±0.481) | 8.73 (±0.651) | 8.38 (± 1.82) | |
| Avg. (all) | 71.32 | 90.04 | 30.06 | 67.27 | 84.78 | 33.63 | 76.41 | 74.95 | 4.44 | |
| Avg. (active) | 90.01 | 54.93 | 9.76 | 84.75 | 64.97 | 14.84 | 97.03 | 97.02 | 3.12 | |
| Gyro.+Mag. | Smoking | 60.64 (±1.497) | 60.54 (±1.645) | 40.23 (±3.16) | 61.35 (±2.468) | 60.59 (±2.604) | 38.22 (±4.16) | 86.76 (±3.827) | 86.79 (±3.738) | 17.74 (±4.98) |
| Eating | 81.14 (±1.512) | 81.17 (±1.449) | 20.61 (±1.47) | 81.67 (±1.875) | 81.50 (±1.917) | 20.29 (±1.46) | 87.24 (±4.701) | 87.52 (±4.434) | 7.71 (±1.80) | |
| Drinking | 49.13 (±16.952) | 46.86 (±21.449) | 47.88 (±3.49) | 63.93 (±2.815) | 63.79 (±2.591) | 40.80 (±2.80) | 78.58 (±2.384) | 78.60 (±2.304) | 20.04 (±4.20) | |
| Inactive | 15.10 (±0.577) | 4.61 (±0.967) | 90.91 (±0.01) | 15.01 (±0.206) | 6.34 (±1.098) | 90.63 (±0.23) | 14.43 (±0.162) | 8.56 (±1.152) | 89.93 (±0.45) | |
| Avg. (all) | 51.50 | 48.30 | 49.91 | 68.98 | 53.06 | 47.49 | 66.75 | 65.37 | 33.86 | |
| Avg. (active) | 63.64 | 62.86 | 36.24 | 44.39 | 68.63 | 33.10 | 84.19 | 84.30 | 15.16 | |
| Acc.+Gyro.+Mag. | Smoking | 88.68 (±0.492) | 88.68 (±0.477) | 11.60 (±1.10) | 80.40 (±2.335) | 80.39 (±2.450) | 21.50 (±6.94) | 97.24 (±0.280) | 97.24 (±0.280) | 2.85 (±0.46) |
| Eating | 95.84 (±1.247) | 95.83 (±1.246) | 5.02 (±0.57) | 95.18 (±0.658) | 95.18 (±0.613) | 5.93 (±2.22) | 98.15 (±0.178) | 98.13 (±0.179) | 2.32 (±0.27) | |
| Drinking | 88.16 (±0.916) | 88.27 (±0.888) | 14.15 (±1.65) | 80.18 (±4.504) | 80.36 (±4.613) | 19.53 (±3.39) | 96.54 (±0.511) | 96.54 (±0.496) | 3.39 (±0.22) | |
| Inactive | 15.34 (±0.136) | 4.13 (±0.038) | 90.90 (±0.01) | 14.89 (±0.325) | 8.38 (±1.965) | 90.57 (±0.56) | 14.62 (±0.330) | 9.22 (±1.107) | 89.92 (±0.68) | |
| Avg. (all) | 72.01 | 69.23 | 30.42 | 67.66 | 66.08 | 34.38 | 76.64 | 75.28 | 24.62 | |
| Avg. (active) | 90.89 | 90.93 | 10.26 | 85.25 | 85.31 | 15.65 | 97.31 | 97.30 | 2.85 | |
| Activity | Identification Performance on Classifier Evaluation of DL Models Using WIDSM-HARB Dataset (Acc. and Gyro.). | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CNN | LSTM | 1D-ResNet-SE | ||||||||
| Accuracy ± SD | F1 ± SD | EER | Accuracy ± SD | F1 ± SD | EER | Accuracy ± SD | F1 ± SD | EER | ||
| Simple Motion | Walking | 68.14 (±1.230) | 67.41 (±1.295) | 31.35 (±3.92) | 78.00 (±3.059) | 77.30 (±3.504) | 20.84 (±3.30) | 93.26 (±3.302) | 93.35 (±3.131) | 10.82 (±7.16) |
| Jogging | 74.66 (±2.131) | 73.84 (±2.309) | 27.69 (±2.16) | 86.84 (±2.473) | 86.62 (±2.518) | 14.74 (±2.32) | 96.25 (±2.100) | 96.20 (±2.088) | 2.43 (±0.49) | |
| Stairs | 41.84 (±3.244) | 42.13 (±2.911) | 56.01 (±2.29) | 58.04 (±3.625) | 56.90 (±3.718) | 44.54 (±2.57) | 82.83 (±7.179) | 82.53 (±7.345) | 13.01 (±8.27) | |
| Sitting | 68.47 (±1.366) | 67.62 (±1.484) | 31.42 (±1.68) | 67.03 (±2.887) | 64.80 (±2.883) | 33.28 (±3.25) | 71.66 (±4.868) | 69.90 (±5.767) | 25.47 (±5.56) | |
| Standing | 59.47 (±2.546) | 58.81 (±2.539) | 41.81 (±1.63) | 61.53 (±1.138) | 58.65 (±1.455) | 38.48 (±2.43) | 64.12 (±8.317) | 61.68 (±9.090) | 36.11 (±4.95) | |
| Kicking | 37.53 (±2.361) | 36.92 (±1.994) | 64.52 (±3.56) | 46.56 (±2.854) | 43.75 (±3.225) | 54.15 (±1.65) | 84.28 (±5.572) | 84.36 (±5.362) | 17.35 (±8.92) | |
| Hand Complex Movement | Dribbling | 58.55 (±6.655) | 57.98 (±6.575) | 40.81 (±2.00) | 75.24 (±1.676) | 74.43 (±1.958) | 26.65 (±2.45) | 93.43 (±4.231) | 93.35 (±4.284) | 9.43 (±11.91) |
| Catch | 52.55 (±3.207) | 51.03 (±3.199) | 53.87 (±3.78) | 64.22 (±4.014) | 62.49 (±4.472) | 33.74 (±4.20) | 94.37 (±4.718) | 94.31 (±4.806) | 4.89 (±1.39) | |
| Typing | 76.98 (±1.429) | 76.26 (±1.701) | 22.08 (±1.56) | 70.74 (±4.555) | 67.79 (±5.454) | 28.46 (±2.52) | 84.69 (±2.886) | 83.74 (±3.188) | 18.34 (±3.93) | |
| Writing | 72.06 (±2.128) | 71.10 (±2.416) | 32.28 (±2.80) | 70.23 (±1.821) | 68.06 (±2.037) | 31.26 (±3.88) | 81.67 (±8.008) | 81.10 (±8.612) | 38.34 (±20.69) | |
| Clapping | 78.59 (±3.466) | 77.96 (±4.025) | 17.48 (±3.24) | 88.89 (±2.398) | 88.55 (±2.590) | 12.69 (±1.32) | 95.99 (±2.523) | 95.76 (±2.800) | 3.14 (±2.36) | |
| Teeth | 68.09 (±2.737) | 67.14 (±3.101) | 31.68 (±2.35) | 68.64 (±4.315) | 67.29 (±4.261) | 29.63 (±2.89) | 95.31 (±1.966) | 95.16 (±2.079) | 5.31 (±1.57) | |
| Folding | 37.80 (±1.622) | 36.31 (±1.761) | 59.93 (±2.56) | 48.84 (±2.396) | 46.15 (±2.343) | 51.28 (±1.90) | 76.12 (±11.614) | 75.19 (±12.463) | 22.84 (±8.31) | |
| Pasta | 56.11 (±2.703) | 55.01 (±2.727) | 43.67 (±1.52) | 62.89 (±2.473 | 61.09 (±2.401) | 37.88 (±2.83) | 82.81 (±5.391) | 82.50 (±5.598) | 15.31 (±4.55) | |
| Soup | 64.68 (±2.369) | 64.21 (±2.512) | 34.25 (±2.91) | 71.31 (±2.613) | 69.99 (±3.035) | 30.06 (±0.76) | 88.02 (±6.895) | 87.92 (±7.091) | 10.69 (±1.49) | |
| Sandwich | 50.83 (±2.568) | 49.43 (±2.252) | 47.98 (±4.74) | 56.83 (±1.992) | 53.25 (±2.512) | 45.50 (±1.13) | 78.08 (±1.063) | 77.83 (±0.953) | 21.99 (±2.49) | |
| Chips | 50.52 (±2.702) | 49.53 (±2.206) | 52.60 (±2.54) | 58.42 (±3.183) | 55.94 (±3.239) | 38.07 (±2.41) | 81.20 (±6.487) | 80.88 (±6.662) | 16.35 (±2.72) | |
| Drinking | 60.11 (±2.413) | 59.51 (±2.591) | 40.90 (±4.19) | 61.94 (±2.148) | 59.57 (±2.682) | 37.74 (±1.33) | 81.80 (±1.485) | 81.38 (±1.675) | 17.02 (±1.90) | |
| Average | 59.83 | 59.01 | 40.57 | 66.45 | 64.59 | 34.94 | 84.77 | 84.29 | 16.05 | |
| Activity | Recognition Effectiveness on Classifier Evaluation of DL Models Using WIDSM-HARB Dataset (Acc.). | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CNN | LSTM | 1D-ResNet-SE | ||||||||
| Accuracy ± SD | F1 ± SD | EER | Accuracy ± SD | F1 ± SD | EER | Accuracy ± SD | F1 ± SD | EER | ||
| Simple Motion | Walking | 52.14 (±1.384) | 52.16 (±1.541) | 44.87 (±3.05) | 66.05 (±2.426) | 64.99 (±3.000) | 38.45 (±4.01) | 91.91 (±1.623) | 91.65 (±1.755) | 12.01 (±4.26) |
| Jogging | 54.80 (±3.332) | 54.32 (±3.556) | 46.36 (±3.85) | 77.74 (±3.976) | 77.48 (±4.231) | 25.76 (±2.69) | 93.42 (±1.980) | 93.28 (±2.238) | 7.10 (±2.47) | |
| Stairs | 32.28 (±2.522) | 31.01 (±2.780) | 66.85 (±1.16) | 45.61 (±3.929) | 42.67 (±4.630) | 52.93 (±2.56) | 78.01 (±8.410) | 77.24 (±8.826) | 20.46 (±7.40) | |
| Sitting | 64.98 (±2.314) | 64.45 (±2.472) | 35.50 (±1.93) | 60.35 (±3.066) | 57.48 (±3.784) | 39.59 (±2.06) | 71.55 (±5.009) | 70.41 (±5.788) | 28.85 (±3.33) | |
| Standing | 61.24 (±1.972) | 59.61 (±2.221) | 38.37 (±2.54) | 56.53 (±2.148) | 52.08 (±2.355) | 43.65 (±1.15) | 62.47 (±3.619) | 60.96 (±3.654) | 36.99 (±5.82) | |
| Kicking | 28.93 (±2.614) | 28.05 (±2.555) | 68.49 (±1.20) | 41.58 (±2.884) | 38.70 (±3.460) | 59.30 (±3.39) | 72.67 (±5.045) | 71.68 (±5.070) | 27.05 (±2.53) | |
| Hand Complex Movement | Dribbling | 44.34 (±1.771) | 43.48 (±1.764) | 54.72 (±1.35) | 63.01 (±6.270) | 61.11 (±6.266) | 38.50 (±1.26) | 90.96 (±3.829) | 90.86 (±3.856) | 12.20 (±14.56) |
| Catch | 37.40 (±3.813) | 36.62 (±3.898) | 65.13 (±2.53) | 57.04 (±4.027) | 55.43 (±4.389) | 42.97 (±2.62) | 90.66 (±1.680) | 90.72 (±1.544) | 19.85 (±14.15) | |
| Typing | 70.12 (±7.315) | 68.85 (±7.755) | 29.26 (±4.93) | 68.77 (±2.418) | 65.68 (±2.560) | 2.18 (±2.71) | 77.22 (±5.938) | 75.81 (±6.881) | 25.46 (±7.33) | |
| Writing | 64.71 (±1.891) | 64.06 (±2.342) | 37.97 (±3.06) | 63.23 (±4.084) | 60.84 (±4.719) | 37.34 (±3.96) | 54.76 (±16.852) | 52.27 (±17.678) | 35.14 (±10.76) | |
| Clapping | 71.63 (±5.277) | 70.78 (±5.572) | 29.46 (±2.11) | 79.82 (±3.143) | 79.16 (±3.505) | 20.45 (±2.23) | 93.09 (±2.551) | 93.00 (±2.561) | 7.03 (±2.25) | |
| Teeth | 59.26 (±2.407) | 58.51 (±2.259) | 37.73 (±3.23) | 63.27 (±2.111) | 61.47 (±1.890) | 38.69 (±3.05) | 90.37 (±3.344) | 90.34 (±3.345) | 7.91 (±1.38) | |
| Folding | 36.24 (±3.944) | 35.30 (±3.842) | 63.66 (±2.34) | 44.42 (±0.754) | 41.62 (±0.719) | 54.68 (±4.95) | 79.54 (±3.411) | 79.24 (±3.461) | 22.39 (±2.81) | |
| Pasta | 52.12 (±2.994) | 51.58 (±2.995) | 48.38 (±2.25) | 56.60 (±2.922) | 54.34 (±3.274) | 43.61 (±3.34) | 82.39 (±2.943) | 81.93 (±2.987) | 27.56 (±11.70) | |
| Soup | 59.27 (±3.055) | 58.43 (±3.125) | 42.73 (±4.47) | 60.63 (±4.157) | 58.12 (±4.833) | 39.18 (±1.01) | 82.68 (±6.134) | 81.78 (±7.039) | 17.38 (±7.21) | |
| Sandwich | 50.46 (±2.102) | 49.33 (±1.517) | 50.20 (±2.12) | 53.28 (±1.784) | 50.06 (±1.866) | 23.80 (±1.76) | 74.28 (±1.979) | 73.70 (±2.101) | 23.80 (±1.76) | |
| Chips | 47.76 (±2.208) | 46.53 (±2.561) | 55.04 (±3.66) | 52.29 (±2.488) | 50.14 (±2.893) | 24.22 (±2.76) | 76.91 (±1.069) | 76.47 (±1.202) | 24.22 (±2.76) | |
| Drinking | 55.08 (±2.754) | 54.03 (±2.571) | 45.96 (±2.47) | 56.44 (±1.570) | 53.36 (±1.842) | 24.81 (±3.13) | 74.23 (±3.473) | 73.21 (±3.614) | 24.81 (±3.13) | |
| Average | 52.38 | 51.51 | 47.82 | 59.26 | 53.93 | 36.12 | 79.84 | 79.14 | 21.12 | |
| Activity | Recognition Effectiveness on Classifier Evaluation of DL Models Using WIDSM-HARB Dataset (Gyro.). | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CNN | LSTM | 1D-ResNet-SE | ||||||||
| Accuracy ± SD | F1 ± SD | EER | Accuracy ± SD | F1 ± SD | EER | Accuracy ± SD | F1 ± SD | EER | ||
| Simple Motion | Walking | 54.72 (±1.465) | 54.18 (±1.506) | 45.97 (±1.50) | 49.69 (±4.723) | 46.49 (±4.400) | 51.33 (±4.89) | 84.74 (±13.344) | 83.92 (±14.802) | 7.89 (±3.86) |
| Jogging | 58.73 (±2.690) | 57.80 (±2.572) | 42.06 (±2.87) | 61.87 (±4.805) | 59.95 (±5.992) | 38.91 (±4.88) | 92.74 (±11.612) | 92.15 (±12.797) | 8.80 (±6.26) | |
| Stairs | 23.57 (±1.631) | 22.37 (±1.524) | 76.48 (±1.59) | 24.48 (±3.510) | 21.656 (±2.971) | 75.56 (±3.52) | 83.57 (±8.468) | 83.22 (±8.659) | 15.12 (±6.85) | |
| Sitting | 18.53 (±1.513) | 17.97 (±1.147) | 82.53 (±1.63) | 09.57 (±0.354) | 7.31 (±0.710) | 91.07 (±0.29) | 19.61 (±1.308) | 18.00 (±1.280) | 81.55 (±2.27) | |
| Standing | 14.76 (±2.124) | 14.22 (±2.384) | 86.09 (±1.98) | 8.118 (±0.802) | 05.87 (±1.002) | 92.83 (±1.15) | 20.76 (±6.836) | 19.57 (±7.979) | 73.52 (±8.14) | |
| Kicking | 17.07 (±2.259) | 16.01 (±2.424) | 83.26 (±1.97) | 25.31 (±4.754) | 22.65 (±4.271) | 75.62 (±4.49) | 80.47 (±5.510) | 80.06 (±5.909) | 18.14 (±3.50) | |
| Hand Complex Movement | Dribbling | 49.88 (±1.678) | 48.88 (±1.400) | 50.08 (±1.88) | 60.96 (±4.594) | 58.01 (±5.165) | 39.32 (±4.55) | 91.75 (±11.119) | 91.51 (±11.570) | 3.30 (±1.73) |
| Catch | 33.93 (±1.015) | 33.61 (±0.900) | 66.97 (±0.84) | 32.37 (±5.311) | 29.080 (±5.411) | 68.47 (±5.36) | 92.457 (±7.628) | 92.17 (±8.210) | 3.76 (±0.92) | |
| Typing | 26.54 (±1.069) | 25.02 (±1.136) | 74.55 (±1.22) | 33.27 (±3.089) | 29.61 (±3.073) | 67.45 (±3.26) | 82.84 (±11.221) | 82.54 (±11.622) | 25.63 (±6.83) | |
| Writing | 23.84 (±1.954) | 22.86 (±2.152) | 78.04 (±1.46) | 34.76 (±5.479) | 32.16 (±5.968) | 66.74 (±5.36) | 58.64 (±15.074) | 54.18 (±17.788) | 25.54 (±20.07) | |
| Clapping | 77.48 (±2.574) | 77.14 (±2.449) | 22.94 (±2.61) | 73.66 (±1.376) | 71.98 (±1.735) | 26.95 (±1.46) | 95.37 (±6.640) | 95.20 (±6.964) | 3.77 (±2.49) | |
| Teeth | 49.38 (±1.549) | 48.38 (±1.764) | 50.47 (±1.48) | 40.86 (±4.84) | 37.24 (±4.594) | 59.50 (±4.63) | 92.65 (±2.852) | 92.57 (±2.887) | 11.24 (±5.35) | |
| Folding | 11.67 (±1.063) | 11.21 (±0.950) | 88.86 (±0.97) | 14.41 (±2.488) | 12.81 (±2.683) | 86.88 (±2.37) | 74.17 (±1.693) | 73.70 (±2.128) | 25.83 (±7.36) | |
| Pasta | 23.67 (±2.899) | 22.61 (±3.101) | 77.48 (±2.74) | 15.32 (±1.698) | 11.90 (±1.699) | 85.23 (±1.69) | 81.90 (±2.340) | 81.38 (±2.690) | 14.71 (±2.77) | |
| Soup | 34.58 (±2.684) | 33.87 (±2.541) | 65.77 (±2.71) | 26.41 (±4.782) | 22.86 (±4.585) | 74.54 (±4.90) | 85.69 (±7.019) | 85.09 (±7.844) | 11.14 (±9.50) | |
| Sandwich | 19.41 (±0.922) | 18.56 (±0.911) | 80.71 (±0.69) | 16.10 (±2.210) | 12.42 (±2.770) | 84.23 (±2.25) | 53.65 (±9.941) | 51.81 (±10.759) | 48.61 (±17.12) | |
| Chips | 18.25 (±2.270) | 17.57 (±1.829) | 82.18 (±2.31) | 14.88 (±4.596) | 11.26 (±4.318) | 85.71 (±4.51) | 73.12 (±10.084) | 73.25 (±10.004) | 27.18 (±4.45) | |
| Drinking | 25.06 (±1.836) | 23.83 (±1.812) | 76.07 (±1.79) | 17.44 (±8.376) | 14.10 (±8.025) | 83.43 (±8.37) | 55.03 (±15.631) | 53.43 (±16.501) | 48.35 (±14.77) | |
| Average | 32.28 | 31.45 | 68.36 | 31.08 | 28.19 | 66.02 | 73.29 | 72.43 | 25.23 | |
| Hand Complex Movement | Test Models | Accuracy ± SD | Wilcoxon Test | |
|---|---|---|---|---|
| p-Value | ||||
| Smoking | 1D-ResNet | 93.61 (±0.45) | 0.043 | reject |
| 1D-ResNet-SE | 97.24 (±0.28) | |||
| Eating | 1D-ResNet | 97.19 (±0.21) | 0.079 | accept |
| 1D-ResNet-SE | 98.15 (±0.18) | |||
| Drinking | 1D-ResNet | 92.71 (±0.51) | 0.022 | reject |
| 1D-ResNet-SE | 96.62 (±0.33) | |||
| Hand Complex Movement | Test Models | Accuracy ± SD | Wilcoxon Test | |
|---|---|---|---|---|
| p-Value | ||||
| Dribbling | 1D-ResNet | 92.95 (±1.07) | 0.686 | accept |
| 1D-ResNet-SE | 93.43 (±4.23) | |||
| Catch | 1D-ResNet | 94.36 (±0.58) | 0.691 | accept |
| 1D-ResNet-SE | 94.37 (±4.12) | |||
| Typing | 1D-ResNet | 76.67 (±13.19) | 0.039 | reject |
| 1D-ResNet-SE | 84.69 (±2.89) | |||
| Writing | 1D-ResNet | 53.30 (±15.65) | 0.012 | reject |
| 1D-ResNet-SE | 81.67 (±8.01) | |||
| Clapping | 1D-ResNet | 94.78 (±0.93) | 0.043 | reject |
| 1D-ResNet-SE | 95.99 (±2.52) | |||
| Teeth | 1D-ResNet | 95.00 (±2.66) | 0.642 | accept |
| 1D-ResNet-SE | 95.31 (±1.97) | |||
| Folding | 1D-ResNet | 75.41 (±2.57) | 0.633 | accept |
| 1D-ResNet-SE | 76.12 (±11.61) | |||
| Pasta | 1D-ResNet | 81.01 (±2.44) | 0.345 | accept |
| 1D-ResNet-SE | 82.81 (±5.39) | |||
| Soup | 1D-ResNet | 87.35 (±2.08) | 0.728 | accept |
| 1D-ResNet-SE | 88.02 (±6.90) | |||
| Sandwich | 1D-ResNet | 77.83 (±2.80) | 0.043 | reject |
| 1D-ResNet-SE | 78.08 (±1.06) | |||
| Chips | 1D-ResNet | 80.40 (±5.86) | 0.138 | accept |
| 1D-ResNet-SE | 81.20 (±6.49) | |||
| Drinking | 1D-ResNet | 78.86 (±4.68) | 0.025 | reject |
| 1D-ResNet-SE | 81.80 (±1.49) | |||
| Activity | Models | Friedman Aligned Ranking Test | Finner Post-Hoc Test | |
|---|---|---|---|---|
| p-Value | ||||
| Smoking | Acc.+Gyro. | 1.1526 | - | - |
| Acc. | 2.6264 | 0.0000021 | reject | |
| Gyro. | 4.3519 | 0.0000203 | reject | |
| Eating | Acc.+Gyro. | 1.2728 | - | - |
| Acc. | 2.6168 | 0.0000036 | reject | |
| Gyro. | 4.5962 | 0.0016952 | reject | |
| Drinking | Acc.+Gyro. | 1.0607 | - | - |
| Acc. | 2.8284 | 0.0000001 | reject | |
| Gyro. | 4.0607 | 0.0000001 | reject | |
| Activity | Models | Friedman Aligned Ranking Test | Finner Post-Hoc Test | |
|---|---|---|---|---|
| p-Value | ||||
| Dribbling | Acc.+Gyro. | 1.7678 | - | - |
| Acc. | 3.3941 | 0.346 | accept | |
| Gyro. | 3.3234 | 0.786 | accept | |
| Catch | Acc.+Gyro. | 1.0606 | - | - |
| Acc. | 3.8890 | 0.043 | reject | |
| Gyro. | 3.5355 | 0.225 | accept | |
| Typing | Acc.+Gyro. | 1.9091 | - | - |
| Acc. | 3.6769 | 0.345 | accept | |
| Gyro. | 2.8991 | 0.686 | accept | |
| Writing | Acc.+Gyro. | 2.1920 | - | - |
| Acc. | 3.6062 | 0.501 | accept | |
| Gyro. | 2.6870 | 0.345 | accept | |
| Clapping | Acc.+Gyro. | 1.3435 | - | - |
| Acc. | 3.8184 | 0.079 | accept | |
| Gyro. | 3.3234 | 0.893 | accept | |
| Teeth | Acc.+Gyro. | 1.6971 | - | - |
| Acc. | 2.7577 | 0.043 | reject | |
| Gyro. | 4.0305 | 0.138 | accept | |
| Folding | Acc.+Gyro. | 2.9698 | - | - |
| Acc. | 2.4041 | 0.982 | accept | |
| Gyro. | 3.1113 | 0.502 | accept | |
| Pasta | Acc.+Gyro. | 1.4142 | - | - |
| Acc. | 3.4648 | 0.079 | accept | |
| Gyro. | 3.6062 | 0.892 | accept | |
| Soup | Acc.+Gyro. | 1.8384 | - | - |
| Acc. | 3.5355 | 0.041 | reject | |
| Gyro. | 3.1112 | 0.501 | accept | |
| Sandwich | Acc.+Gyro. | 1.0607 | - | - |
| Acc. | 3.5355 | 0.138 | accept | |
| Gyro. | 3.8891 | 0.042 | reject | |
| Chips | Acc.+Gyro. | 1.4849 | - | - |
| Acc. | 2.4042 | 0.041 | reject | |
| Gyro. | 4.5962 | 0.015 | reject | |
| Drinking | Acc.+Gyro. | 1.1313 | - | - |
| Acc. | 3.1113 | 0.043 | reject | |
| Gyro. | 4.2426 | 0.021 | reject | |
| Activity | Identification Performance (%Accuracy) | ||||||
|---|---|---|---|---|---|---|---|
| Acc. | Gyro. | Acc.+Gyro. | |||||
| Random Forest [17] | 1D-ResNet-SE | Random Forest [17] | 1D-ResNet-SE | Random Forest [17] | 1D-ResNet-SE | ||
| Simple Motion | Walking | 75.10 | 91.91 | 67.00 | 84.74 | 78.90 | 93.26 |
| Jogging | 75.00 | 93.42 | 74.30 | 92.74 | 82.10 | 96.25 | |
| Stairs | 52.40 | 78.01 | 39.20 | 83.57 | 58.70 | 82.83 | |
| Sitting | 70.40 | 71.55 | 30.10 | 19.61 | 69.30 | 71.66 | |
| Standing | 64.10 | 62.47 | 27.00 | 20.76 | 61.20 | 64.12 | |
| Kicking | 54.30 | 72.67 | 38.30 | 80.47 | 59.80 | 84.28 | |
| Average | 65.22 | 78.34 | 45.98 | 63.65 | 68.33 | 82.07 | |
| Hand Complex Movement | Dribbling | 72.30 | 90.96 | 74.80 | 91.75 | 80.30 | 93.43 |
| Catch | 69.10 | 90.66 | 71.30 | 92.46 | 75.40 | 94.37 | |
| Typing | 81.20 | 77.22 | 51.20 | 82.84 | 84.20 | 84.69 | |
| Writing | 79.60 | 54.76 | 47.60 | 58.64 | 79.10 | 81.67 | |
| Clapping | 83.40 | 93.09 | 73.90 | 95.37 | 85.30 | 95.99 | |
| Teeth | 70.00 | 90.37 | 56.30 | 92.65 | 76.10 | 95.31 | |
| Folding | 60.00 | 79.54 | 38.80 | 74.17 | 63.00 | 76.12 | |
| Pasta | 67.20 | 82.39 | 38.10 | 81.90 | 71.60 | 82.81 | |
| Soup | 74.10 | 82.68 | 50.40 | 85.69 | 76.60 | 88.02 | |
| Sandwich | 61.90 | 74.28 | 37.60 | 53.65 | 62.10 | 78.08 | |
| Chips | 62.60 | 76.91 | 38.70 | 73.12 | 62.40 | 81.20 | |
| Drinking | 63.90 | 74.23 | 41.30 | 55.03 | 65.30 | 81.80 | |
| Average | 70.44 | 80.59 | 51.67 | 78.11 | 73.45 | 86.12 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mekruksavanich, S.; Jitpattanakul, A. Deep Residual Network for Smartwatch-Based User Identification through Complex Hand Movements. Sensors 2022, 22, 3094. https://doi.org/10.3390/s22083094
Mekruksavanich S, Jitpattanakul A. Deep Residual Network for Smartwatch-Based User Identification through Complex Hand Movements. Sensors. 2022; 22(8):3094. https://doi.org/10.3390/s22083094
Chicago/Turabian StyleMekruksavanich, Sakorn, and Anuchit Jitpattanakul. 2022. "Deep Residual Network for Smartwatch-Based User Identification through Complex Hand Movements" Sensors 22, no. 8: 3094. https://doi.org/10.3390/s22083094