1. Introduction
The electromagnetic (EM) waves-based remote sensing has many potential applications such as behind the wall object identification [
1], multi-layer target detection [
2], material characterization [
3], defect detection [
4,
5,
6,
7], and many more. In EM and radio frequency (RF) waves-based detection of objects/defects which are behind or inside a layered structure, the EM waves that reflect from the object/defect are analyzed. Here, one major challenge is the presence of strong unwanted reflections, i.e., clutter [
1,
8]. In this context, the main source of the clutter is the reflection from the surface of the layered material structure.
The state-of-the-art clutter suppression methods such as background subtraction (BS), time-gating, and subspace projection (SP) [
9] are not able to suppress the clutter in the context of object/defect detection. This is due to the fact that in BS, it requires the reference data of the scene, and this reference data is not available most of the time. Moreover, in the SP, prior knowledge is required to determine the perfect threshold for clutter removal. On the other hand, in time-gating, the time window in which clutter resides needs to be determined for successful clutter removal. However, this time window cannot be determined exactly. Clutter suppression becomes even more challenging if objects and clutter are closely located. This occurs regularly in the detection of defects which are inside a layered structure. Then, due to the small delay spread, the signaling responses of defects and clutter superimpose each other. In order to overcome these challenges, advanced signal processing methods are required for clutter suppression [
1,
8,
10].
In many scenarios, the responses of the material defects are weak and, thus, difficult to detect. Even if there is no clutter, due to very low signal amplitude, it may be difficult to detect material defects in the presence of noise. In this context, the weak signal detection in the presence of noise has drawn attention in the defect detection research field. Therefore, we briefly discuss the weak signal detection in the following. Stochastic resonance has been widely used in weak signal detection [
11,
12,
13]. In [
11], to improve upon the weak signal detection by stochastic resonance, the relationship between the current and the previous value of the state variable of the system has been utilized. It is worth noticing that weak signal detection plays an important role in other applications such as health monitoring. Similar to defect detection, health monitoring aims to detect weak signals in the presence of strong noise. In [
14], a comparative study of well-known adaptive mode decomposition approaches that are used for the aforementioned task is reviewed. Here, the advantages, limitations, and the performance comparison of adaptive mode decomposition approaches, namely empirical mode decomposition, Hilbert vibration decomposition, and variational mode decomposition, have been given. Other than signal detection, the extraction of features of the detected signal is important in many applications as these features are used for classification and clustering. In this context, it is important to select the most important features as the accuracy and speed of the classification depend on the features that are used. The impact of the feature selection for electromyographic signal decomposition is studied in [
15]. Moreover, in this study, various feature extraction methods are compared, and a guide to select the most important features that improve the signal decomposition is provided [
15]. As we discussed above, weak signal detection in the presence of disturbances like noise or clutter is challenging, therefore, advanced signal procession methods are required. Next, we discuss clutter suppression in more detail.
In many scenarios, the number of defects is limited. Therefore, the signaling response of the defect is sparse in nature. By exploring this, compressive sensing (CS) [
16] based approaches have shown promising results in object/defect detection with clutter [
1,
8]. In addition, the CS-based approaches do not require a full measurement data set, which results in fast data acquisition and less sensitivity to sensor failure, wireless interference, and jamming. In CS-based approaches, it is considered that the clutter resides in a low-rank subspace and the response of the objects is sparse [
1,
8].
To this end, we present a general data acquisition model where the received data vector
is modeled as a combination of a low-rank matrix
and a sparse matrix
with
:
in which
with
,
are compression operators/measurement matrices and measurement noise, respectively. Here, the compression ratio is defined as
. Further,
denotes the vectorization operator, which converts a matrix to a vector by stacking the columns of the matrix. Given the received data vector
, our aim is to estimate the signals of interest,
, using a small number of linear measurements by minimizing the rank and sparsity as
where
,
are regularization parameters and
is a small positive constant (noise bound). Here,
is the
-norm, i.e., sparsity (the number of non-zero components). Note that the problem given in (
2) is also known as robust principal component analysis (RPCA) [
17]. The RPCA problem has different types as follows: (a) standard/classical RPCA in which both
and
in (
1) are identity matrices [
17], (b) the matrices
and
is a selection operator which select a random subset of size
K from
entries [
18], (c) both
and
are
matrices which map the vector space
to the vector space
[
18].
The problem given in (
2) is an NP-hard problem and, thus, difficult to solve. To this end, convex relaxations of sparsity and rank in terms of
-norm of a matrix (absolute sum of elements) and nuclear norm of a matrix (sum of singular values) are utilized, respectively [
19,
20,
21]. However, enjoying a rigorous analysis, the convex relaxations of sparsity and rank cause disadvantages in many applications. In addition to that, in many applications, the important properties of the signal are preserved by the large coefficients/singular values of the signal [
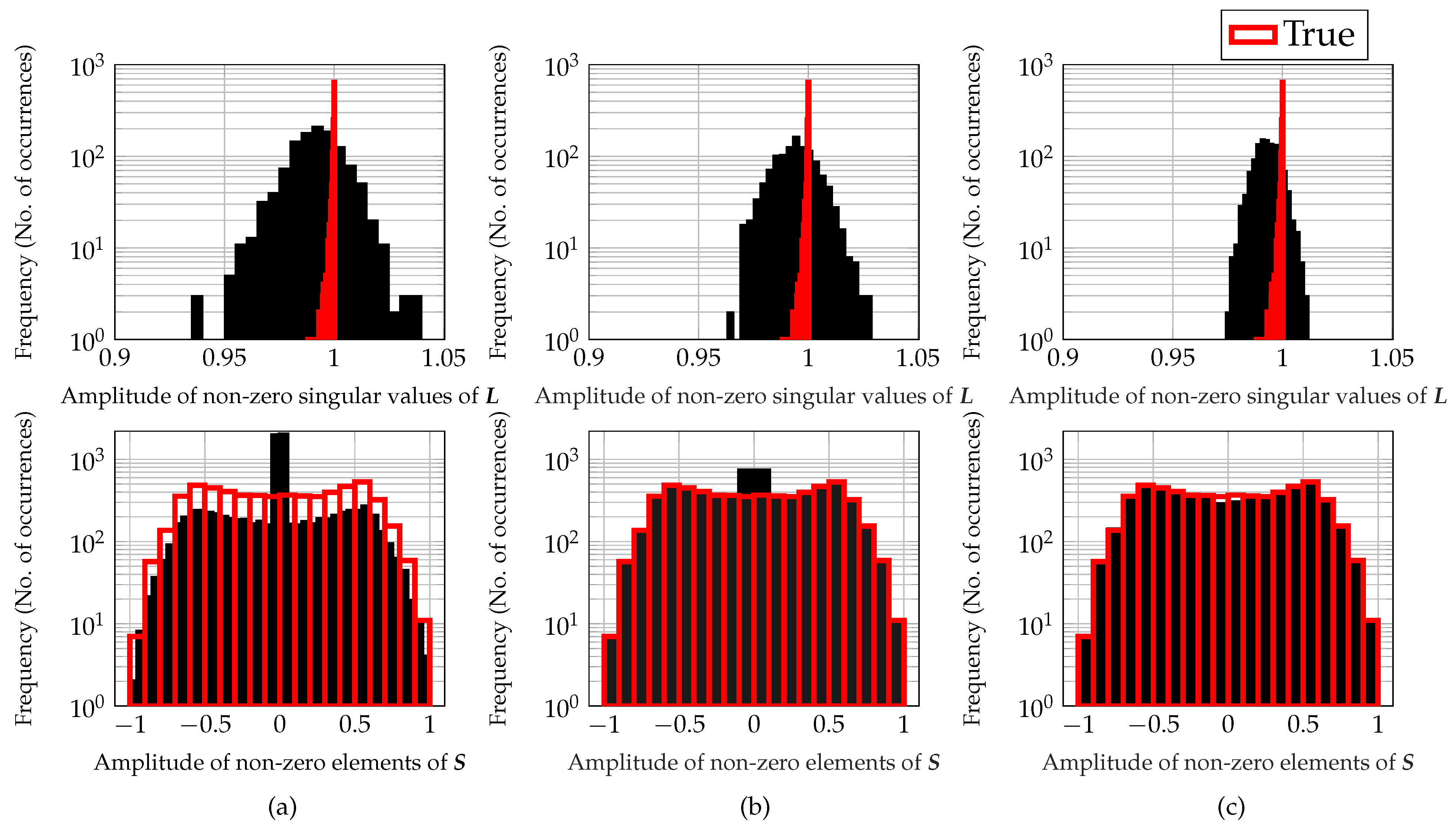
22]. However, the
-norm/nuclear norm minimization algorithms shrink all the coefficients/singular values with the same threshold. Thus, to avoid this weakness, we should shrink less the larger coefficients/singular values. To address aforementioned drawbacks, non-convex approaches such as reweighted nuclear norm and reweighted
-norm minimization have been considered [
22,
23,
24,
25]. These non-convex approaches have shown better performance over the convex relaxations by providing tighter characterizations of rank and sparsity, yet their behavior and convergence have not been fully studied [
26].
Generally, RPCA problems are numerically solved by means of iterative algorithms based on the alternating direction method of multipliers (ADMM) [
17,
27,
28] or accelerated proximal gradient (APG) [
29,
30]. In iterative algorithms, the accuracy of the recovered signal component and the convergence rate depends on the proper selection of parameters (e.g., regularization/thresholding/denoising parameters). Generally, parameters are chosen by handcrafting, and it is a time-consuming task. In this context, machine learning-based parameter tuning using training data has shown promising results in many applications such as sparse vector recovery [
31,
32,
33] and image processing [
34]. For instance, as shown in [
31], the unfolded iterative soft-thresholding algorithm (LISTA) converges twenty times faster than the conventional iterative soft-thresholding algorithm (ISTA). This approach is known as algorithm unrolling/unfolding, and an overview can be found in [
35].
In this work, we formulate the detection of material defects as a RPCA problem. This RPCA problem is solved based on the reweighted nuclear norm and reweighted
-norm minimization. However, most of the time, RPCA problems are solved by using the convex relaxation or with the single reweighting, i.e., either reweighted
-norm or reweighted nuclear norm [
22,
30,
36,
37]. Next, our objective is to jointly estimate the low-rank matrix and the sparse matrix from few compressive measurements. It is worth noticing that most of the work in the literature focuses on the standard RPCA problem, where
and
are identity matrices [
22,
36]. To the best of our knowledge, the full doubly reweighted (joint reweighted nuclear norm and reweighted
-norm) approach has not yet been studied comprehensively in the literature for the compressive case. Then, we propose an iterative algorithm for (locally) minimizing the objective, i.e., reweighted nuclear norm and reweighted
-norm, which is based on the alternating direction method of multipliers (ADMM) [
38,
39]. Further, we propose deep learning-based parameter tuning to improve the accuracies of the recovered low-rank and sparse components and the convergence rate of the ADMM-based iterative algorithm.
In addition to the EM-based defect detection, there are many applications where the data generated by the application can be modeled as a combination of low-rank plus sparse contributions. For instance, in video surveillance, the static background results in a low-rank contribution, and moving objects result in a sparse contribution [
40]. Further, in human face recognition from a corrupted face image, the human face can be approximated as a low-rank structure while self-shadowing and specularities are modeled as sparse contributions [
40,
41]. Therefore, RPCA can be applied to the aforementioned applications and other applications as long as the data/measurements are combinations of low-rank and sparse contributions. It is worth noticing that our proposed full doubly reweighted (joint reweighted nuclear norm and reweighted
-norm) approach with deep learning-based parameter tuning for RPCA is not limited to EM-based defect detection and can be applied to other applications that are solved using RPCA.
In the context of the algorithm unfolding for the RPCA, the convolutional robust principal component analysis (CORONA) [
30,
37] are the closest studies to our work. There are fundamental methodological differences between our work and [
30,
37]: (a) Both [
30,
37] considered the standard convex relaxation (
-norm and nuclear norm) to solve the RPCA problem, while we propose the reweighted
-norm and reweighted nuclear norm. (b) In this work, the RPCA problem is solved by an iterative algorithm based on ADMM, while the iterative algorithm in [
30,
37] is based on fast ISTA (FISTA). The motivation to propose ADMM over ISTA/FISTA for RPCA is as follows. As shown in [
17,
27] for RPCA, the ADMM-based approach is able to achieve the desired solution with a good recovery error with few iterations for a wide range of applications compared to APG-based approaches like ISTA/FISTA. Further, the performances of the APG-based approaches are heavily dependent on the good continuation schemes [
17]. This condition may not be satisfied for a wide range of applications. (c) Different from [
30,
37], our focus is on defect detection based on the stepped-frequency continuous wave (SFCW) radar, while [
30,
37] focus on ultrasound imaging application. Moreover, experimental measurement data of [
30,
37] have considered that
in (
1) is an identity matrix, while we consider both scenarios where
is an identity matrix and it is a compression operator. Further, for the SFCW radar application, we consider that
. Further, we have studied the performance of our approach with a generic real-valued Gaussian model for different compression ratios.
The CORONA focuses on ultrasound imaging applications where sparse matrix has row-sparse structure. Thus, there is a strong relationship between measurement to measurement, and there is a common sparsity structure. Therefore,
-norm minimization is more suitable than
-norm minimization to estimate sparse matrix
. Further, the CORONA is based on a convolutional deep neural network to learn spatial invariance features of data, which is more suitable for ultrasound imaging applications than a dense deep neural network (DNN). However, we assume that there is no strong relationship of a data element to its neighboring elements, nor is there a specific sparsity structure. Thus, we consider a dense DNN in this work. It is straightforward to modify our ADMM approach with convolutional DNN and the
-norm minimization. In CORONA [
30], customized complex-valued convolution layers and singular value decomposition operations are utilized. In our work, we have implemented a dense DNN which supports complex-valued data and singular value decomposition (SVD) operation. The contributions of this work are summarized as follows:
1.1. Contribution
We propose a generic approach based on the non-convex fully double-reweighted approach, i.e., both reweighted -norm and reweighted nuclear norm simultaneously to solve the RPCA problem. To this end, we propose an iterative algorithm based on ADMM to estimate the low-rank and sparse components jointly.
In contrast to standard/classical RPCA, we consider the compressive sensing data acquisition model, which reflects more on the practical problem at hand. Next, to improve the accuracy and convergence speed of the ADMM-based iterative algorithm, we propose a deep neural network (DNN) to tune the parameters of the iterative algorithm (i.e., algorithm unfolding/unrolling) from training data.
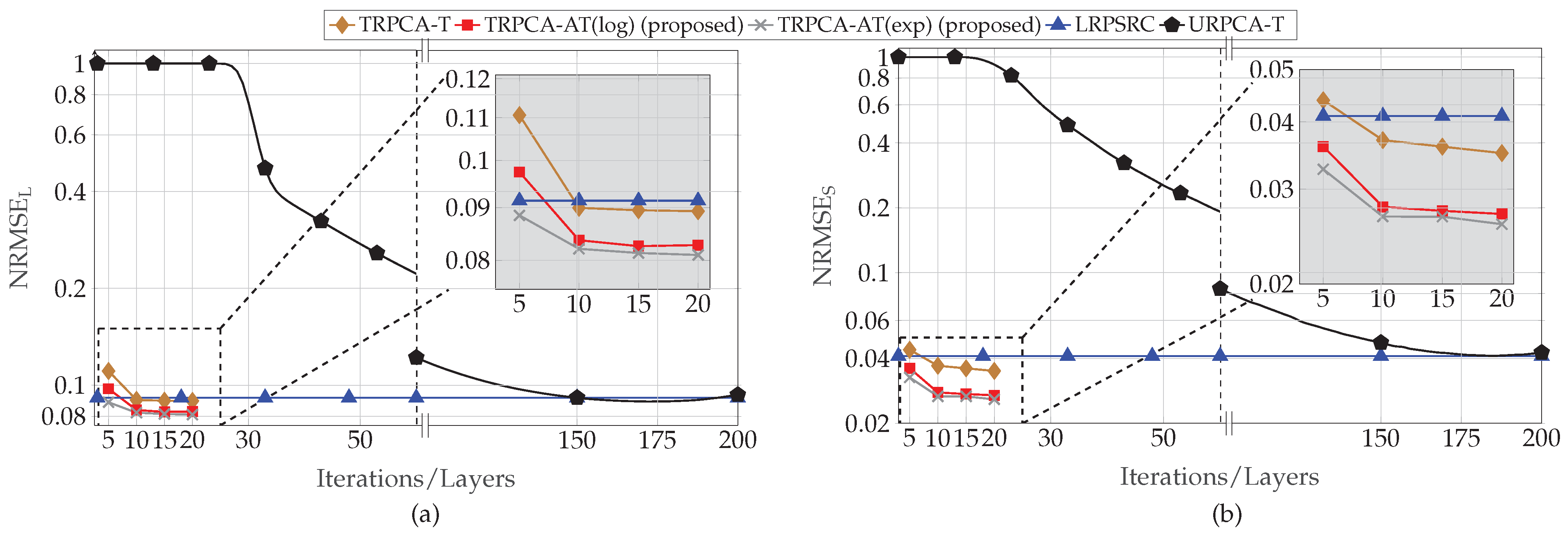
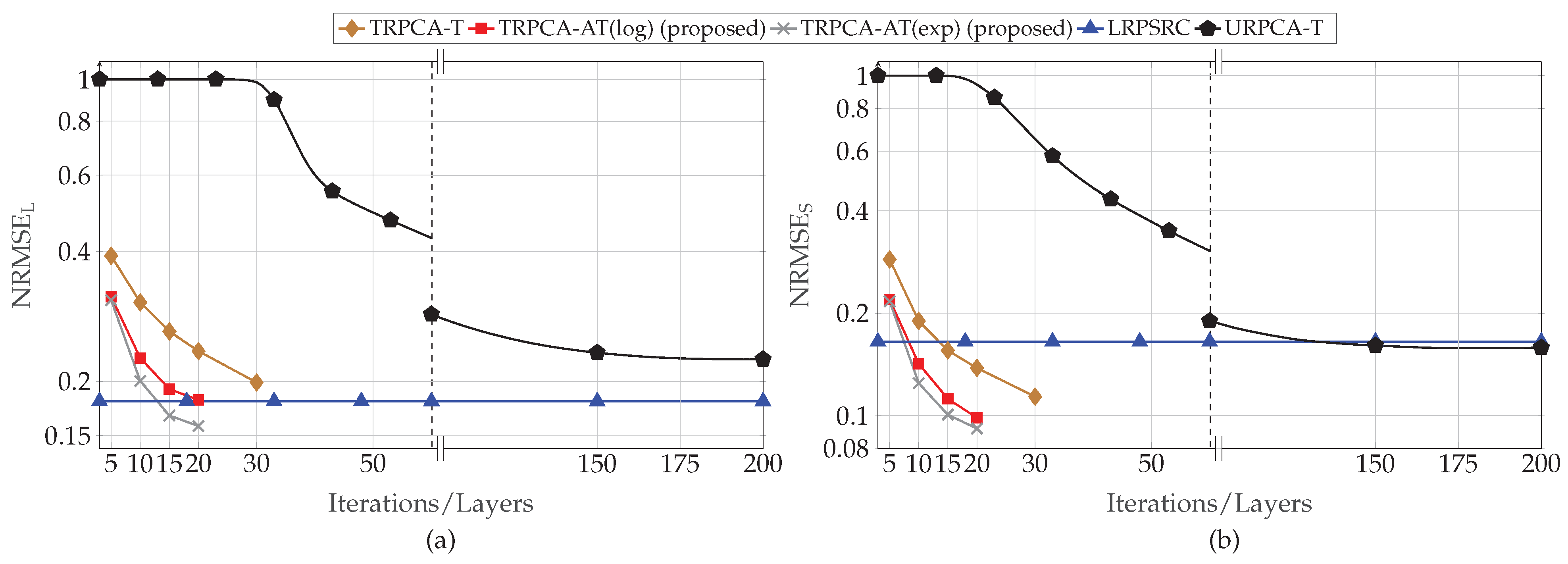
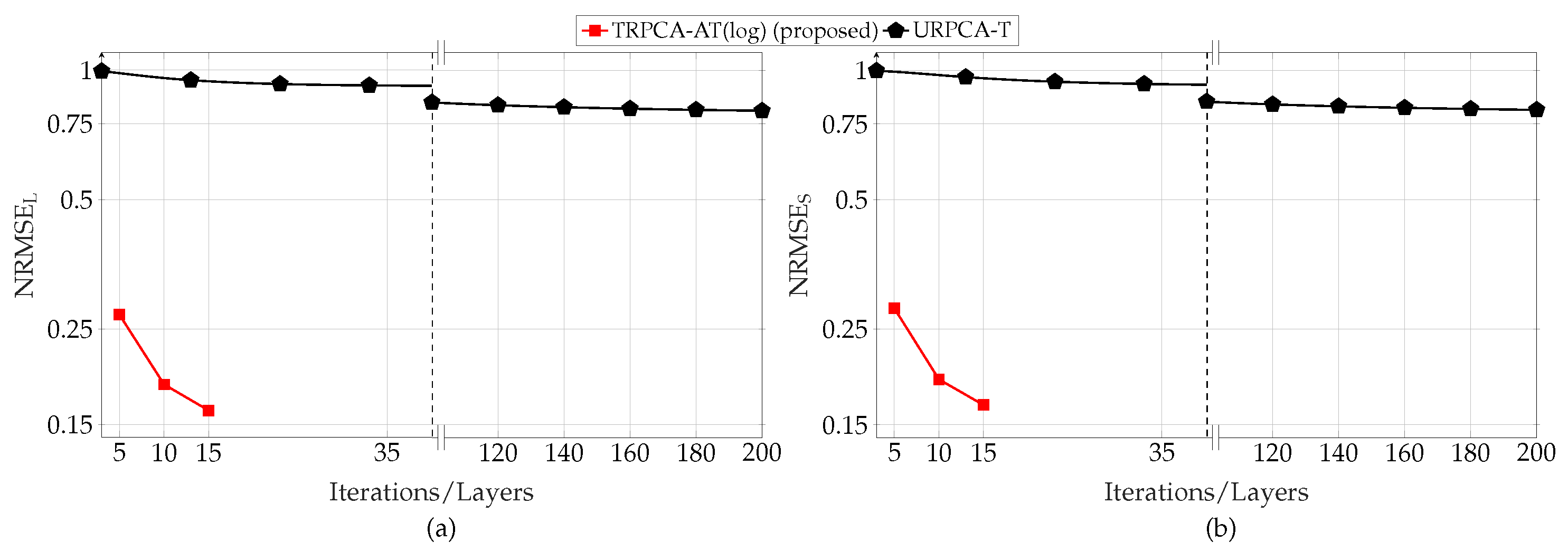
We intensively evaluate our proposed approach for a generic Gaussian data acquisition model with . In addition to that, the defect detection by SFCW radar from compressive measurements with is considered. To compare our approach, we consider the standard convex approach (i.e., nuclear norm and -norm minimization) and the untrained ADMM-based iterative algorithm for different compression ratios. In both the generic Gaussian data acquisition model and SFCW-based defect detection, our numerical results show that the proposed approach outperforms the conventional approaches in terms of mean squared errors of the recovered low-rank and sparse components and the speed of convergence.
In the context of algorithm unrolling for RPCA, we compare our approach with the approach given in [
30] (CORONA). It turns out that our proposed approach shows similar performance as CORONA for experimental ultrasound imaging data used in [
30], and our approach outperforms CORONA for generic Gaussian data. It is worth noticing that there is a row-sparse nature of the experimental ultrasound data. That is the reason CORONA uses
-norm minimization to estimate sparse matrix
. Our approach is generic, yet our approach is able to achieve similar results as CORONA by learning. This shows the applicability of our approach to different types of use cases and data (defect detection, ultrasound imaging, generic Gaussian data).
We numerically analyze the robustness of our proposed approach for the generic Gaussian data acquisition model. Here, we consider the deviation in the measurement matrices () and testing signal-to-noise ratio (SNR) uncertainty. It was observed that the proposed approach is robust for a small deviation in the measurement matrices. Further, it was observed that training with the SNR like 5 dB is favorable when SNR of the testing data is unknown.
The remainder of the paper is organized as follows. We introduce the SFCW radar-based defect detection and the low-rank plus sparse recovery with reweighting in
Section 2. In
Section 3, we discuss the DNN-based low-rank plus sparse recovery algorithm unfolding. In
Section 4, we provide an evaluation of the proposed DNN-based low-rank plus sparse recovery algorithm unfolding approaches and provide interesting insights.
Section 5 concludes the paper.
1.2. Notation
In this paper, the following notation is used. A vector is denoted in boldface lower-case letter, while the matrices are denoted in boldface upper-case. The -norm (the number of nonzero components), -norm (absolute sum of elements) of a matrix/vector, and nuclear norm of a matrix (sum of singular values) are denoted by , , and , respectively. Further, the Frobenius norm of a matrix and -norm is given by and , respectively. The Hermitian and transpose of the matrix are represented by and , respectively. In addition, the Moore–Penrose pseudo inverse is denoted by . A matrix of size with all elements equal to zero and one are denoted by and , respectively. Moreover, a vector of size M with all elements equal to zero and one are denoted by and , respectively. In addition, identity matrix is denoted by . The main variable list and abbreviations that are used in this manuscript are listed at the end of the manuscript.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}