
Runtime ML-DL Hybrid Inference Platform Based on Multiplexing Adaptive Space-Time Resolution for Fast Car Incident Prevention in Low-Power Embedded Systems



Abstract
:1. Introduction
2. Related Research Work
3. Challenges in Object Detection
3.1. Localization Problem
3.2. Speed Problem for Real-Time Detection
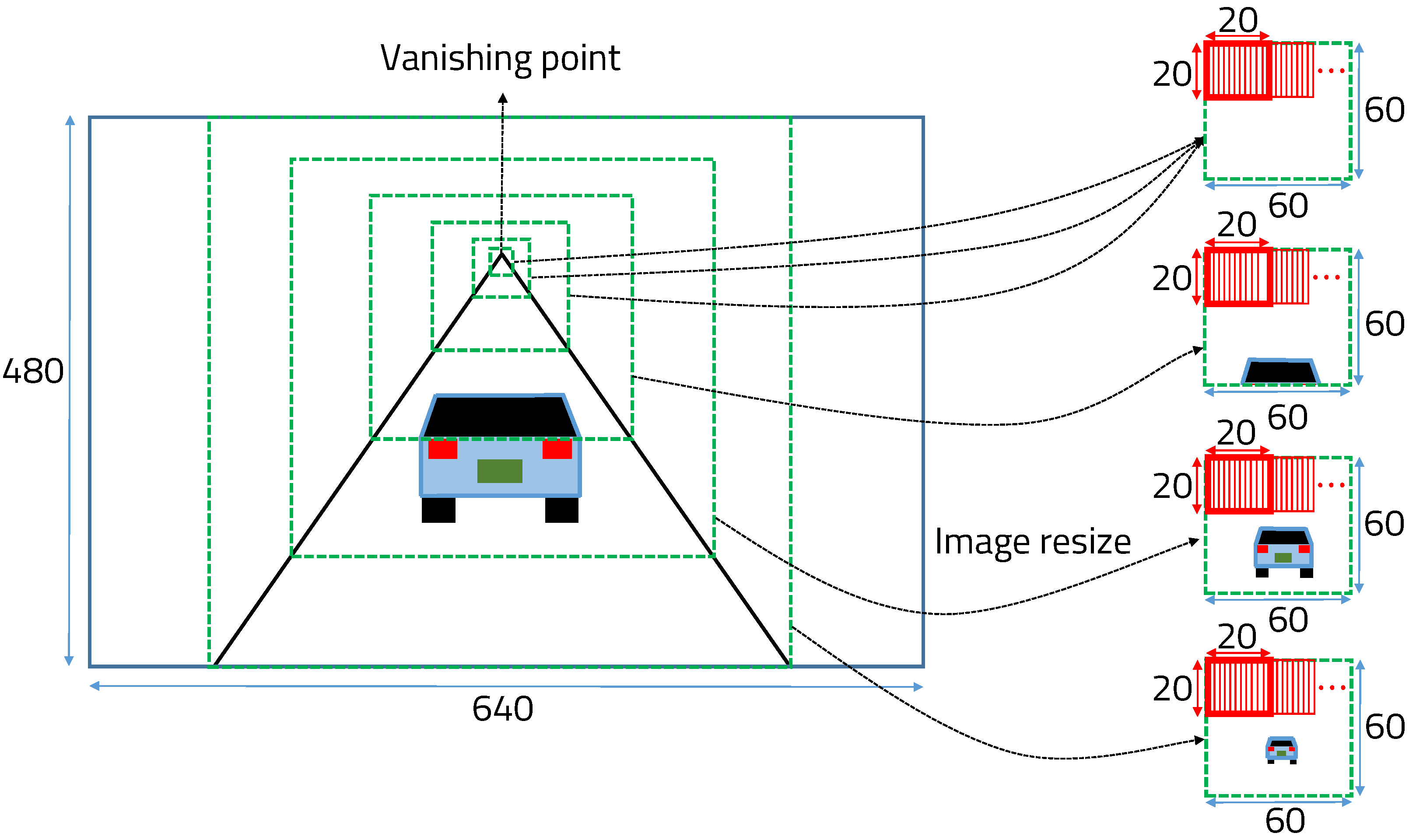
4. System Model and Methods
4.1. Machine-Learning-Based Object Detection
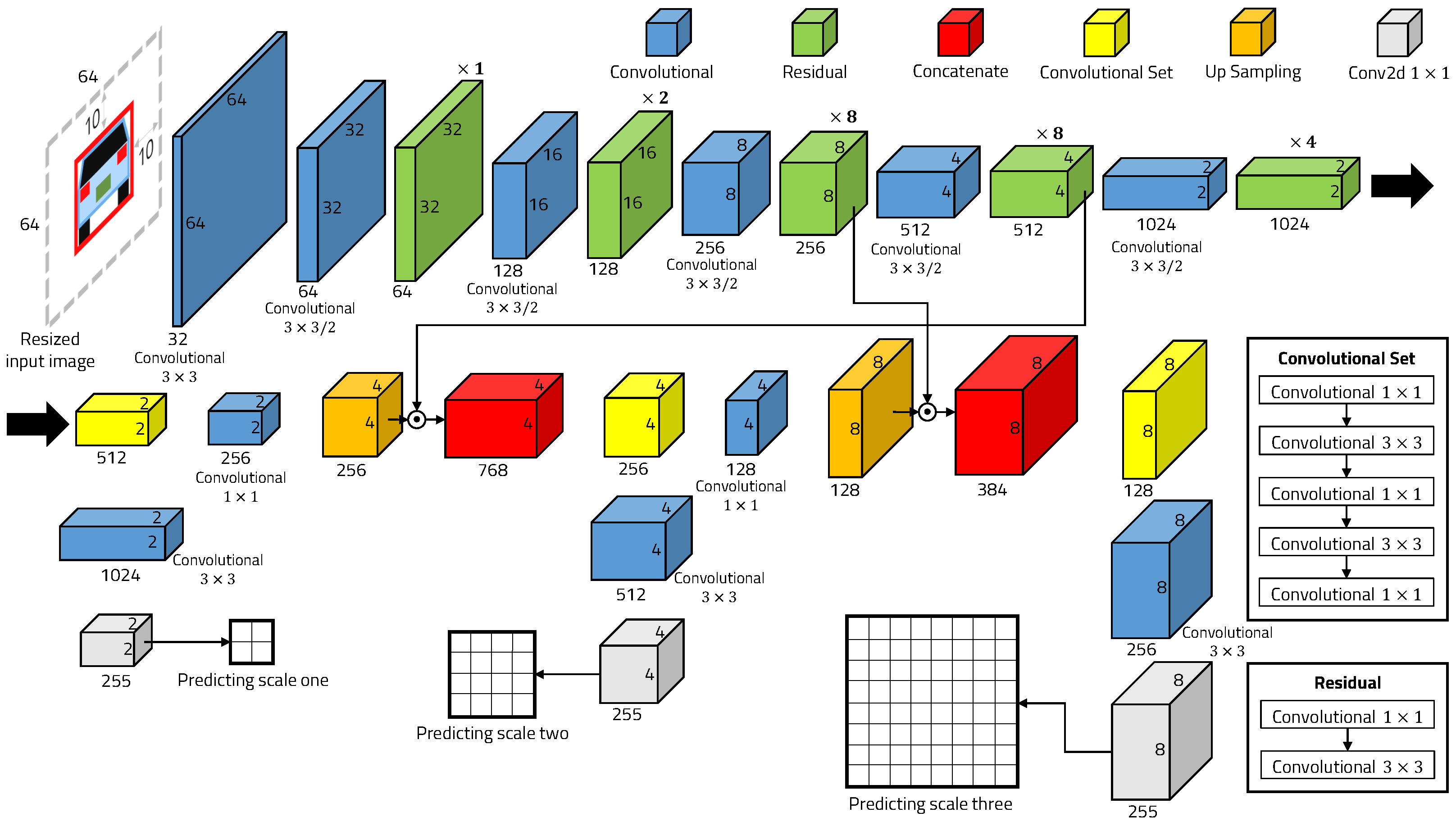
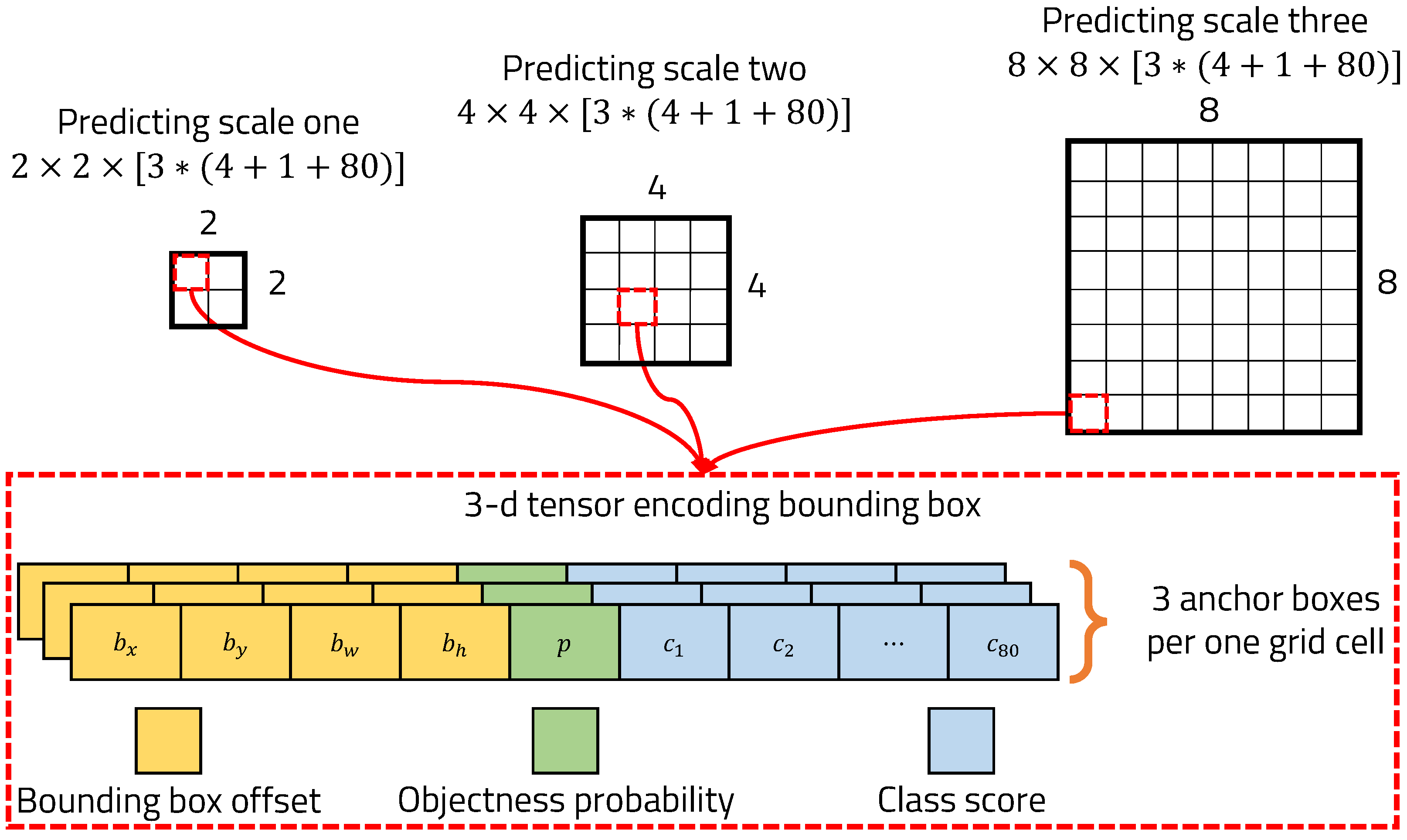
4.2. Deep-Learning-Based Object Detection
4.3. Detected Bounding Box Correction
5. Experiments
- Model: Layerscape® 1028A Applications Processor.
- CPU: 2-core Arm®v8 Cortex-A72 64-bit CPU 48 KB L1-I + 32 KB L1D + 1 MB L2.
- GPU: Vivante GC7000UltraLite.
- RAM: 4 GB 32-bit 1600 MTPS DDR4.
- Storage: 8 GB eMMC.
- Operating System: Linux operating system (an Ubuntu derived OS).
5.1. Execution Time
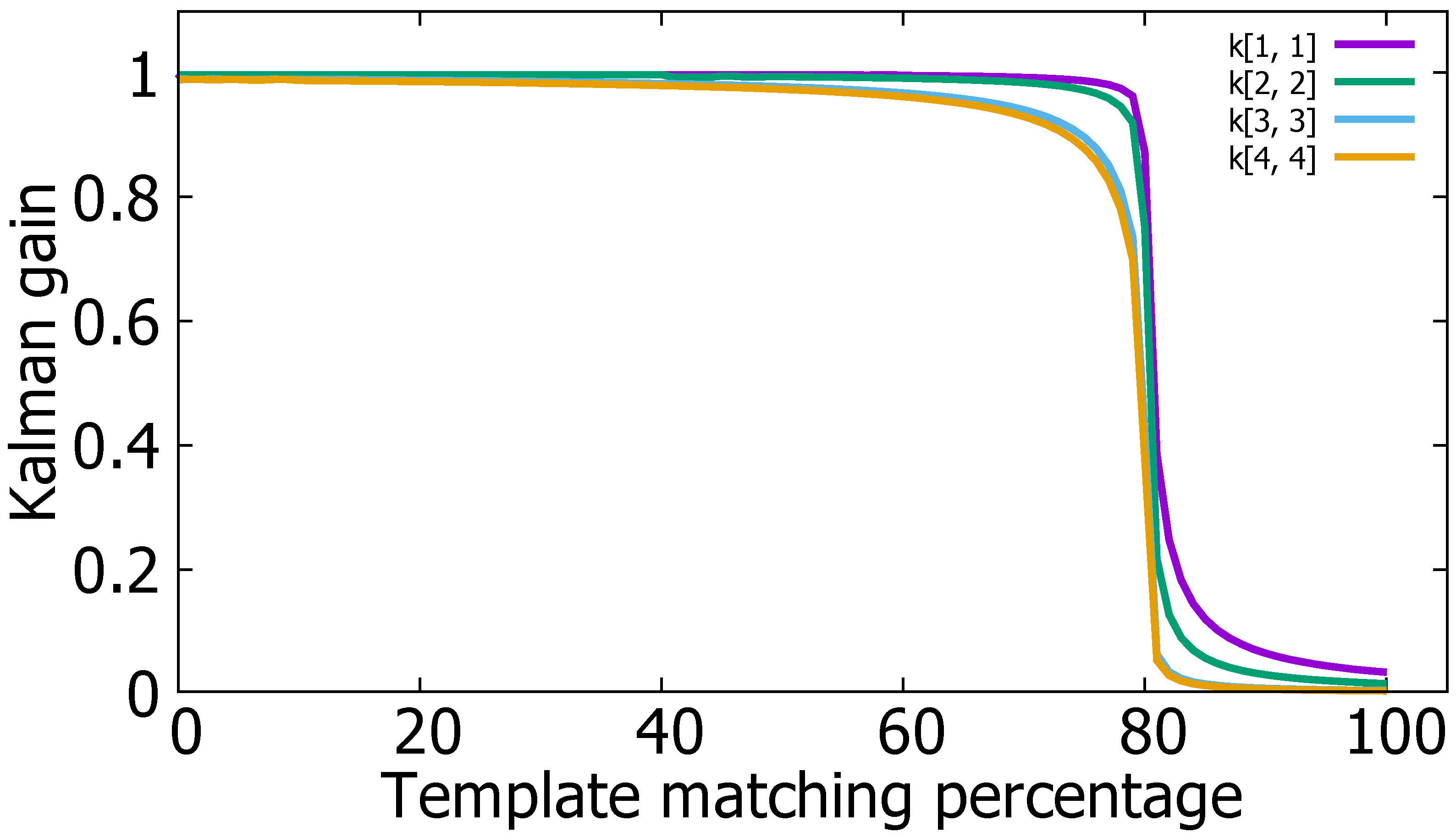
5.2. Kalman Filter Tuning
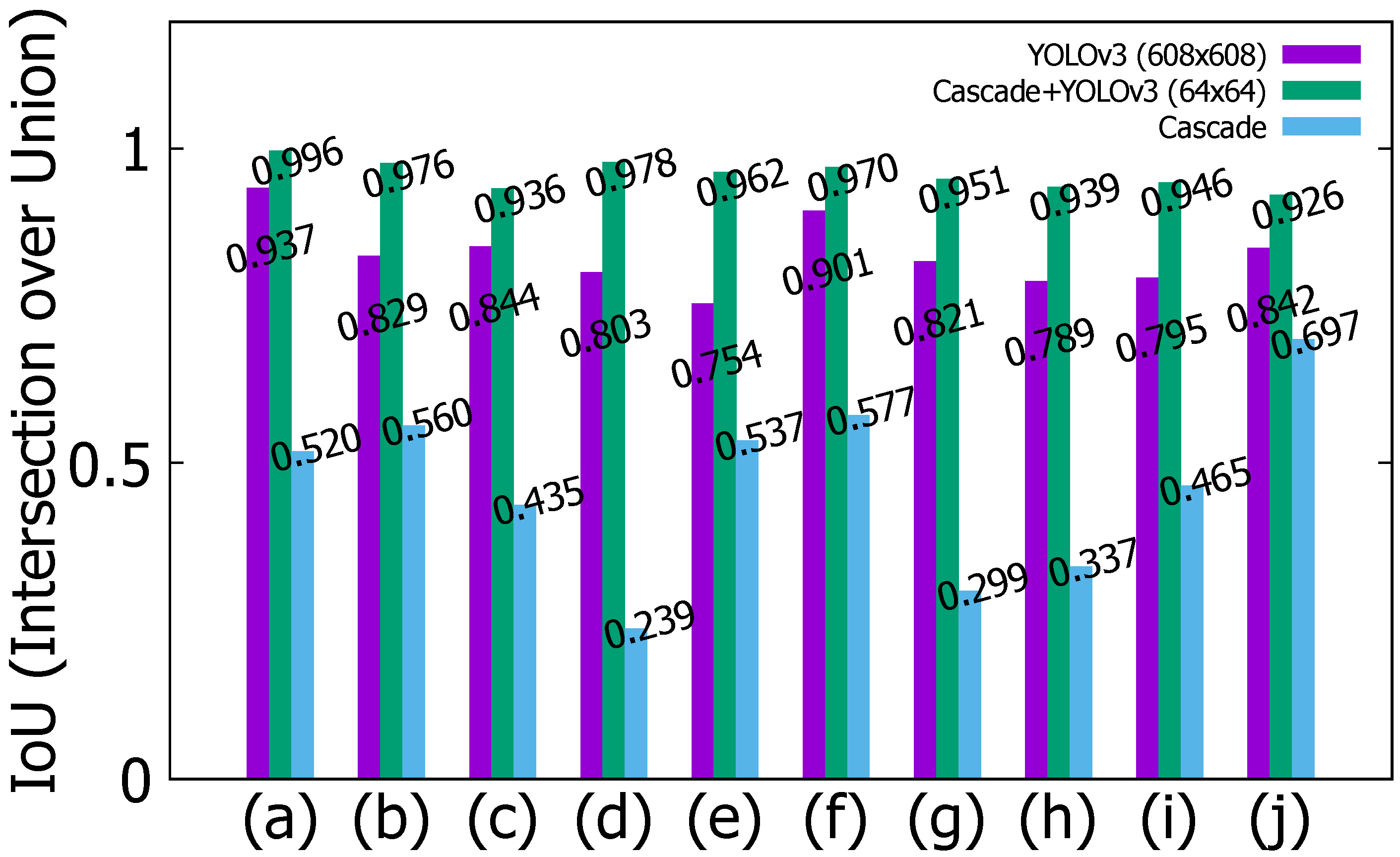
5.3. Detection Performance
6. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ADAS | Advanced Driver Assistance Systems |
| FCWS | Forward Collision Warning System |
| WHO | World Health Organization |
| ML | Machine Learning |
| DL | Deep Learning |
| IoU | Intersection over Union |
References
- World Health Organization. Road Traffic Injuries. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 21 June 2021).
- Okuda, R.; Kajiwara, Y.; Terashima, K. A survey of technical trend of ADAS and autonomous driving. In Proceedings of the Technical Papers of 2014 International Symposium on VLSI Design, Automation and Test, Hsinchu, Taiwan, 28–30 April 2014; pp. 1–4. [Google Scholar]
- Dagan, E.; Mano, O.; Stein, G.P.; Shashua, A. Forward collision warning with a single camera. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 37–42. [Google Scholar]
- National Transportation Safety Board. Vehicle- and Infrastructure-Based Technology for the Prevention of Rear-End Collisions. Available online: https://www.ntsb.gov/safety/safety-studies/Pages/SIR0101.aspx (accessed on 5 January 2001).
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; University of North Carolina at Chapel Hill: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Omachi, S.; Omachi, M. Fast template matching with polynomials. IEEE Trans. Image Process. 2007, 16, 2139–2149. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. WHO Kicks Off a Decade of Action for Road Safety. Available online: https://www.who.int/news/item/28-10-2021-who-kicks-off-a-decade-of-action-for-road-safety (accessed on 28 October 2021).
- Wei, P.; Cagle, L.; Reza, T.; Ball, J.; Gafford, J. LiDAR and camera detection fusion in a real-time industrial multi-sensor collision avoidance system. Electronics 2018, 7, 84. [Google Scholar] [CrossRef] [Green Version]
- Song, W.; Zhang, L.; Tian, Y.; Fong, S.; Liu, J.; Gozho, A. CNN-based 3D object classification using Hough space of LiDAR point clouds. Hum.-Centric Comput. Inf. Sci. 2020, 10, 19. [Google Scholar] [CrossRef]
- Gao, L.; Li, C.; Fang, T.; Xiong, Z. Vehicle detection based on color and edge information. In International Conference Image Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2008; pp. 142–150. [Google Scholar]
- Nur, S.A.; Ibrahim, M.; Ali, N.; Nur, F.I.Y. Vehicle detection based on underneath vehicle shadow using edge features. In Proceedings of the 2016 6th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 25–27 November 2016; pp. 407–412. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Yoo, H.B.; Park, M.S.; Kim, S.H. Real Time Face detection Method Using TensorRT and SSD. KIPS Trans. Softw. Data Eng. 2020, 9, 323–328. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7 December 2015; pp. 1440–1448. [Google Scholar]
- Faster, R. Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 9199, 2969239–2969250. [Google Scholar]
- Cao, D.; Chen, Z.; Gao, L. An improved object detection algorithm based on multi-scaled and deformable convolutional neural networks. Hum.-Cent. Comput. Inf. Sci. 2020, 10, 14. [Google Scholar] [CrossRef] [Green Version]
- Baek, S.; Jeon, J.; Jeong, B.; Jeong, Y.S. Two-stage hybrid malware detection using deep learning. Hum.-Cent. Comput. Inf. Sci. 2021, 11, 2021. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Sarala, S.; Yadav, D.S.; Ansari, A. Emotionally adaptive driver voice alert system for advanced driver assistance system (ADAS) applications. In Proceedings of the 2018 International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 13–14 December 2018; pp. 509–512. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Li, K.; Wang, S.; Du, C.; Huang, Y.; Feng, X.; Zhou, F. Accurate fatigue detection based on multiple facial morphological features. J. Sens. 2019, 2019, 7934516. [Google Scholar] [CrossRef] [Green Version]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed] [Green Version]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Park, J.S.; Park, J.H. Enhanced Machine Learning Algorithms: Deep Learning, Reinforcement Learning, and Q-Learning. J. Inf. Process. Syst. 2020, 16, 1001–1007. [Google Scholar]
- Hong, S.; Park, D. Lightweight Collaboration of Detecting and Tracking Algorithm in Low-Power Embedded Systems for Forward Collision Warning. In Proceedings of the 2021 Twelfth International Conference on Ubiquitous and Future Networks (ICUFN), Jeju, Korea, 17–20 August 2021; pp. 159–162. [Google Scholar]
- Yin, S.; Ouyang, P.; Dai, X.; Liu, L.; Wei, S. An adaboost-based face detection system using parallel configurable architecture with optimized computation. IEEE Syst. J. 2015, 11, 260–271. [Google Scholar] [CrossRef]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The application of improved YOLO V3 in multi-scale target detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Layerscape. LS1028A. Available online: https://www.nxp.com/docs/en/fact-sheet/LS1028AFS.pdf (accessed on 11 December 2021).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frame | 1 | 2 | 3 | ⋯ | 498 | 499 | 500 |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 2 | ⋯ | −2 | −2 | −1 | |
| 1 | 1 | 1 | ⋯ | −2 | 4 | −2 | |
| −3 | −4 | −2 | ⋯ | 2 | 7 | 2 | |
| 6 | 7 | −8 | ⋯ | −14 | −12 | 13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, S.; Park, D. Runtime ML-DL Hybrid Inference Platform Based on Multiplexing Adaptive Space-Time Resolution for Fast Car Incident Prevention in Low-Power Embedded Systems. Sensors 2022, 22, 2998. https://doi.org/10.3390/s22082998
Hong S, Park D. Runtime ML-DL Hybrid Inference Platform Based on Multiplexing Adaptive Space-Time Resolution for Fast Car Incident Prevention in Low-Power Embedded Systems. Sensors. 2022; 22(8):2998. https://doi.org/10.3390/s22082998
Chicago/Turabian StyleHong, Sunghoon, and Daejin Park. 2022. "Runtime ML-DL Hybrid Inference Platform Based on Multiplexing Adaptive Space-Time Resolution for Fast Car Incident Prevention in Low-Power Embedded Systems" Sensors 22, no. 8: 2998. https://doi.org/10.3390/s22082998