
A Neural Network-Based Model for Predicting Saybolt Color of Petroleum Products



Abstract
:1. Introduction
- Saving valuable time spent deciding on the suitable refining feedstock that meets the requirements due to real-time measurements.
- Reducing the cost, since it eliminates sample handling and conditioning for the Saybolt color.
- Constantly monitoring product quality, which serves as an indicator of degrading equipment. This can help to prevent process efficiency losses.
2. Materials and Methods
2.1. Data Collection and Preprocessing
2.2. Feedforward Neural Network-Based Model
2.3. Multiple Linear Regression-Based Model
- y is the predicted output;
- x, , and are the independent input variables;
- and are the regression coefficients;
- is the residual error.
2.4. Model Training and Testing
2.5. Model Performance Evaluation
3. Results and Discussion
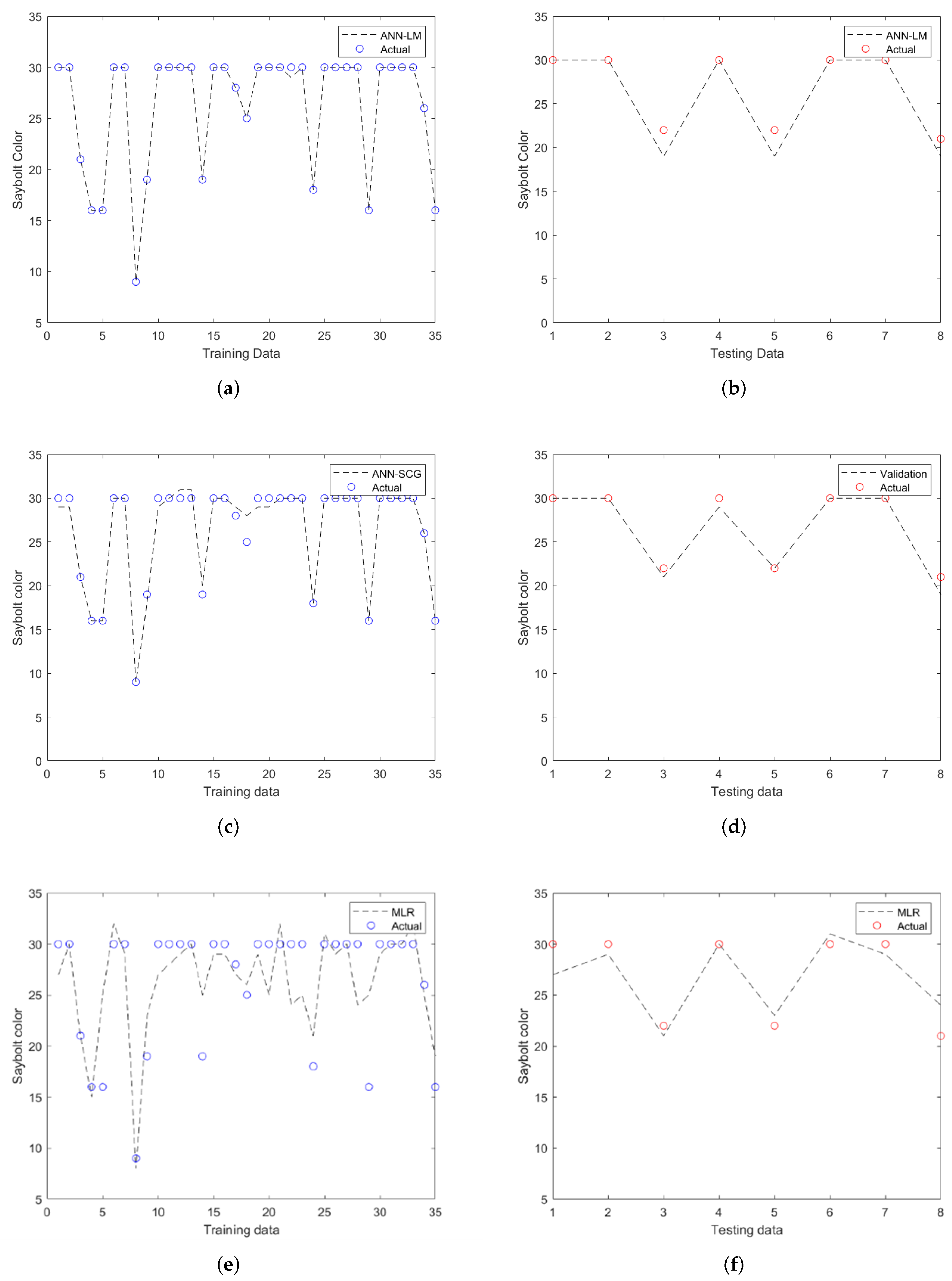
3.1. Performances of ANN Models
3.2. Performances of MLR Models
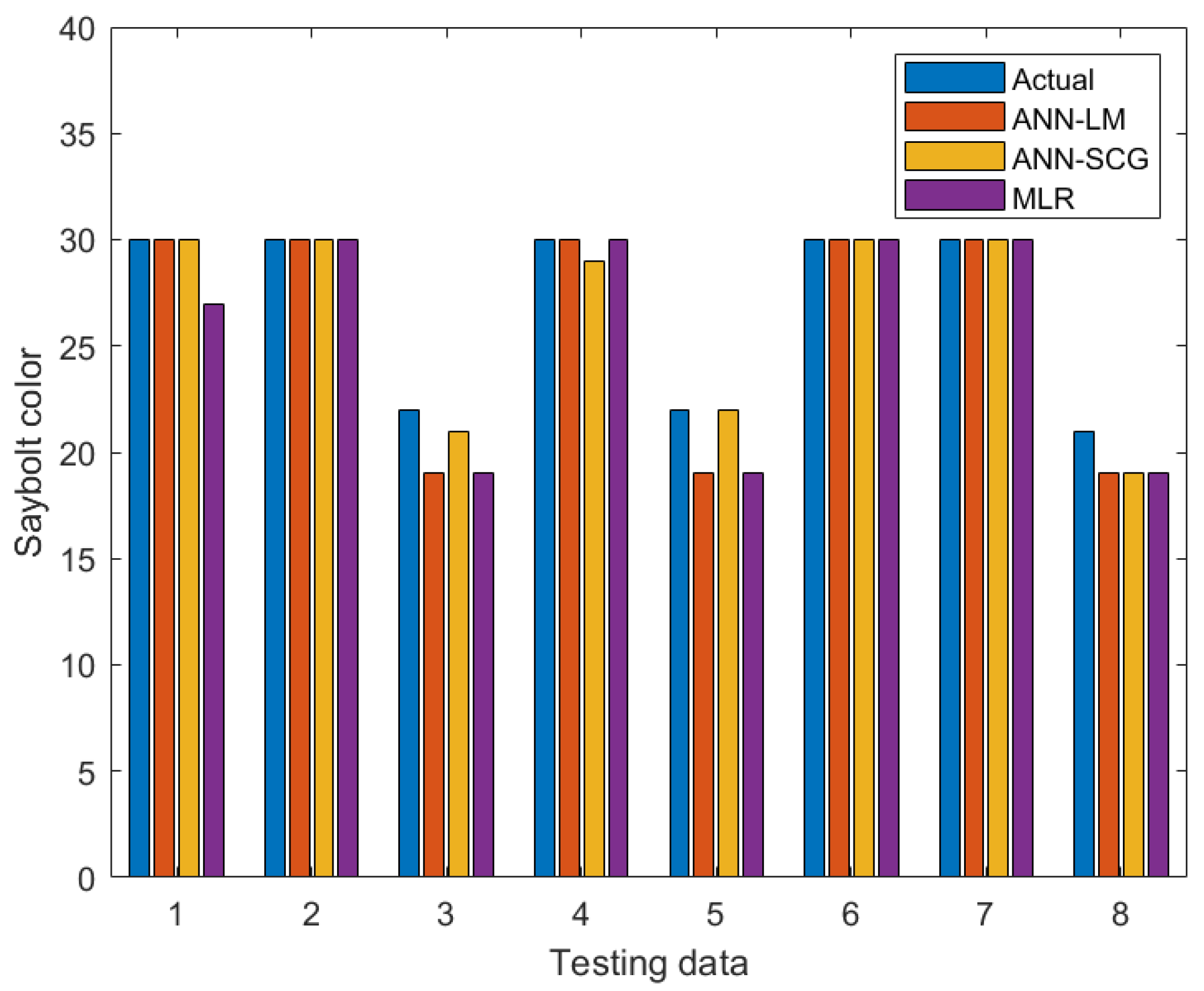
3.3. Comparison between ANN and MLR
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Montemayor, R. Petroleum Solvents; ASTM International: West Conshohocken, PA, USA, 2010. [Google Scholar]
- Yunardi, R.; Akbar, A.; Sukmayani, I.; A’yun, Q.; Apsari, R. Side-polished fiber sensor for measurement of the color concentration in lubricant products. J. Phys. Conf. Ser. Iop Publ. 2020, 1484, 012001. [Google Scholar] [CrossRef]
- Analytics, A.A. Measuring Saybolt Color in Natural Gas Liquids (NGLs). 2022. Available online: https://aai.solutions/documents/AA_AN045_Measuring-Saybolt-Color-in-Natural-Gas-Liquids.pdf (accessed on 1 March 2022).
- Story, B.; Kalichevsky, V. Photoelectric colorimeter for measuring color intensities of liquid petroleum products. Ind. Eng. Chem. Anal. Ed. 1933, 5, 214–217. [Google Scholar] [CrossRef]
- Hadi, M.H.H.; Ker, P.J.; Thiviyanathan, V.A.; Tang, S.G.H.; Leong, Y.S.; Lee, H.J.; Hannan, M.A.; Jamaludin, M.; Mahdi, M.A. The Amber-Colored Liquid: A Review on the Color Standards, Methods of Detection, Issues and Recommendations. Sensors 2021, 21, 6866. [Google Scholar] [CrossRef] [PubMed]
- ASTM D1500; Standard Test Method for ASTM Color of Petroleum Products (ASTM Color Scale). Annual Book of Standards. ASTM International: West Conshohocken, PA, USA, 2012.
- ASTM D156; Standard Test Method for Saybolt Color of Petroleum Products (Saybolt Chromometer Method). Annual Book of Standards. ASTM International: West Conshohocken, PA, USA, 2015.
- Diller, I.; DeGray, R.; Wilson, J., Jr. Photoelectric Color. Description and Mensuration of the Color of Petroleum Products. Ind. Eng. Chem. Anal. Ed. 1942, 14, 607–614. [Google Scholar] [CrossRef]
- Dittrich, P.G.; Grunert, F.; Ehehalt, J.; Hofmann, D. Mobile micro-colorimeter and micro-spectrometer sensor modules as enablers for the replacement of subjective inspections by objective measurements for optically clear colored liquids in-field. In Mobile Devices and Multimedia: Enabling Technologies, Algorithms, and Applications 2015; International Society for Optics and Photonics: Bellingham, WA, USA, 2015; Volume 9411, p. 941107. [Google Scholar]
- Sing, L.Y.; Ker, P.J.; Jamaludin, M.Z.; Ismail, A.; Abdullah, F.; Mun, L.H.; Shukri, C.N.S.M. Determining the color index of transformer insulating oil using UV-Vis spectroscopy. In Proceedings of the 2016 IEEE International Conference on Power and Energy (PECon), Melaka, Malaysia, 28–29 November 2016; pp. 234–238. [Google Scholar]
- Leong, Y.S.; Ker, P.J.; Jamaludin, M.Z.; M Nomanbhay, S.; Ismail, A.; Abdullah, F.; Looe, H.M.; Lo, C.K. UV-vis spectroscopy: A new approach for assessing the color index of transformer insulating oil. Sensors 2018, 18, 2175. [Google Scholar] [CrossRef] [Green Version]
- Hasnul Hadi, M.H.; Ker, P.J.; Lee, H.J.; Leong, Y.S.; Hannan, M.A.; Jamaludin, M.; Mahdi, M.A. Color Index of Transformer Oil: A Low-Cost Measurement Approach Using Ultraviolet-Blue Laser. Sensors 2021, 21, 7292. [Google Scholar] [CrossRef]
- Khor, C.S.; Nurazrin, N.N.S.; Hanafi, F.M.; Asallehan, F.N.; Rosman, N.Z.; Leam, J.J.; Dass, S.C.; Abidin, S.A.Z.; Anuar, F.S. Correlation model development for saybolt colour of condensates and light crude oils. ASM Sci. J. 2020, 13, 434. [Google Scholar]
- Leam, J.J.; Khor, C.S.; Dass, S.C. Saybolt color prediction for condensates and light crude oils. J. Pet. Explor. Prod. 2021, 11, 253–268. [Google Scholar] [CrossRef]
- Diller, I.; Dean, J.; DeGray, R.; Wilson, J., Jr. Color index. Light-colored petroleum products. Ind. Eng. Chem. Anal. Ed. 1943, 15, 365–373. [Google Scholar] [CrossRef]
- Ribeiro, F.C.; Oliveira, A.S.; Araujo, A.; Marinho, W.; Schneider, M.P.; Pinto, L.; Gomes, A.A. Detection oxidative degradation in lubricating oil under storage conditions using digital images and chemometrics. Microchem. J. 2019, 147, 622–627. [Google Scholar] [CrossRef]
- Kumar, U.A. Comparison of neural networks and regression analysis: A new insight. Expert Syst. Appl. 2005, 29, 424–430. [Google Scholar] [CrossRef]
- Abdel-Sattar, M.; Al-Obeed, R.S.; Aboukarima, A.M.; Eshra, D.H. Development of an artificial neural network as a tool for predicting the chemical attributes of fresh peach fruits. PLoS ONE 2021, 16, e0251185. [Google Scholar] [CrossRef] [PubMed]
- Elmabrouk, S.; Shirif, E.; Mayorga, R. Artificial neural network modeling for the prediction of oil production. Pet. Sci. Technol. 2014, 32, 1123–1130. [Google Scholar] [CrossRef]
- Elçiçek, H.; Akdoğan, E.; Karagöz, S. The use of artificial neural network for prediction of dissolution kinetics. Sci. World J. 2014, 2014, 194874. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malekian, A.; Chitsaz, N. Concepts, procedures, and applications of artificial neural network models in streamflow forecasting. In Advances in Streamflow Forecasting; Elsevier: Amsterdam, The Netherlands, 2021; pp. 115–147. [Google Scholar]
- Agwu, O.E.; Akpabio, J.U.; Dosunmu, A. Artificial neural network model for predicting the density of oil-based muds in high-temperature, high-pressure wells. J. Pet. Explor. Prod. Technol. 2020, 10, 1081–1095. [Google Scholar] [CrossRef] [Green Version]
- Spesivtsev, P.; Sinkov, K.; Sofronov, I.; Zimina, A.; Umnov, A.; Yarullin, R.; Vetrov, D. Predictive model for bottomhole pressure based on machine learning. J. Pet. Sci. Eng. 2018, 166, 825–841. [Google Scholar] [CrossRef]
- Cheshmeh Sefidi, A.; Ajorkaran, F. A novel MLP-ANN approach to predict solution gas-oil ratio. Pet. Sci. Technol. 2019, 37, 2302–2308. [Google Scholar] [CrossRef]
- Adewole, B.Z.; Abidakun, O.A.; Asere, A.A. Artificial neural network prediction of exhaust emissions and flame temperature in LPG (liquefied petroleum gas) fueled low swirl burner. Energy 2013, 61, 606–611. [Google Scholar] [CrossRef]
- MATLAB, version R2021a; The MathWorks Inc.: Natick, MA, USA, 2021.
- Al Shamisi, M.H.; Assi, A.H.; Hejase, H.A. Using MATLAB to Develop Artificial Neural Network Models for Predicting Global Solar Radiation in Al Ain City–UAE; Citeseer: Prince, NJ, USA, 2011. [Google Scholar]
- Ouma, Y.O.; Okuku, C.O.; Njau, E.N. Use of artificial neural networks and multiple linear regression model for the prediction of dissolved oxygen in rivers: Case study of hydrographic basin of River Nyando, Kenya. Complexity 2020, 2020, 9570789. [Google Scholar] [CrossRef]
- Sahoo, S.; Jha, M.K. Groundwater-level prediction using multiple linear regression and artificial neural network techniques: A comparative assessment. Hydrogeol. J. 2013, 21, 1865–1887. [Google Scholar] [CrossRef]
- Tiryaki, S.; Aydın, A. An artificial neural network model for predicting compression strength of heat treated woods and comparison with a multiple linear regression model. Constr. Build. Mater. 2014, 62, 102–108. [Google Scholar] [CrossRef]
- Sadiq, R.; Rodriguez, M.J. Disinfection by-products (DBPs) in drinking water and predictive models for their occurrence: A review. Sci. Total Environ. 2004, 321, 21–46. [Google Scholar] [CrossRef] [PubMed]
- Akkol, S.; Akilli, A.; Cemal, I. Comparison of artificial neural network and multiple linear regression for prediction of live weight in hair goats. Yyu J. Agric. Sci. 2017, 27, 21–29. [Google Scholar]
- Maulud, D.; Abdulazeez, A.M. A review on linear regression comprehensive in machine learning. J. Appl. Sci. Technol. Trends 2020, 1, 140–147. [Google Scholar] [CrossRef]
- Lin, C.J.; Su, X.Y.; Hu, C.H.; Jian, B.L.; Wu, L.W.; Yau, H.T. A linear regression thermal displacement lathe spindle model. Energies 2020, 13, 949. [Google Scholar] [CrossRef] [Green Version]
- Upkli, W.R.; Ab Rahman, A.; Razak, I.A.W.A.; Bohari, Z.H.; Azmi, A.N. Output Power Forecasting for 2kW Monocrystalline PV System using Response Surface Methodology. Int. J. Electr. Eng. Appl. Sci. (IJEEAS) 2019, 2, 23–32. [Google Scholar]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation between Training and Testing Sets: A Pedagogical Explanation; ScholarWorks: Allendale Charter Twp, MI, USA, 2018. [Google Scholar]
- Rodríguez-Abreo, O.; Castillo Velásquez, F.A.; Zavala de Paz, J.P.; Martínez Godoy, J.L.; Garcia Guendulain, C. Sensorless Estimation Based on Neural Networks Trained with the Dynamic Response Points. Sensors 2021, 21, 6719. [Google Scholar] [CrossRef]
- Shaik, N.B.; Pedapati, S.R.; Othman, A.; Bingi, K.; Dzubir, F.A.A. An intelligent model to predict the life condition of crude oil pipelines using artificial neural networks. Neural Comput. Appl. 2021, 33, 14771–14792. [Google Scholar] [CrossRef]
- Bingi, K.; Prusty, B.R. Forecasting Models for Chaotic Fractional–Order Oscillators Using Neural Networks. Int. J. Appl. Math. Comput. Sci. 2021, 31, 387–398. [Google Scholar]
- Tiryaki, S.; Özşahin, Ş.; Yıldırım, İ. Comparison of artificial neural network and multiple linear regression models to predict optimum bonding strength of heat treated woods. Int. J. Adhes. Adhes. 2014, 55, 29–36. [Google Scholar] [CrossRef]
- Jierula, A.; Wang, S.; Oh, T.M.; Wang, P. Study on accuracy metrics for evaluating the predictions of damage locations in deep piles using artificial neural networks with acoustic emission data. Appl. Sci. 2021, 11, 2314. [Google Scholar] [CrossRef]
- Bingi, K.; Prusty, B.R.; Kumra, A.; Chawla, A. Torque and temperature prediction for permanent magnet synchronous motor using neural networks. In Proceedings of the 2020 3rd International Conference on Energy, Power and Environment: Towards Clean Energy Technologies, Shillong, India, 5–7 March 2021; pp. 1–6. [Google Scholar]
- Daoud, J.I. Multicollinearity and regression analysis. J. Phys. Conf. Ser. Iop Publ. 2017, 949, 012009. [Google Scholar] [CrossRef]
- Sheela, K.G.; Deepa, S.N. Review on methods to fix number of hidden neurons in neural networks. Math. Probl. Eng. 2013, 2013, 425740. [Google Scholar] [CrossRef] [Green Version]
- Duch, W.; Jankowski, N. Transfer Functions: Hidden Possibilities for Better Neural Networks; ESANN; Citeseer: Prince, NJ, USA, 2001; pp. 81–94. [Google Scholar]
- Sarkar, R.; Julai, S.; Hossain, S.; Chong, W.T.; Rahman, M. A comparative study of activation functions of NAR and NARX neural network for long-term wind speed forecasting in Malaysia. Math. Probl. Eng. 2019, 2019, 6403081. [Google Scholar] [CrossRef]
- Dorofki, M.; Elshafie, A.H.; Jaafar, O.; Karim, O.A.; Mastura, S. Comparison of artificial neural network transfer functions abilities to simulate extreme runoff data. Int. Proc. Chem. Biol. Environ. Eng. 2012, 33, 39–44. [Google Scholar]
- Saeed, U.; Ahmad, S.; Alsadi, J.; Ross, D.; Rizvi, G. Implementation of neural network for color properties of polycarbonates. In Proceedings of the AIP Conference Proceedings; American Institute of Physics: University Park, MD, USA, 2014; Volume 1593, pp. 56–59. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Name | Inputs |
|---|---|---|
| 1 | DVSCA | Density (kg/m3) Kinematic viscosity at −20 °C (cST) Sulfur content (ppm wt) Cetane index Total acid number (mgKOH/g) |
| 2 | DVSC | Density (kg/m3) Kinematic viscosity at −20 °C (cST) Sulfur content (ppm wt) Cetane index |
| 3 | DVSA | Density (kg/m3) Kinematic viscosity at −20 °C (cST) Sulfur content (ppm wt) Total acid number (mgKOH/g) |
| 4 | DSCA | Density (kg/m3) Sulfur content (ppm wt) Cetane index Total acid number (mgKOH/g) |
| 5 | DVCA | Density (kg/m3) Kinematic viscosity at −20 °C (cST) Cetane index Total acid number (mgKOH/g) |
| 6 | VSCA | Kinematic viscosity at −20 °C (cST) Sulfur content (ppm wt) Cetane index Total acid number (mgKOH/g) |
| Number of Neurons | 2 | 3 | ||||||
|---|---|---|---|---|---|---|---|---|
| Training Function | Model | Transfer Function | MAE | RMSE | R2 | MAE | RMSE | R2 |
| Levenberg–Marquardt | 1 | tansig | 0.750 | 1.500 | 0.867 | 1.750 | 2.693 | 0.993 |
| 2 | 2.625 | 5.601 | 0.786 | 1.750 | 3.082 | 0.957 | ||
| 3 | 1.750 | 2.236 | 0.759 | 1.250 | 2.000 | 0.825 | ||
| 4 | 2.125 | 3.446 | 0.557 | 1.000 | 1.803 | 0.975 | ||
| 5 | 1.875 | 2.716 | 0.597 | 2.625 | 3.021 | 0.612 | ||
| 6 | 1.500 | 2.500 | 0.766 | 1.250 | 1.658 | 0.833 | ||
| 1 | logsig | 1.750 | 3.082 | 0.957 | 1.000 | 1.658 | 0.995 | |
| 2 | 2.750 | 3.279 | 0.732 | 2.750 | 3.082 | 0.760 | ||
| 3 | 1.750 | 2.236 | 0.759 | 1.875 | 3.182 | 0.974 | ||
| 4 | 1.375 | 3.221 | 0.484 | 1.250 | 2.550 | 0.634 | ||
| 5 | 2.125 | 3.062 | 0.572 | 26.875 | 45.622 | 0.851 | ||
| 6 | 1.500 | 2.500 | 0.766 | 1.250 | 1.658 | 0.833 | ||
| 1 | radbas | 1.625 | 2.208 | 0.727 | 1.250 | 1.658 | 0.886 | |
| 2 | 1.500 | 1.732 | 0.838 | 1.625 | 2.372 | 0.812 | ||
| 3 | 1.750 | 2.345 | 0.758 | 1.500 | 2.000 | 0.779 | ||
| 4 | 1.875 | 2.622 | 0.753 | 1.500 | 2.345 | 0.725 | ||
| 5 | 1.750 | 2.179 | 0.780 | 1.750 | 2.449 | 0.695 | ||
| 6 | 2.000 | 2.121 | 0.732 | 3.375 | 4.430 | 0.755 | ||
| Scaled Conjugate Gradient | 1 | tansig | 0.750 | 1.500 | 0.867 | 0.500 | 0.866 | 0.984 |
| 2 | 2.125 | 3.221 | 0.615 | 4.375 | 7.706 | 0.875 | ||
| 3 | 1.750 | 2.449 | 0.650 | 1.125 | 2.031 | 0.917 | ||
| 4 | 0.750 | 2.121 | 0.760 | 2.000 | 2.828 | 0.795 | ||
| 5 | 2.250 | 3.606 | 0.462 | 2.375 | 3.824 | 0.559 | ||
| 6 | 1.750 | 2.550 | 0.618 | 1.500 | 2.121 | 0.843 | ||
| 1 | logsig | 1.250 | 1.803 | 0.842 | 1.000 | 1.500 | 0.927 | |
| 2 | 2.125 | 3.062 | 0.712 | 1.750 | 2.500 | 0.786 | ||
| 3 | 1.750 | 2.236 | 0.759 | 1.125 | 2.031 | 0.917 | ||
| 4 | 0.750 | 2.121 | 0.760 | 1.375 | 2.716 | 0.627 | ||
| 5 | 2.875 | 3.657 | 0.501 | 2.500 | 3.969 | 0.633 | ||
| 6 | 1.500 | 2.500 | 0.766 | 1.500 | 2.121 | 0.843 | ||
| 1 | radbas | 1.875 | 2.622 | 0.753 | 1.125 | 1.275 | 0.904 | |
| 2 | 1.500 | 1.802 | 0.817 | 1.625 | 2.031 | 0.791 | ||
| 3 | 1.750 | 2.236 | 0.759 | 1.875 | 3.182 | 0.899 | ||
| 4 | 1.875 | 2.622 | 0.753 | 1.750 | 3.122 | 0.626 | ||
| 5 | 1.750 | 2.121 | 0.803 | 1.750 | 2.550 | 0.673 | ||
| 6 | 1.750 | 2.345 | 0.817 | 1.750 | 2.291 | 0.762 | ||
| Model | Type | MAE | RMSE | R2 |
|---|---|---|---|---|
| 1 | Linear | 2.375 | 3.142 | 0.564 |
| 2 | 2.500 | 3.240 | 0.573 | |
| 3 | 2.375 | 3.142 | 0.518 | |
| 4 | 2.000 | 2.550 | 0.616 | |
| 5 | 2.250 | 3.041 | 0.572 | |
| 6 | 3.750 | 4.000 | 0.024 | |
| 1 | Interaction | 2.750 | 4.062 | 0.279 |
| 2 | 2.000 | 2.646 | 0.588 | |
| 3 | 2.125 | 2.669 | 0.666 | |
| 4 | 2.000 | 2.915 | 0.536 | |
| 5 | 3.000 | 4.387 | 0.108 | |
| 6 | 2.125 | 2.574 | 0.604 | |
| 1 | Pure quadratic | 2.000 | 2.236 | 0.699 |
| 2 | 1.375 | 1.696 | 0.830 | |
| 3 | 2.250 | 2.449 | 0.651 | |
| 4 | 1.625 | 2.150 | 0.721 | |
| 5 | 2.250 | 2.598 | 0.592 | |
| 6 | 3.250 | 3.571 | 0.318 | |
| 1 | Quadratic | 2.125 | 2.622 | 0.696 |
| 2 | 2.000 | 2.550 | 0.607 | |
| 3 | 1.500 | 2.000 | 0.757 | |
| 4 | 1.625 | 2.092 | 0.745 | |
| 5 | 2.500 | 3.969 | 0.254 | |
| 6 | 1.750 | 2.121 | 0.729 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salehuddin, N.F.; Omar, M.B.; Ibrahim, R.; Bingi, K. A Neural Network-Based Model for Predicting Saybolt Color of Petroleum Products. Sensors 2022, 22, 2796. https://doi.org/10.3390/s22072796
Salehuddin NF, Omar MB, Ibrahim R, Bingi K. A Neural Network-Based Model for Predicting Saybolt Color of Petroleum Products. Sensors. 2022; 22(7):2796. https://doi.org/10.3390/s22072796
Chicago/Turabian StyleSalehuddin, Nurliana Farhana, Madiah Binti Omar, Rosdiazli Ibrahim, and Kishore Bingi. 2022. "A Neural Network-Based Model for Predicting Saybolt Color of Petroleum Products" Sensors 22, no. 7: 2796. https://doi.org/10.3390/s22072796