
Dual-Cameras-Based Driver’s Eye Gaze Tracking System with Non-Linear Gaze Point Refinement

Abstract
:1. Introduction
- A dual-cameras-based driver eye gaze tracking system using non-linear gaze point refinement is presented for deploying a pre-trained supervised gaze model in the unconstrained environment. This method makes an initial attempt to reduce the estimation bias in separate model training. It increases the flexibility of system setup and does not require any human intervention.
- An effective gaze point non-linear global refinement with two-stage clustering is presented to extract the typical gaze points by maximizing fixation possibilities. This method aligns the initial unknown gaze points to specific calibration points by topology preservation. It is person-independent and can be directly utilized as post-processing for many pre-trained gaze models.
- Experimental results of real driving scenarios demonstrate that the proposed method reduces the gaze estimation error of the pre-trained model and even has a better performance on cross-subject evaluations. It can be used as a simple-but-effective baseline method for driver gaze calibration or gaze mapping.
2. Related Works
2.1. Driver’s Eye Gaze Estimation
2.1.1. Feature-Based Systems and Appearance-Based Systems
2.1.2. Deep Learning-Based Systems
2.2. Driver’s Eye Gaze Calibration
3. Proposed Method
3.1. Driver Status Tracking
3.1.1. Process Model
3.1.2. Head Model
3.1.3. Eye Model
3.1.4. Measurement Model
3.2. Pre-Trained Gaze Model
3.3. Non-Linear Gaze Point Refinement
3.3.1. Two-Stage Gaze Point Clustering
3.3.2. Gaze Points Clustering
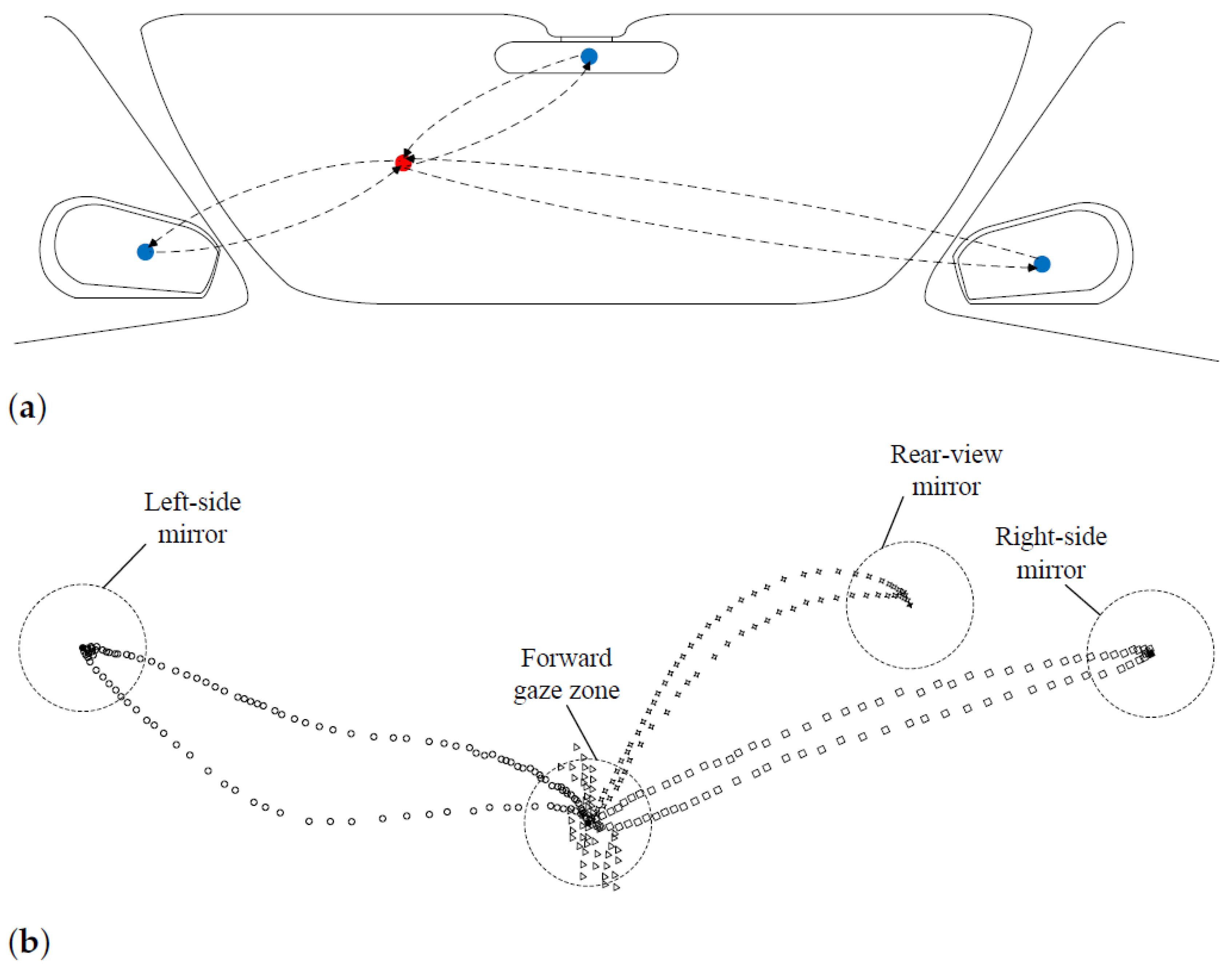
3.3.3. Mirror Gaze Points Clustering
3.3.4. Typical Topology Preservation
3.3.5. Non-Linear Global Refinement
4. Experiments and Discussions
4.1. Naturalistic Data Collection
4.2. Pre-Trained Models and Baseline Methods
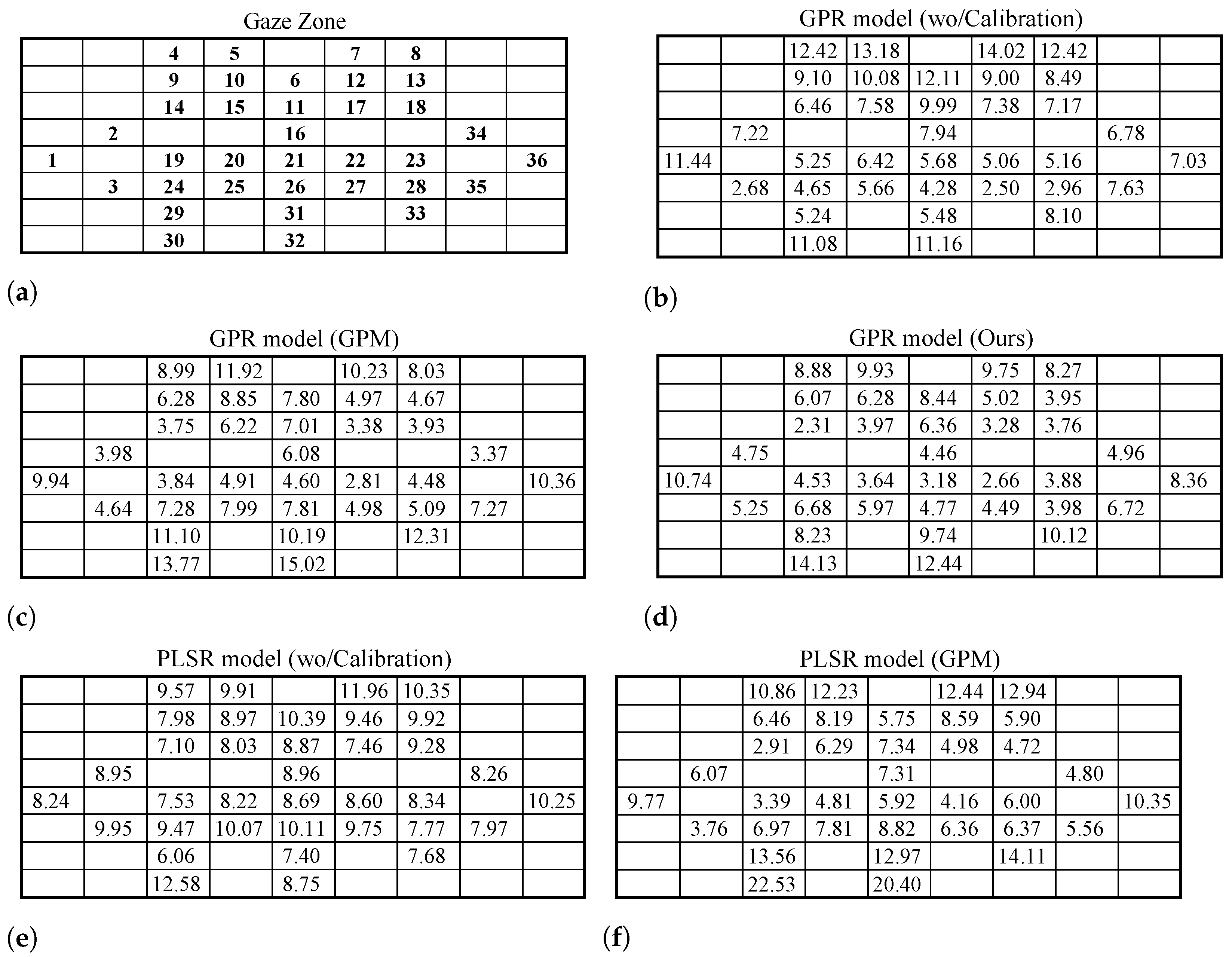
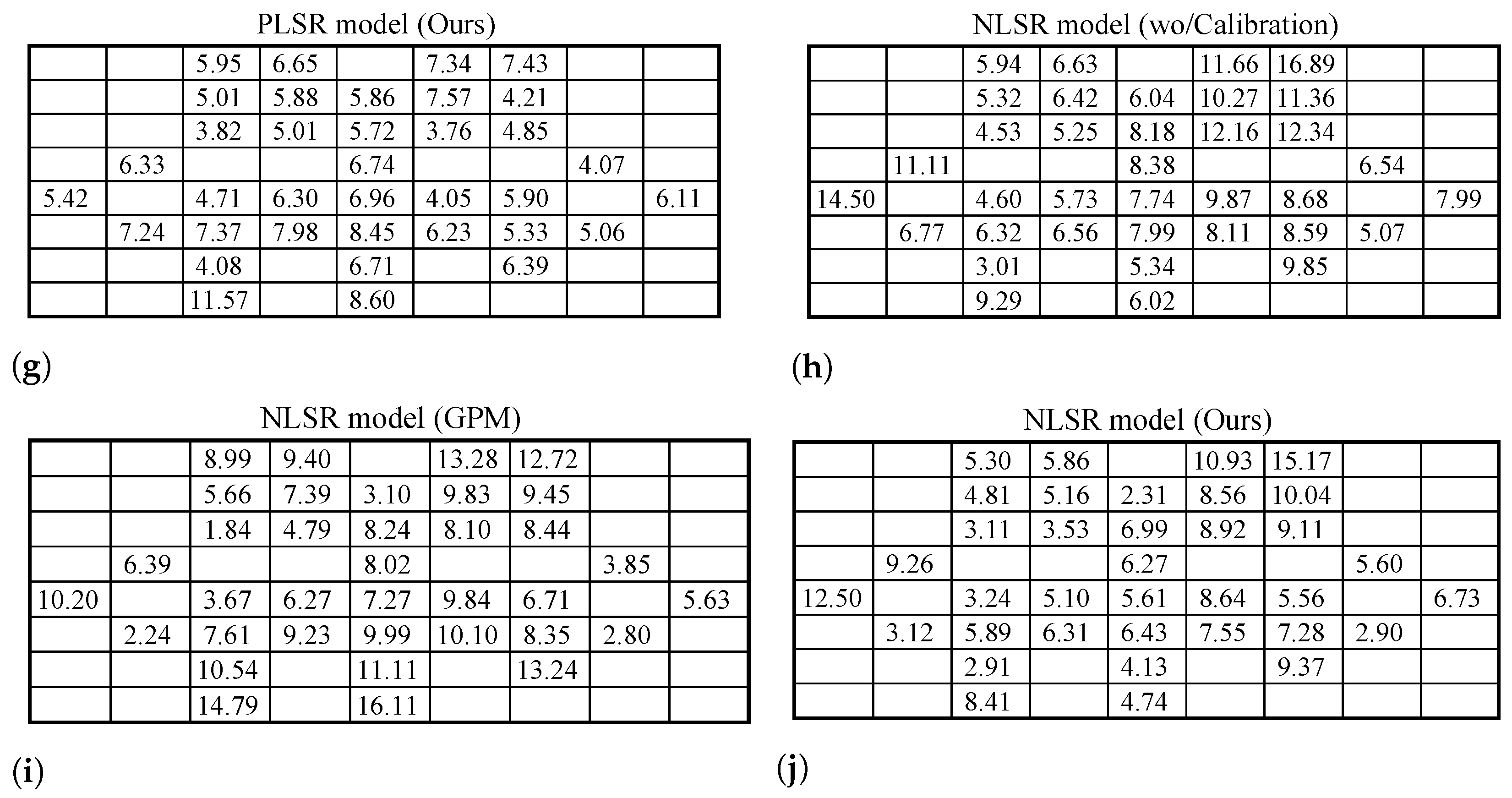
4.3. Gaze Point Prediction Results
4.4. Ablation Study and Error Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, Y.; Hu, Z.; Uchimura, K.; Murayama, N. Driver inattention monitoring system for intelligent vehicles: A review. IEEE Trans. Intell. Transp. Syst. 2010, 12, 596–614. [Google Scholar] [CrossRef]
- Kaplan, S.; Guvensan, M.A.; Yavuz, A.G.; Karalurt, Y. Driver behavior analysis for safe driving: A survey. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3017–3032. [Google Scholar] [CrossRef]
- Sikander, G.; Anwar, S. Driver fatigue detection systems: A review. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2339–2352. [Google Scholar] [CrossRef]
- Khan, M.Q.; Lee, S. Gaze and eye tracking: Techniques and applications in ADAS. Sensors 2019, 19, 5540. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, L.; Dong, K.; Dmitruk, A.J.; Brighton, J.; Zhao, Y. A dual-cameras-based driver gaze mapping system with an application on non-driving activities monitoring. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4318–4327. [Google Scholar] [CrossRef] [Green Version]
- Dua, I.; John, T.A.; Gupta, R.; Jawahar, C. DGAZE: Driver Gaze Mapping on Road. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2020; pp. 5946–5953. [Google Scholar]
- Fu, X.; Guan, X.; Peli, E.; Liu, H.; Luo, G. Automatic calibration method for driver’s head orientation in natural driving environment. IEEE Trans. Intell. Transp. Syst. 2012, 14, 303–312. [Google Scholar] [CrossRef]
- Yamashiro, K.; Deguchi, D.; Takahashi, T.; Ide, I.; Murase, H.; Higuchi, K.; Naito, T. Automatic calibration of an in-vehicle gaze tracking system using driver’s typical gaze behavior. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium (IV), Xi’an, China, 3–5 June 2009; pp. 998–1003. [Google Scholar]
- Yuan, G.; Wang, Y.; Yan, H.; Fu, X. Self-calibrated driver gaze estimation via gaze pattern learning. Knowl.-Based Syst. 2022, 235, 107630. [Google Scholar] [CrossRef]
- Wang, J.; Chai, W.; Venkatachalapathy, A.; Tan, K.L.; Haghighat, A.; Velipasalar, S.; Adu-Gyamfi, Y.; Sharma, A. A Survey on Driver Behavior Analysis from In-Vehicle Cameras. IEEE Trans. Intell. Transp. Syst. 2021, 1–24. [Google Scholar] [CrossRef]
- Shehu, I.S.; Wang, Y.; Athuman, A.M.; Fu, X. Remote Eye Gaze Tracking Research: A Comparative Evaluation on Past and Recent Progress. Electronics 2021, 10, 3165. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, T.; Ding, X.; Bian, J.; Fu, X. Head pose-free eye gaze prediction for driver attention study. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 42–46. [Google Scholar]
- Wang, Y.; Shen, T.; Yuan, G.; Bian, J.; Fu, X. Appearance-based gaze estimation using deep features and random forest regression. Knowl.-Based Syst. 2016, 110, 293–301. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, T.; Ding, X.; Peng, J.; Bian, J.; Fu, X. Learning a gaze estimator with neighbor selection from large-scale synthetic eye images. Knowl.-Based Syst. 2018, 139, 41–49. [Google Scholar] [CrossRef]
- Tawari, A.; Trivedi, M.M. Robust and continuous estimation of driver gaze zone by dynamic analysis of multiple face videos. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium (IV), Dearborn, MI, USA, 8–11 June 2014; pp. 344–349. [Google Scholar]
- Jha, S.; Busso, C. Analyzing the relationship between head pose and gaze to model driver visual attention. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2157–2162. [Google Scholar]
- Tawari, A.; Martin, S.; Trivedi, M.M. Continuous head movement estimator for driver assistance: Issues, algorithms, and on-road evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 818–830. [Google Scholar] [CrossRef] [Green Version]
- Jha, S.; Busso, C. Probabilistic estimation of the driver’s gaze from head orientation and position. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Tawari, A.; Chen, K.H.; Trivedi, M.M. Where is the driver looking: Analysis of head, eye and iris for robust gaze zone estimation. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 988–994. [Google Scholar]
- Vicente, F.; Huang, Z.; Xiong, X.; De la Torre, F.; Zhang, W.; Levi, D. Driver gaze tracking and eyes off the road detection system. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2014–2027. [Google Scholar] [CrossRef]
- Wang, Y.; Yuan, G.; Mi, Z.; Peng, J.; Ding, X.; Liang, Z.; Fu, X. Continuous driver’s gaze zone estimation using rgb-d camera. Sensors 2019, 19, 1287. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jha, S.; Busso, C. Estimation of Driver’s Gaze Region from Head Position and Orientation Using Probabilistic Confidence Regions. arXiv 2020, arXiv:2012.12754. [Google Scholar] [CrossRef]
- Lundgren, M.; Hammarstrand, L.; McKelvey, T. Driver-gaze zone estimation using Bayesian filtering and Gaussian processes. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2739–2750. [Google Scholar] [CrossRef]
- Yu, Z.; Huang, X.; Zhang, X.; Shen, H.; Li, Q.; Deng, W.; Tang, J.; Yang, Y.; Ye, J. A Multi-Modal Approach for Driver Gaze Prediction to Remove Identity Bias. In Proceedings of the 2020 International Conference on Multimodal Interaction, Online, 25–29 October 2020; pp. 768–776. [Google Scholar]
- Lyu, K.; Wang, M.; Meng, L. Extract the Gaze Multi-dimensional Information Analysis Driver Behavior. In Proceedings of the 2020 International Conference on Multimodal Interaction, Virtual Event, The Netherlands, 25–29 October 2020; pp. 790–797. [Google Scholar]
- Lollett, C.; Kamezaki, M.; Sugano, S. Towards a Driver’s Gaze Zone Classifier using a Single Camera Robust to Temporal and Permanent Face Occlusions. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 578–585. [Google Scholar]
- Yoon, H.S.; Hong, H.G.; Lee, D.E.; Park, K.R. Driver’s eye-based gaze tracking system by one-point calibration. Multimed. Tools Appl. 2019, 78, 7155–7179. [Google Scholar] [CrossRef]
- Li, N.; Busso, C. Detecting drivers’ mirror-checking actions and its application to maneuver and secondary task recognition. IEEE Trans. Intell. Transp. Syst. 2015, 17, 980–992. [Google Scholar] [CrossRef]
- Xing, Y.; Tang, J.; Liu, H.; Lv, C.; Cao, D.; Velenis, E.; Wang, F.Y. End-to-end driving activities and secondary tasks recognition using deep convolutional neural network and transfer learning. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1626–1631. [Google Scholar]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.Y. Driver activity recognition for intelligent vehicles: A deep learning approach. IEEE Trans. Veh. Technol. 2019, 68, 5379–5390. [Google Scholar] [CrossRef] [Green Version]
- Shahverdy, M.; Fathy, M.; Berangi, R.; Sabokrou, M. Driver behavior detection and classification using deep convolutional neural networks. Expert Syst. Appl. 2020, 149, 113240. [Google Scholar] [CrossRef]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. Openface 2.0: Facial behavior analysis toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG), Xi’an, China, 15–19 May 2018; pp. 59–66. [Google Scholar]
- Jha, S.; Busso, C. Challenges in head pose estimation of drivers in naturalistic recordings using existing tools. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Araluce, J.; Bergasa, L.M.; Ocaña, M.; López-Guillén, E.; Revenga, P.A.; Arango, J.F.; Pérez, O. Gaze Focalization System for Driving Applications Using OpenFace 2.0 Toolkit with NARMAX Algorithm in Accidental Scenarios. Sensors 2021, 21, 6262. [Google Scholar] [CrossRef]
- Shirpour, M.; Beauchemin, S.S.; Bauer, M.A. A probabilistic model for visual driver gaze approximation from head pose estimation. In Proceedings of the 2020 IEEE 3rd Connected and Automated Vehicles Symposium (CAVS), Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–6. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Calibration Method | GPR Model | PLSR Model | NLSR Model | Average |
|---|---|---|---|---|
| wo/Calibration | 7.74 | 8.97 | 8.09 | 8.27 |
| GPM | 7.16 | 8.37 | 8.20 | 7.91 |
| HTP | 17.98 | 17.63 | 16.99 | 14.45 |
| Ours | 6.39 | 6.13 | 6.59 | 6.37 |
| Calibration Method | GPR Model | PLSR Model | NLSR Model | Average |
|---|---|---|---|---|
| wo/Front | 8.71 | 6.26 | 6.78 | 7.25 |
| wo/Left | 6.70 | 5.96 | 6.62 | 6.42 |
| wo/Middle | 7.00 | 6.50 | 6.80 | 6.77 |
| wo/Right | 11.09 | 9.22 | 7.21 | 9.17 |
| Ours | 6.39 | 6.13 | 6.59 | 6.37 |
| Calibration Method | GPR Model | PLSR Model | NLSR Model | Average |
|---|---|---|---|---|
| wo/Calibration | 6.99 | 5.26 | 5.67 | 5.97 |
| GPM | 6.77 | 8.13 | 7.30 | 7.40 |
| HTP | 7.49 | 10.79 | 5.67 | 7.98 |
| Ours | 6.19 | 5.04 | 5.67 | 5.63 |
| Calibration Method | GPR Model | PLSR Model | NLSR Model | Average |
|---|---|---|---|---|
| wo/Calibration | 7.93 | 9.90 | 8.69 | 8.84 |
| GPM | 7.26 | 8.43 | 8.45 | 8.05 |
| HTP | 20.78 | 19.34 | 19.81 | 19.98 |
| Ours | 6.44 | 6.40 | 6.82 | 6.55 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Ding, X.; Yuan, G.; Fu, X. Dual-Cameras-Based Driver’s Eye Gaze Tracking System with Non-Linear Gaze Point Refinement. Sensors 2022, 22, 2326. https://doi.org/10.3390/s22062326
Wang Y, Ding X, Yuan G, Fu X. Dual-Cameras-Based Driver’s Eye Gaze Tracking System with Non-Linear Gaze Point Refinement. Sensors. 2022; 22(6):2326. https://doi.org/10.3390/s22062326
Chicago/Turabian StyleWang, Yafei, Xueyan Ding, Guoliang Yuan, and Xianping Fu. 2022. "Dual-Cameras-Based Driver’s Eye Gaze Tracking System with Non-Linear Gaze Point Refinement" Sensors 22, no. 6: 2326. https://doi.org/10.3390/s22062326