
Reinforcement Learning-Based Adaptive Streaming Scheme with Edge Computing Assistance


Abstract
:1. Introduction
- We present a reinforcement learning-based mobile edge framework for multi-client adaptive streaming. The mobile edge collects the information of clients and feeds them as inputs into a neural network model to determine the bitrate of video segments to be requested.
- We formulate the multi-client QoE fairness problem as a Markov Decision Process (MDP) to define the optimization objectives of the neural network model. The multi-client QoE fairness problem considers both the improvement of the QoE of clients and the achievement of the fair QoE.
- We trained the neural network model with a state-of-the-art reinforcement learning algorithm to generate the optimal policy for multi-client adaptive streaming. In training, network datasets with various conditions were used for generalizing the neural network model.
- We compared the proposed scheme with the existing schemes through simulation-based experiments. The experimental results show that the proposed scheme achieves better performance than the existing schemes in terms of the overall QoE of clients and the QoE fairness among clients.
2. Related Work
2.1. DASH-Based Bitrate Adaptation
2.2. Challenges for Bitrate Adaptation in Multi-Client Adaptive Streaming
2.3. Reinforcement Learning-Based Adaptive Streaming
3. Framework Design
3.1. State
3.2. Action
3.3. Reward
3.4. Neural Network Model
3.5. Multi-Agent Training Methodology
4. Performance Evaluation
4.1. Implementation
4.2. Experimental Setup
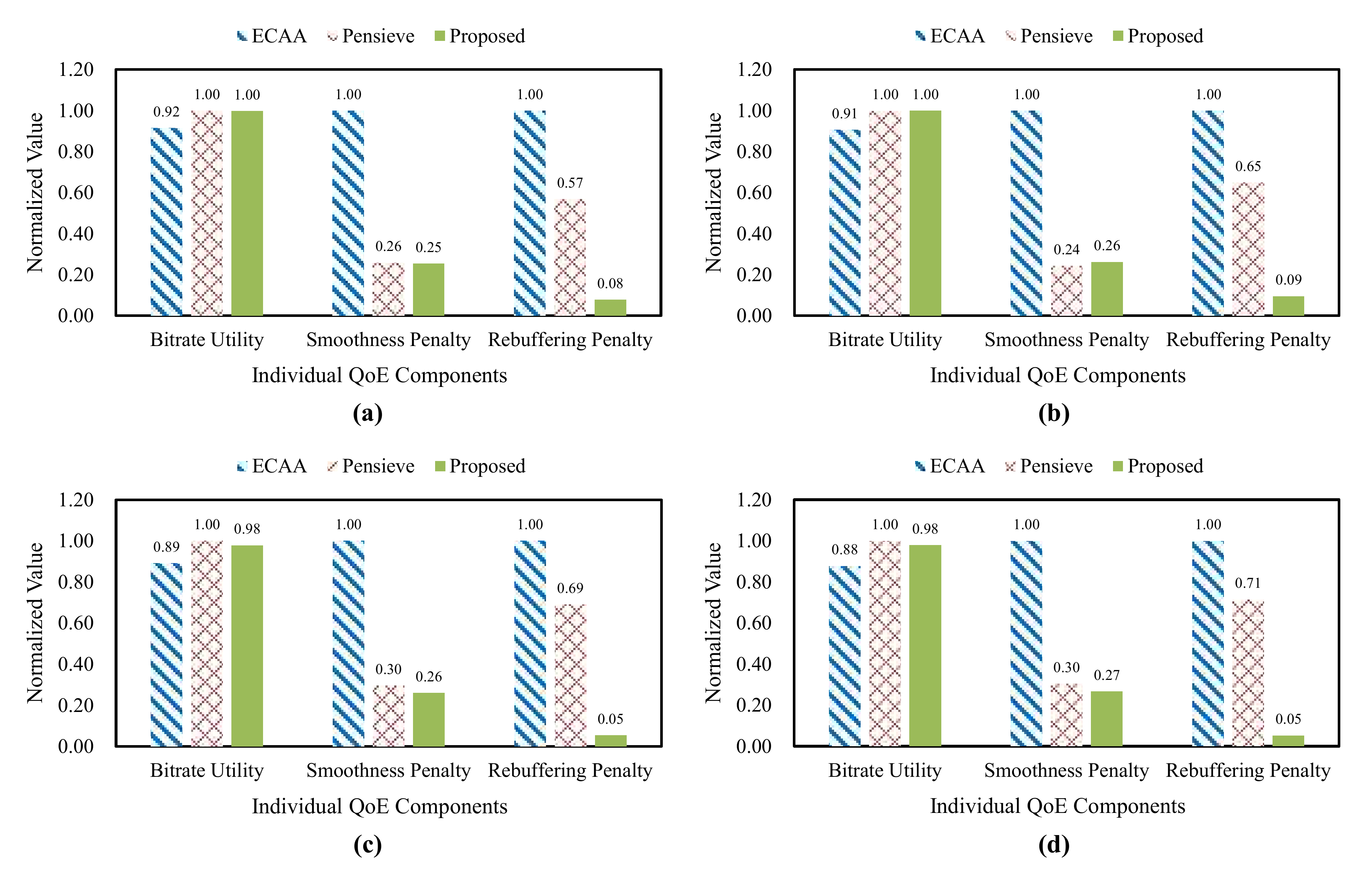
4.3. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cisco Public. Cisco Annual Internet Report (2018–2023) White Paper. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 1 July 2021).
- Kua, J.; Armitage, G.; Branch, P. A Survey of Rate Adaptation Techniques for Dynamic Adaptive Streaming over HTTP. IEEE Commun. Surv. Tutor. 2017, 19, 1842–1866. [Google Scholar] [CrossRef]
- Vega, M.T.; Perra, C.; Turck, F.D.; Liotta, A. A Review of Predictive Quality of Experience Management in Video Streaming Service. IEEE Trans. Broadcast. 2018, 64, 432–445. [Google Scholar] [CrossRef] [Green Version]
- Barakabitze, A.A.; Barman, N.; Ahmad, A.; Zadtootaghaj, S.; Sun, L.; Martini, M.G.; Atzori, L. QoE Management of Multimedia Streaming Services in Future Networks: A Tutorial and Survey. IEEE Commun. Surv. Tutor. 2020, 22, 526–565. [Google Scholar] [CrossRef] [Green Version]
- Petrangeli, S.; Hooft, J.V.D.; Wauters, T.; Turck, F.D. Quality of Experience-Centric Management of Adaptive Video Streaming Services: Status and Challenges. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Bouazizi, I.; Gabboi, M. Rate Adaptation for Adaptive HTTP Streaming. In Proceedings of the Second Annual ACM Conference on Multimedia Systems, San Jose, CA, USA, 23–25 February 2011; pp. 169–174. [Google Scholar]
- Huang, T.-Y.; Johari, R.; McKeown, N.; Trunnell, M.; Watson, M. A Buffer-Based Approach to Rate Adaptation: Evidence from A Large Video Streaming Service. In Proceedings of the 2014 ACM Conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 187–198. [Google Scholar]
- Li, Z.; Zhu, X.; Gahm, J.; Pan, R.; Hu, H.; Begen, A.C.; Oran, D. Probe and Adapt: Rate Adaptation for HTTP Video Streaming at Scale. IEEE J. Sel. Areas Commun. 2014, 32, 719–733. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Sekar, V.; Zhang, H. Improving Fairness, Efficiency, and Stability in HTTP-Based Adaptive Video Streaming with FESTIVE. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies, New York, NY, USA, 10–13 December 2012; pp. 97–108. [Google Scholar]
- Yin, X.; Jindal, A.; Sekar, V.; Sinopoli, B. A Control-Theoretic Approach for Dynamic Adaptive Video Streaming over HTTP. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, New York, NY, USA, 17–21 August 2015; pp. 325–338. [Google Scholar]
- Barman, N.; Martini, M.G. QoE Modeling for HTTP Adaptive Video Streaming—A Survey and Open Challenges. IEEE Access 2019, 7, 30831–30859. [Google Scholar] [CrossRef]
- Li, M.; Lee, C.-Y. A Cost-Effective and Real-Time QoE Evaluation Method for Multimedia Streaming Services. Telecommun. Syst. 2015, 59, 317–327. [Google Scholar] [CrossRef]
- Akhshabi, S.; Anantakrishnan, L.; Begen, A.C.; Dovrolis, C. What Happens When HTTP Adaptive Streaming Players Compete for Bandwidth? In Proceedings of the 22nd International Workshop on Network and Operating System Support for Digital Audio and Video, Toronto, ON, Canada, 7–8 June 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 9–14. [Google Scholar]
- Chen, J.; Mahindra, R.; Khojastepour, M.A.; Rangarajan, S.; Chiang, M. A Scheduling Framework for Adaptive Video Delivery over Cellular Network. In Proceedings of the 19th Annual International Conference on Mobile Computing and Networking, Miami, FL, USA, 30 September–4 October 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 389–400. [Google Scholar]
- De Vleeschauwer, D.; Viswanathan, H.; Beck, A.; Benno, S.; Li, G.; Miller, R. Optimization of HTTP Adaptive Streaming over Mobile Cellular Networks. In Proceedings of the IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 989–997. [Google Scholar]
- Bentaleb, A.; Taani, B.; Begen, A.C.; Timmerer, C.; Zimmermann, R. A Survey on Bitrate Adaptation Schemes for Streaming Media over HTTP. IEEE Commun. Surv. Tutor. 2019, 21, 562–585. [Google Scholar] [CrossRef]
- Bae, S.; Jang, D.; Park, K. Why Is HTTP Adaptive Streaming So Hard? In Proceedings of the 6th Asia-Pacific Workshop on Systems, Tokyo, Japan, 27–28 July 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–8. [Google Scholar]
- Kimura, T.; Kimura, T.; Matsumoto, A.; Yamagishi, K. Balancing Quality of Experience and Traffic Volume in Adaptive Bitrate Streaming. IEEE Access 2021, 9, 15530–15547. [Google Scholar] [CrossRef]
- Akhshabi, S.; Anantakrishnan, L.; Dovrolis, C.; Begen, A.C. Server-Based Traffic Shaping for Stabilizing Oscillating Adaptive Streaming Players. In Proceedings of the 23rd ACM Workshop on Network and Operating Systems Support for Digital Audio and Video, Oslo, Norway, 26 February–1 March 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 19–24. [Google Scholar]
- Yan, Z.; Xue, J.; Chen, C.W. QoE Continuum Driven HTTP Adaptive Streaming over Multi-Client Wireless Networks. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo, Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Ramarkrishnan, S.; Zhu, X.; Chan, F.; Kambhatia, K. SDN Based QoE Optimization for HTTP-Based Adaptive Video Streaming. In Proceedings of the 2015 IEEE International Symposium on Multimedia, Miami, FL, USA, 14–16 December 2015; pp. 120–123. [Google Scholar]
- Li, Z.; Zhao, S.; Medhi, D.; Bouazizi, I. Wireless Video Traffic Bottleneck Coordination with A DASH SAND Framework. In Proceedings of the 2016 Visual Communications and Image Processing, Chengdu, China, 27–30 November 2016; pp. 1–4. [Google Scholar]
- Yan, Z.; Xue, J.; Chen, C.W. Prius: Hybrid Edge Cloud and Client Adaptation for HTTP Adaptive Streaming in Cellular Networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 209–222. [Google Scholar] [CrossRef]
- Mehrabi, A.; Siekkinen, M.; Yla-Jaaski, A. Edge Computing Assisted Adaptive Mobile Video Streaming. IEEE Trans. Mob. Comput. 2019, 18, 878–900. [Google Scholar] [CrossRef] [Green Version]
- Rahman, W.U.; Hong, C.S.; Huh, E.-N. Edge Computing Assisted Joint Quality Adaptation for Mobile Video Streaming. IEEE Access 2019, 7, 129082–129094. [Google Scholar] [CrossRef]
- Aguilar-Armijo, J.; Timmerer, C.; Hellwagner, H. EADAS: Edge Assisted Adaptation Scheme for HTTP Adaptive Streaming. In Proceedings of the IEEE 46th Conference on Local Computer Networks, Edmonton, AB, Canada, 4–7 October 2021; pp. 487–494. [Google Scholar]
- Marai, O.E.; Taleb, T.; Menacer, M.; Koudil, M. On Improving Video Streaming Efficiency, Fairness, Stability, and Convergence Time Through Client-Server Cooperation. IEEE Trans. Broadcast. 2018, 64, 11–25. [Google Scholar] [CrossRef]
- Hoßfeld, T.; Skorin-Kapov, L.; Heegaard, P.E.; Varela, M. Definition of QoE Fairness in Shared Systems. IEEE Commun. Lett. 2018, 21, 184–187. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Hu, L.; Hao, P.; Sun, R.; Hu, J.; Li, H. Q-FDBA: Improving QoE Fairness for Video Streaming. Multimed. Tools Appl. 2018, 77, 10787–10806. [Google Scholar] [CrossRef]
- Altamimi, S.; Shirmohammadi, S. QoE-Fair DASH Video Streaming Using Server-Side Reinforcement Learning. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–21. [Google Scholar] [CrossRef]
- Mok, R.K.P.; Chan, E.W.W.; Luo, X.; Chang, R.K.C. Inferring the QoE of HTTP Video Streaming from User-Viewing Activities. In Proceedings of the First ACM SIGCOMM Workshop on Measurements up the Stack, Toronto, ON, Canada, 19 August 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 31–36. [Google Scholar]
- Mok, R.K.P.; Chen, E.W.W.; Chang, R.K.C. Measuring the Quality of Experience of HTTP Video Streaming. In Proceedings of the 12th IFIP/IEEE International Symposium on Integrated Network Management and Workshops, Dublin, Ireland, 23–27 May 2011; pp. 485–492. [Google Scholar]
- Mao, H.; Netravali, R.; Alizadeh, M. Neural Adaptive Video Streaming with Pensieve. In Proceedings of the Conference on the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 197–210. [Google Scholar]
- Bentaleb, A.; Begen, A.C.; Zimmermann, R. ORL-SDN: Online Reinforcement Learning for SDN-Enabled HTTP Adaptive Streaming. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–28. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Z.; Li, B.; Lu, Y. A Deep Reinforcement Learning Approach to Multiple Streams’ Joint Bitrate Allocation. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2415–2426. [Google Scholar] [CrossRef]
- Gadaleta, M.; Chiariotti, F.; Rossi, M.; Zanella, A. D-DASH: A Deep Q-Learning Framework for DASH Video Streaming. IEEE Trans. Cogn. Commun. 2017, 3, 703–718. [Google Scholar] [CrossRef]
- Wei, X.; Zhou, M.; Kwong, S.; Yuan, H.; Wang, S.; Zhu, G.; Cao, J. Reinforcement Learning-Based QoE-Oriented Dynamic Adaptive Streaming Framework. Inf. Sci. 2021, 569, 786–803. [Google Scholar] [CrossRef]
- Mnih, V.; Badi, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Proceedings of the 12th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; MIT Press: Cambridge, MA, USA, 1999; pp. 1057–1063. [Google Scholar]
- Dabney, W.; Barto, A.G. Adaptive Step-Size for Online Temporal Difference Learning. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 872–878. [Google Scholar]
- Konda, V.R.; Tsitsiklis, J.N. Actor-Critic Algorithms. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2000; pp. 1008–1014. Available online: https://proceedings.neurips.cc/paper/1999/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf (accessed on 18 January 2022).
- Petrangeli, S.; Claeys, M.; Latre, S.; Famaey, J.; Truck, F.D. A Multi-Agent Q-Learning-Based Framework for Achieving Fairness in HTTP Adaptive Streaming. In Proceedings of the 2014 IEEE Network Operations and Management Symposium, Krakow, Poland, 5–9 May 2014; pp. 1–9. [Google Scholar]
- Cui, J.; Liu, Y.; Nallanathan, A. Multi-Agent Reinforcement Learning-Based Resource Allocation for UAV Networks. IEEE Trans. Wirel. Commun. 2020, 19, 729–743. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- TFLearn. TFLearn: Deep Learning Library Featuring a Higher-Level API for TensorFlow. Available online: http://tflearn.org/ (accessed on 1 May 2021).
- Federal Communications Commission (FCC). Raw Data-Measuring Broadband America Mobile Data. Available online: https://www.fcc.gov/reports-research/reports (accessed on 1 June 2021).
- Riiser, H.; Vigmostad, P.; Griwodz, C.; Halvorsen, P. Commute Path Bandwidth Traces from 3G Networks: Analysis and Applications. In Proceedings of the 4th ACM Multimedia Systems Conference, Oslo, Norway, 28 February–1 March 2013; pp. 114–118. [Google Scholar]
- Hooft, J.V.D.; Petrangeli, S.; Wauters, T.; Huysegems, R.; Alface, P.R.; Bostoen, T.; Turck, F.D. HTTP/2-Based Adaptive Streaming of HEVC Video over 4G/LTE Networks. IEEE Commun. Lett. 2016, 20, 2177–2180. [Google Scholar] [CrossRef]
- Sediq, A.B.; Gohary, R.H.; Schoenen, R.; Yanikomeroglu, H. Optimal Tradeoff Between Sum-Rate Efficiency and Jain’s Fairness Index in Resource Allocation. IEEE Trans. Wirel. Commun. 2013, 12, 3496–3509. [Google Scholar] [CrossRef] [Green Version]
- DASH Industry Forum. Reference Client 2.4.0. Available online: https://reference.dashif.org/dash.js/v2.4.0/samples/dash-if-reference-player/index.html (accessed on 1 June 2021).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description | Value |
|---|---|---|
| Number of multiple inputs | 8 | |
| Discount factor | 0.99 | |
| , | Learning rates for the actor network and critic network | 0.0001, 0.001 |
| Entropy weight | 5.0 to 0.1 (over 100,000 iterations) | |
| , | Weight parameters used in the QoE of clients | 1.0, 4.3 |
| Maximum number of clients | 20 |
| Schemes | Overall QoE | Bitrate Utility | Smoothness Penalty | Re-Buffering Penalty |
|---|---|---|---|---|
| ECAA | 1.01 | 1.80 | 0.50 | 0.29 |
| Pensieve | 1.68 | 2.01 | 0.14 | 0.19 |
| Proposed | 1.83 | 1.98 | 0.13 | 0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Chung, K. Reinforcement Learning-Based Adaptive Streaming Scheme with Edge Computing Assistance. Sensors 2022, 22, 2171. https://doi.org/10.3390/s22062171
Kim M, Chung K. Reinforcement Learning-Based Adaptive Streaming Scheme with Edge Computing Assistance. Sensors. 2022; 22(6):2171. https://doi.org/10.3390/s22062171
Chicago/Turabian StyleKim, Minsu, and Kwangsue Chung. 2022. "Reinforcement Learning-Based Adaptive Streaming Scheme with Edge Computing Assistance" Sensors 22, no. 6: 2171. https://doi.org/10.3390/s22062171