
Detection of Farmland Obstacles Based on an Improved YOLOv5s Algorithm by Using CIoU and Anchor Box Scale Clustering


Abstract
:1. Introduction
- (1)
- Obstacles are only detected and located, but obstacles cannot be identified and classified, which is disadvantageous to the accurate path planning and obstacle avoidance of agricultural robots or unmanned agricultural vehicles.
- (2)
- The types and number of detected obstacles are limited, and if the selected features are not enough to represent the target obstacle, the missed or fail detection rate will be increased.
2. Related Work
3. Materials and Methods
3.1. Dataset Creation
3.2. Original YOLOv5s Network Architecture
3.3. Improved YOLOv5s Network Architecture
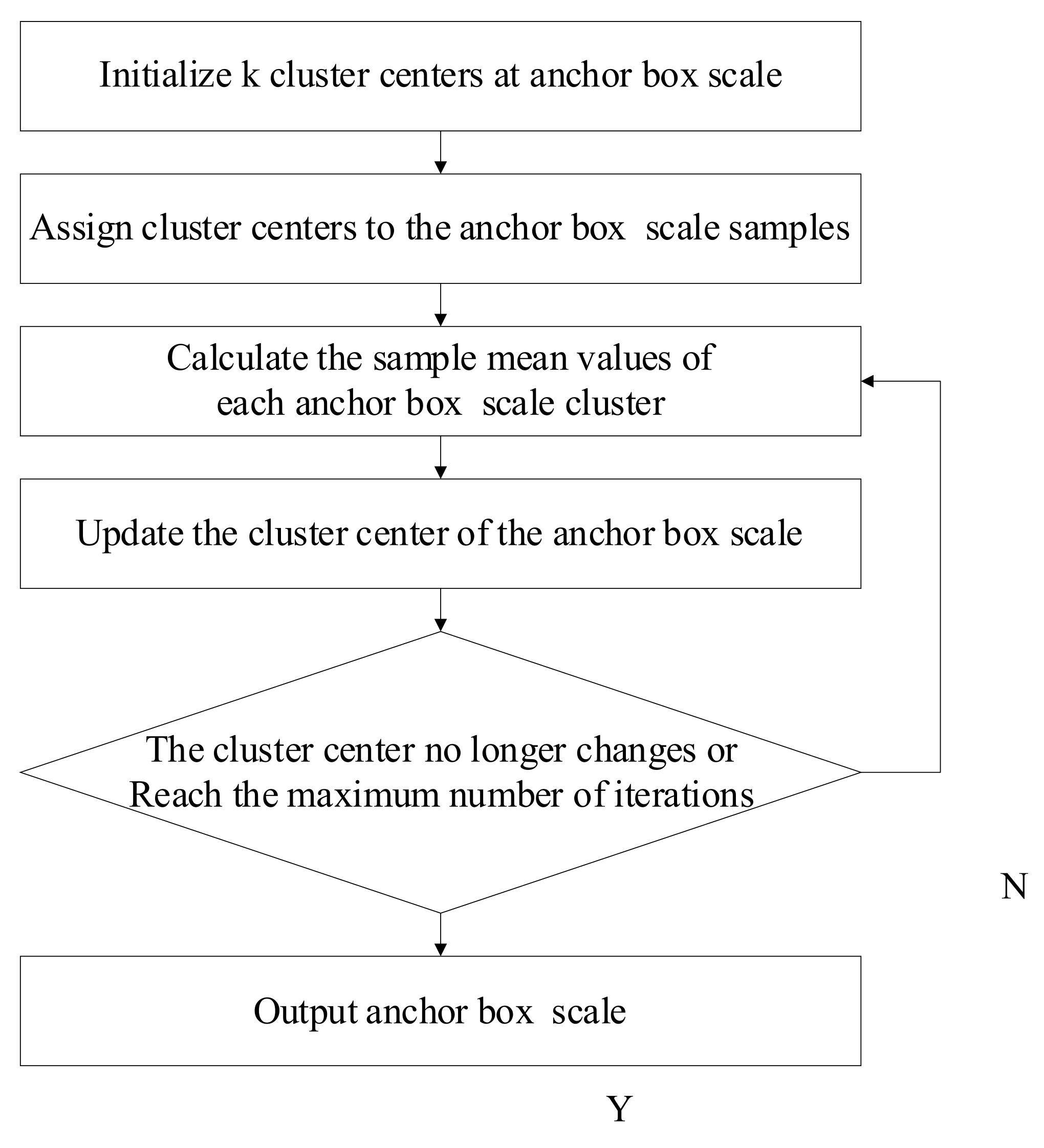
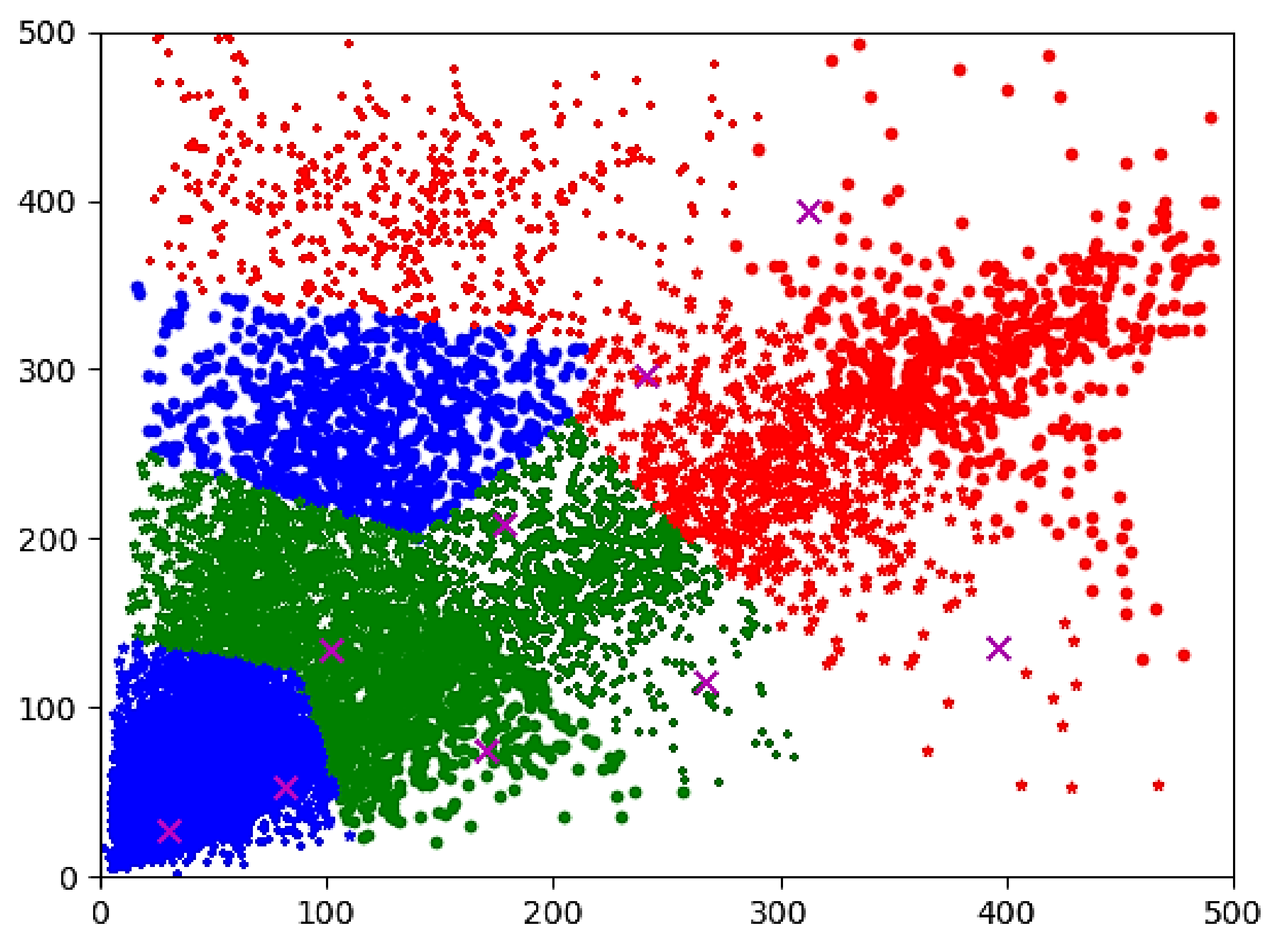
3.3.1. K-Means Clustering Algorithm
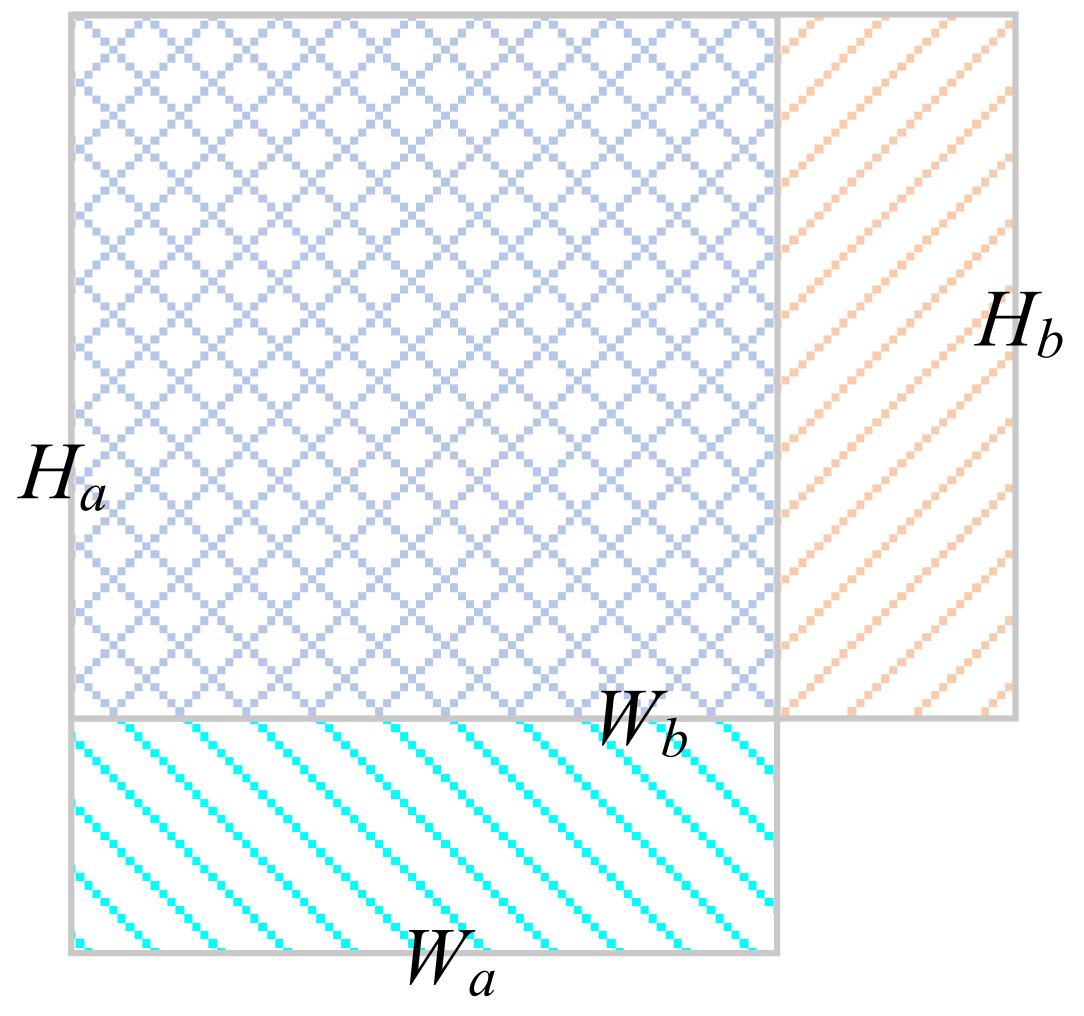
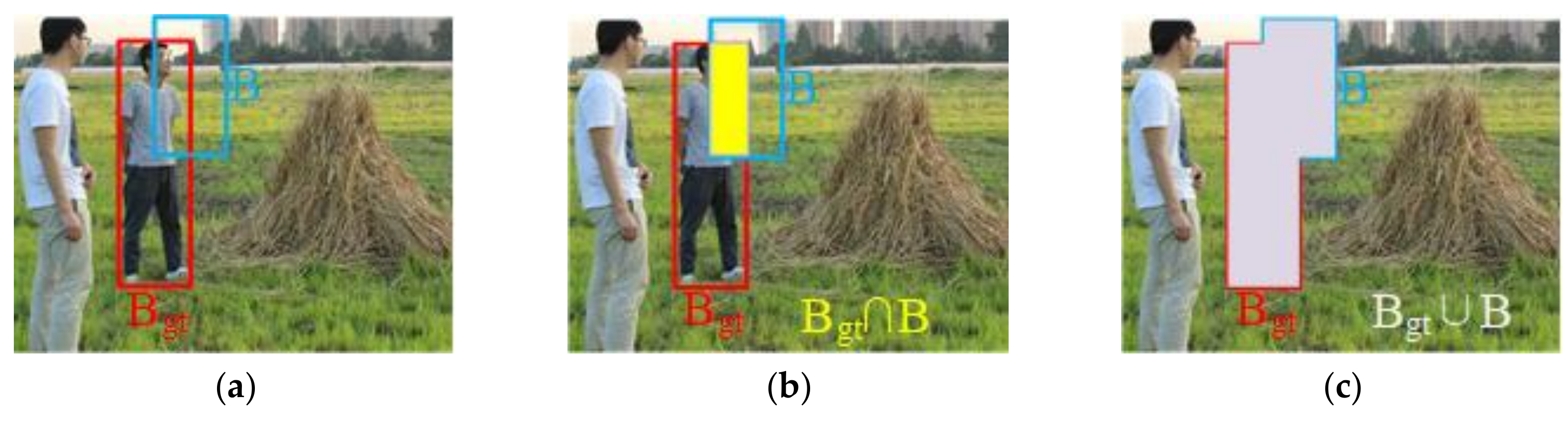
3.3.2. CIoU Loss
3.4. Model Performance Evaluation Indicators
3.5. Training and Inference Process of the Improved YOLOv5s
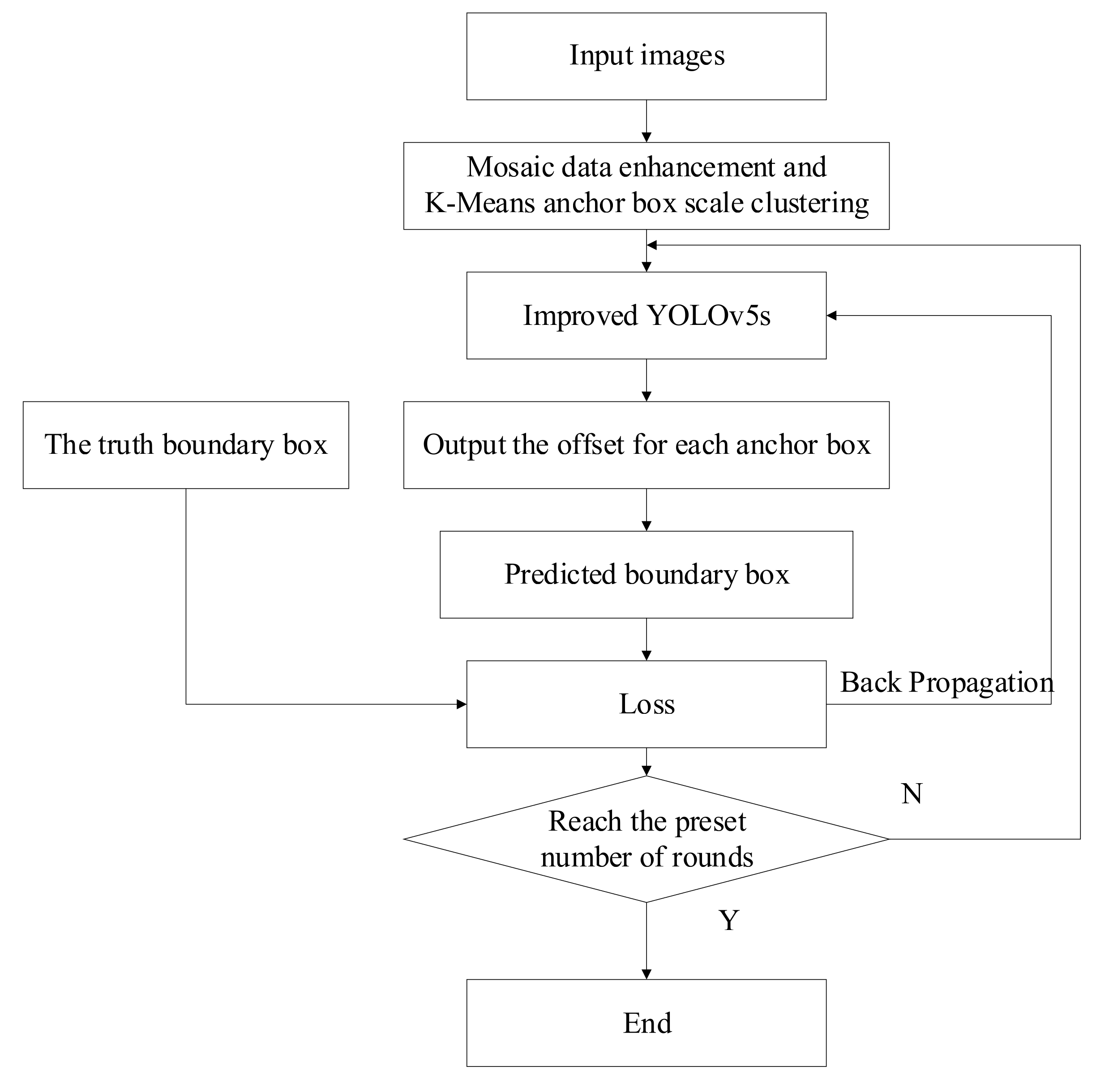
3.5.1. Training Process of the Improved YOLOv5s
3.5.2. Inference Process of the Improved YOLOv5s
4. Results and Discussion
4.1. Experimental Configuration and Training
4.2. Model Performance Evaluation
4.3. Ablation Study on K-Means Clustering Algorithm and CIoU Loss
4.4. Comparison between This Study and Other Target Detection Algorithms
4.5. Comparison between This Study and Other Target Detection Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Francis, S.; Anavatti, S.G.; Garratt, M.; Abbass, H.A. Real-Time Multi-Obstacle Detection and Tracking Using a Vision Sensor for Autonomous Vehicle. Commun. Intell. Syst. 2021, 204, 873–883. [Google Scholar] [CrossRef]
- Mimouna, A.; Khalifa, A.B.; Alouani, I.; Amara, N.E.B.; Rivenq, A.; Taleb-Ahmed, A. Entropy-Based Ultra-Wide Band Radar Signals Segmentation for Multi Obstacle Detection. IEEE Sens. J. 2021, 21, 8142–8149. [Google Scholar] [CrossRef]
- Ji, Y.; Li, S.; Peng, C.; Xu, H.; Cao, R.; Zhang, M. Obstacle Detection and Recognition in Farmland Based on Fusion Point Cloud Data. Comput. Electron. Agric. 2021, 189, 106409. [Google Scholar] [CrossRef]
- Wosner, O.; Farjon, G.; Bar-Hillel, A. Object Detection in Agricultural Contexts: A Multiple Resolution Benchmark and Comparison to Human. Comput. Electron. Agric. 2021, 189, 106404. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review. Sensors 2020, 20, 1520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, H.; Li, S.; Ji, Y.; Cao, R.; Zhang, M. Dynamic Obstacle Detection Based on Panoramic Vision in the Moving State of Agricultural Machineries. Comput. Electron. Agric. 2021, 184, 106104. [Google Scholar] [CrossRef]
- Li, Y.; Li, M.; Qi, J.; Zhou, D.; Zou, Z.; Liu, K. Detection of Typical Obstacles in Orchards Based on Deep Convolutional Neural Network. Comput. Electron. Agric. 2021, 181, 105932. [Google Scholar] [CrossRef]
- Wang, X.; Yang, C.; Ju, Z.; Ma, H.; Fu, M. Robot Manipulator Self-Identification for Surrounding Obstacle Detection. Multimed. Tools Appl. 2017, 76, 6495–6520. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Li, W.; Liu, X.; Li, N.; Zhang, C. UAV Environmental Perception and Autonomous Obstacle Avoidance: A Deep Learning and Depth Camera Combined Solution. Comput. Electron. Agric. 2020, 175, 105523. [Google Scholar] [CrossRef]
- Liu, B.; Lv, Y.; Gu, Y.; Lv, W. Implementation of a Lightweight Semantic Segmentation Algorithm in Road Obstacle Detection. Sensors 2020, 20, 7089. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, Y.; Zhang, J. An Improved Tiny-Yolov3 Pedestrian Detection Algorithm. Optik 2019, 183, 17–23. [Google Scholar] [CrossRef]
- Wang, L.; Lan, Y.; Zhang, Y.; Zhang, H.; Tahir, M.N.; Ou, S.; Liu, X.; Chen, P. Applications and Prospects of Agricultural Unmanned Aerial Vehicle Obstacle Avoidance Technology in China. Sensors 2019, 19, 642. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qi, G.; Zhang, Y.; Wang, K.; Mazur, N.; Liu, Y.; Malaviya, D. Small Object Detection Method Based on Adaptive Spatial Parallel Convolution and Fast Multi-Scale Fusion. Remote Sens. 2022, 14, 420. [Google Scholar] [CrossRef]
- Qi, G.; Wang, H.; Haner, M.; Weng, C.; Chen, S.; Zhu, Z. Convolutional Neural Network Based Detection and Judgement of Environmental Obstacle in Vehicle Operation. CAAI Trans. Intell. Technol. 2019, 4, 80–91. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Xu, Z.; Huang, X.; Huang, Y.; Sun, H.; Wan, F. A Real-Time Zanthoxylum Target Detection Method for an Intelligent Picking Robot under a Complex Background, Based on an Improved YOLOv5s Architecture. Sensors 2022, 22, 682. [Google Scholar] [CrossRef]
- Azam, M.A.; Sampieri, C.; Ioppi, A.; Africano, S.; Vallin, A.; Mocellin, D.; Fragale, M.; Guastini, L.; Moccia, S.; Piazza, C.; et al. Deep Learning Applied to White Light and Narrow Band Imaging Videolaryngoscopy: Toward Real-Time Laryngeal Cancer Detection. Laryngoscope 2021. early view. [Google Scholar] [CrossRef]
- Hsieh, I.-H.; Cheng, H.-C.; Ke, H.-H.; Chen, H.-C.; Wang, W.-J. A CNN-Based Wearable Assistive System for Visually Impaired People Walking Outdoors. Appl. Sci. 2021, 11, 10026. [Google Scholar] [CrossRef]
- Lin, F.; Hou, T.; Jin, Q.; You, A. Improved YOLO Based Detection Algorithm for Floating Debris in Waterway. Entropy 2021, 23, 1111. [Google Scholar] [CrossRef]
- Yu, Y.; Zhao, J.; Gong, Q.; Huang, C.; Zheng, G.; Ma, J. Real-Time Underwater Maritime Object Detection in Side-Scan Sonar Images Based on Transformer-YOLOv5. Remote Sens. 2021, 13, 3555. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, X.; Zhou, Y.; Sun, Q.; Ge, Z.; Liu, D. Real-Time Detection of Particleboard Surface Defects Based on Improved YOLOV5 Target Detection. Sci. Rep. 2021, 11, 21777. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, T.U.; Hossain, S.; Hossain, M.S.; Ul Islam, R.; Andersson, K. Facial Expression Recognition Using Convolutional Neural Network with Data Augmentation. In Proceedings of the 2019 Joint 8th International Conference on Informatics, Electronics & Vision (iciev) and 2019 3rd International Conference on Imaging, Vision & Pattern Recognition (icIVPR) with International Conference on Activity and Behavior Computing (ABC), Spokane, WA, USA, 30 May–2 June 2019; IEEE: New York, NY, USA, 2019; pp. 336–341. [Google Scholar]
- Wang, H.; Zhang, S.; Zhao, S.; Wang, Q.; Li, D.; Zhao, R. Real-Time Detection and Tracking of Fish Abnormal Behavior Based on Improved YOLOV5 and SiamRPN++. Comput. Electron. Agric. 2022, 192, 106512. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Mark Liao, H.-Y.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Zhao, P.; Gao, H.; Zhang, Y.; Li, H.; Yang, R. An Aircraft Detection Method Based on Improved Mask R-Cnn in Remotely Sensed Imagery. In Proceedings of the 2019 Ieee International Geoscience and Remote Sensing Symposium (IGARSS 2019), Yokohama, Japan, 28 July–2 August 2019; IEEE: New York, NY, USA, 2019; pp. 1370–1373. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th Ieee Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 6517–6525. [Google Scholar]
- Liu, G.; Qi, L.; Tie, Y.; Ma, L. Region-of-Interest Detection Based on Statistical Distinctiveness for Panchromatic Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 271–275. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the Thirty-Fourth Aaai Conference on Artificial Intelligence, the Thirty-Second Innovative Applications of Artificial Intelligence Conference and the Tenth Aaai Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Assoc Advancement Artificial Intelligence: Palo Alto, CA, USA, 2020; Volume 34, pp. 12993–13000. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Algorithms | Application | Improvement Method |
|---|---|---|
| Algorithms in the literature | Main research on single-type target detection and recognition | Adding modules which can make the model of YOLOv5s lightweight |
| Algorithm in this paper | Recognition of multi-type obstacles in farmland for un-manned agricultural machinery | Using K-Means clustering to speed up convergence and CIoU Loss function to reduce missed detection and false detection |
| Configuration | Parameter |
|---|---|
| Operating system | Ubuntu16.04 LTS (Canonical, London, UK) |
| Graphics card | GeForce GTX1060 6G (NVIDIA, Santa Clara, CA, USA) |
| CPU | Intel(R) Core (TM) I7-8700K CPU @3.70GHz (Intel, Santa Clara, CA, USA) |
| Deep learning framework | Pytorch1.6.0 |
| Programming environment | Python 3.6, CUDA9.0, CUDNN7.4.2 |
| Improvement Measures | Inference Time of Single Image (s) | mAP (%) |
|---|---|---|
| Original YOLOv5s | 0.062 | 59.32 |
| Original YOLOv5s (With K-Means) | 0.060 | 59.61 |
| Original YOLOv5s (With CIoU Loss) | 0.071 | 65.08 |
| Improved YOLOv5s | 0.074 | 65.12 |
| Detection Algorithm | Inference Time of Single Image (s) | mAP (%) |
|---|---|---|
| Faster R-CNN | 0.274 | 66.76 |
| Original YOLOv5s | 0.062 | 59.32 |
| Improved YOLOv5s | 0.074 | 65.12 |
| Detection Algorithm | Inference Time of Single Image (s) | mAP (%) |
|---|---|---|
| Improved YOLOv5s (With K-Means and CIoU) | 0.074 | 65.12 |
| Improved YOLOv5s (With SE module) | 0.073 | 58.14 |
| Improved YOLOv5s (With Specter module) | 0.076 | 57.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, J.; Cheng, F.; Li, Y.; Song, Y.; Mao, T. Detection of Farmland Obstacles Based on an Improved YOLOv5s Algorithm by Using CIoU and Anchor Box Scale Clustering. Sensors 2022, 22, 1790. https://doi.org/10.3390/s22051790
Xue J, Cheng F, Li Y, Song Y, Mao T. Detection of Farmland Obstacles Based on an Improved YOLOv5s Algorithm by Using CIoU and Anchor Box Scale Clustering. Sensors. 2022; 22(5):1790. https://doi.org/10.3390/s22051790
Chicago/Turabian StyleXue, Jinlin, Feng Cheng, Yuqing Li, Yue Song, and Tingting Mao. 2022. "Detection of Farmland Obstacles Based on an Improved YOLOv5s Algorithm by Using CIoU and Anchor Box Scale Clustering" Sensors 22, no. 5: 1790. https://doi.org/10.3390/s22051790